
ForesightNav: 基于场景想象的高效机器人导航探索策略
ForesightNav:基于场景想象的机器人目标导航框架 摘要:本文提出ForesightNav,一种创新的机器人导航框架,通过引入场景想象能力实现从反应式探索到预见式规划的范式转变。该框架包含三个核心组件:(1)GeoSem Map融合几何与语义信息;(2)场景想象模块基于局部观察预测未探索区域结构;(3)语义匹配机制实现目标定位。实验表明,在Gibson和HM3D数据集上,Foresight
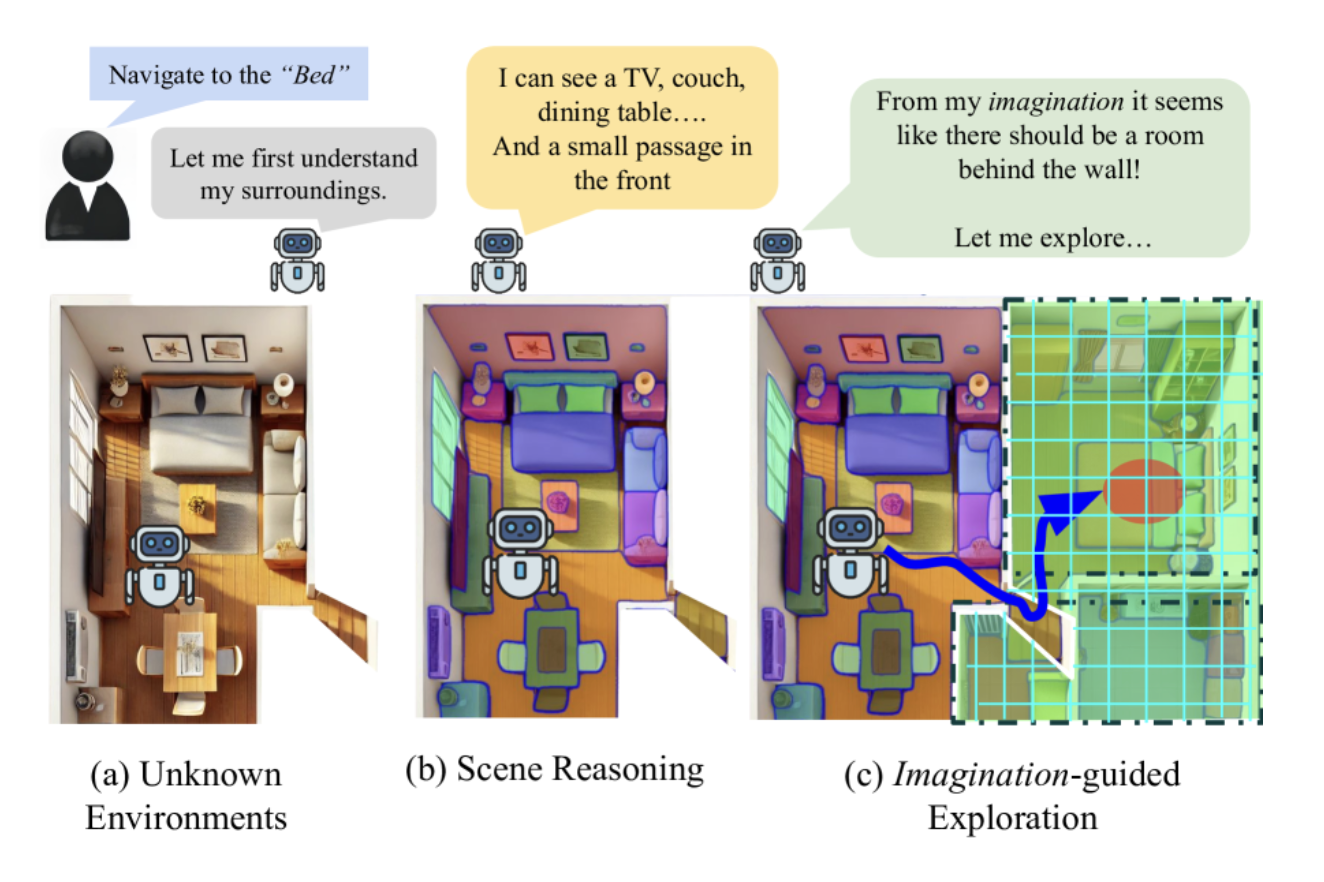
1. 引言:从反应式探索到预见式规划
在机器人导航领域,如何让机器人在完全未知的环境中高效地找到目标物体,一直是一个极具挑战性的研究课题。传统的导航方法大多采用"反应式探索"策略,即机器人只能根据当前传感器观测到的局部信息做出决策,本质上是"走一步看一步"的思路。这种方法在面对复杂室内环境时往往效率低下,机器人会产生大量无效的探索路径。
人类在陌生环境中导航时,会自然而然地运用"想象"能力。当我们走进一个房间,看到客厅的布局后,大脑会自动推测相邻区域可能存在的结构:厨房可能在哪个方向、卧室大概是什么样子。这种基于先验知识的场景想象能力,使人类能够制定更加高效的探索策略。
ForesightNav正是受到这一人类认知能力启发而诞生的导航框架。该工作由苏黎世联邦理工学院(ETH Zurich)和苏黎世大学的研究团队提出,发表于CVPR 2025 Workshop。ForesightNav的核心创新在于:让机器人具备"场景想象"能力,能够基于局部观察推理出全局场景结构,从而实现从"反应式探索"到"预见式规划"的范式转变。代码地址在:https://github.com/uzh-rpg/foresight-nav
2. 技术背景:目标导航领域的发展脉络
2.1 具身目标导航任务定义
具身目标导航(Object-Goal Navigation, ObjectNav)是具身智能领域的核心任务之一。给定一个语义目标(如"找到床"),机器人需要在未知环境中自主探索并导航到目标物体附近。这一任务的难点在于:机器人初始时对环境一无所知,需要在探索过程中逐步构建对环境的理解,同时做出合理的导航决策。
2.2 现有方法的局限性
当前主流的目标导航方法可以分为以下几个流派:
| 方法类别 | 核心技术 | 优势 | 不足 |
|---|---|---|---|
| 传统 ObjectNav | 强化学习/示范学习/语义拓扑图 | 训练数据充足时精度高 | 泛化性差,依赖预定义类别 |
| 零样本 ObjectNav | CLIP/LLM + 前沿探索点 | 支持开放词汇,零样本适应 | 计算开销大,缺乏全局推理 |
| 场景图表示方法 | 拓扑图/多模态嵌入 | 支持大规模环境建模 | 需预探索,实时性不足 |
| ForesightNav | GeoSem Map + 想象模块 | 几何-语义联合预测,主动推理导航 | 大场景下内存消耗较高 |
传统方法的核心问题在于:它们只能利用已观察到的信息进行决策,无法对未探索区域进行有效推理。这就像一个人在黑暗中摸索前进,每次只能看到脚下的一小块区域,自然难以找到最优路径。
而ForesightNav提出了一种全新的思路:通过神经网络学习"局部观察到全局场景"的映射规律,让机器人能够"脑补"未探索区域的几何结构和语义信息。这种方法的本质是将人类的空间想象能力工程化,使机器人具备类似人类的前瞻性规划能力。
3. 核心框架:ForesightNav系统架构
3.1 整体流程概述
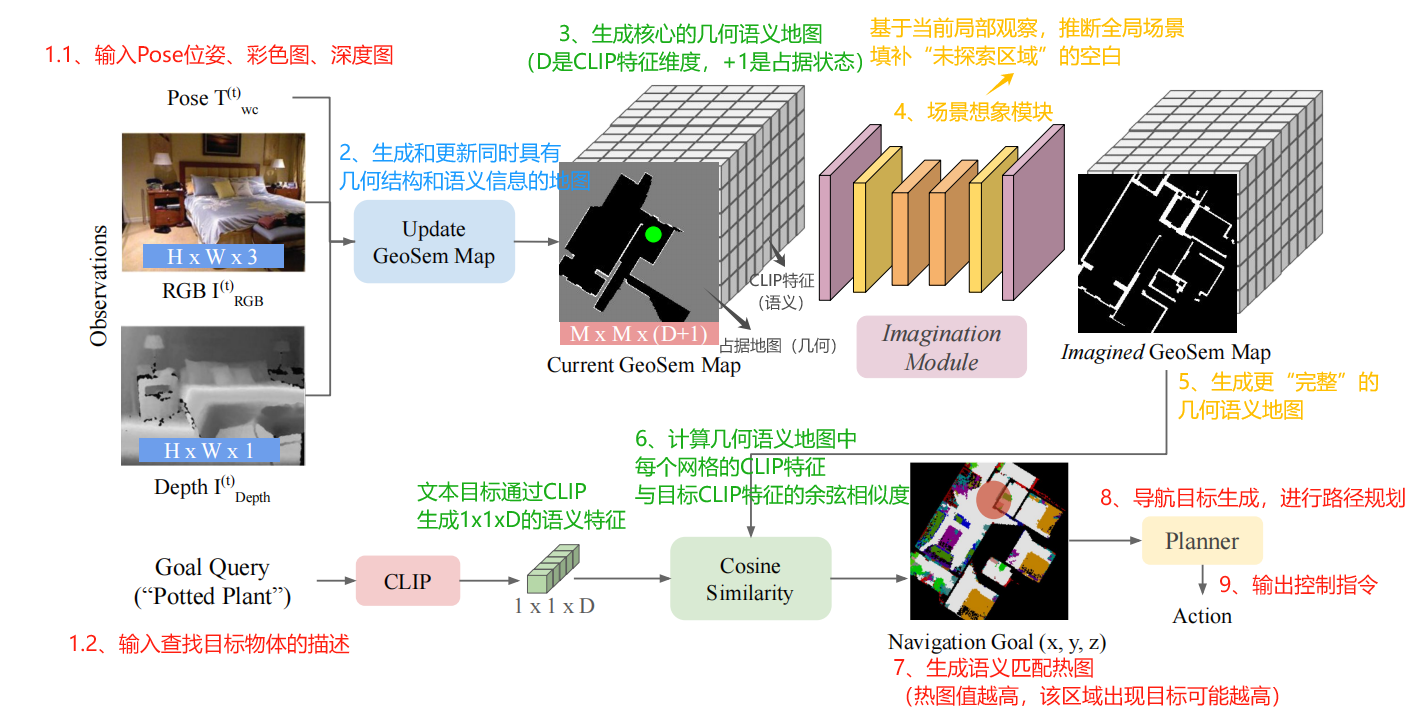
ForesightNav的核心思想可以概括为**"观察-记忆-想象-规划"闭环**。整个系统的处理流程如下图所示:
系统的完整处理流程包含以下九个关键步骤:
- 输入采集:获取机器人的位姿(Pose)信息、RGB彩色图像和深度图
- 目标查询:接收用户输入的目标物体描述(如"Bed"、“TV”)
- 地图生成与更新:构建包含几何结构和语义信息的GeoSem Map
- 语义特征提取:使用CLIP模型生成图像的语义嵌入向量
- 场景想象:基于局部观察,通过神经网络推理未探索区域的结构
- 地图补全:生成"完整"的几何语义地图,包含推理出的未知区域
- 语义匹配:计算地图中每个网格与目标物体的CLIP特征余弦相似度
- 目标生成:基于语义热力图确定导航目标点
- 路径规划:使用A*算法规划从当前位置到目标点的路径
3.2 几何语义地图(GeoSem Map)
GeoSem Map是ForesightNav的核心数据结构,它创新性地将几何占据信息和语义嵌入特征融合在统一的表示中。
GeoSem Map的维度为 M × M × (D+1),其中:
M × M:地图的空间分辨率(默认224×224)D:CLIP语义特征的维度(使用ViT-B/32时为512维)+1:占据状态通道(0表示空闲,1表示占据,0.5表示未知)
这种设计的优势在于:
- 几何层:通过深度点云投影构建占据地图,解决"哪里能走"的问题
- 语义层:通过LSeg编码器提取CLIP嵌入,解决"哪里有什么"的问题
- 统一表示:几何和语义信息在同一张地图中对齐,便于后续联合推理
下图展示了GeoSem Map的生成过程和可视化效果:
3.3 场景想象模块(Imagination Module)
场景想象模块是ForesightNav的核心创新点,它负责将部分观察到的GeoSem Map"补全"为完整的全局场景预测。
想象模块支持两种网络架构:
U-Net架构:
- 采用经典的编码器-解码器结构,卷积层深度为[64, 128, 256, 512, 1024]
- 擅长捕捉局部几何特征(如墙壁轮廓、门窗位置)
- 适合占据掩码的精确预测
ViT架构(基于MAE):
- 基于Masked Autoencoder的Vision Transformer结构
- 利用自注意力机制捕捉全局语义关联
- 适合语义特征的上下文推理(如"客厅有沙发→卧室可能有床")
想象模块的输出包含三个部分:
- 预测的CLIP特征图:未探索区域的语义嵌入
- 预测的占据图:未探索区域的几何结构
- 室内掩码:区分室内外区域
4. 代码实现深度解析
4.1 CLIP、GeoSem Map与U-Net的联合工作流程
在深入代码之前,首先需要理解这三个核心组件是如何协同工作的。整个流程可以用下图来表示:
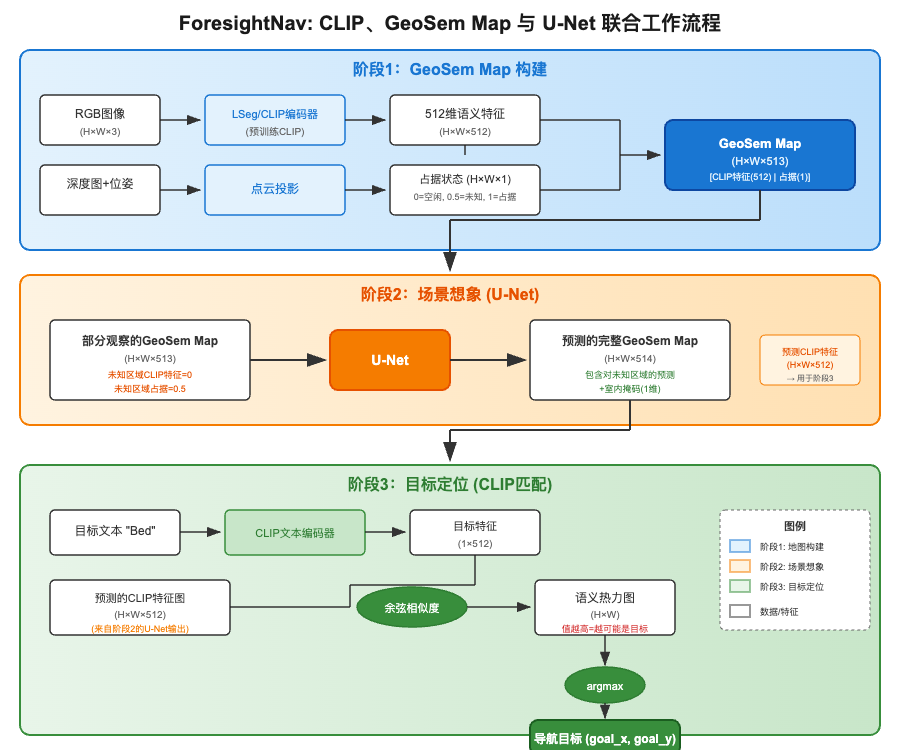
核心理解要点:
-
CLIP的作用:CLIP在两个地方发挥作用
- 构建阶段:通过LSeg编码器将RGB图像编码为512维语义特征,存入GeoSem Map
- 匹配阶段:将目标文本编码为512维向量,与地图中的特征计算相似度
-
GeoSem Map的本质:它是一个"语义-几何融合地图"
- 每个像素位置存储513个数值:512维CLIP语义特征 + 1维占据状态
- 已观察区域有完整的语义+几何信息
- 未观察区域的CLIP特征为0,占据状态为0.5
-
U-Net的任务:将"残缺的"GeoSem Map补全为"完整的"GeoSem Map
- 输入:部分观察的地图(未知区域特征为0)
- 输出:预测的完整地图(包含对未知区域的推理)
- 本质是学习"已知→未知"的空间推理能力
-
数据流的关键转换:
[H,W,512] CLIP特征 + [H,W,1] 占据 = [H,W,513] GeoSem Map ↓ U-Net [H,W,512] 预测CLIP + [H,W,1] 预测占据 + [H,W,1] 室内掩码 = [H,W,514] ↓ 与目标CLIP特征做矩阵乘法 [H,W] 相似度热力图 ↓ argmax (goal_x, goal_y) 导航目标
理解了这个联合流程后,下面我们来看具体的代码实现。
4.2 U-Net网络结构实现
ForesightNav采用经典的U-Net架构作为想象模块的基础网络。以下是U-Net的核心实现代码:
class UNet2D(nn.Module):
def __init__(self, in_channels, out_channels, conv_depths=(64, 128, 256, 512, 1024)):
assert len(conv_depths) > 2, 'conv_depths must have at least 3 members'
super(UNet2D, self).__init__()
# 编码器层:逐步下采样并增加通道数
encoder_layers = []
encoder_layers.append(First2D(in_channels, conv_depths[0], conv_depths[0]))
encoder_layers.extend([
Encoder2D(conv_depths[i], conv_depths[i + 1], conv_depths[i + 1])
for i in range(len(conv_depths)-2)
])
# 解码器层:逐步上采样并减少通道数
decoder_layers = []
decoder_layers.extend([
Decoder2D(2 * conv_depths[i + 1], 2 * conv_depths[i],
2 * conv_depths[i], conv_depths[i])
for i in reversed(range(len(conv_depths)-2))
])
decoder_layers.append(Last2D(2*conv_depths[0], conv_depths[0], out_channels))
self.encoder_layers = nn.Sequential(*encoder_layers)
self.center = Center2D(conv_depths[-2], conv_depths[-1],
conv_depths[-1], conv_depths[-2])
self.decoder_layers = nn.Sequential(*decoder_layers)
U-Net的核心设计思想是跳跃连接(Skip Connection):编码器的每一层特征都会与解码器对应层的特征进行拼接,这样可以同时保留低层的细节信息和高层的语义信息。
4.3 GeoSem Map预测模型
基于U-Net的GeoSem Map预测模型实现如下:
class UNet2D_GeoSem_Pred(UNet2D):
"""
用于预测完整GeoSem Map的U-Net模型
输入:部分观察的GeoSem Map [N, D+1, H, W]
输出:预测的完整GeoSem Map [N, D+2, H, W]
"""
def forward(self, input: torch.Tensor, inference: bool=False) -> torch.Tensor:
pred_geosem = self.forward_pass(input) # [N, D+2, H, W]
if inference:
# 分离CLIP特征、占据图和室内掩码
pred_clip = pred_geosem[:, :512, :, :]
pred_occ = pred_geosem[:, 512, :, :]
pred_int_mask = pred_geosem[:, 513, :, :]
# CLIP特征归一化
pred_clip = nn.functional.normalize(pred_clip, p=2, dim=1)
# 占据图和室内掩码应用sigmoid激活
pred_occ = nn.functional.sigmoid(pred_occ).unsqueeze(1)
pred_int_mask = nn.functional.sigmoid(pred_int_mask).unsqueeze(1)
pred_geosem_inf = torch.cat([pred_clip, pred_occ, pred_int_mask], dim=1)
return pred_geosem_inf
else:
return pred_geosem
这段代码展示了推理时的关键处理步骤:
- CLIP特征需要进行L2归一化,以便进行余弦相似度计算
- 占据图和室内掩码通过sigmoid函数转换为概率值
4.4 想象模型的目标提取逻辑(核心联合逻辑)
这部分代码是理解CLIP、GeoSem Map和U-Net如何联合工作的关键:
想象模型在导航过程中的实际应用逻辑如下:
class ImaginationModel(ExplorationModel):
def get_goal(self, input):
"""
使用想象模块预测全局场景,并提取导航目标点
"""
x, y = input["x"], input["y"]
pred_map = torch.from_numpy(input["pred_map"]).unsqueeze(0)
# 构建当前观察的GeoSem Map
clipfeat_map = deepcopy(self.gt_clipfeat_map)
clipfeat_map[pred_map.squeeze(0) == 0.5] = 0 # 未知区域清零
# 归一化CLIP特征
norm = np.linalg.norm(clipfeat_map, axis=-1, keepdims=True)
norm[norm == 0] = 1
clipfeat_map = clipfeat_map / norm
clipfeat_map = torch.from_numpy(clipfeat_map).permute(2, 0, 1)
# 拼接CLIP特征和占据图
cur_geosem_map = torch.cat([clipfeat_map, pred_map], dim=0).unsqueeze(0)
# 使用想象模块预测完整场景
with torch.no_grad():
pred_geosem_map = self.model(input=cur_geosem_map, inference=True)
# 解析预测结果
pred_geosem_map = pred_geosem_map.squeeze(0).permute(1, 2, 0).cpu().numpy()
pred_clipfeat_map = pred_geosem_map[:, :, :512]
pred_occ = pred_geosem_map[:, :, 512] > self.occ_thresh
int_mask = pred_geosem_map[:, :, 513] > self.int_thresh
# 使用室内掩码过滤室外区域
if self.use_int_mask:
pred_clipfeat_map[~int_mask] = 0
pred_clipfeat_map[pred_map.squeeze(0) != 0.5] = 0
# 计算与目标物体的语义相似度
map_feats = pred_clipfeat_map.reshape(-1, pred_clipfeat_map.shape[-1])#压缩(size,512)尺寸
goal_sim = map_feats @ self.goal_clip_feat.T
goal_sim = goal_sim.reshape(pred_clipfeat_map.shape[:2])
# 选择相似度最高的位置作为导航目标
goal_idx = np.argmax(goal_sim)
goal_x, goal_y = np.unravel_index(goal_idx, goal_sim.shape)
return {"goal_x": goal_x, "goal_y": goal_y, "roll_back": False}
代码逐步解析:
步骤1 - 构建部分观察的GeoSem Map:
clipfeat_map = deepcopy(self.gt_clipfeat_map)
clipfeat_map[pred_map.squeeze(0) == 0.5] = 0 # 关键:未知区域CLIP特征清零
cur_geosem_map = torch.cat([clipfeat_map, pred_map], dim=0) # 拼接为513通道
这一步将已观察区域的CLIP特征保留,未观察区域设为0,与占据图拼接形成输入。
步骤2 - U-Net推理预测完整场景:
pred_geosem_map = self.model(input=cur_geosem_map, inference=True)
U-Net接收513通道输入,输出514通道预测(含室内掩码)。
步骤3 - CLIP特征与目标文本匹配:
map_feats = pred_clipfeat_map.reshape(-1, 512) # 展平为(H*W, 512)
goal_sim = map_feats @ self.goal_clip_feat.T # 矩阵乘法计算相似度
这里self.goal_clip_feat是目标文本"Bed"的CLIP编码(1×512),通过矩阵乘法一次性计算所有位置与目标的相似度。
步骤4 - 选取导航目标:
goal_idx = np.argmax(goal_sim)
goal_x, goal_y = np.unravel_index(goal_idx, goal_sim.shape)
选择相似度最高的位置作为导航目标。
…详情请参照古月居

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 25
25 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)