
重构数字人交互体验:魔珐星云+DeepSeek打造情绪陪伴数字人全流程实战测评
《情绪陪伴数字人:基于魔珐星云平台的具身智能实践》摘要 本文探讨了如何利用魔珐星云具身智能平台构建具备情绪识别与共情能力的数字人。传统3D数字人存在交互延迟、表情不同步等问题,而星云平台通过参数流架构实现端侧渲染,将延迟降至500ms以内。文章详细介绍了情绪陪伴数字人的实现过程:通过关键词匹配识别用户情绪,结合220条手工构建的RAG知识库生成共情回复,并利用星云SDK快速接入数字人交互能力。测试
目录
摘要
传统的3D数字人常常沦为"技术花瓶"——看起来炫酷,交互起来却卡顿、出戏。本文以魔珐星云具身智能数字人开放平台为核心,结合魔搭社区DeepSeek-V3.2大模型,从零构建一个具备情绪识别与共情能力的"情绪陪伴数字人"。文章将围绕星云SDK的接入方式、端侧渲染+参数流架构如何破解低延迟高并发难题、以及情绪识别与RAG知识库增强对话体验等核心环节展开深度测评。读者将全面了解:为什么星云不是传统数字人播放器而是"AI屏幕OS"、参数流架构相比视频流的技术代差、以及一个完整的情感陪伴Agent如何在一周内从想法变成可运行的应用。
1. 引言:当数字人有了"情绪",事情就不一样了
1.1 数字人的尴尬现状
过去两年,"数字人"三个字从资本热词变成了行业标配。银行大厅有数字人客服、电商直播间有数字人主播、甚至县城政务大厅也上了数字人引导员。
但如果你真正体验过,大概率会有同感——这些东西真的很"假"。
不是画面不够精致。现在的3D渲染技术,把皮肤纹理、衣服褶皱、头发丝都做得真假难辨。问题出在交互上:
-
你在屏幕前问"今天心情不太好",它需要停顿3-5秒才开始回应
-
它的表情永远慢半拍——你说完一句伤心的话,它笑着回答
-
它在网页上加载半分钟,手机上直接卡成PPT
这些问题的核心,在于数字人交互链路的实时性与同步性不足,AI生成文本 → TTS合成语音 → 云端渲染视频 → 推流到终端。这条链路每一步都在累积延迟,每一步都在消耗带宽和算力。
1.2 为什么"情绪陪伴"是一个理想的实验场景
我选"情绪陪伴数字人"作为测评场景,有三层考虑:
第一层:交互频率高。 情绪陪伴是对话密集型场景,用户期待实时响应。
第二层:对"真实感"要求极高。 用户输入的是情绪("我今天特别难过"),输出必须是符合情绪的反馈——表情、语气、动作都需要对得上。这比"帮我查个天气"复杂一个量级。
第三层:技术栈完整。 情绪识别 → 共情生成 → 具身表达,恰好覆盖了星云平台的"感知层→认知层→表达层"全链路。一次开发,能把平台能力摸透。
1.3 我的测评方法
这篇文章不是官方说明书的翻译,也不是PPT的复述。以下全部内容来自我亲自跑通的一个完整项目:Emotion Companion(情绪陪伴数字人)。
我会遵循这条路来讲:
项目想法 → 技术选型 → 架构设计 → 核心实现 → 实际体验 → 踩坑记录 → 总结评价代码部分我会点到为止,不会大段贴源码。重点是让你理解为什么这样做和实际效果如何,而不是复制粘贴。
2. 魔珐星云:不是数字人播放器,是AI屏幕OS
2.1 先搞清楚一个基本概念
大部分人对魔珐星云的误解是:"哦,就是做3D数字人的公司。"
这个理解相当于说"苹果是做手机壳的公司"——不能说完全错,但偏离了本质。
魔珐星云真正的定位是具身智能数字人开放平台。关键词不是"数字人",而是"具身智能"和"开放平台"。
让我用一个对比来澄清:
|
维度 |
传统数字人厂商 |
魔珐星云 |
|
技术路线 |
云端渲染视频流 |
端侧渲染参数流 |
|
核心产品 |
给你一个做好的数字人 |
给你一套造数字人的工具链 |
|
对接方式 |
买数字人 → 嵌入网页 |
SDK接入 → 自己造数字人 |
|
自定义程度 |
低,仅支持服饰、背景等基础形象替换 |
高,可精准控制表情、微动作、语气、交互逻辑、场景行为 |
|
响应延迟 |
1.5‑3 秒,云端传输链路冗长,延迟偏高 |
≤500ms,端到端毫秒级实时响应 |
|
部署成本 |
高,依赖云端 GPU 服务器,算力开销大 |
低,端侧本地运行,普通设备即可承载,轻量化部署 |
|
并发承载 |
性能薄弱,并发量提升则算力成本线性上涨 |
支持千万级高并发,并发规模扩大后成本稳定可控 |
|
终端适配 |
适配受限,强依赖网络与解码能力,老旧终端无法运行 |
全终端兼容,适配企业大屏、车机、手机、PC 等多类终端 |
|
交互能力 |
单向被动播报,无法实时打断,动作表情依赖预制模板 |
双向实时交互,支持随时打断,神态动作随对话语义动态联动 |
|
开发门槛 |
门槛较高,云端架构适配复杂,需专业算力运维 |
门槛低,SDK 封装完善,几行代码即可快速接入落地 |
简单来说:魔珐星云不提供成品数字人,而是交付构建数字人交互能力的底层工具与技术底座。
2.2 参数流 vs 视频流:为什么延迟能降到毫秒级
这是我认为星云最核心的技术差异化点。
视频流方案(传统路线):
用户输入 → 云端AI处理 → 云端TTS合成 → 云端3D渲染 → 视频编码 → CDN分发 → 终端播放 ↓_______________500ms-2s_______________↓每一步都在云端完成,每一步都在累积延迟。而且云端渲染3D是沉重的GPU开销,一个并发用户就需要一堆GPU资源。
参数流方案(星云路线):
用户输入 → 云端AI处理 → 返回动作/表情/语音参数 → 终端本地渲染
↓______________500ms_______________↓关键区别:
-
云端不渲染视频,只计算"数字人应该怎么动、什么表情、说什么话"的参数
-
终端设备渲染,利用手机/电脑自身的GPU能力
-
传输的是参数(几KB),不是视频流(几MB/秒)
这带来的好处是结构性的:
|
指标 |
视频流方案 |
星云参数流 |
|
首帧延迟 |
1-5秒 |
≈500ms |
|
带宽消耗 |
2-5 Mbps |
<100 Kbps |
|
并发成本 |
线性增长(GPU实例) |
几乎恒定 |
|
终端兼容 |
需要强解码能力 |
普通设备即可 |
本质优势在于:端侧本地渲染 + 参数流传输,彻底解决交互延迟、音画不同步问题,实现实时流畅的数字人交互。
2.3 平台三层架构
星云平台的技术架构可以理解为三层:
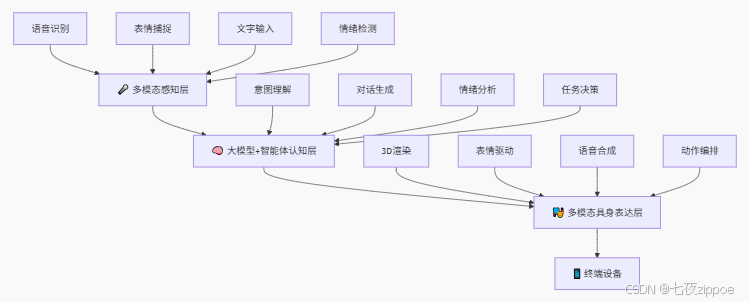
-
感知层:接收用户的多模态输入(文字、语音、表情等)
-
认知层:大模型理解意图、生成回应、做出决策
-
表达层:将认知结果转化为数字人的表情、动作和语音
我的情绪陪伴项目恰好完整贯穿了这三层,下面我会逐一展示每层的实现方式。
3. 情绪陪伴数字人:架构设计与核心实现
3.1 整体架构
这个项目的架构不算复杂,但层次分明:
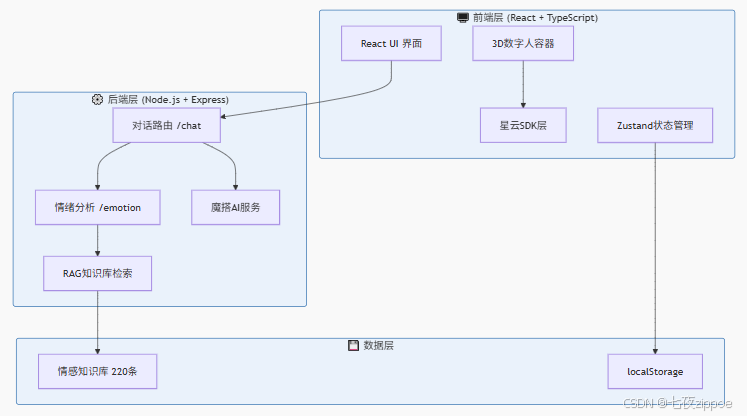
前端:React + TypeScript + TailwindCSS,主要负责UI渲染和数字人展示。状态管理用Zustand(轻量、无模板代码)。
后端:Node.js + Express,提供对话API、情绪分析、RAG检索。所有AI调用都在后端完成,前端只负责展示。
数据:220条手工构建的情感陪伴知识库,按四个维度(情绪陪伴、共情回应、安慰支持、激励鼓励)组织。用户数据存localStorage。
3.2 数字人SDK接入:5分钟搞定的体验
这是整个项目中给我体验最好的部分。魔珐星云提供了JavaScript CDN接入方式,不需要安装任何npm包,只需要在HTML中引入一个script标签,然后调几个API就搞定了。
// 数字人SDK初始化(极简版)
// 1. 引入SDK CDN
// <script src="https://media.youyan.xyz/youling-lite-sdk/...js"></script>
// 2. 初始化
const avatar = new XingYunAvatar({
container: document.getElementById('avatar-container'),
appId: 'your-app-id',
appSecret: 'your-app-secret'
});
// 3. 连接数字人
await avatar.connect();
// 4. 让数字人说话
await avatar.speak('你好,我是你的情绪陪伴师小云,今天想和我聊什么?');
// 5. 控制表情
avatar.setEmotion('happy', 0.8); // 情绪类型 + 强度经过五步就实现了一个可对话、有表情的三维数字人。初始化的代码非常简洁:appId和appSecret在星云控制台申请,container指定数字人渲染的容器元素。connect()方法会建立WebSocket长连接,这一步通常耗时1-2秒。连接成功后调用speak()数字人就会开始口播,同时伴以自然的身体微动作。setEmotion()可以实时控制表情——这正是情绪陪伴场景的核心能力。
整个接入过程,从打开文档到数字人在浏览器里动起来,我花了不到半小时。对于习惯了"接一个SDK要读两天文档"的开发者来说,这个体验可以说是惊喜。
3.3 情绪识别:关键词匹配就够了?
这里我得说实话——这个项目用的是基于关键词的情绪识别,不是什么深度学习情绪分析模型。
# 情绪识别核心逻辑(服务端)
EMOTION_KEYWORDS = {
'happy': ['开心', '高兴', '快乐', '哈哈', '太好了', '棒'],
'sad': ['难过', '伤心', '悲伤', '想哭', '失落', '郁闷'],
'angry': ['生气', '愤怒', '火大', '恼火', '烦死了'],
'anxious': ['焦虑', '紧张', '不安', '担心', '心慌'],
'fear': ['害怕', '恐惧', '恐慌', '吓人'],
}
def detect_emotion(text: str):
scores = {}
for emotion, keywords in EMOTION_KEYWORDS.items():
score = sum(text.count(kw) * (i + 1) # 关键词位置加权
for i, kw in enumerate(keywords) if kw in text)
if score > 0:
scores[emotion] = min(score / 10, 1.0) # 归一化到0-1
return scores or {'normal': 0.0}这段代码实现了基于关键词的情绪识别。它遍历预定义的六种情绪关键词列表,对用户输入进行匹配。每个关键词根据列表中的位置计算权重——越靠前的关键词权重越高。最终分数会根据匹配数量累加并归一化到0-1之间。比如用户说"我今天特别开心",happy情绪得分可能是0.7。如果没有任何关键词匹配到,就返回normal状态。
为什么不用深度学习模型?
三个原因:
-
够用。情绪陪伴场景不需要72种情绪的精细分类,"开心/难过/愤怒/焦虑/害怕"五类覆盖了90%的对话
-
快。关键词匹配是O(n)的,不需要加载模型,不需要GPU
-
可控。想加一个情绪类别,加几行关键词就搞定,不需要重新训练
当然我也知道这个方案的局限——比如"我开心得要哭了"会被误判为sad。但在Demo阶段,这是一个性价比极高的选择。
3.4 RAG知识库:让AI的安慰不是"正确的废话"
项目最大的亮点之一是220条手工构建的情感陪伴知识库:
|
知识库分类 |
数量 |
用途举例 |
|
emotion 情绪陪伴 |
55条 |
"我理解你现在的感受..." |
|
empathy 共情回应 |
55条 |
"如果是我遇到这种情况..." |
|
comfort 安慰支持 |
55条 |
"没关系,一切都会好起来的..." |
|
motivation 激励鼓励 |
55条 |
"你已经做得很好了..." |
这些不是从网上爬取的,而是根据真实心理咨询对话模式手工编写的。每条都针对特定的情绪场景。
RAG的工作流程:
用户输入:"工作压力好大,感觉快撑不住了"
↓
情绪识别:anxious (焦虑), sad (悲伤)
↓
知识库检索:匹配 comfort + empathy 相关内容
↓
构建增强Prompt:系统指令 + 知识库内容 + 用户输入
↓
DeepSeek-V3.2 生成带共情的回复加了RAG和没加RAG的对比非常明显:
|
场景 |
不加RAG |
加RAG |
|
"工作压力大" |
"适当运动可以缓解压力" |
"我能感受到你现在承受了很多。工作压力大的时候,给自己一个喘息的空间很重要。想聊聊具体是什么让你感到吃力吗?" |
|
"好孤独" |
"可以多参加社交活动" |
"孤独是一种很真实的感受。有时候即使周围很多人,也会觉得孤单。你愿意和我分享一下,这种感觉是什么时候开始的吗?" |
RAG的效果是两个维度的:内容上,回复从"通用鸡汤"变成了"具体共情";风格上,回复从"给建议"变成了"先倾听"。
4. 实操体验:从连接数字人到完成一次情绪对话
4.1 完整交互流程
以下是我在浏览器中实际操作的完整流程,每一步都有能实操还原:
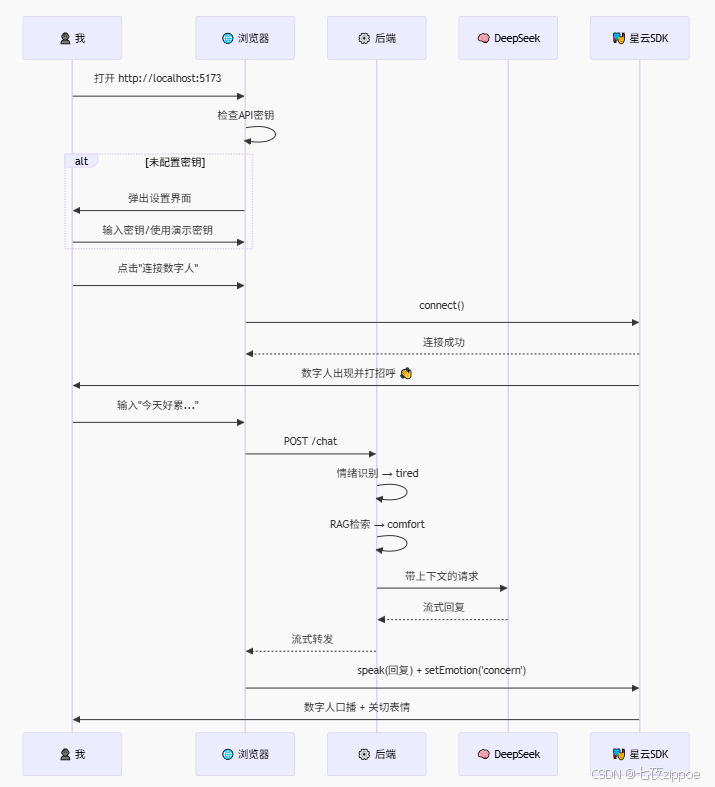
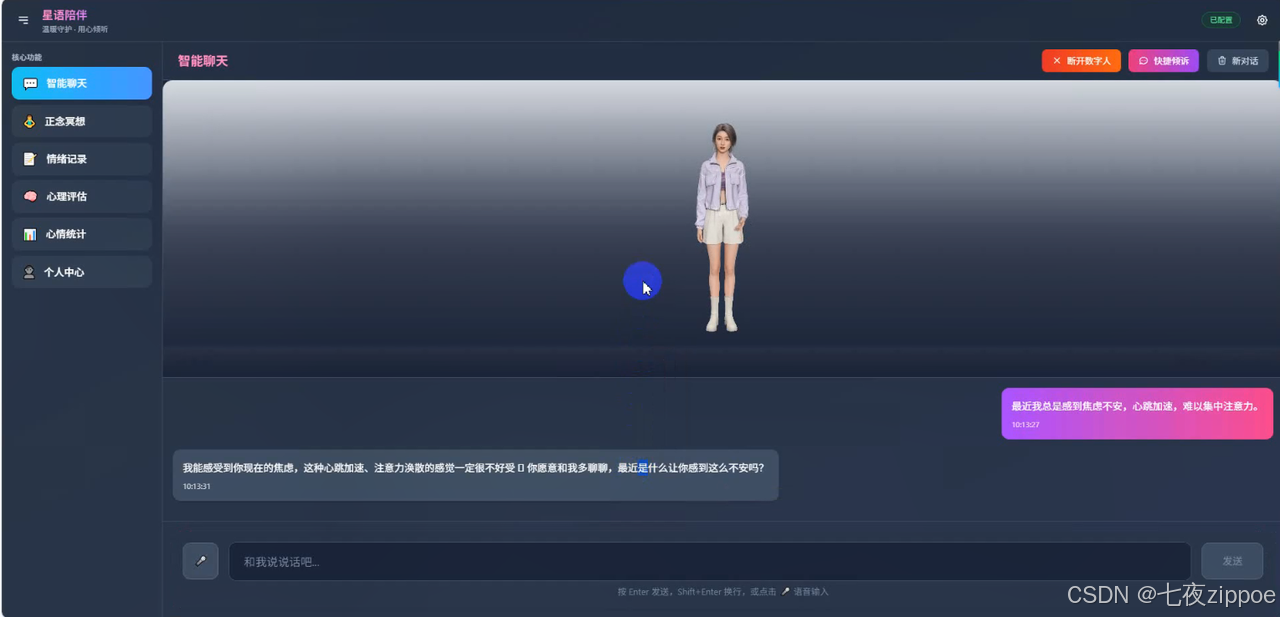
实操效果截图:
4.2 多个功能模块体验
除了核心的聊天功能,项目还集成了几个辅助模块:
|
模块 |
体验评价 |
说明 |
|
智能聊天 |
⭐⭐⭐⭐⭐ |
核心功能,数字人实时对话 |
|
正念冥想 |
⭐⭐⭐⭐ |
冥想引导,数字人语音陪伴 |
|
情绪记录 |
⭐⭐⭐⭐ |
日记形式记录情绪变化 |
|
心理评估 |
⭐⭐⭐ |
基础心理测试问卷 |
|
心情统计 |
⭐⭐⭐⭐ |
可视化情绪历史数据 |
|
快捷倾诉 |
⭐⭐⭐⭐⭐ |
18种预设场景一键触发 |
实操效果展示:
情绪陪伴数字人
5. 总结与展望
5.1 一句话总结
魔珐星云的端侧参数流渲染架构,将 3D 数字人从 “观感精致但交互受限” 的展示品,转化为实用的交互入口。结合主流大模型的情感对话能力,具备共情能力的情绪陪伴数字人应用,一周内即可完成从构思到 Demo 落地。
5.2 我对"具身Agent"这件事的看法
从情绪陪伴这个项目延伸开去,我认为"具身Agent"会成为下一代人机交互的核心范式。原因很简单:
纯文本交互正在触及天花板。 GPT已经够好了,但改变不了一个事实——人类沟通中,文字只占信息量的30%,剩下70%来自表情、语气、肢体语言。
而星云做的事,本质上就是给Agent赋予这70%的表达能力。
当Agent不仅能"想"、还能"表达"的时候,它的应用场景就从"帮你搜个东西"扩展到"陪你聊聊天"、"帮你讲解一个概念"、"在大屏上引导你办理业务"。这个扩展空间是巨大的。
参考资料

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)