
基于 LiveTalking + MuseTalk 部署自定义数字人全流程笔记(附常见问题解决方案)
本文详细介绍了在Linux(Debian12.2)系统下使用3090显卡部署LiveTalking和MuseTalk数字人项目的完整流程。主要内容包括:环境配置(CUDA12.4、conda环境)、项目依赖安装(PyTorch2.5.0、mmcv等)、模型下载部署、以及自定义数字人视频处理的具体步骤。文章特别强调了CUDA与PyTorch版本的兼容性,并提供了两种数字人方案(MuseTalk和wa
前言
本文记录在 Linux 环境下基于 LiveTalking 框架整合 MuseTalk 方案部署数字人直播的完整流程,包括环境搭建、模型部署、自定义数字人处理,以及部署过程中遇到的典型问题与解决方案,尤其聚焦 MuseTalk 预处理与训练数据不足的核心问题梳理。
一、环境准备
基础环境信息
- 系统:Linux Debian 12.2
- 显卡:NVIDIA GeForce RTX 3090(需支持 CUDA 加速)
- 核心依赖:CUDA、git、miniconda、ffmpeg(需提前安装,确保版本兼容)
前置工具安装验证
- CUDA 版本确认:
运行nvidia-smi查看 CUDA 版本(本文以 CUDA 12.2 为例,需注意与 PyTorch 版本匹配)。nvidia-smi # 输出需包含CUDA Version: 12.x - 基础工具检查:
确认 git、miniconda、ffmpeg 已安装:git --version conda --version ffmpeg -version
二、LiveTalking 部署流程
1. 代码拉取与环境创建
# 拉取LiveTalking代码
git clone https://github.com/lipku/LiveTalking.git
cd LiveTalking
# 创建并激活conda环境
conda create -n nerfstream python=3.10 -y
conda activate nerfstream
2. PyTorch 与依赖安装
需根据 CUDA 版本安装兼容的 PyTorch(关键!版本不匹配会导致运行失败):
# 若CUDA为12.4,直接安装:
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 其他CUDA版本参考:https://pytorch.org/get-started/previous-versions/
安装项目依赖:
# 安装基础依赖
pip install -r requirements.txt
# 配置FFmpeg路径(已提前安装系统级FFmpeg)
export FFMPEG_PATH=/usr/bin/ffmpeg # 替换为实际FFmpeg路径
# 安装MMLab系列库(计算机视觉核心依赖)
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"如果有ffmpeg就不用安装了我这里是在系统中安装(已经安装好了)

3. 模型下载与部署
- 下载 MuseTalk 所需模型:迅雷链接
- 模型文件整理:
- 将
models文件夹内容复制到项目根目录models/下; - 将
musetalk_avatar1.tar.gz解压后,复制到data/avatars/下(默认数字人)。
- 将
4. 启动 LiveTalking
python app.py --transport webrtc --model musetalk --avatar_id musetalk_avatar1
访问网页:http://[本地IP]:8010/dashboard.html,点击 “连接” 即可测试默认数字人。
三、自定义数字人部署(基于 MuseTalk)
我准备的是一段十秒钟2k的数字人视频

这里还是使用Musetalk方案
1. MuseTalk 环境搭建
# 拉取MuseTalk代码
git clone https://github.com/TMElyralab/MuseTalk.git
cd MuseTalk
# 创建独立conda环境(避免依赖冲突)
conda create -n MuseTalk python=3.10 -y
conda activate MuseTalk
# 安装PyTorch(CUDA 11.8示例,与3090兼容)
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
# 安装项目依赖
pip install -r requirements.txt
# 安装MMLab库(版本需严格匹配)
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv==2.0.1"
mim install "mmdet==3.1.0"
mim install "mmpose==1.1.0"Download weights 下载权重
您可以采用两种方式下载权重:
选项 1:使用下载脚本(推荐)
我们提供了两个用于自动下载的脚本:
sh ./download_weights.sh
选项 2:手动下载(运行少什么可以单独下)
您也可以从以下链接手动下载权重:
- 下载我们的训练权重
- 下载其他组件的权重:
-
- sd-vae-ft-mse
- whisper
- dwpose
- syncnet
- face-parse-bisent
- resnet18
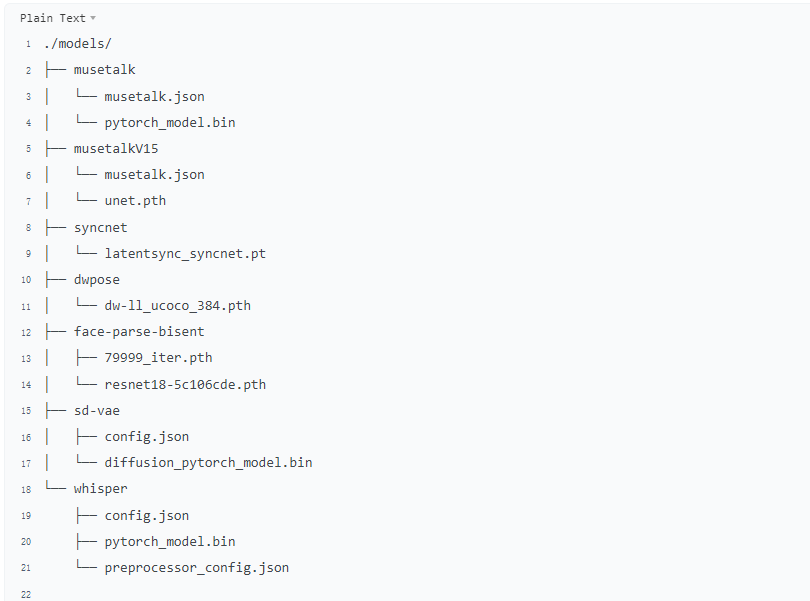
Finally, these weights should be organized in models as follows:最后,这些权重应该按以下方式组织在 models 中:
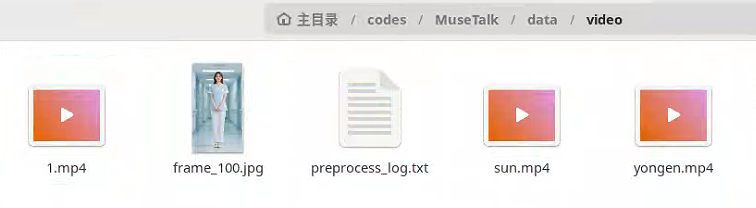
把自己的视频放在这个路径下我命名为1.mp4
cd MuseTalk
修改配置文件 configs/inference/realtime.yaml
我音频使用的默认yongen.wav,视频使用的自己的1.mp4(如下图)

执行预处理
sh inference.sh v1.5 realtime运行之后会出现新的avator: avator_1(文件夹)
运行后将results/avatars下文件拷到LiveTalking的data/avatars下
然后运行Livetalking
python app.py --transport webrtc --model musetalk --avatar_id avator_1
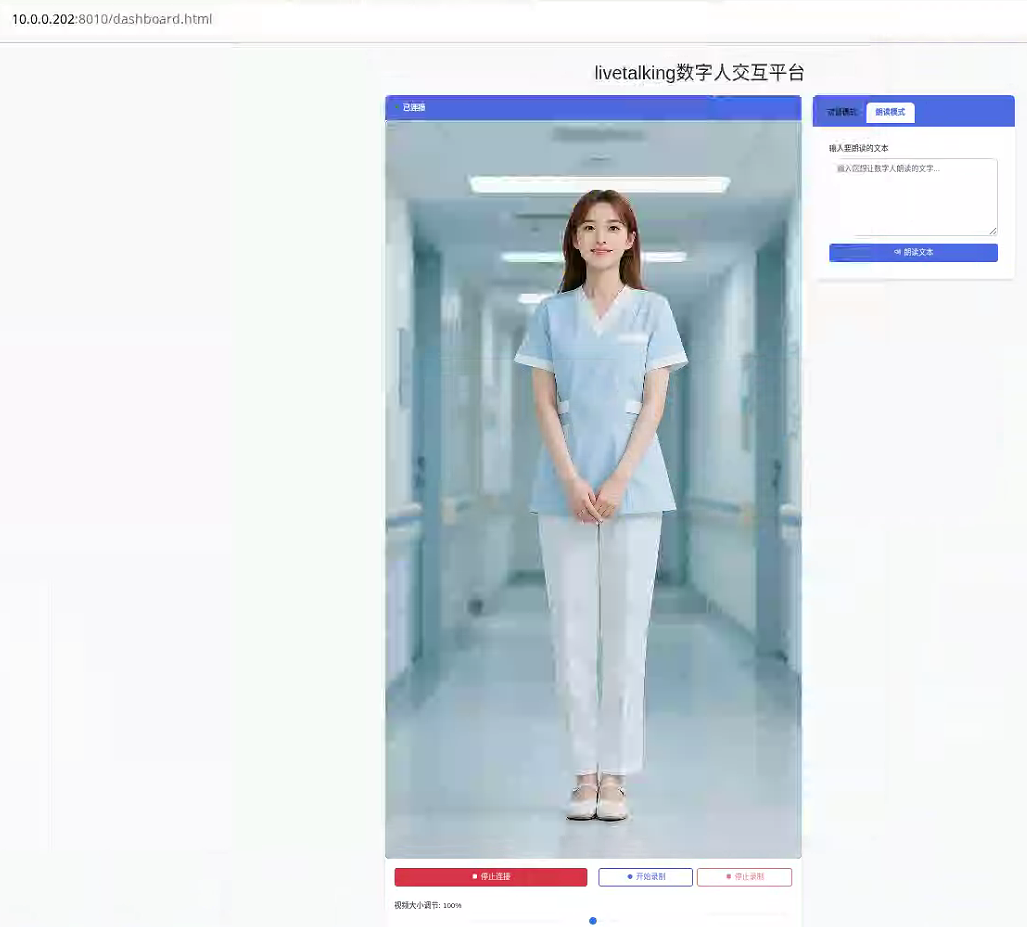
访问网页
http://10.0.0.202:8010/dashboard.html(前面换成自己本地ip)
点击连接就可以了
如果要使用对话模式修改llm.py中api调用接口
export DASHSCOPE_API_KEY=<your_api_key>
四、常见问题与解决方案
问题 1:模型误用导致界面卡死
现象:
用 MuseTalk 处理的数字人文件夹(avator_1)搭配 wav2lip 模型运行,界面加载后输入内容即卡死。
原因:
不同数字人模型(MuseTalk vs wav2lip)依赖的文件结构不同:
- MuseTalk 输出包含人脸特征帧、音频对齐参数;
- wav2lip 需要原始人脸图像序列(face_imgs),结构不匹配导致数据解析失败。
解决方案:
- 严格匹配模型与数字人文件夹:MuseTalk 模型对应 MuseTalk 预处理的文件夹,wav2lip 对应其专用预处理结果;
- 若需用 wav2lip,需重新用 wav2lip 的预处理脚本生成
face_imgs文件夹。
问题 2:MuseTalk 预处理仅生成 train.txt,训练提示 “数据不足”
现象:
执行 MuseTalk 训练预处理脚本后,仅生成 train.txt(内容为 JSON),正式训练时提示 “样本数不足”。
排查与解决方案:
MuseTalk 训练需要视频帧、音频特征、人脸关键点等多维度数据,仅生成 train.txt 说明预处理不完整,需按以下步骤排查:
-
检查预处理日志:
预处理脚本会输出人脸检测、帧提取日志,若存在“No face detected”或“Frame extraction failed”,说明视频中人脸未被正确识别(2K 视频可能因分辨率过高导致检测模型失效)。
✅ 解决:降低视频分辨率(如 1080P),确保人脸清晰无遮挡,重新预处理。 -
验证输出文件结构:
正常预处理应生成以下文件(若缺失则数据不足):./data/processed/ ├── frames/ # 视频帧图像(每帧一张图) ├── audio/ # 音频特征文件 ├── keypoints/ # 人脸关键点数据 └── train.txt # 标注文件(关联帧、音频、关键点)✅ 解决:检查
configs/preprocess.yaml中output_dir路径是否正确,确保脚本有权限写入数据。 -
检查输入数据量:
MuseTalk 训练至少需要1000 + 帧数据,10 秒视频按 25FPS 计算仅 250 帧,样本量不足。
✅ 解决:使用更长视频(如 1 分钟以上),或在预处理时调整帧采样率(修改配置文件frame_sample_rate: 1即每帧都保留)。 -
依赖库兼容性问题:
mmdet、mmpose 版本不匹配可能导致人脸检测 / 关键点提取失败,无数据生成。
✅ 解决:严格安装指定版本:mmcv==2.0.1、mmdet==3.1.0、mmpose==1.1.0,并运行测试代码验证:# 测试人脸检测 from mmdet.apis import init_detector, inference_detector model = init_detector("./configs/dwpose/detector/yolox_s_8x8_300e_coco.py", "./models/dwpose/yolox_s_8x8_300e_coco_20211121_095414-4592a793.pth") result = inference_detector(model, "./1.mp4_frame_0.jpg") # 替换为实际帧图像 print("检测到人脸数:", len(result[0][result[0][:,4]>0.5])) # 应输出>=1
五、关键注意事项
- 版本兼容性:CUDA 版本需与 PyTorch、MMLab 库严格匹配(参考官方文档);
- 模型路径:所有模型文件需按指定目录结构存放,路径错误会导致加载失败;
- 硬件资源:3090 显卡需确保显存充足(预处理时建议关闭其他占用显存的程序);
- 自定义视频:优先使用光线充足、人脸正面、无剧烈动作的视频,提升预处理成功率。
总结
本文梳理了从环境搭建到自定义数字人部署的全流程,重点解决了模型匹配问题与 MuseTalk 训练数据不足的核心痛点。通过严格控制版本兼容性、规范文件结构、优化输入数据质量,可有效避免多数部署问题。后续可进一步探索 LLM 接口集成(修改 llm.py 配置 API 密钥),实现数字人对话功能。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)