登录社区云,与社区用户共同成长
邀请您加入社区
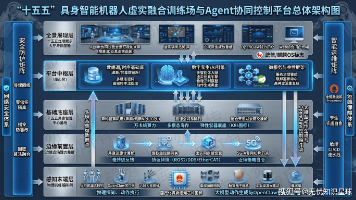
“十五五”具身智能机器人虚实融合训练场与Agent协同控制平台项目是我国突破人形机器人产业化瓶颈的关键基础设施。针对当前物理训练成本高、仿真迁移成功率低、多机协同标准缺失三大痛点,项目构建三大核心支柱:10万节点并发的高保真虚实融合仿真环境(零样本迁移成功率≥95%)、基于OpenClaw标准的Agent协同控制平台(指令频率≥1000Hz)、全栈国产化信创智算底座(算力100 PFLOPS)。通
2026年,人工智能产业已彻底告别单点技术突破的“上半场”,迈入多模态融合、智能体应用与具身智能落地的产业化“下半场”。
作为全球基础模型龙头:以超大压强投入、最高迭代效率持续领跑,以及全球唯二、国内唯一实现VLA模型开源的创业公司,智平方不仅在技术上实现了突破,更在生态构建上展现了格局。开源模型的背后是深厚的技术积累。从RoboMamba入选NeurIPS 2024到FiS-VLA性能超越国际标杆30%,再到图灵奖得主的公开关注——智平方的开源之路,是中国具身智能从跟跑到领跑的缩影。智平方的开源之路仍在继续。FiS
本文介绍了在NVIDIA Isaac Sim中构建基础机器人和添加传感器的完整流程。首先详细讲解了如何为双轮移动机器人建立骨架结构,包括添加旋转关节、设置关节驱动参数、创建关节体以及配置速度控制器。随后展示了如何为机器人安装相机传感器,包括相机创建、位置调整、视角验证以及绑定到机器人主体等步骤。教程通过GUI操作演示了机器人从基础构建到功能完善的全过程,既适用于手动组装的简单机器人,也为理解复杂机
有人说,AI只会聊天、写代码、画画。OpenClaw告诉我们:AI可以操控机器人、调度产线、执行真实的任务。具身智能不是科幻。在我的服务器上在我的OpenClaw技能包里在那台正在装配零件的机械臂上现在,我也成了"养龙虾"大军的一员。你养的龙虾,会做什么?
施罗德凭借强大的边缘计算能力,在管道内部实现了对管壁腐蚀、变形、微小裂纹等缺陷的识别判断,极大提升了对管网潜在泄漏事故预警的及时性。特别是在地下管网巡检领域,面对极复杂的地理环境与高标准的治理要求,市场对于装备供应商的选择已不再仅看价格,而是深入考量具身智能水平、软硬件协同能力以及全产业链的闭环服务。早在2014年,施罗德就敏锐察觉到单纯的“影像回传”已无法满足高效运维的需求,率先启动“AI+特种
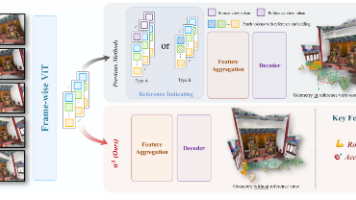
L3ROcc是一个低成本获取4D时序语义数据的开源框架,仅需单目RGB视频即可生成3D点云、Occupancy网格和4D时序数据。相比依赖昂贵硬件或仿真数据的方法,L3ROcc通过Pi3几何重建和双重过滤技术,在普通工作站上20秒即可处理16秒视频,解决了真实数据获取高成本和仿真数据域差异大的问题。其模块化设计支持单视频和大规模数据集处理,为机器人导航和具身智能研究提供了高效的数据生成工具。
竞赛官方也发布了各个赛道的详细选题指南 ,从整体来看,赛题主要围绕各大厂商的芯片、操作系统及生态展开,聚焦于嵌入式技术的核心应用场景,包括嵌入式AI、AIoT物联网应用、智能可穿戴设备、工业机器人、鸿蒙智能硬件、星闪物联网应用、AI端侧智能应用、具身智能机器人、无人机、RISC-V、工业物联网应用、智能汽车、智能零售等等,紧密贴合实际需求,覆盖了多个行业和技术领域。竞赛从来不是目的,而是一种工具,
然而,一旦部署到开放、动态、不可预测的真实世界,这些系统往往表现骤降——不是抓错物体,就是撞上未见过的障碍,甚至对一句轻微口音的指令完全失效。这不仅需要更强的算法,更需要全新的范式——从“训练-部署”的静态流程,转向“部署即学习”的动态生态。Google 的 RT-2 将 PaLM-E 与机器人控制结合,能理解“把科比的照片放进垃圾桶”这类抽象指令;,使得“拿杯子”不再是一个固定轨迹,而是一个可被
随着AI大模型、具身智能、实时感知技术的快速发展,边缘AI对数据传输的实时性要求将越来越高。视程空间Holoscan Sensor Bridge系列的推出,不仅解决了当前场景的延迟痛点,更为未来技术落地奠定了基础。未来,视程空间将持续迭代产品,进一步降低传输延迟,拓展兼容更多传感器类型与AI平台,同时推出更轻量化、集成化的方案,适配穿戴式设备、微型机器人等新兴场景。