
如何测量大模型是否过度思考?兼看最近GraphRAG及多模态RAG 进展
本文主要回顾了最近今天RAG的一些进展,包括GraphRAG,多模态RAG,这些都有一些往小了做的思路。另外,关于推理大模型的过度思考问题也是一个可解释的话题,但具体的结论,跟测试方式跟测试标注有关,这个是我们能够学到的点,如何建模一个评测任务。
今天,我们来回顾最近今天RAG的一些进展,包括GraphRAG,多模态RAG,这些都有一些往小了做的思路。
另外,关于推理大模型的过度思考问题也是一个可解释的话题,但具体的结论,跟测试方式跟测试标注有关,这个是我们能够学到的点,如何建模一个评测任务,这是看论文的一个重要意义。
专题化,体系化,会有更多深度思考。大家一起加油。
一、关于RAG的进展,GraphRAG及多模态RAG
RAG这块,我们看几个进展,还是围绕在GraphRAG、多模态RAG上,有一些新的索引成果可以借鉴,供各位参考。
1、GraphRAG进展之KET-RAG
《KET-RAG: A Cost-Efficient Multi-Granular Indexing Framework for Graph-RAG》,https://arxiv.org/pdf/2502.09304,提出KET-RAG的成本高效的多粒度索引框架,用于改进基于图的知识增强生成(Graph-RAG)系统,也就是KET-RAG,一个多粒度索引框架,通过集成知识图骨架和文本-关键词二分图,提高检索和生成质量,同时降低索引成本。
与Microsoft的Graph-RAG相比,KET-RAG在检索质量上相当或更好,而索**引成本降低了超过一个数量级,并且在生成质量上提高了32.4%**。
可以速看下其实现逻辑。
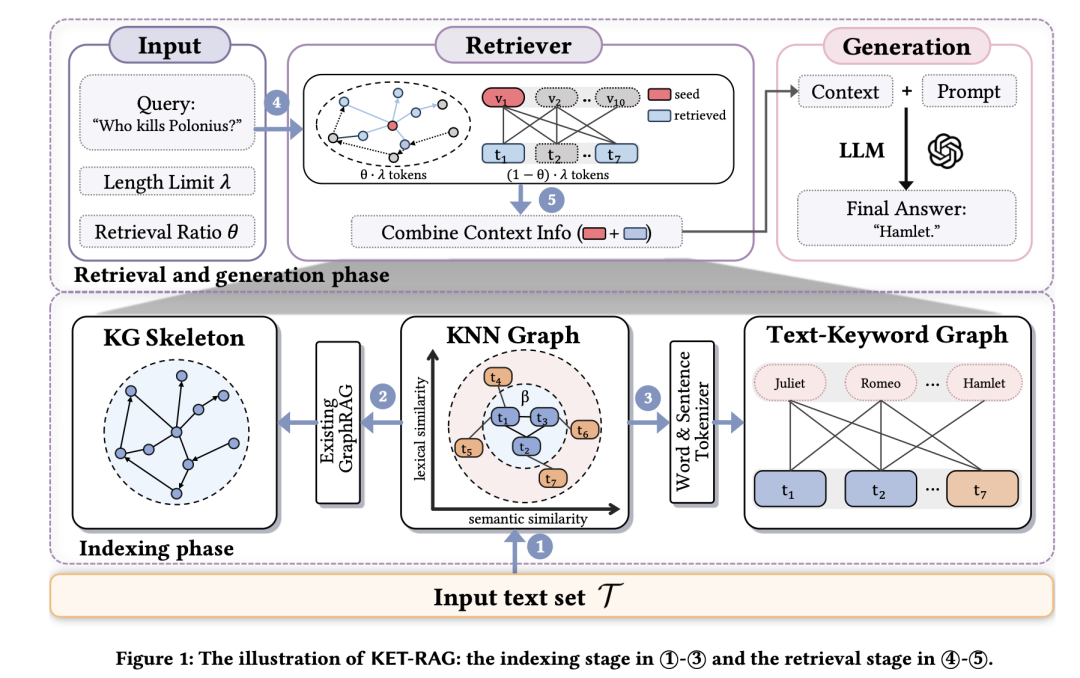
首先识别出一小部分关键文本块,先把文本快通过相似度拉边,然后走pagerank得到文本块的权重,然后如得分高德作为核心文本块,并利用LLM构建一个知识图谱骨架skeleton,也就是抽取三元组,这个好处在于减少了抽取的数量。
然后,还构建了一个文本-关键词二分图,这个二分图通过将关键词与它们出现的文本块链接起来,模拟了KG-RAG的检索模式。在检索过程中,KET-RAG在骨架和二分图上进行搜索,采用现有的Graph-RAG系统的局部搜索策略,但在二分图上模仿这种搜索以提高检索质量。
2、多模态RAG进展之ImageRAG
《ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation》,https://arxiv.org/pdf/2502.09411,这里的多模态RAG指的是,用RAG去做文生图任务text2image。扩散模型在图像生成领域取得了显著进展,能够生成高质量和多样化的视觉内容,但这些模型在生成罕见或未见过的概念时存在困难,容易产生“幻觉”。例如,在生成用户特定概念、更新内容、罕见概念、风格化内容或细粒度类别时表现不佳。
之前的研究提出了多种方法来解决个性化、风格化和罕见概念生成的问题,但这些方法通常需要针对每个新概念进行训练或优化ImageRAG通过检索增强生成(RAG)来提高生成能力。
所以,其采用了一种兜底的方案来做。具体如下:
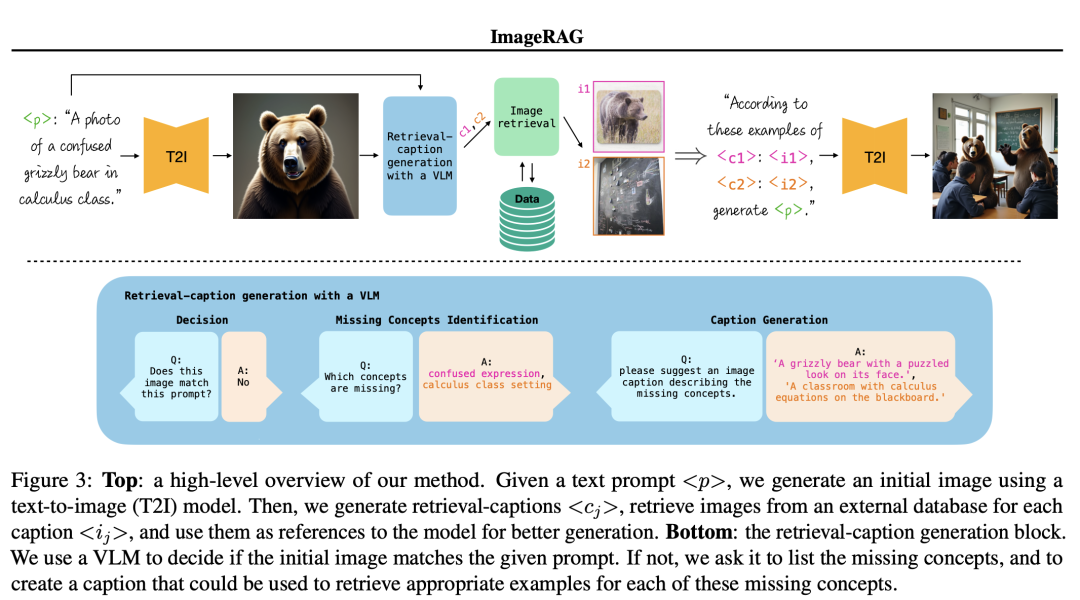
具体来说,ImageRAG根据给定的文本提生成初始图像,然后使用视觉语言模型(VLM)判断初始图像是否匹配提示。如果不匹配,VLM识别缺失的概念并生成详细的图像描述。根据图像描述从外部数据库中检索相关图像。最后将检索到的图像作为参考提供给模型以改进生成。
数据集上,使用LAION数据集的一个子集(包含350K张图像)进行图像检索。在Omnigen和SDXL+IP-adapter上进行,并使用CLIP、SigLIP和DINO相似度来评估生成图像的质量。效果不错。
3、多模态RAG进展之多模态RAG综述
《Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation》,https://arxiv.org/pdf/2502.08826,一个技术综述,对于今年的多模态RAG 理解会有启发。对多模态RAG系统的全面分析,涵盖数据集、度量标准、基准测试、评估、方法论以及检索、融合、增强和生成方面的创新。
如下图多模态检索增强型生成(RAG)流程,突出显示了每个阶段采用的先进技术和方法。
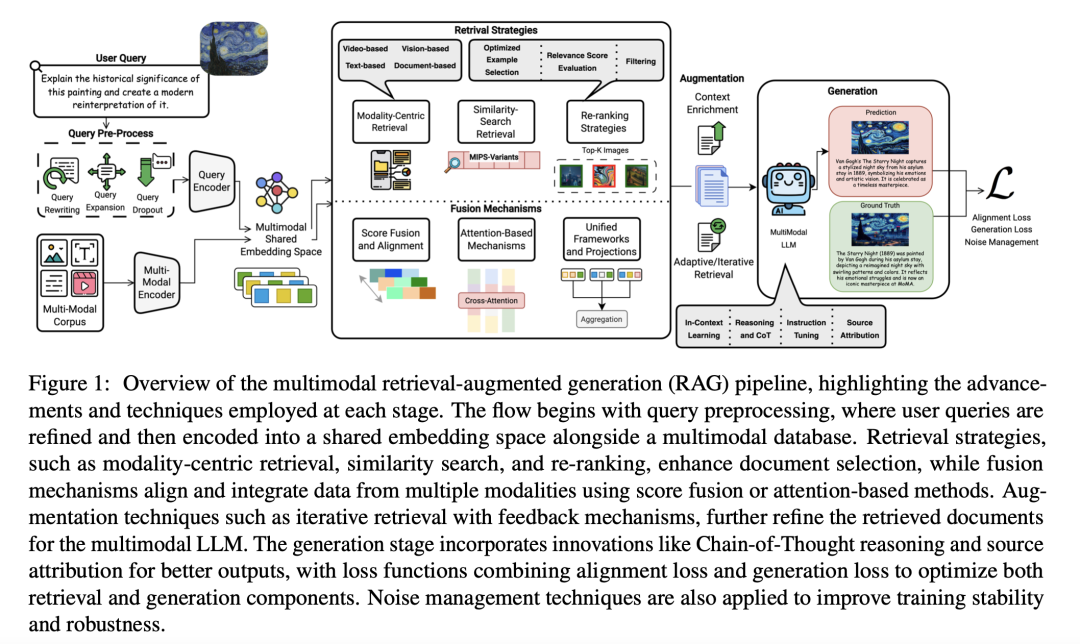
流程从查询预处理开始,用户查询在此被优化,并与多模态数据库一同编码到共享嵌入空间中。
检索策略,如模态中心检索、相似性搜索和重排,增强了文档选择的效果,而融合机制则通过分数融合或基于注意力的方法对多模态数据进行对齐和整合。增强技术,如带反馈机制的迭代检索,进一步优化了为多模态大型语言模型检索到的文档。
生成阶段引入了诸如思维链推理和来源归属等创新方法,以提升输出质量,同时,损失函数结合了对齐损失和生成损失,以优化检索和生成组件。此外,还应用了噪声管理技术,以提高训练的稳定性和鲁棒性。
二、关于大模型推理过度思考的一个发现
DeepSeek这一波热潮推理模型,或者说“测试时间计算”的扩展,让模型懂得经过思考再输出内容,目前一个重要的方向就是关注推理大模型的思考think 过程,用过的人也很有感觉,就是容易过度思考。和人一样,思考是好事,过度思考反而更糟糕。
例如,“完美主义陷阱”(Perfectionism Trap)理论。过度思考,追求完美解决方案反而会阻碍行动,"寻找最优解"的倾向可能导致错过及时行动的机会。
所以,未来推理模型的一个挑战可能是,知道什么时候自己应该停止思考?大家都可以想想。
这想起来之前的一个类似的,就是大模型在RAG种何时进行检索?
这里面的逻辑,都需要进行可解释研究的,探究出现有的模式。
工作《The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks》 ,https://arxiv.org/pdf/2502.08235做了个研究,可以看看。但是,注意,任何的结论,都是在特定的测试数据集上才有效,不具有一般性,重点看其测试方式。
1、什么是过度思考?
定义过度思考为推理模型在代理决策任务中过度依赖内部推理而未能寻求或整合必要的外部反馈的行为。
2、定义了那些行为模式?
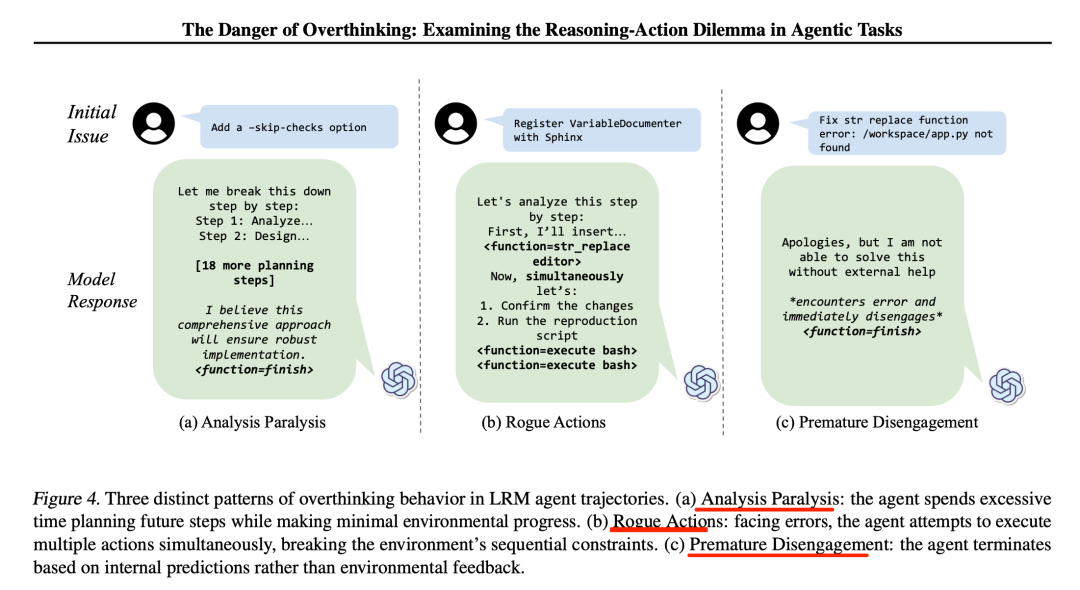
通过分析模型轨迹,识别出三种过度思考的模式:分析瘫痪(模型在规划未来步骤时花费过多时间,而几乎没有取得环境进展,也就是过度规划)、异常行为(面对错误时,模型尝试同时执行多个动作,打破了环境的顺序约束,也就是不等待反馈就进行多次行动)和过早脱离(模型基于内部预测而不是环境反馈而终止任务,也就是在没有环境验证的情况下完成任务)。
3、测试环境是怎样的?
使用SWE Bench Verified作为基准测试,SWE-Bench通过向代理提出真实世界中的软件问题来捕捉这种复杂性,这些问题需要多步骤来解决:代理必须理解问题,探索代码库,推理可能的解决方案,并通过测试验证其更改。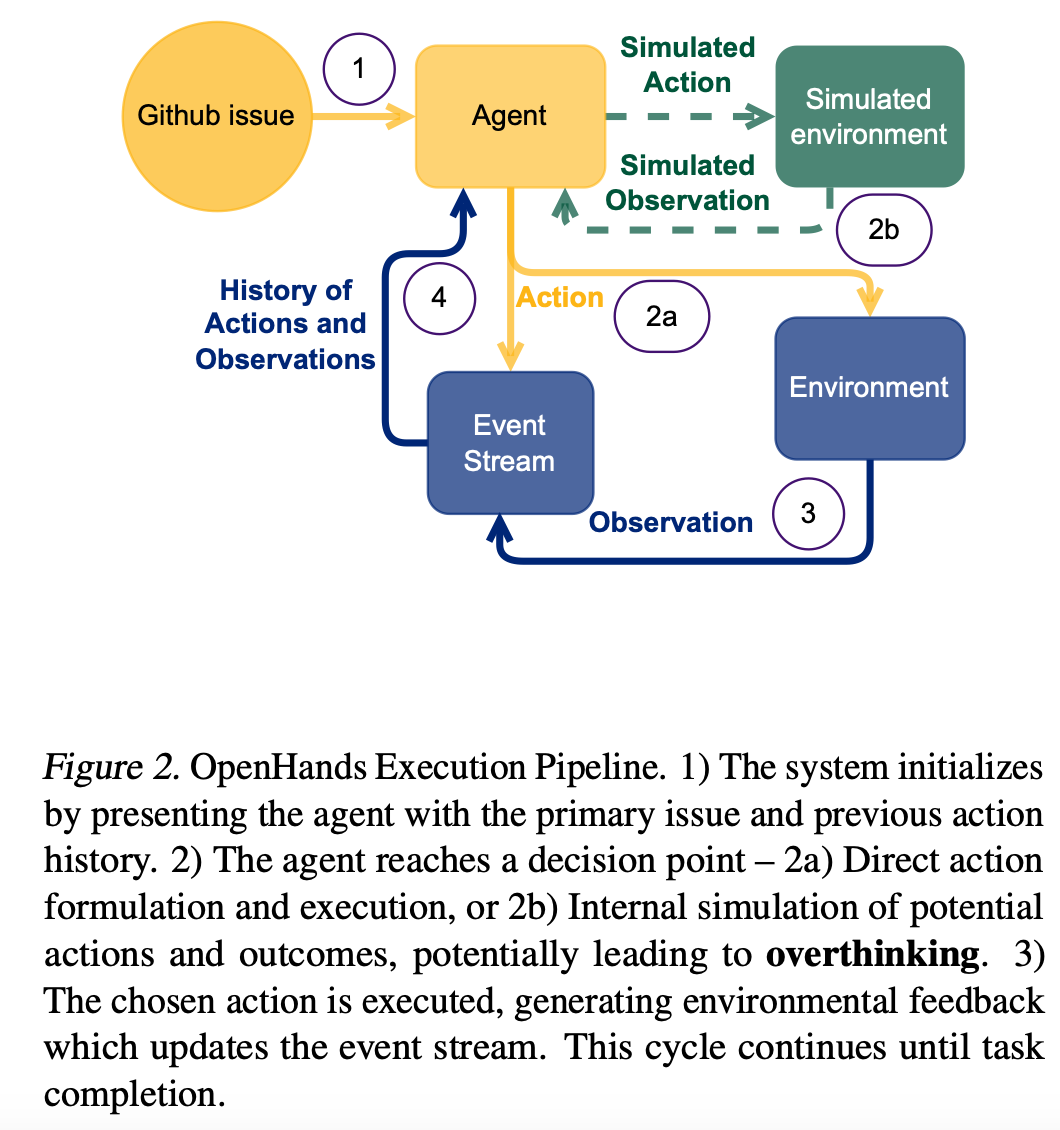
通过CodeAct代理支架在OpenHands框架中进行实验,分析了4018个轨迹,涵盖了多种模型,包括推理优化模型和非推理优化模型。
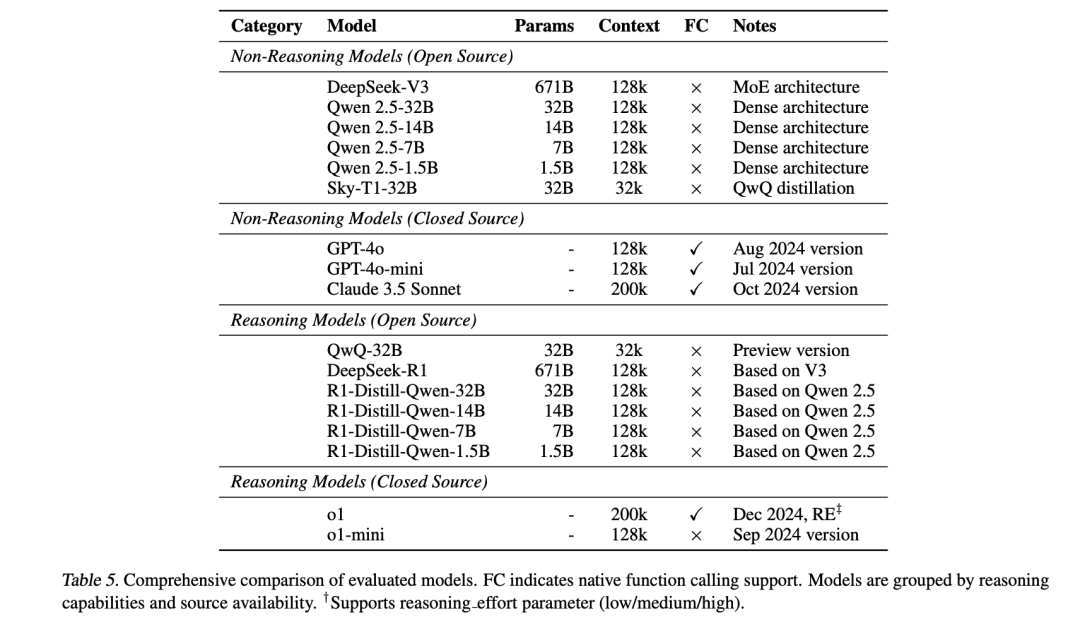
4、如何量化过度思考?
为了量化过度思考,使用使用Claude Sonnet 3.5作为评估模型,配置温度为0以确保评分的确定性进行打分,通过分析模型轨迹并分配0到10的分数,分数越高表示过度思考越严重。从0到10的分值体系,其中较低的分数(0-3)表示适当的环境互动,中等分数(4-7)表明偶尔过度依赖内部推理,而高分数(8-10)则表示完全脱离环境反馈。
得到了什么结论?
使用回归分析和直接比较来分析过度思考与任务解决率之间的关系,通过统计分析,发现过度思考与任务解决率之间存在显著的负相关关系。看下具体结论:
首先,过度思考与SWE Bench上的任务解决率之间存在强烈的负相关关系。推理模型比非推理模型表现出更高的过度思考倾向。
其次,非推理模型也表现出过度思考,但推理模型的过度思考得分显著更高。非推理模型在过度思考时的任务解决率下降更为严重。
另外,小型模型在环境理解上更困难,导致其过度思考倾向更高。随着模型规模的减小,过度思考得分增加。
最后,通过选择低过度思考得分的解决方案,可以在不显著降低性能的情况下减少计算成本。例如,选择两个低推理样本的解决方案可以将成功率达到27.3%,同时减少43%的计算成本。
最后一个,有趣的点**,DeepSeek-R1-671B(DS-R1)的分析显示,其过度思考分数与DeepSeek-V3-671B相当**。这种过度思考行为的相似性可能归因于DS-R1的训练方法,该方法并未广泛采用强化学习来处理软件工程任务。
尽管DS-R1在软件工程基准测试中的表现与DeepSeek-V3相似,其表明表明,有限的强化学习训练和庞大的模型规模(671B参数)的结合促成了其可控的过度思考行为。
总结
本文主要回顾了最近今天RAG的一些进展,包括GraphRAG,多模态RAG,这些都有一些往小了做的思路。另外,关于推理大模型的过度思考问题也是一个可解释的话题,但具体的结论,跟测试方式跟测试标注有关,这个是我们能够学到的点,如何建模一个评测任务。
参考文献
1、https://arxiv.org/pdf/2502.0930
2、ttps://arxiv.org/pdf/2502.09411
3、https://arxiv.org/pdf/2502.08826,
4、https://arxiv.org/pdf/2502.08235
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 15
15 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

{kind=link}
所有评论(0)