
魔珐星云数字人:从英语陪练场景出发的具身智能开发与体验
一、魔珐星云与英语陪练场景的适配性
魔珐星云是魔珐科技推出的面向开发者的具身智能3D数字人开放平台。它有三大产品能力,具身驱动、视频生成以及语音合成。具身驱动支持基于文本输入,实时生成 3D 数字人的语音、表情、眼神、手势和身体动作,让任何屏幕、应用、终端都能像真人一样自然表达和交互。现在AI不只是“会思考”,还能“有身体”——每块屏幕、每个APP里都能有个会说话、会做表情的数字人,这就是魔珐星云—具身智能数字人开放平台最厉害的地方。
而这刚好能解决传统英语陪练的痛点:互动没意思、练习场景单一、反馈慢。魔珐星云的3D数字人能带着表情动作说话、实时跟你互动、模拟真实场景,就像真的有人面对面陪你练英语,让你敢开口、练得像!
魔珐星云有六大核心技术能力:高质量、低延时、低成本、高并发、多风格、多终端等能力来为的我们的英语陪练数字人来保驾护航: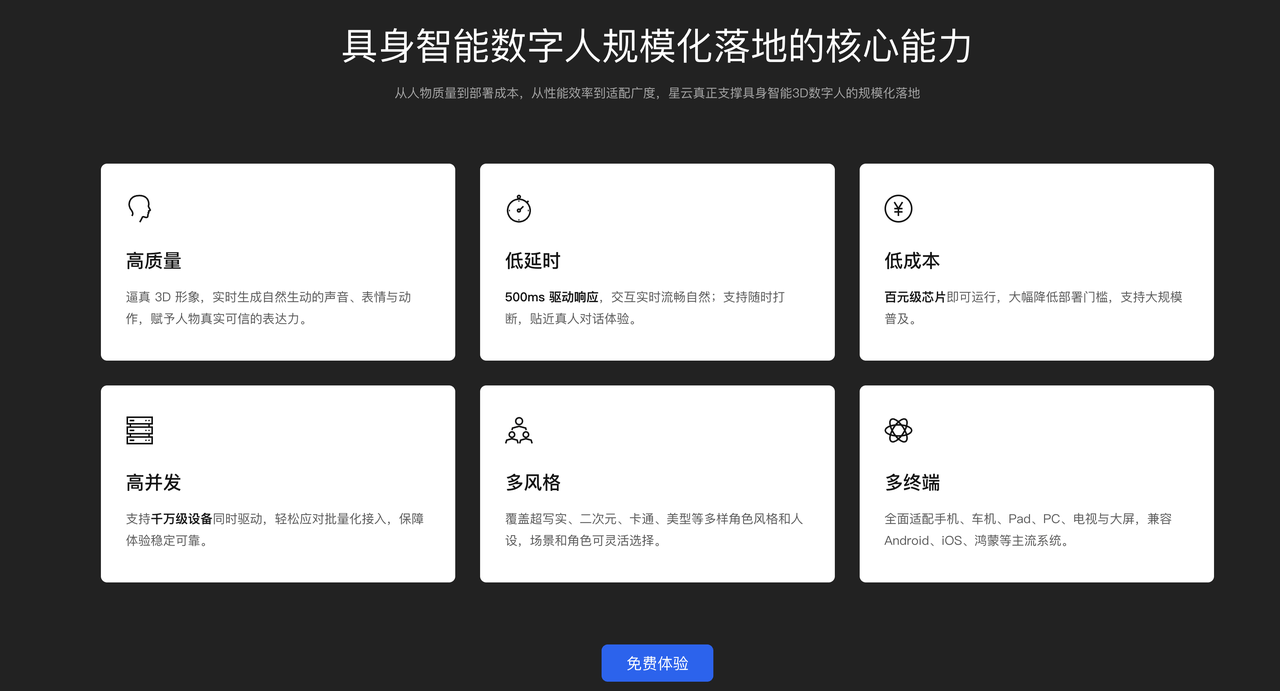
除此之外数字人说话时的口型、语气变化和真人一模一样,你能清楚看到“正确发音该怎么动嘴”,练发音再也不用瞎猜了。你输入的英语句子是疑问、感叹还是陈述,数字人都能看出来,还会用表情和小动作回应,比如疑问时歪头、开心时微笑,练对话像跟朋友聊天一样有趣。
二、英语陪练场景下的前期准备
准备阶段不用复杂操作,重点就一件事:把数字人“打扮”成适合陪练英语的样子,既要亲切又要专业。
-
平台注册
-
快速注册账号,注册入口
-
注册登录完整后,我们可以进入控制台体验数字人
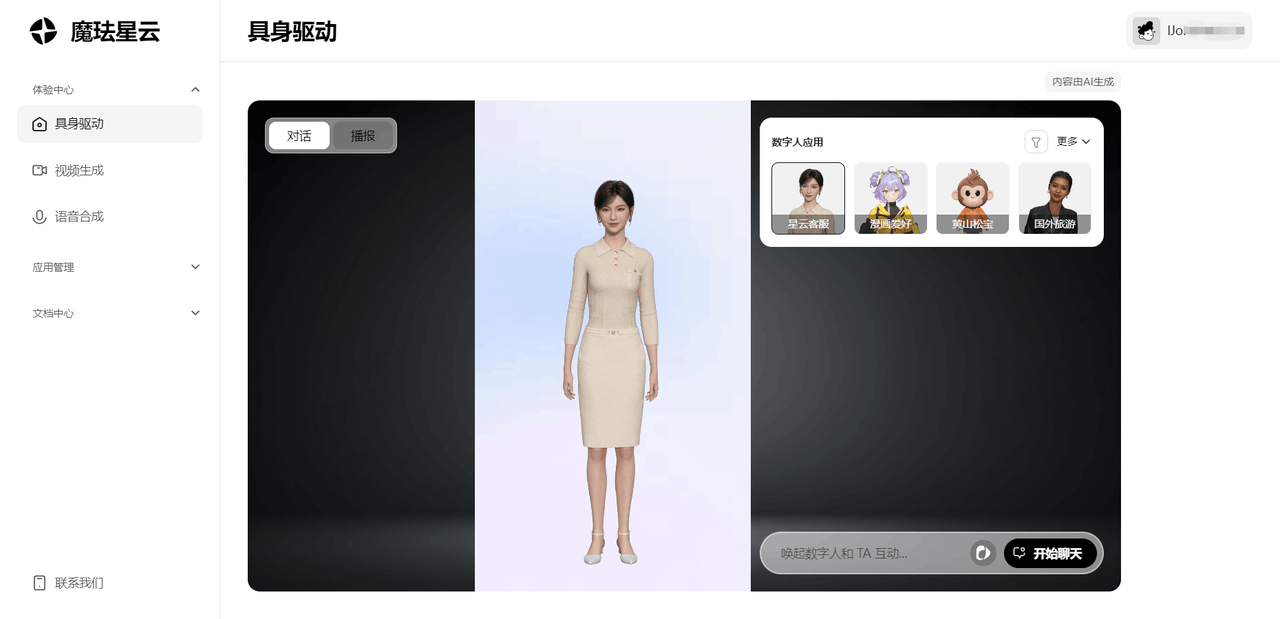
-
-
创建创建与配置
-
创建应用
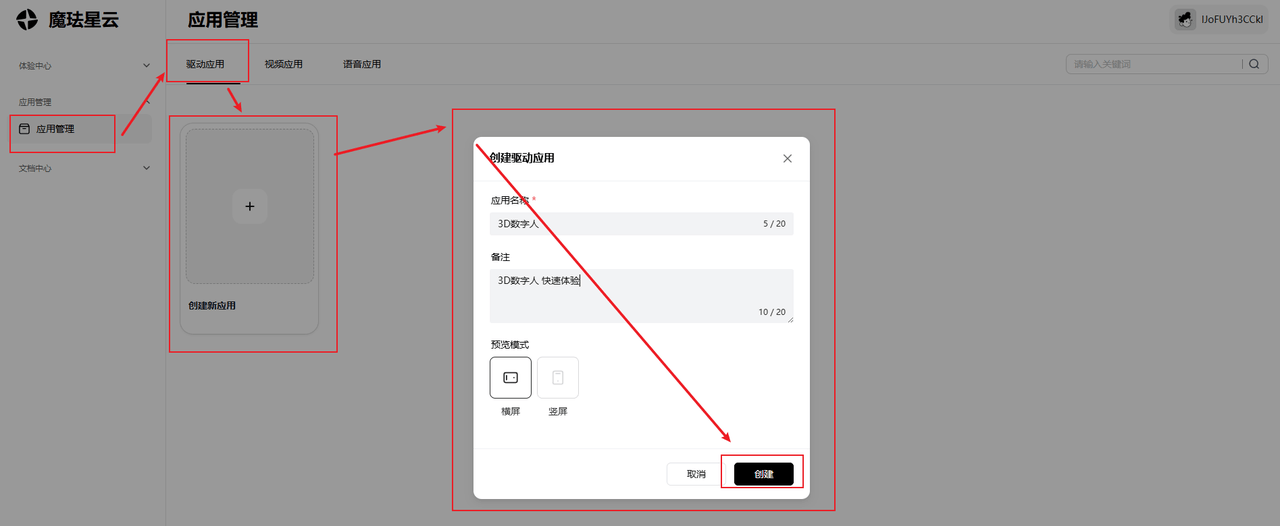
-
配置应用的数据人基本信息,形象、场景、音色、表演等配置完成后保存数字人
-
挑个看着亲切、表情多的,比如“校园老师”或“同龄伙伴”,别选太严肃或太夸张的;把“情感化表达”开关打开,这样数字人说不同语气的英语时,会自动做对应表情和小动作。
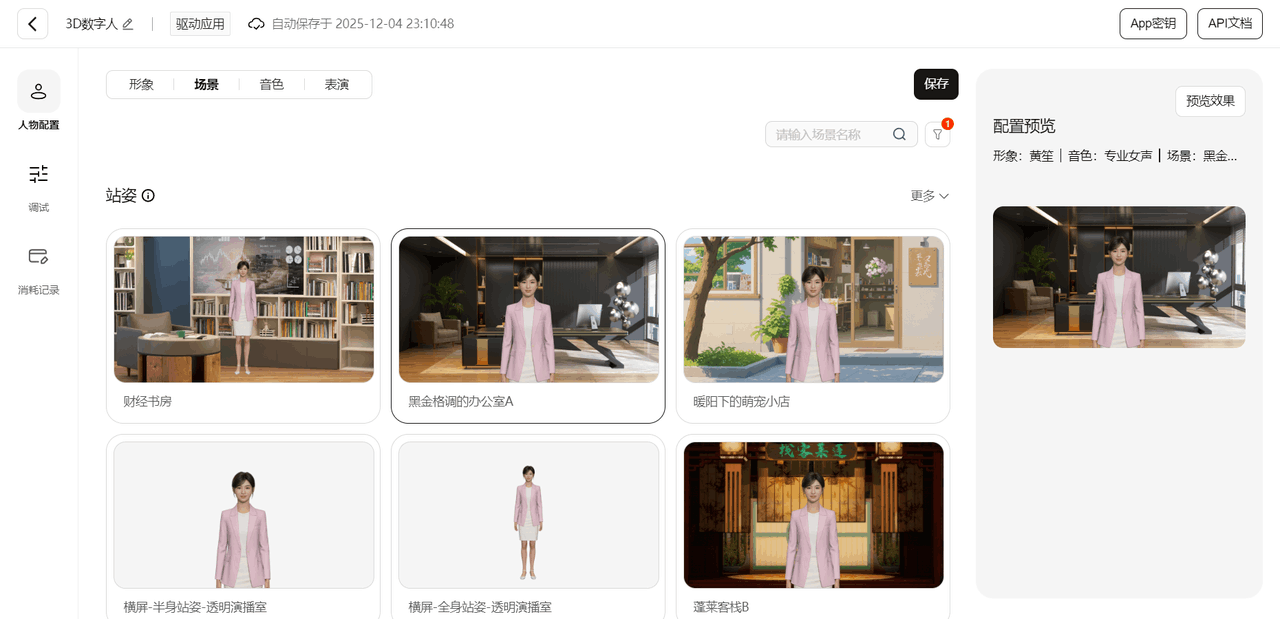
-
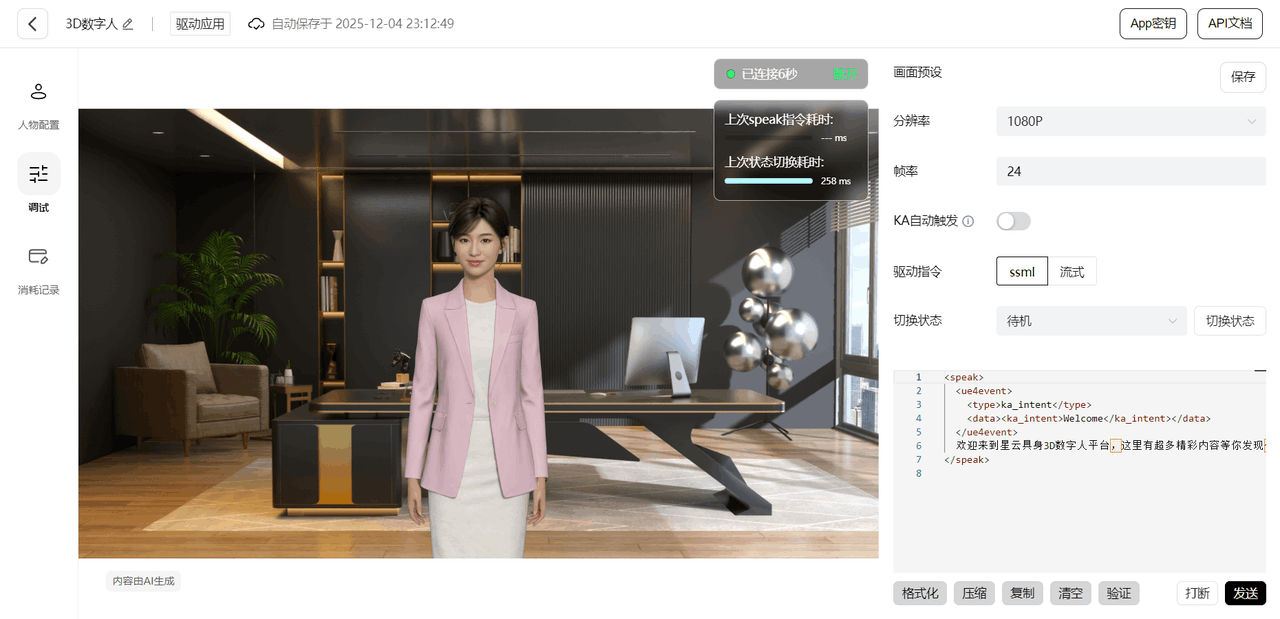
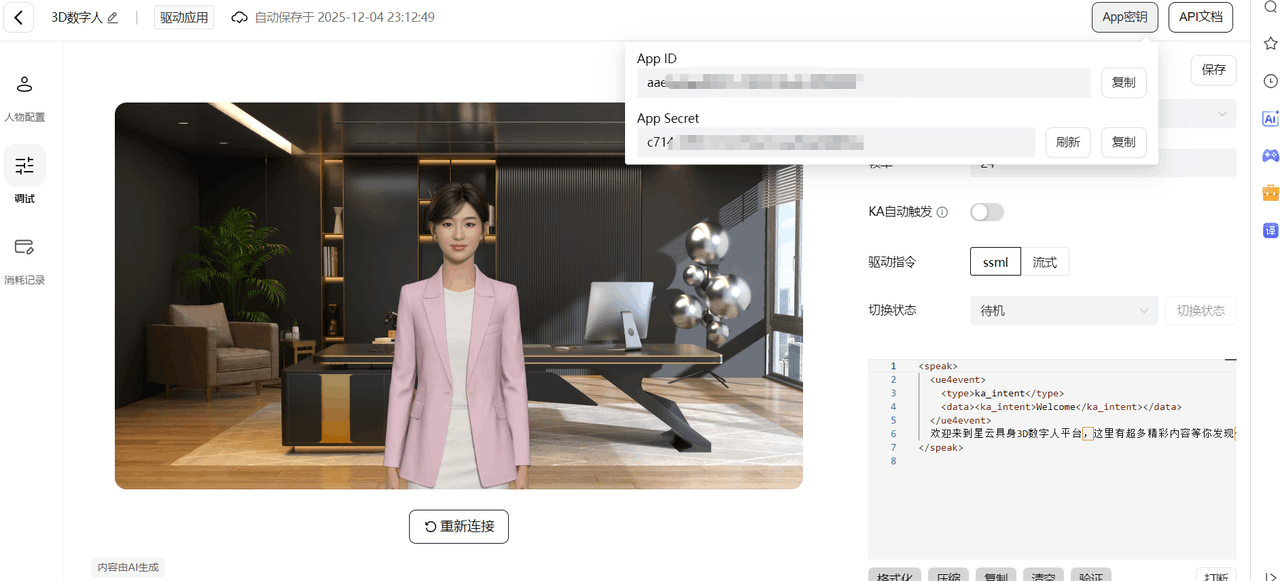
在右上角查看并保存应用的 App ID 与 App Secret ,后续代码调试会用到
-
-
SDK 引入规范,这里我们体验具身驱动SDK
一定要注意环境要求,具体可参考:
三、快速搭建英语陪练数字人
项目初始化
-
创建基础项目
Z:\>npm create vite@latest my-first-3d-DH -- -t vue-ts --rolldown --no-interactive > npx > create-vite my-first-3d-DH -t vue-ts --rolldown --no-interactive | o Scaffolding project in Z:\my-first-3d-DH... | — Done. Now run: cd my-first-3d-DH npm install npm run dev -
使用VSCode IDE调整项目,删除无用代码信息.
PS Z:\my-first-3d-DH> npm install tailwindcss @tailwindcss/vite openai @vueuse/core added 19 packages in 9s 10 packages are looking for funding run `npm fund` for details -
引入数字人的SDK
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <link rel="icon" type="image/svg+xml" href="/vite.svg" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script> <title>my-first-3d-dh</title> </head> <body> <div id="app"></div> <script type="module" src="/src/main.ts"></script> </body> </html> -
xmovAvatar.d.ts代码示例,这里根据官网文档对文件进行了注释说明,方便大家理解代码逻辑。
// types/xmovAvatar.d.ts export {}; declare global { interface XmovAvatarConfig { /** * 容器id */ containerId: string | undefined | HTMLElement; /** * 应用id */ appId: string | undefined; /** * 应用秘钥 */ appSecret: string | undefined; /** * 数字人服务接口完整路径 */ gatewayServer: | string | undefined | 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session'; /** * Widget事件回调函数 * @param e * @returns */ onWidgetEvent?: (e: any) => void; /** * 当前网络状况 * @param e * @returns */ onNetworkInfo?: (e: any) => void; /** * SDK 消息 * @param e * @returns */ onMessage: (e: any) => void; /** * 监听虚拟人状态变化 * @param e * @returns */ onStateChange?: (e: any) => void; onStatusChange?: (e: any) => void; /** * 监听虚拟人状态变化耗时 从发送action到状态首帧渲染 * @param e * @param e * @returns */ onStateRenderChange?: (e: any, e: any) => void; /** * 监控sdk音频播放状态 * @param e * @returns */ onVoiceStateChange?: (e: any) => void; /** * 是否打印sdk日志 */ enableLogger?: boolean; proxyWidget?: Map<string, (e: any) => void>; } interface InitXmovAvatar {} class XmovAvatar { constructor(config: XmovAvatarConfig); //初始化构造 /** * 初始化连接房间 * @param options 监控信息 */ init(options?: { onDownloadrogress?: (progress: number) => void; //进度条 }): Promise<void>; /** * 驱动数字人说话 * @param ssml * @param is_start * @param is_end */ speak(ssml: string, is_start: boolean, is_end: boolean): void; destroy(): void; offlineMode(): void; onlineMode(): void; idle(): void; interactiveidle(): void; listen(): void; think(): void; /** * setVolume:控制声音 取值范围0->1 0:静音 1:最大音量 * @param volume */ setVolume(volume: number): void; /** * 显示调试信息 */ showDebugInfo(): void; /** * 隐藏调试信息 */ hideDebugInfo(): void; } enum EErrorCode { // 容器不存在 CONTAINER_NOT_FOUND = 10001, // socket连接错误 CONNECT_SOCKET_ERROR = 10002, // 会话错误,start_session进入catch(/api/session的接口数据异常,均使用response.error_code) START_SESSION_ERROR = 10003, // 会话错误,stop_session进入catch STOP_SESSION_ERROR = 10004, VIDEO_FRAME_EXTRACT_ERROR = 20001, // 视频抽帧错误 INIT_WORKER_ERROR = 20002, // 初始化视频抽帧WORKER错误 PROCESS_VIDEO_STREAM_ERROR = 20003, // 抽帧视频流处理错误 FACE_PROCESSING_ERROR = 20004, // 表情处理错误 BACKGROUND_IMAGE_LOAD_ERROR = 30001, // 背景图片加载错误 FACE_BIN_LOAD_ERROR = 30002, // 表情数据加载错误 INVALID_BODY_NAME = 30003, // body数据无Name VIDEO_DOWNLOAD_ERROR = 30004, // 视频下载错误 AUDIO_DECODE_ERROR = 40001, // 音频解码错误 FACE_DECODE_ERROR = 40002, // 表情解码错误 VIDEO_DECODE_ERROR = 40003, // 身体视频解码错误 EVENT_DECODE_ERROR = 40004, // 事件解码错误 INVALID_DATA_STRUCTURE = 40005, // ttsa返回数据类型错误,非audio、body、face、event等 TTSA_ERROR = 40006, // ttsa下行发送异常信息 NETWORK_DOWN = 50001, // 离线模式 NETWORK_UP = 50002, // 在线模式 NETWORK_RETRY = 50003, // 网络重试 NETWORK_BREAK = 50004, // 网络断开 } interface SDKMessage { code: EErrorCode; message: string; timestamp: number; originalError?: string; } interface SDKNetworkInfo { rtt: number; // 延迟,毫秒 downlink: number; // 下载速率(MB/s) } enum SDKStatus { online = 0, offline = 1, network_on = 2, network_off = 3, close = 4, } }启动项目
-
启动命令
npm run dev,打开网页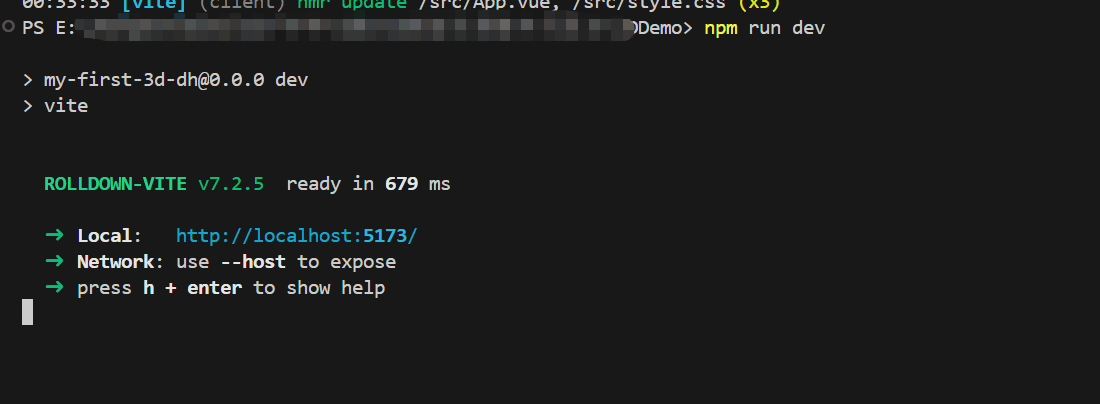
-
点击「连接」按钮初始化,等待加载完成即可看到 3D 数字人
-
等待几秒完成初始化即可,效果如下:

-
在文本框输入需要对话问题,点击「发送」,数字人会智能识别你的需求,并根据回答播放英语并同步表情动作 ,这样一个智能英语陪练数字人就实现啦

功能效果演示
-
加载数字人:点“连接”按钮,等进度条走完,左边就会出现3D英语陪练老师;
-
基础对话:在输入框写英语句子(比如“I want to learn English”),点“发送按钮”,数字人会开始进行语音播报并回应你;
-
AI智能加强:接入通义千问AI大模型API, 数字人能够自主理解用户输入指令,再通过3D数字人形象生动的解答用户的问题
持续迭代
-
场景化练习:点“Start Ordering Practice(开始点餐练习)”,数字人会开启点餐对话,点“Next Sentence(下一句)”就能继续聊,像真的在餐厅点餐一样;
-
跟读模式:点“Enter Follow Mode(进入跟读)”,数字人说完话会提示你跟读,后续可以加语音识别打分(新手先练开口)。
项目总结
通过本次项目的搭建,刚入门的编程小白,也能借助魔珐星云快速落地项目:无需掌握3D建模、动作捕捉等专业技能,只要具备基础的前端知识,就能按文档步骤开发。API设计清晰易懂,配套示例代码丰富,从平台注册、数字人配置到核心功能实现,全程仅需2小时。尤其得益于高质量与低成本能力——情绪表达功能无需开发者编写复杂动作逻辑,文生3D大模型会自动根据文本语气生成对应表情动作;客户端渲染架构省去服务器部署成本,百元级芯片即可测试运行,极大降低了开发与试错门槛。
四、魔珐星云产品体验分享
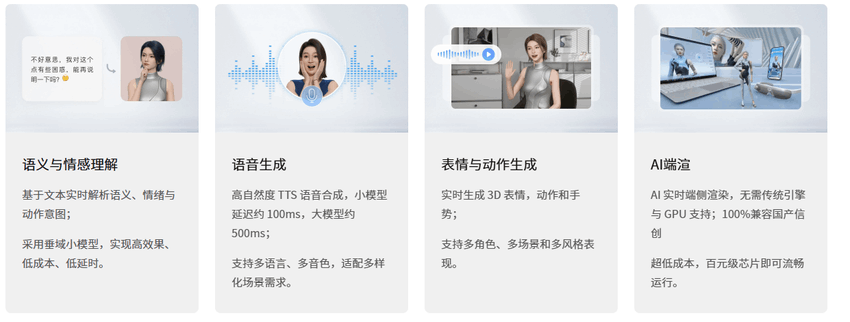
魔珐星云的核心竞争力在于,依托文生3D多模态动作大模型与AI端渲解算技术,从底层打破了3D数字人生成“高质量、低成本、低延时”的不可能三角,从而真正支持AI具身智能大规模应用。文生3D大模型可直接将文本/语音指令转化为自然连贯的3D动作与表情,省去人工建模与动捕环节;AI端渲解算则通过WebGL将渲染任务转移至客户端,无需依赖GPU服务器,在保证视觉效果的同时降低硬件成本与网络延时,最终为AI具身智能的大规模应用扫清技术障碍。这一突破也集中体现在其六大核心能力上:
1、3D数字模型高质量
实际使用过程中,英语陪练数字人在浏览器中实时渲染,表情、口型、动作毫秒级同步,视觉效果涵盖超写实、二次元等多风格,细节表现力媲美专业级制作;高质量3D数字人生动的表情与连贯动作,相比单一音频或文字,能显著提升学习兴趣,让用户更愿意开口表达。
2、人机交互低延时
在进行英语陪练过程中,数字人能实现500ms内驱动响应,实际使用中无明显卡顿,支持随时打断数字人说话,交互流畅度接近真人,发音纯正且语速可调,新手也能轻松跟上,测试用户反馈:“像跟外教聊天,但不用怕说错尴尬
3、客户使用低成本
SDK采用客户端渲染架构,无需GPU服务器,服务端仅传输轻量化驱动数据,流量消耗极低,百元级芯片(如RK3566、RK3588)即可稳定运行;
4、服务端支持高并发
将渲染压力转移至客户端,服务端可轻松承载千万级设备同时在线,适配教育、客服等大规模场景需求;通过这一高并发能力可以支撑学校、培训机构等批量部署,真正实现AI具身智能在教育领域的规模化应用。
5、数字人风格种类多
平台提供10+种预置角色,涵盖校园老师、卡通形象、二次元人物等,搭配丰富音色,满足不同场景人设需求;
针对儿童用户,选用多风格中的卡通角色,搭配英语小游戏,实现“边玩边学”。
6、多终端适配
支持各种浏览器,全面适配手机、车机、Pad、PC、电视与大屏,兼容 Android、iOS、鸿蒙等主流系统,得益于多终端兼容特性使得用户可在通勤、午休等碎片时间通过手机练习英语。
五、小结:用简单代码,解锁具身智能教育场景新可能
魔珐星云具身驱动 SDK(JS 版本)的核心价值,在于把复杂的 3D 数字人技术 “降维” 成开发者可快速上手的实用工具 —— 无需深耕 3D 建模、动作捕捉等专业领域,通过前端技术栈与清晰的 API 设计,只需完成注册配置、SDK 引入、核心代码编写三步,就能快速实现文本驱动的 3D 数字人交互。
魔珐星云最牛的就是:让“好看又好用的交互”和“简单易上手的开发”同时实现。做英语陪练时,你不用纠结“怎么让数字人动起来”,只要琢磨“怎么让练习更有趣”就行——它帮你把技术难题都解决了。从简单对话到场景练习,从新手开发者到普通用户,魔珐星云让“有身体的智能”在教育里发挥大作用。不管是练英语、学技能,还是给小朋友做启蒙,它都是门槛最低的工具。
无论是想为产品添加人性化交互入口,还是探索教育、陪伴、家居等场景的智能升级,魔珐星云都提供了最低门槛的落地路径。现在前往魔珐星云官网(https://xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc40)免费注册,获取专属 App ID 与 Secret,用几行代码开启你的具身智能开发之旅,让 AI 真正 “有身体、会交流”!
仓库代码地址: https://gitcode.com/m0_61243965/3D_Digital_Human

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)