
具身智能大模型年度技术总结
最近参与了CSDN官方的活动:博客之星2025年度总评选。借此机会总结一下本人从2025年5月到2025年12月底期间学习具身智能大模型的历程,总结一下这半年多相关领域的技术工具以及CSDN平台的使用心得等等。
0. 前言
最近参与了CSDN官方的活动:博客之星2025年度总评选。
借此机会总结一下本人从2025年5月到2025年12月底期间学习具身智能大模型的历程,总结一下这半年多相关领域的技术工具以及CSDN平台的使用心得等等。
1. 年度技术主线
1.1 VLA 成为具身大模型的“默认答案”
过去一年,“具身智能大模型”从概念热度走向工程闭环:VLM(视觉语言模型)不再只负责理解,开始直接参与控制;策略模型从“为某一台机械臂定制”转向“跨本体可迁移”;数据与仿真从成本中心变为增长飞轮。
今年最明确的趋势是:Vision-Language-Action(VLA) 从论文范式变成工程范式。早期做法通常是“VLM 负责理解 + 规划器/控制器负责动作”,但 VLA 直接把“看、听懂、动”端到端打通,核心价值是更强的泛化、更少的任务工程。
- 典型代表是Physical Intelligence (π),简直是明灯,名字很有意思,“具身智能”取单词第一个字母组合,pi,
。他们相继开源了pi0,pi0.5,最近更是发表了pi star 0.6,以及其他诸多优秀工作。
- 另一个具有杰出贡献的我认为是lerobot,一套具身智能应用开源框架,从性价比极高的硬件so100/so101机械臂,到软件层面的策略的集成,再到被广泛使用的lerobot数据集格式,毋庸置疑成为具身智能新手到老手必懂的项目。
当然也有一些其他或公司/团队/学校/研究院等优秀的工作,在这里便不一一列举,相关的盘点在CSDN社区中也非常丰富。
1.2 世界模型
2025 年如果要用一句话盘点世界模型(World Model),我的感受是:它从“给 model-based RL 用的内部组件”,变成了更通用、更直观的“预测引擎”——先把未来几秒会看到什么、环境会怎么变这件事学明白,再用它反过来服务控制、规划和数据扩展。
研究上最明显的转向是视频生成式世界模型:不再只在潜变量里滚动状态,而是直接预测未来观测(甚至是连续视频)。比如 Navigation World Models(CVPR 2025)用 Conditional Diffusion Transformer 去做可控视频预测,并把规模推到 1B 参数级别,强调“用生成的未来画面来支撑导航决策”。
同时,机器人操作领域开始把“动作”和“视频预测”更紧地绑在一起:Unified World Models(UWM,2025)把动作扩散和视频扩散放进同一个统一架构里,你通过控制不同模态的扩散步数,就能在“当策略、当前向动力学、当逆动力学、当视频生成器”之间切换,等于是把 world model 和 policy 的边界拉得很模糊,但工程上反而更好用。
产业侧的信号也很明确:NVIDIA 把 Cosmos 定位成“世界基础模型/世界状态预测”,并突出可以从多模态输入生成长达数十秒的未来视频,用于机器人/自动驾驶的预测与场景推演,同时强调开放与生态绑定(数据飞轮、仿真、训练栈一起推)。
但是由于我个人对世界模型还没有更精细的使用和研究,只是看过一些论文,期待明年这个方向继续蓬勃发展,我也有时间能够体验一番。
2. 技术项目实战经验
2.1 硬件
(1)机器人本体与末端执行器
-
机械臂优先看三件事:重复定位精度、关节速度/加速度上限、力矩裕度。很多“看起来是模型问题”的抖动,其实是机械臂速度环/力矩余量不够。
-
末端执行器别一开始就追求“万能夹爪”,更推荐两套:
-
通用并联夹爪(主力做大多数抓取)
-
软夹/吸盘/指尖套(专门解决易滑、易碎、薄片类)
-
-
如果你做的是接触丰富任务(插拔、装配),建议尽早引入 力/扭矩传感器(F/T) 或等效信号(电流/力矩估计),否则后期会被“卡住但看不出来”反复折磨。
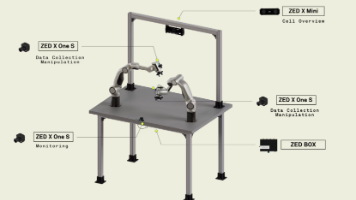
(2)相机配置
- 普通相机有opencv的接口,realsense有单独的专业的接口,都可以正常使用。
-
相机至少两视角:全局视角(overhead / 前视)+ 腕部视角(wrist)。单视角会让数据覆盖天生不足,多篇论文都有做相关测试,而且wrist想当重要。
(3)训练与部署设备
-
微调模型所需的显卡要求还是比较高的,尤其是需要全量微调模型的时候,一般的显卡往往难以支撑,需要lora或切片或其他方法。
-
部署的显存要求略低一些,但是也会影响到模型推理速度。
(4)校准与健康检查(每次上电都应该可诊断)
-
比如我使用过的so101,虽然断电之后会保存校准文件,但是重新使用的时候还是会find port找主从臂串口,然后才能一一对应。
2.2 录制数据
社区中缺乏对录制数据的完整指导,对于某种VLA要完成的某种任务来说,多少条数据也没有很精细的说明,这很容易理解,每个人的录制环境各不相同,设备之间也有差异,数据集的质量也就参差不齐,数量那更是没法界定。
我个人实验之后任务官方说的至少50条模型进行训练,确实是至少,50条在一些VLA上确实没办法完成任务,或者成功率很低,这个大多数时候只是一个“学习”级别的数据量,尤其是初学者录制的数据并不“完美”,50条还是太少了。
个人建议在某一个非常具体的任务上,要有150+的episode,这样即便数据集有个别质量一般,也没太大问题。
录制数据的方式基本就是主从臂,末端遥操比较好用一些,当然这是针对机械臂来说的,我也有相关的文章说明。如果是底盘那就是用按键摇杆遥控了,xlerobot就非常经典,可以参考。
2.3 训练与部署模型
训练资源较少的话初学者可以微调以下smolvla,0.5B,非常轻量,而且lerobot官方说明,社区教程完善,就算出了问题也容易解决。但是并不适合在具体的工程上使用,除非你用的硬件是so100/so101。
那么这就引出了一个点:如果一个VLA在大量某embodiment的数据上训练,那么它在这种机体上的表现会优于其他的embodiment。有优点有缺点,缺点是无法通用,或者说微调到其他embodiment的表现不是很好;优点就是在某种机体上表现优异,甚至能与更大参数量的模型媲美。
对于部署来说可以把模型推理融入硬件运行部分,也可以尝试服务端客户端网络通信式部署。
2.4 实验验证
针对各自的任务设置就可以,简单短时序就单纯的SR%就可以,复杂长时序可以多设计几个“子任务”按照完成多少子任务和最终成功率综合打分。
3. 技术工具与平台使用心得
四条宗旨:
多看Github,多逛Hugging face,多用lerobot,多写CSDN。
很简单,github可以让我们了解有什么值的复现的项目,huggingface可以让我们了解有哪些开源模型与数据集,lerobot可以让我们积累丰富的真机实践经验,CSDN可以让我们将前面三步进行总结记录。
很多东西看过用过之后很容易忘,做笔记可以让我们快速的回忆细节,而且由于这个领域更新极快,如果不做好记录,之前用过的习惯的东西容易被更新掉。而且CSDN自带MarkDown编辑器,稍加使用就会爱上这种极简风格。对“具身智能”这类需要大量配置与代码片段的内容,Markdown 是更合适的选项。
总之,2025 下半年的收获不是“我已经掌握了具身智能大模型”,而是我开始更清楚地知道:要把它做成一个能反复成功的系统,应该从哪里入手、先打通哪条链路、哪些坑最值得提前规避。期待 2026 年,我能在世界模型与更复杂任务的闭环上再向前走一步,也希望在 CSDN 上继续把这些实践过程沉淀成对后来者更有用的经验。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)