
会跳舞、能演讲!RoboPerform 让人形机器人听懂声音,即兴解锁双重技能
本文的主要作者来自北京智源人工智能研究院、哈尔滨工业大学、香港科技大学、上海交通大学、北京大学和悉尼大学。本文的第一作者为北京智源人工智能研究院的实习生李哲,主要研究方向为具身智能和3D数字人。共同一作是哈尔滨工业大学的韦杨扬。本文的通讯作者为北京大学计算机学院研究员、助理教授仉尚航和北京智源研究院研究员迟程。
本文的主要作者来自北京智源人工智能研究院、哈尔滨工业大学、香港科技大学、上海交通大学、北京大学和悉尼大学。本文的第一作者为北京智源人工智能研究院的实习生李哲,主要研究方向为具身智能和3D数字人。共同一作是哈尔滨工业大学的韦杨扬。本文的通讯作者为北京大学计算机学院研究员、助理教授仉尚航和北京智源研究院研究员迟程。
行业痛点:多阶段流程带来的信息损失
当爵士乐的节拍响起,人形机器人即刻舒展肢体,抬手、转身、踏步精准踩中每一个鼓点;当演讲者的话音落下,它又能顺着语调的抑扬、话语的重音,自然抬手、侧身、点头,用恰到好处的肢体语言强化表达。 这不是科幻电影里的片段,而是 RoboPerform 正在实现的现实。
它打破了人形机器人 “照本宣科” 的动作困境,既让机器能随音乐即兴起舞,也能配合语音生成自然手势,真正听懂声音的情绪与节奏,跳出有温度、有灵气的 “自由舞步”,讲出有感染力的 “肢体语言”。

- 论文链接:https://arxiv.org/pdf/2512.23650
- 论文标题:Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control
- 项目主页:https://gentlefress.github.io/RoboPerform-proj/
- Youtube:https://www.youtube.com/watch?v=YAEdWPqXemQ
行业痛点:音频与关节驱动的弱耦合
长久以来,音频驱动的人形机器人运动始终被一道无形的 “镣铐” 束缚:音频与关节驱动的弱耦合困境,让机器人永远慢半拍、没灵气,无论是跳舞还是配合演讲都显得僵硬违和。
人类的肢体动作与音频天然同频:音乐的快慢、旋律的起伏,会映射为动作的节奏与幅度;语音的重音、语调的转折,会自然催生出辅助表达的手势。但现有系统却始终走在 “弯路” 上:先根据音频生成人类运动数据,再重定向到机器人,最后执行动作。
这种多阶段流程就像一场 “传话游戏”:人类运动与机器人的物理约束本就不匹配,重定向过程又会丢失音频的细粒度特征。音乐到高潮时,机器人动作还停留在前奏;演讲者强调核心观点时,机器人的手势却慢了半秒。更核心的问题在于,高层的音频线索与底层的关节驱动之间,始终缺少直接的映射路径。
部分方法试图用精心设计的奖励或单一运动模板弥补,但换一首没训练过的曲子、换一种没接触过的语音,机器人的动作就会瞬间 “失灵”;长序列运动时,误差不断累积,甚至会出现动作 “跑偏”、摔倒的情况。要让机器人真正拥有 “即兴发挥” 的能力,无论是跳舞还是配合演讲,我们必须撕掉这层 “镣铐”,建立一条从音频到运动的直接映射路径。
破局之思:运动是 “内容 + 风格” 的协同创作
“为什么人类能随随便便跟着音乐跳舞、跟着说话做手势?” 这是团队在研究初期反复琢磨的问题。
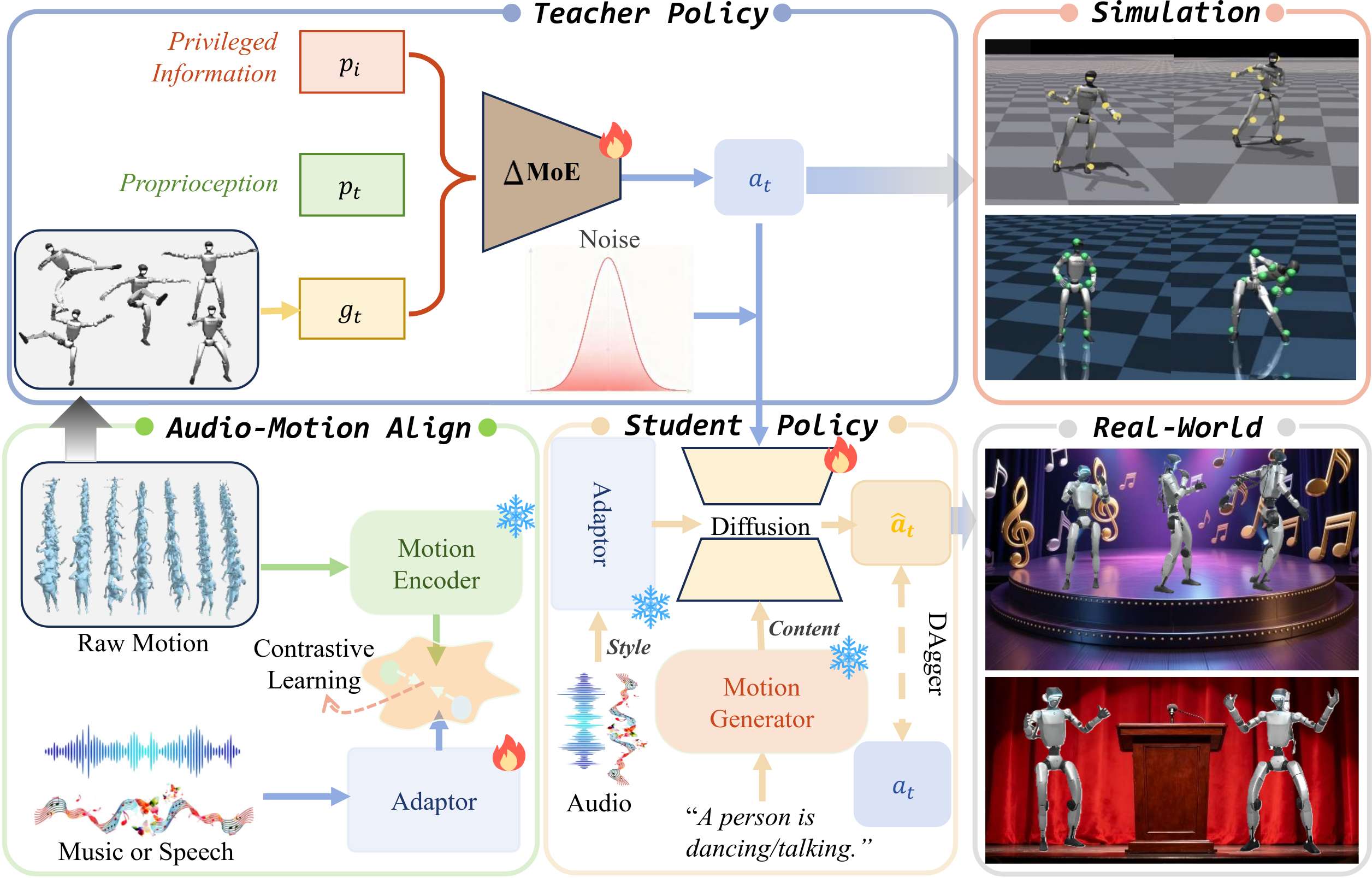
团队发现,人类的运动本质是一场 “内容 + 风格” 的协同创作:“内容” 是核心任务(比如 “跳舞”“演讲”),“风格” 则是音频赋予的节奏与情绪(比如音乐的节拍、语音的韵律)。基于这个核心洞察,团队提出了 RoboPerform,一个无需重定向的一体化音频 - 运动生成框架,让机器人直接 “听懂” 音频,生成适配自身的动作。
不同于传统方法 “音频→人类运动→机器人动作” 的绕路模式,RoboPerform 直接将机器人策略建立在音频驱动的 “内容 - 风格” 双潜表征之上。它绕开了显式的运动重建与重定向流程,让基于扩散模型的学生策略,在运动内容潜变量的引导下,直接融合音频风格潜变量解算可执行动作。
在这里,∆MoE 混合专家教师策略与 InfoNCE 音频 - 运动对齐模块形成了完美互补:前者通过多个专家网络的分工协作,让机器人既能驾驭动感舞蹈,也能适配自然演讲;后者则像一座桥梁,将运动动力学先验注入音频特征,让动作精准踩住音频的每一个节拍与重音,彻底告别 “动作慢半拍” 的尴尬。
技术解密:从 “听懂” 到 “会做” 的三重突破
团队设计了 “对齐 - 蒸馏 - 生成” 三阶段训练流程,结合 “内容 - 风格” 解耦机制,实现音频到机器人动作的直接映射:
1. 跨模态对齐:让音频与运动 “同频共振”
团队设计了基于 6 层 Transformer 与时序注意力的音频适配模块,结合 InfoNCE 对比学习损失,让音频潜变量与运动潜变量在嵌入空间精准对齐。这一步就像给机器人装上 “音乐耳朵” 与 “语言感知力”:面对音乐,它能捕捉节拍、旋律起伏;面对语音,它能识别重音、语调变化,为跨模态关联筑牢基础。
2. 分层策略:兼顾多样性与精准度
团队提出了∆MoE 混合专家教师策略,它通过嵌套条件子空间划分,让多个专家网络分别适配不同的运动场景(快节奏舞蹈、舒缓手势等),再通过 “残差融合” 机制减少信息冗余、强化互补性。后续通过 DAgger 式蒸馏,将教师知识迁移至扩散模型学生网络,以固定运动潜变量引导去噪,通过 AdaLN 跨层注入音频潜变量,实现 “内容定任务、风格调表达” 的解耦生成,跳舞时贴合音乐风格,演讲时匹配语音韵律。
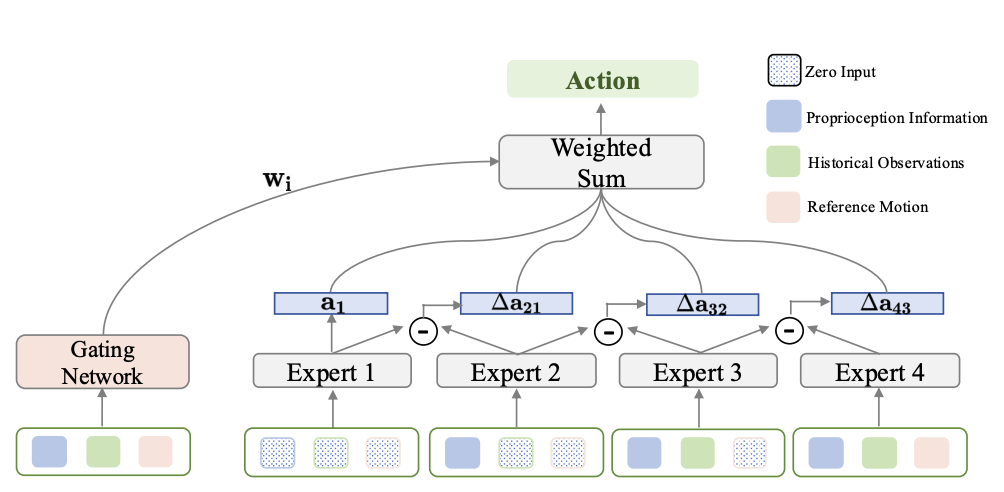
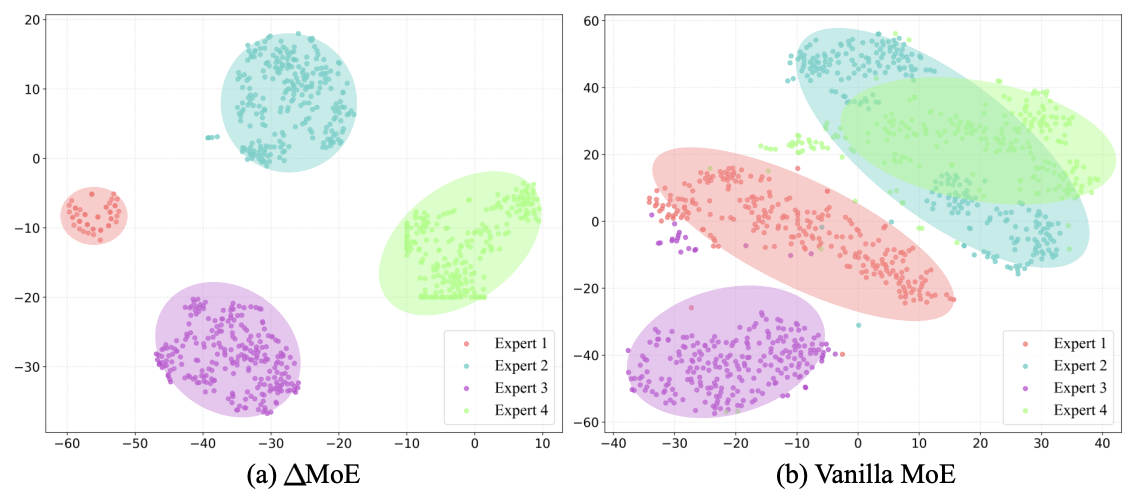
3. 高效生成:实时响应无延迟
为了让机器人能 “即兴” 表演,团队采用 x₀-prediction训练目标与两步 DDIM 采样技术,将单动作推理延迟压缩至 5.3ms,整体部署时间仅需1.2s。这个速度远超传统重定向方案,完全满足人形机器人实时运动控制的严苛要求。同时通过域随机化、课程学习等训练策略,让机器人在面对未见过的音乐或语音时,也能稳定输出高质量动作。
结果说话:精准同步,高效部署
为了全面验证 RoboPerform 的实际性能,团队搭建了一套从数据训练到仿真、实机测试的完整验证体系:训练阶段采用 FineDance 舞蹈数据集与 BEAT2 语音数据集,前者覆盖多样曲风与舞蹈动作,后者包含多语种、多语调的语音片段;测试环节则横跨 IsaacGym、MuJoCo 两大主流仿真平台,并落地 Unitree G1 人形机器人开展实机验证。核心对比传统重定向基线方案与 vanilla MoE 架构,从音频 - 运动对齐精度、运动追踪效果、部署实时性、场景泛化能力四个核心维度展开测评。
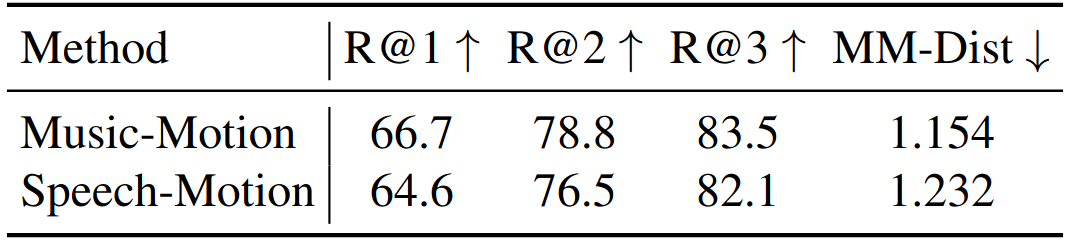
在音频 - 运动对齐能力这一核心指标上,RoboPerform 交出了一份亮眼的答卷。在音乐 - 运动检索任务中,模型的 Top-1 检索准确率高达 66.7%,Top-3 准确率更是攀升至 83.5%;即便是对语调、韵律更敏感的语音 - 运动检索任务,其 R@1 与 R@3 也分别达到 64.6% 和 82.1%。更关键的是,在衡量节拍匹配度的 Beat Alignment Score(BAS) 指标上,RoboPerform 显著超越所有基线方案,这意味着机器人不仅能 “听懂” 音频的内容,更能精准捕捉音乐的节拍、语音的重音。
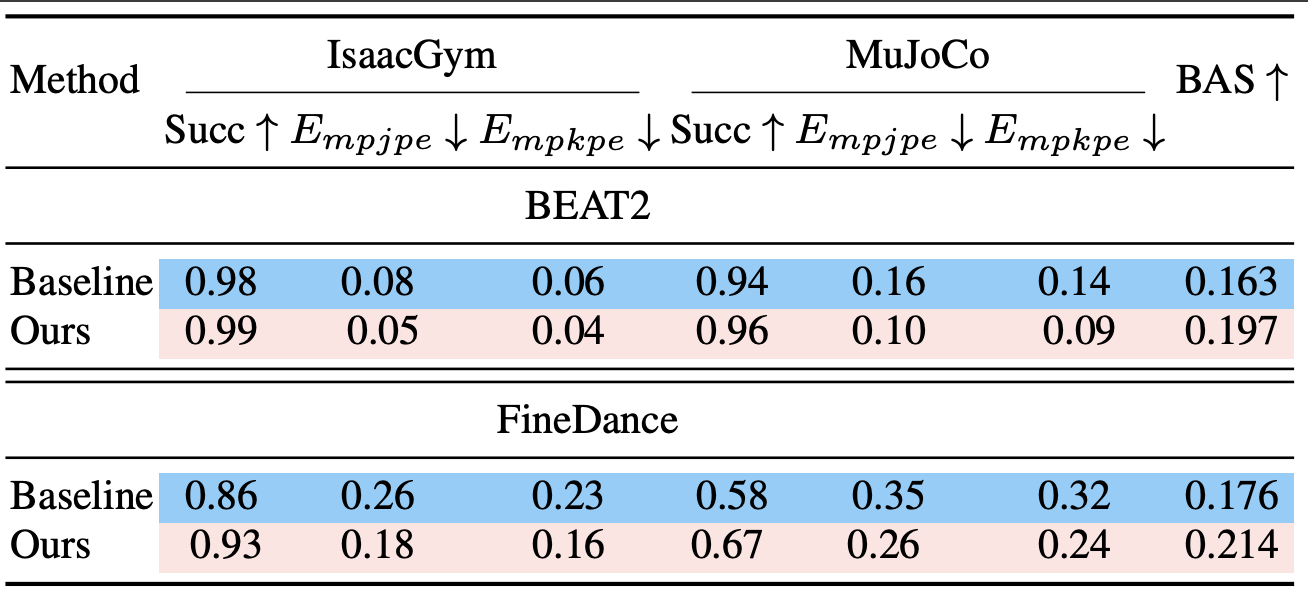
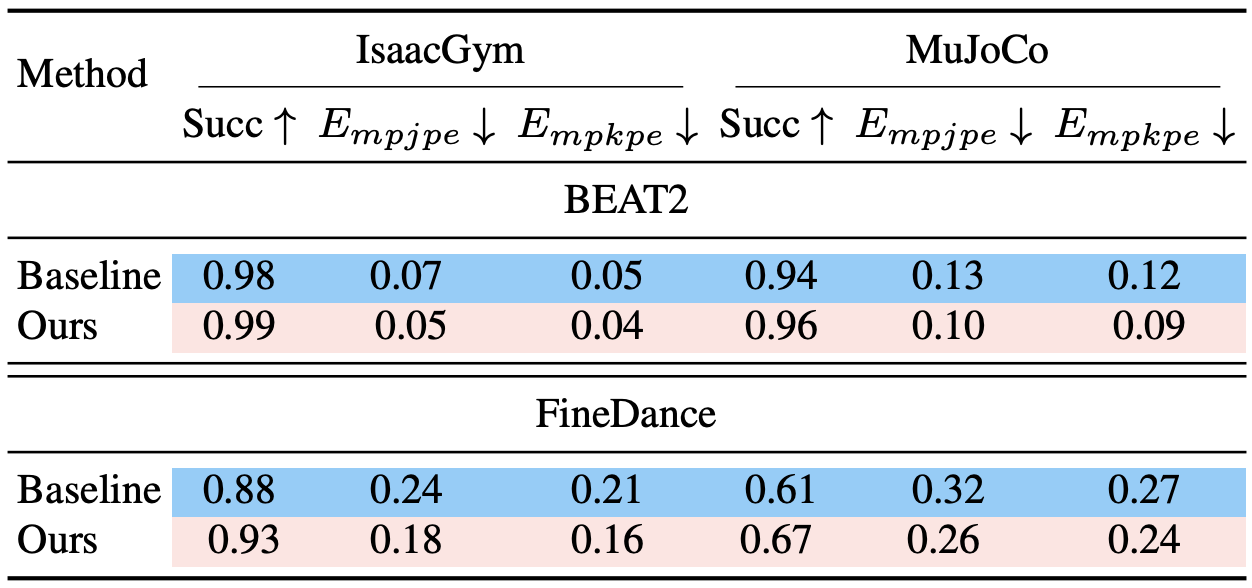
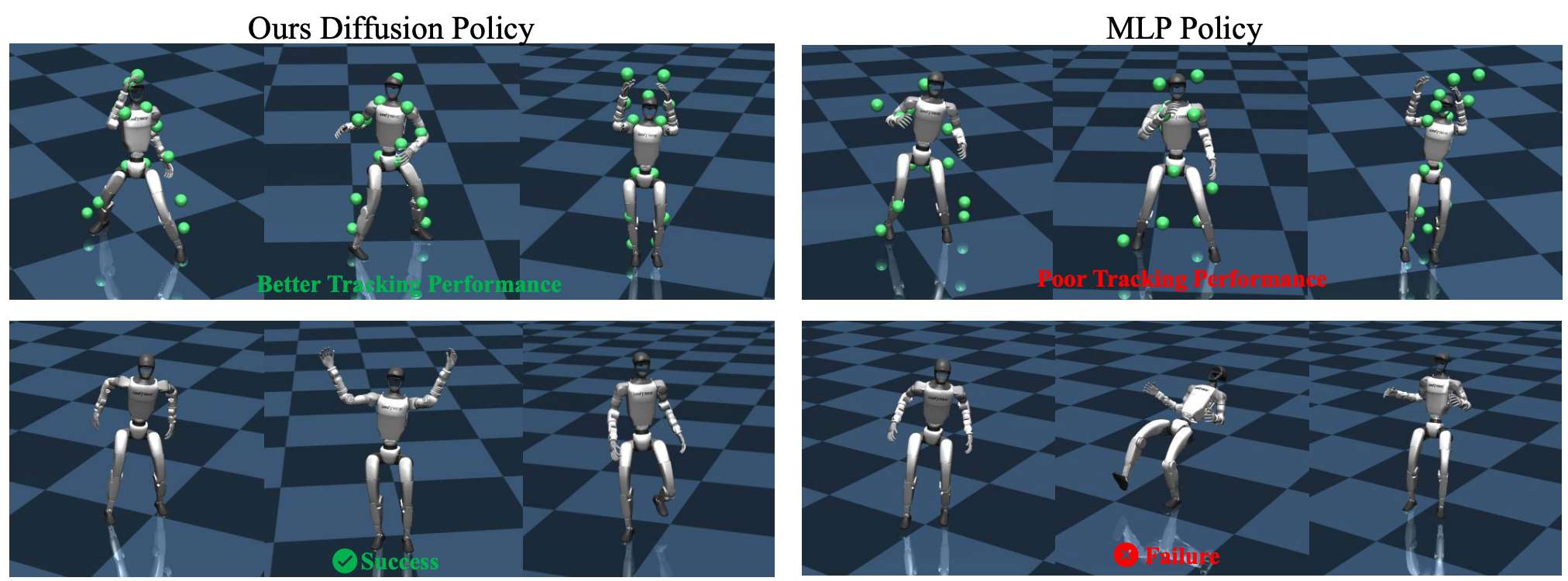
在运动追踪精度与物理合理性的测试中,RoboPerform 的优势同样十分突出。无论是仿真环境还是 Unitree G1 实机平台,模型在两类数据集上的任务成功率最高达到 99%;而在衡量动作精准度的核心指标 Mean Per Joint Position Error(MPJPE) 与 Mean Per Keypoint Position Error(MPKPE) 上,RoboPerform 的数值均显著低于传统重定向方案与 vanilla MoE 架构。这一结果充分证明:得益于 “内容 - 风格” 解耦的设计与运动动力学先验的注入,RoboPerform 生成的关节动作不仅精准复现了目标运动的形态,更严格契合人形机器人的物理约束,避免了仿真到实机迁移时常见的 “动作漂移”“关节超限” 等问题。
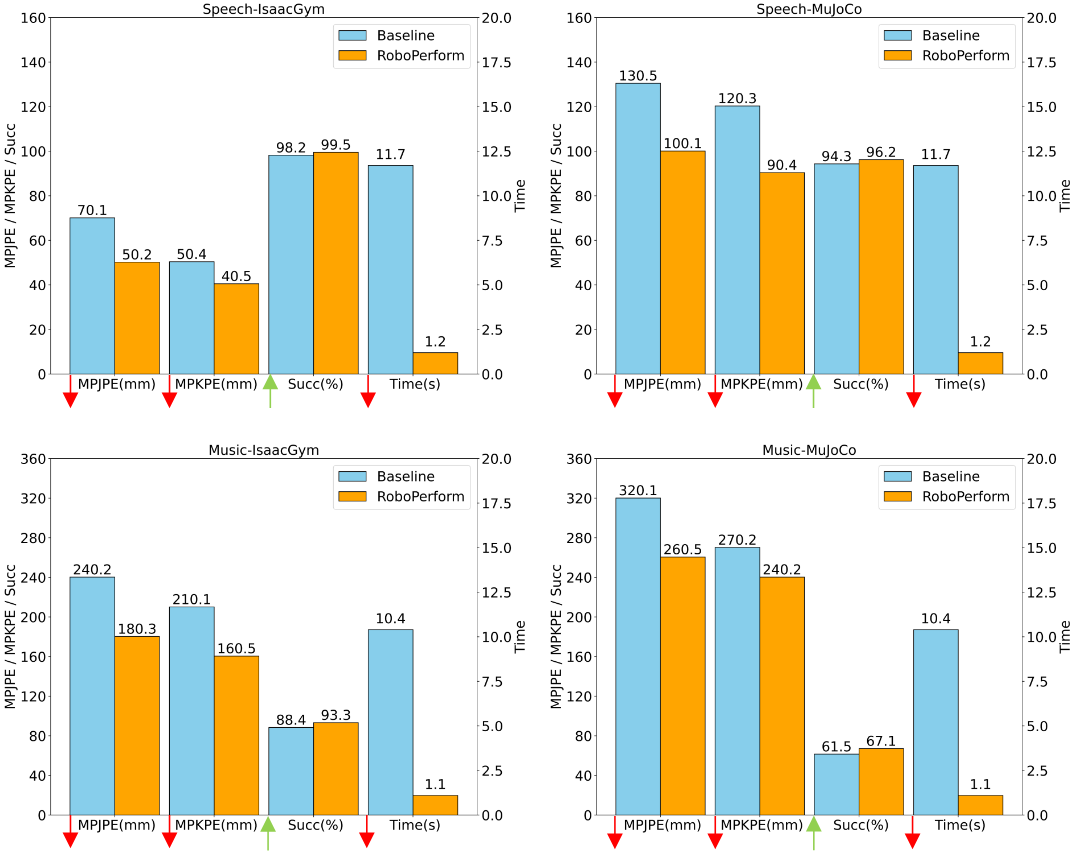
部署实时性则是 RoboPerform 走向实际应用的关键。团队针对性优化了扩散模型的采样流程,通过 x₀-prediction与 两步 DDIM 采样技术的结合,将单动作推理延迟压缩至 5.3ms,整体部署时间仅需1.2s左右。这一速度不仅远超传统重定向方案的整体推理延迟水平,更满足了人形机器人实时运动控制的严苛要求。
在实机演示中,Unitree G1 机器人能够流畅跟随音乐节拍完成抬手、转身、踏步等连贯舞蹈动作,或是配合语音的抑扬顿挫做出自然的手势与肢体姿态,全程无卡顿、无延迟,真正实现了 “音频输入 - 动作输出” 的端到端实时响应。
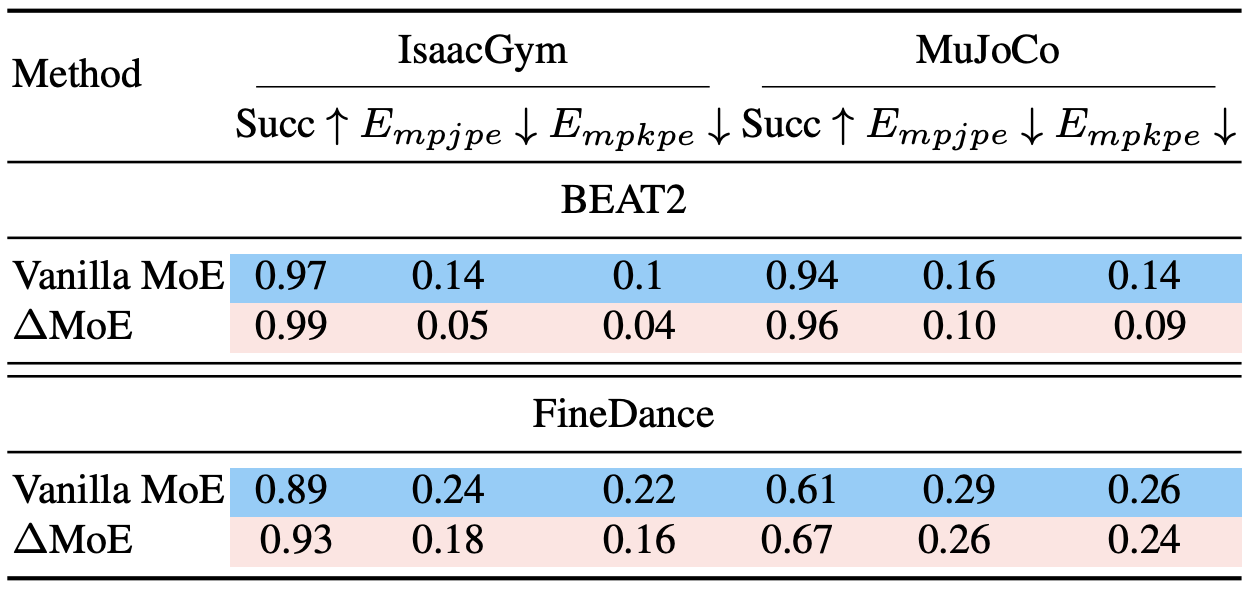
泛化性验证中,面对未见过的音频信号,其运动追踪成功率与稳定性仍优于 vanilla MoE 及基线方案,动态场景下长序列运动无失控情况,并且能根据音频的抑扬顿挫做出相应的反映。
此外,团队通过仿真与实机演示,直观展示了 RoboPerform 在音乐驱动舞蹈、语音伴随手势生成任务中的表现:机器人能够精准跟随音乐节拍完成即兴舞蹈,同步语音重音与语调变化做出自然手势,充分验证了无重定向音频直接驱动架构的实用性与优越性。
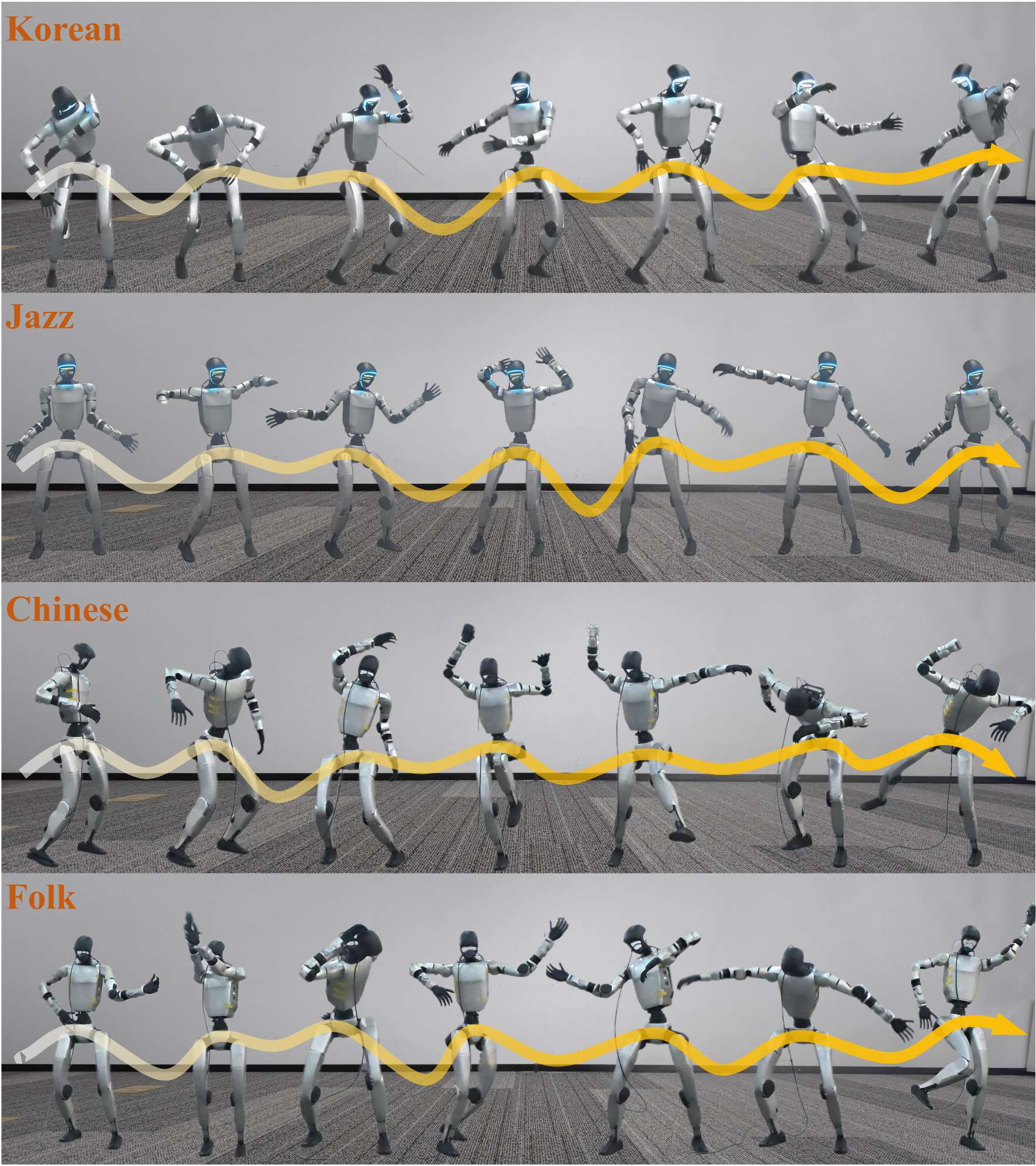
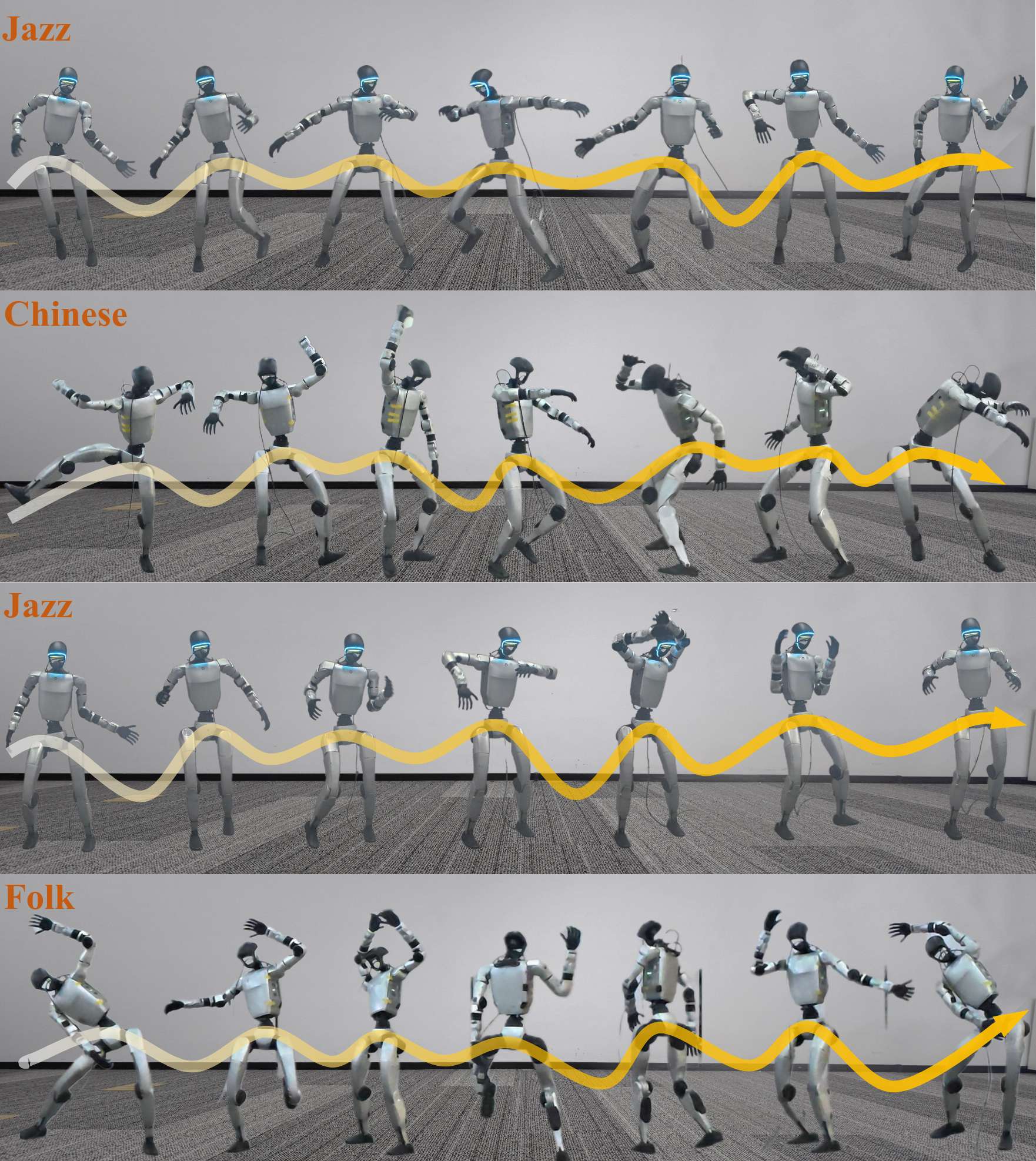
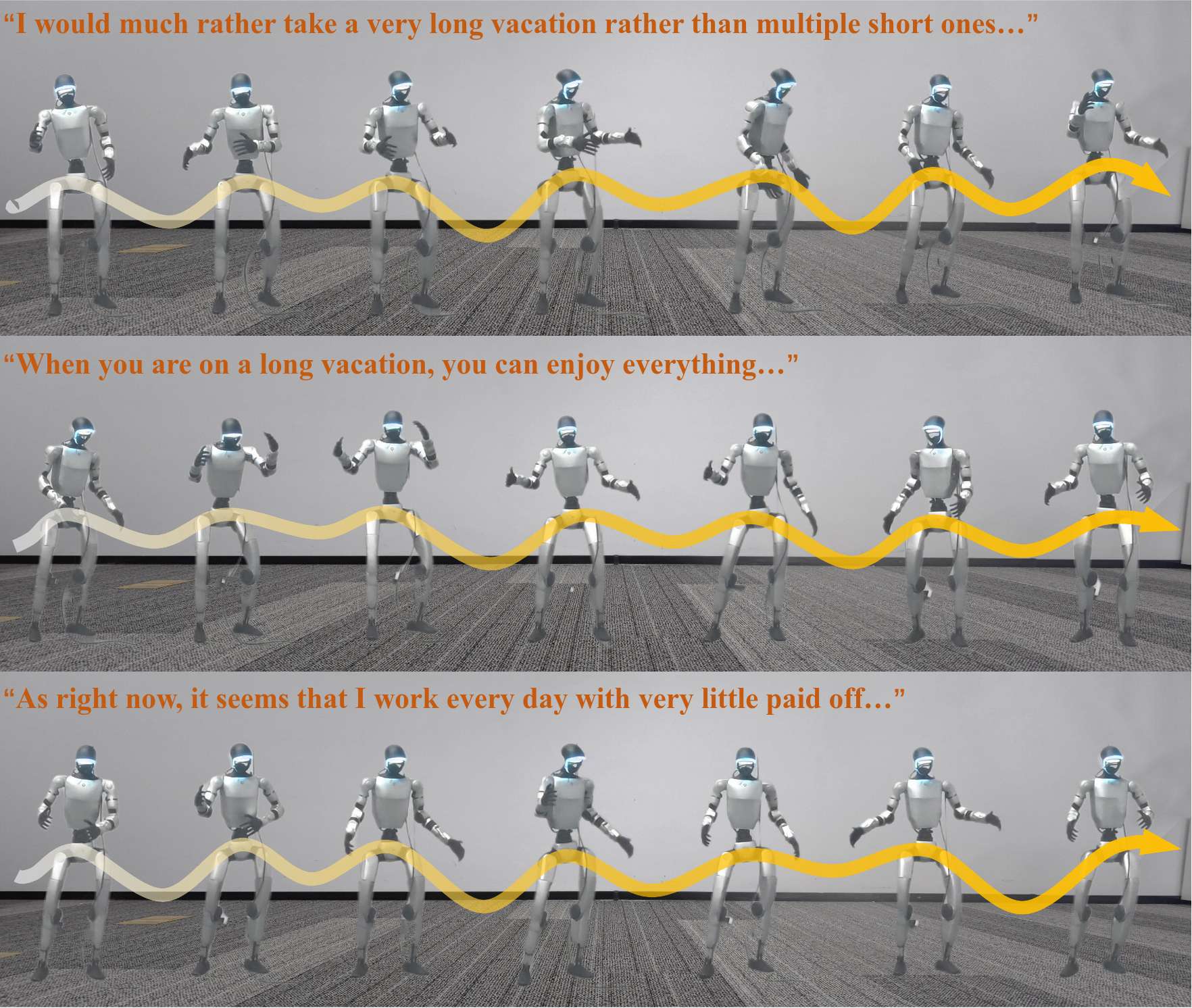
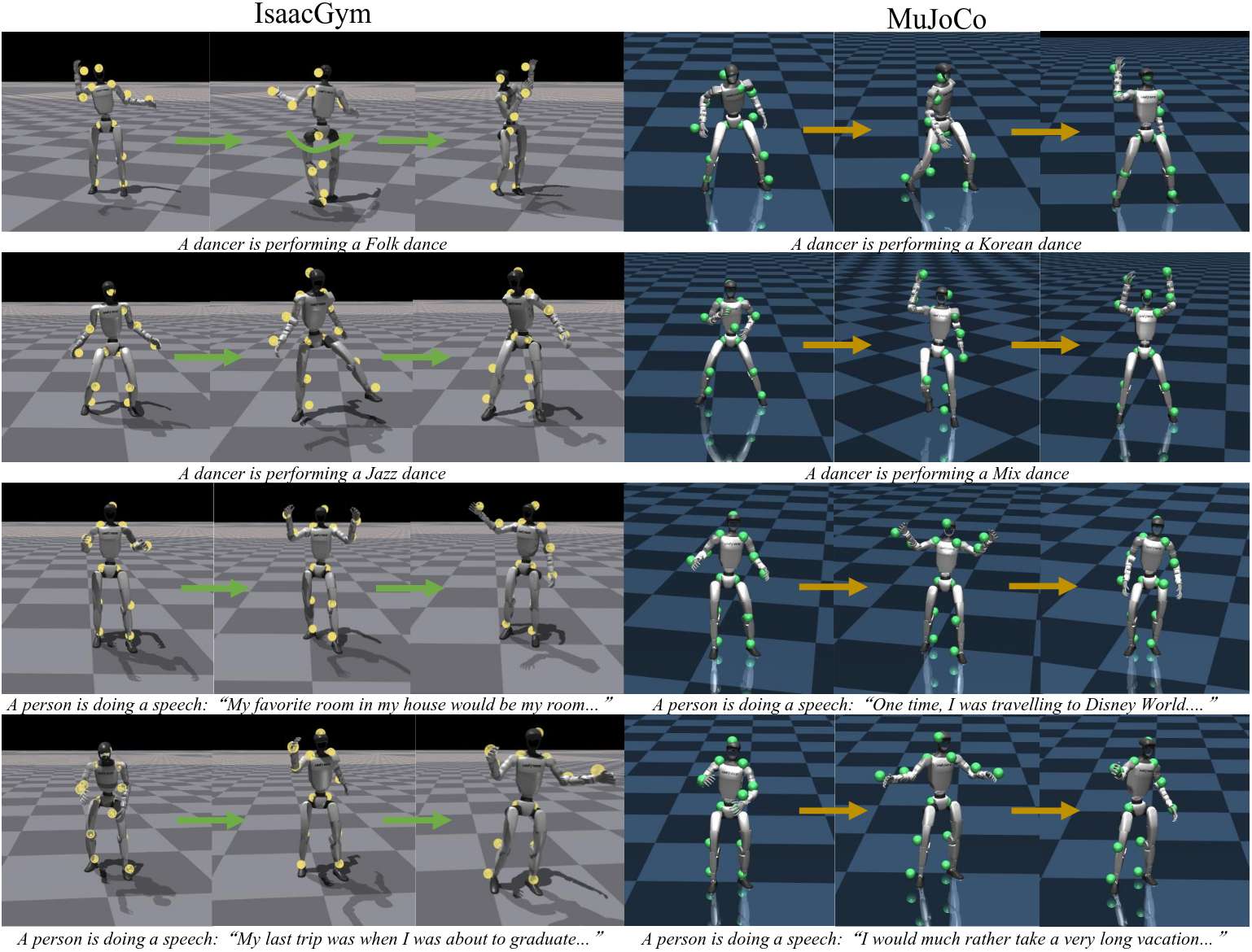
最后,团队在仿真环境中也验证了策略的Freestyle能力,并与Baseline进行了对比。团队发现,RoboPerform可以做出稳定且语义更丰富的舞蹈动作,而Baseline方法会出现摔倒以及抖动的现象。
更多技术细节和demo视频欢迎查看论文和项目主页。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 24
24 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)