
QVLA:首个面向具身控制的通道级动作感知量化框架
摘要: 视觉-语言-动作(VLA)模型在具身智能领域展现出强大潜力,但其高算力需求限制了在机器人上的实时部署。传统大语言模型(LLM)量化方法直接应用于VLA时,因动作输出的连续性和误差累积效应导致性能显著下降。上海交通大学等团队提出QVLA框架,通过分析VLA模型各模块对量化的敏感度差异,发现视觉编码器较鲁棒,而投影层和动作头极敏感。QVLA采用通道级混合精度量化策略,结合Hessian矩阵近似
1. 引言:当大模型遇上小算力机器人
视觉-语言-动作(Vision-Language-Action, VLA)模型正在重塑具身智能的技术版图。从 Google 的 RT-2 到斯坦福的 OpenVLA,这类模型将视觉感知、语言理解和动作生成统一在一个端到端的框架中,让机器人能够根据一句自然语言指令和当前的视觉观测,直接输出末端执行器的连续动作序列。这种能力在泛化性和语义推理上远超传统的任务特定策略,被视为通往通用机器人操作的关键路径。
然而,能力的提升伴随着算力需求的急剧膨胀。一个标准的 7B 参数 VLA 模型在半精度(BF16)下需要超过 14GB 的显存,而在 NVIDIA Jetson AGX Orin 这类机器人常用的边缘计算平台上,单次推理延迟可达数百毫秒——对于需要实时闭环控制的抓取、装配等任务而言,这个速度远远不够。模型压缩,特别是低比特量化(Low-bit Quantization),是解决这一矛盾的最直接手段。量化技术在大语言模型(LLM)领域已经非常成熟,SmoothQuant、AWQ、GPTQ 等方法能够将模型压缩到 4-bit 甚至更低,同时保持文本生成质量。但一个关键问题是:这些为"生成文本"而设计的量化方法,能否直接搬到"控制机器人"的 VLA 模型上?
在 ICLR 2026 上,来自上海交通大学 AutoLab、无界动力、中科院自动化所和蚂蚁集团的研究团队给出了系统性的回答。他们提出了 QVLA(Quantized VLA),这是首个专门面向具身控制场景的通道级动作感知量化框架。论文链接:https://arxiv.org/abs/2602.03782,代码仓库:https://github.com/AutoLab-SAI-SJTU/QVLA
2. 核心问题:LLM 的量化方法为什么在机器人上失效
要理解 QVLA 的设计动机,首先需要搞清楚一个根本性的区别:LLM 的输出是文本 token,而 VLA 的输出是连续的动作值(末端执行器的位姿、关节速度等)。这个区别看似简单,却导致了量化误差在两个场景中截然不同的传播方式。
在 LLM 中,量化的优化目标通常是保持文本困惑度(perplexity)或视觉特征的保真度。量化引入的微小数值偏差,在经过 softmax 归一化后,对最终 token 采样的影响往往是可控的。但在 VLA 的闭环控制场景中,情况完全不同。模型输出的动作值直接驱动机器人的物理运动,即便是极其微小的动作偏差,也会被物理环境中的接触力、重力和摩擦力放大。更关键的是,VLA 模型通常以自回归方式逐步生成动作序列——上一步的动作执行结果会改变环境状态,进而影响下一步的视觉输入。这意味着量化误差不是一次性的,而是会在时间维度上累积。一个初始的微小偏差,经过长序列任务的逐步放大,最终可能导致抓取失败或轨迹完全偏离。
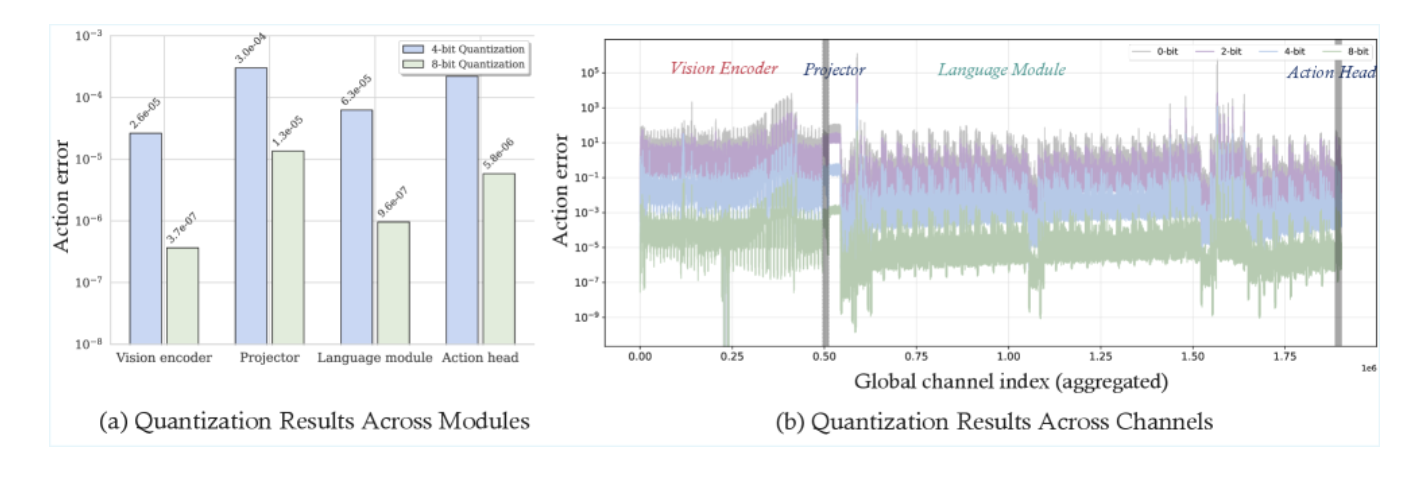
定量分析VLA的量化敏感度
研究团队的实验数据直观地验证了这一点:在 OpenVLA-OFT 模型上,直接套用 LLM 领域的 SmoothQuant 进行 W4A4 量化,任务成功率从 97.1% 暴跌到 73.4%,下降了 23.7 个百分点。这不是"性能略有下降",而是"系统基本不可用"。
用数学语言表达,VLA 量化的优化目标应该是最小化原始策略 Π θ \Pi_\theta Πθ 和量化策略 Π θ ^ \Pi_{\hat{\theta}} Πθ^ 在动作分布上的 KL 散度:
Q ∗ = arg min Q E ( V t , p , H t ) ∼ D [ D K L ( Π θ ( a t ∣ V t , p , H t ) ∥ Π Q ( θ ) ( A t ∣ V t , p , H t ) ) ] Q^* = \underset{Q}{\arg\min} \; \mathbb{E}_{(\mathcal{V}_t, p, \mathcal{H}_t) \sim \mathcal{D}} \left[ D_{KL} \left( \Pi_\theta(a_t | \mathcal{V}_t, p, \mathcal{H}_t) \| \Pi_{Q(\theta)}(\mathcal{A}_t | \mathcal{V}_t, p, \mathcal{H}_t) \right) \right] Q∗=QargminE(Vt,p,Ht)∼D[DKL(Πθ(at∣Vt,p,Ht)∥ΠQ(θ)(At∣Vt,p,Ht))]
其中 V t \mathcal{V}_t Vt 是视觉观测, p p p 是语言指令, H t \mathcal{H}_t Ht 是历史信息, D \mathcal{D} D 是数据分布。传统的 LLM 量化方法优化的是中间特征的重构误差,而非这个动作空间的目标——这正是它们在 VLA 上失效的根本原因。
3. 关键洞察:Not All Channels Are Equal
QVLA 的核心思想建立在一个经验发现之上:VLA 模型中不同模块、不同层、甚至同一层内不同通道对量化的敏感度存在巨大差异。这个发现直接否定了"一刀切"式均匀量化的合理性。
研究团队对 VLA 模型的四个核心组件——视觉编码器 θ v i s \theta_{vis} θvis、投影层 θ p r o j \theta_{proj} θproj、语言模型骨干 θ l l m \theta_{llm} θllm、动作头 θ a c t \theta_{act} θact——分别进行了隔离量化实验。结果揭示了一个清晰的敏感度梯度:视觉编码器对量化最为鲁棒,这可能是因为视觉特征本身具有高维冗余性,少量精度损失不会显著改变特征的语义信息;语言模型骨干次之;而投影层和动作头对量化极其敏感,稍加压缩就会导致性能崩塌。这并不难理解——投影层是视觉模态和语言模态对齐的关键接口,动作头则是将抽象表征转化为物理动作的最后一环,任何在这两个位置引入的扰动都会直接、无衰减地传播到最终的动作输出。
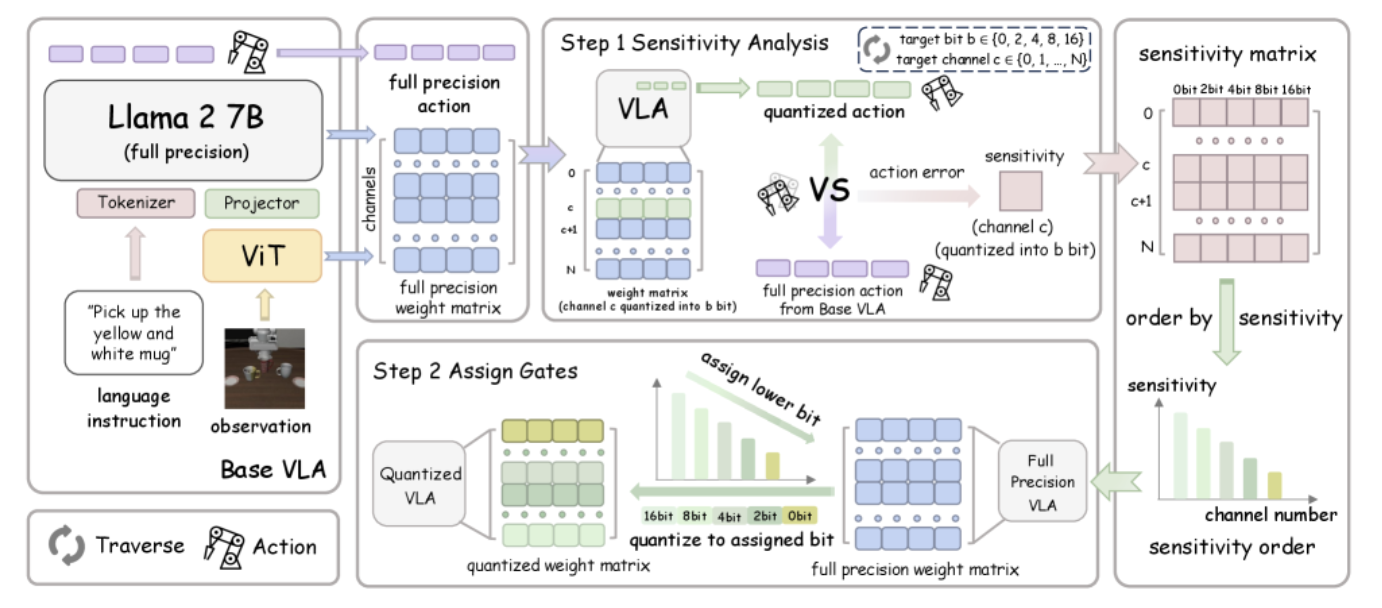
QVLA 的工作流程
更重要的发现在通道级别。即使在同一个线性层内部,不同输出通道对最终动作误差的贡献也天差地别。有些通道被量化后几乎不影响动作精度,而另一些通道哪怕轻微扰动就会引发显著的动作偏差。这种通道间的异质性,是传统的层级(layer-wise)或模块级(module-wise)混合精度策略无法捕捉的。
这个洞察直接引出了 QVLA 的设计原则:以动作空间的敏感度为锚点,为每个通道独立分配位宽。关键通道保留高精度(16-bit 或 8-bit),冗余通道激进压缩甚至直接剪枝(0-bit)。这样,量化和剪枝被统一到了同一个框架中——0-bit 就是剪枝,2/4/8-bit 是不同程度的量化,16-bit 是保持原精度。
在代码实现中,这个"哪些模块该量化、哪些该保护"的决策被硬编码为一个模块过滤函数:
# 文件:qvla/inject_fake_w.py
def _is_target_module(module_name: str, module: nn.Module) -> bool:
# 投影层、动作头、LM输出头:不量化,保留全精度
if module_name.startswith("projector.") or "action_head" in module_name \
or module_name.startswith("language_model.lm_head"):
return False
# 语言模型和视觉骨干中的 Linear/Conv2d 层:量化目标
if isinstance(module, (nn.Linear, nn.Conv2d)):
if module_name.startswith("language_model."):
return True
if module_name.startswith("vision_backbone."):
return True
return False
这段代码清晰地体现了敏感度分析的结论:投影层(projector)、动作头(action_head)和语言模型输出头(lm_head)被明确排除在量化范围之外,保留 BF16 全精度;而语言模型骨干和视觉编码器中的线性层和卷积层则是量化的目标。这种"保护关键接口、压缩大体积骨干"的策略,是 QVLA 在极致压缩下仍能保持高性能的基础。
4. QVLA 方法详解:两步走的量化流水线
QVLA 的工作流程可以概括为两个核心步骤:第一步,计算每个通道在不同位宽下对动作空间的敏感度;第二步,基于敏感度排名,用贪心算法为每个通道分配最优位宽。整个过程属于训练后量化(Post-Training Quantization),不需要重新训练模型,只需要一小批校准数据。
4.1 动作空间敏感度计算:基于 Hessian 代理的快速估计
QVLA 的敏感度度量直接锚定在动作空间,而非中间特征空间。对于第 l l l 层的第 c c c 个输出通道,将其量化到位宽 b b b 后,单步动作敏感度定义为:
s l , c ( b ) = E x ∼ D [ ∥ A ~ l , c ( b ) ( V , l ) − A ∗ ( V , l ) ∥ 2 2 ] s^{(b)}_{l,c} = \mathbb{E}_{x \sim \mathcal{D}} \left[ \left\| \tilde{\mathcal{A}}^{(b)}_{l,c}(\mathcal{V}, l) - \mathcal{A}^*(\mathcal{V}, l) \right\|_2^2 \right] sl,c(b)=Ex∼D[ A~l,c(b)(V,l)−A∗(V,l) 22]
其中 A ~ l , c ( b ) \tilde{\mathcal{A}}^{(b)}_{l,c} A~l,c(b) 是量化该通道后的动作输出, A ∗ \mathcal{A}^* A∗ 是全精度模型的参考动作。考虑到长序列任务中误差会累积,还引入了累积敏感度:
S l , c ( b ) = E [ ∑ t = 1 T ∥ A ~ l , c ( b ) ( V t , l ) − A ∗ ( V t , l ) ∥ 2 ] S^{(b)}_{l,c} = \mathbb{E} \left[ \sum_{t=1}^{T} \left\| \tilde{\mathcal{A}}^{(b)}_{l,c}(\mathcal{V}_t, l) - \mathcal{A}^*(\mathcal{V}_t, l) \right\|_2 \right] Sl,c(b)=E[t=1∑T A~l,c(b)(Vt,l)−A∗(Vt,l) 2]
但逐通道、逐位宽地做完整前向传播来计算精确敏感度,计算成本是不可接受的。QVLA 的解决方案是利用泰勒展开推导一个一阶近似代理指标。核心思路是:通道输出的微小扰动 Δ X l , c \Delta \mathbf{X}_{l,c} ΔXl,c 对动作的影响可以用 Jacobian 矩阵线性近似:
∥ Δ A ∥ ≈ ∥ J A , X l , c ∥ ⋅ ∥ Δ X l , c ∥ \|\Delta \mathcal{A}\| \approx \|J_{\mathcal{A}, \mathbf{X}_{l,c}}\| \cdot \|\Delta \mathbf{X}_{l,c}\| ∥ΔA∥≈∥JA,Xl,c∥⋅∥ΔXl,c∥
其中量化引入的扰动为 Δ X l , c ≈ ( Q ( W l ) − W l ) X l \Delta \mathbf{X}_{l,c} \approx (Q(\mathbf{W}_l) - \mathbf{W}_l) \mathbf{X}_l ΔXl,c≈(Q(Wl)−Wl)Xl,即量化误差乘以输入。在实现中,这个代理指标通过 Hessian 矩阵的对角线来高效计算。代码中的 _HessianProxy 类完成了这一过程:
# 文件:qvla/sensitivity_hessian_proxy.py
@dataclass
class _HessianProxy:
layer: nn.Module
device: torch.device
def __post_init__(self) -> None:
W = self.layer.weight.data.clone()
if isinstance(self.layer, nn.Conv2d):
W = W.flatten(1)
self.rows = W.shape[0] # 输出通道数
self.columns = W.shape[1] # 输入维度
# 初始化输入协方差矩阵 H = X^T X
self.H = torch.zeros((self.columns, self.columns), device=self.device)
self.nsamples = 0
def add_batch(self, inp: torch.Tensor) -> None:
"""累积输入统计量,构建协方差矩阵"""
if len(inp.shape) == 2:
inp = inp.unsqueeze(0)
tmp = inp.shape[0]
if isinstance(self.layer, nn.Linear):
if len(inp.shape) == 3:
inp = inp.reshape((-1, inp.shape[-1]))
inp = inp.t()
# 增量更新协方差矩阵
self.H *= self.nsamples / (self.nsamples + tmp)
self.nsamples += tmp
inp = torch.sqrt(torch.tensor(2.0 / self.nsamples, device=inp.device)) * inp.float()
self.H += inp.matmul(inp.t())
def diag_hinv(self, percdamp: float = 0.01) -> torch.Tensor:
"""通过 Cholesky 分解计算 H^{-1} 的对角线"""
H = self.H
dead = torch.diag(H) == 0
H[dead, dead] = 1 # 处理死通道
damp = percdamp * torch.mean(torch.diag(H))
diag = torch.arange(self.columns, device=self.device)
H[diag, diag] += damp # 阻尼正则化
H = torch.linalg.cholesky(H) # Cholesky 分解
H = torch.cholesky_inverse(H) # 求逆
H = torch.linalg.cholesky(H, upper=True) # 上三角分解
return torch.diag(H)
这段代码的核心逻辑是:在校准数据上运行模型前向传播,通过 forward hook 截获每一层的输入张量,累积构建输入协方差矩阵 H = 1 n ∑ i x i x i T H = \frac{1}{n} \sum_i \mathbf{x}_i \mathbf{x}_i^T H=n1∑ixixiT。然后通过 Cholesky 分解高效求解 H − 1 H^{-1} H−1 的对角线,作为每个输入维度的"重要性权重"。
有了 Hessian 对角线之后,计算每个通道在不同位宽下的代理敏感度就很直接了:
def _compute_proxy_for_bits(layer, diag_hinv, bits):
W = layer.weight.data.clone().float()
if isinstance(layer, nn.Conv2d):
W = W.flatten(1)
d2 = (diag_hinv.float() ** 2).clamp_min(1e-12)
out = {}
for b in bits:
if b >= 16:
out[b] = torch.zeros(W.shape[0], device=W.device)
continue
# 对每个输出通道做对称量化
q = torch.stack([_quantize_row_sym(W[i], b) for i in range(W.shape[0])])
# 加权量化误差:(W - Q(W))^2 / diag(H^{-1})^2
loss = ((W - q) ** 2) / d2.unsqueeze(0)
out[b] = loss.sum(dim=1) # 每个输出通道一个标量
return out
这里的关键在于 loss = ((W - q) ** 2) / d2.unsqueeze(0) 这一行:量化误差 ( W − Q ( W ) ) 2 (W - Q(W))^2 (W−Q(W))2 被 Hessian 对角线的平方加权,使得那些输入激活值大的维度上的误差被放大——因为这些维度的扰动对输出的影响更大。最终,每个输出通道得到一个标量的代理敏感度分数,用于后续的比特分配。
4.2 贪心比特分配:在预算约束下最小化动作误差
有了每个通道在每个候选位宽 b ∈ { 0 , 2 , 4 , 8 , 16 } b \in \{0, 2, 4, 8, 16\} b∈{0,2,4,8,16} 下的敏感度分数,下一步就是在给定的平均比特预算 B ˉ \bar{B} Bˉ 下,为所有通道分配最优位宽。这是一个组合优化问题:
min { b l , c } ∑ l , c s l , c ( b l , c ) s.t. 1 N ∑ l , c b l , c ≤ B ˉ \min_{\{b_{l,c}\}} \sum_{l,c} s^{(b_{l,c})}_{l,c} \quad \text{s.t.} \quad \frac{1}{N} \sum_{l,c} b_{l,c} \leq \bar{B} {bl,c}minl,c∑sl,c(bl,c)s.t.N1l,c∑bl,c≤Bˉ
其中 N N N 是总通道数, b l , c = 0 b_{l,c} = 0 bl,c=0 意味着剪枝。这个问题是 NP-hard 的,QVLA 采用贪心降级(greedy demotion)算法来高效求解。
算法的核心思路非常直观:从所有通道都是 16-bit 全精度开始,每次找到"降级代价最小"的通道,将其位宽降低一档,直到满足预算约束。"降级代价"用敏感度-比特比(sensitivity-to-bit ratio)来衡量:
ρ l , c = s l , c ( b lo ) − s l , c ( b hi ) b hi − b lo \rho_{l,c} = \frac{s^{(b_{\text{lo}})}_{l,c} - s^{(b_{\text{hi}})}_{l,c}}{b_{\text{hi}} - b_{\text{lo}}} ρl,c=bhi−blosl,c(blo)−sl,c(bhi)
这个比值表示每节省一个 bit 所引入的边际误差增量。 ρ \rho ρ 越小,说明降级该通道的"性价比"越高——花最少的精度代价,省最多的存储。
代码实现使用了最小堆(min-heap)来高效维护候选降级操作的优先级:
# 文件:qvla/assign_gates_from_sensitivity.py
def greedy_allocate(proxies, bit_list, target_avg):
bit_list_desc = sorted(bit_list, reverse=True) # [16, 8, 4, 2, 0]
highest = bit_list_desc[0] # 16-bit
layer_bits = {}
total_bits = 0
n_ch = 0
heap = [] # 最小堆:(单位代价, 步骤ID, 层名, 通道索引, 目标位宽)
step_id = 0
def push_candidate(layer, idx, cur_bit):
"""将一个通道的下一级降级操作推入堆中"""
nb = next_lower_bit(cur_bit, bit_list_desc) # 找到下一个更低的位宽
if nb < 0:
return
saving = cur_bit - nb # 节省的比特数
cost = float(proxies[layer][nb][idx]) # 降级后的敏感度
unit_cost = cost / saving # 单位比特的边际代价
nonlocal step_id
heapq.heappush(heap, (unit_cost, step_id, layer, idx, nb))
step_id += 1
# 初始化:所有通道设为最高精度(16-bit)
for layer, v in proxies.items():
C = next(iter(v.values())).numel() # 通道数
layer_bits[layer] = [highest] * C
total_bits += highest * C
n_ch += C
for ci in range(C):
push_candidate(layer, ci, highest)
avg_bit = total_bits / max(1, n_ch)
# 贪心降级:每次弹出代价最小的操作,直到满足预算
while heap and avg_bit > target_avg:
unit_cost, _, layer, idx, nb = heapq.heappop(heap)
cur_bit = layer_bits[layer][idx]
if nb >= cur_bit:
continue
saving = cur_bit - nb
total_bits -= saving
layer_bits[layer][idx] = nb
avg_bit = total_bits / n_ch
push_candidate(layer, idx, nb) # 推入下一级降级候选
return layer_bits, stats
这个算法的时间复杂度为 O ( C log C ) \mathcal{O}(C \log C) O(ClogC),其中 C C C 是总通道数。它的优雅之处在于:通过一个统一的优先级队列,自动决定了哪些通道应该被保护(高敏感度, ρ \rho ρ 大,排在堆底),哪些通道应该被激进压缩甚至剪枝(低敏感度, ρ \rho ρ 小,最先被弹出)。最终输出的是一个 JSON 文件,记录了每一层每个通道的位宽分配方案。
4.3 权重伪量化注入:让每个通道"各得其所"
…详情请参照古月居

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 26
26 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)