
Video2Motion之GVHMR——基于重力-视角坐标的人体运动恢复:从RGB视频中提取人的SMPL轨迹(含人体姿态估计WHAM的详解)
本文系统介绍了三种3D人体姿态估计方法:WHAM、HaMeR和GVHMR。重点阐述了WHAM的架构设计,它通过结合ViTPose检测的2D关键点和图像特征,利用RNN编码运动上下文,实现从视频到SMPL参数的精确估计。文章详细解析了WHAM的两阶段训练策略:先在AMASS数据集预训练,再在真实视频数据上微调。同时介绍了WHAM的创新点,包括全局轨迹解码器设计和接触感知轨迹优化方案,有效解决了脚滑问
前言
本文一开始是属于《对人体建模之SMPL-X和AMASS数据集的详解:包含人形全身动捕系统的从零搭建、人体姿态估计WHAM(含手眼标定的详解)》中的部分内容
考虑到
- 一方面,把太多的内容扎堆到同一篇文章里,会使得对其中需要深入细致阐述的内容,则可能因为担忧篇幅过长 而珍惜笔墨,而对我个人而言 为了珍惜所谓的笔墨而丧失对重要内容的深入细致 阐述,在我看来 是不值得的
- 二方面,由于GVHMR在我解读的三篇具身论文中都出现过,本质上属于video-to-motion模型,即把视频转化为可用的 motion 数据
故我准备也解读下这个GVHMR
综上,WHAM、HaMeR拆分出来,和GVHMR(巧的是,GVHMR刚好和WHAM 有较大的相关性,能有如此巧合,可能跟我的研究直觉 有关?^_^ ) 放在同一篇文章 即本文之中
第一部分 人体姿态估计之 WHAM
1.1 WHAM的整体架构
根据arXiv的记录,此篇论文WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion的提交记录为[Submitted on 12 Dec 2023 (v1), last revised 18 Apr 2024 (this version, v2)],其对应的GitHub地址则为:yohanshin/WHAM
如下图所示,WHAM的输入是由可能具有未知运动的相机捕获的原始视频数据,接下来的目标是预测对应的SMPL模型参数序列
,以及在世界坐标系中表达的根方向
和平移
,具体做法是

- 使用ViTPose [54] 检测2D关键点
,从中使用Motion Encoder获得运动特征
- 此外,使用预训练的Image Encoder[7,21,25] 提取静态图像特征
,然后将这个图像特征与上面的运动特征
结合,以获得细粒度的运动特征
1.1.1 Motion Encoder and Decoder
对于 Motion Encoder and Decoder而言,与之前的方法使用固定时间窗口不同,这里使用RNN来作为运动编码器、运动解码器
- 运动编码器
的目标是基于当前和之前的2D 关键点(keypoints)和初始隐藏状态
而提取运动上下文
,即
过程中,We normalize keypoints to a bounding box around the person and concatenate the box’s center and scale to the keypoints,similar to CLIFF [ 25]. - 运动解码器
的作用是从运动特征历史中恢复:
SMPL参数
即
其中的如上面说过的,是图像特征与运动特征结合而成的细粒度运动特征
其中有一个关键点是咱们需要利用时间上的人体运动上下文,将2D关键点提升到3D网格,那如何做到呢,一个比较好的办法便是利用图像线索来增强这些2D关键点信息
具体而言,可以
- 先使用一个图像编码器,在人体网格恢复这个任务上做预训练,以提取图像特征
,这些特征包含与3D人体姿态和形状相关的密集视觉上下文信息
- 然后我们训练一个特征整合网络
,将
与
1.1.2 全局轨迹解码器Global Trajectory Decoder
作者团队还设计了一个额外的解码器,用于从运动特征
中预测粗略的全局根方向
和根速度
「We design an additional decoder, DT , to predict the rough global root orientation Γ(t)0 and root velocity v(t)0 from the motion feature ϕ(t)m」
但由于是从相机坐标系中的输入信号派生的,因此将人类和相机运动从中解耦是非常具有挑战性的。为了解决这种模糊性,我们将相机的角速度
,附加到运动特征
,创建一个与相机无关的运动上下文。 这种设计选择使WHAM兼容现成的SLAM算法 [46, 47] 和现代数字相机广泛提供的陀螺仪测量
再之后,使用单向RNN递归预测全局方向
1.1.3 通过脚是否触地:做接触感知轨迹的优化(Contact Aware Trajectory Refinement)
具体来说,新轨迹优化器旨在解决脚滑问题,并使WHAM能够很好地泛化到各种运动(包括爬楼梯),而这个新轨迹优化涉及两个阶段
首先,根据从运动解码器估计的脚-地面接触概率
,调整自我中心的根速度
以最小化脚滑
其中,是当接触概率
高于阈值时,脚趾和脚跟在世界坐标中的平均速度。 然而,当接触和姿态估计不准确时,这种速度调整往往会引入噪声平移
因此,我们提出了一种简单的学习机制,其中轨迹优化网络更新根部方向和速度以解决此问题。 最后,通过展开操作计算全局平移:
1.2 WHAM的两阶段训练:先AMASS上预训练,然后视频数据集上微调
分两个阶段进行训练:
- 使用合成数据进行预训练
- 使用真实数据进行微调
1.2.1 在AMASS上进行预训练
预训练阶段的目标是教会运动编码器从输入的2D关键点序列中提取运动上下文。 然后,运动和轨迹解码器将此运动上下文映射到相应的3D运动和全局轨迹空间(即它们将编码提升到3D)
作者使用AMASS数据集[32]生成由2D关键点序列和真实SMPL参数组成的大量合成对。为了从AMASS合成2D关键点,作者创建了虚拟摄像机,将从真实网格派生的3D关键点投影到这些摄像机上
与MotionBERT[62]和ProxyCap[61]使用静态摄像机进行关键点投影不同,我们采用了结合旋转和平移运动的动态摄像机。 这个选择有两个主要动机
- 首先,它考虑到了在静态和动态相机设置中捕捉到的人类运动的固有差异
- 其次,它使得能够学习与相机无关的运动表示,从中轨迹解码器可以重建全局轨迹
作者还通过噪声和掩蔽来增强2D数据
1.2.2 在视频数据集上微调
从预训练网络开始,作者在四个视频数据集上微调WHAM:
- 3DPW[49]
- Human3.6M [11]
- MPI-INF-3DHP [33]
- InstaVariety [15]
对于人类网格恢复任务,作者在AMASS和3DPW的真实SMPL参数、Human3.6M和MPI-INF-3D
HP的3D关键点以及InstaVariety的2D关键点上监督WHAM
对于全局轨迹估计任务,作者使用AMASS、Human3.6M和MPI-INF-3DHP
此外,在训练期间,作者尝试添加BEDLAM [1],这是一个具有真实视频和真实SMPL参数的大型合成数据集
微调有两个目标:1)使网络暴露于真实的2D关键点,而不是仅在合成数据上训练,2)训练特征整合网络以聚合运动和图像特征
为了实现这些目标,我们在视频数据集上联合训练整个网络,同时在预训练模块上设置较小的学习率
与之前的工作一致[6, 17, 30, 43, 52],我们采用预训练和固定权重的图像编码器[21]来提取图像特征。然而,为了利用最近的网络架构和训练策略,我们在以下部分中还尝试了不同类型的编码器[1, 7, 25]
以下是有关训练的部分细节
- 在预训练阶段,我们在AMASS上训练WHAM 80个周期,学习率为5 × 10−4。 然后我们在3DPW、MPI-INF-3DHP、Human3.6M和InstaVariety上微调WHAM 30个周期
- 在微调期间,对特征整合器使用的学习率为 1 × 10−4,对预训练组件使用的学习率为1×10−5。在训练期间,使用Adam优化器和批量大小
第二部分(选读) 手势估计HaMeR
Reconstructing Hands in 3D with Transformers在arXiv的提交记录为[Submitted on 8 Dec 2023]

// 待更
第三部分 GVHMR:基于重力-视角坐标的世界坐标系人体运动恢复
3.1 引言与相关工作
3.1.1 引言
如GVHMR原论文所说,基于世界坐标的人体运动恢复(HumanMotion Recovery,HMR)旨在在一个具有重力感知的世界坐标系中重建连续的三维人体运动
与在相机坐标系中捕获的传统运动数据不同 [Kanazawa et al.2018],基于世界坐标的运动天生更适合作为生成式和物理模型的基础数据——例如文本到动作生成 [Guo et al.2022; Tevet et al.2023] 以及仿人机器人模仿学习 [He et al.2024]
- 在这些应用中,运动序列必须在重力感知的世界坐标系中保持高质量与一致性
大多数现有的 HMR 方法都可以从视频中恢复较为理想的相机空间人体运动 [Kocabas et al.2020; Shen et al.2023; Wei etal.2022]
为了恢复全局运动,一个直接的做法是利用相机位姿[Teed et al.2024],将相机空间的运动变换到世界空间
————
然而,这样得到的结果并不被保证与重力方向对齐,但平移和姿态中的误差会随着时间积累,从而导致不合理的全局运动 - 近期工作即本文第一部分所介绍的WHAM [Shin et al.2024] 试图通过使用 RNN 自回归地预测相对全局姿态来恢复全局运动
尽管该方法取得了显著改进,但它需要良好的初始化,并且在长序列上会出现误差累积的问题,使得在重力方向上保持一致性变得具有挑战性
作者认为,对世界坐标系定义的歧义性。在给定世界坐标轴的情况下,围绕重力轴的任意旋转都可以定义一个合法的、感知重力的世界坐标系
在本研究中,作者提出了GVHMR方法
- 其对应的paper地址为:World-Grounded Human Motion Recovery via Gravity-View Coordinates,其Submitted on 10 Sep 2024
- 其对应的项目地址为:zju3dv.github.io/gvhmr
其对应的GitHub地址为:github.com/zju3dv/GVHMR
其用于在每一帧中估计感知重力的人体姿态,然后通过施加重力约束将各帧姿态组合起来,从而避免在重力方向上产生累积误差
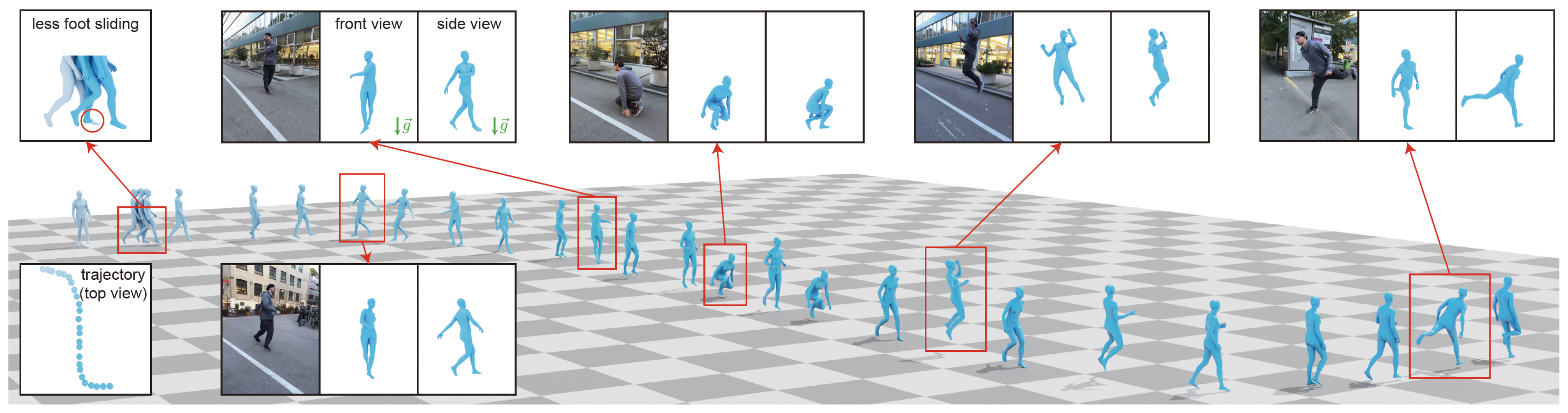
总之,给定一段真实场景中的单目视频,GVHMR能够在感知重力的世界坐标系中,精确回归“世界对齐的人体运动”:即 4D 人体姿态和形状。所提出的网络(不包括预处理:2D 人体跟踪、特征提取、相机相对旋转估计)在 RTX 4090 GPU 上处理一段 1430 帧的视频(约 45 秒)仅需 280 ms
该设计的动机源于这样一个观察:对于任意图像中的人物,人类都能够轻松推断出其感知重力的人体姿态,如图 2所示
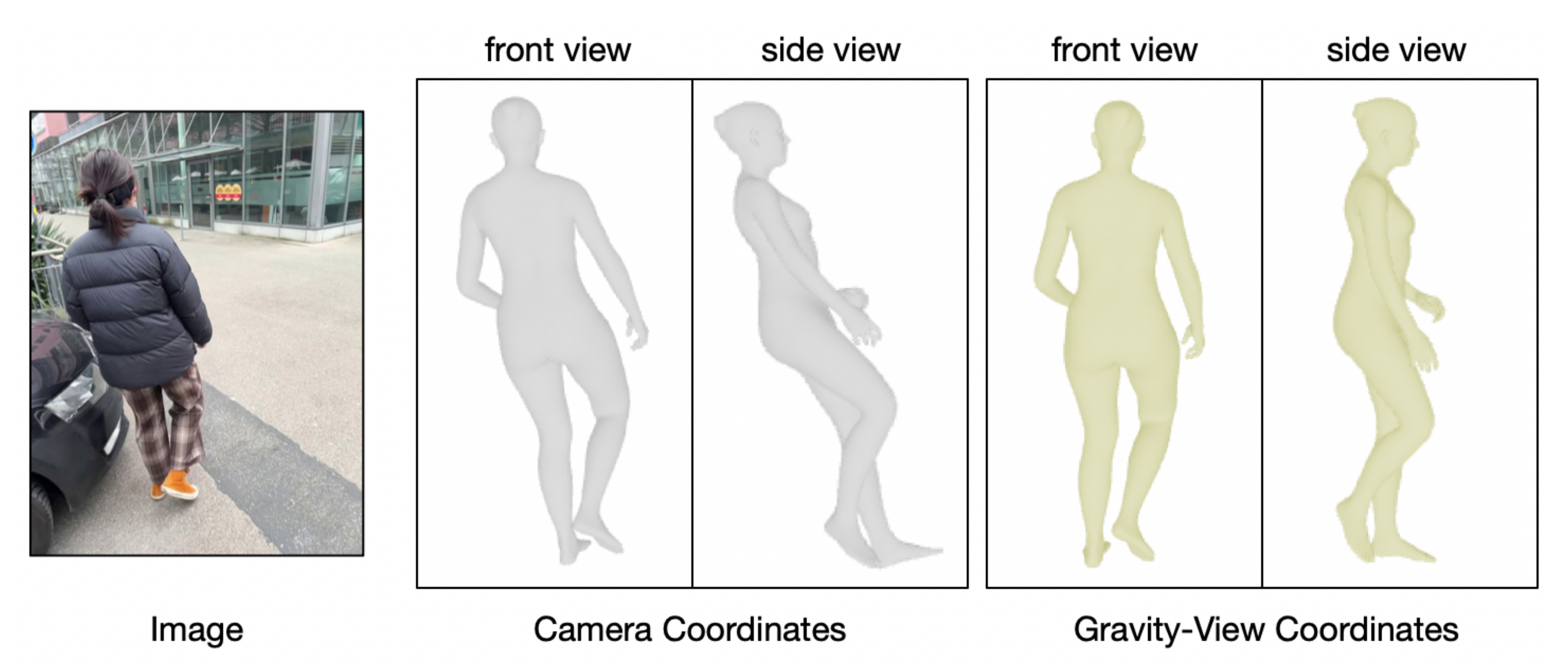
- 此外,对于给定的两个连续帧,相比于估计完整的 3 自由度旋转,直观上更容易估计围绕重力方向的1 自由度旋转
因此,作者提出了一种新的重力-视角(Gravity-View)坐标系,由重力方向和相机视角方向共同定义 - 基于 GV 坐标系,作者构建了一个网络,用于预测感知重力的人体朝向
同时,作者还提出了一种恢复算法,用于估计不同 GV 坐标系之间的相对旋转,从而将所有帧对齐到一个一致的、感知重力的世界坐标系中 - 得益于 GV 坐标,使得能够可以在时间维度上并行处理人体旋转
且作者提出了一种基于 transformer [Vaswani et al.2017] 的模型,并结合 Rotary Positional Embedding(RoPE) [Su et al. 2024],以直接回归整段运动序列
与常用的绝对位置编码相比,RoPE 能更好地捕获视频帧之间的相对关系,并且在处理长序列时更为有效
————
在推理阶段,作者引入一个掩码来限制每一帧的感受野,从而避免复杂的滑动窗口机制,并使得对无限长序列的并行推理成为可能
此外,作者还为手部和脚部预测静止标签,用于细化脚部滑动和全局轨迹
3.1.2 相关工作
第一,对于摄像机空间中的人体动作恢复
- 近年来,3D人体恢复的研究主要采用参数化人体模型,如SMPL [Loper等,2023;Pavlakos等,2019]。在给定单张图像或视频的情况下,目标是将人体网格与二维图像精确对齐
早期方法 [Bogo等,2016;Pavlakos等,2019] 采用基于优化的方法,通过最小化重投影误差来实现
最近,基于回归的方法 [Goel等,2023;Kanazawa等,2018] 在大量数据上进行训练,用于直接从输入图像中获取SMPL参数 - 为提升精度,研究者们进行了大量尝试,包括
专门设计的架构[Li等,2023;Zhang等,2023]
基于部件的推理[Kocabas等,2021a;Li等,2021]
以及引入相机参数[Kocabas等,2021b;Li等,2022b]
HMR2.0[Goel等,2023]设计了一种ViT架构[Vaswani等,2017],并在性能上优于以往方法 - 为利用时序线索,[Shi等,2020]采用深度网络直接从视频中预测骨架姿态序列
为恢复人体网格,大多数方法基于HMR流程
[Kanazawa等,2019]采用卷积编码器
[Choi等,2021;Kocabas等,2020;Luo等,2020]则成功应用了RNN
[Sun等,2019]将自注意力机制引入CNN
[Shen等,2023;Wan等,2021]采用transformer编码器提取时序信息
尽管这些方法能够准确估算人体姿态,但它们的预测结果均位于相机坐标系中。因此,当相机发生移动时,人体运动会变得物理上不合理
第二,基于世界坐标系的人体运动恢复
传统上,在考虑重力的世界坐标系中估算人体运动需要额外的地面平面校准或重力传感器。在多相机捕捉系统中[Huang等,2022;Ionescu等,2014],通常将标定板放置于地面以重建地面平面和全局尺度
- 基于IMU的方法[Kaufmann等,2023;von Marcard等,2018;Yi等,2021]则利用陀螺仪和加速度计来估算重力方向,并将人体运动投影到重力方向上
近年来,研究者们致力于从单目视频中估算全局人体运动
[Yu等,2021]利用物理定律重建人体运动,但需要提供场景信息
类似地,[Li等,2022a;Yuan等,2022]根据行走线索预测全局轨迹 - 然而,相机运动与人体运动存在耦合,导致结果较为噪声
SLAHMR [Ye等,2023] 和 PACE [Kocabas等,2024] 进一步将SLAM [Teed和Deng,2021;Teed等,2024] 与预训练的人体运动先验[Rempe等,2021]集成到优化框架中
尽管这些方法取得了有希望的结果,但优化过程耗时较长,并且在处理长视频序列时存在收敛性问题。此外,这些方法并未获得与重力方向对齐的人体运动
第三,最相关的工作是本文第一部分介绍的 WHAM [Shin 等,2024]
该方法以自回归方式直接回归每帧的姿态和位移。然而,他们的方法依赖于良好的初始化,并且在长时序动作恢复中,由于误差累积,性能会下降
此外,还有两项并行研究同样关注基于世界坐标的人体动作恢复
- WHAC [Yin 等人, 2024] 利用视觉里程计 [Teed 等人, 2024] 将相机坐标系下的结果转换到世界坐标系,并依赖另一网络对全局轨迹进行精细化
- TRAM [Wang 等人, 2024] 则采用 SLAM [Teed 和Deng, 2021] 恢复相机运动,并通过场景背景推导运动尺度
他们同样将相机坐标系下的结果转换为世界坐标系。与这些方法不同,GVHMR 无需额外的精细化网络,即可直接预测基于世界坐标的人体动作
3.2 GVHMR的完整方法论
给定一个单目视频,作者将该任务表述为预测:
- 局部身体姿态
,和SMPL-X 的形状系数
- 从SMPL 空间到相机空间的人体轨迹,包括朝向
和平移
- 到世界空间的轨迹,包括朝向
,和位移
如图3所示,提出的流程概览如下
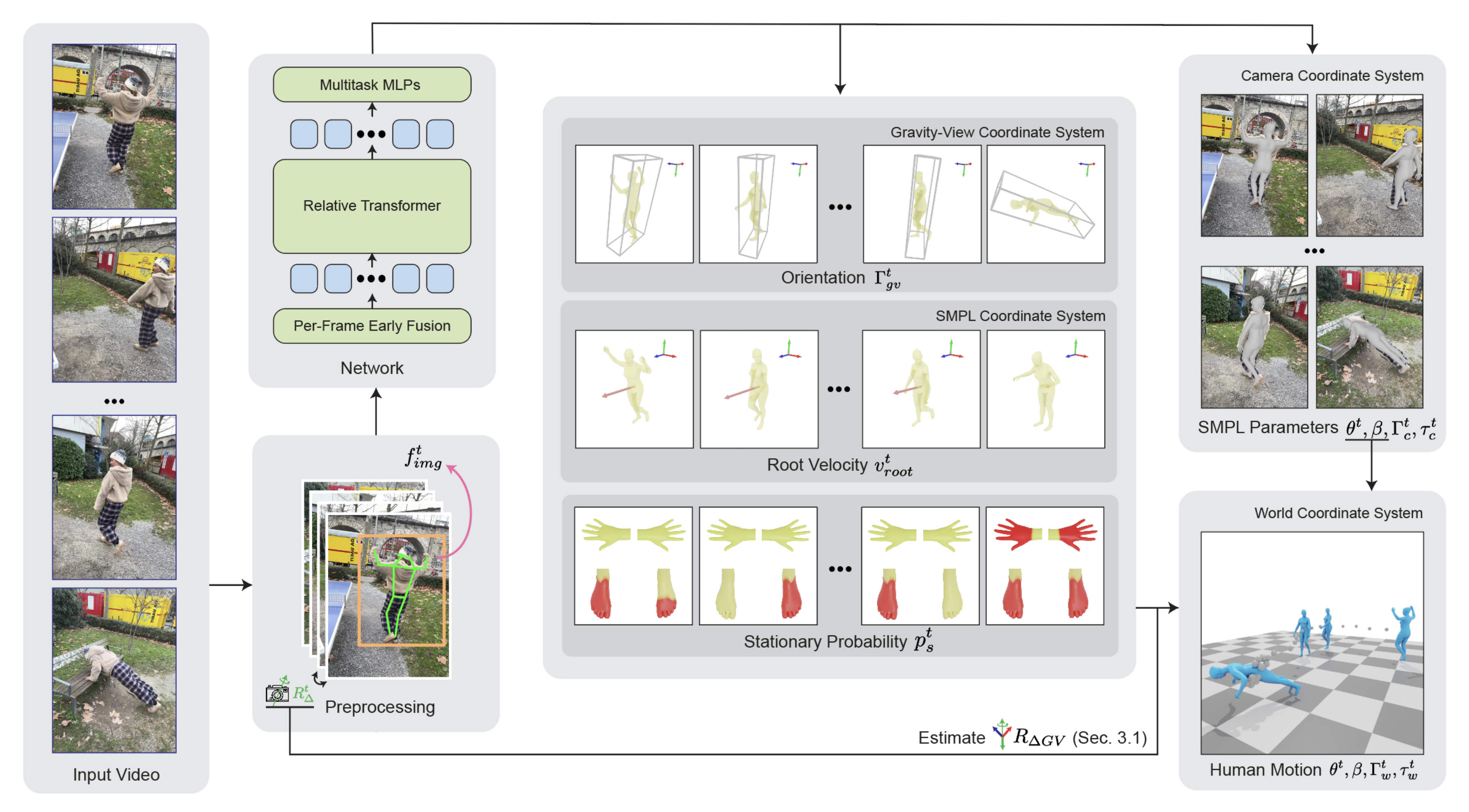
- 给定单目视频(左)
GVHMR 按照 WHAM [Shin et al. 2024] 的方式,对视频进行预处理:跟踪人体边界框、检测 2D 关键点、提取图像特征,并利用视觉里程计或陀螺仪估计相机的相对旋转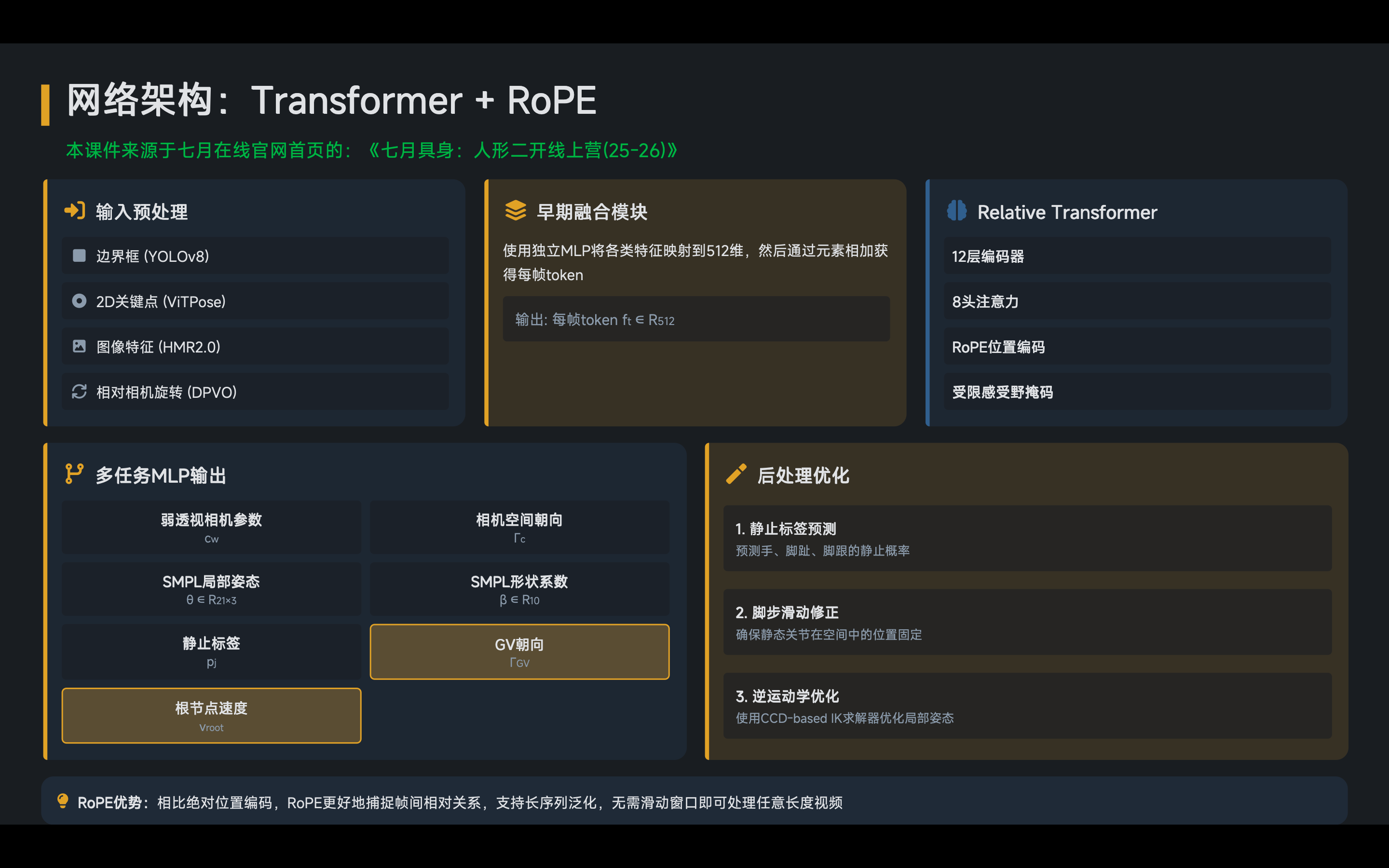
- 随后,GVHMR将这些特征融合为逐帧token,并通过相对Transformer与多任务MLP进行处理
输出包括:
1)中间表征(中间部分),即
重力-视角坐标系下的人体朝向-human orientation in the Gravity-View coordinate system
SMPL坐标系下的根部速度-root velocity in the SMPL coordinate system
以及预定义关节的静止概率-and the stationary probability for predefined joints
2)相机坐标系下的SMPL参数(右上) - 最后,如第1.2.1节所述,通过将这些中间表征转换到世界坐标系中,恢复出全局轨迹(右下)
接下来
- 在第1.2.1节中,将介绍全局轨迹表示,并讨论了其相较于以往轨迹表示的优势
- 接着,第1.2.2节描述了一种专门设计的网络结构以及用于目标预测的后处理技术
- 最后,第1.2.3节给出了实现细节
3.2.1 全局轨迹表示
如GVHMR原论文所述,全局人体轨迹指的是从 SMPL 空间到重力感知世界空间
的变换。然而,
的定义并不唯一,因为绕重力方向对
进行任意旋转都是有效的,这会导致不同的
和
作者提出,首先为每张图像恢复一个重力感知的人体姿态,然后将这些姿态转换为一致的全局轨迹。这一方法的灵感来源于这样一个观察:人类能够很容易地推断图像中人物的朝向和重力方向。而对于连续帧,估算绕重力方向的相对旋转在直观上更简单也更稳健
- 具体而言,对于每一张图像,作者利用世界重力方向和相机的视角方向(即图像平面的法向量)来定义重力-视角(GV)坐标系
所提出的新GV坐标系主要用于解决旋转歧义问题,因此作者仅预测每帧的人体朝向——相对于GV系统
- 当相机移动时,作者通过相机之间的相对旋转
来计算两个相邻帧的GV系统之间的相对旋转,从而将所有
对于全局平移,按照 [Rempe etal.2021; Shin et al.2024] 的方法,在 SMPL 坐标系中预测人体从时刻到
的位移,最终在前述的世界参考系中进行展开
对于重力-视图坐标系,具体而言,如图4所示
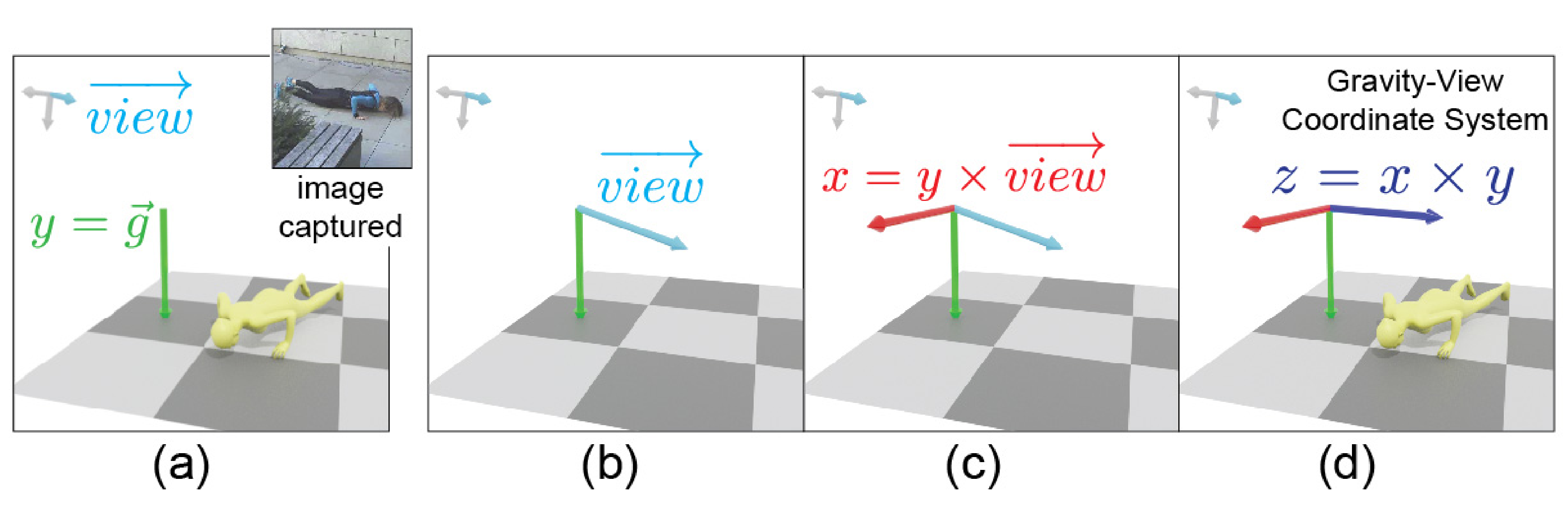
- a) 给定一个具有方向
的人体,以及一个在相机空间中以
描述的重力方向
- b)GV 坐标系的y 轴与重力方向−
- c)x 轴通过叉积法垂直于相机视线方向−−
和−
,即−
- d)最后,z 轴通过右手法则计算,即−
获得这些坐标轴后,作者可以重新计算人在GV 坐标系中的朝向,作为作者的学习目标:
恢复全局轨迹。值得注意的是,对于每个输入帧 ,都存在一个独立的
,其中作者预测了人的朝向
。为了恢复一致的全局轨迹
,所有朝向都必须被转换到一个统一的参考系中。实际上,作者使用
作为世界参考系
首先,在静态摄像机的特殊情况下,系统在所有帧中都是相同的。因此,人体全局朝向
等同于
。平移
通过使用朝向
将所有预测的局部速度
转换到世界坐标系下,并进行累加和得到:
// 待更

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)