
具身智能初学篇-task1
李飞飞认为,"看"是智能的基础,视觉理解是通往通用智能的关键路径。该模型将PaLM大语言模型与机器人视觉感知系统相融合,能够直接理解"把抽屉里的芯片拿出来放到盒子里"这样的复杂指令,并自主规划完整的动作序列来完成指令(Dadkhahi et al., 2023)。(Robotics Transformer 2)是DeepMind在2023年发布的重要工作,它是第一个能够直接从互联网规模的视觉-语言
一、机器人起源
1.1 人类对人造生命的追求
希腊神话中,赫菲斯托斯(Hephaestus)——希腊神话中的火神与工匠之神,用黄金打造了能够帮助他锻造金属的机械女仆。中国东汉科学家张衡发明的"木牛流马"被认为是最早的"自动机械"之一。
1738年,法国发明家雅克·德·沃康松(Jacques de Vaucanson)制作了一只能够活动翅膀、吃东西、排泄的"机械鸭",随后,瑞士的制表大师们更是制作出能够写字、绘画、弹奏乐器的"自动人偶",这些装置被收藏在欧洲各大宫廷中,成为当时科技与艺术完美结合的象征。
1.2 "Robot"一词的诞生
1920年,捷克作家卡雷尔·恰佩克(Karel Čapek)在他的科幻剧作《罗梭的万能工人》(Rossum's Universal Robots,简称R.U.R.)中,首次创造了"Robot"这个词。

1920年首演的《罗梭的万能工人》海报,卡雷尔·恰佩克创造了"Robot"一词
在捷克语中,"robota"意为"强制劳动"或"苦工",恰佩克用它来描述一种能够不知疲倦地为人类工作的"人造工人"。这部戏剧讲述了一个人造机器人反叛并消灭人类的故事,是最早对人工智能可能带来的风险进行深刻思考的文艺作品之一Robot"一词
"robotics"(机器人学)这个学科名称,则是由科幻大师艾萨克·阿西莫夫(Isaac Asimov)在1942年首次提出。
二、发展阶段
2.1 三次浪潮
1.第一代示教再现型机器人(1960s-1970s)
1961年,美国通用汽车公司在其新泽西工厂中,安装了世界上第一台工业机器人——尤尼梅特(Unimate)。由工程师约瑟夫·恩格尔伯格(Joseph Engelberger)发明,重达两吨,靠液压驱动,能够精确地完成焊接操作。尤尼梅特的诞生,标志着机器人正式进入工业生产领域。

1961年安装在通用汽车工厂的世界上第一台工业机器人尤尼梅特
这一代机器人的核心特征是"示教再现"——工人需要先手动操作机器人完成一遍任务,机器人会记住整个动作轨迹,然后可以无限次地重复执行。这种方式虽然开启了工业自动化的序幕,但缺点也很明显:无法应对复杂多变的环境,一旦产品型号变化,就需要重新示教。
2.第二代:感知型机器人(1980s-1990s)
1980年代,随着传感器技术的进步,机器人开始拥有"感知"世界的能力。这一代机器人配备了力觉传感器、触觉传感器甚至视觉传感器,能够根据环境变化调整自己的行为。
日本在这个时期成为全球最大的工业机器人生产国。发那科(Fanuc)、安川(Yaskawa)、松下(松下)等日本企业迅速崛起,成为工业机器人领域的巨头。1980年,也因此被业界称为"机器人元年"。
3.第三代:智能机器人(2000s-至今)
进入21世纪,人工智能技术的突破让机器人真正变得"智能"起来。2000年,日本本田公司展示了能够像人类一样行走、跑步、上下楼梯的阿西莫(ASIMO)机器人,这是世界上最早具备双足运动能力的人形机器人之一。2013年,波士顿动力公司(Boston Dynamics)的Atlas双足机器人首次公开亮相,它能够完成跳跃、翻滚、后空翻等高难度动作,刷新了人们对机器人运动能力的认知。
智元机器人(AGIBOT)于2023年由华为前高管创立,专注于通用人形机器人的研发。智元机器人致力于打造具有高度智能化的人形机器人平台,应用于工业制造、商业服务和家庭场景。
逐际动力(LimX Dynamics)是中国领先的足式机器人公司,在双足和多足机器人领域拥有深厚的技术积累。逐际动力发布的P系列双足机器人具备稳定的行走和奔跑能力,在复杂地形适应方面表现突出。
2.2国产机器人与Atlas的对比:
|
维度 |
波士顿动力Atlas |
中国人形机器人 |
|
驱动方式 |
液压驱动 |
电机驱动 |
|
运动能力 |
跑酷、后空翻 |
行走、奔跑 |
|
成本 |
百万级 |
十万级 |
|
应用场景 |
研究为主 |
商业化探索 |
|
产业链 |
美国 |
中国制造 |
总体来看,中国人形机器人在商业化落地和成本控制方面具有优势。
三、行业应用背景
工业制造——汽车行业的革命性变革
物流仓储——电商时代的幕后英雄
医疗健康——生命的守护者
四、机器人技术发展趋势
未来已来——这些趋势正在重塑机器人产业
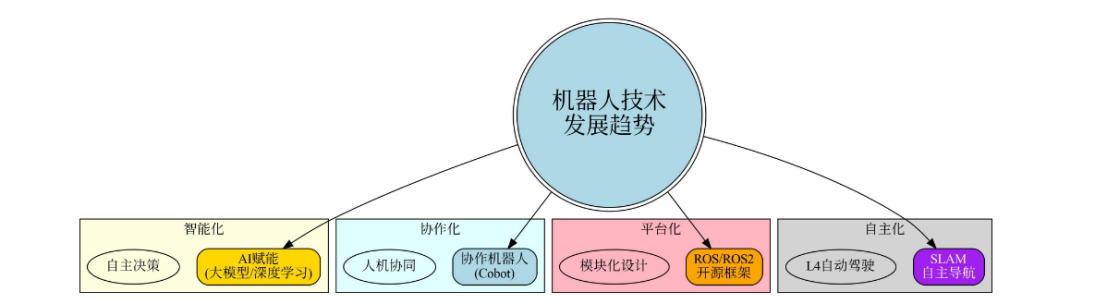
具身智能全景图
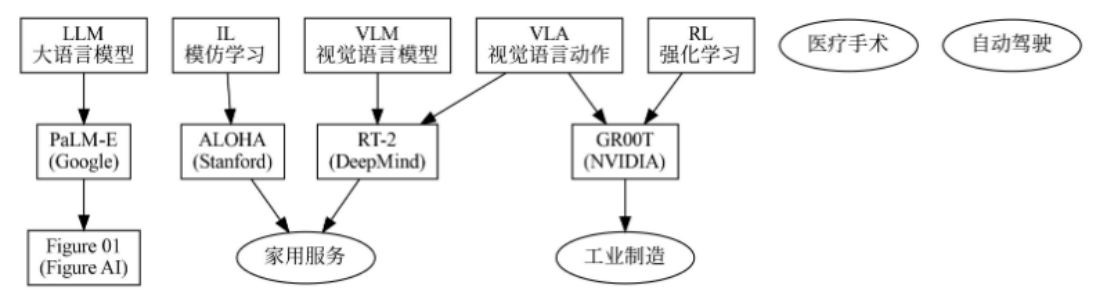
大语言模型(Large Language Model,简称LLM)
五、各种模型和方法在机器人中的应用
1.谷歌于2023年发布的PaLM-E模型是这一领域的里程碑式工作。该模型将PaLM大语言模型与机器人视觉感知系统相融合,能够直接理解"把抽屉里的芯片拿出来放到盒子里"这样的复杂指令,并自主规划完整的动作序列来完成指令(Dadkhahi et al., 2023)。PaLM-E展示了LLM在机器人任务规划中的巨大潜力。
2.SayCan(Ahn et al., 2022)则采用了一种更实用的方法,将LLM作为"大脑"与可学习的技能库相结合。LLM负责理解任务并选择合适的技能,而每个技能则由强化学习训练的子策略执行。这种模块化架构既保留了语言理解的灵活性,又保证了动作执行的可靠性。
3.Code as Policies(Liang et al., 2023)更进一步,提出用代码作为机器人的通用表示形式。LLM可以直接生成Python代码来控制机器人,这些代码能够调用感知API、执行器控制函数,甚至包含反馈循环来实现复杂行为。
4.PaLM-E模型理解自然语言指令并控制机器人执行任务
5.视觉语言模型(Vision-Language Model,简称VLM)则让机器人拥有了"眼睛"。VLM能够同时理解图像和文本信息,实现跨模态的推理和理解,这在机器人感知环境中发挥着至关重要的作用。
6.RT-2(Robotics Transformer 2)是DeepMind在2023年发布的重要工作,它是第一个能够直接从互联网规模的视觉-语言数据中学习泛化能力的机器人操作模型(Brohan et al., 2023)。RT-2将视觉输入和语言指令同时编码,通过Transformer架构直接输出机器人动作。
7.OK-Robot(Liu et al., 2024)专注于开放词汇物体抓取任务。该工作提出了一个简洁而有效的框架,能够在从未见过的环境中抓取任意物体。
8.Manipulate Anything(Song et al., 2024)则探索了在没有人类演示的情况下,如何让机器人通过视觉语言模型泛化操作技能。
9.视觉语言动作模型(Vision-Language-Action Model,简称VLA)是具身智能领域最前沿的研究方向之一。与VLM不同,VLA直接建立从视觉观察到动作输出的映射,实现端到端的学习和推理。
10.在RT-1的基础上,RT-2进一步引入了互联网规模的视觉语言预训练,使得模型具备了推理和泛化的能力(Brohan et al., 2023)。RT-2能够执行"把零食放到最近的人手里"这样的语义推理任务,展现了VLA在理解抽象概念方面的潜力。
VLA的核心优势在于其"端到端"特性:从感知到决策再到执行,整个过程在一个统一的神经网络中完成。这不仅简化了系统架构,更重要的是实现了全局优化。
11.强化学习在机器人控制中的应用
强化学习(Reinforcement Learning,简称RL)是让机器人通过与环境交互、自我试错来学习最优策略的方法。与传统的基于规则的编程不同,强化学习能够让机器人在未知环境中自主发现有效的行为模式。
2013年,DeepMind展示了Deep Q-Network(DQN)能够学习玩Atari游戏(Mnih et al., 2013),这一突破证明了深度强化学习在处理高维感知输入方面的潜力。
深度确定性策略梯度(DDPG)(Lillicrap et al., 2016)及其后续改进算法(如TD3、SAC)成为机器人运动控制的主流方法。
强化学习的核心挑战在于样本效率——机器人需要在真实环境中进行大量试错才能学到有效策略。为了解决这一问题,研究者们发展出了模拟到真实(Sim-to-Real)迁移技术。
12.模仿学习在机器人技能习得中的应用
模仿学习(Imitation Learning)是让机器人从人类演示中学习技能的方法。与强化学习相比,模仿学习更加直观——人类直接展示如何完成任务,机器人通过观察学习执行相同的行为。
行为克隆(Behavior Clone,BC)是最基础的模仿学习方法。机器人直接监督学习的方式,从演示数据中学习从状态到动作的映射。
为了解决分布偏移问题,DAgger(Ross et al., 2011)提出了迭代式的训练方法。该方法让机器人在执行过程中不断收集人类纠正数据,然后用这些数据重新训练策略。
斯坦福大学的ALOHA(Zhao et al., 2024)框架则将模仿学习推向了新的高度。ALOHA使用低成本的可穿戴设备记录人类操作的高精度演示数据,然后通过行为克隆训练机器人执行相同任务。
13.空间智能与3D理解
空间智能是指机器人理解3D空间关系的能力。这是实现通用具身智能的关键技术之一。
PointNet(Qi et al., 2017)是3D深度学习的里程碑工作,它能够直接处理点云数据,实现3D物体的分类和分割。
NVIDIA GR00T是2024年发布的通用机器人基础模型,旨在让机器人具备理解3D空间、执行复杂任务的能力。
李飞飞(Fei-Fei Li)是斯坦福大学教授、斯坦福AI Lab主任,她近年来大力推动"空间智能(Spatial Intelligence)"概念。2024年,李飞飞在多个场合强调:真正的智能不仅仅是语言理解,更重要的是理解3D空间。她领导的团队正在研究如何让AI系统像人类一样理解空间关系、进行物理推理。李飞飞认为,"看"是智能的基础,视觉理解是通往通用智能的关键路径。她的研究涵盖3D场景理解、神经渲染、具身智能等领域。
杨立昆(Yann LeCun)是图灵奖得主、Meta前AI首席科学家。2025年,杨立昆创立了新公司Advanced Machine Intelligence (AMI),筹集了超过10亿美元用于开发"世界模型"(World Models)。与当前的大语言模型不同,杨立昆认为真正的AI需要理解物理世界,需要具备常识和推理能力。他提出的JEPA(联合嵌入预测架构)是实现这一目标的关键路径。杨立昆多次公开表示:"现有的LLM无法实现通用人工智能,我们需要能够理解和预测物理世界的AI系统。"
两者的共识:尽管方法不同,李飞飞和杨立昆都认为空间理解是通往更高级智能的关键。李飞飞从视觉角度出发,杨立昆从世界模型角度出发,两者共同推动具身智能的发展。
六、思考
1.想一想:在你生活的周围,有哪些地方已经或将要使用机器人?它们属于哪一类机器人?
在酒店,送餐机器人、扫地机器人已经使用,属于家用型机器人。
2. 查一查:你最感兴趣的机器人公司或产品是什么?它们使用了哪些核心技术?
|
公司 |
代表机器人 |
特点 |
核心技术 |
|
波士顿动力 |
Atlas 人形机器人 |
动作超厉害,能跑、跳、后空翻 |
运动控制、平衡算法、力学控制 |
|
特斯拉 |
Optimus 擎天柱 |
适合家用、工厂,量产便宜 |
大模型、视觉 AI、电机控制 |
|
宇树科技(中国) |
H1 人形、Go2 四足 |
性价比高、动作灵活、国产优秀 |
自研电机、运动算法、足式机器人 |
最感兴趣的是宇树科技(Unitree),它是全球领先的足式与人形机器人公司,核心产品是Unitree H1、G1 人形机器人与Go2 四足机器人。
产品有:Unitree H1:1.8 米、55kg、34 自由度,可完成后空翻、高速奔跑等高动态动作。 • Unitree G1:127cm、35kg,起售价约 9.9 万元,主打教育与科研场景。 • Unitree Go2:消费级四足机器人,全球市占率超 70%,用于家庭陪伴与巡检。
核心技术有:
1. 硬件核心(机器人的 “肌肉与骨骼”)
- 自研高性能无框力矩电机:效率 92%、功率密度 3.2kW/kg,成本比进口低 60%。
- 力控灵巧手 + 力位混合控制:抓取精度接近人手,可完成精细操作。
- 高精度编码器:关节角度控制精度 ±0.05°,动态稳定性强。
2. 运动控制(机器人的 “小脑”)
- 模型预测控制(MPC)算法:实时优化全身运动轨迹,复杂地形稳定性强。
- 全身动力学控制:实现双足 / 四足稳定行走、跳跃、攀爬,台阶落地误差≤2mm。
- 高动态运动规划:支持后空翻、360° 旋转等高难度动作。
3. 感知系统(机器人的 “眼睛”)
- 双目 3D 相机 + 激光雷达融合:200 米测距、高密度点云,实现环境 3D 建模与避障。
- 多传感器融合:视觉、力觉、IMU 协同,提升复杂场景感知可靠性。
4. 智能决策(机器人的 “大脑”)
- 具身智能大模型:将视觉、语言、动作统一建模,支持自然语言指令执行。
- 模仿学习 + 强化学习:通过人类示范与自主试错快速掌握新技能。
- 端到端 VLA 模型:直接从图像 + 文本生成机器人动作序列。
3.议一议:具身智能的发展可能带来哪些伦理问题?人类应该如何应对?具身智能可能带来的伦理问题
- 机器人失控或被攻击,会带来安全隐患。
- 收集大量个人信息,容易侵犯隐私。
- 机器人伤人、出错,责任难以界定。
- 人们过度依赖机器人,人际关系变冷淡。
人类的应对措施
- 制定相关法律,明确责任与安全规范。
- 加强安全监管,防止机器人失控。
- 严格保护个人隐私
- 人们不断学习新技能,适应新时代。
- 合理使用机器人,不过度依赖。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)