
【小白】一文读懂CLIP图文多模态模型:零样本学习新范式,小白也能上手的收藏教程
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别,并且在计算效率更高的同时优于公开可用的最佳ImageNet模型。该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学
CLIP是由OpenAI开发的多模态预训练模型,通过学习图像与文本的对应关系实现零样本学习。模型包含图像编码器(ResNet或ViT)和文本编码器(Transformer),通过计算余弦相似度进行图文匹配。CLIP使用4亿对互联网图文数据集(WIT)进行预训练,采用对比学习预测图文对,仅需预测哪些文本与图像匹配而非具体单词。这种设计使CLIP在图像分类、检索等任务中表现出色,无需特定领域微调即可适应新任务。
目录
简介
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别,并且在计算效率更高的同时优于公开可用的最佳ImageNet模型。
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
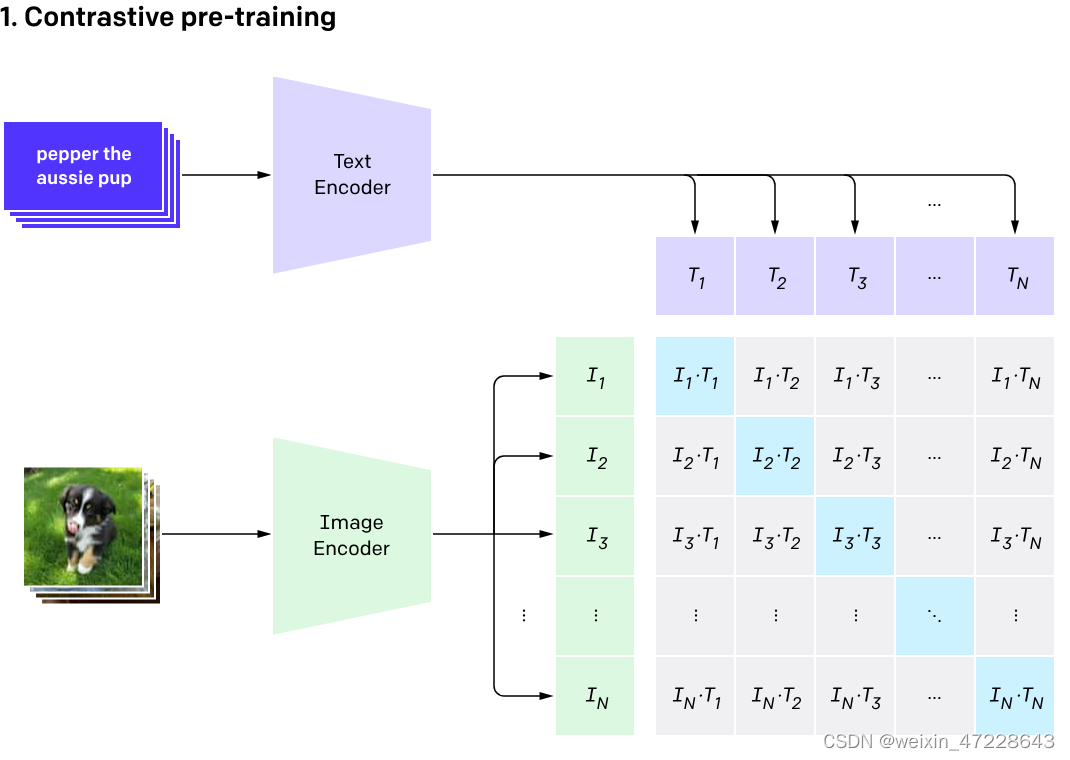
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
论文:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf
1.网络模型结构
1.1图像编码器Image Encoder
图像编码器有两种架构,一种是使用ResNet50 作为基础架构,并在此基础上根据ResNetD的改进和抗锯齿rect-2模糊池对原始版本进行了修改。同时,还将全局平均池化层替换为注意力池化机制。注意力池化机制通过一个单层的“transformer式”多头QKV注意力,其中查询query是基于图像的全局平均池表示。
第二个架构使用最近引入的Vision Transformer(ViT)进行实验。只进行了小修改,即 在transformer之前对 combined patch 和 position embeddings添加了额外的层归一化,并使用稍微不同的初始化方案。ViT模型结构如下图。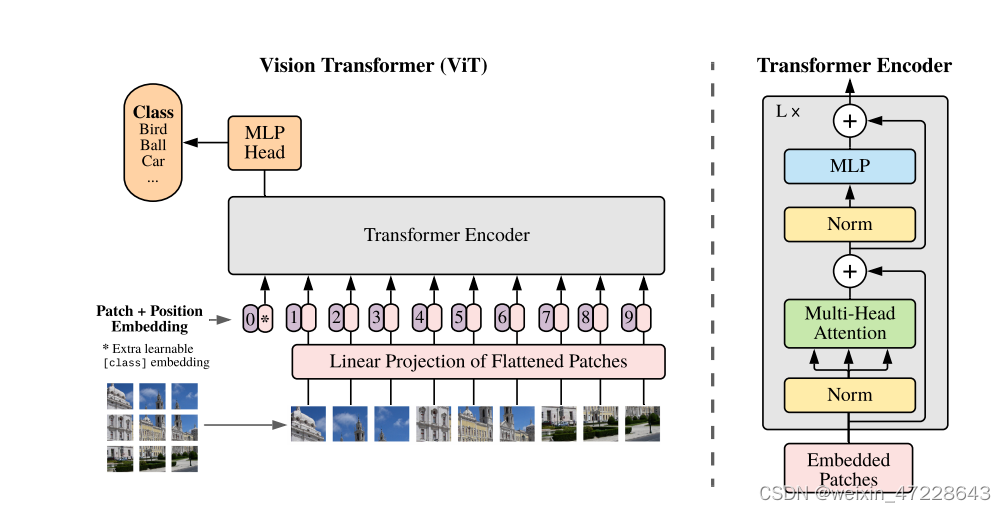
同时,ViT模型引入了多头注意机制,投影n次,dk=dv=dmodel/h,每个投影上并行计算,提高了计算效率。
1.2 文本编辑器Text Encoder
文本编辑器是Transformer架构,如下图所示,并在此基础上根据Radford模型进行了架构修改。作为基础尺寸,文章使用12层512宽的模型,有8个注意头。transformer执行对文本的小写字节对编码(BPE)的表示。
文本序列用**[SOS]和[EOS]**令牌括起来,[EOS]令牌上transformer最高层的激活函数(层归一化)被用作文本的特征表示,然后线性投影到多模态嵌入空间中。在文本编码器中使用了隐藏的自注意,以保留添加语言模型作为辅助目标的能力。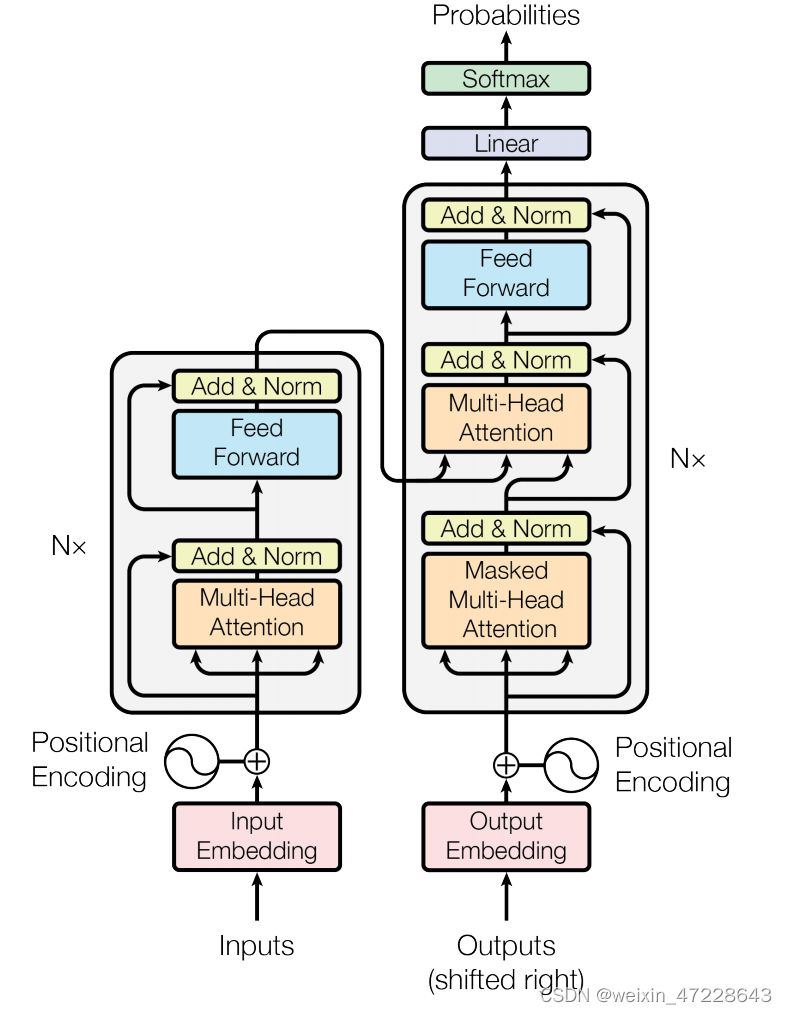
2.方法
工作的核心是从与图像配对的自然语言中包含的监督中学习感知的想法。
2.1构造数据集
现有工作主要使用MS-COCO 、Visual Genome 和YFCC100M三个数据集。虽然MS-COCO和Visual Genome是高质量的人群标记数据集,但按照现代标准,它们的规模很小,每个数据集大约有10万张训练照片。相比之下,其他计算机视觉系统在多达35亿张照片上进行了训练。
文章构建了一个新的数据集,其中包含4亿对(图像、文本),这些数据集来自互联网上各种公开可用的资源。为了尝试覆盖尽可能广泛的视觉概念集,文中将搜索(图像,文本)对作为构建过程的一部分,其文本包含500,000个查询集中的一个。
通过每个查询包含多达20,000对(图像、文本)来近似地平衡结果。结果数据集的总字数与用于训练GPT-2的WebText数据集相似。将此数据集称为WebImageText的WIT。
2.2 选择有效的预训练方法
文章探索了训练一个系统来解决潜在的更容易的代理任务,即只预测哪个文本作为一个整体与哪个图像配对,而不是该文本的确切单词。
给定一批N(图像、文本)对,CLIP被训练来预测N × N个可能的图像文本对中哪一个实际发生。为此,CLIP通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批处理中N对真实对的图像和文本嵌入的余弦相似度,同时最小化N2−N对错误对的嵌入的余弦相似度。在这些相似性得分上优化对称交叉熵损失。
下图,包含了CLIP实现核心的伪代码。这种批量构建技术和目标最初是作为多类n对损失引入的,最近被Zhang等人(2020)应用于医学成像领域的对比(文本、图像)表示学习。

文章从头开始训练CLIP,而不是用预训练的权重初始化。去掉了表示和对比嵌入空间之间的非线性投影,只使用一个线性投影从每个编码器的表示映射到多模态嵌入空间。
文章还删除了文本转换函数tu,该函数从文本中均匀采样单个句子,因为CLIP的预训练数据集中的许多(图像,文本)对只是单个句子;还简化了图像变换函数tv,从调整大小的图像中随机裁剪是训练期间使用的唯一数据增强。
最后,控制softmax中对数范围的温度参数τ在训练过程中被直接优化为对数参数化的乘法标量,以避免变成超参数。
2.3 模型训练思路
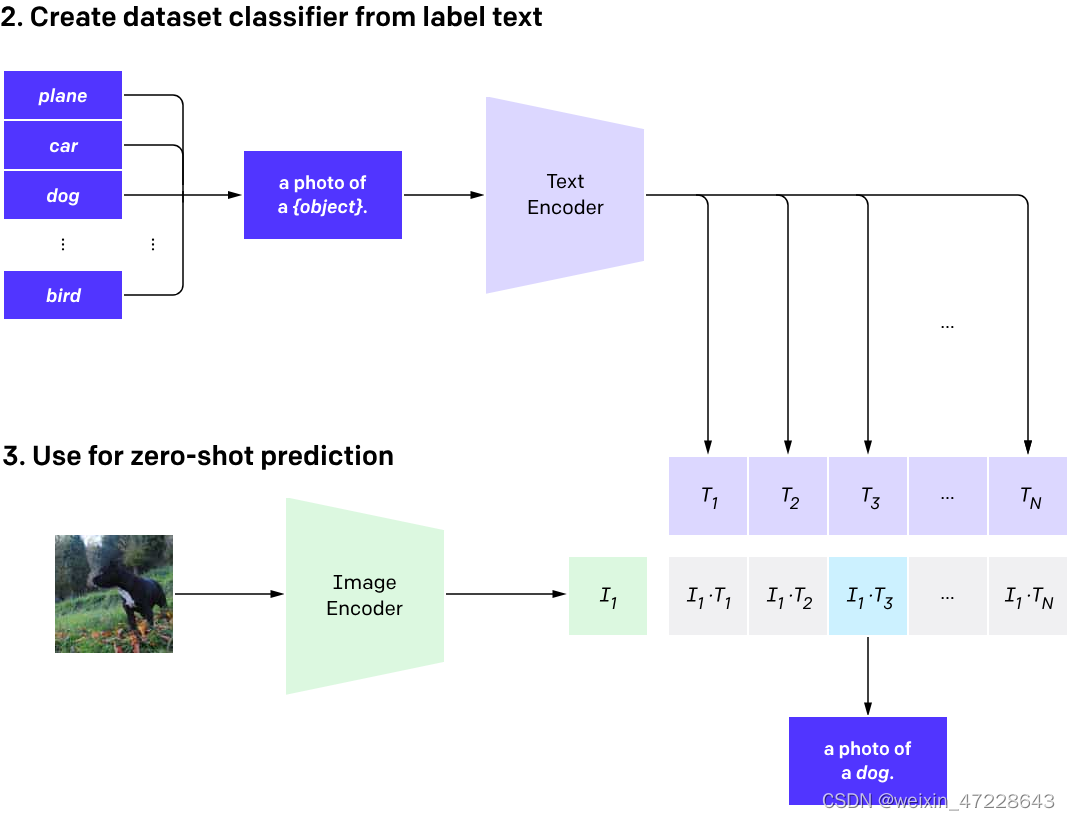
CLIP预训练图像编码器和文本编码器,以预测数据集中哪些图像与哪些文本配对。然后,使用这种行为将CLIP转换为zero-shot分类器。将数据集的所有类转换为文本,例如“一张狗的照片”,并预测CLIP估计的标题类与给定图像的最佳配对。
模型中使用visual_embedding 叉乘 text_embedding,得到一个[N, N]的矩阵,那么对角线上的值便是成对特征内积得到的,如果visual_embedding和对应的text_embedding越相似,那么它的值便越大。
选取[N, N]矩阵中的第一行,代表第1个图片与N个文本的相似程度,其中第1个文本是正样本,将这一行的标签设置为1,那么就可以使用交叉熵进行训练,尽量把第1个图片和第一个文本的内积变得更大,那么它们就越相似。
[交叉熵]:一种用于衡量两个概率分布之间差异的度量方式。其定义为
H
(
P
,
Q
)
−
∑
x
P
(
x
)
log
(
Q
(
x
)
)
H(P,Q)= -\sum_{x} P(x) \log(Q(x))
H(P,Q)=−x∑P(x)log(Q(x)),其中P(x)为实际概率分布,Q(x)为预测概率分布。
参考
(
Q
(
x
)
)
H(P,Q)= -\sum_{x} P(x) \log(Q(x))
H(P,Q)=−x∑P(x)log(Q(x)),其中P(x)为实际概率分布,Q(x)为预测概率分布。
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)