
【缺失多模态】【论文翻译】Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Ap
摘要——多模态网络比单模态网络表现出显著的性能改进。现有的多模态网络是以多分支方式设计的,由于对融合策略的依赖,如果缺少一个或多个模态,则表现出恶化的性能。在这项工作中,我们提出了一种模态不变的多模态学习方法,它不太容易受到缺失模态的影响。它由跨多个模态共享权重的单分支网络组成,以学习模态间表示,从而最大化性能以及对缺失模态的鲁棒性。在四个具有挑战性的数据集上进行了广泛的实验,包括文本视觉(UPM
处理缺失模态的模态不变多模态学习:一种单分支方法
arxiv 2024
论文链接
0.论文摘要和信息
摘要
摘要——多模态网络比单模态网络表现出显著的性能改进。现有的多模态网络是以多分支方式设计的,由于对融合策略的依赖,如果缺少一个或多个模态,则表现出恶化的性能。在这项工作中,我们提出了一种模态不变的多模态学习方法,它不太容易受到缺失模态的影响。它由跨多个模态共享权重的单分支网络组成,以学习模态间表示,从而最大化性能以及对缺失模态的鲁棒性。在四个具有挑战性的数据集上进行了广泛的实验,包括文本视觉(UPMC Food-101, Hateful Memes, Ferramenta)和视听模态(VoxCeleb1)。与现有的最先进的方法相比,我们提出的方法在所有模态都存在时以及在训练或测试期间缺少模态的情况下实现了优异的性能。
1.引言
包括文本、图像、视频和音频的多种模态通常包含关于共同主题的补充信息[4]、[5]、[6]。这些模态的不同组合已经被广泛研究,以解决各种任务,如多模态分类[7]、跨模态检索[8]、[9]、跨模态验证[10]、多模态命名实体识别[11]、视觉问答[12]、图像字幕[13]、多模态情感分析[14]和多模态机器翻译[15]。由于各种模态的结构和表示的差异,多模态建模具有挑战性[4]。现有的多模态方法通常使用基于神经网络的映射来学习多模态的联合表示。例如,利用单独的独立网络来提取每个模态的嵌入,以学习多分支网络[16]、[8]、[17]、[10]、[18]、[19]、[20]中的联合表示。类似地,一些最近的多模态方法利用Transformers来学习使用多分支的联合表示网络[21],[22]。在这些方法中,多分支网络的模块化性质是开发各种多模态应用的关键,并且已经证明了优于单模态方法的显著性能。然而,这些方法的局限性在于它们需要训练数据中的完整模态来展示良好的测试性能。
由于缺少模态,从现实世界收集的多模态数据通常是不完美的,导致现有模型的性能显著恶化[23]、[24]、[25]、[26]、[27]、[28]、[29]。例如,如表I所示,基于多模态Transformer model的模型ViLT[2]显示,当在测试时缺少70%的文本模态时,性能下降了28.3%。这种恶化的性能使得多模态学习对于可能遇到缺失模态的真实世界场景无效。性能的下降可能归因于实现用于模态交互的融合层的常用多分支设计(图1(a)-(c))。这种设计可以以性能高度依赖于输入模态的正确组合的方式学习权重[21],[2]。

表I:在不同训练和测试设置下,SRMM与ViLT[2]在UPMC Food-101[3]数据集上的比较。 ∆ ↓ ∆ ↓ ∆↓表示由于测试时缺少模态而导致的性能恶化。 ∆ ↓ = ( P c o m p l e t e − P m i s s i n g ) / P c o m p l e t e ∆ ↓ = (P_{complete} − P_{missing})/P_{complete} ∆↓=(Pcomplete−Pmissing)/Pcomplete,其中 P c o m p l e t e P_{complete} Pcomplete和 P m i s s i n g P_{missing} Pmissing是对完整和缺失模态的性能。每个设置中的最佳结果以粗体显示。
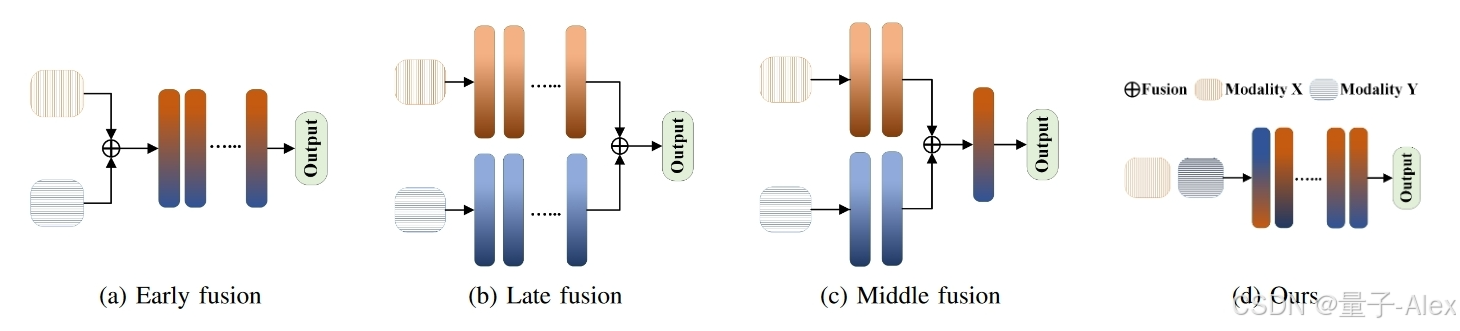
图1:常用的多分支网络的图示。这些方法从模态X和Y的嵌入中学习具有融合机制(早期、晚期或中期)的联合表示[1]。相比之下,我们提出的模态不变量方法仅利用一个分支来学习相似的表示。
在这项工作中,我们通过假设学习不同模态的共享表示能够实现公共连续表示空间[30]、[31]、[32]、[33]来解决对缺失模态的鲁棒性问题。在缺少模态的情况下,这种模态间表示可能是有益的。受此启发,我们提出了对缺失模态鲁棒的单分支方法(SRMM),该方法利用单分支网络中多个模态之间的权重共享来实现模态间表示的学习(图1d)。SRMM利用每个模态的预训练嵌入,并使用模态切换机制学习联合表示来执行训练。它在几个多模态数据集上优于最先进的(SOTA)方法,并在训练和测试期间表现出对缺失模态的卓越鲁棒性。例如,如表I所示,与现有的多模态SOTA方法ViLT[2]相比,当图像和文本模态在UPMC Food-101[3]上完全可用时,SRMM的分类准确率为91.9%。在相同的设置下,我们的方法优于ViLT,实现了94.6%的准确率.在严重缺失模态的情况下(即,在测试期间只有30%的文本模态可用),ViLT证明了65.9%的准确性。相比之下,SRMM通过在只有30%的文本模态可用时实现84.9%的准确率来证明对缺失模态的实质性鲁棒性,这优于单模态性能。在用于评估我们的方法的其他多模态分类数据集中也观察到了类似的趋势(第IV-D节)。我们工作的主要贡献如下:
1)SRMM:一种多模态学习方法,在训练和测试过程中对缺失模态具有鲁棒性。
2)模态不变机制,能够在单分支网络中跨多个模态进行权重共享。
3)在具有挑战性的数据集上进行了广泛的实验,包括文本-视觉(UPMC Food-101[3]、Hateful Memes[34]和Ferramenta[35])和视听(Voxceleb1[36])模态。当存在完整的模态时,SRMM表现出SOTA性能。类似地,在缺少模态的情况下,与现有的SOTA方法相比,我们的方法表现出更好的鲁棒性。
与会议版本的区别:我们的单分支训练的初步版本发表在2023年声学、语音和信号处理国际会议上[37]。在初步版本中,我们提出了一个单分支网络,并使用跨模态验证和匹配将其与现有多分支网络在基准多模态学习任务上的性能进行了比较。目前的工作是会议论文的实质性扩展,特别侧重于证明单分支网络对缺失模态场景是稳健的。首先,我们通过利用四个具有挑战性的多模态数据集来探索单分支网络在多模态分类新任务上的鲁棒性。其次,我们将研究扩展到另一种模态对(文本-视觉),以研究单分支训练的一般适用性。第三,我们广泛地展示了单分支训练对缺失模态具有显著的鲁棒性。
2.相关工作
多模态学习的目标是利用跨多个模态的互补信息来提高各种机器学习任务(如分类、检索或验证)的性能。每个多模态任务都不同,而基本目标保持不变:学习跨多模态的联合表征[4]、[5]、[38]。现有的多模态方法采用多分支网络通过最小化不同模态之间的距离来学习联合表示[8]、[18]、[19]、[20]、[39]、[40]、[41]。这种使用多分支网络的方法已经取得了显著的性能[42]、[3]、[43]、[39]、[35]、[44]。然而,如果一些模态在测试时缺失,大多数多模态方法会遭受性能恶化,这个问题通常被称为缺失模态问题[45]、[46]、[47]、[48]。
考虑到多模态方法的重要性,近年来人们对处理缺失模态问题越来越感兴趣[24]、[25]、[27]、[28]、[48]、[49]、[50]、[51]。通常,解决该问题的现有多模态方法可以分为三类。第一类是输入屏蔽方法,其在训练时随机移除输入以模拟缺失的模态信息。比如Parthasarathy等人[52]引入了一种在训练期间随机移除视觉输入的策略,以模拟多模态情感的缺失模态场景识别任务。第二类利用可用的模态来生成缺失的模态[27],[53]。比如张等人[47]以可用的视觉模态为条件生成缺失的文本模态。第三类学习具有来自多个模态的相关信息的联合表示[54]。比如韩等人[55]学习了视听联合表征来提高单模态情感识别任务的性能,然而,它不能在测试时利用完整的模态信息。
与先前的方法相反,我们建议使用跨多个模态的权重共享的单分支网络来学习模态不变表示。与现有的SOTA方法相比,SRMM不仅表现出优异的多模态性能,而且表现出对缺失模态的显著鲁棒性。
3.方法
在本节中,我们将描述SRMM,这是一种对缺失模态具有鲁棒性的多模态学习方法。SRMM建立在直觉上,即使用模态特定网络提取的多个嵌入表示相似的概念,但在不同的表示空间中。使用单分支网络的权重共享使得能够学习这些概念的模态间表示。然后,当在推理时缺少模态时,模型从表示中受益。图2展示了我们的方法。在下一节中,我们将解释模态嵌入提取、单分支网络和用于训练网络的损失公式。
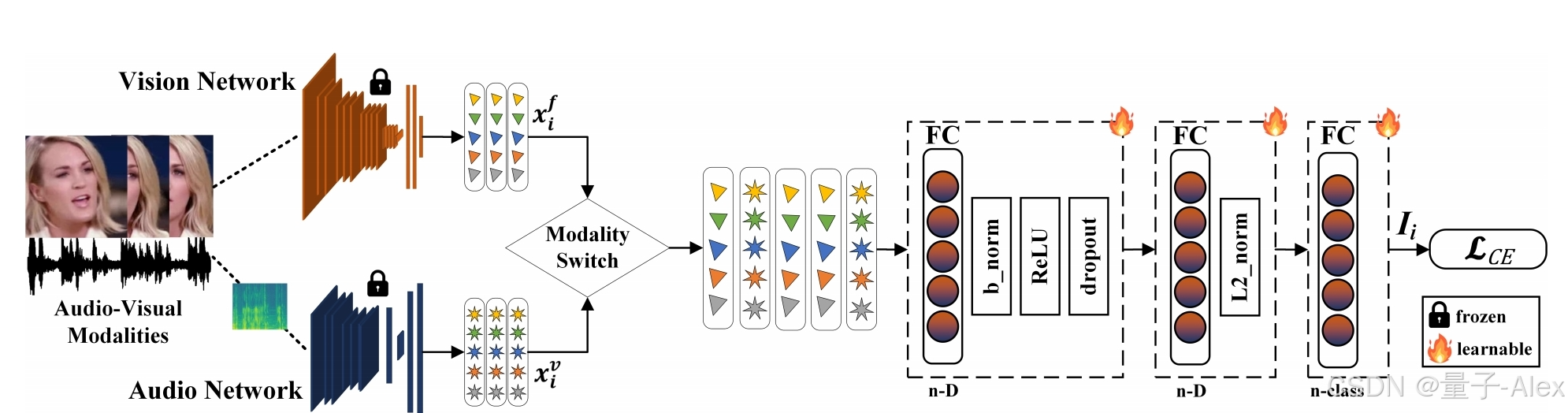
图2:SRMM的总体架构。特定于模态的预训练网络(给定示例中的视觉和音频网络)用于提取嵌入,所述嵌入通过模态切换机制并输入到我们的单分支网络,所述单分支网络学习模态独立表示,以编码跨多个模态的权重共享的模态间表示。
A.预备工作
给定 D = { ( M i 1 , M i 2 ) } i = 1 N \mathcal{D} = \{(M^1_i ,M^2_i )\}^N_{i=1} D={(Mi1,Mi2)}i=1N是训练集,其中 N N N是实例模态对 M i 1 M^1_i Mi1和 M i 2 M^2_i Mi2的数量。此外, x i M i 1 x^{M^1_i}_i xiMi1和 x i M i 2 x^{M^2_i}_i xiMi2分别是第 i i i个实例的单独模态嵌入。具体地,在视听情况下,各个模态嵌入被表示为 x i f x^f_i xif和 x i v x^v_i xiv。此外,每对 ( x i f , x i v ) (x^f_i , x^v_i) (xif,xiv)具有类别标签yi。多模态学习旨在将多个模态映射到一个共同但有区别的联合嵌入空间,在该空间中,它们充分对齐,并且来自同一类的实例在附近,而来自不同类的实例相距很远[4]。
局限性:典型的现有多模态方法通过使用以融合为中心的多分支网络(CMB)来执行分类任务,将多模态作为输入:
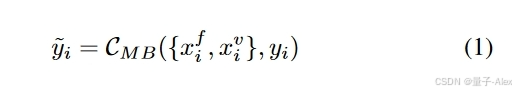
这种多分支配置需要模态完整的数据来执行给定的任务,缺失的模态会导致显著的性能下降[24]、[23]、[27]、[51]。
B. SRMM
动机
我们假设学习跨不同模态的共享表示能够实现公共连续表示空间。在缺少模态的情况下,这种模态间表示是有益的。因此,在我们的方法中,等式1采用以下形式:
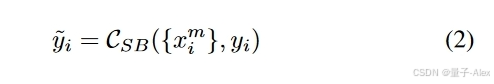
其中 x i m x^m_i xim可以是 x i f x^f_i xif或 x i v x^v_i xiv。将多个模态映射到公共但有区别的联合嵌入空间使模型能够学习对缺失模态鲁棒的表示,从而产生与融合无关的多模态网络。我们引入了一种模态切换机制来确定不同模态的嵌入输入到单分支的顺序。在我们的实验(第V-C节)中,不出所料,我们观察到当输入数据独立且同分布(IID)时,我们的方法表现最佳。然而,令人惊讶的是,模态切换的其他选择产生了相当的性能,证明了我们的方法通常对输入模态的顺序是鲁棒的。
单分支网络
SRMM的总体架构如图2所示。该网络包括三个块的单分支。第一个块由全连接(FC)层组成,随后是Batch Normalization (b范数)、ReLU和dropout层。第二块由FC层组成,随后是归一化(L2范数)层。第三块由FC层组成,其大小与特定数据集中的类的数量相同,后跟softmax。这些FC层的权重由以获得的顺序方式输入的不同模态嵌入共享从我们的模态切换机制。在测试时间,如果存在完整的模态,则通过取从所有模态的softmax层获得的对数的平均值来采用后期融合。在只有一种模态的情况下,不采用融合机制。
我们采用交叉熵损失进行训练。形式上,我们利用权重表示为 W = [ w 1 , w 2 , . . . , w C ] ∈ R d × C W = [w_1, w_2, . . . , w_C ] ∈ \mathbb{R}^{d×C} W=[w1,w2,...,wC]∈Rd×C的线性分类器来计算对应于 l i l_i li的对数,其中 C C C是类的数量, d d d是嵌入的维数。然后将损失计算为:
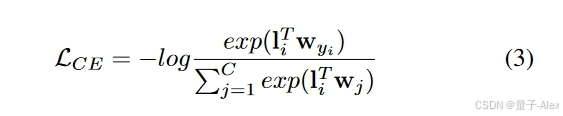
SRMM学习跨模态的模态间表征,将它们带入一个相似的潜在空间。这导致由两种模态补充的更丰富的表示,并且当模态之一缺失时产生鲁棒的模型。换句话说,当模态缺失时,可用模态使得能够使用来自共享模态间表示的多模态知识。
4.实验
我们使用四个数据集在多模态分类任务中评估SRMM,包括文本视觉模态,包括UPMC Food-101[3]、Hateful Memes[56]、Ferramenta[35]和基于Voxceleb1[36]的视听模态。我们在训练和测试期间使用各种设置进行实验,包括完整的模态和不同级别的缺失模态。此外,还进行了广泛的消融研究,以评估我们方法的不同设计选择。为了公平比较,我们采用了每个数据集的原作者和后续SOTA方法使用的相同评估指标,即分类精度和接收器工作特征下的面积(AUROC)。
A.数据集
最近,马等人[24]和李等人[28]引入了一种评估协议来研究训练和测试期间的缺失模态问题。为了进行比较,我们从[24]和[28]中选择了UPMC Food-101和Hateful Memes数据集。此外,我们选择了一个视听数据集(VoxCeleb1)来评估SRMM在其他模态上的一般适用性。最后,我们选择了一个广泛流行和具有挑战性的多模态数据集Ferramenta,它通过使用文本模态来解决视觉样本之间的模糊性。
UPMC Food-101
它是一个由文本和视觉模态组成的分类数据集。数据集是从web上抓取的,每个条目都由一个图像和找到它的HTML网页组成。该数据集包含90,704个图像-文本对和101个类,并以预定义的75/25训练/测试分割发布。
Hateful Memes
它是一个多模态数据集,包含作为两种模态的模态图像及其各自的文本内容,以及识别模态中仇恨言论存在的二进制标签。数据集包含10,000个模因。
Ferramenta
它由属于52个类别的88,010个文本-视觉对组成。数据分为66141个训练实例和2186个测试实例。
Voxceleb1
这是一个视听数据集,包含1251个说话者的人类语音视频,是从YouTube上“在野外”提取的。数据分为145,265个训练实例和8,251个测试实例。
图3示出了完整和缺失的视觉和音频模态的示例。
图3:(a)完整模态、(b)视觉缺失和©音频缺失设置的示例。
B.实现细节
网络设置
SRMM使用Adam optimizer训练,学习率为0.01,dropout为50%。网络具有FC层为:{输入dim,层dim,层dim,类数},其中输入dim对于视听为512,对于文本-视觉模态为768。此外,用于视听的层dim为2048,用于文本-视觉模态的层dim为768。
模态特定嵌入
我们采用特定于模态的网络来提取嵌入,如本节所述。第V-B节(表X)还提供了使用其他特定模态提取器的额外分析。然而,以下网络是我们默认的实验选择。
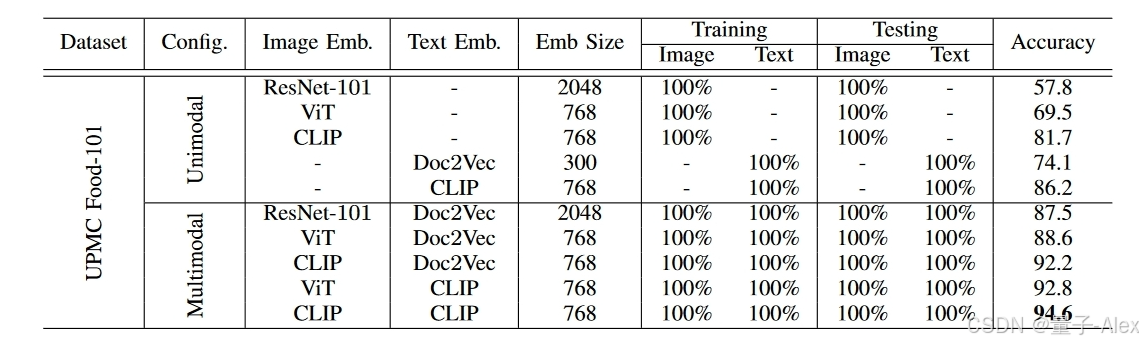
表X:SRMM与使用各种预训练模型提取的嵌入的性能比较。当使用CLIP作为图像和文本特征提取器时,可以获得最佳结果。
图像嵌入
我们使用对比语言-图像预训练(CLIP)提取图像嵌入[57]。输出嵌入的大小为768,与相应的文本模态匹配。
文本嵌入
我们从剪辑中提取文本嵌入。输出嵌入的大小被固定为768以匹配相应的图像模态。
面部嵌入
我们使用用triplet loss预训练的Inception-ResNet-V1[58]提取人脸嵌入[59]。输出嵌入的大小为512,其与相应的音频模态匹配。
音频嵌入
我们使用为具有VoxCeleb1[36]数据集的说话者识别任务训练的话语级聚合器[60]来提取音频嵌入。保持(512)输出嵌入的大小以匹配相应的面部嵌入。用固定大小的频谱图训练网络对应于从每个话语中随机提取的2.5秒时间段[60]。
C.完整模态设置下的评估
当在训练和测试期间存在完整的模态时,我们首先评估SRMM,并将结果与现有的SOTA方法进行比较。表II、III、IV和V给出了结果。SRMM在四分之三的数据集上实现了SOTA性能。更具体地说,在UPMC-Food101数据集(表II)上,我们的模型实现了94.6%的分类性能,优于所有现有方法。在Ferramenta和VoxCeleb1(表IV和V)数据集上,我们的模型分别达到了96.5%和98.0%的准确率,优于所有SOTA方法。只有在Hateful Memes数据集(表III)上,SRMM没有达到SOTA结果,但表现出了与除Vilio之外的几种方法相当的性能[41]。可以注意到,Vilio是一种集成方法,采用五个视觉和语言模型来实现所报道的AUROC,因此不能直接与基于使用单个系统进行推理的任何方法相比。
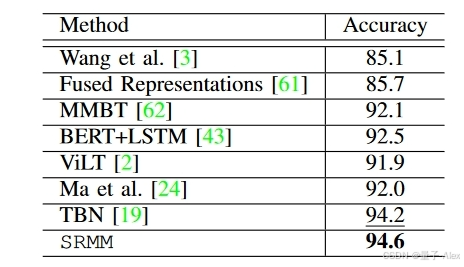
表II:SRMM与UPMC-Food-101上的最先进方法的比较。最佳结果以粗体显示;第二好的下划线。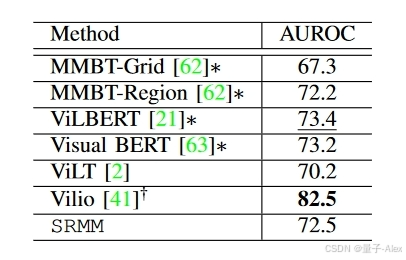
表三:SRMM与最先进的多模态方法在Hateful Memes上的比较。*表示Hateful Memes Challenge的结果[56]。 † † †五种不同视觉和语言模型的集合。最佳结果以粗体显示;第二好的下划线。
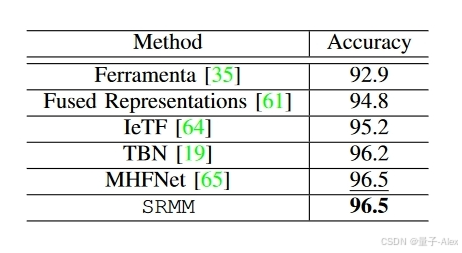
表四:SRMM与Ferramenta数据集上最先进的多模态方法的比较。
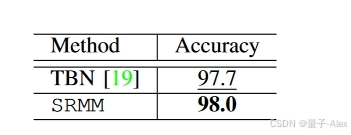
表V:SRMM与TBN在VoxCeleb1数据集上的比较。
D.缺失模态下的评估
测试期间缺失的模态
马等人[24]已经表明,多模态方法在测试时易受缺失模态的影响。SRMM旨在通过学习多模态表示来显示对缺失模态更好的鲁棒性。表VI将我们的方法与现有的SOTA方法进行了比较;ViLT[2],Ma等人[24],Kim等人[66]和双分支网络[19](TBN),用于UPMC食物-101和仇恨模因数据集上不同数量的缺失模态。在手稿中,我们将TBN视为我们提出的方法的基线网络,因为输入嵌入和损耗公式是相同的,而网络是可比较的。唯一的根本区别是TBN在多分支设计中有一个融合组件。为了提供广泛的分析,我们考虑了TBN的几种变体,包括早期、晚期和中期融合,如图1所示。我们观察到,早期融合的TBN(类似于FOP[19] )比晚期或中期融合的TBN表现略好。因此,为了避免冗余结果,我们在手稿中主要使用该网络作为SOTA比较的基线。总体而言,SRMM以相当大的优势优于所有现有的SOTA方法,包括TBN基线。在严重缺失文本模态的情况下(当只有10%可用时),在UPMC食品101数据集上,SRMM表现出83.3%的准确性。与此相比,具有早期融合的TBN、ViLT、Ma等人和Kim等人。分别表现出81.6%、58.4%、73.3%和74.7%的性能。类似地,在仇恨模因数据集上,当在测试时只有10%的文本模态可用时,SRMM表现出71.2%的AUROC。相比之下,具有早期融合的TBN、ViLT、Ma等人和Kim等人分别表现出59.7%、58.0%、59.6%和61.8%的性能。在Ferramenta和VoxCeleb1数据集上观察到类似的趋势,如表VII所示,其中提供了与具有早期融合的TBN的比较[19]。这证明了我们提出的对缺失模态鲁棒的多模态训练方法的重要性。我们的工作作为一个概念证明,鼓励研究人员在构建鲁棒的多模态方法时考虑模态不变学习。
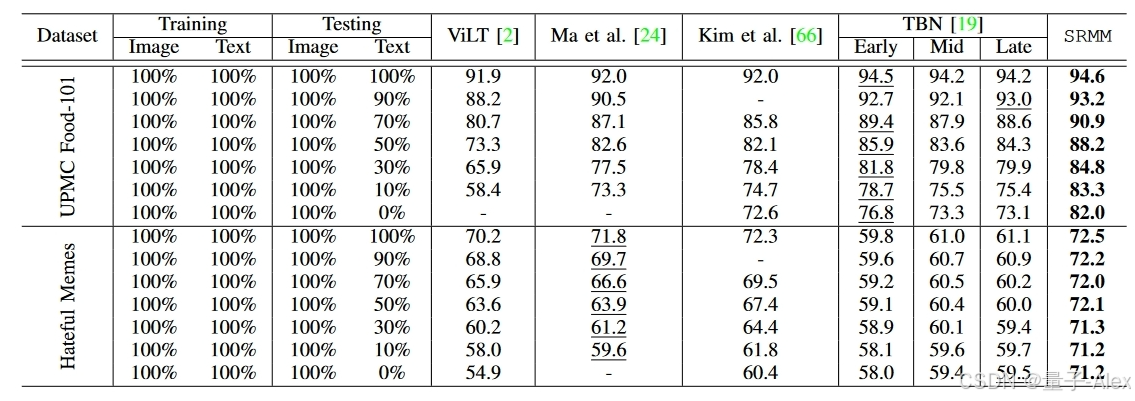
表VI:使用UPMC-Food-101和仇恨模因数据集在测试集中评估具有不同水平的可用模态的SRMM。提供了与ViLT[2]*、Ma等人的比较[24],金等人[66]和TBN[19]。*ViLT值取自[24]。分别报告了Hateful Memes和UPMC-Food-101的AUROC和准确性。粗体和下划线分别表示最佳和次佳结果。
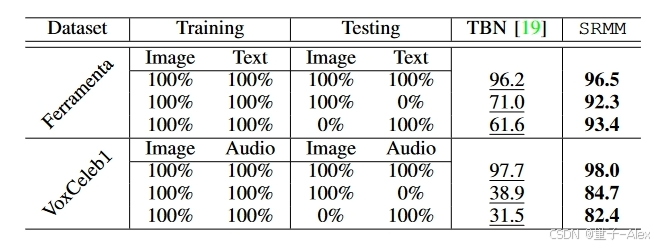
表VII:使用Ferramenta和VoxCeleb1数据集的测试集中100%缺失模态配置SRMM的分类准确性。将我们的方法与TBN[19]进行比较,以了解我们的单分支设计的重要性。最佳结果以粗体打印。
训练期间缺失的模态
最近,Lee等人[28]通过在训练和测试期间引入缺失模态的场景扩展了评估协议,即在训练和测试时,一种模态的30%可用,而另一种模态的100%可用。表VIII将我们的方法与现有的SOTA方法进行了比较,包括ViLT[2]、Lee等人[28]关于UPMC Food-101和Hateful Memes数据集。在大多数场景中,SRMM表现出比现有方法更好的性能。由于SRMM没有以融合为中心的多分支设计,因此在训练和测试期间不需要模态完整数据,从而展示了对缺失模态场景的弹性。
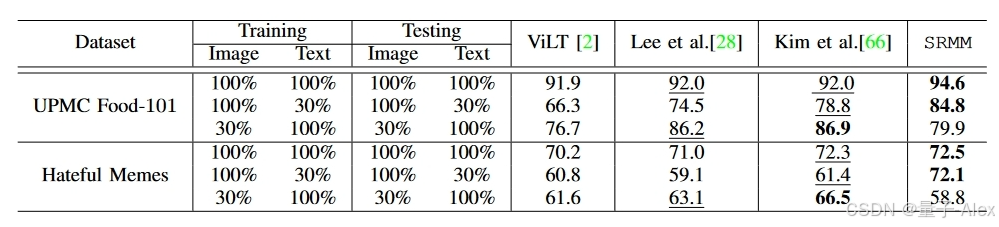
表八:SRMM与ViLT的比较[2]*,Ma等人[28]和Kim等人[66]关于UPMC Food-101,以及不同训练和测试环境下的Hateful Memes。*ViLT值取自[28]。每个设置中的最佳结果以粗体显示。
E.损坏模态下的评估
在现实世界的场景中,由于包括故障设备、低带宽等在内的几个原因,模态通常可能不是丢失而是损坏。为了评估SRMM对损坏模态的鲁棒性,我们通过向测试集中两种模态的特征值添加不同水平的噪声来执行一系列实验,并在表IX中报告结果。如图所示,SRMM在测试时间对具有几个高斯噪声水平( μ = 0 , σ = 0.1 , 0.5 , 1.0 μ=0,σ=0.1,0.5,1.0 μ=0,σ=0.1,0.5,1.0)的100%损坏模态显示出合理的容差。然而,在极端噪声( μ = 0 , σ = 1.0 μ=0,σ=1.0 μ=0,σ=1.0)下,性能明显恶化。
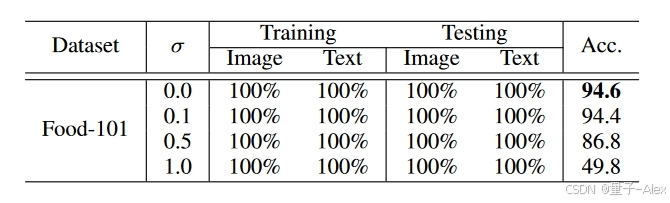
表IX:通过添加高斯噪声,我们的方法在100%损坏模态下的性能。标准偏差( σ σ σ)变化,而平均值( μ μ μ)设置为0。报告准确度结果,最佳结果以粗体显示
5.附加实验
在本节中,我们进一步分析了各种嵌入提取器和不同模态切换策略对SRMM的训练和鲁棒性的影响。
A.多模态与单模态训练
一般来说,多模态网络很受欢迎,因为它们比在单个模态上训练的模型具有性能改进。然而,当多模态方法暴露于缺失模态时,性能通常低于在单个模态上训练的模型的性能,使多模态训练的好处无效[24]。因此,我们进行了一系列实验,以观察与仅对单个模态进行训练相比,我们的方法在缺少模态的情况下是否表现出更好的性能。为了进行这些实验,随机消除测试数据中的实例,以评估所提出的方法对缺失模态的鲁棒性。图4显示,对于任一模态,随着缺失数据百分比的增加,我们的方法表现出较低的敏感性。值得注意的是,与在单个模态上训练和测试的模型相比,即使其中一个模态缺失超过90%,我们的方法也能保持更好的性能。这证明了我们提出的单分支网络在多模态学习中的重要性。
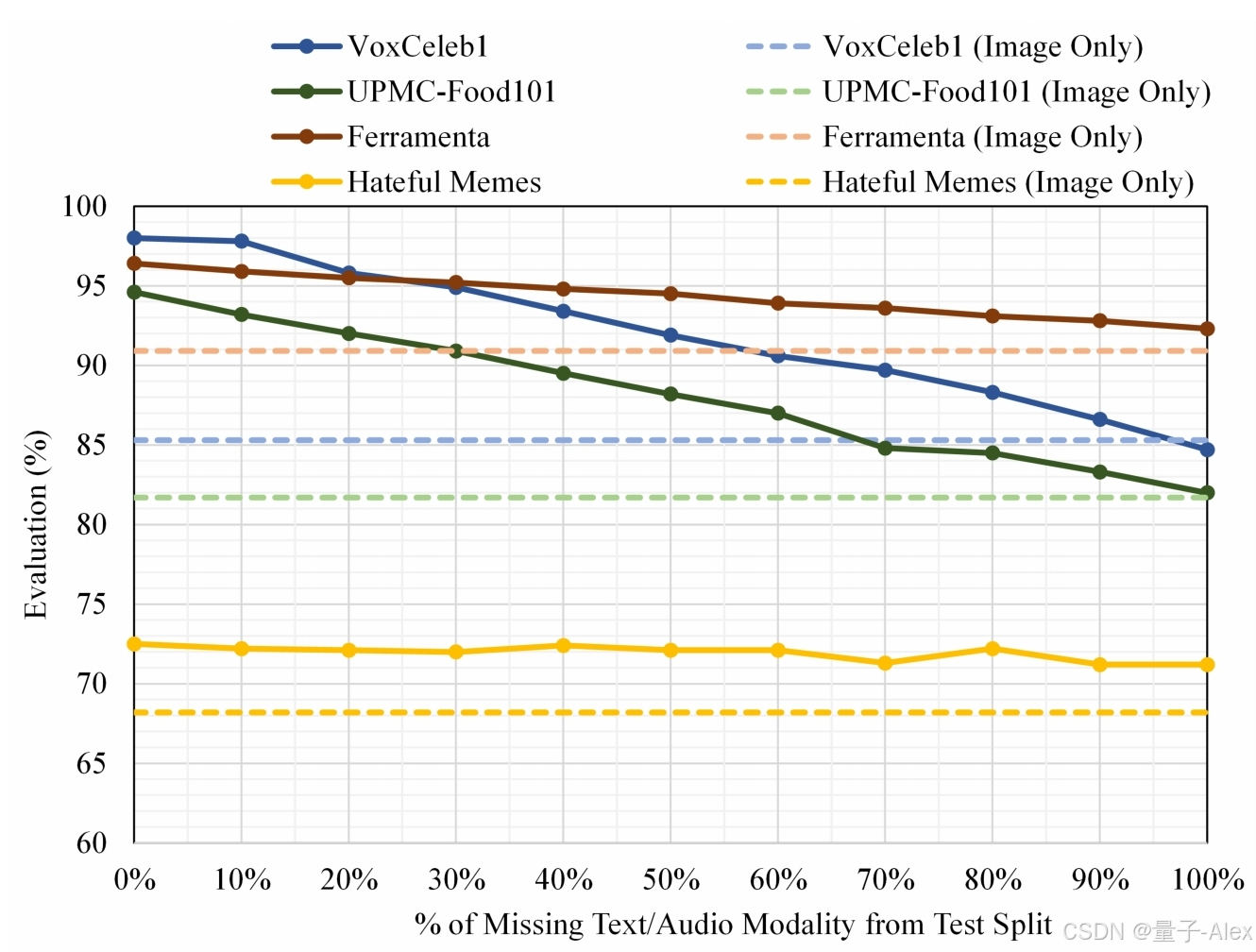
图4:SRMM在四个数据集上对缺失模态的性能评估,包括文本-视觉(UPMC Food101,Hateful Memes,Ferramenta)和视听模态(VoxCeleb1)。虚线表示单峰结果。通过从测试数据中随机消除样本,音频模态(在VoxCeleb1的情况下)和文本模态(在其他三个数据集的情况下)从0%逐渐下降到100%。
B.嵌入提取器
我们使用不同的预训练模型作为特征提取器进行实验,包括用于图像嵌入的ResNet-101 [67]、ViT[68]和CLIP [57],以及用于文本嵌入的Doc2Vec[69]和CLIP。在训练和测试期间,实验在单模态设置以及完全模态设置中进行。
总体而言,SRMM多模态训练中的任何嵌入组合都优于单模态设置。例如,ResNet-101和Doc2Vec多模态训练产生87.5%的准确率,这显著高于这些嵌入提取器的单模态性能,即57.8%和74.1%。类似地,使用剪辑嵌入,SRMM在文本模态的情况下比单模态训练的性能提高了8.4%,在图像模态的情况下提高了12.9%。
C.模态切换策略
我们设计并研究各种切换策略的影响:
S-1随机选择任何可用模态,从而在开关的输出端产生多模态嵌入流。在该策略中,所有批次都是多模态的,批次选择也是随机的。
S-2在每个时期,50%的批次是多模式的,如第一个策略中所讨论的,而其余50%的批次是单模式的。对于每个单峰批次,随机选择任一模态。在训练期间,批次选择是随机的,导致单模态和多模态批次的混合流。
S-3在该策略中,所有批次都是单峰的。对于每个批次,随机选择任一种模式。在训练期间,然后随机选择单模态批次,从而产生单模态批次的多模态流。
表XI比较了UPMC Food-101的结果。S-1在本节研究的三种策略中表现最佳,在测试过程中文本模态100%缺失时,准确率为94.6%,准确率下降了13.3%。另一方面,S-2导致略低的准确率为94.5%,当文本模态完全缺失时,准确率下降了14.3%。S-3表现出最低的性能,在完整模态上只有93.2%的准确率,当文本模态完全缺失时,准确率下降了13.6%。有趣的是,模态开关的所有选择都产生了相当的性能,证明了我们的方法通常对输入模态的顺序是鲁棒的。总的来说,由于S-1的表现相对较好,我们手稿中报告的结果将其用作默认值。
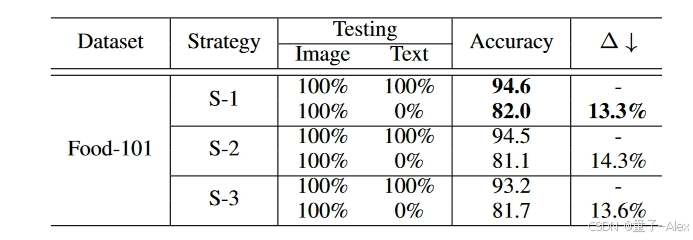
表XI:模态切换策略的性能分析。使用训练集中的100%模态报告结果。最佳结果以粗体显示。
D.定性结果
除了实证结果和分析之外,我们还使用tSNE来可视化UPMC Food-101具有完整模态以及缺失文本和视觉模态的SRMM的嵌入空间。与基线(TBN)和ViLT相比,可视化有助于观察SRMM的总体效果。图5示出了从SRMM的第二块以及ViLT和TBN提取的多模态嵌入。可以看出,SRMM改善了整体分类边界,突出了SRMM的成功。此外,图5示出了当文本和视觉模态在测试时间完全缺失时从SRMM提取的嵌入。尽管一些失真是明显的,但与ViLT和TBN相比,类别的整体可分离性得以保留。这证明了SRMM对缺失模态的鲁棒性。
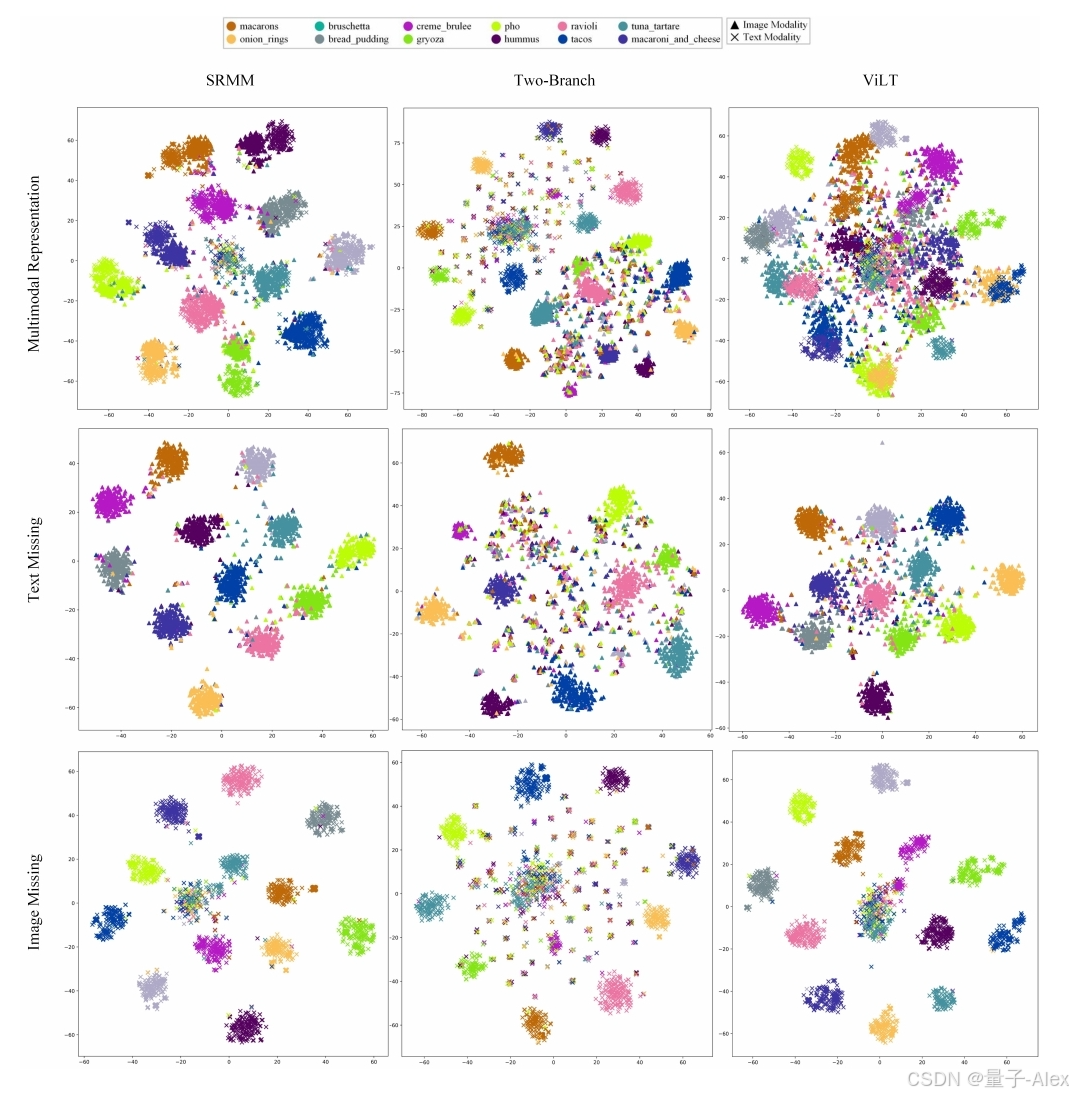
图5:UPMC Food-101测试集上SRMM(来自第二块的嵌入)、ViLT和TBN的特征空间的t-SNE可视化。可以看出,SRMM不仅在测试时完整模态可用时增强了分类边界,而且在测试时文本模态完全缺失时保留了这些边界。
6.优点和局限性
优点
我们的方法的显著优点是高性能和对缺失模态的鲁棒性。此外,SRMM包括明显更小的网络,这导致用于训练的参数更少。例如,与TBN[19]的244万个参数相比,当两者都在图像和文本模态上训练时,SRMM只需要126万个参数。与变形金刚或其他复杂的基于注意力的机制相比,这使得SRMM的训练更加有效[24],[28]。
局限性
SRMM利用模态切换机制,利用单分支网络跨多个模态的权重共享。这种设计需要从模态特定网络中提取的表示相同的嵌入尺寸。我们可以将嵌入转换为所需的大小。然而,这需要进一步的实验,超出了我们的工作范围。
7.结论
我们提出了一种模态不变的多模态学习方法,与现有方法相比,该方法在训练和测试期间对缺失的模态具有很大的鲁棒性。为了确保模态不变学习,模态切换机制将嵌入流串行化到单分支网络。它促进了网络的完全权重共享,并对跨模态的共享语义进行编码。在四个数据集上进行了广泛的实验,包括视听(VoxCeleb1)和文本视觉模态(UPMC Food-101, Hateful Memes和Ferramenta)。对于缺失的模态,对所提出的方法进行了彻底的评估。所提出的网络的性能下降明显小于现有方法,显示出显著的鲁棒性。
8.引用文献
- [1] Di Feng, Christian Haase-Sch ̈ utz, Lars Rosenbaum, Heinz Hertlein, Claudius Glaeser, Fabian Timm, Werner Wiesbeck, and Klaus Dietmayer, “Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 3, pp. 1341–1360, 2020. 2
- [2] Wonjae Kim, Bokyung Son, and Ildoo Kim, “Vilt: Vision-and-language transformer without convolution or region supervision,” in International Conference on Machine Learning. PMLR, 2021, pp. 5583–5594. 1, 2, 5, 6, 7
- [3] Xin Wang, Devinder Kumar, Nicolas Thome, Matthieu Cord, and Frederic Precioso, “Recipe recognition with large multimodal food dataset,” in 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, 2015, pp. 1–6. 1, 2, 4, 5
- [4] Tadas Baltruˇ saitis, Chaitanya Ahuja, and Louis-Philippe Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423443, 2018. 1, 2, 3
- [5] Peng Xu, Xiatian Zhu, and David A Clifton, “Multimodal learning with transformers: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 1, 2
- [6] Cong Zhang, Wenxia Yang, Xin Li, and Huan Han, “Mmginpainting: Multi-modality guided image inpainting based on diffusion models,” IEEE Transactions on Multimedia, 2024. 1
- [7] Douwe Kiela, Edouard Grave, Armand Joulin, and Tomas Mikolov, “Efficient large-scale multi-modal classification,” Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, pp. 51985204, 2018. 1
- [8] Liwei Wang, Yin Li, and Svetlana Lazebnik, “Learning deep structurepreserving image-text embeddings,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5005–5013. 1, 2
- [9] Lei Pang, Shiai Zhu, and Chong-Wah Ngo, “Deep multimodal learning for affective analysis and retrieval,” IEEE Transactions on Multimedia, vol. 17, no. 11, pp. 2008–2020, 2015. 1
- [10] Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8427–8436. 1
- [11] Seungwhan Moon, Leonardo Neves, and Vitor Carvalho, “Multimodal named entity recognition for short social media posts,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers. 2018, pp. 852–860, Association for Computational Linguistics. 1
- [12] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6077–6086. 1
- [13] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164. 1
- [14] Tong Zhu, Leida Li, Jufeng Yang, Sicheng Zhao, Hantao Liu, and Jiansheng Qian, “Multimodal sentiment analysis with image-text interaction network,” IEEE transactions on multimedia, vol. 25, pp. 3375–3385, 2022. 1
- [15] Desmond Elliott, Stella Frank, Khalil Sima’an, and Lucia Specia, “Multi30k: Multilingual english-german image descriptions,” arXiv preprint arXiv:1605.00459, 2016. 1
- [16] Scott Reed, Zeynep Akata, Honglak Lee, and Bernt Schiele, “Learning deep representations of fine-grained visual descriptions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 49–58. 1
- [17] Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler, “Vse++: Improving visual-semantic embeddings with hard negatives,” in Proceedings of the British Machine Vision Conference (BMVC), 2018. 1
- [18] Arsha Nagrani, Samuel Albanie, and Andrew Zisserman, “Learnable pins: Cross-modal embeddings for person identity,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 71–88. 1, 2
- [19] Muhammad Saad Saeed, Muhammad Haris Khan, Shah Nawaz, Muhammad Haroon Yousaf, and Alessio Del Bue, “Fusion and orthogonal projection for improved face-voice association,” in ICASSP 20222022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7057–7061. 1, 2, 5, 6, 7
- [20] Changil Kim, Hijung Valentina Shin, Tae-Hyun Oh, Alexandre Kaspar, Mohamed Elgharib, and Wojciech Matusik, “On learning associations of faces and voices,” in Asian Conference on Computer Vision. Springer, 2018, pp. 276–292. 1, 2
- [21] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-andlanguage tasks,” Advances in neural information processing systems, vol. 32, 2019. 1, 5
- [22] Hao Tan and Mohit Bansal, “Lxmert: Learning cross-modality encoder representations from transformers,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019. 1
- [23] Qiuling Suo, Weida Zhong, Fenglong Ma, Ye Yuan, Jing Gao, and Aidong Zhang, “Metric learning on healthcare data with incomplete modalities.,” in IJCAI, 2019, pp. 3534–3540. 1, 3
- [24] Mengmeng Ma, Jian Ren, Long Zhao, Davide Testuggine, and Xi Peng, “Are multimodal transformers robust to missing modality?,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18177–18186. 1, 2, 3, 4, 5, 6, 7
- [25] Jinming Zhao, Ruichen Li, and Qin Jin, “Missing modality imagination network for emotion recognition with uncertain missing modalities,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 2608–2618. 1, 2
- [26] Jiandian Zeng, Tianyi Liu, and Jiantao Zhou, “Tag-assisted multimodal sentiment analysis under uncertain missing modalities,” in Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2022, pp. 1545–1554. 1
- [27] Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng, “Smil: Multimodal learning with severely missing modality,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, pp. 2302–2310, 2021. 1, 2, 3
- [28] Yi-Lun Lee, Yi-Hsuan Tsai, Wei-Chen Chiu, and Chen-Yu Lee, “Multimodal prompting with missing modalities for visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14943–14952. 1, 2, 4, 5, 7
- [29] Hu Wang, Yuanhong Chen, Congbo Ma, Jodie Avery, Louise Hull, and Gustavo Carneiro, “Multi-modal learning with missing modality via shared-specific feature modelling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15878–15887. 1
- [30] Orhan Firat, Kyunghyun Cho, and Yoshua Bengio, “Multi-way, multilingual neural machine translation with a shared attention mechanism,” in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, California, June 2016, pp. 866–875, Association for Computational Linguistics. 1
- [31] Raj Dabre, Chenhui Chu, and Anoop Kunchukuttan, “A survey of multilingual neural machine translation,” ACM Comput. Surv., vol. 53, no. 5, sep 2020. 1
- [32] Paul Pu Liang, Amir Zadeh, and Louis-Philippe Morency, “Foundations and trends in multimodal machine learning: Principles, challenges, and open questions,” arXiv preprint arXiv:2209.03430, 2022. 1
- [33] Christian Ganh ̈ or, Marta Moscati, Anna Hausberger, Shah Nawaz, and Markus Schedl, “A multimodal single-branch embedding network for recommendation in cold-start and missing modality scenarios,” in Proceedings of the 18th ACM Conference on Recommender Systems, 2024. 1
- [34] Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine, “The hateful memes challenge: Detecting hate speech in multimodal memes,” Advances in Neural Information Processing Systems, vol. 33, pp. 26112624, 2020. 2
- [35] Ignazio Gallo, Alessandro Calefati, and Shah Nawaz, “Multimodal classification fusion in real-world scenarios,” in 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, vol. 5, pp. 36–41. 2, 4, 5
- [36] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: a large-scale speaker identification dataset,” in INTERSPEECH, 2017. 2, 4
- [37] Muhammad Saad Saeed, Shah Nawaz, Muhammad Haris Khan, Muhammad Zaigham Zaheer, Karthik Nandakumar, Muhammad Haroon Yousaf, and Arif Mahmood, “Single-branch network for multimodal training,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5. 2
- [38] Sijie Mai, Songlong Xing, and Haifeng Hu, “Locally confined modality fusion network with a global perspective for multimodal human affective computing,” IEEE Transactions on Multimedia, vol. 22, no. 1, pp. 122137, 2019. 2
- [39] John Arevalo, Thamar Solorio, Manuel Montes-y G ́ omez, and Fabio A Gonz ́ alez, “Gated multimodal units for information fusion,” arXiv preprint arXiv:1702.01992, 2017. 2
- [40] Valentin Vielzeuf, Alexis Lechervy, St ́ ephane Pateux, and Fr ́ ed ́ eric Jurie, “Centralnet: a multilayer approach for multimodal fusion,” in Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018, pp. 0–0. 2
- [41] Niklas Muennighoff, “Vilio: state-of-the-art visio-linguistic models applied to hateful memes,” arXiv preprint arXiv:2012.07788, 2020. 2, 5
- [42] Xiangteng He and Yuxin Peng, “Fine-grained image classification via combining vision and language,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5994–6002. 2
- [43] Ignazio Gallo, Gianmarco Ria, Nicola Landro, and Riccardo La Grassa, “Image and text fusion for upmc food-101 using bert and cnns,” in 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE, 2020, pp. 1–6. 2, 5
- [44] Shah Nawaz, Alessandro Calefati, Moreno Caraffini, Nicola Landro, and Ignazio Gallo, “Are these birds similar: Learning branched networks for fine-grained representations,” in 2019 International Conference on Image and Vision Computing New Zealand (IVCNZ). IEEE, 2019, pp. 1–5. 2
- [45] Chaohe Zhang, Xu Chu, Liantao Ma, Yinghao Zhu, Yasha Wang, Jiangtao Wang, and Junfeng Zhao, “M3care: Learning with missing modalities in multimodal healthcare data,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 2418–2428. 2
- [46] Ning Wang, Hui Cao, Jun Zhao, Ruilin Chen, Dapeng Yan, and Jie Zhang, “M2r2: Missing-modality robust emotion recognition framework with iterative data augmentation,” IEEE Transactions on Artificial Intelligence, 2022. 2
- [47] Xiaodan Zhang, Qiao Song, and Gang Liu, “Multimodal image aesthetic prediction with missing modality,” Mathematics, vol. 10, no. 13, pp. 2312, 2022. 2, 3
- [48] Ronghao Lin and Haifeng Hu, “Missmodal: Increasing robustness to missing modality in multimodal sentiment analysis,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 1686–1702, 2023. 2
- [49] Merey Ramazanova, Alejandro Pardo, Humam Alwassel, and Bernard Ghanem, “Exploring missing modality in multimodal egocentric datasets,” arXiv preprint arXiv:2401.11470, 2024. 2
- [50] Jiandian Zeng, Jiantao Zhou, and Tianyi Liu, “Robust multimodal sentiment analysis via tag encoding of uncertain missing modalities,” IEEE Transactions on Multimedia, vol. 25, pp. 6301–6314, 2022. 2
- [51] Muhammad Irzam Liaqat, Shah Nawaz, Muhammad Zaigham Zaheer, Muhammad Saad Saeed, Hassan Sajjad, Tom De Schepper, Karthik Nandakumar, and Muhammad Haris Khan Markus Schedl, “Chameleon: Images are what you need for multimodal learning robust to missing modalities,” arXiv preprint arXiv:2407.16243, 2024. 2, 3
- [52] Srinivas Parthasarathy and Shiva Sundaram, “Training strategies to handle missing modalities for audio-visual expression recognition,” in Companion Publication of the 2020 International Conference on Multimodal Interaction, 2020, pp. 400–404. 2
- [53] Lei Cai, Zhengyang Wang, Hongyang Gao, Dinggang Shen, and Shuiwang Ji, “Deep adversarial learning for multi-modality missing data completion,” in Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 11581166. 3
- [54] Zilong Wang, Zhaohong Wan, and Xiaojun Wan, “Transmodality: An end2end fusion method with transformer for multimodal sentiment analysis,” in Proceedings of The Web Conference 2020, 2020, pp. 25142520. 3
- [55] Jing Han, Zixing Zhang, Zhao Ren, and Bj ̈ orn Schuller, “Implicit fusion by joint audiovisual training for emotion recognition in mono modality,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 5861–5865. 3
- [56] Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Casey A Fitzpatrick, Peter Bull, Greg Lipstein, Tony Nelli, Ron Zhu, et al., “The hateful memes challenge: competition report,” in NeurIPS 2020 Competition and Demonstration Track. PMLR, 2021, pp. 344–360. 4, 5
- [57] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763. 4, 7
- [58] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Thirty-first AAAI conference on artificial intelligence, 2017. 4
- [59] Florian Schroff, Dmitry Kalenichenko, and James Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823. 4
- [60] Weidi Xie, Arsha Nagrani, Joon Son Chung, and Andrew Zisserman, “Utterance-level aggregation for speaker recognition in the wild,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 5791–5795. 4, 5
- [61] Shah Nawaz, Alessandro Calefati, Muhammad Kamran Janjua, Muhammad Umer Anwaar, and Ignazio Gallo, “Learning fused representations for large-scale multimodal classification,” IEEE Sensors Letters, vol. 3, no. 1, pp. 1–4, 2018. 5
- [62] Douwe Kiela, Suvrat Bhooshan, Hamed Firooz, Ethan Perez, and Davide Testuggine, “Supervised multimodal bitransformers for classifying images and text,” arXiv preprint arXiv:1909.02950, 2019. 5
- [63] LH Li, M Yatskar, D Yin, CJ Hsieh, and KW Chang, “A simple and performant baseline for vision and language,” arXiv preprint arXiv:1908.03557, 2019. 5
- [64] Ignazio Gallo, Alessandro Calefati, Shah Nawaz, and Muhammad Kamran Janjua, “Image and encoded text fusion for multi-modal classification,” in 2018 Digital Image Computing: Techniques and Applications (DICTA). IEEE, 2018, pp. 1–7. 5
- [65] Tan Yue, Yong Li, Jiedong Qin, and Zonghai Hu, “Multi-modal hierarchical fusion network for fine-grained paper classification,” Multimedia Tools and Applications, pp. 1–17, 2023. 5
- [66] Donggeun Kim and Taesup Kim, “Missing modality prediction for unpaired multimodal learning via joint embedding of unimodal models,” arXiv preprint arXiv:2407.12616, 2024. 5, 6, 7
- [67] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770778. 7
- [68] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020. 7
- [69] Quoc Le and Tomas Mikolov, “Distributed representations of sentences and documents,” in International conference on machine learning. PMLR, 2014, pp. 1188–1196. 7

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)