
【vLLM-框架及特性学习】vllm-ascend torch.compile 的原理与使用
`torch.compile` 是 PyTorch 2.0 引入的一项核心性能优化功能,旨在通过即时编译(JIT)技术将 PyTorch 模型编译为更高效的机器代码,从而显著提升模型训练和推理的运行速度,同时几乎不需要用户修改原有代码
作者:昇腾实战派torch.compile 是 PyTorch 2.0 引入的一项核心性能优化功能,旨在通过即时编译(JIT)技术将 PyTorch 模型编译为更高效的机器代码,从而显著提升模型训练和推理的运行速度,同时几乎不需要用户修改原有代码
一、torch.compile 的基本原理
1. 图捕获(Graph Capture)
PyTorch 原本是动态图(eager mode)执行的,这使得优化困难。torch.compile 的核心是 TorchDynamo,它通过 Python 的 Frame Evaluation API 动态拦截 Python 字节码,在运行时捕获模型的计算图(computation graph),将其转换为静态图表示 。
2. 图优化(Graph Optimization)
一旦捕获到计算图,torch.compile 会调用指定的后端(如 inductor、aot_eager、eager 等)对图进行优化。默认后端是 inductor,它会进一步将图转换为 Triton(一种 GPU 编程语言)或 C++ 代码,生成高度优化的内核 。
ascend使用的是 torchair、aot_eager、eager
3. 支持任意 Python 控制流
torch.compile 能处理任意 Python 代码。当遇到无法编译的部分(如自定义 Python 函数),它会中断编译,以 eager 模式执行该部分,然后继续编译后续代码,这种机制称为 “图中断”(graph break) 。
二、基本使用方法
1. 安装要求
需要 PyTorch 2.0 或更高版本:
pip install torch>=2.0
2. 编译模型
2.1 直接调用compile()
对 torch.nn.Module 实例调用 torch.compile():
import torch
model = MyModel()
compiled_model = torch.compile(model)
# 后续像平常一样使用 compiled_model
output = compiled_model(input_tensor)
也可以直接在模型上调用 .compile() 方法(PyTorch 2.3+):
model.compile()
2.2 使用装饰器@torch.compile
2.2.1 装饰整个函数
import torch
@torch.compile
def my_function(x):
return torch.relu(x @ x.T)
x = torch.randn(1000, 1000, device='cuda')
y = my_function(x) # 第一次调用会触发编译
这种方式适用于任意接受张量并返回张量的 Python 函数
2.2.2 装饰模型的 forward 方法(不推荐)
虽然技术上可行,但官方一般不建议直接装饰 forward 方法,因为 torch.nn.Module 的状态管理(如参数、缓冲区)可能与编译上下文不兼容。推荐的做法是编译整个模块对象:
# 推荐:编译整个模型
model = MyModel()
compiled_model = torch.compile(model)
# 不推荐(可能出错或无法优化):
class MyModel(torch.nn.Module):
@torch.compile # 可能导致图中断或状态不一致
def forward(self, x):
return x
2.3 vllm 自行封装的装饰器@support_torch_compile
@support_torch_compile
class DeepSeekMTP(nn.Module, SupportsPP):
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
super().__init__()
self.config = vllm_config.model_config.hf_config
self.model = DeepSeekMultiTokenPredictor(
vllm_config=vllm_config, prefix=maybe_prefix(prefix, "model")
)
大体调用流程如下:
-
前端捕获: 利用
torch.compile及其集成的 Dynamo 技术,将模型的 Python 代码追踪并转换为 FX Graph 格式。 -
自定义后端: 实现
torch.compile的自定义后端VllmBackend。该后端接管由 Dynamo 生成的 FX Graph,从而接管后续编译及执行流程。 -
图拆分 (
split_graph): 在VllmBackend内部,调用split_graph函数。此函数依据预定义的切分点(如unified_attention_with_output),将单一的、庞大的计算图分解为一个主图和多个独立的子图模块 (submodule)。 -
子图替换与调度:
- 通过
PiecewiseCompileInterpreter遍历拆分后的子图。 - 将原始的子图模块替换为一个自定义的调度器对象,即
NPUPiecewiseBackend。 - 此后,模型前向传播至该部分时,将调用
NPUPiecewiseBackend的__call__方法。
- 通过
-
动态 Graph 捕获与重放:
NPUPiecewiseBackend的__call__方法内实现了动态调度逻辑:- 运行时形状检查: 检查当前输入的张量形状。
- 按需捕获: 若当前形状满足预设的捕获条件(如生产环境高频出现的
batch_size),则触发 ACL Graph 的捕获流程,并将生成的 Graph 缓存。 - 条件性重放: 若当前形状命中了已缓存的 Graph,则直接调用
replay()执行,从而绕过框架开销,实现高性能推理。
3. 指定后端和模式(可选)
compiled_model = torch.compile(model, backend="inductor", mode="default")
backend:如"inductor"、"aot_eager"、"eager"等。mode:可选"default"、"reduce-overhead"(适合小 batch)、"max-autotune"(极致优化,但编译时间长)等 。- ascend 参考:https://www.hiascend.com/document/detail/zh/Pytorch/700/modthirdparty/torchairuseguide/torchair_0002.html
三、性能与注意事项
-
性能提升:根据模型结构和硬件(尤其是 GPU),
torch.compile在推理阶段通常可带来 最高 30% 的加速 。 -
首次运行较慢:因为需要编译,第一次调用会比后续慢,属于正常现象。
-
兼容性:绝大多数 PyTorch 模型无需修改即可使用,但某些动态控制流或复杂 Python 逻辑可能导致图中断,影响优化效果 。
npu:aclnn算子才支持图模式, aclop不支持
四、原理剖析
想要搞清楚torch compile到底是怎么实现的,我们首先需要了解一个关键组件TorchDynamo
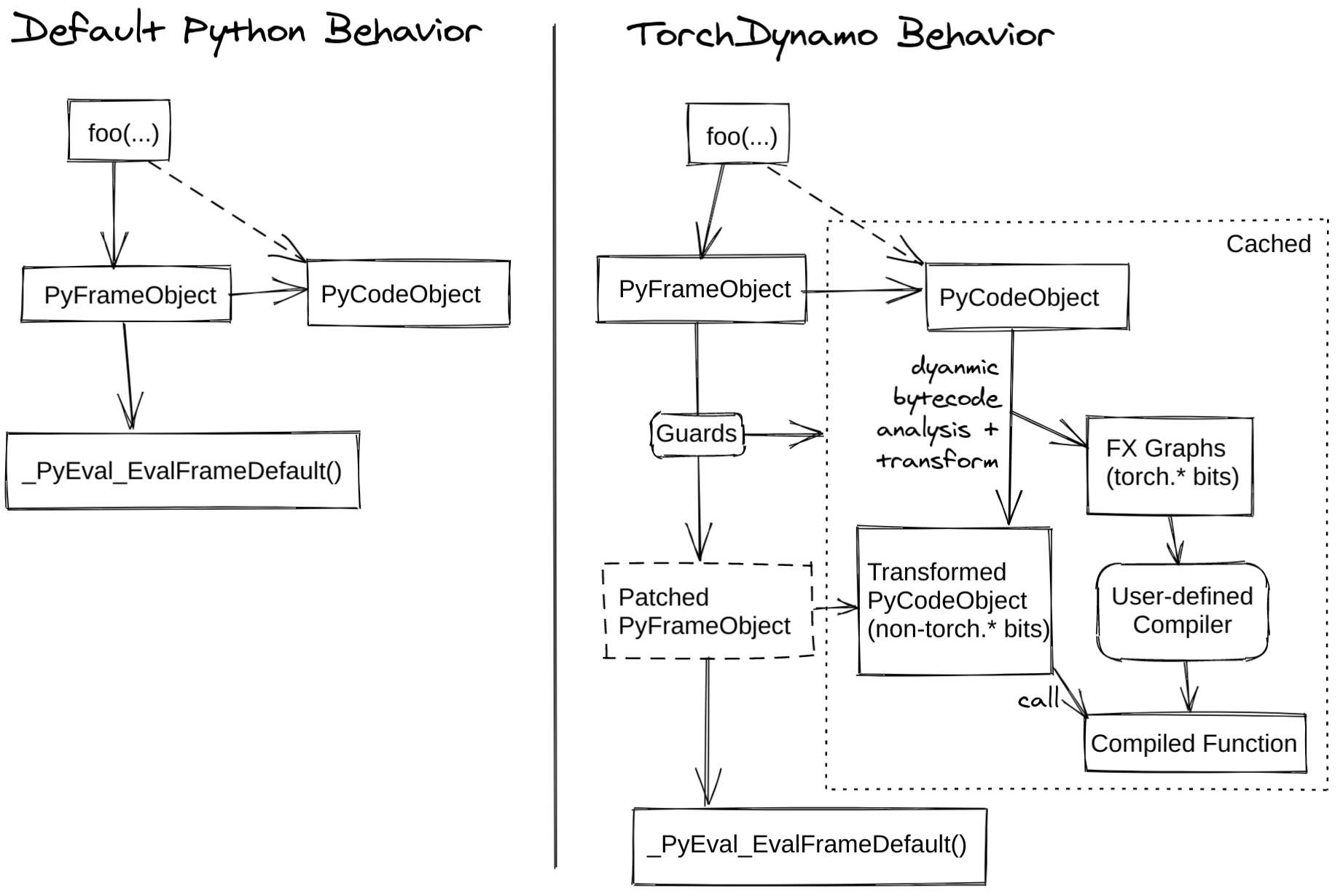
TorchDynamo 的作用是从 PyTorch 应用中抓取计算图,相比于 TorchScript 和 TorchFX,TorchDynamo 更加灵活、可靠性更高。用过 TorchScript 的朋友知道,通过 jit.trace 或者 jit.script 把模型转化为 TorchScript 的过程困难重重,往往需要修改大量源代码。而 TorchFX 在捕获计算图时,遇到不支持的算子会直接报错,最常见的就是 if 语句。TorchDynamo 克服了 TorchScript 和 TorchFX 的缺点,使用起来极为方便,用户体验相比于 TorchScript 和 TorchFX 大幅提升。配合 TorchInductor 等后端编译器,经 TorchDynamo 捕获的计算图只需要几行代码的改动就可以观测到不错的性能提升。
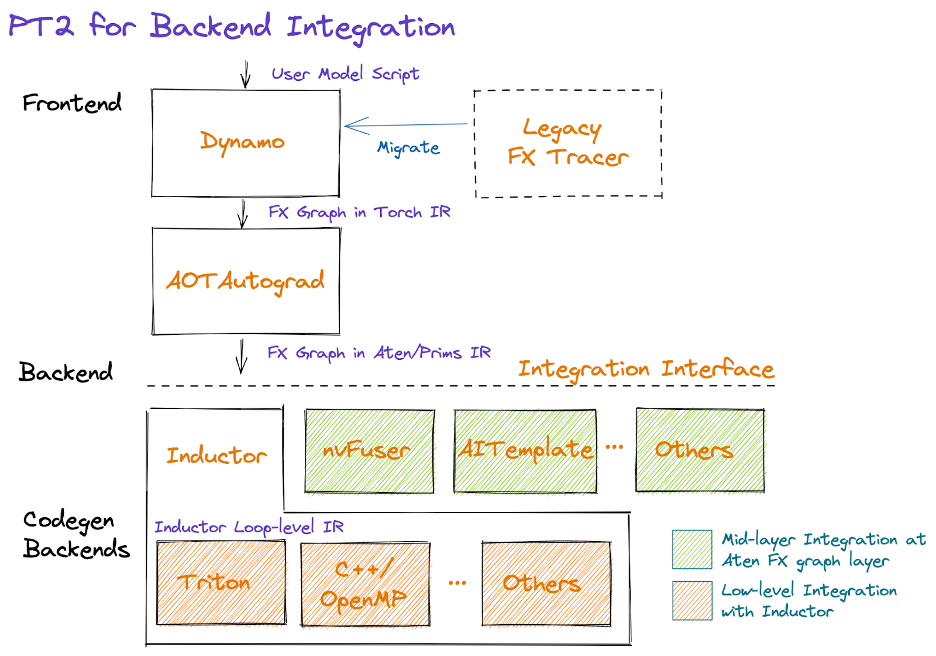
TorchDynamo 的 编译过程发生在将要执行前,它是一个 JIT 编译器。在 Python 将要执行函数时,TorchDynamo 开始翻译字节码并捕获计算图。在 Python 虚拟机 (PVM) 中有一个非常重要的函数 _PyEval_EvalFrameDefault,它的功能是在 PVM 中逐条执行编译好的字节码。TorchDynamo 的入口是 PEP-523 提供的 CPython Frame Evaluation API,它可以让用户通过 回调函数(callback function) 获取字节码,并把修改过后的字节码返回给解释器执行,或者执行预先编译好的目标代码,从而可以在 Python 中实现 即时编译器 (JIT Compiler) 的功能。TorchDynamo 正是通过 PEP-523 把 TorchDynamo 的核心逻辑引入到 Python 虚拟机中,从而在函数将要运行前获取字节码。
下图展示了 TorchDynamo 的核心原理:
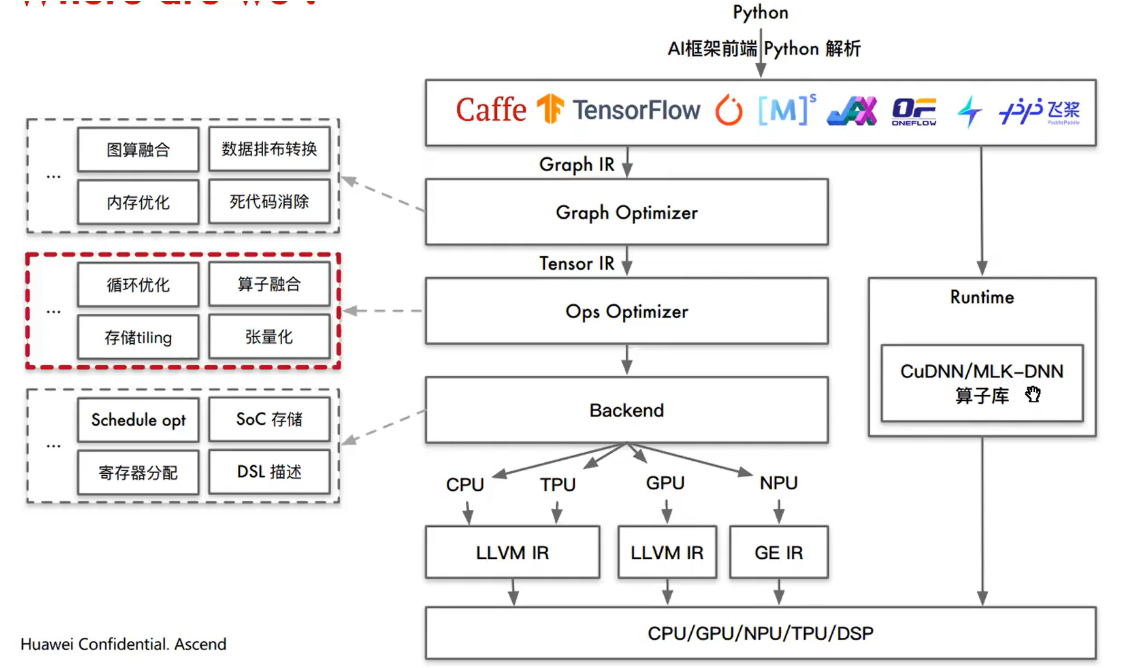
PyTorch 2.0 还有其他4个核心组件: TorchDynamo,AOTAutograd,PrimTorch 和 TorchInductor。下图为简要说明:
Reference:
聊聊 PyTorch 2.0(Inductor):
https://zhuanlan.zhihu.com/p/595996564
一文搞懂 TorchDynamo 原理:
https://fkong.tech/posts/2023-05-20-dynamo/
【AI实操 · 优化篇】01 Triton在PyTorch中的角色:
https://www.bilibili.com/video/BV1ZoRPYQE2K?spm_id_from=333.788.videopod.sections&vd_source=47f784e23fe40eaf12ef33eaac1a0c80

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)