
全文 AMD GPGPU 通信问题 - Understanding Data Movement in AMD Multi-GPU Systems with Infinity Fabric
现代 GPU 系统在不断发展,以满足科学和机器学习领域中计算密集型应用的需求。然而,硬件性能与实际应用中可实现的性能之间通常存在差距。这项工作旨在更深入地了解 AMD GPU 和 CPU 上的 Infinity Fabric 互连技术。我们提出了一种测试和评估方法,用于描述多 GPU 系统上数据传输的性能,重点研究 AMD MI250X GPU 上的不同通信方式,包括点对点通信和集合通信,以及 G

此文可对照 gem5 AMDGPU sim
摘要
现代 GPU 系统在不断发展,以满足科学和机器学习领域中计算密集型应用的需求。然而,硬件性能与实际应用中可实现的性能之间通常存在差距。这项工作旨在更深入地了解 AMD GPU 和 CPU 上的 Infinity Fabric 互连技术。我们提出了一种测试和评估方法,用于描述多 GPU 系统上数据传输的性能,重点研究 AMD MI250X GPU 上的不同通信方式,包括点对点通信和集合通信,以及 GPU 之间和主机 CPU 的内存分配策略。在一个配备四个 GPU 的单节点设置中,我们发现,在内存 / 通信延迟和带宽方面,GPU 之间的直接对等内存访问以及 RCCL 库的使用,优于基于 MPI 的解决方案。我们的测试和评估方法为验证系统上的内存和通信策略以及改进 AMD 多 GPU 计算系统上的应用程序奠定了基础。
一、引言
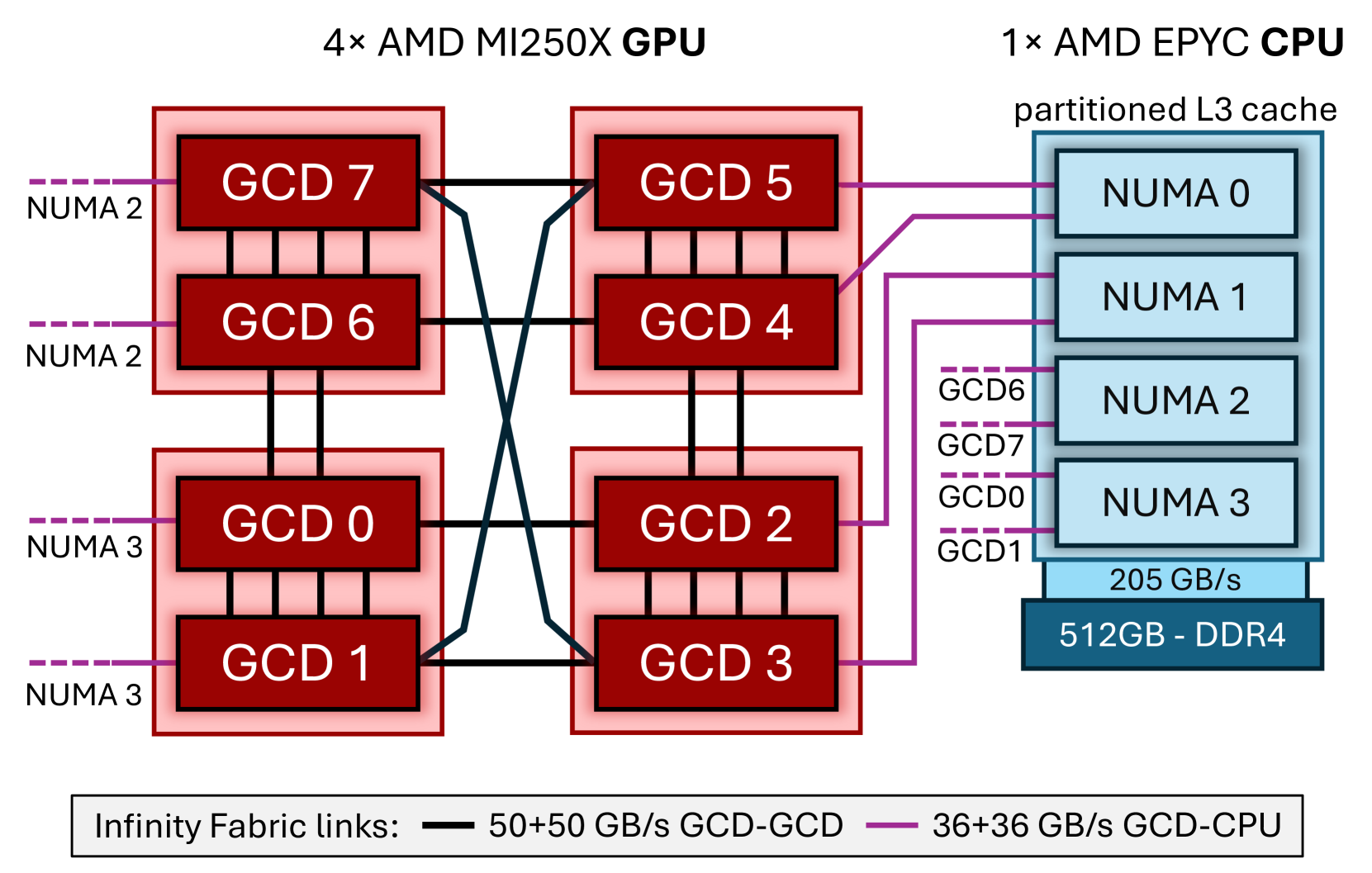
Figure 1: Overview of a multi-GPU compute node, totaling eight GCDs, distributed onto four physical MI250X GPUs, coupled with a single-socket AMD 3rd generation EPYC CPU. Adapted from [1].
多 GPU 高性能计算(HPC)节点在大规模超级计算机中已无处不在,以支持各种加速的科学工作负载,包括天气预报 [2]、计算流体动力学 [3, 4]、分子动力学 [5]、等离子体模拟 [6] 和量子计算机模拟 [7]。目前,大规模 HPC 集群的计算节点在同一节点上配备多个 GPU,通过高性能互连或 PCIe 进行连接。虽然多 GPU 超级计算机最初由英伟达主导,但如今许多超级计算机也依赖 AMD GPU 来加速科学工作负载 [8]。例如,橡树岭国家实验室(ORNL)的 “前沿”(Frontier)超级计算机每个计算节点配备四个 AMD Instinct MI250X GPU,每个 GPU 包含两个图形计算芯片(GCD)。从用户的角度来看,一个计算节点看起来像是一个八 GPU 节点,每个 GCD 都被视为一个 GPU。在这个系统中,CPU 和 GPU 通过封装内的 Infinity Fabric 高性能互连进行连接,类似于英伟达的 NVLink。这种互连为系统中所有处理器(CPU 和 GPU)之间的数据传输创建了多条路径,并且可以通过各种接口来利用。在这个网状结构中,各种链路表现出三种不同的带宽级别,这使得高性能应用程序的设计变得更加复杂,而这些应用程序希望有效地利用该系统的硬件功能。其他超级计算机,如 LUMI,也采用了这种独特的节点架构。
从历史上看,GPU 加速系统的性能一直受到主机和 GPU 之间可用延迟和带宽的限制。为了解决这个问题,已经设计了一些技术改进,例如用于提高带宽的专用互连或重叠技术。如今,每个节点有多个 GPU,在所有为同一应用程序代码服务的多个设备之间的数据传输性能问题变得更加严重。因此,必须了解数据传输的性能优势和瓶颈,并描述 CPU 和 GPU 之间以及同一节点上不同 GPU 之间的数据传输性能。这样的理解可以帮助科学家为应用程序和运行时系统设计数据放置和迁移技术。
本文的总体目标是测试和描述 AMD 多 GPU 节点上的数据传输性能,其中 CPU-GPU 和 GPU-GPU 通过 Infinity Fabric 互连。这项工作基于一个具有八个 GCD 的计算节点,这些 GCD 被组合在四个物理 AMD MI250X GPU 上,这与 “500 强” 榜单上排名第一的超级计算机 “前沿” 所使用的拓扑结构类似。我们的测试方法包括三个步骤,涵盖了 Infinity Fabric 互连的三个基本使用场景。首先,我们描述 CPU-GPU 数据传输的性能,比较可用的编程接口和内存分配方式。然后,我们在对等数据传输的背景下,重点关注 GPU-GPU 的 Infinity Fabric 互连。最后,我们以 MPI 集合通信和 RCCL 集合通信的形式,对在 HPC 和人工智能应用中广泛使用的高级多 GPU 集合通信进行评估。为了实现可重复性,我们提供了代码和基准测试脚本。
本文的主要贡献总结如下:
我们研究了由 AMD CPU 和四个带有通过 Infinity Fabric 互连的八个 GCD 的 MI250X GPU 组成的计算节点上的各种点对点数据传输选项。
我们评估了内存分配策略对 AMD CPU 和 GPU 之间数据传输性能的影响。
我们描述了集合通信的性能,并在具有代表 “前沿”/LUMI 超级计算机拓扑结构的多 GPU 节点上比较了 MPI 和 RCCL 库。
我们确定了在复杂的 Infinity Fabric 拓扑结构中优化路由的重要性。
二、背景
在这项工作中,我们专注于一个 HPC 多 GPU 节点,该节点配备四个 AMD MI250X GPU、一个第三代 AMD EPYC CPU,以及用于 CPU-GPU 和 GPU 间通信的 Infinity Fabric 互连。图 1 展示了这种多 GPU 节点的互连情况。该系统一个重要且独特的特点是,每个 MI250X GPU 由两个图形计算芯片(GCD)组成,每个 GCD 具有 64GB 的 HBM2e 内存,提供 1.6TB/s 的峰值带宽。每个 GCD 有一个 8MB 的二级缓存,供所有计算单元共享,每个计算单元有 16KB 的一级向量缓存和 16KB 的一级标量缓存,每两个计算单元共享。从用户的角度来看,每个 GCD 的行为就像一个单独的 GPU,因为一个 GCD 拥有自己的计算单元和物理内存。该节点中的 CPU 是基于 Zen 3 微架构的 AMD 第三代 EPYC 处理器,具体来说是一个 64 核的 AMD 7A53 CPU。CPU 连接到 512GB 的 DDR4 内存,该内存被划分为四个非统一内存访问(NUMA)域,每两个 GCD(一个物理 MI250X GPU)恰好连接到一个 NUMA 域,如图 1 所示。该系统的另一个重要特点是 Infinity Fabric 互连,它提供了高性能的 CPU-GPU 以及 GPU-GPU 通信能力。这个节点的特性和拓扑结构与 “前沿”[9] 和 LUMI [10] 超级计算机的计算节点相似。
(一)Infinity Fabric 互连
一个 GPU 内部和不同 GPU 之间的 GCD 通过 Infinity Fabric 链路连接。图 1 展示了完整的节点拓扑结构。不同 GCD 之间的 Infinity Fabric 实现为单向、双向或四向连接,每条链路的双向带宽为 50+50GB/s。位于同一物理 GPU 上的 GCD 通过四条链路连接,总双向带宽达到 400GB/s。以 GCD0 为例,它还通过双向链路直接连接到 GCD6(即双向 200GB/s),并通过单向链路连接到 GCD2(即双向 100GB/s)。从 GCD0 出发,通过两跳可以到达所有其他 GCD。本质上,Infinity Fabric 互连实现了 xGMI 协议,通过不同数量的 xGMI 链路互连 GCD。每条链路每次事务操作 16 位,事务速率为 25GT/s,即每条链路每个方向的峰值带宽为 50GB/s [11]。此外,每个 GCD 通过一条 Infinity Fabric 链路连接到系统的主机 CPU,理论峰值带宽为 36GB/s(双向 72GB/s)。Infinity Fabric 互连支持零拷贝内存访问,系统中的任何处理器(CPU 或 GPU)都可以直接通过互连访问彼此的物理内存,而无需维护本地副本。
(二)HIP 编程模型
AMD GPU 主要使用 HIP 编程模型进行编程,这是一种基于 C++ 的运行时 API 和内核语言,类似于英伟达 GPU 已有的 CUDA 编程环境。本质上,在运行时,HIP 运行时与 HSA 运行时交互,HSA 运行时再与 AMD 内核驱动程序(ROCk)通信。AMD 的 ROCm 平台提供了用于使用 HIP 对 GPU 进行编程的编译器和开发工具,以及常见 HPC 库的 HIP 版本,如 rocBLAS。它还提供了一个命令行工具,用于将 CUDA 代码转换为 HIP 代码(hipify),本文使用了该工具。
(三)内存管理
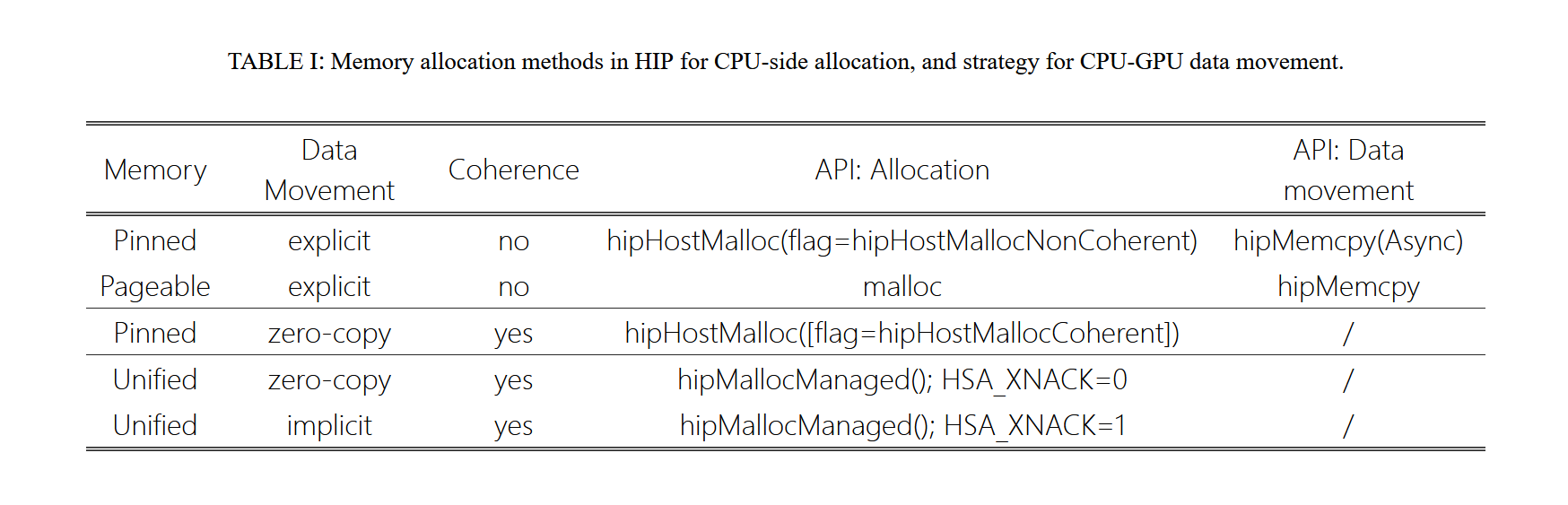
从用户的角度来看,多 GPU 节点的拓扑结构使得内存分配和数据传输成为一项复杂的任务,因为该系统中的物理内存分布在八个 GPU 和一个 CPU 上,并且进一步划分为四个 NUMA 域。为了抽象这种复杂性,AMD 提供了几个 API 来分配内存并执行 GPU 间通信,这些 API 具有不同的抽象级别和粒度,类似于 CUDA 编程模型中的 API。
统一内存将系统中所有处理器的物理内存组合到一个单一的虚拟内存空间中。这意味着任何处理器(CPU 或 GPU)都可以使用单个虚拟地址访问其他处理器的物理内存。统一内存可以通过托管内存使用 hipMallocManaged 进行分配。此外,其他类型的内存分配可以映射到 GPU 的虚拟地址空间中,可以在分配时由运行时自动完成,也可以使用 HIP API 显式完成。映射内存允许 GPU 访问其物理内存之外的内存。
内存分配可以配置为一致性内存。当 GPU 修改标记为一致性的 CPU 内存时,更改会立即反映在 CPU 端。在 MI250X 上,为了实现这种效果,一致性内存会禁用 GPU 端的缓存。因此,对位于远程一致性内存中的数据的每次访问都会在 CPU-GPU 互连上产生流量。虽然使用一致性内存通常会对性能产生不利影响,但它简化了具有复杂访问模式的应用程序的编程,例如在同一数据上共同运行的 CPU 和 GPU 内核。请注意,在更新的系统(如 AMD MI300A)上,由于引入了缓存一致性互连,无缓存限制可以被解除。在 HIP 中,默认情况下,主机固定内存被标记为一致性内存。
当 GPU 内核访问既不在 GPU 的物理内存中,也未映射到 GPU 虚拟内存中的内存时,会触发页面错误。MI250X 系统能够解决页面错误,并重新尝试内存访问。这个功能称为 XNACK,可以通过设置环境变量 HSA_XNACK=1 来启用。此外,用户必须确保构建的 GPU 内核与系统的 XNACK 配置(启用 / 禁用)相匹配。
表 1 总结了 HIP 中的一系列内存分配 API。第二列进一步详细说明了内存传输的执行方式。列出了三种类型的数据传输,即显式传输、隐式传输和零拷贝传输。显式数据传输是指使用 hipMemcpy,用户负责传输数据。零拷贝表示数据通过 Infinity Fabric 互连进行访问。最后,隐式数据传输表示内存会在被访问时自动迁移。迁移以页面粒度进行,即整个页面被迁移,而与正在访问的数据大小无关。当启用 XNACK 时,这就是 hipMallocManaged 内存的行为。
三、测试方法
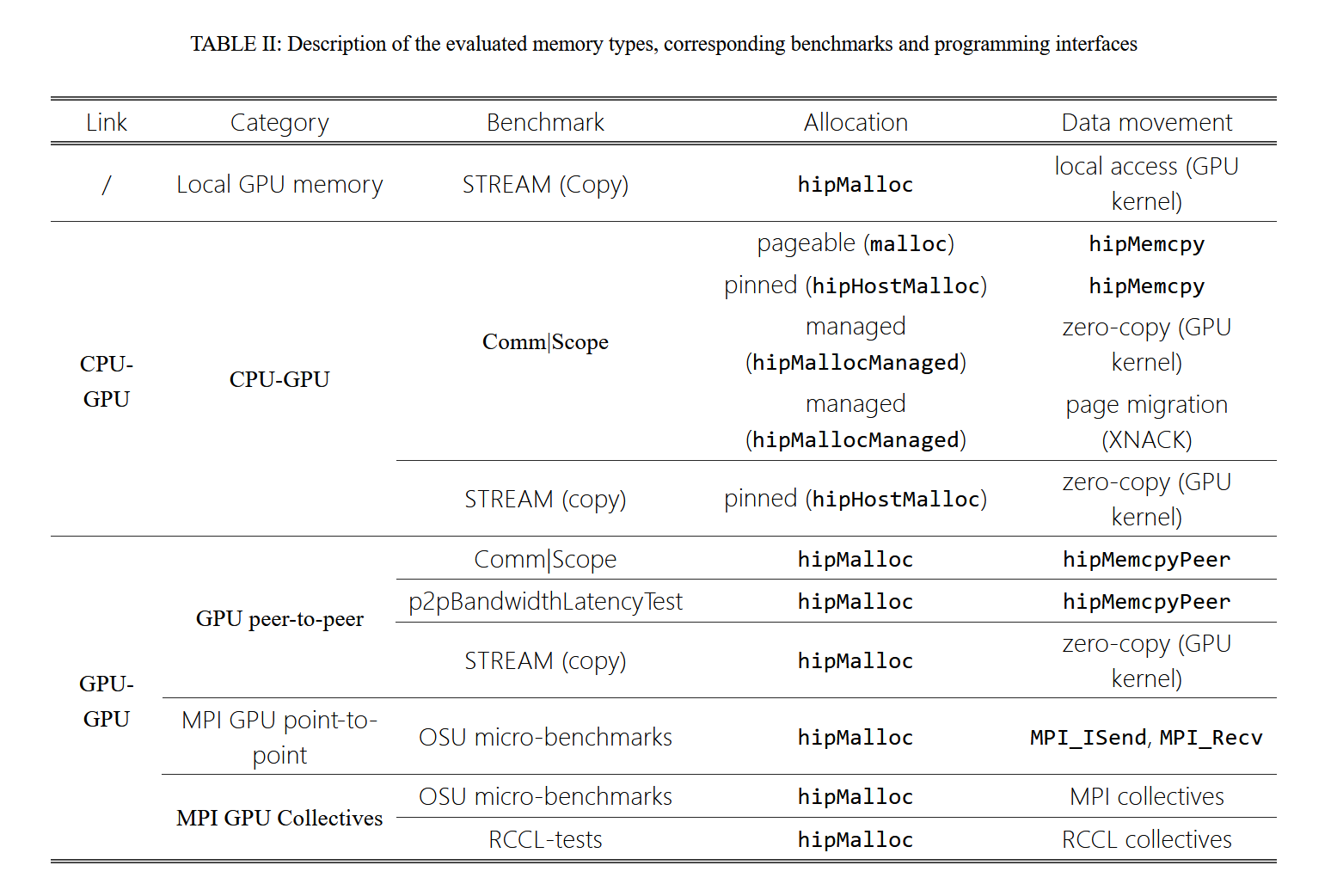
在这项工作中,我们采用了一种测试方法,用于量化和验证在不同计算对(包括 CPU-GPU 和 GPU-GPU)之间通过 Infinity Fabric 实现的数据传输的可实现性能。本文中使用的工具和基准测试的详细信息见表 2。一般来说,我们评估了不同传输大小下数据传输的带宽,以及 GPU-GPU 通信的延迟。
对于 CPU-GPU 数据传输,我们首先确定不同内存分配和内存访问接口可达到的基线峰值带宽。为此,我们使用了 Comm|Scope [12] 微基准测试中的主机到设备测试用例。Comm|Scope 是一组微基准测试,专注于多 GPU 多 CPU 系统上的数据传输。它为各种数据放置场景和数据传输接口提供了测试用例。我们还使用了 STREAM 基准测试的一个变体,来评估从 GPU 内核直接访问 CPU 内存的性能。MI250X 系统上的八个 GCD 中的每一个都作为一个可以独立编程的 GPU 呈现给用户。为了评估这一方面,我们将简单的 CPU-GPU STREAM 基准测试从一个 GCD 并行扩展到系统上的八个 GCD,我们还评估了放置策略对整体 CPU-GPU 总带宽的影响。
为了评估 GPU-GPU Infinity Fabric 互连的性能,我们采用了与 CPU-GPU 类似的方法,即我们既评估依赖 hipMemcpyPeer 的显式数据传输的性能,也评估 GPU 内核的直接内存访问性能。在这次评估中,我们将由不同层级的 GCD-GCD Infinity Fabric 链路组成的物理拓扑结构(如图 1 所示)与所实现的性能进行比较。这些实验总结在表 2 中。在这组测试中,除了 STREAM 基准测试和 Comm|Scope 之外,我们还使用了 p2pBandwidthLatencyTest 的 HIP 移植版本,这是英伟达提供的一个用于测量对等数据传输性能的基准测试 [13]。通过将使用这些 API 选项获得的性能与理论峰值性能进行比较,我们能够验证和评估数据传输的性能。
由于 HPC 用户在其应用程序中高度依赖 MPI 来实现进程间通信,因此在多 GPU 应用程序的背景下评估 MPI 例程的性能至关重要。因此,我们使用来自俄亥俄州立大学(OSU)微基准测试套件 [14] 的点对点带宽测试来完成我们的 GPU 对等分析,该测试依赖 MPI 进行通信。在这个实验中,我们旨在了解 MPI 通信使用的底层传输接口,以及利用 Infinity Fabric 互连实现直接 GPU-GPU 数据传输的能力。
除了点对点通信之外,多 GPU 集合通信的性能对于 HPC 和人工智能应用都非常重要。虽然 MPI 是一个可行的选择,但实现多 GPU 集合通信的专用库被广泛使用,尤其是在人工智能应用中。英伟达集合通信库(NCCL)和 AMD 的 RCCL 库是两个广泛使用的 GPU 集合通信库。在本文中,我们评估了 MPI 和 RCCL 的 GPU 集合通信性能。为此,我们使用了 OSU 集合微基准测试和 RCCL-tests 库。这种基准测试的选择总结在表 2 中。我们测量了五种集合通信(即 Reduce、Broadcast、AllReduce、ReduceScatter 和 AllGather)的延迟,涵盖了三种通信模式(即多对一、一对多和多对多)。我们将我们的结果与基于先前 GPU-GPU 延迟测试测量的简单最低理论界限进行比较。
对于我们的实验,我们使用了 ROCm 5.7.0,其中包括 HIP 运行时和 RCCL 库 2.17.1。作为我们的工具链,我们使用了 Cray 编程环境 23.12 中的编译器,以及 hipcc 编译器(ROCm 安装的一部分);这两个编译器都基于 LLVM/Clang 17。作为 MPI 实现,我们使用了系统上可用的 Cray-MPICH 8.1.28,我们通过启用环境变量 MPICH_GPU_SUPPORT_ENABLED=1 将其配置为支持 GPU。我们使用了 OSU 微基准测试的 7.4 版本。
四、中央处理器(CPU)与图形处理器(GPU)之间的通信
CPU 与 GPU 之间的数据传输是通过 CPU-GPU 的无限互联结构(Infinity Fabric)链路来实现的。一条 Infinity Fabric 链路的理论带宽为每个方向 36GB 每秒(双向 72GB 每秒),并且每个图形计算芯片(GCD)都恰好通过其中一条链路与 CPU 相连。作为参考,我们的 AMD EPYC CPU 的双倍速率同步动态随机存储器(DDR)内存延迟为 96 纳秒;CPU 内存带宽为 204.8GB 每秒。图 2 总结了我们使用 Comm|Scope 工具,在采用统一内存或 hipMemcpy 函数的情况下,所得到的 CPU 到 GPU 数据传输的结果,我们将在本节详细阐述这些内容。
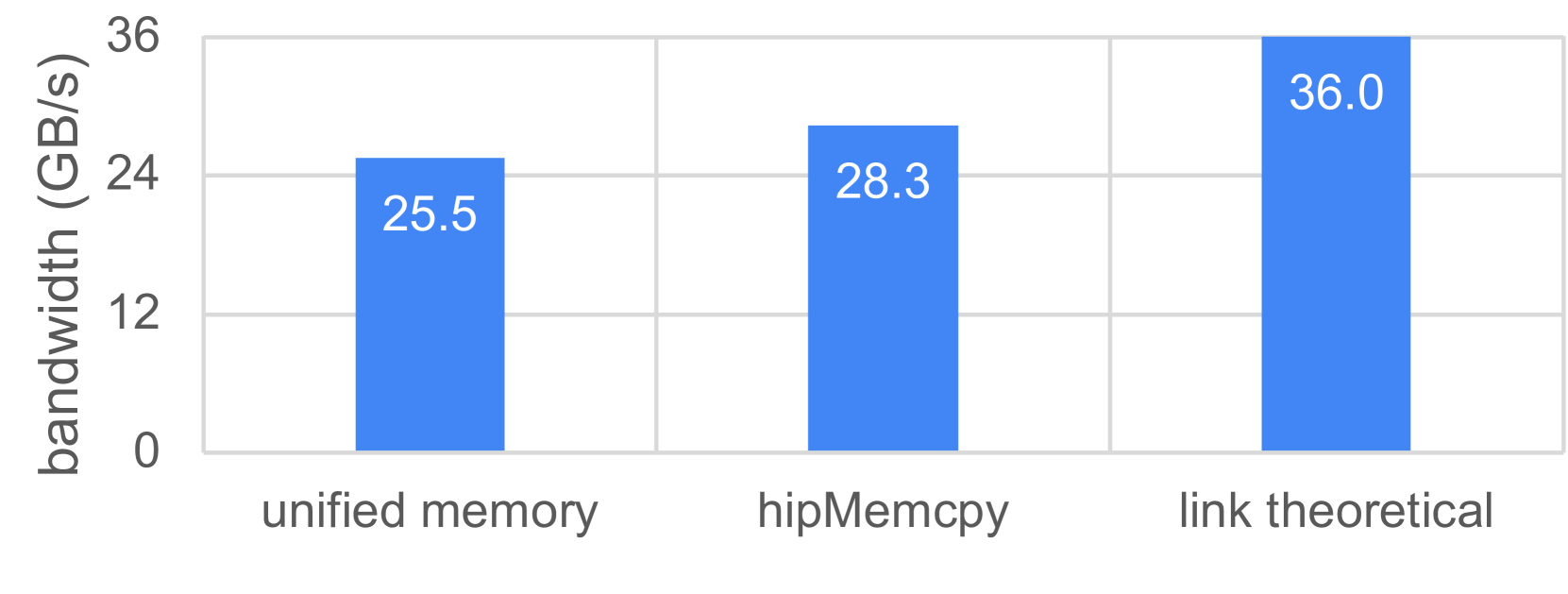
Figure 2: Peak achieved host-to-device bandwidth in our experiments, for direct GPU access to CPU memory with unified memory, and explicit data movements with hipMemcpy
(一)可实现的峰值带宽
我们采用与文献 [15] 中提出的类似方式,使用 Comm|Scope 工具 [12] 来评估在统一内存和显式数据传输这两种情况下,CPU 与 GPU 之间可实现的峰值带宽。图 3 展示了在主机到设备方向上,传输大小从 4KB 到 1GB 变化时的测试结果。显式数据传输通过 hipMemcpy 函数来完成,数据来源可以是可分页内存(通过 malloc 函数分配),也可以是主机固定内存(通过 hipHostMalloc 函数分配)。隐式数据传输则是使用托管内存,其方式要么是零拷贝(即 GPU 通过 Infinity Fabric 链路直接访问位于 CPU 端的内存),要么是页面迁移(即当 GPU 访问页面时,运行时会根据需要迁移这些页面)。
通过从固定内存进行显式数据传输,我们实现了 28.3GB 每秒的最大带宽。当增加传输大小时,可分页内存的表现会有所不同。这是可以预料到的,因为不可预测的分页操作可能会降低性能。对于隐式数据传输,采用页面迁移的托管内存仅实现了 2.8GB 每秒的带宽,而采用零拷贝访问的托管内存则实现了最高 25.5GB 每秒的带宽。
此外,在传输大小达到 32MB 之前,零拷贝托管内存的表现与固定内存相近,而在传输大小超过 32MB 之后,固定内存的带宽能够达到比托管内存更高的值。这一现象可能是由 32MB 的 GPU 三级缓存所导致的。这些结果表明,零拷贝内存能够实现 CPU 与 GPU 链路的高利用率,这使其成为对用户具有吸引力的编程接口。
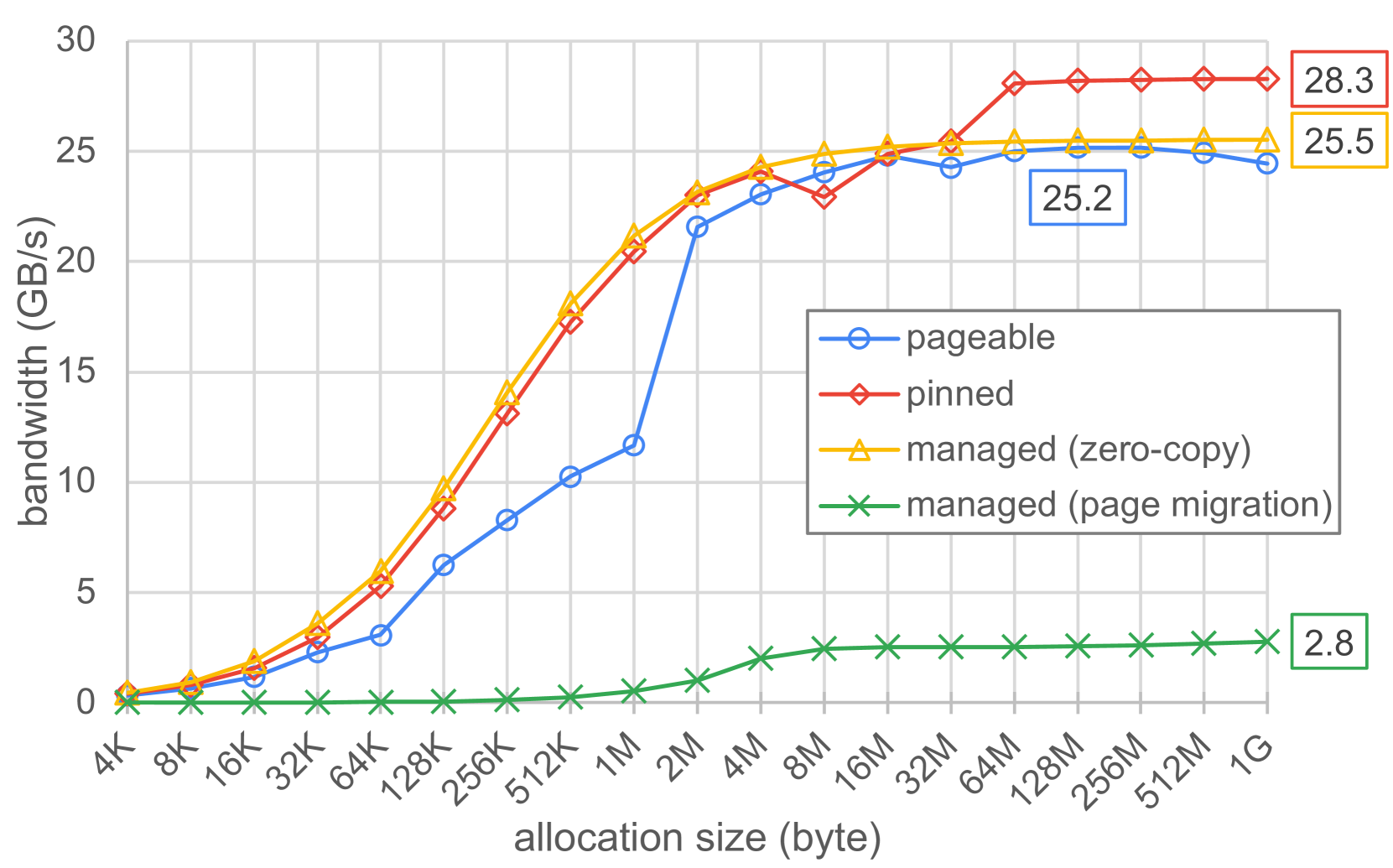
Figure 3: Host-to-device memory bandwidth at increased data transfer sizes, measured with Comm|Scope. The maximum for each interface is indicated in boxes.
(二)支持 GPU 感知的内存放置
所研究的 MI250X 计算节点的 CPU 内存被划分为四个非统一内存访问(NUMA)节点。每个节点都直接连接到一个物理 GPU 的两个 GCD;这种 NUMA 与 GCD 的映射关系可以通过 rocm-smi --showtoponuma 命令获取。在我们的测试平台上,这种映射关系与 “前沿”(Frontier)和 “鲁米”(LUMI)超级计算机上的完全相同,如图 1 所示。
从用户的角度来看,无需了解这种映射关系。实际上,默认情况下,hipHostMalloc 应用程序编程接口(API)会在距离当前活动 GPU 最近的 NUMA 节点上分配固定内存,当前活动 GPU 可通过例如 hipSetDevice 函数来选择。在我们的实验中,我们依靠这种特性在正确的 NUMA 节点上分配内存。
为了改变这种默认行为,用户可以通过向 hipHostMalloc 函数传递 hipHostMallocNumaUser 标志,指示运行时遵循用户自定义的 NUMA 放置策略。也可以采用其他方法来达到相同的目的,比如使用 numa_alloc_on_node 函数在一个 NUMA 节点上分配内存,然后再使用 hipHostRegister 函数将其固定。使用 Comm|Scope 的 “NUMA 到 GPU” 基准测试(该测试会强制将数据放置在选定的 NUMA 节点上),我们发现在非最优的 NUMA 节点与 GCD 组合中执行复制操作时,并未出现任何带宽下降的情况。这可以解释为,NUMA 节点之间的带宽比互联结构上的带宽要高得多。
(三)多 GPU 带宽
为了评估多 GPU 主机到设备传输的性能,我们使用 STREAM 复制内核,在系统中的每个 GPU 上启动一个内核,从一个 GPU 扩展到八个可用的 GPU。我们使用单线程程序,针对每个 GPU,在 CPU 端使用 hipHostMalloc 函数分配两个固定缓冲区。然后,为每个 GPU 启动一个 STREAM 复制内核,并在每个 GPU 的内核执行完毕后,强制进行 CPU 与 GPU 之间的同步操作。这样就可以测量所有 GPU 内核的总执行时间,进而得出总带宽。清单 1 展示了这种方法。双向带宽通过公式 BW = N_GPU * 2 * N /t 来计算,其中 t 是经过的时间,N 是一个缓冲区中的字节数。在我们的实验中,N 取值为 8GB。
// allocate host-pinned buffers
for(int i = 0; i < num_gpus; i++) {
hipSetDevice(i);
hipHostAlloc(&a[i], N);
hipHostAlloc(&b[i], N);
init_array<<<...>(a[i], N);
}
// launch one kernel per GPU
t0 = clock();
for(int i = 0; i < num_gpus; i++) {
hipSetDevice(i);
STREAM_Copy<<<...>>>(a[i], b[i], N); // b[i] ← a[i]
}
for(int i = 0; i < num_gpus; i++) {
hipSetDevice(i);
hipDeviceSynchronize();
}
t1 = clock(); Listing 1: Multi-GPU CPU-GPU STREAM benchmark
我们分别在一个、两个、四个和八个 GCD 上执行这个基准测试。在这个实验中,需要注意正确启动基准测试,以便其能够利用选定的物理 GPU。这可以通过系统的作业调度器来实现,例如使用 Slurm 的 --gpu-bind 选项。然而,这种解决方案可能并非在所有系统上都受支持,因此,为了执行我们的基准测试,我们将一个节点中的所有 GPU 都分配给基准测试进程,并使用 HIP_VISIBLE_DEVICES 环境变量来限制实际使用的 GPU。
在第一个实验中,我们将基准测试从一个 GCD 扩展到两个 GCD。对于两个 GCD 的执行情况,我们评估了两种放置策略:一种是选择在同一物理 GPU 的两个 GCD 上执行(即 “相同 GPU” 策略),另一种是将内核启动分散到属于不同物理 GPU 的两个 GCD 上(即 “分散” 策略)。图 4 展示了所实现的总带宽。我们观察到,只有 “分散” 策略能够正确地扩展性能,因为在 “分散” 放置策略下,从一个 GCD 增加到两个 GCD 时,带宽翻倍。相比之下,使用同一 GPU 的两个 GCD 并没有比单个 GCD 带来带宽上的提升。这可能是因为 CPU 的每个 NUMA 域要处理两条 Infinity Fabric 链路所导致的 [15]。在传输大小较小的情况下,通常是在 CPU 缓存大小范围内,Infinity Fabric 链路上可能会表现出更高的带宽。
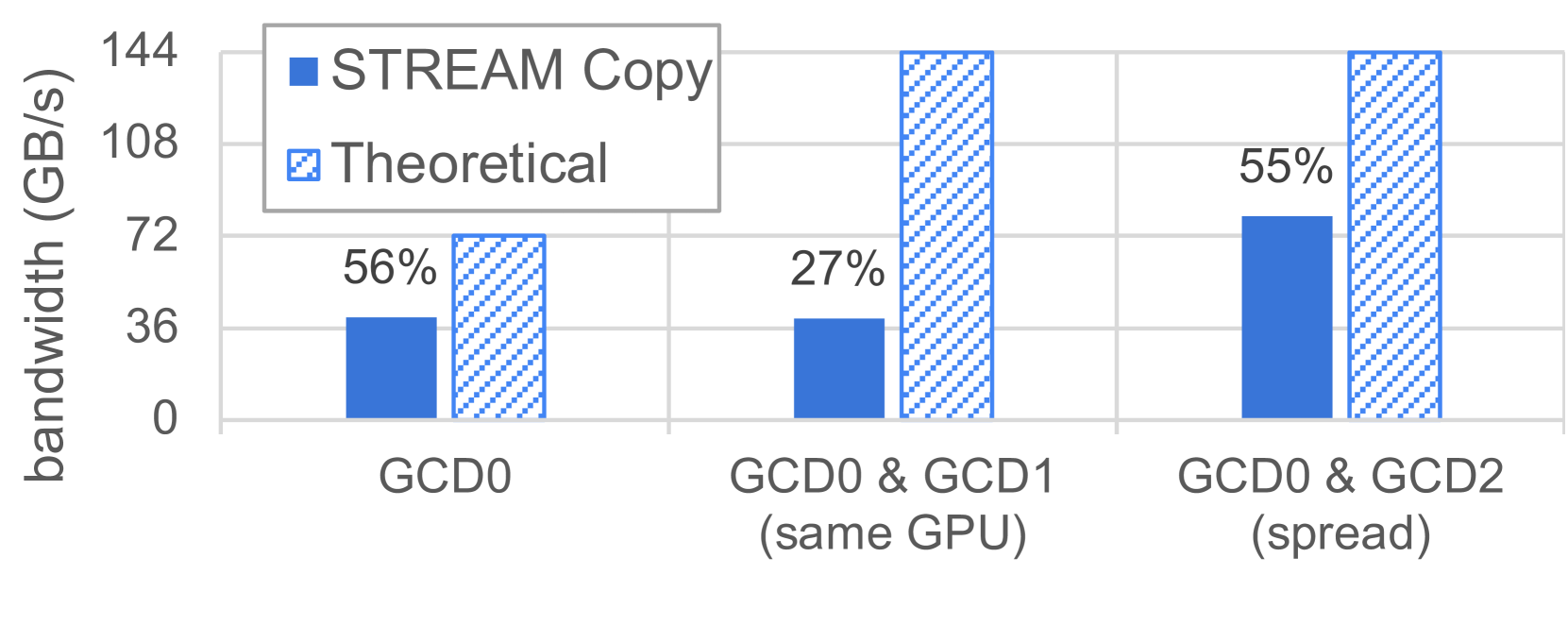
Figure 4: Total bidirectional CPU-GPU bandwidth, measured using STREAM copy kernels, parallelly-running on one or two GCDs. For the dual-GCDs cases, the two GCDs are either located on a single physical GPU (same GPU), or on two distinct physical GPUs (spread). The achieved percentage of theoretical bandwidth is presented.
遵循相同的方法,我们重复这个实验,使用 “分散” 放置策略,将基准测试从一个 GCD 扩展到八个 GCD。图 5 展示了所有使用链路的聚合带宽,以及理论带宽和所实现带宽占理论带宽的百分比。我们观察到,在 1 到 4 个 GCD 的范围内扩展时,带宽会随着使用的 GCD 数量成比例增加。然而,与使用四个 GCD 相比,使用八个 GCD 并没有提高聚合带宽。这是可以预料到的,因为我们之前已经表明,在单个物理 GPU 上同时使用两个 GCD(本次实验中的情况就是如此)并不会增加测量到的带宽。
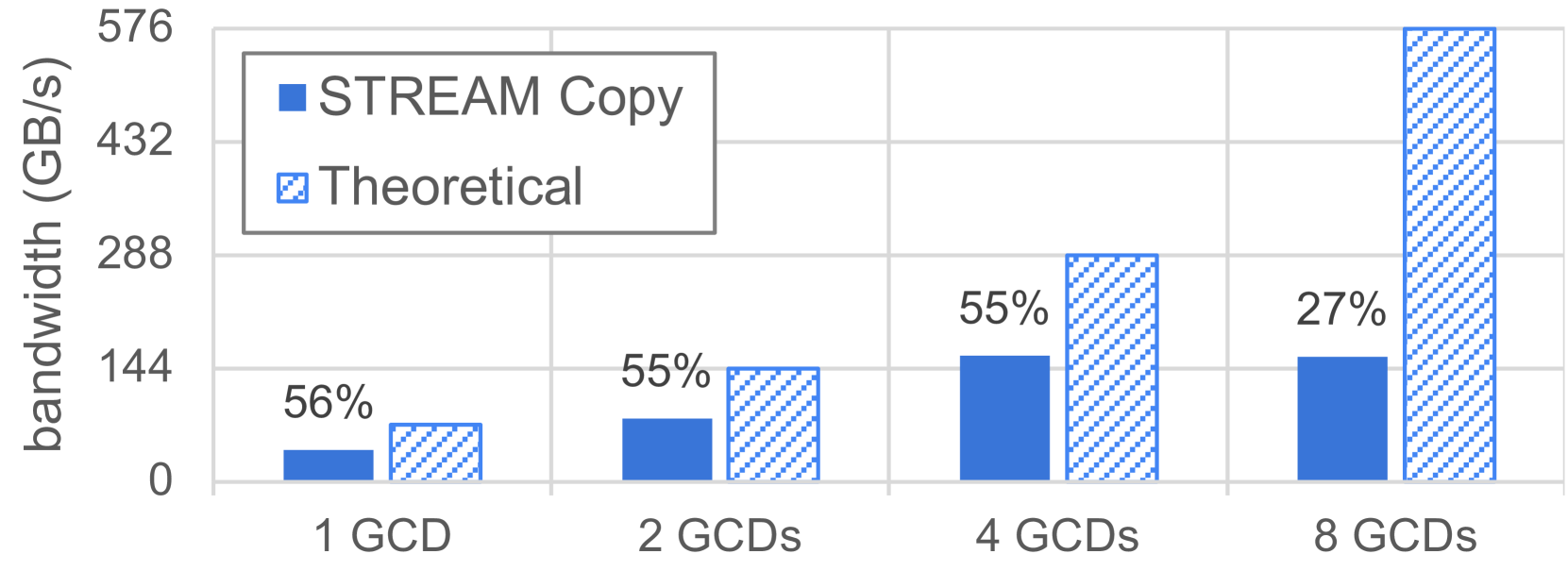
Figure 5: Total bidirectional CPU-GPU bandwidth, measured using STREAM copy kernels, parallelly-running on one to eight GCDs. The achieved percentage of theoretical bandwidth is presented.
5. 点对点 GPU 通信
在本节中,我们将评估两个图形计算芯片(GCD)之间的点对点通信。有两个异构计算平台(HIP)接口可以支持用户执行此类通信,即通过 hipMemcpyPeer 应用程序编程接口(API)进行的显式数据传输、统一内存,以及支持 GPU 感知的消息传递接口(MPI)点对点通信。
5.1 显式对等数据传输
5.1.1 延迟
我们首先使用 p2pBandwidthLatencyTest 工具来量化 hipMemcpyPeer 操作的延迟。作为我们分析的参考,图 6(a)根据跳数可视化了任意两个给定 GCD 之间最短路径的长度。在这个拓扑结构中,最短路径的长度从不超过两跳。然而,虽然就跳数而言,这样的路径是最短的,但它并没有使带宽最大化。例如,GCD 1 和 7 通过两跳的最短路径(1 - 3 - 7)连接;然而,使带宽最大化的路径由三跳组成(1 - 0 - 6 - 7)。
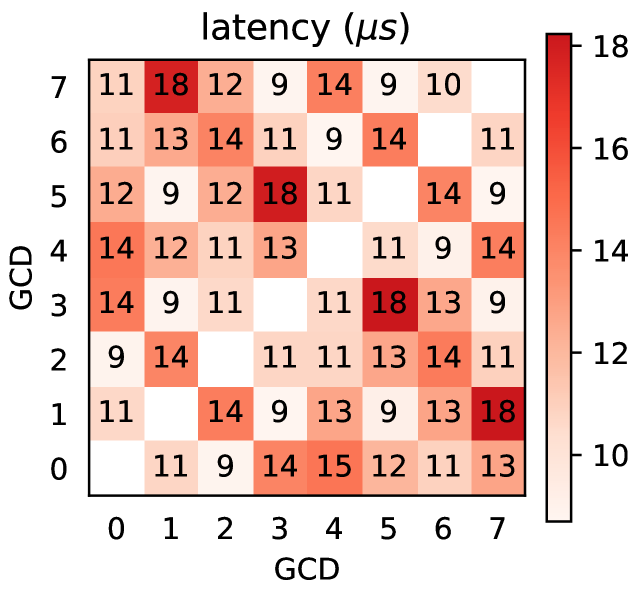
我们使用经过 HIP 化的 p2pBandwidthLatencyTest 版本来测量对等显式数据传输的延迟。为此,我们使用 hipMemcpyPeerAsync API,传输大小为 16 字节。在源 GCD 和目标 GCD 上都使用 hipMalloc 分配内存。使用 hipDeviceEnablePeerAccess API 使内存对对等方可用。使用 HIP 事件 API 在 GPU 端对 hipMemcpyPeerAsync 操作进行计时来测量延迟。每个实验重复 100 次。结果以矩阵形式显示在图 6(b)中。
测量到的延迟在 8.7 - 18.2 微秒之间变化。位于同一物理 GPU 上的 GCD 之间测量到的延迟在 10.5 - 10.8 微秒之间,这并不总是低于其他 GCD 对测量到的延迟。有趣的是,GCD 对 0 - 2、1 - 3、1 - 5、3 - 7、4 - 6、5 - 7 的延迟低于 10 微秒。与图 1 中所示的拓扑结构相比,我们观察到这些对正是通过单个 Infinity Fabric 链路互连的那些。
此外,我们观察到四个异常值,延迟值在 17.8 - 18.2 微秒之间,对应于 GCD 对 1 - 7 和 5 - 3。我们注意到这两对是仅有的带宽最大化路径不是最短路径的情况。这可能表明即使对于低传输大小,hipMemcpyPeer 也使用带宽最大化路径而不是最短路径。这与 hipMemcpyPeer 的目的是一致的,与例如在统一内存中使用直接零拷贝访问执行的细粒度访问相比,它允许进行大尺寸传输。
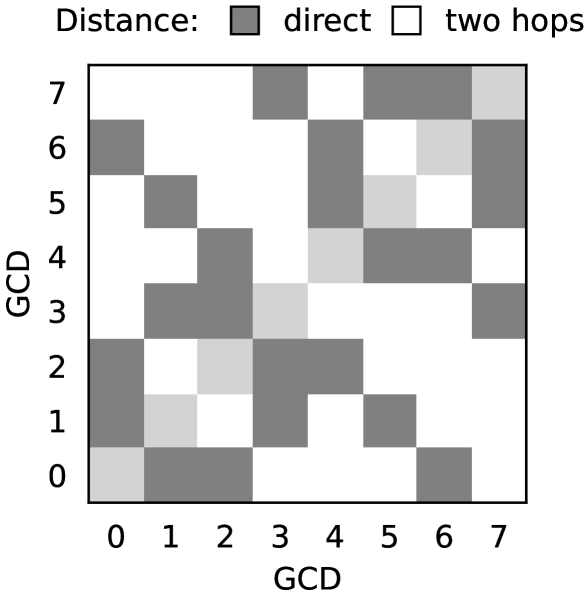

(a) Length of shortest path (b) Latency (c) Bandwidth
Figure 6: Length of shortest path for each given GCD pairs (6(a)), peer-to-peer GPU latency (6(b)) and unidirectional bandwidth (6(c)), measured with p2pBandwidthLatencyTest.
5.1.2 带宽
我们使用 p2pBandwidthLatencyTest 基准测试来测量每对 GCD 之间的单向带宽,该基准测试依赖于 HIP API 来执行复制操作。图 6(c)展示了结果。我们可以将结果分为两个带宽值:50GB/s 和 37 - 38GB/s。这个结果是出乎意料的,因为应该观察到三个不同级别的带宽,即对于单向、双向和四向链路分别为 50GB/s、100GB/s 和 200GB/s。特别是,位于同一 GPU 上的 GCD 对(0 - 1、2 - 3、4 - 5 和 6 - 7)测量到的带宽约为 50GB/s,这明显低于预期的 200GB/s 带宽。这表明使用 hipMemcpyPeer 进行的单个复制操作无法充分利用 GCD 间链路的全部带宽。AMD 记录了这种行为,这表明用于 hipMemcpy 的系统直接内存访问(SDMA)引擎是为 PCIe - 4.0 x16 调整的,无法利用 GPU - GPU Infinity Fabric 互连的全部带宽。使用 SDMA 引擎的优点是 hipMemcpy 的使用可以与计算重叠,而不会影响内核性能。可以通过设置环境变量 HSA_ENABLE_PEER_SDMA = 0 来禁用 SDMA 引擎的使用,而是为 hipMemcpyPeer 使用专门的 “blit” 复制内核。
此外,根据这些结果,我们可以确认使用 HIP 内存复制 API 进行对等通信时选择的路径倾向于优化带宽而不是延迟。实际上,对于 GCD 对 1 - 7 和 3 - 5 测量到的 50GB/s 带宽只能通过三跳路径实现,比这些对的最短两跳路径更长。
我们通过运行针对 hipMemcpyPeer 的 Comm|Scope 基准测试来进一步完成这个高级分析,从 GCD0 到直接连接的 GCD(即 GCD {1,2,6})执行相同的对等复制。图 7 展示了数据传输大小在 256 字节到 8GB 之间的带宽。我们得到了与图 6(c)中相当的值。在这种情况下,对于所有传输大小,hipMemcpyPeer 无法充分利用四向 Infinity Fabric 链路的观察结果仍然有效。单向、双向和四向 Infinity Fabric 链路的带宽利用率分别为 75%、50% 和 25%。
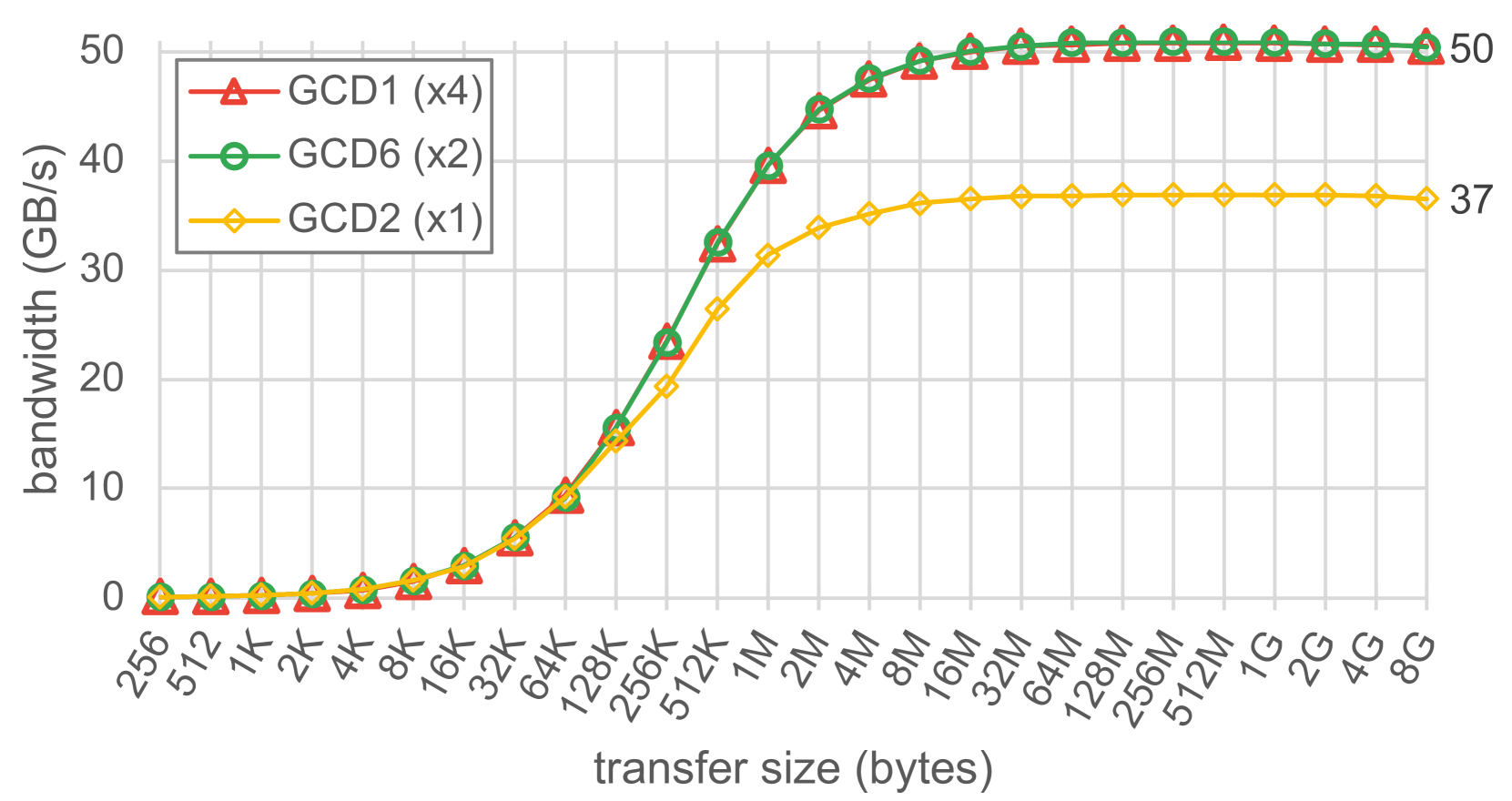
Figure 7: Peer-to-peer unidirectional bandwidth of a hipMemcpyPeer operation, from GCD0 to adjacent GCDs, measured with Comm|Scope. The theoretical link bandwidth is indicated in parenthesis, as multiple of 50+50 GB/s links.
5.2 直接内存访问
为了描述直接访问对等方内存的性能,我们使用 STREAM 复制内核,方式与评估 CPU - GPU 互连时类似。复制内核在 GCD0 上执行,数据放置在相邻的 GCD 上,即 GCD {1,2,6}。作为参考,当在本地 GCD0 内存中放置数据使用相同的基准测试时,我们观察到带宽为 1400GB/s,即理论 1.6TB/s 内存带宽的 87%。图 8 报告了这三种放置方式下随着大小增加(直至 8GB)的复制带宽。我们观察到测量带宽值的三个层级,代表连接 GCD0 与其邻居的 Infinity Fabric 链路的三个层级:单向连接到 GCD2、双向连接到 GCD6 和四向连接到 GCD1。图 9 展示了实现的带宽以及基于单个 Infinity Fabric 链路 50 + 50GB/s 的理论带宽的实现比率。对于所有放置方式,我们观察到理论峰值的实现比率为 43 - 44%。我们没有观察到使用 hipMemcpy API 时确定的相同瓶颈,即使用四向 Infinity Fabric 链路与使用双向链路相比没有任何改进。如前所述,这是因为对远程内存的内核级访问不使用带宽有限的 SDMA 引擎。
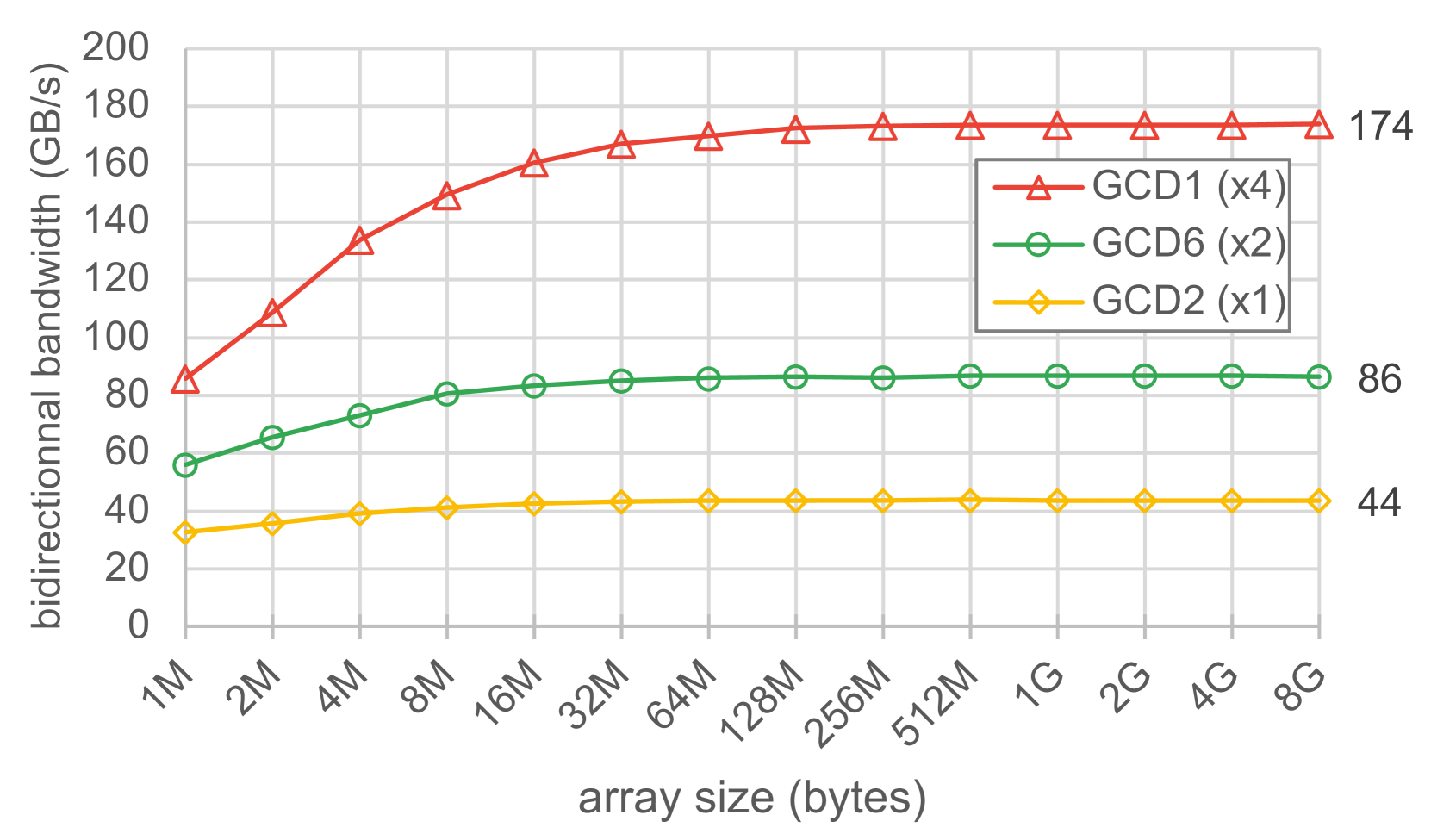
Figure 8: Bidirectional bandwidth measured with the STREAM copy kernel, executed on GCD0, with data placement on adjacent GCDs, namely GCD{1,2,6}, for increasing array sizes. The theoretical link bandwidth is indicated in parenthesis, as multiple of 50+50 GB/s links.
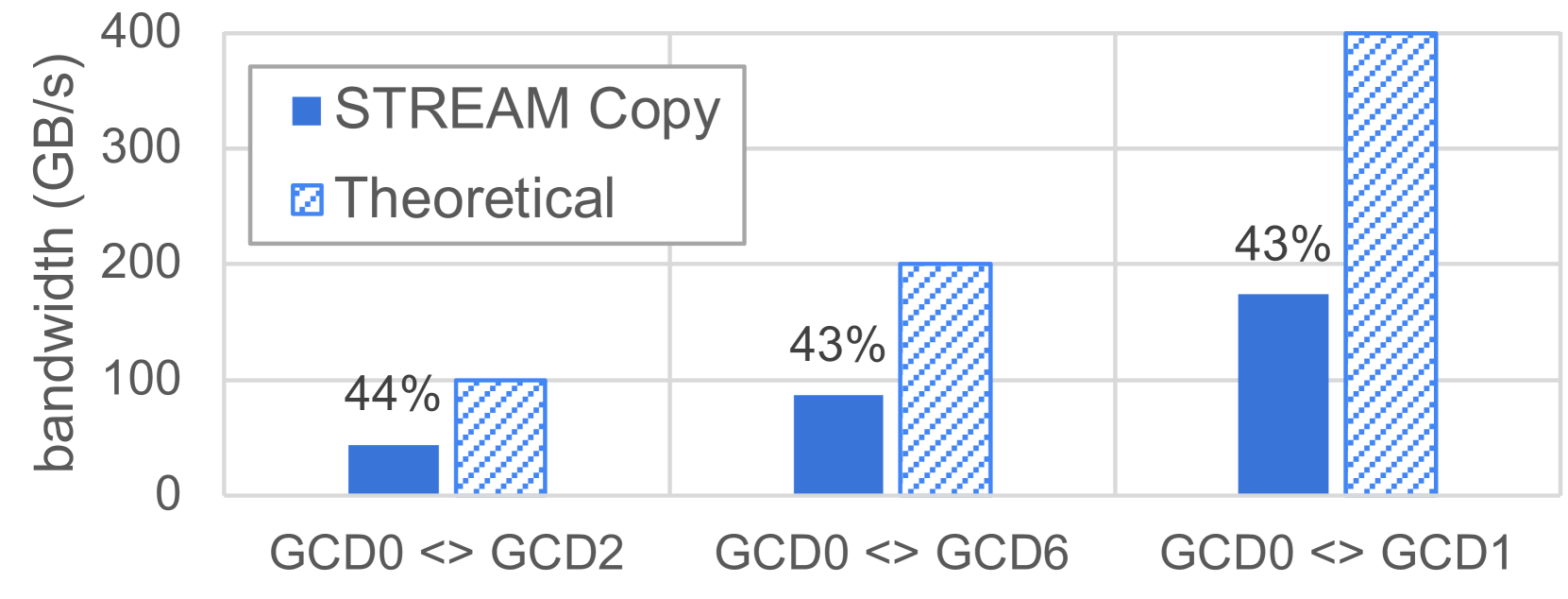
Figure 9: Peak bidirectional bandwidth, measured with the STREAM copy kernel, executed on GCD0, with data placement on adjacent GCDs, namely GCD{1,2,6}. Theoretical bandwidth is based on 50+50 GB/s for a simple Infinity Fabric link. Percentage values represent the ratio between measured and theoretical bandwidth.
5.3 支持 GPU 感知的 MPI 通信
MPI 在高性能计算(HPC)应用中常用于点对点通信。最近支持 GPU 感知的 MPI 实现可作为基于 HIP 通信的替代方案。在本节中,我们使用供应商提供的 Cray MPICH 实现,它支持直接的对等 GPU 通信。我们使用俄亥俄州立大学(OSU)的 MPI 点对点带宽基准测试 [14],该测试依赖于 MPI_ISend 和 MPI_Recv 在两个 MPI 进程之间执行数据传输,每个进程连接到一个 GPU。我们发现 HSA_ENABLE_SDMA 环境变量会影响带宽,这表明 MPICH 实现执行的数据传输可能依赖于类似 hipMemcpy 的接口。
图 10 展示了从 GCD0 向其他 GCD 发送数据的 OSU 点对点带宽基准测试的带宽。同时展示了 MPI 和使用类似 STREAM 内核的直接对等通信的结果。对于 MPI 基准测试,我们提供了使用 SDMA 引擎(启用 SDMA 且类似 hipMemcpy)和使用直接复制内核(禁用 SDMA 且使用复制内核)的结果。
正如预期的那样,使用 SDMA 提供的带宽不理想,低于 50GB/s,这与显式数据传输的对等结果(在第 V - A2 节中)类似。请注意,使用 SDMA 引擎的优点是 MPI_ISend 操作可以与 GPU 内核执行重叠。由于 GCD0 与 GCD {2,3,4,5} 之间的最大单向带宽为 50GB/s,使用 SDMA 引擎仍然可以高利用率地利用可用带宽。然而,从 GCD0 到 GCD {1,6,7} 的结果不同,因为这些链路具有更高的可用带宽。在这里,启用 SDMA 的 MPI 传输仅达到 50GB/s,对于双向 Infinity Fabric 链路低于 50%,对于四向链路为 25%。因此,如果不需要或不可能将数据传输与 GPU 内核执行重叠,建议通过设置环境变量 HSA_ENABLE_SDMA = 0 来禁用 SDMA 数据传输。
有趣的是,禁用 SDMA 的 MPI 传输比直接对等复制内核的带宽低 10 - 15%。这种差异可能来自 MPI 通信中的开销,与 HIP 中直接实现复制内核相比。此外,我们观察到从 GCD0 向非邻居 GCD(即 GCD3、4、5、7)传输数据与向邻居 GCD 传输数据相比,在测量带宽上没有显著差异。
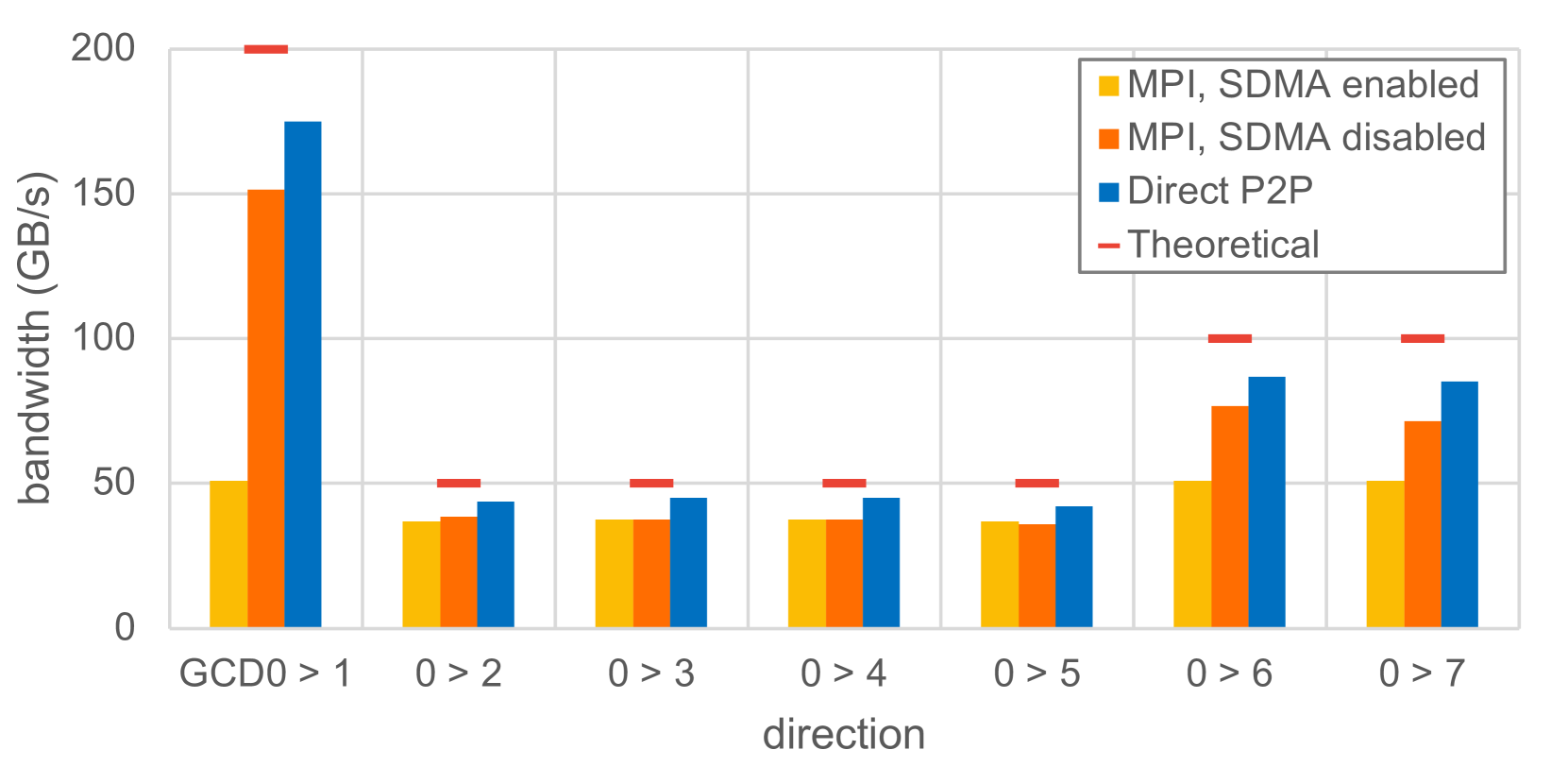
Figure 10: Unidirectional bandwidth of MPI point-to-point communication, measured with the OSU microbenchmarks (message size: 1 GiB), “direct P2P” is the bandwidth for a unidirectional STREAM copy from peer to local memory.
六、GPU 集合通信
当多个 GPU 需要通信时,使用集合通信可能比利用点对点通信精心设计的算法更有效。在本节中,我们研究五种常用集合通信(Reduce、Broadcast、AllReduce、ReduceScatter 和 AllGather)的延迟。这些集合通信可以分为两类:对于 Reduce 和 Broadcast,只需要从所有 GCD 到一个 GCD(或从一个 GCD 到所有其他 GCD)进行一次通信传递。对于 AllReduce、AllGather 和 ReduceScatter,需要两次通信传递,其中第一次传递将所有 GCD 的数据聚合为一个结果,然后将结果传播回所有 GCD。我们使用集合 OSU 微基准测试并研究两个常见接口:MPI 集合通信和 RCCL 集合通信。

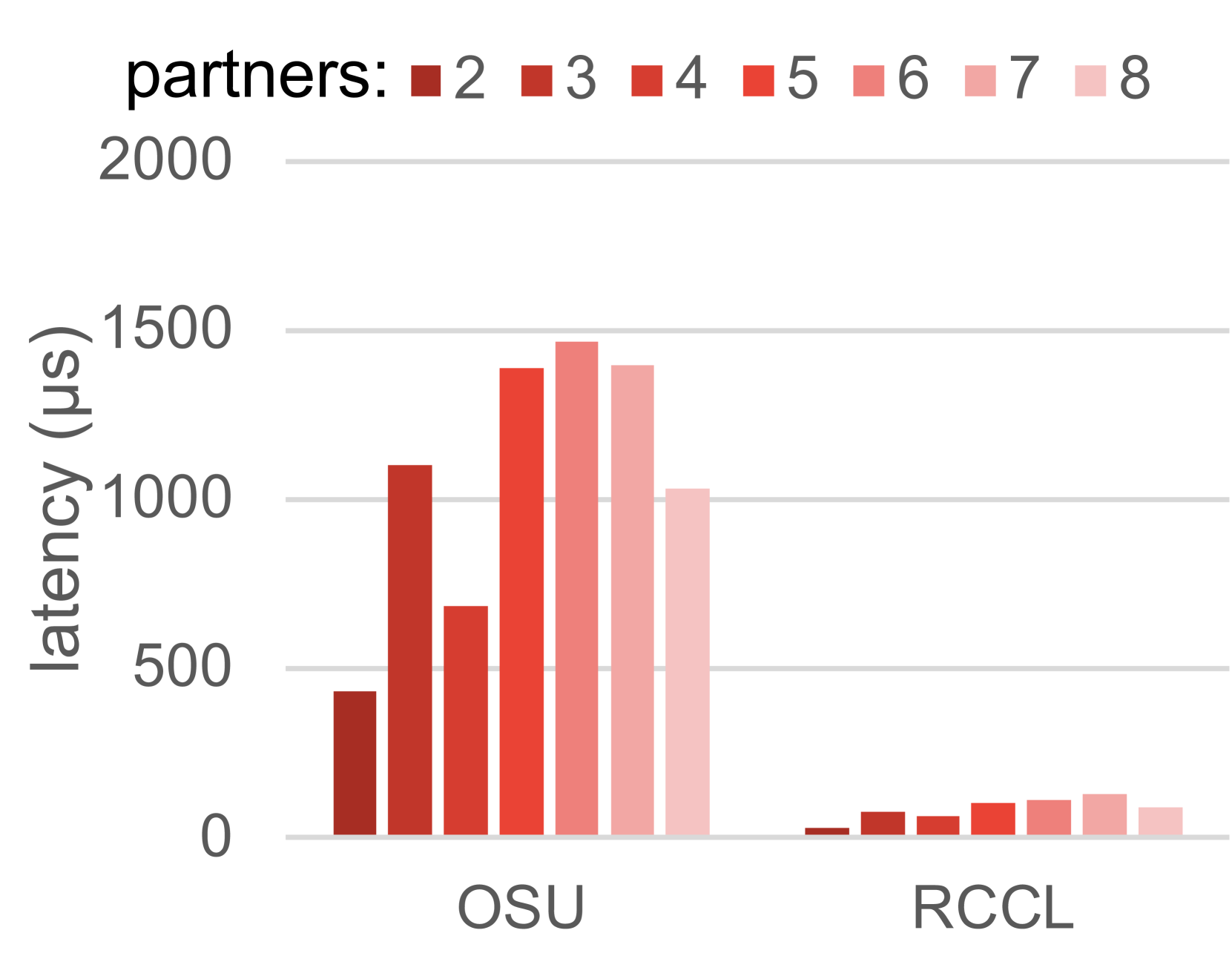
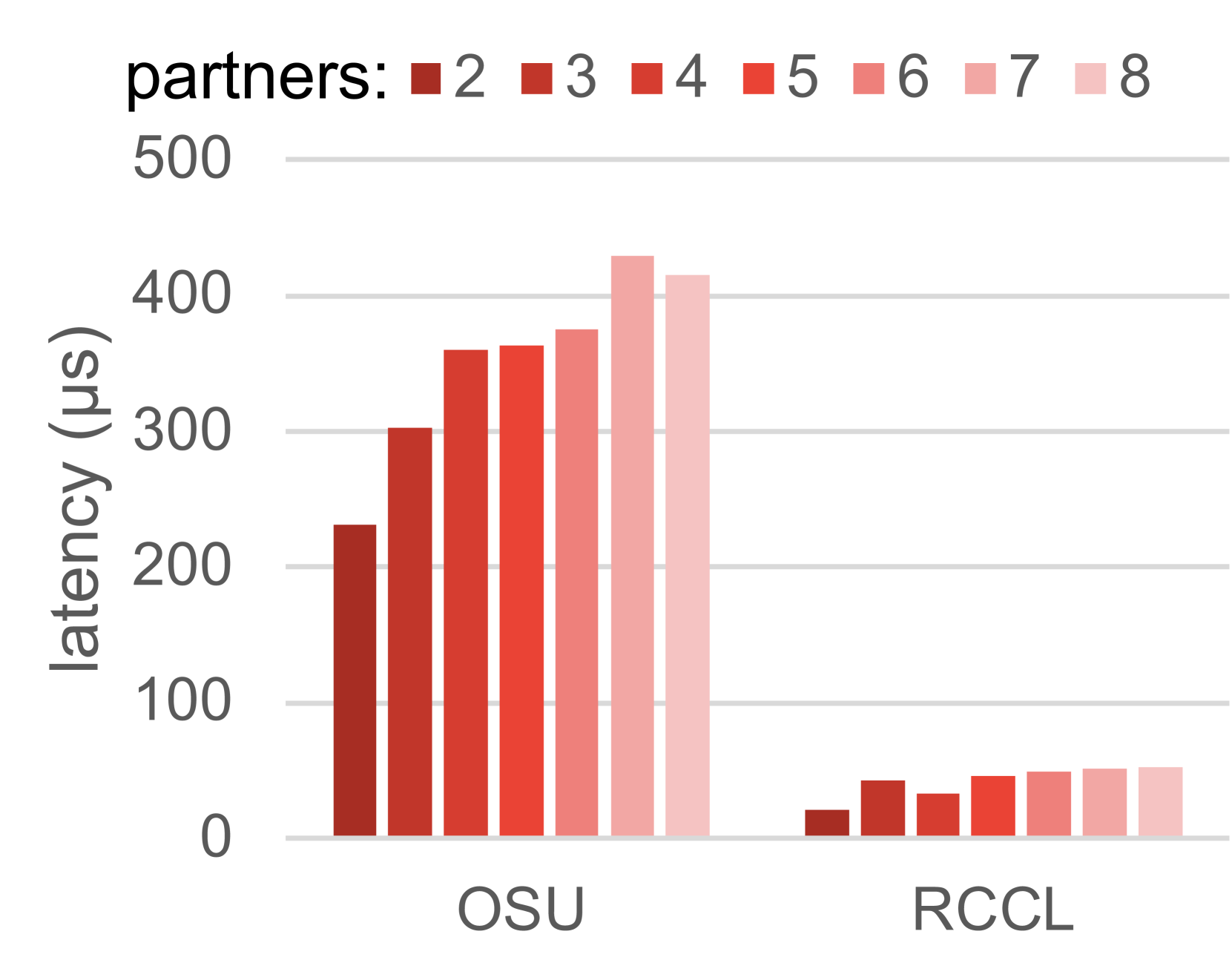
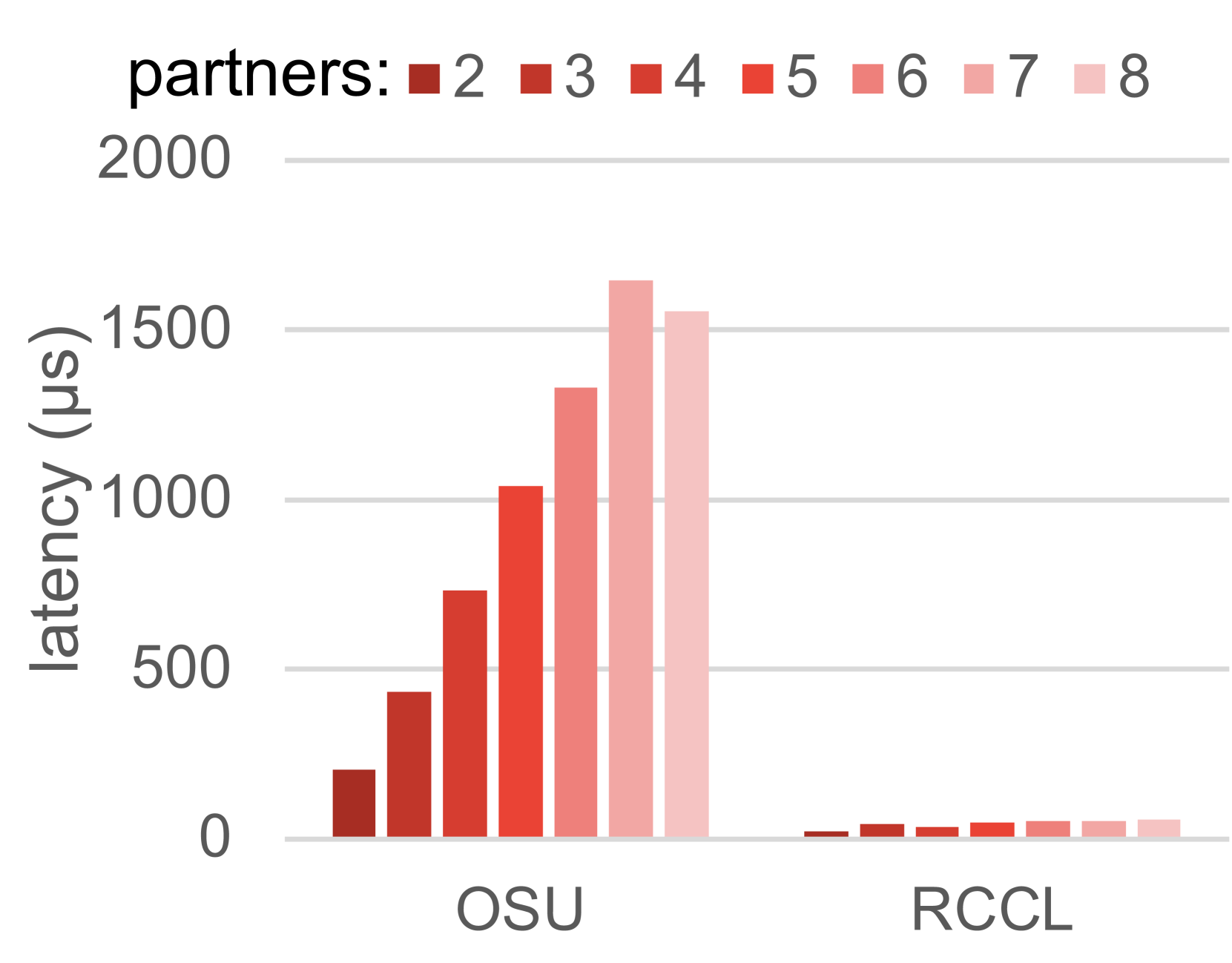
(a) Reduce (b) Broadcast (c) AllReduce (d) ReduceScatter (e) AllGather
Figure 11: Latency of five collective operations (11(a)-11(e)) with OSU micro-benchmarks, compared to RCCL, using two to eight communication partners (message size: 1 MiB), each partner uses one GPU. For MPI, a partner is a MPI process, for RCCL, a partner is a CPU thread.
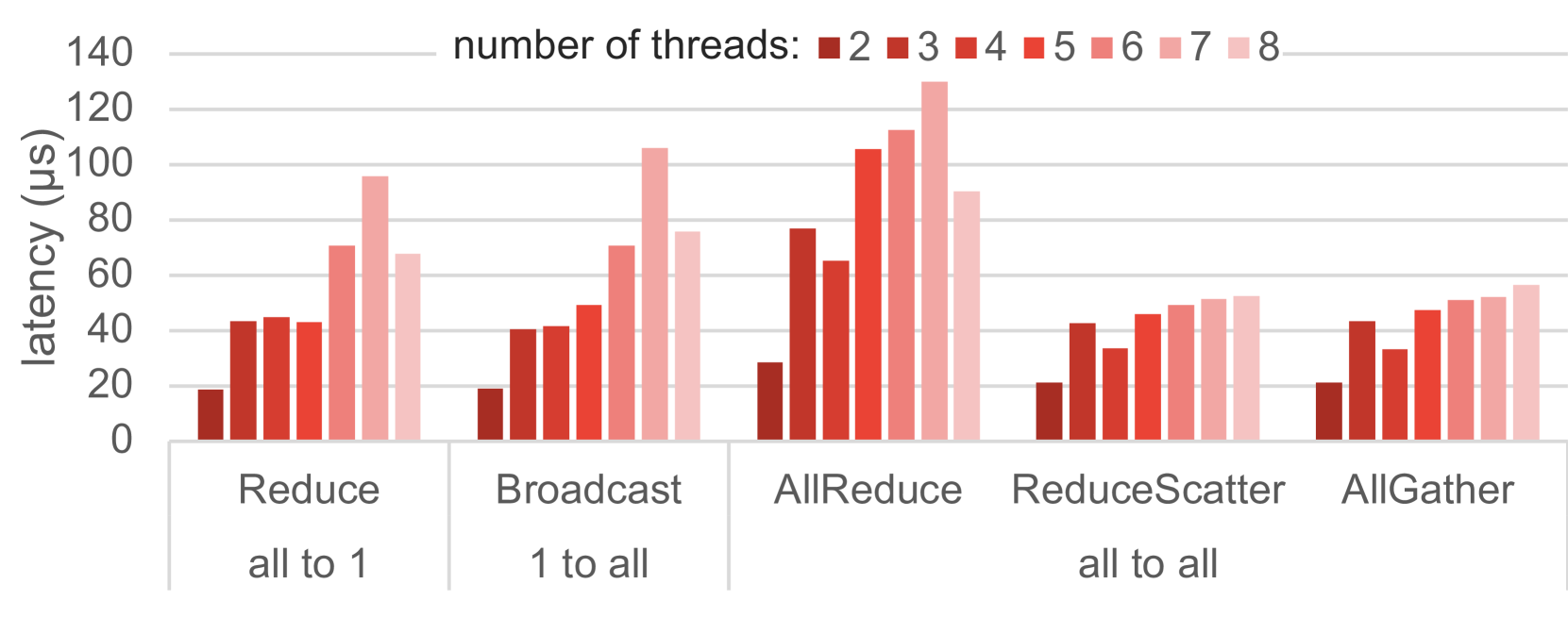
Figure 12: Latency of five collective operations in RCCL, with two to eight CPU threads. Each thread takes part in the collective operation, one GPU per thread.
从分析角度来看,我们可以从图 6(b)中呈现的延迟矩阵来近似这两类集合通信的延迟下限,该矩阵报告了所有 GCD 对之间的通信延迟。取最低的 GCD - GCD 延迟 8.7 微秒,单轮集合通信延迟的下限为 8.7 微秒,双轮集合通信的延迟应至少为 17.4 微秒。
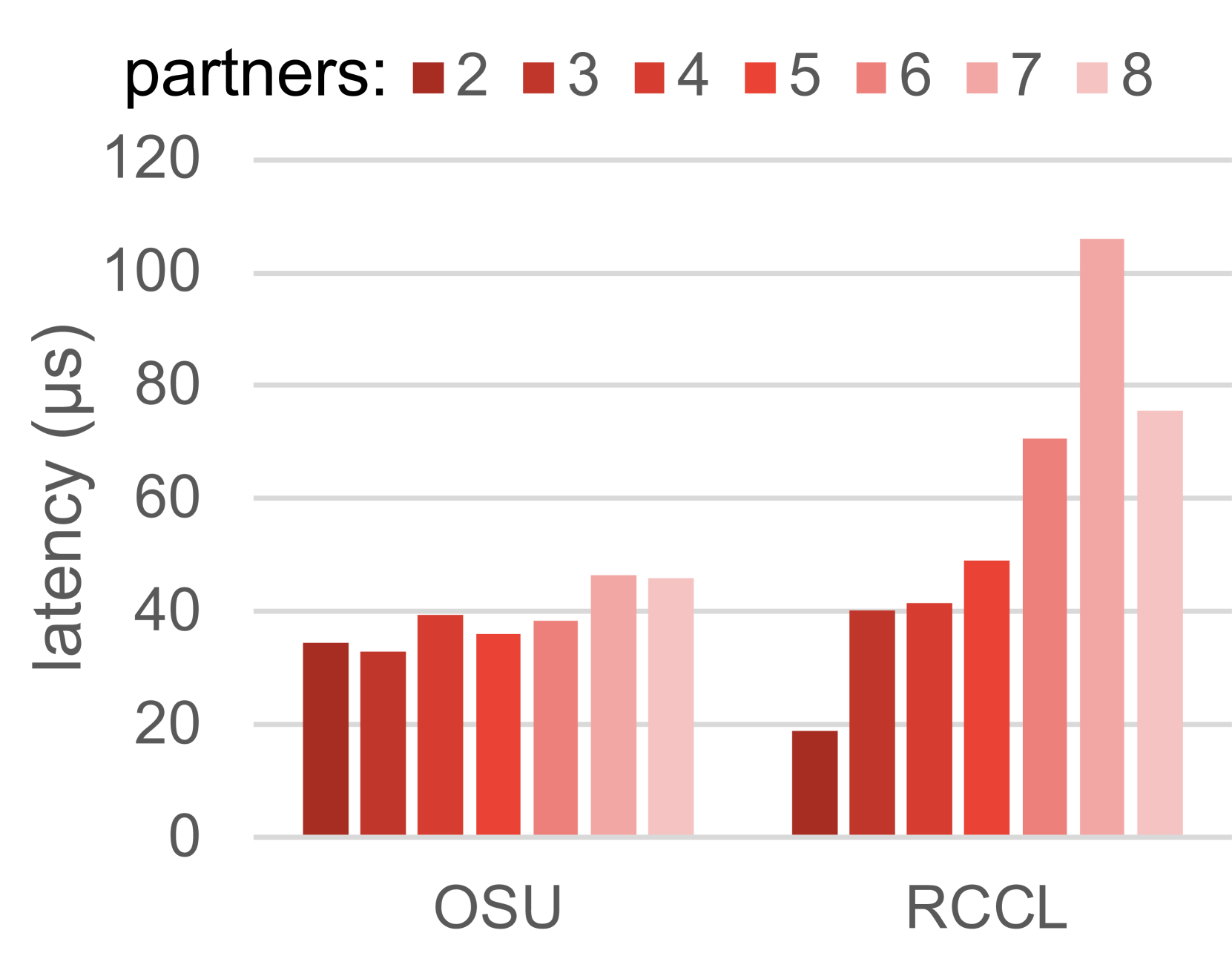
图 12 展示了 RCCL 集合通信中测量到的延迟。对于两个线程,多对多集合通信测量到的最低延迟接近 17.4 微秒的下限。当线程数量增加到 2 以上时,延迟如预期增加,因为多对多操作的实现可能不会遵循能够实现最低延迟下限的简单模式。有趣的是,对于 Reduce、Broadcast 和 AllReduce 集合通信,当从 7 个线程增加到 8 个线程时,延迟下降,这可能是由于使用所有 8 个 GPU 时通信模式更加平衡。
图 11 比较了在 1MB 数组上 MPI 和 RCCL 集合通信的测量延迟。我们的评估结果表明,除了广播之外,对于所有测试的集合通信,RCCL 比 MPI 集合通信更高效。之前的工作 [16] 也报告了类似的发现。MPI 集合通信的性能开销可能来自内存映射开销,其中需要额外的开销来将 HIP 指针交换并映射到每个进程的虚拟内存空间中,以支持 MPI 中的 CPU 侧进程间通信。请注意,尽管与 MPI 相比,RCCL 在单个节点内更高效,但 RCCL 依赖 MPI 进行多节点通信,因此,对于多节点集合通信的结论可能不同。
七、相关工作
之前已经对 AMD MI250X GPU 的各个方面进行了研究。Pearson 等人 [15] 专注于节点内 MI250X GPU 之间的互连性能。Schieffer 等人 [17] 专注于 AMD MI250X GPU 上的矩阵核心单元。相比之下,我们的工作侧重于多 GPU 节点上数据访问和通信的各种编程接口的效率。Leinhauser 等人 [18] 为 AMD GPU 设计并开发了一个指令屋顶线模型。他们专注于问题大小和 GPU 启动配置对 V100、A100、MI100 和 MI250X 图形处理单元屋顶线性能的影响。Eberius 等人 [19] 扩展了屋顶线模型以考虑问题大小,并使用饱和问题大小作为附加性能指标来描述 AMD250X GPU 上的强扩展性。Punniyamurthy 等人 [20] 通过在机器学习工作负载中利用 GPU 发起的通信和不同 GPU 之间的通信来研究将计算与相关集合通信融合的优势。
其他工作也评估了用于节点内通信的编程系统和库的性能。Godoy 等人 [21] 评估了高级编程模型(包括 Julia、Python/Numba 和 Kokkos)在具有多个 AMD GPU 的 HPC 节点上的性能和可移植性。Nek5000 的 HipBone [22] 代理应用程序被开发为性能可移植的 GPU C++ 版本,以描述不同 GPU(包括 AMD MI250X)的性能。
在 AMD GPU 内存系统方面,Jin 等人 [23] 专注于使用 HIP 编程接口的统一内存的性能。他们得出结论,虽然统一内存可以提高可编程性,但它的使用会带来显著的开销,影响 AMD GPU 的性能。在英伟达 GPU 上也进行了类似的工作。Chien 等人 [24] 研究了内存策略和提示对英伟达 GPU 上 CUDA 托管内存的影响。Schieffer 等人 [25] 研究了英伟达 Grace Hopper 超级芯片上可用的集成 CPU - GPU 系统内存。Li 等人 [26] 通过 Tartan 基准测试套件分析了英伟达 GPU 的互连。在这项工作中,在 AMD GPU 上进行了类似的实验,以便对这两种架构进行比较。一些关于多 GPU 的特定应用工作也研究了 AMD GPU 上的性能。他们专注于改进内存管理和数据传输,例如多 GPU 量子计算模拟 [27, 28] 和图处理工作负载 [29]。
八、结论
在这项工作中,我们评估了使用 Infinity Fabric 将 CPU 与八个 AMD Instinct GCD 互连的多 GPU 节点上的各种数据传输选项。测试平台代表了与第一台百亿亿次超级计算机 “前沿” 超级计算机类似的拓扑结构。我们的测试方法从确定峰值硬件容量开始,并评估了各种数据传输的软件选项,包括 CPU - GPU、点对点 GPU - GPU 和 GPU 集合通信。我们的结果量化了内存分配策略对 AMD CPU 和 GPU 之间数据传输的影响。对于集合通信的性能,我们在 AMD 多 GPU 节点上比较了 MPI 和 RCCL 库。我们的结果强调,尽管多 GPU 拓扑结构被抽象为一个简单而灵活的编程模型,但为了在数据传输中实现硬件能力的高利用率,必须考虑其复杂性。特别是,必须关注环境配置、任务到 GPU 的映射以及接口和库的选择。
致谢
这项工作由欧盟资助。这项工作得到了欧洲高性能计算联合事业(JU)以及瑞典、芬兰、德国、希腊、法国、斯洛文尼亚、西班牙和捷克共和国的资助,资助协议编号为 101093261。计算是由瑞典国家学术超级计算基础设施(NAISS)提供的资源实现的,部分由瑞典研究委员会通过资助协议编号 2022 - 06725 资助。这项研究得到了瑞典研究委员会(编号 2022.03062)的支持。
References
[1]
OLCF, “Frontier user guide,” 2023. [Online]. Available: https://docs.olcf.ornl.gov/systems/frontier_user_guide.html
[2]
T. Geenen, N. Wedi, S. Milinski, I. Hadade, B. Reuter, S. Smart, J. Hawkes, E. Kuwertz, T. Quintino, E. Danovaro et al., “Digital twins, the journey of an operational weather system into the heart of destination earth,” Procedia Computer Science, vol. 240, pp. 99–108, 2024.
[3]
M. Karp, D. Massaro, N. Jansson, A. Hart, J. Wahlgren, P. Schlatter, and S. Markidis, “Large-scale direct numerical simulations of turbulence using gpus and modern fortran,” The International Journal of High Performance Computing Applications, vol. 37, no. 5, pp. 487–502, 2023.
[4]
N. Jansson, M. Karp, A. Perez, T. Mukha, Y. Ju, J. Liu, S. Páll, E. Laure, T. Weinkauf, J. Schumacher et al., “Exploring the ultimate regime of turbulent rayleigh–bénard convection through unprecedented spectral-element simulations,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2023, pp. 1–9.
[5]
M. I. Andersson, N. A. Murugan, A. Podobas, and S. Markidis, “Breaking down the parallel performance of gromacs, a high-performance molecular dynamics software,” in International Conference on Parallel Processing and Applied Mathematics. Springer, 2022, pp. 333–345.
[6]
J. J. Williams, A. Bhole, D. Kierans, M. Hoelzl, I. Holod, W. Tang, D. Tskhakaya, S. Costea, L. Kos, A. Podolnik et al., “Understanding large-scale plasma simulation challenges for fusion energy on supercomputers,” arXiv preprint arXiv:2407.00394, 2024.
[7]
S. Markidis, “Enabling quantum computer simulations on amd gpus: a hip backend for google’s qsim,” in Proceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 1478–1486.
[8]
G. H. Loh, M. J. Schulte, M. Ignatowski, V. Adhinarayanan, S. Aga, D. Aguren, V. Agrawal, A. M. Aji, J. Alsop, P. Bauman et al., “A research retrospective on amd’s exascale computing journey,” in Proceedings of the 50th Annual International Symposium on Computer Architecture, 2023, pp. 1–14.
[9]
OLCF, “Frontier supercomputer debuts as world’s fastest, breaking exascale barrier,” 2023. [Online]. Available: https://www.ornl.gov/news/frontier-supercomputer-debuts-worlds-fastest-breaking-exascale-barrier
[10]
LUMI consortium, “Lumi’s full system architecture revealed,” 2021. [Online]. Available: https://www.lumi-supercomputer.eu/lumis-full-system-architecture-revealed/
[11]
AMD, “Amd instinct mi250 microarchitecture,” 2024. [Online]. Available: https://rocm.docs.amd.com/en/latest/conceptual/gpu-arch/mi250.html
[12]
C. Pearson, A. Dakkak, S. Hashash, C. Li, I.-H. Chung, J. Xiong, and W.-M. Hwu, “Evaluating characteristics of cuda communication primitives on high-bandwidth interconnects,” in Proceedings of the 2019 ACM/SPEC International Conference on Performance Engineering, ser. ICPE ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 209–218. [Online]. Available: https://doi.org/10.1145/3297663.3310299
[13]
Nvidia, “Cuda samples,” 2018. [Online]. Available: https://github.com/NVIDIA/cuda-samples
[14]
“Osu micro-benchmarks,” 2001. [Online]. Available: http://mvapich.cse.ohio-state.edu/benchmarks/
[15]
C. Pearson, “Interconnect bandwidth heterogeneity on amd mi250x and infinity fabric,” arXiv preprint arXiv:2302.14827, 2023.
[16]
C.-C. Chen, K. Shafie Khorassani, P. Kousha, Q. Zhou, J. Yao, H. Subramoni, and D. K. Panda, “Mpi-xccl: A portable mpi library over collective communication libraries for various accelerators,” in Proceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 847–854.
[17]
G. Schieffer, D. A. De Medeiros, J. Faj, A. Marathe, and I. Peng, “On the rise of amd matrix cores: Performance, power efficiency, and programmability,” in 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2024, pp. 132–143.
[18]
M. Leinhauser, R. Widera, S. Bastrakov, A. Debus, M. Bussmann, and S. Chandrasekaran, “Metrics and design of an instruction roofline model for amd gpus,” ACM Transactions on Parallel Computing, vol. 9, no. 1, pp. 1–14, 2022.
[19]
D. Eberius, P. Roth, and D. M. Rogers, “Understanding strong scaling on gpus using empirical performance saturation size,” in 2022 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC). IEEE, 2022, pp. 26–35.
[20]
K. Punniyamurthy, B. M. Beckmann, and K. Hamidouche, “Gpu-initiated fine-grained overlap of collective communication with computation,” arXiv preprint arXiv:2305.06942, 2023.
[21]
W. F. Godoy, P. Valero-Lara, T. E. Dettling, C. Trefftz, I. Jorquera, T. Sheehy, R. G. Miller, M. Gonzalez-Tallada, J. S. Vetter, and V. Churavy, “Evaluating performance and portability of high-level programming models: Julia, python/numba, and kokkos on exascale nodes,” arXiv preprint arXiv:2303.06195, 2023.
[22]
N. Chalmers, A. Mishra, D. McDougall, and T. Warburton, “Hipbone: A performance-portable graphics processing unit-accelerated c++ version of the nekbone benchmark,” The International Journal of High Performance Computing Applications, p. 10943420231178552, 2023.
[23]
Z. Jin and J. S. Vetter, “Evaluating unified memory performance in hip,” in 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2022, pp. 562–568.
[24]
S. Chien, I. Peng, and S. Markidis, “Performance evaluation of advanced features in cuda unified memory,” in 2019 IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC). IEEE, 2019, pp. 50–57.
[25]
G. Schieffer, J. Wahlgren, J. Ren, J. Faj, and I. Peng, “Harnessing integrated cpu-gpu system memory for hpc: a first look into grace hopper,” in Proceedings of the 53rd International Conference on Parallel Processing, 2024, pp. 199–209.
[26]
A. Li, S. L. Song, J. Chen, X. Liu, N. Tallent, and K. Barker, “Tartan: evaluating modern gpu interconnect via a multi-gpu benchmark suite,” in 2018 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 2018, pp. 191–202.
[27]
H. Horii, C. Wood et al., “Efficient techniques to gpu accelerations of multi-shot quantum computing simulations,” arXiv preprint arXiv:2308.03399, 2023.
[28]
J. Faj, I. Peng, J. Wahlgren, and S. Markidis, “Quantum computer simulations at warp speed: Assessing the impact of gpu acceleration: A case study with ibm qiskit aer, nvidia thrust & cuquantum,” in 2023 IEEE 19th International Conference on e-Science (e-Science). IEEE, 2023, pp. 1–10.
[29]
S. W. Min, V. S. Mailthody, Z. Qureshi, J. Xiong, E. Ebrahimi, and W.-m. Hwu, “Emogi: Efficient memory-access for out-of-memory graph-traversal in gpus,” arXiv preprint arXiv:2006.06890, 2020.

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)