
数字人开源代码运行---wav2lip
手把手教你数字人wav2lip项目运行
·
代码地址:
论文地址:
1、下载代码

2、安装环境
conda create -n wav2lip python==3.9.0
conda activate wav2lip
conda install ffmpeg
修改requirements.txt中依赖版本号为
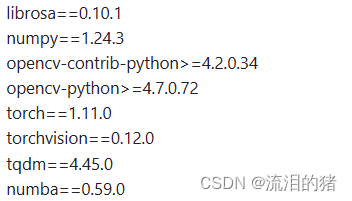
安装依赖
pip install -r requirements.txt2、下载模型
下载s3fd.pth模型,下载后放在face_detection/detection/sfd/s3fd.pth

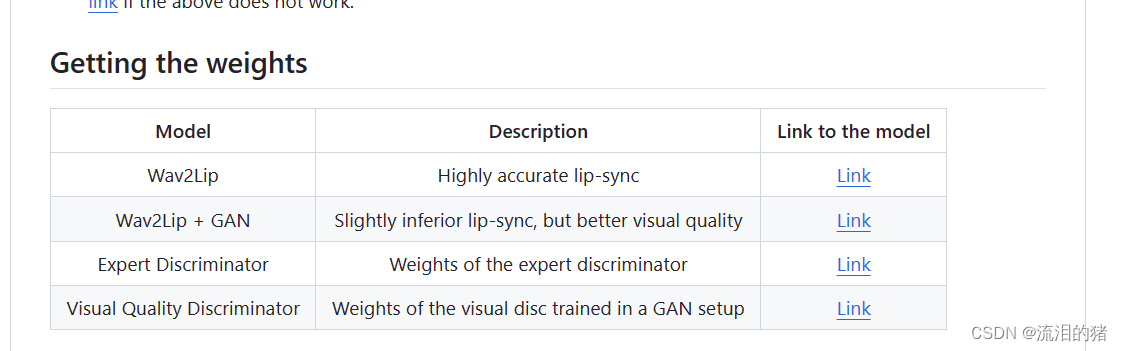
项目地址中给出了训练好的模型链接,下载就可以了,四个下载后都放在checkpoints目录下。
3、推理
根据参考视频和音频生成对应的说话视频
python inference.py --checkpoint_path ./checkpoints/wav2lip_gan.pth --face ./demo/short_demo.mp4 --audio ./demo/test.wav4、可能会遇到的问题:

issues中给出了答案:
修改audio.py 第一百行代码:
return librosa.filters.mel(sr=hp.sample_rate, n_fft=hp.n_fft, n_mels=hp.num_mels,
fmin=hp.fmin, fmax=hp.fmax)
5、评价指标

evaluation目录中给出了Average Confidence,Average Minimum Distance评价指标的计算。利用的是syncnet项目计算。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)