
Instant-NPG论文阅读
Instant-ngp的全称是使用哈希编码的多分辨率的即时神经图形原语,所以补充的第一个知识是哈希存储。计算机当中有多种数据存储方式,如常用的顺序存储、链式存储和哈希(散列)存储。上图展示的是顺序存储,它的意思就是开辟一个连续的内存空间来存储数据,数据也按照顺序依次放入内存当中,如上图就是开辟的100-200的连续内存空间依次存储数组元素a[0]-a[100]。它的优点就是只要知道初始数据的存储位
1、前置知识补充
1.1 哈希存储
Instant-ngp的全称是使用哈希编码的多分辨率的即时神经图形原语,所以补充的第一个知识是哈希存储。计算机当中有多种数据存储方式,如常用的顺序存储、链式存储和哈希(散列)存储。

上图展示的是顺序存储,它的意思就是开辟一个连续的内存空间来存储数据,数据也按照顺序依次放入内存当中,如上图就是开辟的100-200的连续内存空间依次存储数组元素a[0]-a[100]。它的优点就是只要知道初始数据的存储位置,就可以很快的找到其他的数据,缺点就是需要开辟一段连续的空间,如果要存储的数据过大,那么计算机当中可能没有这么大的连续内存。
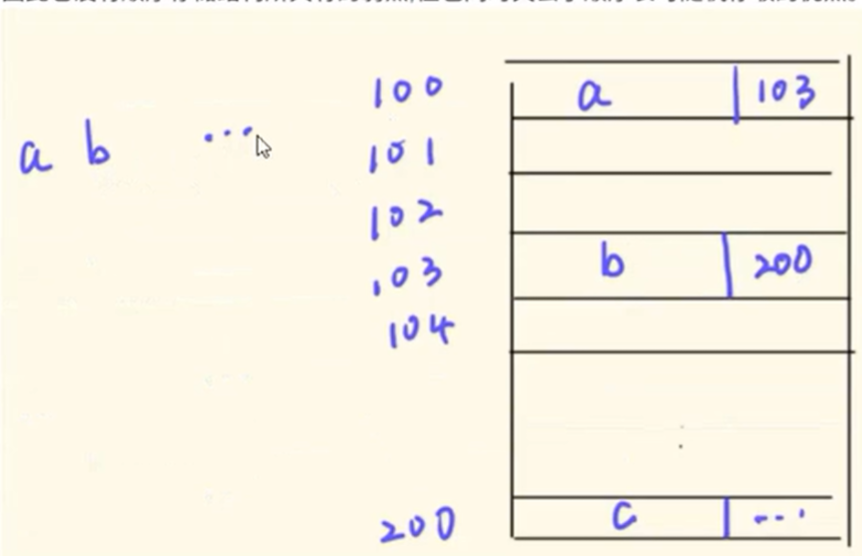
上图展示的是链式存储,它的意思就是在存储一组数据的时候,每当存储一个数据时,存储的不仅仅是这个数据,还有下一个数据存储的地址,如上图要存储a、b和c,那么在存储a的时候,还会在该内存空间存上b的存储地址。它的优点就是不需要连续的存储空间,缺点就是如果要查找一组数据中的某个数据,必须从这组数据的第一个数据开始查找。
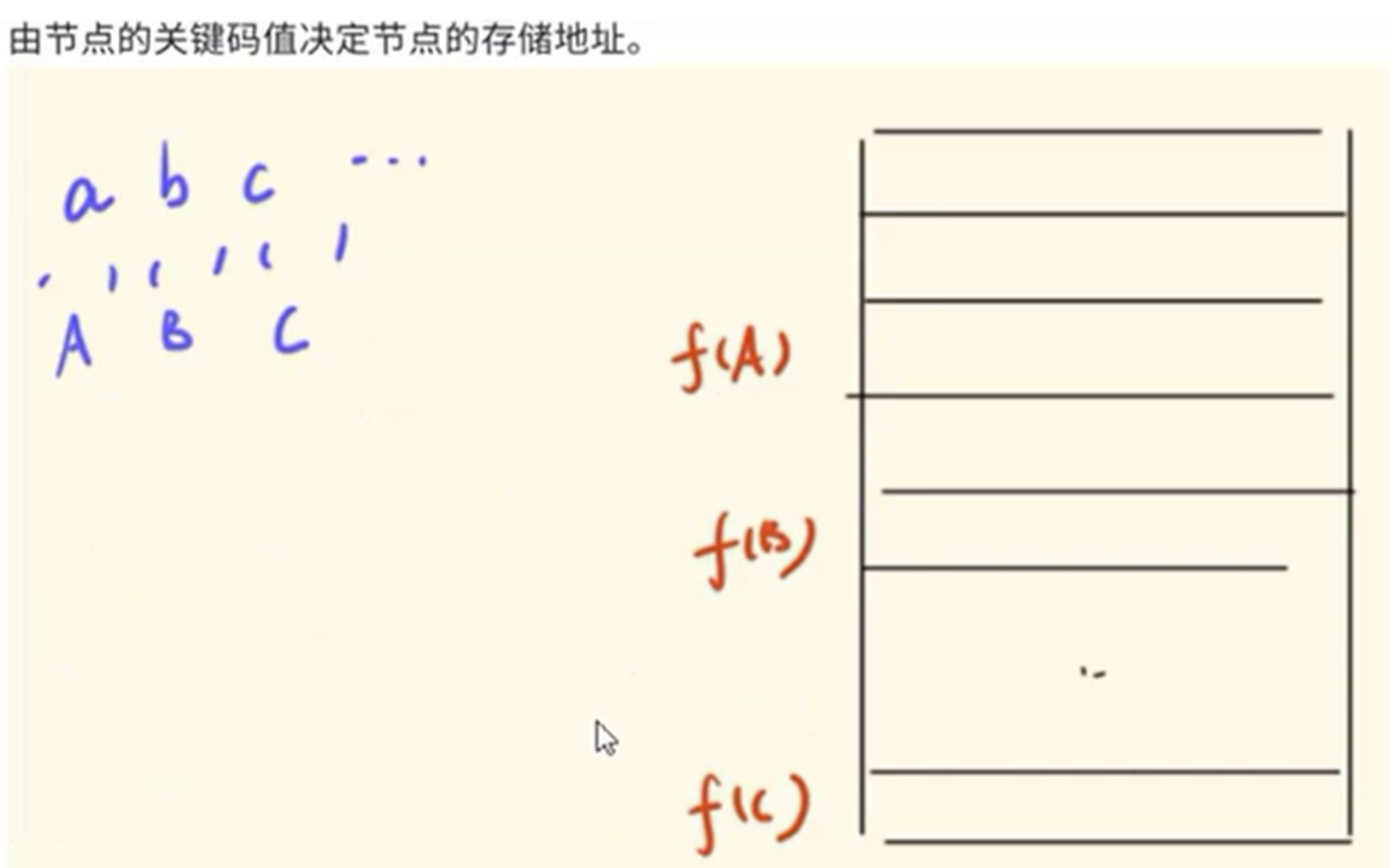
上图展示的就是一个哈希(散列)存储,它其实是顺序和链式的一种折中方案,在存储的过程中每个要存储的数据需要对应一个关键码,关键码是我们自己设定的,然后还会有一个哈希函数,那么每个数据对应的关键码经过哈希函数后就会映射到一个地址,也就是存储这个数据的地址。如上图由一组数据a、b、c,对应的关键码是A、B、C,那么f是哈希函数,f(A)就是a的存储地址。它的优点就是不需要连续的内存,查找数据的速度也非常快,缺点就是当不同数据的关键码经过哈希函数之后可能映射到同一个内存单元,这就叫做哈希冲突。
1.2 神经图像原语
在计算机视觉和图形学中,我们常常需要保存二维数据(图像)和三维数据(三维模型)的外观信息,常规的方法是利用标准的数据结构进行存储,例如存储一张彩色图片的时候,其存储方式就是HxWx3(RGB三色通道)。那么还有一种深度学习的方法进行存储,也就是利用神经网络进行存储,这种方式就是叫神经图像原语。
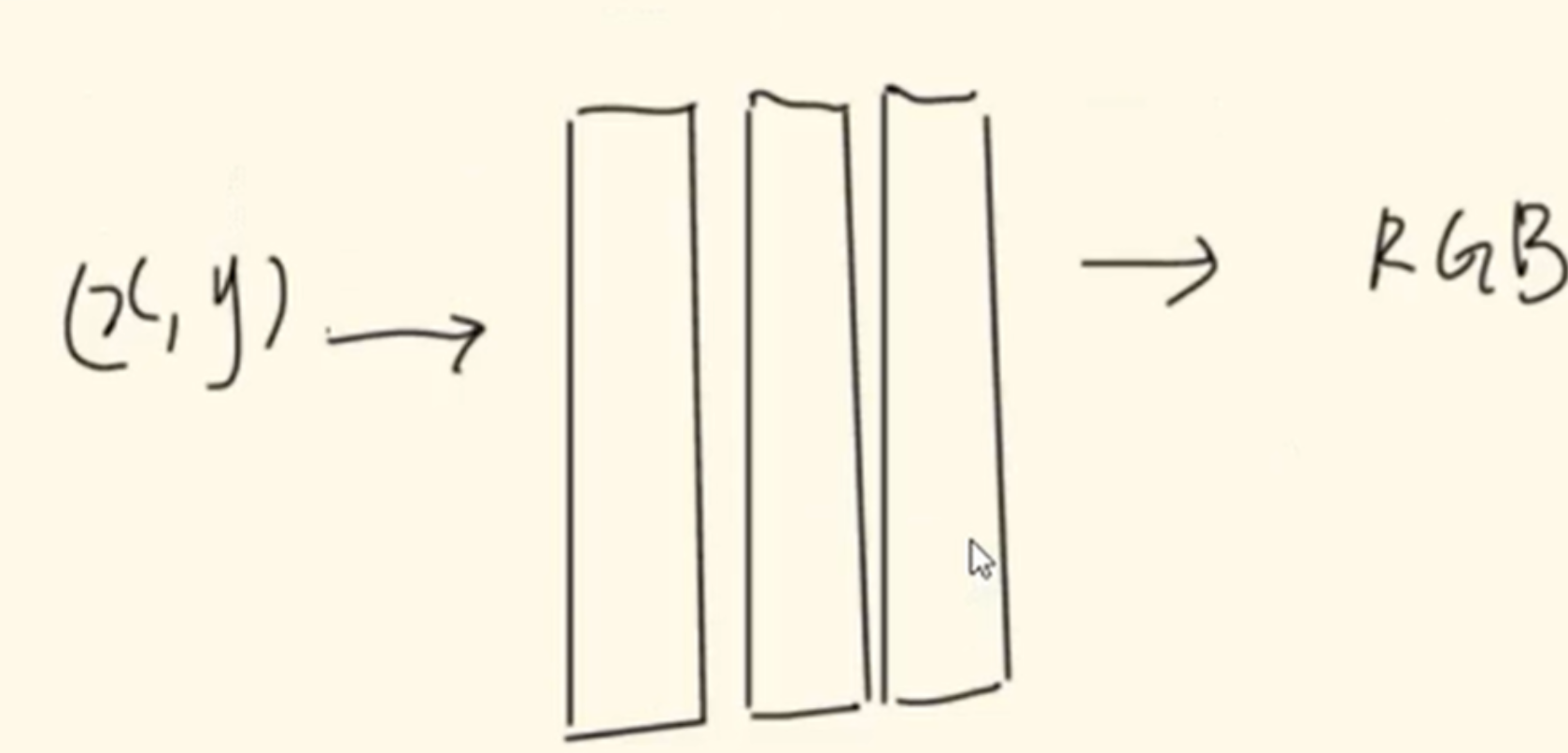
上图是利用神经图像原语存储二维数据的例子,在一个超大图像的压缩任务当中,将图像每个像素点的位置坐标通过神经网络输出该像素点的RGB,那么如果这个神经网络的参数比HxWx3少的话,就达到了一个图片压缩的目的。
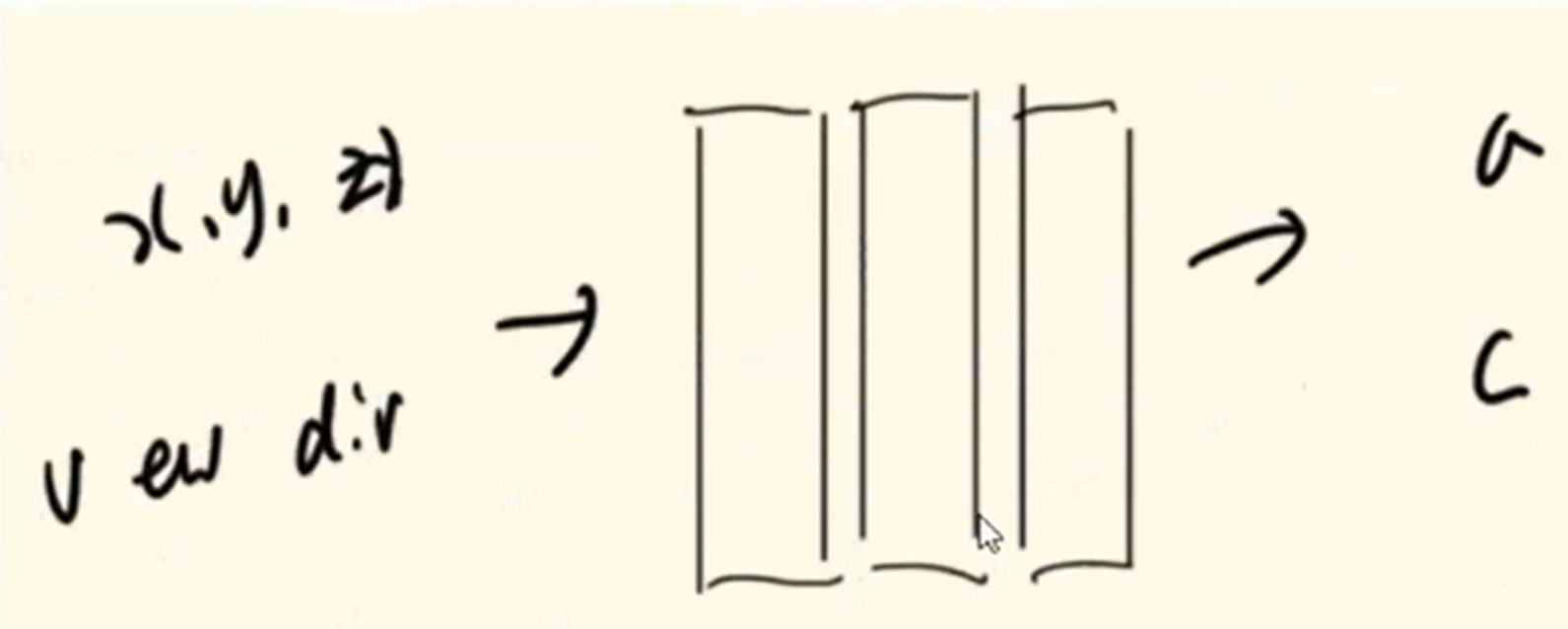
上图是利用神经图像原语存储三维数据的例子。在Nerf中就是将每张图像上像素点的位置坐标和观测角度通过神经网络就可以得到对应像素点的颜色和密度,也就是将最终三维模型的信息存储在了神经网络中。

如果要利用神经网络来存储二维、三维数据的话,就需要对输入进行位置编码。上图就是通过神经网络压缩图片,但是没有进行位置编码的效果,可以看到非常的模糊。

上图是进行Nerf渲染而没有进行位置编码后的效果,也是非常模糊的。(对于位置编码这个问题在原nerf论文当中也有提到,但是在instant-NPG当中比较系统的进行了描述。)
2、位置编码
2.1 固定位置编码
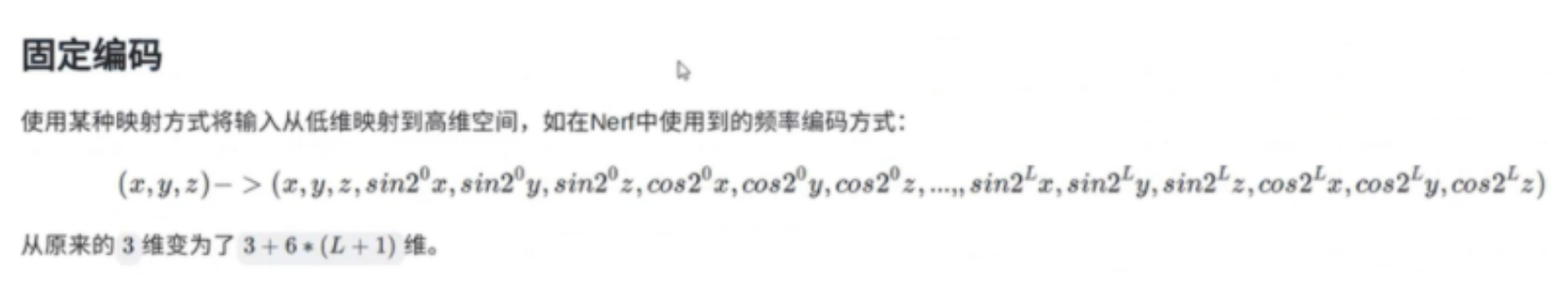
现在常用的对输入进行编码的方式有两种:固定编码和可学习编码。首先介绍一下固定编码,固定编码是指使用一个固定的数学公式使一个低维度的输入映射到一个高维度,且映射的过程中不需要任何的参数。上图有一个例子,就是通过一个固定的函数将一个3维的输入映射到了一个3+6*l维度的输入。
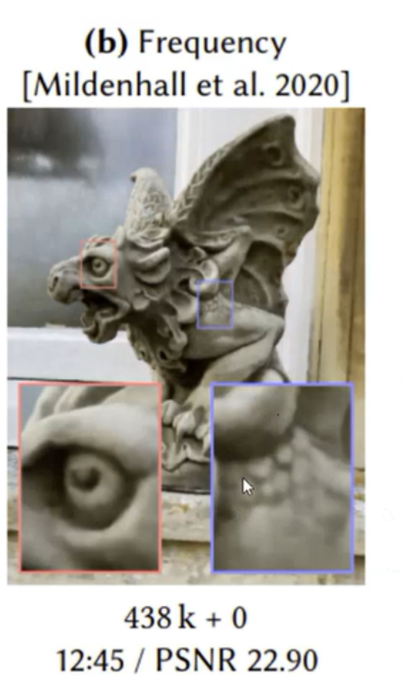
上图通过固定编码进行位置编码后的渲染效果,可以看到清晰了很多,并且其参数量也没有增加多少(没有位置编码时是411K,有固定编码时是438K)。
2.2 可学习位置编码

还有一种对输入进行编码的方式是可学习的编码。它是指设定一个神经网络自己去学习每个坐标的编码方式,而不用设定一个固定的数学公式,让它自己去学习。这是现在常用的一种方式,但是在nerf当中如何去学习每个点的编码形式呢?三维都是连续的点,因此不可能对每个点都进行学习,就提出了Dense Grid,意思是对三维空间进行划分,然后对每个区域离散的顶点的编码形式进行学习。可学习的编码又分为了多分辨率和单分辨率两种。
2.2.1 单分辨率可学习位置编码
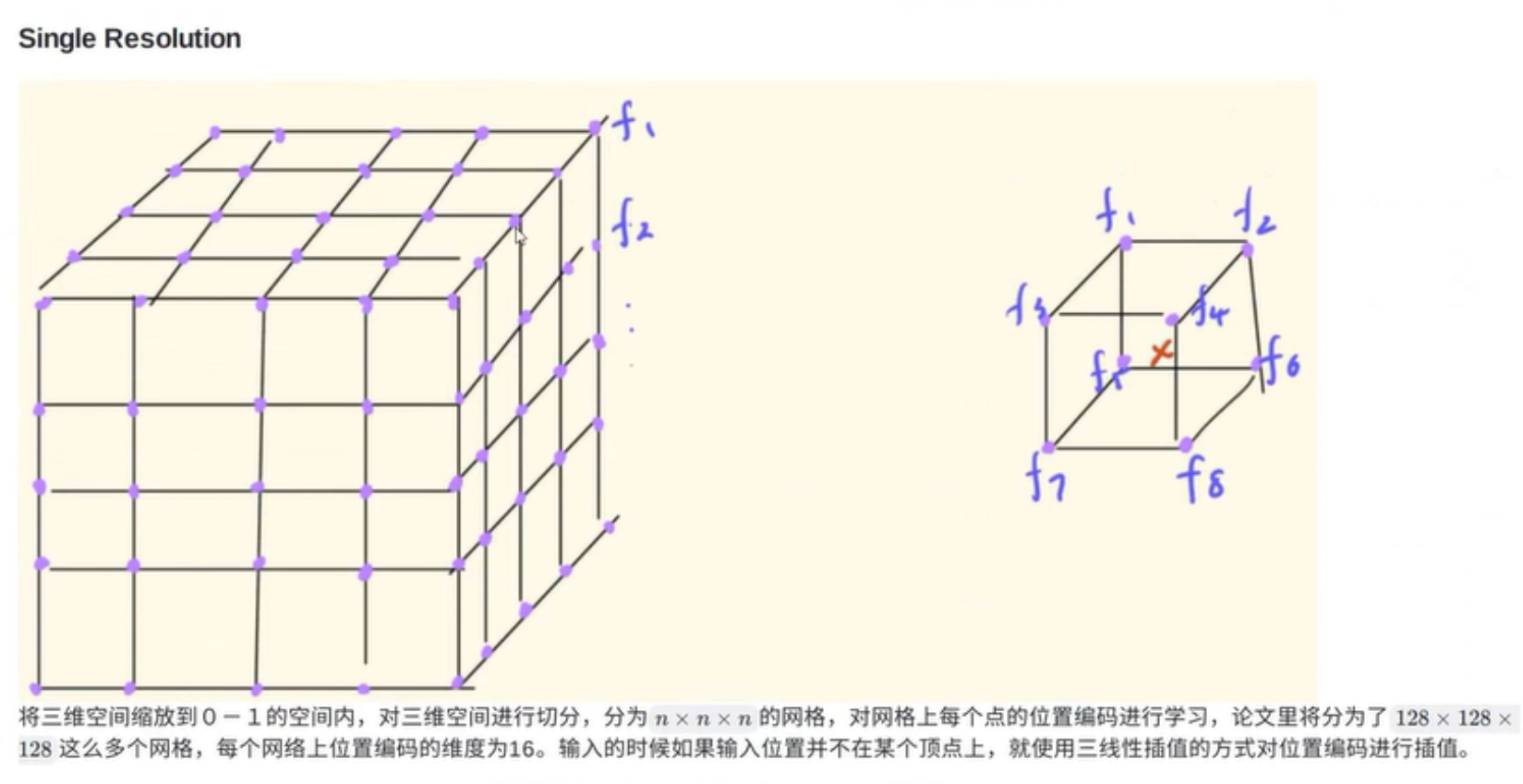
上图是单分辨率的可学习编码。它的一个思想是将三维空间放到一个0-1的空间里面,将三维空间划分为很多的小方格,然后对这个类似于魔方的外表面的nxnxn个顶点的编码方式进行学习。那么我们在辐射场进行采样的时候,这个采样点可能不是小方格的顶点,那么这个采样点的位置编码如何获得?这时候就会找出这个点所在的小方格的八个顶点的位置编码特征值,然后利用三线性插值对这8个值做处理计算出这个采样点的位置编码作为神经网络的输入。文章中是将三维空间划分为了每个面为128个小方块的模型,然后规定可学习的位置编码的维度为16。

上图是利用单分辨率的可学习编码作为神经网络输入后的结果,可以看到效果不错。其神经网络的参数值也小了很多(438K~10K),但是顶点的可学习编码的参数增大了(33.6M=16x128x128x128)。正是因为有了可学习的编码神经网络的参数才能小许多,因为将大部分的压力都给到了可学习的编码上。但是并不影响渲染的速率,因为可学习的编码使得神经网络反向传播的时候只涉及到离散的顶点,而不是全部采样点。
2.2.2 多分辨率可学习位置编码
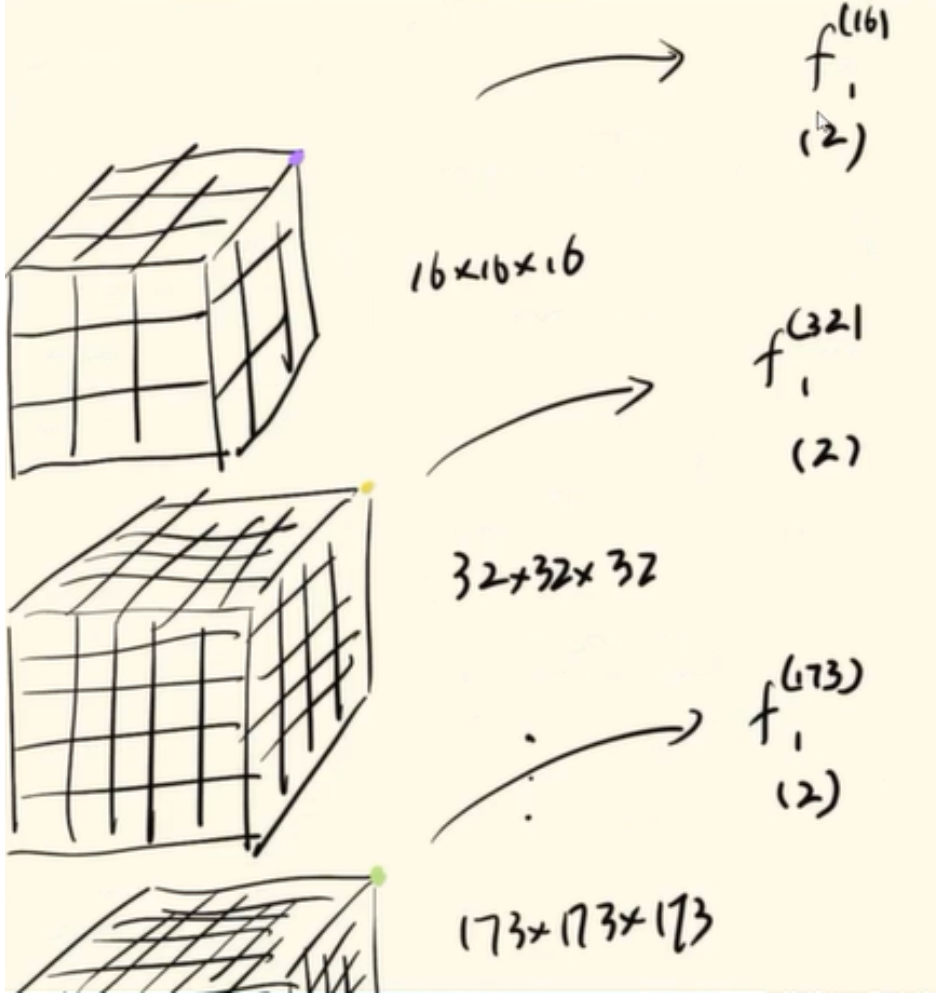
多分辨率的可学习编码和单分辨率的可学习编码不同之处就在于,单分辨率的可学习编码只有一种网格划分,而多分辨率的可学习编码有8种网格划分(16x16~173x173)。在多分辨率的可学习编码中,对于每种网格划分上面的离散的顶点都进行了编码方式的学习,每个点的可学习编码的维度是2。那我们在辐射场取得的一个采样点不在方格顶点上时,要获得它的位置编码,就看它在每种网格划分方式里面都属于哪个个具体的格子,然后利用三线性插值计算出各种网格划分方式种这个点的位置编码,然后再将每个网格划分方式下这个点的位置编码连接起来,就构成了和单分辨率一样的位置编码的维度16=8x2,从而获得这个采样点的位置编码。

这就是使用多分辨率的可学习的位置编码作为神经网络输入后的渲染效果,可以看到效果还要好一点,并且其神经网络的参数还是10K,位置编码的参数还减少为16.3M=16x16x16x2+……+173x173x173x2,可以说是更快更好。
单分辨率可学习的位置编码和多分辨率的可学习位置编码其实效果都还不错,但是带来的代价就是位置编码的参数增多了,使得渲染速度减慢。并且要想渲染效果更好的话,网格划分还要精细,那也就是编码参数还要以三次方的速度增加,那么渲染速度会更慢。那么能不能使得Nerf的渲染效果好,参数还少(渲染速度也快)呢?这就是Instant-NPG主要探讨的一个问题。
2.2.3 多分辨率哈希位置编码
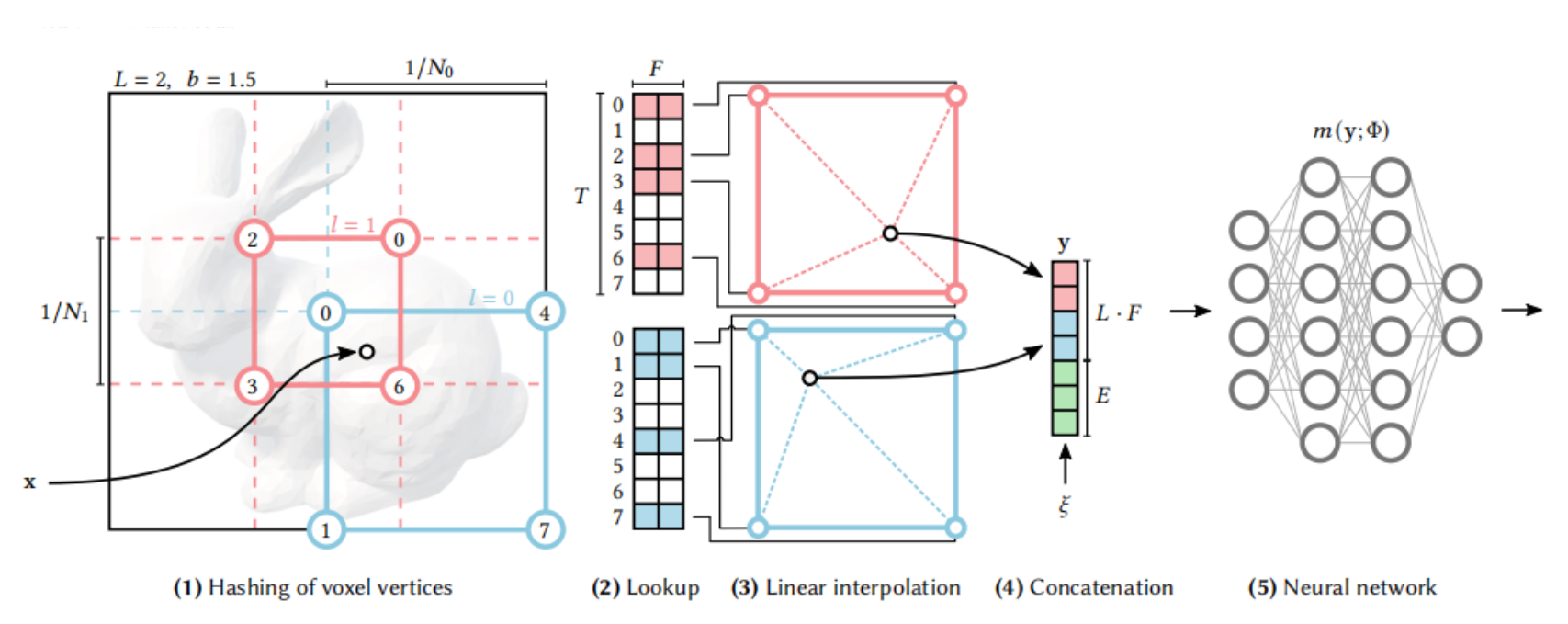
Instant-NPG当中提出非常关键的一点,对于nerf渲染的速度和效果都有很好的提升。也就是在进行网格划分时,对于每个小方格所有顶点都进行可学习的位置编码是没有必要的,因为很多的点都是在空气中的,对于最后的渲染效果并没有帮助,更加关注的是物体边缘的点,所以针对于这个现象Instant-NPG提出的文章的核心部分,也就是多分辨率的哈希编码(如上图),其过程与多分辨率的可学习的位置编码很类似,只不过加入了哈希映射的过程。
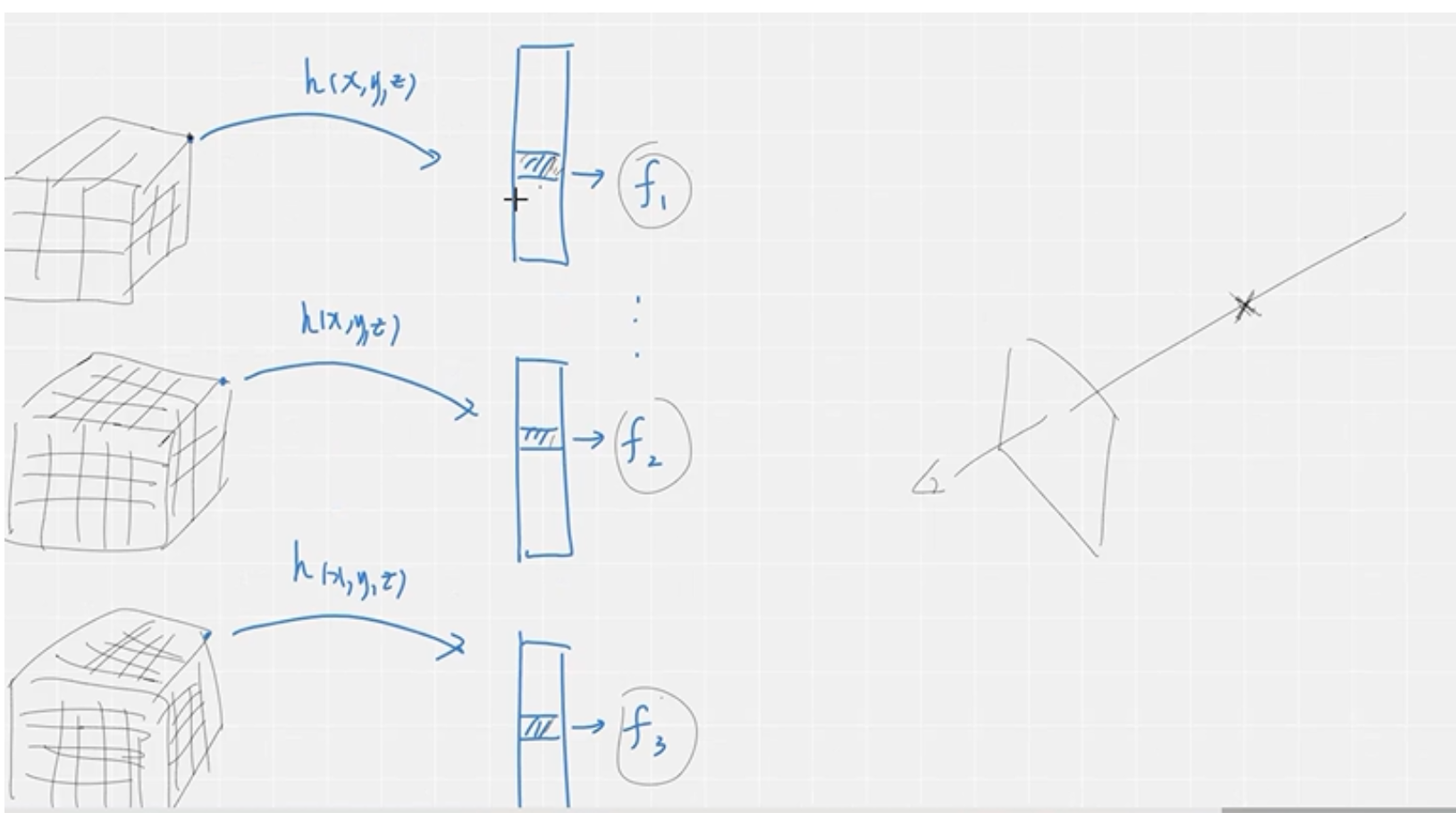
具体的哈希映射过程如上图,它也与多分辨率的可学习的位置编码一样,把三维空间划分为不同精细程度的网格(也就是不同的分辨率),但是不同的是哈希编码里面没有将每种分辨率下每个方格各个顶点的位置编码都算出来,只针对于权重比较大的方格顶点进行位置编码的计算。然后在哈希编码中,要想得到一个方格顶点的位置编码,是将这个顶点的位置坐标进行哈希函数运算,从而映射到哈希表的表项上,哈希表里面的每个表项都是一个位置编码,从而就可以获得对应的方格顶点的位置编码。那么在辐射场中采样的点,不在方格顶点上,它的位置编码与多分辨率的可学习的位置编码里面的操作方式一样,就是找出这个采样点在不同分辨率下所在的小方格,然后利用三线性插值计算出每个分辨率下这个采样点的位置编码(2维),然后也是将不同分辨率下这个采样点的位置编码(2维)进行连接,形成这个采样点最终的位置编码。
注意:每个分辨率对应哈希表的长度都是都是根据分辨率来定的,划分的网格越细,哈希表就越长,越粗糙,哈希表就越短。
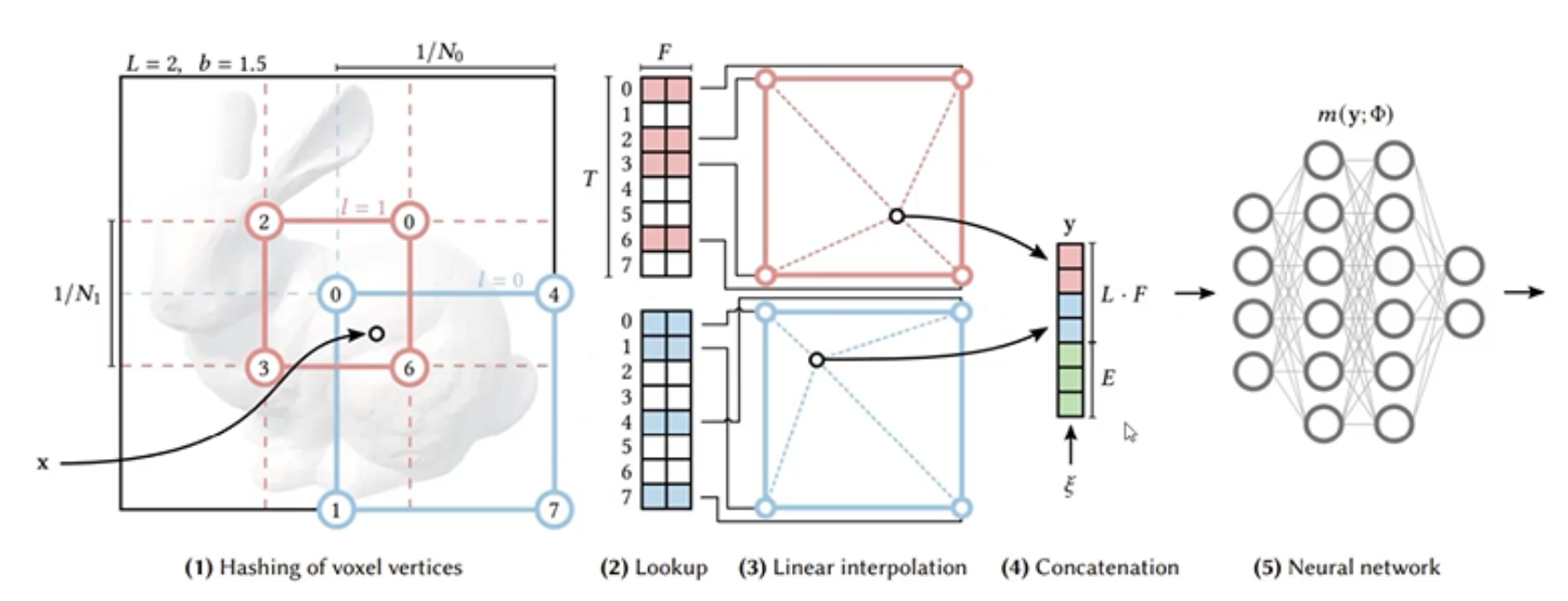
上图就是多分辨率哈希编码(文章核心)的过程。其实这张图和上面的那个手画的图是一样的,只不过说这个更规整,且是基于二维的一种表示。可以看到x是我们的一个采样点,它位于不同分辨率下的不同小方格里,要求它的位置编码就要先求出它在不同分辨率下的不同小方格的顶点的位置编码(通过哈希映射求得),然后通过三线性插值求得这个点在不同分辨率下的二维位置编码,最后将不同分辨率下的二维位置编码进行拼接就可以获得x这个采样点最终的位置编码,然后这个位置编码将作为神经网络的输入。

上图是对于各个参数的规定,第一个是分辨率(网格的划分精细)有16种;第二个是哈希表的长度是214到224;第三个是不同分辨率下的不同小方格的顶点的位置编码的维度为2;第三个是最粗糙的网格划分是16x16,最精细的是512x512。
那么有一个问题就是为什么多分辨率哈希编码可以达到和多分辨率可学习位置编码相同的效果,而它的速度又要快一点呢?因为多分辨率可学习位置编码是将每个分辨率下所有方格的所有顶点的位置编码都进行了计算,而多分辨率哈希编码种所给的哈希表的长度是比每个分辨率下所有方格的所有顶点的个数要少的。如上图最精细的划分是512x512x512,那么位置编码的参数个数512x512x512=227,而所给的最长的哈希表的长度是224,这样就进行了压缩。
3、哈希冲突
还有文章一个比较大的疑惑就是,其实这篇文章并没有考虑一个哈希冲突的问题。也就是说每个分辨率下的两个位置差异很大的顶点在经过哈希映射后映射到了同一个哈希表的表项,这样的哈希冲突并没有解决,但是最终的渲染效果还是比较好,文章给出了这样的两个解释。一是渲染场景的稀疏性,为什么稀疏,因为我们只关心物体边缘或者边缘相近的采样点,而不考虑那些在空气当中的采样点,所以大部分的点都是属于无效的采样点,所以这些点发生哈希冲突,对最后的渲染效果的影响其实并不大。二是,其实在粗采样,也就是低分辨率的情况下,哈希表的长度其实与要求位置编码的顶点个数是一样的,也就是一一对应的,所以在低分辨率的情况下,是不容易产生哈希冲突的,并且最终采样点的位置编码,是所有分辨率下该点位置编码的连接,又因低分辨率的情况下的位置编码是准确的,所以提高了整体的一个准确性。这就是有哈希冲突,但是多分辨率的哈希编码仍然表现得比较好的原因。
4、哈希函数的选用

上图就是Instant-NGP的所使用的哈希函数。其中Πi是规定好的数值(Π1、Π3、Π3),xi是指你选用的维度,例如三维的就是x、y、z,然后将每个维度的值与不同的Π值相乘,再将最后相乘结果进行异或,再将异或的结果对哈希表的长度T进行求模,防止溢出。下面是一个简单的例子,首先取一个点的位置(在不同分辨率下的坐标,例如60x60x60当中的(15,20,58)),其维度是三维的,然后分别将x、y、z分别与Π1、Π3、Π3相乘,在进行异或,最后对T求模,最后得到的是这个点在哈希表的对应表项,表项里面就是这个点的位置坐标。
那么为什么要选用这个哈希函数,一是因为这个函数本来就简单,且在cuda下编程速度很快(Instant-ngp是利用cuda进行编程),二是每个维度值都乘以不同的Π值,使得原本的坐标被打乱,鲁棒性更强。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)