
(Arxiv-2025)径向注意力:用于长视频生成的 $\mathcal{O}(n \log n)$ 稀疏注意力与能量衰减机制
本文提出了一种名为径向注意力的新型稀疏注意力机制,用于解决长视频生成中的计算效率问题。该机制基于观察到的时空能量衰减现象(即注意力分数随token间时空距离增大而减小),设计了一种计算复杂度为O(n log n)的静态稀疏注意力掩码。每个token仅关注空间邻近token,且注意力窗口随时间距离指数收缩。实验表明,该方法在保持视频质量的同时,相比标准稠密注意力可提升推理速度最高达3.7倍,并减少4
径向注意力:用于长视频生成的 O ( n log n ) \mathcal{O}(n \log n) O(nlogn) 稀疏注意力与能量衰减机制
paper是MIT发布在Arxiv 2025的工作
paper title:Radial Attention: O ( n log n ) \mathcal{O}(n \log n) O(nlogn) Sparse Attention with Energy Decay for Long Video Generation
Code:链接
“没有任何传播是无损的;每一个信号、每一种影响、每一份注意力——都会随距离衰减。” —— 灵感来源于热力学原理

图1:我们提出了径向注意力(Radial Attention),这是一种计算复杂度为 O ( n log n ) O(n \log n) O(nlogn) 的稀疏注意力机制。径向注意力在默认视频长度下对预训练的 HunyuanVideo [1] 提速 1.9 倍,同时保持了可比的视频质量。在生成 4 倍更长的视频时,相比于稠密注意力,它最多可减少 4.4 倍的微调成本,并将推理速度提升至最多 3.7 倍。
Abstract
扩散模型的最新进展已实现高质量的视频生成,但额外的时间维度会显著增加计算成本,使得在长视频上的训练和推理变得极其昂贵。在本文中,我们识别出一种现象,称为视频扩散模型中的时空能量衰减(Spatiotemporal Energy Decay):当 token 之间的空间和时间距离增加时,softmax 之后的注意力分数会减小,类似于自然界中信号或波在空间和时间中的物理衰减。受到这一现象的启发,我们提出了径向注意力(Radial Attention),这是一种具有 O ( n log n ) O(n \log n) O(nlogn) 复杂度的可扩展稀疏注意力机制,将能量衰减转化为指数衰减的计算密度,比标准 O ( n 2 ) O(n^2) O(n2) 的稠密注意力更高效,同时比线性注意力更具表达能力。具体而言,径向注意力采用一个简单、静态的注意力掩码,每个 token 仅关注空间上邻近的 token,且注意力窗口的大小会随着时间距离的增加而收缩。此外,它还能让预训练的视频扩散模型通过高效的基于 LoRA 的微调机制扩展视频生成长度。大量实验证明,径向注意力在 Wan2.1-14B、HunyuanVideo 和 Mochi 1 等模型中均能保持视频质量,同时在推理过程中相较原始稠密注意力实现最高 1.9 倍的加速。通过最小化的微调,它可以使视频生成长度提升至原来的 4 倍,同时相比直接微调,训练成本最多减少 4.4 倍,并在推理过程中相较稠密注意力实现最高 3.7 倍的加速。
1 Introduction
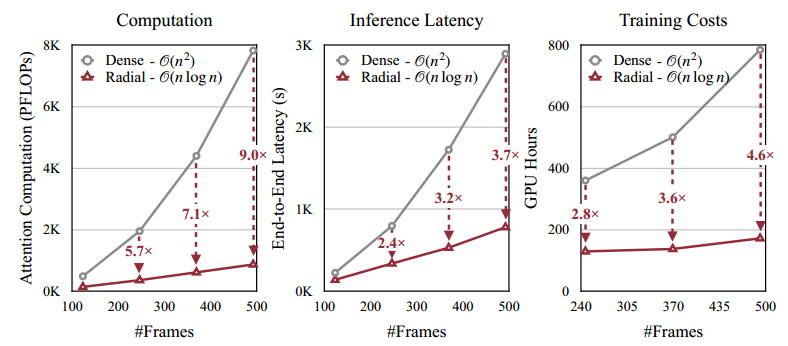
图2:径向注意力(Radial Attention)将注意力的计算复杂度从 O ( n 2 ) O(n^2) O(n2) 降低到 O ( n log n ) O(n \log n) O(nlogn)。在使用 HunyuanVideo 生成一个 500 帧的 720p 视频时,它将注意力计算量减少了 9 倍,实现了 3.7 倍的推理加速,并节省了 4.6 倍的微调成本。
扩散模型在生成高质量图像方面已取得显著成功 [2, 3]。近期的研究进一步将其能力扩展至视频生成,能够生成视觉效果出色、时间连贯的视频结果 [4, 5, 6, 7, 1]。然而,这些提升也带来了巨大的计算成本。与图像生成不同,视频合成涉及额外的时间维度,显著增加了需要处理的 token 数量。由于自注意力的计算复杂度随序列长度呈二次增长,长视频的训练和推理变得极其昂贵,限制了模型的实用性和可扩展性。已有一些研究尝试通过稀疏注意力来缓解这一问题。例如,如图3(a)所示,Sparse VideoGen (SVG) [8] 采用了一种在线分析策略,将每个注意力头分类为空间或时间类别,并应用相应的稀疏掩码。尽管该方法在推理阶段能够加速,但在训练过程中,尤其是处理长视频时,仍存在挑战。在线分析可能会在未见过的数据分布上错误分类注意力头,这种误差在优化过程中可能被放大,从而导致性能下降。其他方法则尝试用线性注意力替代 softmax 注意力 [9, 10],但这类方法通常需要对模型架构进行较大修改,通常仅靠轻微微调难以恢复原有的视频生成质量。
在物理学中,信号和波在传播过程中通常会经历能量衰减。受这一原理启发,我们在注意力机制中也观察到类似现象:当 token 对之间的空间或时间距离增加时,softmax 之后的注意力分数会趋于减小(见图 4(b))。我们将这一现象称为时空能量衰减(Spatiotemporal Energy Decay),并将该衰减建模为空间和时间距离的指数函数。基于这一模型,我们将 SVG [8] 中的空间与时间注意力头统一为径向注意力(Radial Attention),这是一种具有 O ( n log n ) O(n \log n) O(nlogn) 计算复杂度的可扩展稀疏注意力机制(见图 2)。径向注意力通过静态稀疏注意力掩码,将能量衰减的概念转化为相应的计算密度衰减。该掩码设计简单却有效:每个 token 仅关注空间位置相近的其他 token,且注意力窗口会随时间距离的增加而呈指数收缩,如图 3(b) 所示。
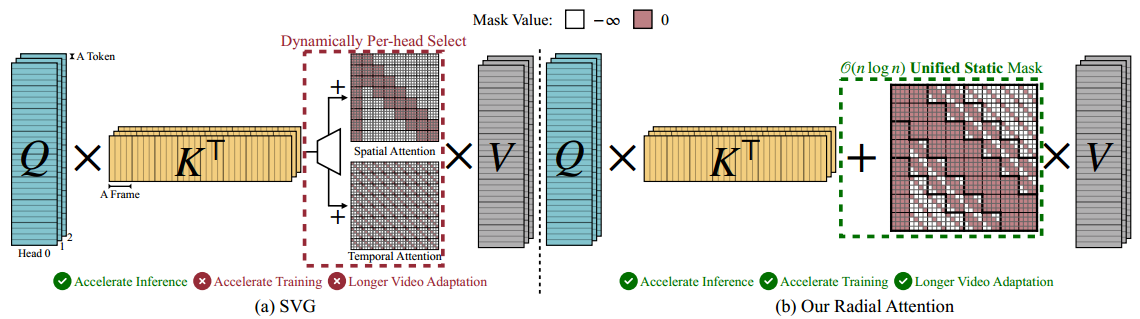
图3:SVG [8] 和我们提出的径向注意力(Radial Attention)的注意力流程图。为简洁起见,此处省略了 softmax。(a) SVG 会为每个注意力头动态选择空间或时间注意力,以加速推理。然而,该方法无法克服原模型的长度限制,且无法在长视频等未见过的分布上进行训练。(b) 我们的径向注意力使用一个静态掩码,将空间和时间注意力统一,计算复杂度为 O ( n log n ) O(n \log n) O(nlogn)。这种静态设计能够高效适配长视频生成。
此外,由于径向注意力仅剪枝了不重要的 token 关系,且未修改底层 softmax 注意力机制,因此能高效适配预训练视频扩散模型至更长序列,仅需轻量微调,例如 LoRA [11]。与使用稠密注意力的全参数微调相比,径向注意力能获得更优视频质量,因为 LoRA 更专注于更新对时间一致性和视觉保真度最关键的参数。扩展长度的 LoRA 也能兼容现有的同类 LoRA 方法(见第 5.2 节)。
在默认视频长度下生成视频时,径向注意力能为领先的视频扩散模型(如 Wan2.1-14B [7] 和 HunyuanVideo [1])带来高达 1.9 倍的加速效果。在生成 4 倍更长的视频时,径向注意力可将微调成本最多降低 4.4 倍,并在推理中实现高达 3.7 倍的加速,同时不损失视频质量。图 1 展示了 HunyuanVideo 上的一些可视化示例。
2 Related Work
视频扩散模型。扩散模型在图像合成任务中已达到了当前最先进(SOTA)的效果 [2, 3, 12, 10]。研究人员进一步将其扩展至视频领域。早期方法 [13, 14, 15, 16] 基于 2D UNet [2, 17],通过添加时间模块来处理帧序列。自从 Sora [4] 出现以来,社区大多转向使用 DiT [18] 作为主干网络。Latte [19] 首次提出了解耦的空间和时间注意力机制,用于建模视频序列。为了更好地捕捉长程依赖关系并联合建模空间-时间动态,近期的 SOTA 模型采用了 3D 稠密注意力机制 [20, 21, 5, 22, 1, 7, 6]。然而,稠密注意力的计算开销极高——通常比解耦注意力高出几个数量级,其计算成本随着帧数的增加呈二次增长,这在训练和部署中都带来了巨大挑战。
高效视频生成。许多用于加速图像扩散模型的技术——如时间步蒸馏 [23, 24]、缓存机制 [25, 26]、量化方法 [27, 28, 29] 以及分布式推理 [30, 31, 32]——也被应用于视频扩散。然而,视频模型通常依赖 3D 稠密注意力,将瓶颈从前馈层转移到注意力层。近期工作如 SageAttention [33, 34, 35, 36] 和 FlashAttention-3 [37] 显示,量化注意力可显著加速推理。在大语言模型(LLMs)中,稀疏注意力已被广泛研究用于降低注意力复杂度 [38, 39, 40, 41, 42, 43, 44, 45, 46]。例如,Long LoRA [39] 结合两种局部稀疏注意力模式及平移机制,以在视频理解中实现全局感受野。PowerAttention [45] 则将注意力限制在 2 的幂次 token 距离内,实现 O ( n log n ) O(n \log n) O(nlogn) 复杂度。然而,这些方法忽视了视频数据中的固有空间和时间结构,使其在视频生成任务中的效果不佳(见第 5.2 节)。为更好地利用这一结构,已有多种视频专用的稀疏注意力方法被提出 [8, 47, 48, 49]。例如,STA [47] 使用滑动的 3D 窗口进行局部注意力,SVG 则为每个头动态选择空间或时间模式。两者虽提升了效率,但在长视频上仍面临挑战:STA 的固定感受野限制了长程依赖,而 SVG 的运行时分析在未见过的长视频分布上表现不稳定。相比之下,我们的径向注意力(Radial Attention)采用了一个静态的 O ( n log n ) O(n \log n) O(nlogn) 模式,所有头共享。这种静态设计同时加速了训练和推理,支持高效的长视频扩展。
长视频生成。由于稠密注意力的二次复杂度,长视频生成在训练和推理中的资源消耗仍然极高。RIFLEx [50] 通过修改 RoPE [51] 频率以缓解时间重复和运动减慢问题,使得预训练模型可实现 2 倍时长外推。然而,该方法在生成长视频时仍会导致视频质量下降(如模糊)。Dalal 等人提出生成短视频片段并通过测试时训练层进行拼接 [52]。Framepack [53] 则采用自回归策略,基于上下文帧编码为固定数量的 token,逐段生成短片段。其他方法用线性注意力替代稠密注意力 [10, 9, 54, 55, 56, 57, 58, 59],虽然计算速度更快并具备全局感受野,但往往难以捕捉局部细节 [60],导致质量下降。我们的径向注意力(Radial Attention)在 O ( n 2 ) O(n^2) O(n2) 的稠密注意力和 O ( n ) O(n) O(n) 的线性注意力之间实现了平衡,具备 O ( n log n ) O(n \log n) O(nlogn) 复杂度,同时保留了视觉保真度。此外,它能通过 LoRA [11] 从现有模型中高效微调,实现可扩展的长视频生成,几乎无额外开销。
具有 O ( n log n ) O(n \log n) O(nlogn) 复杂度的注意力机制。该方向的初步探索包括 Reformer [61],其利用局部敏感哈希(LSH)对相似的 key/query 进行分桶,从而近似稠密注意力;H-Transformer [62],其在注意力矩阵上施加分层结构;多分辨率注意力(Multi-resolution attention)[63],通过递归细化那些注意力分数较大的区域;以及快速多极注意力(Fast Multipole Attention)[64],它将经典的快速多极方法应用于分层交互。然而,这些方法通常对硬件不友好,且在大规模场景中的可扩展性有限。相比之下,我们的方法采用了一个简单的静态注意力掩码,具备良好的硬件友好性,在保持强大建模能力的同时,实现了高效扩展。
3 Preliminary
扩散模型通过在潜在空间中采样高斯噪声 X T ∼ N ( 0 , I ) X_T \sim \mathcal{N}(0, I) XT∼N(0,I) 并通过神经网络逐步去噪生成清晰的潜在变量 X 0 X_0 X0,随后利用预训练解码器解码为最终视频。相比图像,视频引入了额外的时间维度,显著增加了潜在 token 的数量。例如,在 HunyuanVideo [1] 中生成一个 5 秒 720p 的视频,大约需要 115K 个 token。过度压缩潜在空间通常会损害视频质量,从而对 token 数量的压缩设置了下限 [3]。
为了捕捉视频生成中的时空相关性,近期模型 [7, 1, 22, 5] 采用了 3D 稠密注意力机制,计算所有 token 对之间的交互。给定 n n n 个 token,嵌入维度为 d d d,注意力计算公式为:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d ) V , \text{Attention}(Q, K, V) = \text{softmax} \left( \frac{Q K^\top}{\sqrt{d}} \right) V, Attention(Q,K,V)=softmax(dQK⊤)V,
其中 Q , K , V ∈ R n × d Q, K, V \in \mathbb{R}^{n \times d} Q,K,V∈Rn×d 分别为 query、key 和 value 矩阵。注意力矩阵 Q K ⊤ Q K^\top QK⊤ 的大小为 n × n n \times n n×n,计算复杂度为 O ( n 2 ) O(n^2) O(n2),涉及时间和内存开销。尽管如 FlashAttention [65, 66] 等技术能减少内存开销,但二次时间复杂度仍是瓶颈,尤其在长视频或高分辨率视频中尤为突出。因此,设计更高效的注意力机制对扩散视频模型的扩展至关重要。
为缓解这一计算负担,稀疏注意力通过限制 token 对的交互来减少计算。具体而言,这通常通过向注意力 logits 添加稀疏掩码 M ∈ { − ∞ , 0 } n × n M \in \{-\infty, 0\}^{n \times n} M∈{−∞,0}n×n 来实现:
SparseAttention ( Q , K , V ) = softmax ( Q K ⊤ + M d ) V 。 \text{SparseAttention}(Q, K, V) = \text{softmax} \left( \frac{Q K^\top + M}{\sqrt{d}} \right) V。 SparseAttention(Q,K,V)=softmax(dQK⊤+M)V。
在 softmax 计算中,被置为 − ∞ -\infty −∞ 的项会被忽略。已有多种方案用于构建掩码。静态方法(如 STA [47])为所有输入应用预定义的稀疏模式,但通常表达能力有限。相比之下,动态方法如 SVG [8] 根据输入内容自适应稀疏模式,以提升保真度。然而,动态掩码会引入额外开销来实时确定稀疏模式,且无法用于训练。那么,我们能否设计出一种静态注意力模式,既具备动态方法的表达能力,又能在训练中使用?
4 Method
径向注意力(Radial Attention)的核心洞察在于:token 之间的注意力分数会随着空间和时间距离的增加而衰减。这促使我们基于视频数据中的内在时空相关性来分配计算资源。在第 4.1 节中,我们首先分析了注意力中的时空能量衰减现象。随后,在第 4.2 节,我们正式定义了径向注意力,将能量衰减转化为相应的计算密度降低,从而实现硬件加速。我们还分析了其复杂度和近似误差,证明了该方法的复杂度为 O ( n log n ) O(n \log n) O(nlogn),并且我们的注意力掩码能够有效捕捉注意力中的关键信息。最后,在第 4.3 节中,我们展示了如何利用径向注意力将预训练模型扩展至更长的视频序列。
4.1 Spatiotemporal Energy Decay in Attention
在图4(a)中,我们展示了来自 HunyuanVideo [1] 的两个 softmax 后的注意力图。按照 SVG [8] 中的术语,左侧的注意力图被称为空间注意力(spatial attention),其中每个 token 主要关注同一帧或相邻帧中的邻近 token。右侧的注意力图则表示时间注意力(temporal attention),其中每个 token 关注跨不同帧但处于相同空间位置的 token。图4(b)展示了这两张注意力图的注意力分数分布,以及第三条曲线——多个注意力头和扩散步骤下的平均注意力分数。在图4(b1)中,我们展示了相同空间位置下,随着时间距离增加,token 之间的平均注意力分数。在图4(b2)中,我们展示了同一帧内,随着空间距离增加,token 之间的平均注意力分数。在这两种情况下,注意力分数都随着 query 和 key token 之间的距离增加而明显衰减。我们将这一现象称为“时空能量衰减”(Spatiotemporal Energy Decay)。此外,回归分析表明,这种衰减趋势与指数分布高度吻合(见第 5.3 节)。
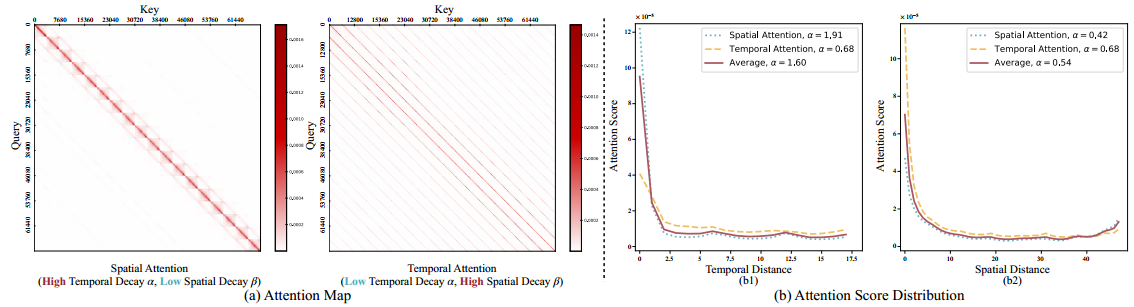
图4:(a)来自 HunyuanVideo 的空间和时间注意力图示例(定义见第 4.1 节)。(b)注意力分数分布。(b1):相同空间位置下的 token,其平均注意力分数随时间距离增加而下降。(b2):同一帧内的 token,其平均注意力分数随空间距离增加而下降。Spatial 和 Temporal Attention 分别表示来自 (a) 中对应注意力图的分布。Average 表示在多个随机注意力图和扩散步骤下的平均值。图中的曲线表明,空间注意力具有较强的时间衰减、而空间衰减相对较弱,而时间注意力则表现出相反的趋势。
具体而言,按照第 3 节中的符号约定,假设视频潜在表示包含 f f f 帧,每帧包含 s s s 个 token(总共有 n = f s n = f s n=fs 个 token)。考虑一个 query token,其位于第 i 0 i_0 i0 帧中第 k 0 k_0 k0 个空间位置。softmax 后的对应注意力分数记为 p ∈ [ 0 , 1 ] n \mathbf{p} \in [0, 1]^n p∈[0,1]n,其计算公式为:
p = softmax ( Q i 0 s + k 0 K ⊤ ) 。 \mathbf{p} = \text{softmax}(\mathbf{Q}_{i_0 s + k_0} \mathbf{K}^\top)。 p=softmax(Qi0s+k0K⊤)。
则存在常数 α , β > 0 \alpha, \beta > 0 α,β>0 和 C rel > 0 C_{\text{rel}} > 0 Crel>0,对于每个位于第 j j j 帧、空间位置 l l l 的 key token,满足以下不等式:
p j s + l ≤ C rel e − α ∣ j − i 0 ∣ − β ∣ l − k 0 ∣ p i 0 s + k 0 。 p_{j s + l} \leq C_{\text{rel}} e^{-\alpha |j - i_0| - \beta |l - k_0|} p_{i_0 s + k_0}。 pjs+l≤Crele−α∣j−i0∣−β∣l−k0∣pi0s+k0。
其中,参数 α \alpha α 和 β \beta β 分别控制时间和空间的衰减。高 β \beta β(强空间局部性)和低 α \alpha α 用于建模时间注意力,而高 α \alpha α 和低 β \beta β 用于捕捉空间注意力,如图 4(b) 中的实证曲线所示。这一观察启发了我们提出的统一稀疏模式,该模式能够系统性地同时利用空间和时间的衰减特性。
4.2 Radial Attention: Convert the Energy Decay to Compute Density Decay
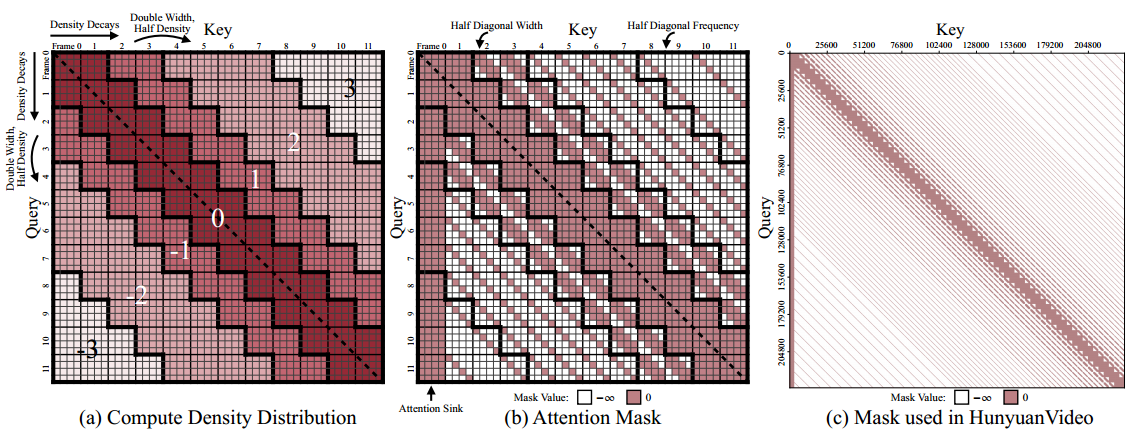
图 5:(a)计算密度模式。注意力图根据 token 之间的时间距离被划分为 2 ⌈ log 2 ( max ( f , 2 ) ) ⌉ − 1 2 \left\lceil \log_2 (\max(f, 2)) \right\rceil - 1 2⌈log2(max(f,2))⌉−1 个带(此处帧数 f = 12 f = 12 f=12)。中心带具有完整的计算密度,每个外层带的密度是前一带的一半。除去带 ± 1 \pm 1 ±1 外,每个带的对角宽度也是其前一带的两倍。(b)与(a)对应的注意力掩码。计算密度通过每个帧间块的对角宽度反映出来。当对角宽度低于 1 时,我们减少对角线的频率。此外,我们还加入了一个 attention sink(注意力汇)。(c)HunyuanVideo 中使用的一个掩码示例,展示了实际应用中的最终稀疏模式。
径向注意力通过计算密度衰减来模拟能量衰减,从而节省计算量。
Temporal density decay(时间密度衰减)。沿时间维度,径向注意力采用简单的指数衰减规则:帧 i i i 和帧 j j j 之间的计算密度设为$
\left( \frac{1}{2} \right)^{\lfloor \log_2 (\max(|i-j|, 1)) \rfloor}。$
这在图 5(a) 中展示了一个结构化模式:注意力图被划分为 2 ⌈ log 2 ( max ( f , 2 ) ) ⌉ − 1 2 \left\lceil \log_2 (\max(f, 2)) \right\rceil - 1 2⌈log2(max(f,2))⌉−1 条以主对角线(带 0)为中心的对角带。对角线上下的带被编号为 1 , 2 , 3 , … 1, 2, 3, \ldots 1,2,3,… 和 − 1 , − 2 , − 3 , … -1, -2, -3, \ldots −1,−2,−3,…。每条带的宽度是上一条带的两倍,从而保证每个带内的总计算量受限。帧 i i i 到帧 j j j 的注意力落在带$
\text{sign}(j - i) \cdot \lfloor \log_2 \max(|i - j|, 1) \rfloor。$
中心带(带 0)保留 100% 计算密度,每向外一带的计算密度减半,形成逐渐变浅的径向衰减效果。
Spatial density decay(空间密度衰减)。如图 4 和公式 (3) 所示,大部分注意力集中在跨帧相似空间位置的 token 上。我们保留这些高能量交互,在每个帧间注意力块内形成对角线结构。由于时间衰减,这些块的对角宽度随时间距离增加而收缩。具体而言,图 5(b) 中,帧 i i i 和帧 j j j 之间的对角宽度为:$
\left\lfloor \frac{s}{2^{\lfloor \log_2 \max(|i - j|, 1) \rfloor}} \right\rfloor。$
若结果小于 1,我们减少对角线数量,仅保留满足$
|i - j| \bmod \left\lceil \frac{2^{\lfloor \log_2 \max(|i - j|, 1) \rfloor}}{s} \right\rceil = 0$
的对角线,以保持均摊的注意力密度衰减。
Formal definition(正式定义)。径向注意力中的注意力掩码 M ~ ∈ { − ∞ , 0 } f × f × s × s \tilde{M} \in \{-\infty, 0\}^{f \times f \times s \times s} M~∈{−∞,0}f×f×s×s 定义如下:若元素 M ~ i , j , k , l = 0 \tilde{M}_{i,j,k,l} = 0 M~i,j,k,l=0,表示第 i i i 帧第 k k k 位置的 token 允许关注第 j j j 帧第 l l l 位置的 token;若 M ~ i , j , k , l = − ∞ \tilde{M}_{i,j,k,l} = -\infty M~i,j,k,l=−∞,表示禁止该对 token 之间的注意力。掩码构造如下:
M ~ i , j , k , l = { 0 , 若 2 ⌊ log 2 max ( ∣ i − j ∣ , 1 ) ⌋ ≤ s 且 ∣ k − l ∣ + 1 ≤ ⌊ s 2 ⌊ log 2 max ( ∣ i − j ∣ , 1 ) ⌋ ⌋ 0 , 若 ∣ i − j ∣ m o d ⌈ 2 ⌊ log 2 max ( ∣ i − j ∣ , 1 ) ⌋ s ⌉ = 0 且 k = l − ∞ , 其他情况 \tilde{M}_{i,j,k,l} = \begin{cases} 0, & \text{若 } 2^{\lfloor \log_2 \max(|i - j|, 1) \rfloor} \leq s \text{ 且 } |k - l| + 1 \leq \left\lfloor \frac{s}{2^{\lfloor \log_2 \max(|i - j|, 1) \rfloor}} \right\rfloor \\ 0, & \text{若 } |i - j| \bmod \left\lceil \frac{2^{\lfloor \log_2 \max(|i - j|, 1) \rfloor}}{s} \right\rceil = 0 \text{ 且 } k = l \\ -\infty, & \text{其他情况} \end{cases} M~i,j,k,l=⎩
⎨
⎧0,0,−∞,若 2⌊log2max(∣i−j∣,1)⌋≤s 且 ∣k−l∣+1≤⌊2⌊log2max(∣i−j∣,1)⌋s⌋若 ∣i−j∣mod⌈s2⌊log2max(∣i−j∣,1)⌋⌉=0 且 k=l其他情况
最终的注意力掩码 M ∈ { − ∞ , 0 } n × n M \in \{-\infty, 0\}^{n \times n} M∈{−∞,0}n×n 通过将帧和空间索引展平成 M i s + k , j s + l = M ~ i , j , k , l M_{i s + k, j s + l} = \tilde{M}_{i,j,k,l} Mis+k,js+l=M~i,j,k,l 获得。图 5© 展示了我们在 HunyuanVideo 中生成 253 帧 720p 视频时使用的掩码示例。
该策略在高时间接近性下保留空间交互,同时对远距离帧稀疏采样以提升效率。为进一步提升视频质量,我们还加入了 attention sink [38, 8],确保所有 token 都能关注第一帧的 token。
Relation to SVG(与 SVG 的关系)。径向注意力使用单一掩码统一了 SVG [8] 中的空间和时间注意力。掩码中的中心带(图 5(a) 中的带 0)已覆盖密集的空间交互,相当于吸收了 SVG 的空间注意力。而在时间维度上,SVG 忽略了时间衰减,对远帧分配了多余计算;相反,径向注意力减少了对远帧的关注,集中计算预算于时间接近的 token,从而同时提升效率和局部时间动态建模能力。
Complexity analysis(复杂度分析)。我们方法的计算成本与掩码 M ~ \tilde{M} M~ 中的 0 元素数量成正比。对于大帧数 f f f,其上界为:
KaTeX parse error: Expected 'EOF', got '#' at position 27: …hered} \text { #̲zeros in } \til…
公式 5 的详细推导见附录 A.1。从公式 6 可知,对于长视频(即 f f f 大)且空间分辨率 s s s 固定的情况,总计算复杂度呈 O ( n log n ) O(n \log n) O(nlogn) 规模扩展。HunyuanVideo 的实验(图 2)证实了该趋势。在生成 509 帧 720p 视频时,径向注意力比稠密注意力减少 9 倍计算量。
Error analysis(误差分析)。根据公式 3,我们为 query token ( i 0 , k 0 ) (i_0, k_0) (i0,k0) 的注意力分数推导了误差界。设 p ~ = softmax ( Q i 0 s + k 0 K ⊤ + M ~ i 0 s + k 0 ) \tilde{\mathbf{p}} = \text{softmax} (\mathbf{Q}_{i_0 s + k_0} \mathbf{K}^\top + \tilde{M}_{i_0 s + k_0}) p~=softmax(Qi0s+k0K⊤+M~i0s+k0) 为掩码后的注意力分数,则 ℓ 1 \ell_1 ℓ1 误差满足:
∥ p ~ − p ∥ 1 ≤ C rel [ 8 e − β ( s 2 + 1 ) ( 1 − e − α ) ( 1 − e − β ) + 4 1 + e − β 1 − e − β e − α ( s + 1 ) 1 − e − α ] = O ( C rel e − min ( β / 2 , α ) s ) 。 \| \tilde{\mathbf{p}} - \mathbf{p} \|_1 \leq C_{\text{rel}} \left[ \frac{8 e^{-\beta \left( \frac{s}{2} + 1 \right)}}{(1 - e^{-\alpha})(1 - e^{-\beta})} + 4 \frac{1 + e^{-\beta}}{1 - e^{-\beta}} \frac{e^{-\alpha (s + 1)}}{1 - e^{-\alpha}} \right] = O \left( C_{\text{rel}} e^{-\min(\beta / 2, \alpha) s} \right)。 ∥p~−p∥1≤Crel[(1−e−α)(1−e−β)8e−β(2s+1)+41−e−β1+e−β1−e−αe−α(s+1)]=O(Crele−min(β/2,α)s)。
证明细节见附录 A.2。公式 7 表明,当衰减率 α \alpha α 和 β \beta β 较大时,误差呈指数下降。在第 5.3 节,我们进一步实证比较了该误差界和 SVG 的误差,显示径向注意力具有更小的误差,从而验证了其有效性。
Hardware-friendly block sparsity(硬件友好的块稀疏性)。为确保现代硬件上的高效执行,我们采用基于块的注意力计算,而非逐个 1 × 1 1 \times 1 1×1 token 计算 [67, 8, 40, 43, 44, 65]。我们的实现采用 128 × 128 128 \times 128 128×128 的块大小。
4.3 Low-Rank Adaptation for Long Videos
尽管我们采用了高效的注意力机制,但预训练模型最初是基于短视频训练的。近期工作 [50] 探索了无需训练的方法来扩展长视频生成,但由于长度分布不匹配,其性能仍然受限。与此同时,直接在长视频上训练在时间和内存上都是不可承受的。Radial Attention 通过将训练时间复杂度降低到 O ( n log n ) \mathcal{O}(n \log n) O(nlogn) 缓解了这一难题。更重要的是,它保留了 softmax 注意力中的关键 token 间关系,使原始预训练权重基本保持不变。因此,只需最小量的微调即可。为进一步降低训练开销,我们在注意力机制中引入了低秩适配器(LoRA)[11, 39]。具体而言,LoRA 被应用于注意力层的 query、key、value 和输出投影部分,从而实现了高效微调,显著减少了内存和计算成本。实证结果表明,将 LoRA 微调与 Radial Attention 结合,不仅减少了开销,还通过只微调最关键的权重并更有效地集中注意力,提升了视频质量。详见第 5.3 节的详细结果。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 23
23 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)