
用大模型构建专属AI智能客服
通过OpenAI提供的接口可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,提取语义特征向量存入向量数据库中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配,得到蹩脚的、不连续的回复关键字句,然后这个时候再经ChatGPT润色就可以轻松实现智能AI客服,AI知识库等应用。所以,不少人会有这样子的想法,将产品资料、售前内容资料,将这些资料告诉给ChatGPT,然后ChatGPT
在大模型之前,其实对话式AI一直在被广泛使用在客服场景,只不过不大智能而已。比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。那么,怎么用ChatGPT搭建基于私有数据的 AI客服机器人?
01 只需Prompt就可以将大模型训练成客服?
面向C端或B端用户群体,售前会有很多的用户咨询,比如产品介绍、产品优势、产品价格、部署问题等等,需要耗费比较多的精力去维护。
但目前ChatGPT是一个大而广的模型,它的内容可能会超出了我们希望的范围。
所以,不少人会有这样子的想法,将产品资料、售前内容资料,将这些资料告诉给ChatGPT,然后ChatGPT能基于这些数据回答我的问题,甚至能给用户提供更好的建议等。
在提问的时候,将我的Prompt 文本直接传给 大模型,比如角色、要求、参考资料等。
最早的demo时候,这种非常笨的方法是可以有像样的结果的,这个方法能用是能用,而且效果还不错。
02 Token限制怎么解决?
目前 大模型有个非常大的限制,它限制了最大的 token 数是 4096,大约是 16000 多个字符。换句话来说,我的一次对话,如果token 数超过4096时候, 大模型就会忘了我之前喂给他的内容,就会一本正经“胡说八道” 了!
这个问题就一直卡了我很久,直到我一个朋友给我介绍,他说OpenAI官方提供了两种方法,可以直接调用他们接口,将自己的数据上传给GPT:
Fine-tuning(微调)和Embeddings(嵌入)
那么这两种方式有各有什么优劣呢?
-
Fine-tuning(微调)就是在大模型的数据基础上做二次训练,比如davinci、ada等等,需要事先准备好一批prompt-complition(类似于答Q&A)的数据,适合很久知识都不变且数据集较小的情况。
-
Embeddings(嵌入)则是每次向ChatGPT发送消息(Prompt)的时候,把你自己数据结果带上发送给GPT。让GPT根据这个预设的Prompt和问题再加私有数据做回答,适合数据量超大且实时更新的一些数据。
你可以这样简单理解,ChatGPT就像一个已经训练好的家政阿姨,她懂中文,会做家务,但是对你家里的情况不了解。
-
Fine-tuning(微调)就相当于阿姨第一次到你家干活的时候,你要花一小时时间告诉她家里的情况,比如物件的摆放、哪些地方不能动,哪些地方要重点照顾。
-
Embeddings(嵌入)就相当于你省去了对阿姨进行二次培训,而是在家里贴满纸条,这样阿姨一看到纸条就知道该怎么做了。
综合考虑后,我们这个产品采用了Embeddings(嵌入)模型,并在每次对话中,将预设Prompt+AI角色打包发送给GPT,让大模型根据这个预设的Prompt+私有数据+问题做回答,这样就解决了绝大部分4096个token限制的问题了。
03 Embeddings模型和私有数据
怎么整合?
这里先解释下什么是 Embedding模型。
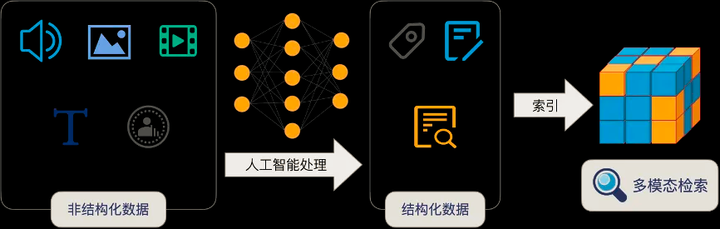
人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些向量如同数学空间中的坐标,标识着各个实体和实体关系。我们一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程。
具体产品思路,如图所示
原理如下:
1)把PDF/Word/TXT/Markdown等文档切分成小的文本片段,通过OpenAI的Ada模型创建Embedding放到本地或远程向量数据库。
2)把用户的提问也创建成Embedding,用它和之前创建的PDF/Word/TXT/Markdown向量比对,通过语义相似性搜索(余弦算法),找到最相关的文本片段。比关键词搜索好的一点是不要求关键词包含,也能发现文本相关性,比如汽车和公路。
3)把用户提问和相似文本片段发给OpenAI,写Prompt要求ChatGPT基于给定的内容生成回答,如果没有相似文本或关联度不高,则回答不知道。
实际上大部分传统的问答机器人,都是基于规则的知识图谱方式实现,这种方式需要对大量的语料进行分类整理。
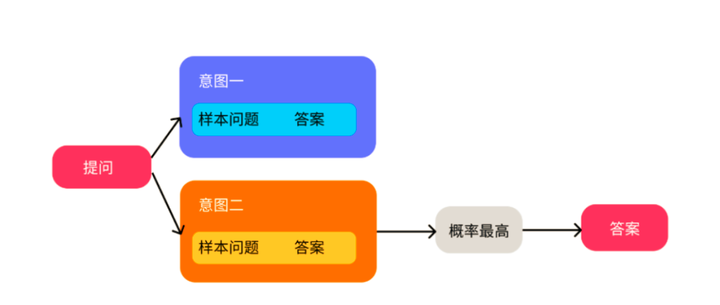
通过大模型提供的接口可以彻底摆脱对语料的预处理,只需提供问题和答案的对应关系,提取语义特征向量存入向量数据库中,然后对提问的问题也进行语义特征向量提取,通过对向量特征的匹配,得到蹩脚的、不连续的回复关键字句,然后这个时候再经大模型润色就可以轻松实现智能AI客服,AI知识库等应用。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)