
LLaMA Factory 多模态微调实践:微调 Qwen2-VL 构建文旅大模型
本教程将基于通义千问团队开源的新一代多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 PAI 平台及 LLaMA Factory 训练框架完成文旅领域大模型的构建。
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 3 万。本教程将基于通义千问团队开源的新一代多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 PAI 平台及 LLaMA Factory 训练框架完成文旅领域大模型的构建。
运行环境要求
- GPU 推荐使用 24GB 显存的 A10(
ecs.gn7i-c8g1.2xlarge)或更高配置 - 镜像选择 DSW 官方镜像
modelscope:1.18.0-pytorch2.3.0-gpu-py310-cu121-ubuntu22.04
1. 安装 LLaMA Factory
首先,拉取 LLaMA-Factory 项目到 DSW 实例。
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
%cd LLaMA-Factory
接着,我们安装 LLaMA-Factory 依赖环境。
!pip uninstall -y accelerate vllm matplotlib
!pip install llamafactory==0.9.0
运行如下命令,如果显示 LLaMA Factory 的版本,则表示安装成功。
!llamafactory-cli version
2. 下载数据集
LLaMA-Factory 项目内置了丰富的数据集,放在了 data 目录下。您可以跳过本步骤,直接使用内置数据集。您也可以准备自定义数据集,将数据处理为框架特定的格式,放在 data 下,并且修改 dataset_info.json 文件。
本教程准备了一份多轮对话数据集,运行下述命令下载数据。
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
!mv data rawdata && unzip Qwen2-VL-History.zip -d data
数据集中的样本为单轮对话形式,含有 261 条样本,每条样本都由一条系统提示、一条用户指令和一条模型回答组成,微调过程中模型不断学习样本中的回答风格,从而达到学习文旅知识的目的。数据样例如下所示:
[
{
"conversations": [
{
"from": "system",
"value": "你是一个导游,请生动有趣地回答游客提出的问题"
},
{
"from": "human",
"value": "给我讲讲这个东西<image>"
},
{
"from": "gpt",
"value": "各位游客朋友们,大家好!\n\n现在映入大家眼帘的,是一件极为珍贵的文物——**神面纹玉戚**。它可不是一般的宝贝,而是来自遥远的新石器时代的一件精美玉器哦!\n\n这件宝贝现藏于山西博物院,它的尺寸相当精致:高20.6厘米,宽13.1厘米,厚仅0.4厘米,真是薄如蝉翼,工艺精湛!\n\n1964年,它在黎城县后庄村广志山出土,仿佛穿越时空,向我们诉说着古老的故事。\n\n大家仔细看,这块玉戚采用了线刻工艺,一侧雕刻着神人的半侧面头像,头戴华美的冠饰,披拂着飘逸的长发,眼眉清晰可辨,仿佛在凝视着我们;而另一侧则是一个方形台座上置神人冠饰的形象,显得神秘而威严。\n\n要知道,玉戚在古代可是象征军事统帅权力的神器,握有它,就如同掌握了千军万马!\n\n大家不妨多停留片刻,感受一下这件文物散发出的古老而神秘的气息吧!\n\n谢谢大家的聆听,接下来我们将继续参观其他精彩展品,敬请期待!"
}
],
"images": [
"images/instance_1579398113581395972.jpg"
]
}
]
3. 模型微调
3.1 启动 Web UI
做好前序准备工作后,直接运行下述命令就可以启动 Web UI。这里用到的环境变量解释如下:
USE_MODELSCOPE_HUB设为 1,表示模型从 ModelScope 魔搭社区下载。避免从 HuggingFace 下载模型导致网速不畅。
点击返回的 URL 地址,进入 Web UI 页面。
!USE_MODELSCOPE_HUB=1 llamafactory-cli webui
3.2 配置参数
进入 WebUI 后,可以切换语言到中文(zh)。首先配置模型,本教程选择 Qwen2VL-2B-Chat 模型,微调方法修改为 full,针对小模型使用全参微调方法能带来更好的效果。 
数据集使用上述下载的 train.json。 
可以点击「预览数据集」。点击关闭返回训练界面。 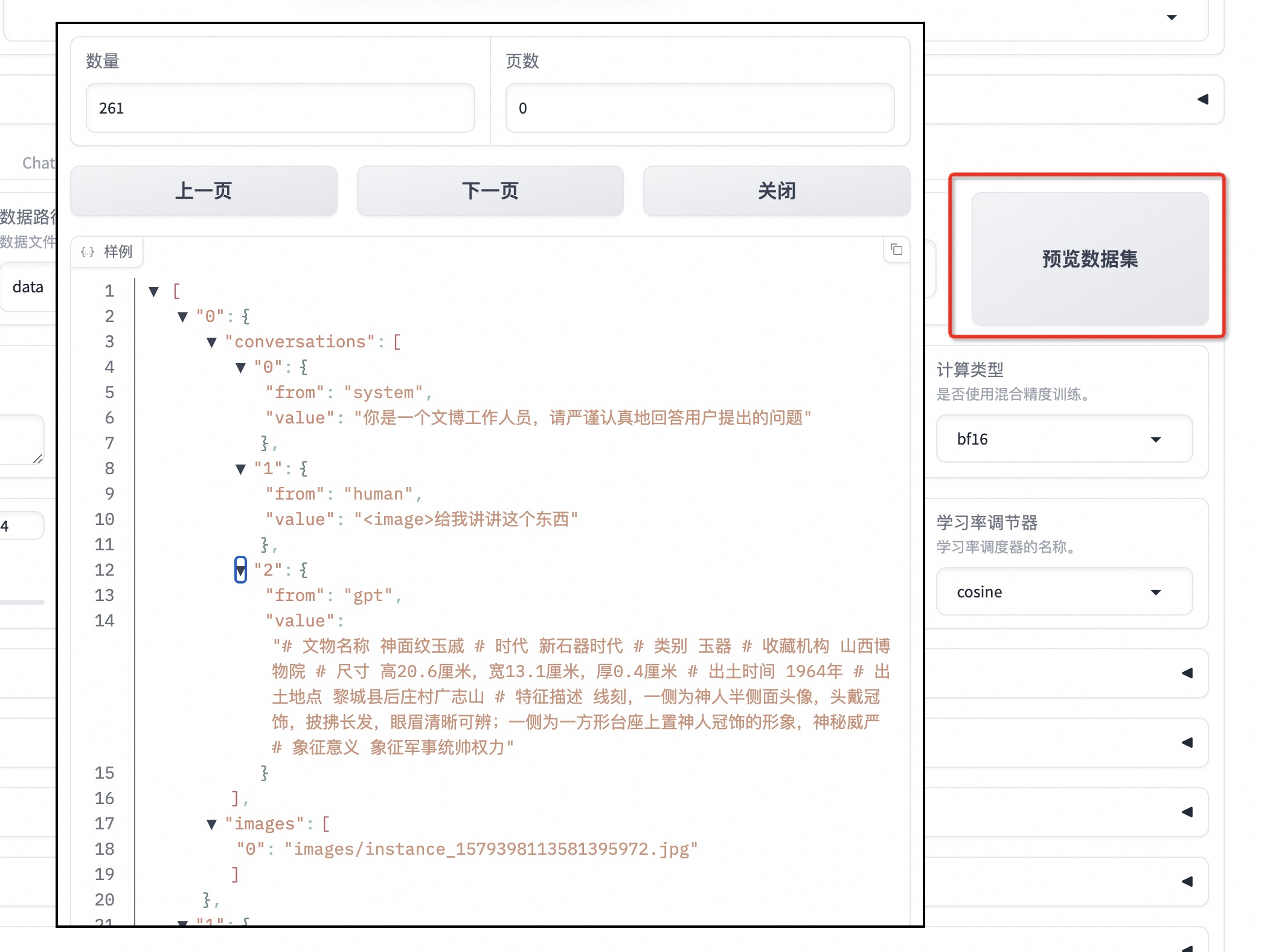
设置学习率为 1e-4,训练轮数为 10,更改计算类型为 pure_bf16,梯度累积为 2,有利于模型拟合。 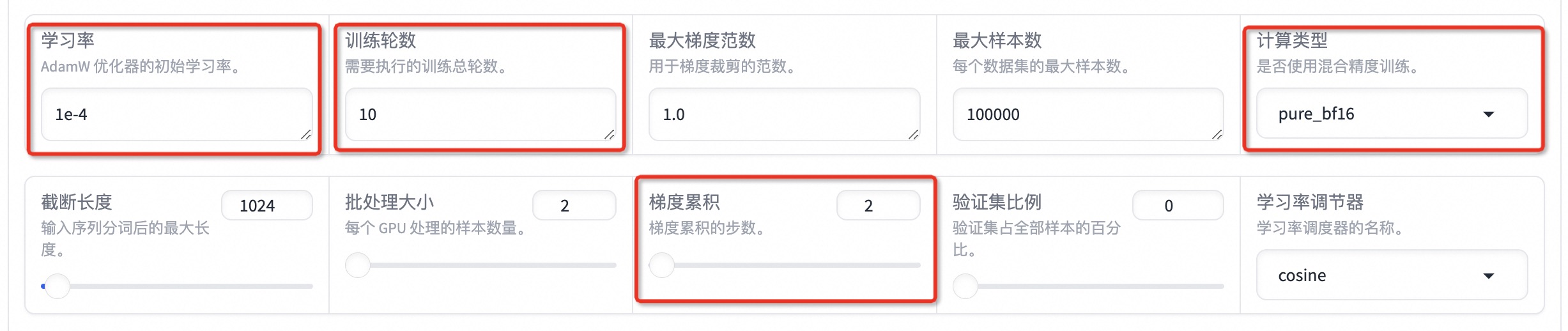
在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。 
3.3 启动微调
将输出目录修改为 train_qwen2vl,训练后的模型权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,您如果想通过代码运行微调,可以复制这段命令,在命令行运行。
点击「开始」启动模型微调。 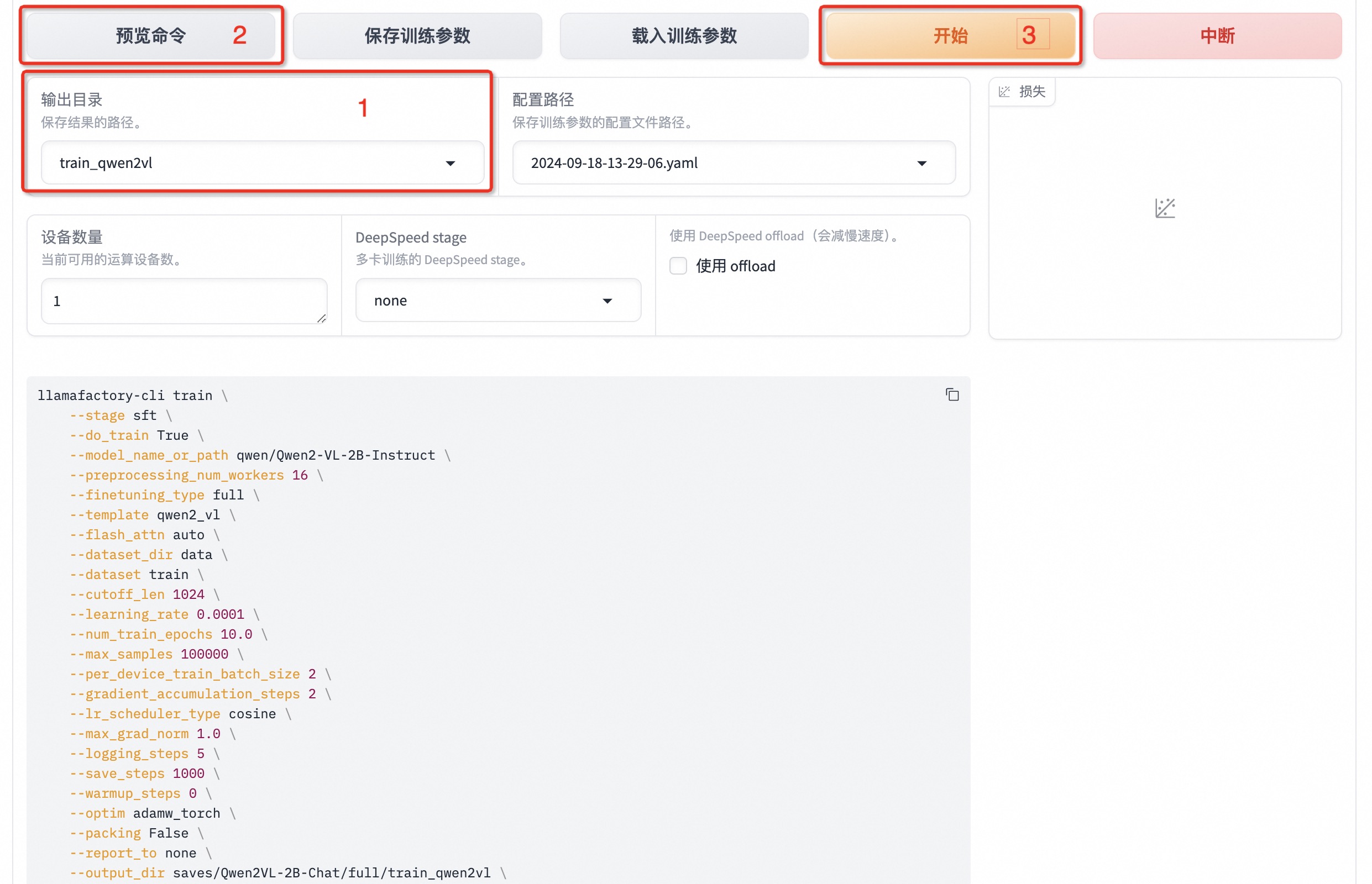
启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要 14 分钟,显示“训练完毕”代表微调成功。 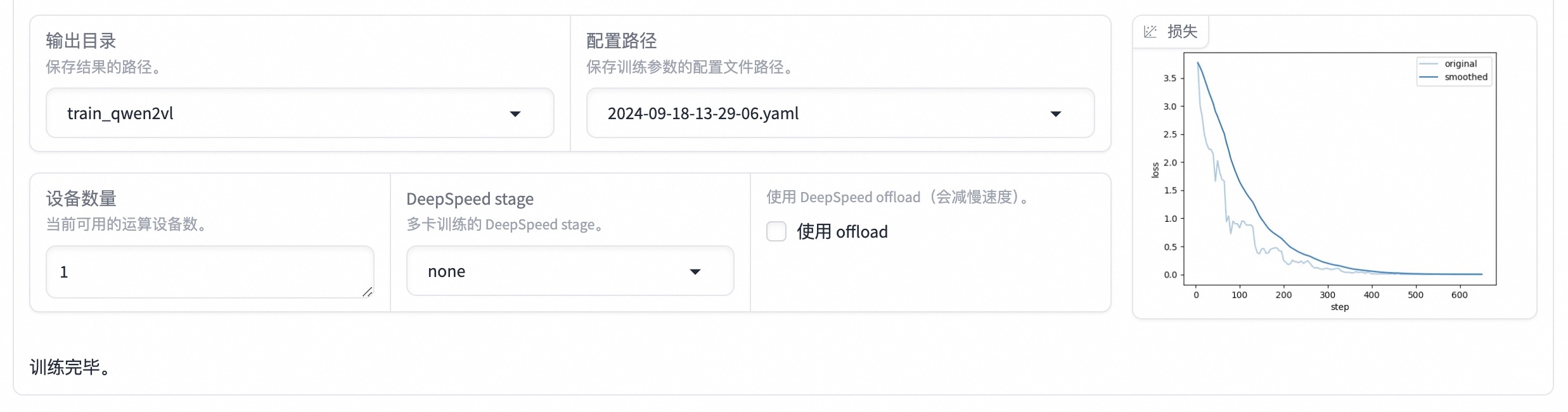
4. 模型对话
选择「Chat」栏,将检查点路径改为 train_qwen2vl,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。 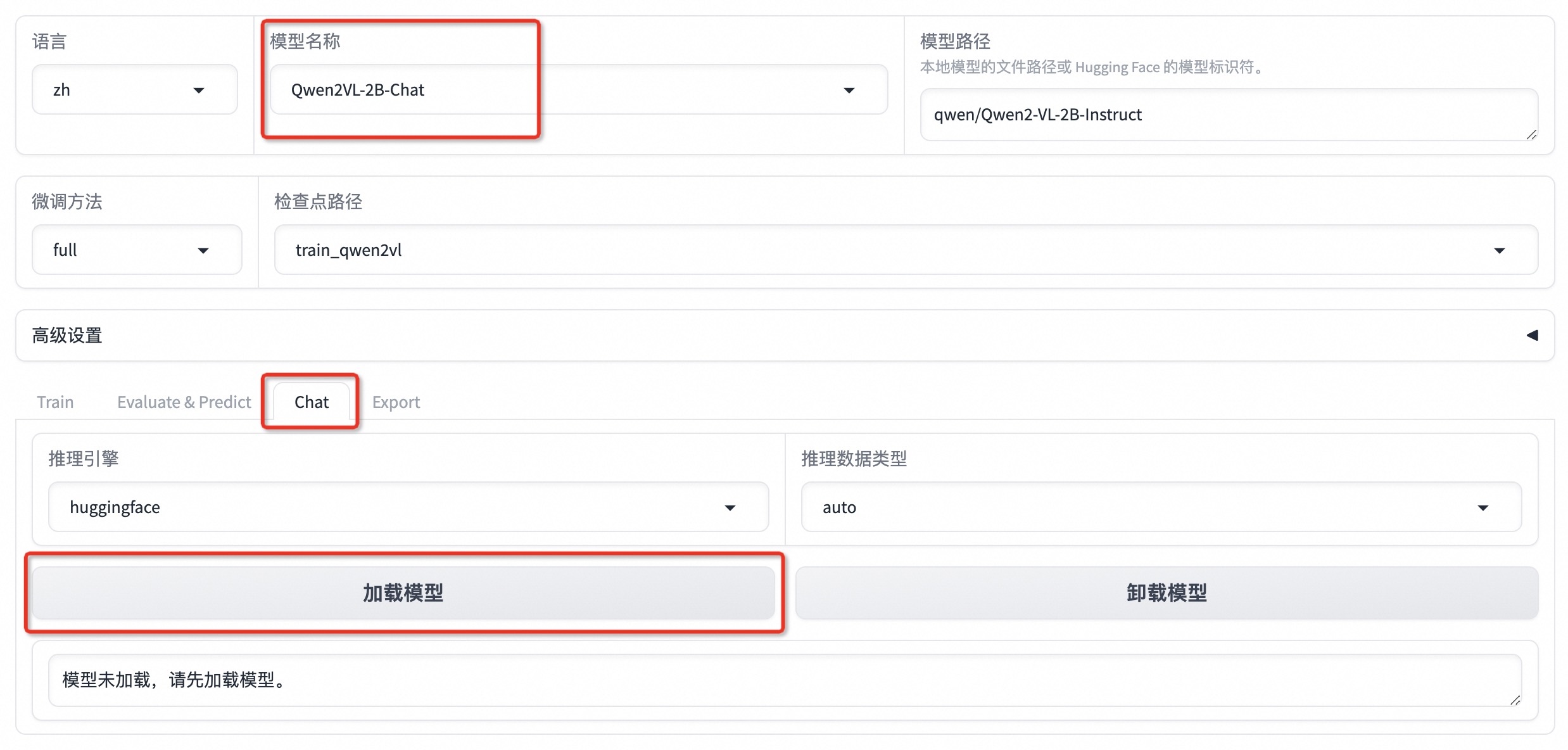
首先点击下载测试图片1或测试图片2,并上传至对话框的图像区域,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。在页面底部的对话框输入想要和模型对话的内容,点击提交即可发送消息。 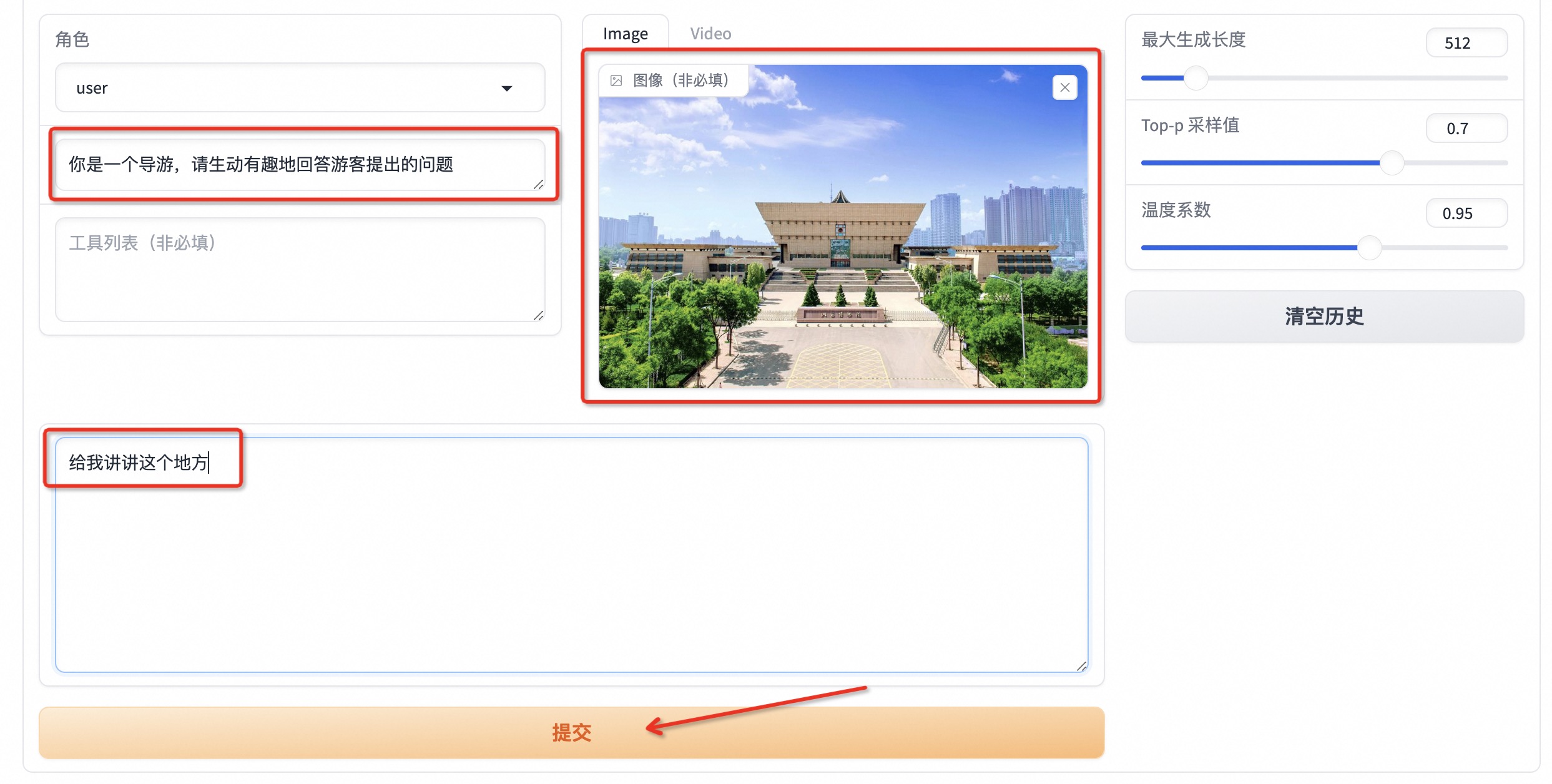
发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿导游的语气介绍图中的山西博物院。 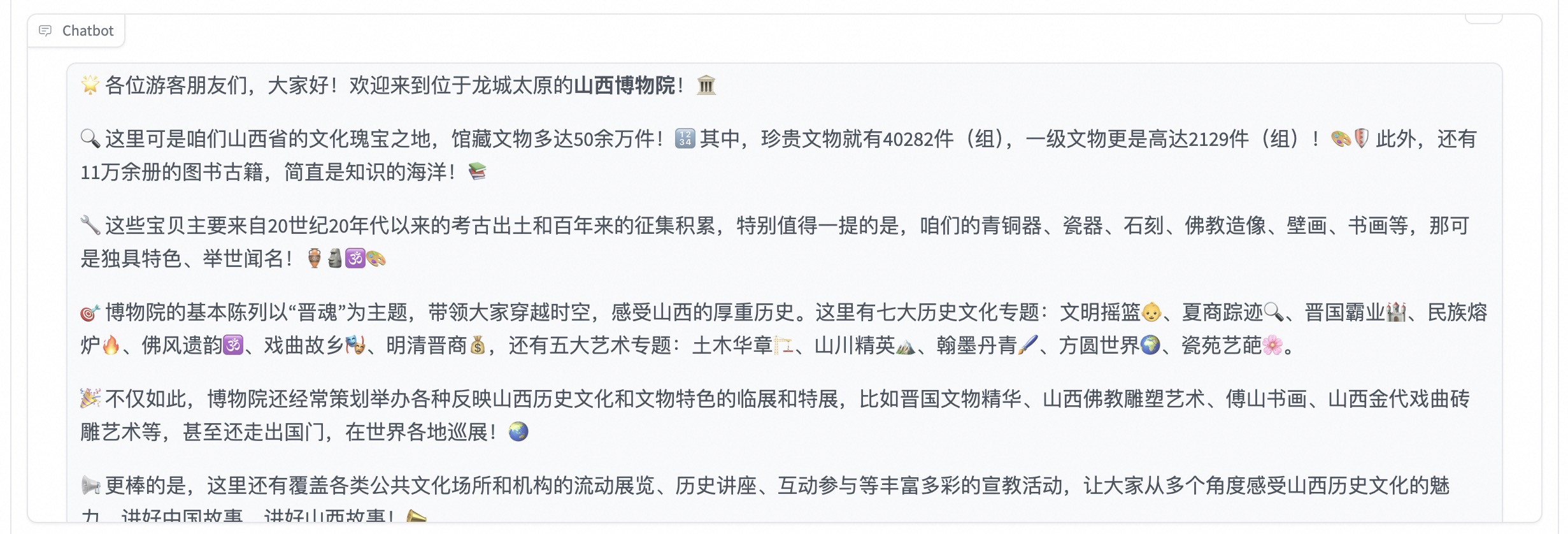
点击「卸载模型」,点击检查点路径输入框取消勾选检查点路径,再次点击「加载模型」,即可与微调前的原始模型聊天。 
重新向模型发送相同的内容,发现原始模型无法准确识别山西博物院。 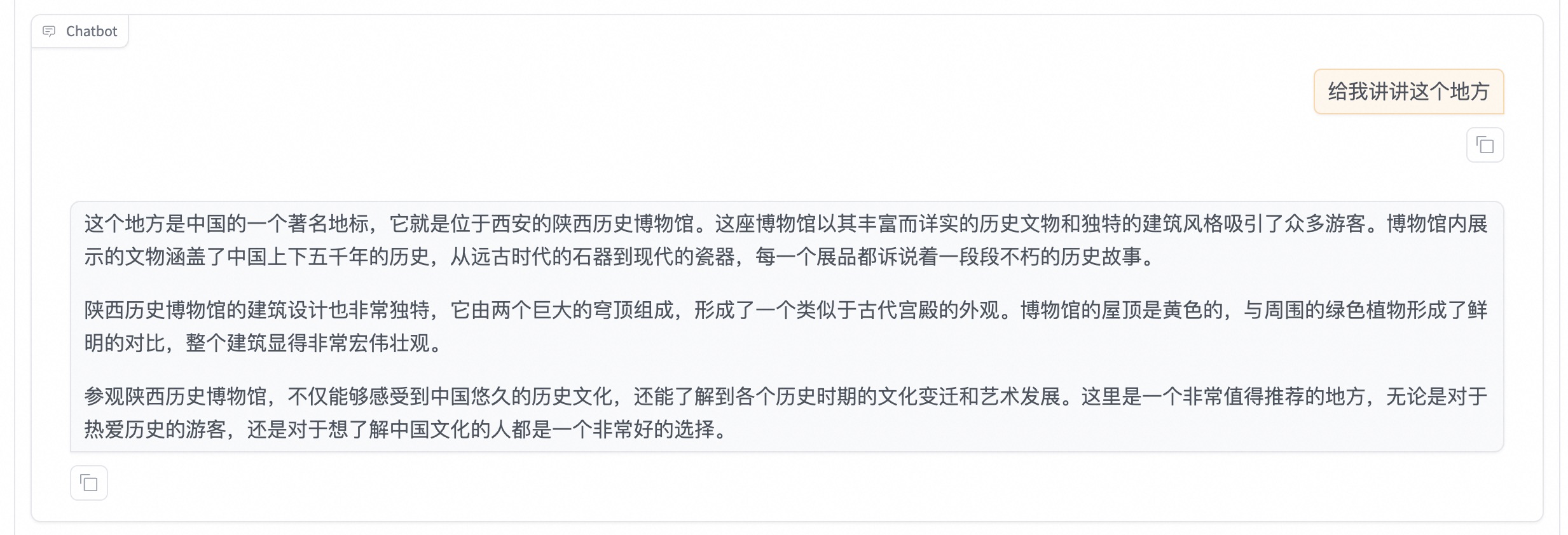
5. 总结
本次教程介绍了如何使用 PAI 和 LLaMA Factory 框架,基于全参方法微调 Qwen2-VL-2B 模型,使其能够进行文旅领域知识问答,同时通过人工测试验证了微调的效果。在后续实践中,可以使用实际业务数据集,对模型进行微调,得到能够解决实际业务场景问题的本地领域多模态大模型。
如何学习大模型技术,享受AI红利?
面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,详尽的全套学习资料,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
无论是初学者,还是希望在某一细分领域深入发展的资深开发者,这样的学习路线图都能够起到事半功倍的效果。它不仅能够节省大量时间,避免无效学习,更能帮助开发者建立系统的知识体系,为职业生涯的长远发展奠定坚实的基础。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

结语
大模型作为新时代的风口,确实为那些希望转行或寻求职业突破的人提供了广阔的舞台。然而,是否选择进入这一领域还需综合考虑自身的兴趣、特长以及长远规划。通过构建基础知识体系、参与实际项目、拓展软技能、关注跨学科融合以及建立广泛的社交网络,你可以在这个充满机遇的新领域中迅速站稳脚跟。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 20
20 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

{kind=link}
{kind=link}
所有评论(0)