
多模态论文3:LAVT模型
LAVT模型,一种用于指称图像分割的语言感知视觉Transformer。传统方法通常在特征编码后才进行跨模态融合,而LAVT创新地在视觉Transformer编码器中早期融合语言和视觉特征。通过PWAM模块计算跨模态注意力,并结合LG模块自适应控制语言信息流向。该方法仅需轻量级解码器,在三个基准测试上均优于现有技术。消融实验表明,残差式融合方式能有效保留预训练视觉特征的性能。LAVT通过充分利用T
标题:LAVT: Language-Aware Vision Transformer for Referring Image Segmentation --2022
用于指称图像分割的语言感知视觉Transformer网络
摘要:
本文认为通过在视觉Transformer编码器网络中早期融合语言和视觉特征,可以实现更好的跨模态对齐,可以利用Transformer编码器的极佳的相关建模能力来挖掘有用的多模态上下文。这样,准确的分割结果只需要轻量级的解码器,没有其他花里胡哨的东西
(过去是在分别提取完特征后通过复杂的解码器对视觉语言特征进行融合,本文方法优于之前的所有效果)
关键图:
模型图
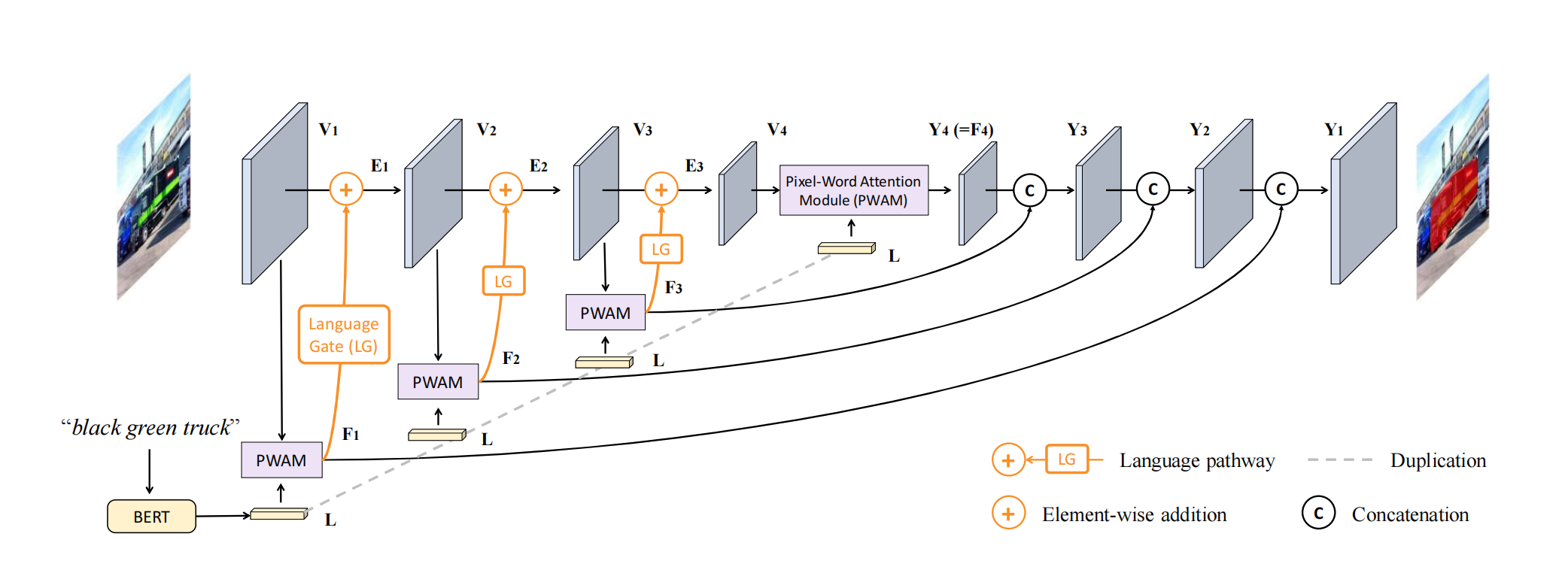
使用多个Transformer编码层(每层具有相同的输出大小),多模态特征融合模块(PWAM)θi,和一个可学习的门控单位(LG)ψi. 在每个阶段中,通过三个步骤生成和改进语言感知视觉特征:
一 Transformer层将前一阶段的特征作为输入,输出丰富的视觉特征,记为Vi∈RCi×Hi×Wi(此处指SwinTransformer层)
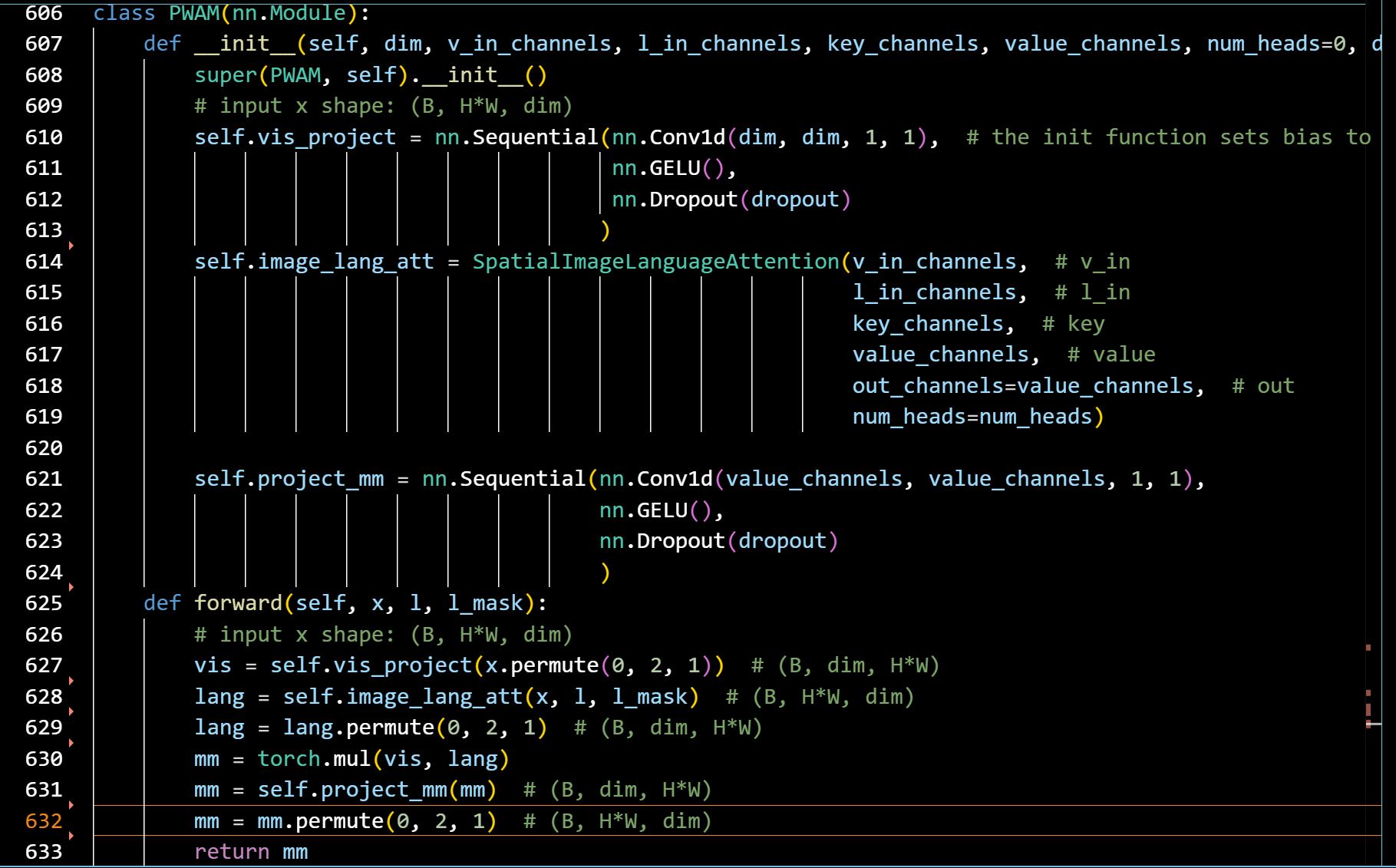
二 通过多模态特征融合模块θi将Vi与语言特征L结合,得到一组多模态特征,记为Fi∈RCi×Hi×Wi(即通过PWAM计算跨模态注意力并与原视觉特征做残差连接)
三 Fi中的每个元素被可学习的门控单元ψi加权,然后将元素添加到Vi中,以产生一组嵌入语言信息的增强视觉特征,将其记为Ei∈RCi×Hi×Wi(控制多模态特征在视觉特征的占比)
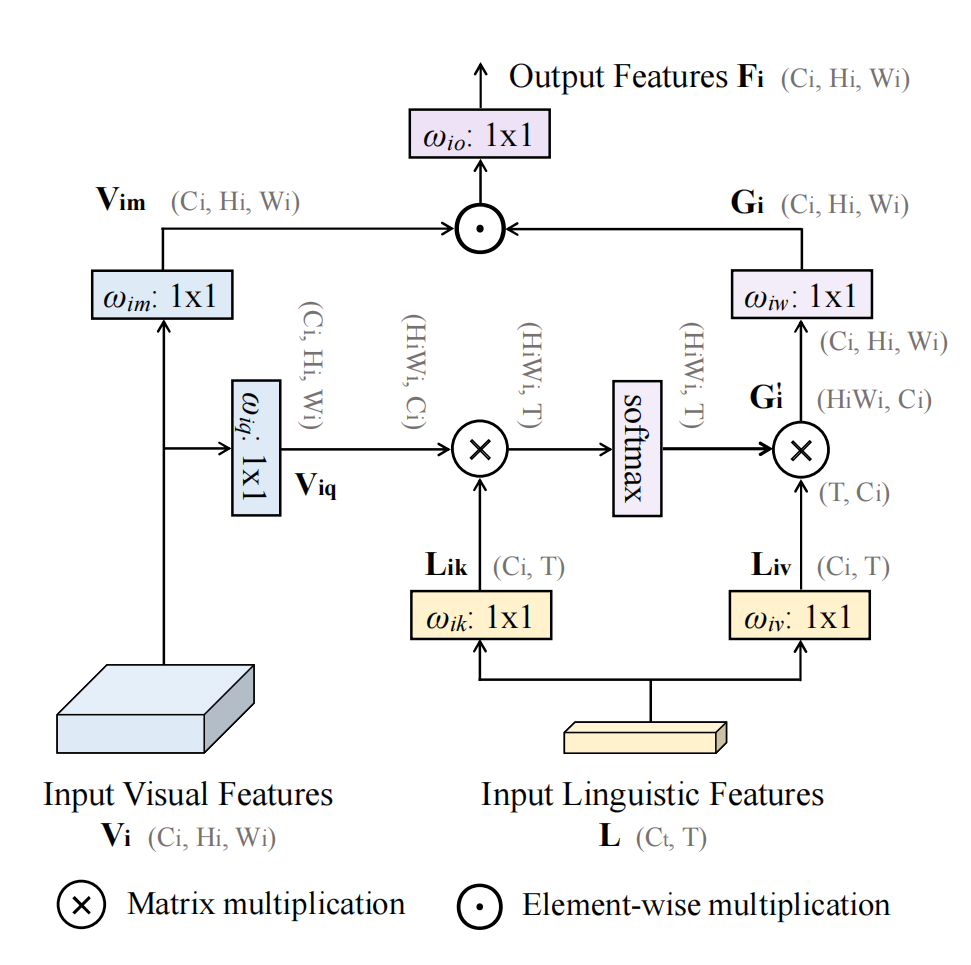
PWAM模块
输入的视觉特征作为Q,语言特征作为K,V,通过Q、K计算出语言特征在视觉特征上的注意力分数(RHWxT)后,
与V进行点积,得出跨模态融合后的视觉特征图
其中ωiq ωik ωiv和ωiw是投影函数。每个语言投影ωik和ωiv都被实现为1×1与Ci的卷积输出通道,
将查询投影ωiq和最终投影ωiw分别实现为1×1卷积,然后进行实例归一化,输出通道数为Ci
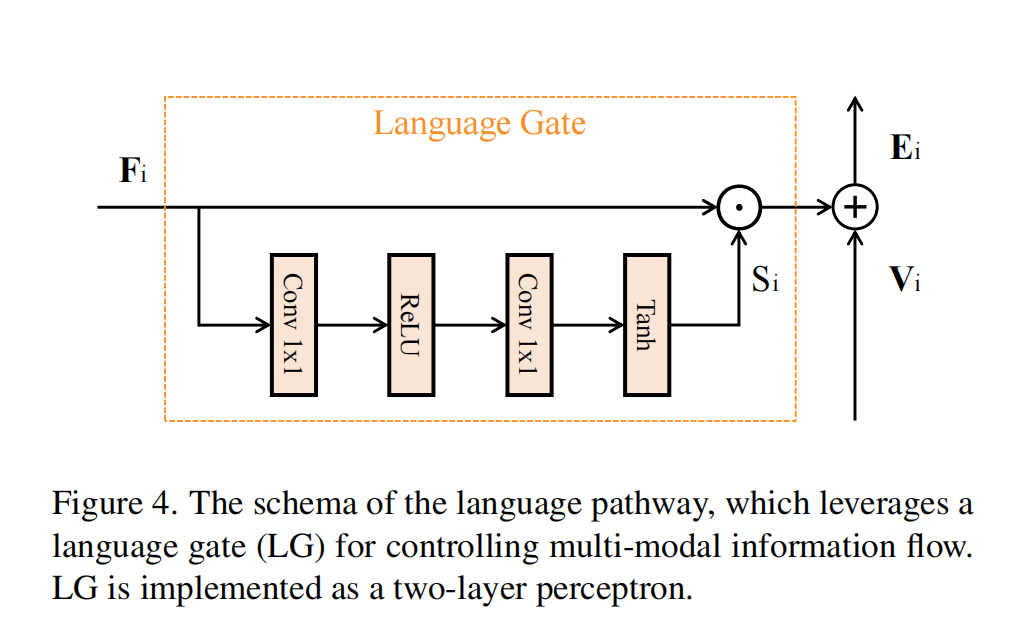
LG模块
(为了防止Fi压倒Vi中的视觉信号,并允许自适应数量的语言信息流向Transformer层的下一阶段,官方源码采用线性层的方式进行处理而非Conv卷积)
最后的求和运算是一种利用预训练视觉的有效方法
用于多模态嵌入的转换层,因为将多模态特征作为“补充”(或“残差”)处理,避免了干扰在纯视觉数据上预训练的初始化权重。
实验观察到采用替换或串联的结果要差得多。
结论:
本文提出了一个用于指称图像分割的语言感知视觉Transformer(LAVT)框架,
该框架利用视觉Transformer的多阶段设计来联合编码多模态输入,
在三个基准上的实验结果已经证明了其相对于当前技术水平的优势
引言:
研究背景:
指称图像分割的关键挑战是利用与给定文本信息相关的视觉特征,
过去被广泛采用的模式是首先从不同的编码器网络中独立提取视觉和语言特征,然后用跨模态解码器将它们融合在一起进行预测
研究问题:
先前的方法中,跨模态交互只发生在特征编码之后,跨模态解码器单独负责对齐视觉和语言特征。
因此,以前的方法不能有效地利用编码器中丰富的Transformer层来挖掘有用的多模态上下文。
解决方案:
提出了一种语言感知视觉Transformer(LAVT)网络,
其中视觉特征与语言特征一起编码,在每个空间位置“意识到”它们的相关语言上下文
这种方法使得可以放弃复杂的跨模态解码器,
因为提取的语言感知视觉特征可以很容易地采用轻量级解码器来获取准确的分割掩码
代码:
视觉骨架部分:SwinTransformer源码
PWAM部分
LG部分

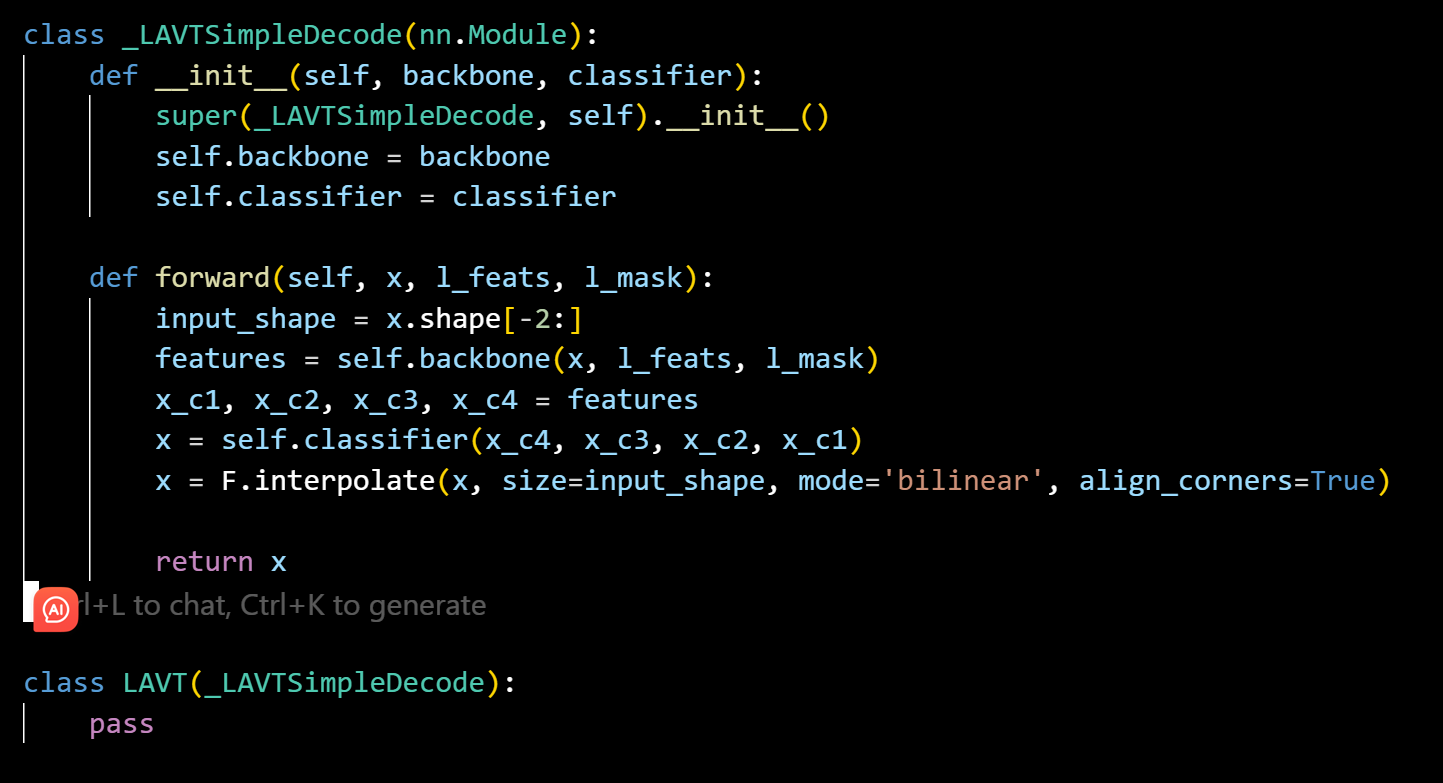
解码器部分
每阶段串联上一阶段输入和对应的PWAM输出,并进行两次卷积操作
class SimpleDecoding(nn.Module):
def __init__(self, c4_dims, factor=2):
super(SimpleDecoding, self).__init__()
hidden_size = c4_dims//factor
c4_size = c4_dims
c3_size = c4_dims//(factor**1)
c2_size = c4_dims//(factor**2)
c1_size = c4_dims//(factor**3)
self.conv1_4 = nn.Conv2d(c4_size+c3_size, hidden_size, 3, padding=1, bias=False)
self.bn1_4 = nn.BatchNorm2d(hidden_size)
self.relu1_4 = nn.ReLU()
self.conv2_4 = nn.Conv2d(hidden_size, hidden_size, 3, padding=1, bias=False)
self.bn2_4 = nn.BatchNorm2d(hidden_size)
self.relu2_4 = nn.ReLU()
self.conv1_3 = nn.Conv2d(hidden_size + c2_size, hidden_size, 3, padding=1, bias=False)
self.bn1_3 = nn.BatchNorm2d(hidden_size)
self.relu1_3 = nn.ReLU()
self.conv2_3 = nn.Conv2d(hidden_size, hidden_size, 3, padding=1, bias=False)
self.bn2_3 = nn.BatchNorm2d(hidden_size)
self.relu2_3 = nn.ReLU()
self.conv1_2 = nn.Conv2d(hidden_size + c1_size, hidden_size, 3, padding=1, bias=False)
self.bn1_2 = nn.BatchNorm2d(hidden_size)
self.relu1_2 = nn.ReLU()
self.conv2_2 = nn.Conv2d(hidden_size, hidden_size, 3, padding=1, bias=False)
self.bn2_2 = nn.BatchNorm2d(hidden_size)
self.relu2_2 = nn.ReLU()
self.conv1_1 = nn.Conv2d(hidden_size, 2, 1)
#传入的参数x_c(4-1)分别表示编码器阶段每阶段PWAM的输出
def forward(self, x_c4, x_c3, x_c2, x_c1):
# fuse Y4 and Y3
if x_c4.size(-2) < x_c3.size(-2) or x_c4.size(-1) < x_c3.size(-1):
x_c4 = F.interpolate(input=x_c4, size=(x_c3.size(-2), x_c3.size(-1)), mode='bilinear', align_corners=True)
x = torch.cat([x_c4, x_c3], dim=1)
x = self.conv1_4(x)
x = self.bn1_4(x)
x = self.relu1_4(x)
x = self.conv2_4(x)
x = self.bn2_4(x)
x = self.relu2_4(x)
# fuse top-down features and Y2 features
if x.size(-2) < x_c2.size(-2) or x.size(-1) < x_c2.size(-1):
x = F.interpolate(input=x, size=(x_c2.size(-2), x_c2.size(-1)), mode='bilinear', align_corners=True)
x = torch.cat([x, x_c2], dim=1)
x = self.conv1_3(x)
x = self.bn1_3(x)
x = self.relu1_3(x)
x = self.conv2_3(x)
x = self.bn2_3(x)
x = self.relu2_3(x)
# fuse top-down features and Y1 features
if x.size(-2) < x_c1.size(-2) or x.size(-1) < x_c1.size(-1):
x = F.interpolate(input=x, size=(x_c1.size(-2), x_c1.size(-1)), mode='bilinear', align_corners=True)
x = torch.cat([x, x_c1], dim=1)
x = self.conv1_2(x)
x = self.bn1_2(x)
x = self.relu1_2(x)
x = self.conv2_2(x)
x = self.bn2_2(x)
x = self.relu2_2(x)
return self.conv1_1(x)
整体模型
backbone表示编码器骨架,classifier表示解码器部分
最终封装到LAVT接口来调用

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)