
ADGaussian:用于自动驾驶的多模态输入泛化GS方法
《ADGaussian:基于多模态输入的自动驾驶通用高斯泼溅方法》提出了一种创新的街道场景重建框架。该研究通过融合单目图像和稀疏LiDAR深度数据,构建多模态联合优化模型,解决了传统方法泛化性差和多模态融合不足的问题。核心创新包括:1)多模态特征匹配机制,利用Siamese编码器和交叉注意力实现深度-图像特征交互;2)深度引导位置嵌入增强3D空间感知;3)多尺度高斯解码器实现几何与外观解耦预测。在
ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs,25年4月来自香港中文大学和浙大。
我们提出了一种新的方法,称为ADGaussian,用于可推广的街道场景重建。所提出的方法能够从单视图输入中实现高质量的渲染。与之前主要关注几何细化的高斯散斑方法不同,我们强调图像和深度特征的联合优化对于精确高斯预测的重要性。为此,我们首先将稀疏LiDAR深度作为额外的输入模态,将高斯预测过程制定为视觉信息和几何线索的联合学习框架。此外,我们提出了一种多模态特征匹配策略,结合多尺度高斯解码模型,以增强多模态特征的联合细化,从而实现高效的多模态高斯学习。在Waymo和KITTI两个大型自动驾驶数据集上进行的大量实验表明,我们的ADGaussian实现了最先进的性能,并在新颖的视图移动中表现出优异的零样本泛化能力。
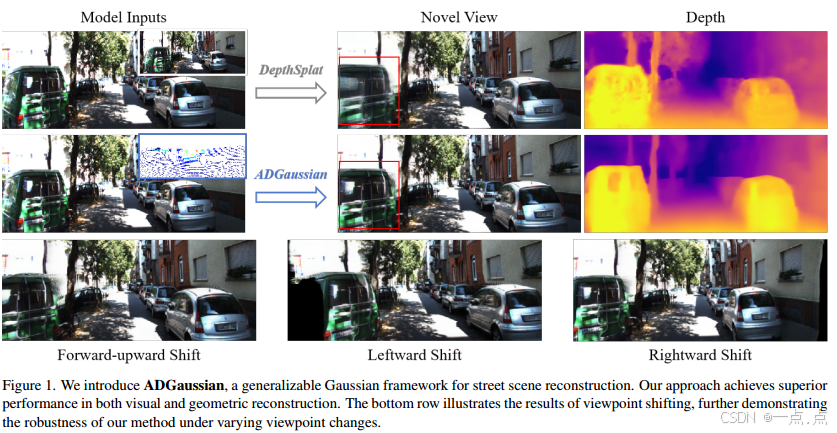
1. 研究背景与核心问题
-
背景:
3D高斯泼溅(3DGS)因实时渲染和高精度重建在自动驾驶场景建模中备受关注,但现有方法存在两大局限:-
泛化性差:传统方法依赖每场景优化(如Street-Gaussians),计算成本高且难以适应新场景。
-
多模态融合不足:现有方法(如DepthSplat)直接拼接图像与深度特征,导致复杂场景重建质量下降(如无纹理区域、动态物体)。
-
-
核心问题:
如何实现单视图输入下的高精度泛化重建,同时有效融合多模态数据(RGB图像+深度)提升几何与外观一致性?
2. 创新方法:ADGaussian框架
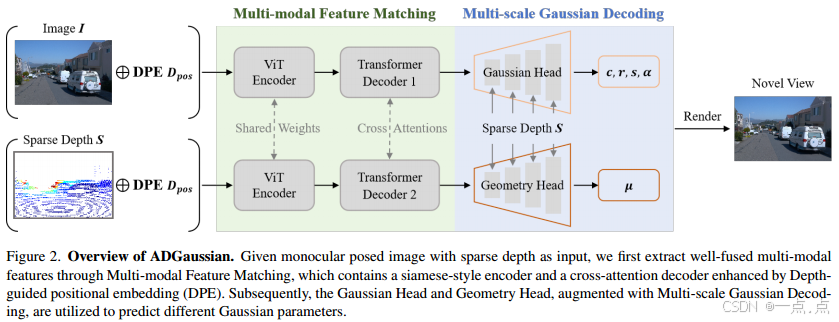
核心思想
提出多模态联合优化框架,通过深度引导的特征匹配与解码机制,实现图像外观特征与深度几何特征的同步优化。
关键技术
-
多模态特征匹配(Multi-modal Feature Matching)
-
输入:单目图像 + 稀疏LiDAR深度图(提供精确尺度先验)。
-
架构:
-
Siamese编码器:权重共享的ViT,分别提取图像特征 FIFI 和深度特征 FSFS。
-
交叉注意力解码器:通过跨模态交互生成融合特征 GIGI 和 GSGS(公式2)。
-
-
深度引导位置嵌入(DPE):
将2D图像坐标与深度值结合,生成3D空间位置编码(xyxy-zz 平面),增强空间感知。
-
-
多尺度高斯解码(Multi-scale Gaussian Decoding)
-
双分支预测头:
-
高斯头(Gaussian Head):预测颜色 cc、透明度 αα。
-
几何头(Geometry Head):预测3D高斯中心 μμ、协方差 ΣΣ。
-
-
多尺度深度融合:
在DPT解码器各尺度层,将下采样的深度图通过卷积层提取特征,与图像特征叠加,提供尺度先验。
-
-
损失函数
-
视图合成损失:MSE + LPIPS(权重 λ=0.05λ=0.05)。
-
深度平滑损失:惩罚相邻像素深度突变(公式5),提升几何连续性。
-
3. 实验验证
数据集与指标
-
数据集:Waymo(静态/动态场景)、KITTI(挑战:图像质量低)。
-
指标:PSNR、SSIM、LPIPS(渲染质量);推理速度与显存(效率)。
主要结果
-
SOTA性能对比
-
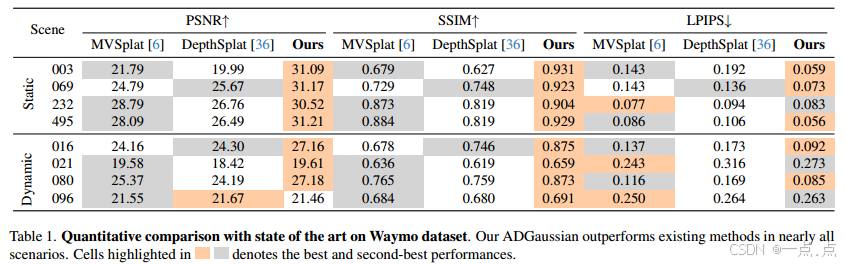
Waymo(表1):
-
静态场景PSNR提升 >4 dB(e.g., 场景003:31.09 vs. 21.79/19.99)。
-
动态场景细节优化显著(e.g., 车辆边缘、信号杆)。
-
-
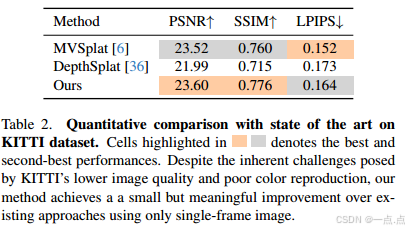
KITTI(表2):PSNR 23.60(优于MVSplat 23.52),证明单帧输入下鲁棒性。
-
关键优势:遮挡区域与细粒度结构重建质量显著提升(图3-4)。
-
-
消融实验(表3)
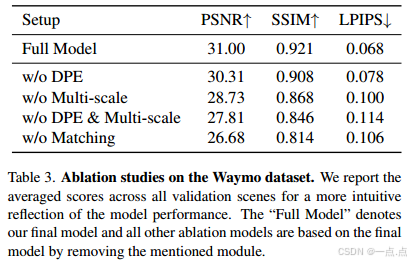
-
DPE模块:移除后PSNR↓0.69,LPIPS↑0.01(深度线索对多模态融合至关重要)。
-
多尺度解码:移除后PSNR↓2.27,几何重建质量大幅下降。
-
多模态匹配:替换为双帧RGB输入后PSNR↓4.32,证明深度-图像联合优化的必要性。
-
-
泛化能力验证
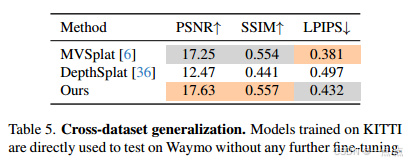
-
跨数据集(表5):KITTI→Waymo零样本泛化,PSNR 17.63(超DepthSplat 12.47)。
-
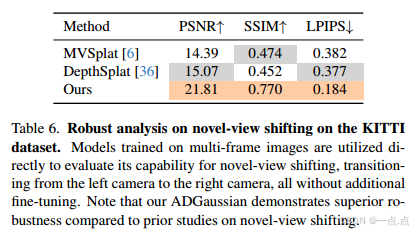
新视角生成(表6):左→右相机切换,PSNR 21.81(超基线>6 dB),接近正常训练性能(23.60)。
-
4. 贡献与局限性
核心贡献
-
首个多模态泛化框架:联合RGB与深度数据建模街景,支持单视图高精度重建。
-
创新模块设计:
-
多模态特征匹配(Siamese编码器 + 交叉注意力)。
-
深度引导位置嵌入(DPE)增强3D空间感知。
-
多尺度高斯解码实现几何-外观解耦预测。
-
-
SOTA性能:Waymo/KITTI实验证明渲染质量、泛化性、新视角生成能力领先。
局限性
-
单帧输入瓶颈:在低质量数据(如KITTI)中细节保留不足。
-
动态场景提升有限:动态物体重建质量弱于静态场景(表1动态场景PSNR增益较低)。
-
依赖传感器:需同步RGB与LiDAR数据(实际部署可能增加硬件成本)。
5. 未来方向
-
多帧信息融合:引入时序帧提升动态场景重建。
-
无监督深度估计:减少对LiDAR的依赖,增强适用性。
-
轻量化部署:优化计算效率以适应车载实时系统。
总结
ADGaussian通过多模态联合优化与深度引导的3D空间编码,解决了自动驾驶场景中单视图重建的泛化性与质量瓶颈,为实时街景建模提供了新范式。其核心价值在于平衡了几何精度与外观真实性,并在零样本泛化与新视角生成中展现强大潜力。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)