
数字人项目介绍:LivePortrait
概述、技术、评测、LivePortrait、EchoMimic、V1、V2、V3、LiveTalking、Streamer-Sales、Duix-Avatar、HeyGem、MuseTalk、Live Avatar、Gaussian-VRM、MagicTryOn、推荐阅读、
概述
一个完整的数字人项目,本质上是构建一个能看、能听、能说、会思考的数字智能体。
核心由两项关键技术构成:TTS与F2F形象生成(Face-to-Face)。前者负责将文本转化为自然语音,后者实现数字人形象的建模与驱动。两者协同工作,使数字人能够在语音与表情上实现一致、逼真的交互表现。
应用场景
- 内容创作:快速生成动画、教育视频等,降低制作成本;
- 在线教育:创建虚拟教师,支持多语言教学,提升趣味性;
- 直播营销:用在虚拟直播、产品推广,降低人力成本;
- 影视特效:生成虚拟角色或特效镜头,简化制作流程;
- 智能客服:创建虚拟客服,提供自然的人机交互体验;
- 数字员工:提供问题咨询、业务办理服务,显著降低人力成本,常用于金融、电信、政务等领域。
未来挑战与趋势:
- 核心挑战:主要包括多模态协同的自然度(避免表情、动作生硬)、高并发下的实时性保障,以及长期交互的个性化与内容合规性。
- 发展趋势:AIGC技术将极大降低数字人制作门槛;大模型让数字人“大脑”更聪明;未来数字人将更深入地融入元宇宙和具身智能等前沿领域。
对TTS感兴趣,请参考合集:
技术
形象生成与驱动模块
- 建模技术:分为高精度的3D建模(使用Blender、Maya等工具)和基于照片快速生成的AI建模(如NeRF技术)。风格上可以是超写实、美型或卡通风格。
- 驱动方式:
- 真人驱动:通过动作捕捉设备,将真人的动作、表情映射到数字人上,常用于直播。
- AI驱动:由AI自动生成动作,是实现智能交互的关键。口型同步(Lip-sync)是核心技术,通常由TTS(语音合成)引擎在生成语音时,同步输出精确到帧的口型驱动参数。
AI大脑模块
- 感知(输入):ASR,将用户语音转为文本;
- 认知与决策(处理):NLP,通常基于LLM,理解用户意图,管理多轮对话,并生成回复文本。更高级的系统会结合情感识别与知识库,让回答更智能;
- 表达(输出):TTS,将回复文本转化为自然、带情感的语音,是交互自然度的关键。
实时渲染与呈现模块
- 实时渲染引擎:如Unity或Unreal Engine,负责根据驱动参数(口型、表情、动作、指令等)实时渲染出最终画面;
- 交互层:通过实时音视频(RTC)技术,将数字人的音视频流低延迟推送给用户,完成面对面互动。
F2F,通过对视频或照片素材的建模,实现数字人视觉形象的构建与动态驱动。
- 视频建模方案:可基于3–5分钟的真人动态视频,通过多帧特征融合与行为学习,精确复刻人物的面部细节、肤色纹理及动作习惯,还原度可达95%以上。适合个人IP数字分身或企业虚拟主播等场景,能大幅减少真人出镜成本,实现内容的规模化生产。
- 照片建模方案:仅需一张人像照片,借助预训练3D模板与AI补全算法,数分钟内即可生成基础数字人模型,并绑定通用动作库(如讲解手势、自然眨眼等)。优势在于轻量、高效、低门槛,适合广告讲解员或短视频虚拟形象等对制作周期敏感的场景。还原度略低于视频建模(约85%),但能显著降低数字人应用的技术与硬件门槛。
评测
对于数字人模型或项目的测评,目前行业内已形成多个维度的权威评估体系。既有官方发布的标准,也有行业领先企业提出的框架。
| 维度类别 | 核心考察方面 | 关键指标示例 | 来源/标准 |
|---|---|---|---|
| 基础技术能力 | 形象、语音、驱动、交互等核心功能的技术水平与效果 | 形象的真实/风格化程度、语音的自然度与表现力、动作的协调性、交互的理解与响应能力 | 团体标准T/BIA17-2024、通信行业标准YD/T4393.1-2023 |
| 工程化与可用性 | 系统是否稳定、易用、易集成,以支持实际业务落地 | 系统的可靠性、可扩展性、兼容性、易用性、可移植性、时效性(响应速度) | T/BIA17-2024 |
| 安全保障与合规 | 内容安全、版权保护、隐私与可控性等风险控制能力 | 内容风险控制、形象版权保障、数据与隐私保护、行为的可追溯与可问责性 | T/BIA17-2024、“求索”EIBench基准 |
| 智能化与泛化能力 | 在复杂、多变环境下的自主任务完成与适应能力 | 任务成功率、平均执行用时、人工干预次数、指令跟随率、跨任务/场景的泛化能力 | “求索”EIBench具身智能测评基准 |
| 战略与生态价值 | 产品的市场定位、商业潜力及产业生态构建能力 | 战略愿景的清晰度、市场认知度、生态合作丰富度、创新规划能力 | 商汤科技等发布的《大模型赋能下的AI2.0数字人平台》白皮书 |
不同的评估体系各有侧重,你可以根据具体项目类型和目标来选择:
- 对于通用数字人平台或系统:应重点关注基础技术能力、工程化与安全性。可依据T/BIA 17-2024或YD/T 4393.1-2023等行业标准,构建覆盖技术、工程、安全的全面测试方案;
- 对于具身智能或机器人项目:核心在于智能化与泛化能力,需要参考求索EIBench这类专用基准。除了任务成功率、效率等常规指标,要特别关注其在多变环境下的泛化能力和安全可靠性;
- 若是选型或行业分析:需要结合产品能力与市场生态。可以参考商汤白皮书提出的产品能力、战略愿景、市场生态三维模型,综合评估厂商的当前实力与未来潜力。
注:上面这些官方的评判标准,好像GitHub开源项目,或Arxiv论文里用的比较少。
其他指标:
- FPS:Frames Per Second,每秒帧数
- TTFF:Time To First Frame,首帧耗时
- Dino-S:身份一致性指标
- ASE:美学评分
- IQA:图像质量
- Sync-C:口型同步
LivePortrait
论文,快手开源(GitHub,17.4K Star,1.8K Fork)。
请参考快手开源模型/项目介绍
EchoMimic
蚂蚁集团开源,目前有3个版本。
V1
论文,开源(GitHub,4.1K Star,449 Fork),HF开源模型,
V2
论文,开源(GitHub,4.4K Star,515 Fork),HF开源模型,
V3
官网,开源(GitHub,626 Star,62 Fork)高效多模态、多任务数字人视频生成框架,1.3B参数,基于任务混合和模态混合范式,结合新颖的训练与推理策略,实现快速、高质量、强泛化的数字人视频生成。
功能
- 多模态输入支持:模型能处理多种模态的输入,包括音频、文本、图像等,实现更丰富和自然的人类动画生成;
- 多任务统一框架:将多种任务整合到一个模型中,如音频驱动的面部动画、文本到动作生成、图像驱动的姿态预测等;
- 高效推理与训练:保持高性能,基于优化的训练策略和推理机制,实现高效的模型训练和快速的动画生成;
- 高质量动画生成:支持生成高质量、自然流畅的数字人动画。框架生成的动画在细节和连贯性上表现出色,能满足各种应用场景的需求;
- 强泛化能力:能适应不同输入条件和任务需求。
原理
- 任务混合范式(Soup-of-Tasks):用多任务掩码输入和反直觉的任务分配策略。在训练过程中同时学习多个任务,实现多任务的增益无需多模型的痛苦。
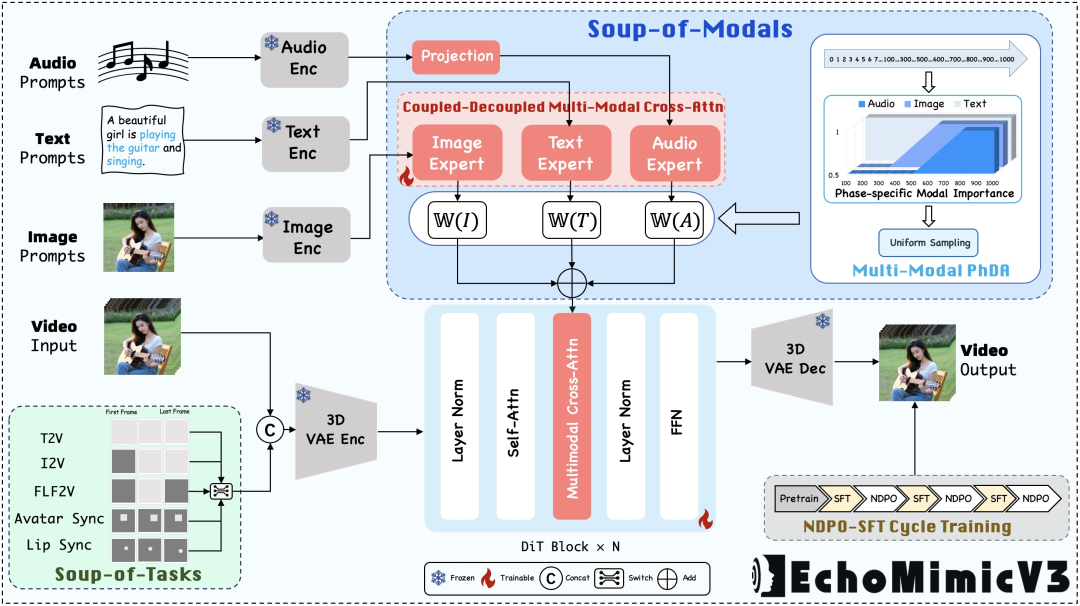
- 模态混合范式(Soup-of-Modals):引入耦合-解耦多模态交叉注意力模块,用在注入多模态条件。结合时间步相位感知多模态分配机制,动态调整多模态混合。
- Transformer架构:基于Transformer架构构建,用强大的序列建模能力处理时间序列数据。自注意力机制使模型能有效地捕捉输入数据中的长距离依赖关系,生成更加自然和连贯的动画。
LiveTalking
开源(GitHub,6.8K Star,1.1K Fork)实时交互流式数字人,实现音视频同步对话。官方文档。
支持:
- 多种数字人模型:ernerf、musetalk、wav2lip、Ultralight-Digital-Human
- 声音克隆
- 数字人说话被打断
- webrtc、虚拟摄像头输出
- 动作编排:不说话时播放自定义视频
- 多并发
Streamer-Sales
开源(GitHub,3.6K Star,545 Fork)卖货主播LLM,一个能根据给定商品特点,从激发用户购买意愿角度出发进行商品解说的卖货主播LLM。集成LMDeploy加速推理、ASR、TTS、RAG、数字人生成等功能。
托管:https://openxlab.org.cn/apps/detail/HinGwenWong/Streamer-Sales
主要功能:主播文案一键生成;KV Cache+Turbomind推理加速,Agent使用网络查询实时快递等信息。
Duix-Avatar
官网,开源(GitHub,11.8K Star,1.9K Fork)数字人模型。
HeyGem
官网,GitHub,硅基智能基于Duix-Avatar的的开源数字人系统,专为Windows系统设计,以低门槛、高效率、高精度为核心优势。仅需1秒视频或1张照片,能在30秒内完成数字人形象和声音克隆,在60秒内合成4K超高清视频。支持多语言输出、多表情动作,具备100%口型匹配能力,在复杂光影或遮挡场景下能保持高度逼真的效果。基于全离线运行模式,保护用户隐私,支持低配置硬件部署,极大地降低使用门槛,为内容创作、直播、教育等场景提供高效、低成本的数字人解决方案。
系统内置Morpheus面部引擎,通过光子流形映射算法与视觉-听觉时序对齐技术,能够从短视频或单张照片快速生成数字人形象,并在唇音同步、表情捕捉等方面保持极高的还原度。即使在侧脸或佩戴眼镜等复杂场景中,仍能实现自然流畅的口型与表情匹配。借助神经辐射场压缩技术,HeyGem在大幅降低显存占用的同时,保证了高质量渲染效果,使主流中高端显卡即可稳定运行。平台支持Docker一键部署与二次开发,全流程无需依赖云端,兼顾数据安全与部署灵活性。
主要功能
- 秒级克隆:仅需1秒视频或1张照片,完成数字人形象和声音的克隆,30秒内完成克隆,60秒内合成4K超高清数字人视频;
- 高效推理:推理速度达到1:0.5,视频渲染合成速度达到1:2;
- 高质量输出:支持4K超高清、32帧/秒的视频输出,超越好莱坞电影24帧的标准;
- 多语言支持:克隆后的数字人支持8种语言输出,满足全球市场需求;
- 无限量克隆:支持无限量克隆数字人形象和声音,无限量合成视频;
- 100%口型匹配:在复杂光影、遮挡或侧面角度下,实现高度逼真的口型匹配;
- 低配可跑:支持Docker一键部署,最低只需NVIDIA 1080Ti显卡即可运行。
技术原理
- 声音克隆技术:基于AI等先进技术,根据给定的声音样本生成与之相似或相同声音的技术,涵盖语音中的语境、语调、语速等;
- 自动语音识别:将人类语音中的词汇内容转换为计算机可读输入,让计算机听懂人们说的话;
- 计算机视觉技术:用在视频合成中的视觉处理,包括面部识别、口型分析等,确保虚拟形象的口型与声音和文字内容相匹配。
docker pull guiji2025/fun-asr:1.0.2
docker pull guiji2025/fish-speech-ziming:1.0.39
docker pull guiji2025/heygem.ai:0.0.7_sdk_slim
安装客户端:运行npm run build:win生成安装程序HeyGem-1.0.0-setup.exe。双击安装程序进行安装。
通过Docker安装的只是HeyGem的服务端,前端需要进入Duix.Avatar GitHub Release页面下载exe文件并安装。
HeyGem还提供Lite版本,没有通过文字生成视频功能,数字人的音频需要单独上传(可使用个人喜欢的TTS模型生成音频后再上传)。
MuseTalk
Live Avatar
项目主页,阿里联合多高校开源(GitHub,965 Star,84 Fork)的能实时生成高质量的数字人视频模型,支持无限长度的视频制作,且在生成过程中画质不下降。
三大核心优势:
- 实时音视频驱动与流式生成:结合麦克风与摄像头,可实现用户与数字人的自然面对面交互。能实时捕捉用户的语音与微动作,驱动数字人进行口型、表情的同步响应,延迟极低,生成速度超越实时流媒体播放。
- 无限时长稳定生成:突破传统方案仅能短时运行的局限,支持长达10,000秒以上的连续、稳定生成。在整个过程中,数字人的面容、肤色、风格等特征均能保持一致,有效杜绝长时生成中常见的面部漂移与色彩失真问题。
- 高保真画质:依托140亿参数的扩散模型,无论是写实肖像还是卡通风格,都能生成细节丰富、清晰自然的画面,在实现高速生成的同时,确保无可妥协的视觉保真度。
Gaussian-VRM
论文,简称GVRM,一款开源(GitHub,374 Star,24 Fork)基于three.js的即时蒙皮高斯化身库,专为Web、移动和VR应用设计。核心是把Gaussian Splats技术与VRM虚拟角色标准结合,让开发者能以极低成本实现高保真、可动画的3D化身。底层依赖three-vrm(VRM格式支持)和gaussian-splats-3d(高斯渲染),完全封装复杂细节,实现开箱即用的开发体验。项目主页。
高斯泼溅:Gaussian Splatting,
核心特性:
- 极致简化的开发流程:3步就能实现化身加载+动画驱动,无需深入理解高斯渲染或蒙皮技术;
- 全平台兼容性:原生支持Web(浏览器直接运行)、移动设备和VR应用,复用
three.js生态的跨平台能力; - 无缝对接VRM生态:直接支持VRM格式化身的所有操作(移动、动画、交互),无需格式转换;
- 无限制性依赖:不使用SMPL模型、深度学习框架或受限许可证的网格优化器,开发无顾虑;
- 高保真视觉效果:基于高斯泼溅技术,呈现远超传统网格模型的细节表现力,兼顾画质与性能。
官方提供6个样本化身+原始扫描数据:通过Google Drive免费下载。
动画文件获取:推荐通过Mixamo下载,选择FBX ASCII格式、60fps、无皮肤、不缩减关键帧,直接适配样本化身。
import * as THREE from 'three';
import { GVRM } from 'gvrm';
// 1. 初始化基础环境(three.js 常规操作)
const renderer = new THREE.WebGLRenderer({ canvas: document.getElementById('canvas') });
const scene = new THREE.Scene();
const camera = new THREE.PerspectiveCamera(65, 640/480, 0.01, 100);
camera.position.set(0, 0.4, 1.5);
// 2. 核心3步:加载化身+设置动画+帧更新
const gvrm = await GVRM.load('./assets/author.gvrm', scene, camera, renderer); // 加载GVRM化身
await gvrm.changeFBX('./assets/Idle.fbx'); // 绑定FBX动画文件
renderer.setAnimationLoop(() => { gvrm.update(); renderer.render(scene, camera); }); // 帧更新
上传图片生成ply文件
处理.ply文件点云到mesh转化的工具
MagicTryOn
视频虚拟试穿(Video Virtual Try-On,VVT)旨在模拟服装在连续视频帧中的自然外观,捕捉其随人体动作变化的动态表现与交互。现有VVT方法在时空一致性和服装内容保留方面仍面临诸多挑战:
- 普遍采用基于U-Net的扩散模型,但该结构表现力有限,难以还原复杂细节。
- 现有方法在空间和时间注意力机制上采取分离建模的方式,这限制对结构关系和跨帧动态一致性的有效捕捉。
- 服装细节的表达仍显不足,影响整体合成结果在人物运动过程中的真实感与稳定性。
为解决上述问题,浙大提出MagicTryOn,一个开源的基于大规模视频扩散Transformer的视频虚拟试穿框架。利用Wan2.1内置的全自注意力机制,实现统一的时空建模。同时设计一种由粗到细的服装保留策略,逐步将服装信息注入去噪网络,从而增强对服装细节的控制能力与生成质量。此外引入一种掩码感知损失(mask-aware loss),引导网络在优化过程中更加关注服装区域。
整体流程:输入包括人物视频、姿态表示、去衣遮罩(Clothing Agnostic Masks)以及目标服装图像。视频和姿态由Wan Video Encoder编码为去衣潜变量(Agnostic Latents)和姿态潜变量(Pose Latents),遮罩则被调整尺寸后编码为遮罩潜变量(Mask Latents)。这些潜变量与随机噪声一起被输入到DiT主干网络中。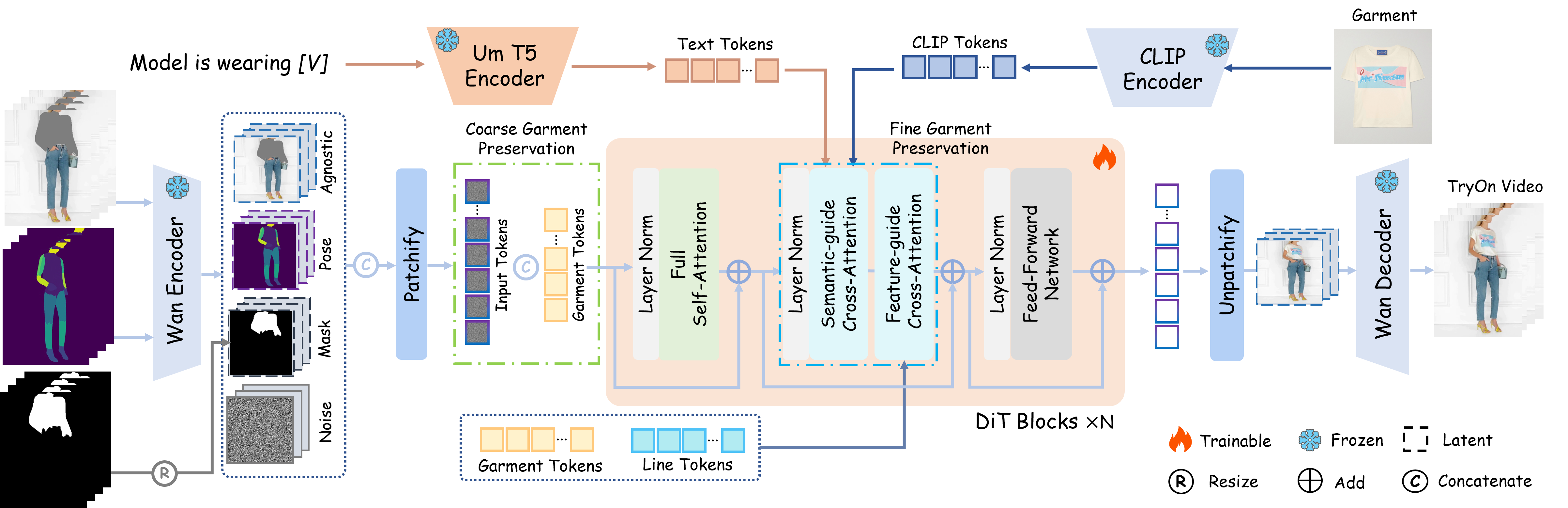
与此同时,服装图像被提取出多层次特征,包括文本、CLIP特征、服装Token和轮廓线Token。其中,服装Token通过序列拼接的方式提供粗粒度引导,所有Token都被注入到DiT各个模块中,用于细粒度条件控制。经过 n n n个去噪步骤后,DiT主干网络生成试穿潜变量(Try-on Latents),再由Wan Video Decoder解码为最终的视频输出。
视频虚拟试穿任务不同于其他视频生成任务,面临独特挑战:在人体姿态和动作动态变化的过程中,既要保持服装图案细节和整体风格的一致性,又要确保视觉效果自然流畅、无感知上的违和感。因此,有效地从服装图像中提取不同类型的信息(如语义特征和结构特征),并在去噪过程中提供合理的引导,是提升生成质量的关键因素。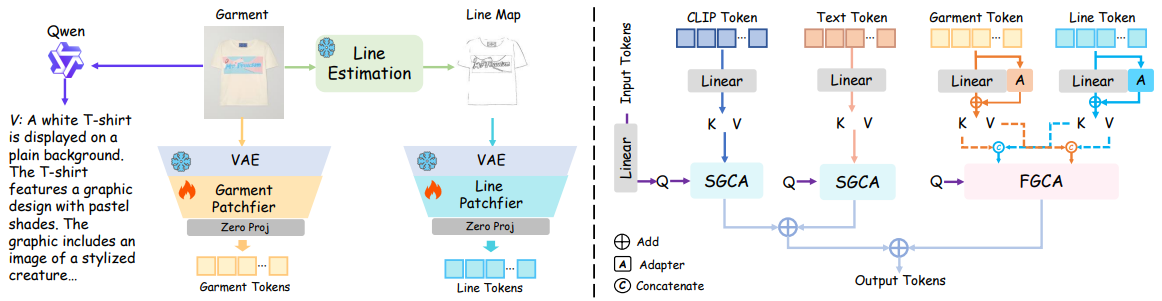
左图:服装细节提取的架构,利用Qwen生成详细的服装描述,同时使用线条估计器提取相应的轮廓线图。右图:细粒度的服装保留策略,包括语义引导交叉注意力(Semantic-Guided Cross-Attention)和特征引导交叉注意力(Feature-Guided Cross-Attention)。
问题:在推理过程中至少需要进行10个去噪步骤,才能生成高质量图像。
推荐阅读

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)