
【技术追踪】CoLa-Diff:用于多模态 MRI 合成的条件潜在扩散模型(MICCAI-2023)
本文介绍了CoLa-Diff,首个基于潜在扩散模型(LDM)的多模态MRI合成方法。该方法旨在解决临床实践中MRI模态缺失的问题,通过在多模态MRI输入中平衡多种条件,有效利用多模态信息。CoLa-Diff在潜在空间中运行,降低了内存消耗,并引入了相似协同滤波和脑区掩模作为先验信息,以保持解剖结构。此外,提出了自动权重适应方法,以优化多模态信息的利用。实验结果表明,CoLa-Diff在MRI合成任
第一个基于 LDM 实现 MRI 的多对一图像转译~
论文:CoLa-Diff: Conditional Latent Diffusion Model for Multi-Modal MRI Synthesis
代码:https://github.com/SeeMeInCrown/CoLa_Diff_MultiModal_MRI_Synthesis
0、摘要
磁共振成像(MRI)合成有望缓解临床实践中缺失 MRI 模态的挑战。扩散模型作为一种通过建模复杂且多变的数据分布来进行图像合成的有效技术,已经崭露头角。(研究意义)
然而,大多数基于扩散模型的 MRI 合成方法仅使用单一模态。由于它们在原始图像域中运行,因此对内存需求较高,不太适合多模态合成。此外,这些方法常常无法在 MRI 中保留解剖结构。而且,平衡多模态 MRI 输入中的多种条件对于多模态合成至关重要。(当前研究挑战)
本文提出了首个基于扩散模型的多模态 MRI 合成模型,即条件潜在扩散模型(Conditioned Latent Diffusion Model,CoLa-Diff)。为了降低内存消耗,设计 CoLa-Diff 在潜在空间中运行。
本文提出了一种新颖的网络架构,例如相似协同滤波(similar cooperative filtering),以解决潜在空间中可能出现的压缩和噪声问题。为了更好地保持解剖结构,引入了脑区掩模作为密度分布的先验信息,以指导扩散过程。并进一步提出了自动权重适应方法,以有效利用多模态信息。
实验表明,CoLa-Diff 优于其他最先进的 MRI 合成方法,有望成为多模态 MRI 合成的有效工具。
1、引言
1.1、研究意义
(1)获取多模态 MRI 是耗时的、昂贵的,而且在某些特定模态下有时是不可行的,例如,由于造影剂的潜在危害;
(2)多模态 MRI 的合成方法(即多对一转译)已经优于单模态模型(即一对一转译);
1.2、当前局限
GAN 网络:
(1)基于 GAN 的模型在建模复杂的多模态数据分布方面受到对抗学习能力有限的挑战;
(2)GAN 的性能在处理和生成变异性较小的数据时可能会受到限制;
(3)GAN 的超参数和正则化项通常需要进行精细调整,否则往往会导致梯度消失和模式坍塌;
DM 网络:
(1)基于 扩散模型(DM)的方法主要集中在一对一的 MRI 转换上;
(2)扩散模型在原始图像域中进行,内存负担高,采样速度慢;
(3)由于噪声的随机性,扩散去噪过程往往会改变目标图像的原始分布结构,使得扩散模型常常忽略了医学图像中嵌入的解剖结构的一致性,从而导致结果在临床上的相关性较低;
1.3、本文贡献
(1)提出了一种基于多模态 MRI 的去噪扩散概率模型,是首个基于 DM 的多对一 MRI 合成模型;
(2)设计了一种量身定制的架构,以促进在潜在空间中的扩散操作,例如相似协同滤波,从而减少潜在空间中过度信息压缩和高维噪声的风险;
(3)在扩散过程的每一步中引入脑区结构指导,保持解剖结构并提高合成质量;
(4)提出了一种方法,用于自动调整条件权重,以平衡多种条件并最大化利用相关多模态信息的可能性;
2、多条件 LDM(Multi-conditioned Latent Diffusion Model)
图1 展示了模型设计。作为一种潜在扩散模型,CoLa-diff 将多条件 b b b 从可用的 MRI 对比中整合到一个紧凑且低维的潜在空间中,以指导缺失模态 x ∈ R H × W × 1 x∈\mathbb R^{H×W×1} x∈RH×W×1 的生成。具体而言, b b b 包括可用对比度以及从可用对比度生成的解剖结构掩模。
Figure 1 | CoLa-Diff 示意图:在前向扩散过程中,原始图像 x 0 x_0 x0 使用编码器 E E E 进行压缩以获得 κ 0 κ_0 κ0,在添加噪声 t t t 步之后,图像变为 κ t κ_t κt;在逆向扩散过程中,潜在空间网络 ϵ θ ( κ t , t , y ) ϵ_θ(κ_t,t,y) ϵθ(κt,t,y) 用于预测所添加的噪声,同时其他可用模态和解剖结构掩模作为结构引导被编码到 y y y 中,随后经过自动权重适应模块 W W W 处理,并嵌入到潜在空间网络中;从网络学习到的分布中抽取样本得到 κ ^ 0 \hat κ_0 κ^0,然后由 D D D 对 κ ^ 0 \hat κ_0 κ^0 进行解码以获得合成图像;
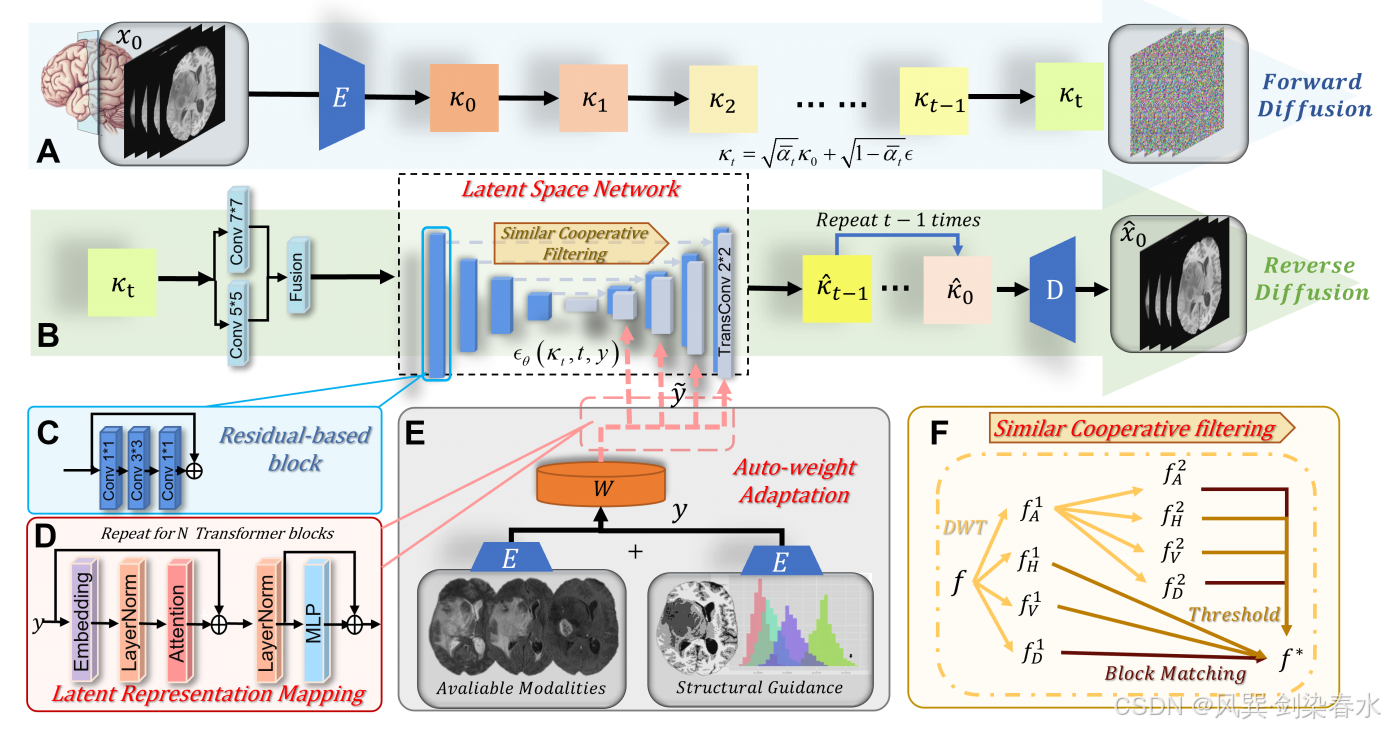
CoLa-Diff 包含一个正向扩散过程和一个逆向扩散过程。
在前向扩散过程中, x 0 x_0 x0 由 E E E 编码生成 κ 0 κ_0 κ0,然后经过 T T T 扩散步骤逐渐添加噪声 ϵ ϵ ϵ 并生成一系列中间表示: { κ 0 , . . . , κ T } {\{κ_0,...,κ_T }\} {κ0,...,κT}。第 t t t 步中间表示记为 κ t κ_t κt,计算为: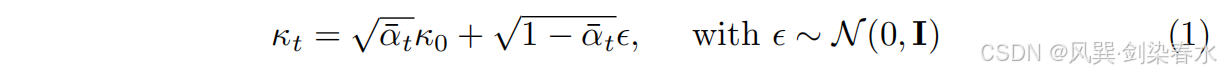
其中 α ˉ t = ∏ i = 1 t α i \bar α_t=\prod_{i=1}^t α_i αˉt=∏i=1tαi, α i α_i αi 表示与方差相关的超参数。
反向扩散通过一个具有参数 θ θ θ 的潜在空间网络建模,该网络以中间扰动特征图 κ t κ_t κt 和 y y y(压缩 b b b )作为输入,预测噪声水平 ϵ θ ( κ t , t , y ) ϵ_θ(κ_t,t,y) ϵθ(κt,t,y),用于从前几步恢复特征图 κ ^ t − 1 \hat κ_{t−1} κ^t−1: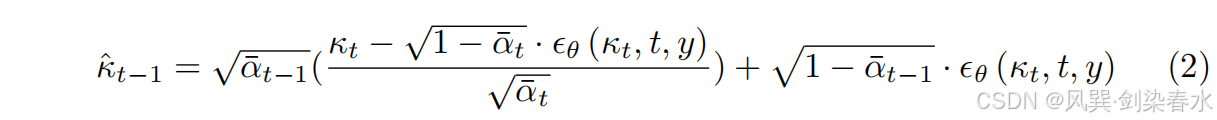
为了有效学习 κ 0 κ_0 κ0 的底层分布,需要准确估计噪声水平。为此,网络采用了相似协同滤波和自适应权重策略。通过重复 等式2 过程 t t t 次来恢复 κ ^ 0 \hat κ_0 κ^0,并解码最终特征图以生成合成图像 x ^ 0 \hat x_0 x^0。
2.1、潜空间网络(Latent Space Network)
本文将多条件映射到潜在空间网络中,以指导每个时间步 t t t 的噪声预测。这种映射是通过 N N N 个变换器模块实现的(见 图1D),其中包括全局自注意力层、层归一化以及逐位置的多层感知机(MLP)。网络 ϵ θ ( κ t , t , y ) ϵ_θ(κ_t,t,y) ϵθ(κt,t,y) 被训练来预测每一步添加的噪声: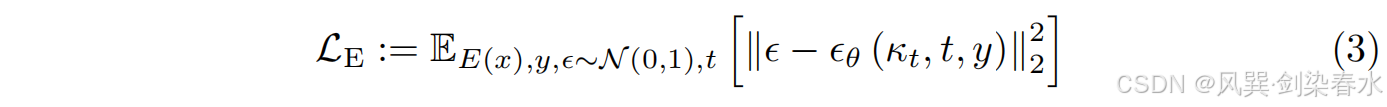
为了缓解潜在空间容易出现的过度信息丢失问题,本文将简单的卷积操作替换为基于残差的模块(三个连续的卷积,卷积核分别为 1×1、3×3、1×1,并带有残差连接),并且在下采样部分通过融合(5×5和7×7卷积后接自适应特征融合模块[AFF])来扩大感受野。
此外,为了减少潜在空间中产生的高维噪声,这些噪声会显著破坏多模态生成的质量,本文设计了一种相似协同滤波方法,具体如下:
相似协同滤波(Similar Cooperative filtering)
设计了该方法来过滤下采样特征,每个过滤的特征连接到其相应的上采样组件(如 图1(F) 所示)。给定 f f f,它是 κ t κ_t κt 的下采样特征,假设二维离散小波变换 ϕ \phi ϕ 将特征分解为低频分量 f A ( i ) f_A^{(i)} fA(i) 和高频分量 f H ( i ) f_H^{(i)} fH(i)、 f V ( i ) f_V^{(i)} fV(i)、 f D ( i ) f_D^{(i)} fD(i),继续分解 f A ( i ) f_A^{(i)} fA(i),其中 i i i 是小波变换层数。
对组件进行分组,并通过相似块匹配 δ δ δ 或阈值 γ γ γ 进一步过滤,使用逆小波变换 ϕ − 1 ( ⋅ ) \phi^{−1}{(·)} ϕ−1(⋅) 重建去噪结果,给定 f ∗ f^∗ f∗。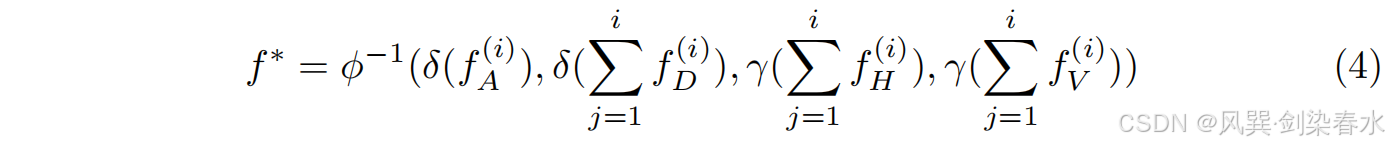
2.2、结构指导(Structural Guidance)
与自然图像不同,医学图像包含丰富的解剖信息,因此,保存解剖结构对于 MRI 生成至关重要。然而,扩散模型常常会破坏解剖结构,这种局限性可能是由于扩散模型的学习和采样过程高度依赖于概率密度函数,而大脑结构在 MRI 密度分布上本质上是重叠的,并且由于病理变化而变得更加复杂。(嘶,值得思考…)
先前的研究表明,引入几何先验可以显著提高医学图像生成的鲁棒性。因此,本文假设引入结构先验可以增强生成质量,同时保留解剖结构。具体而言,利用 FSL-FAST 工具对四种类型的脑组织进行分割:白质、灰质、脑脊液和肿瘤。然后,将生成的组织掩模和固有的密度分布(见 图1(E) )用作条件 y i y_i yi,以指导逆向扩散过程。
多条件下的潜在扩散的组合损失函数定义为: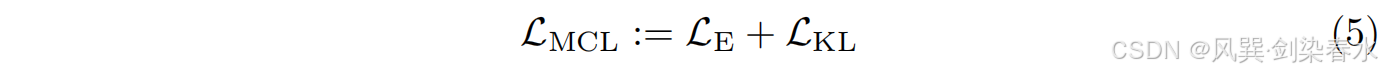
其中 KL 是 KL 散度损失,用于测量编码图像的真实 q q q 和预测 p θ p_θ pθ 分布之间的相似性: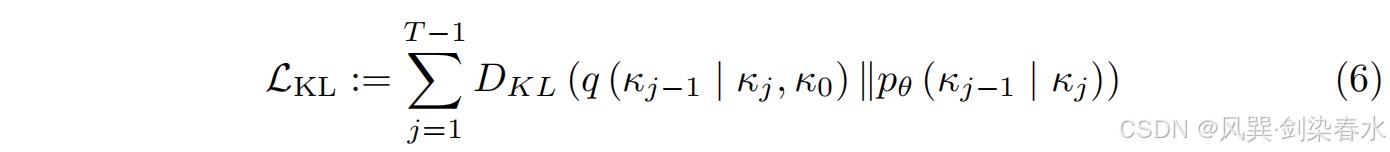
2.3、权重自适应(Auto-weight adaptation)
平衡多种条件至关重要,以最大限度地获取相关信息并尽量减少冗余信息。对于编码条件 y ∈ R h × w × c y∈\mathbb R^{h×w×c} y∈Rh×w×c, c c c 为条件通道数。将自动权重适应后的值设为 y ~ \widetilde y y
,该模块的操作表示为(如 图1(E) 所示):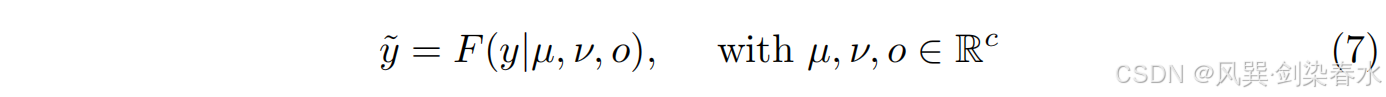
嵌入输出通过嵌入权重 µ µ µ 进行调整。自激活由可学习的权重 ν ν ν 和偏置 o o o 控制。 y c y_c yc 表示 y y y 的每个通道,其中 y c = [ y c m , n ] h × w ∈ R h × w y_c = [y_c^{m,n}]_{h×w}∈R^{h×w} yc=[ycm,n]h×w∈Rh×w, y c m , n y_c^{m,n} ycm,n 是通道 c c c 中位置 ( m , n ) (m,n) (m,n) 处的特征值。
使用大感受野和上下文嵌入来避免局部模糊性,提供嵌入权重 μ = [ μ 1 , μ 2 , . . . , μ c ] \mu=[\mu_1,\mu_2,...,\mu_c] μ=[μ1,μ2,...,μc]。操作 G c G_c Gc 定义为: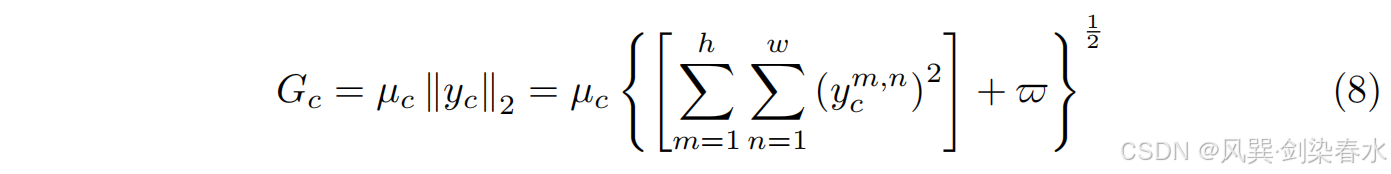
其中 w ˉ \bar w wˉ 是加在方程中的一个很小的常数,以避免在零点处导数的问题。归一化方法可以建立通道之间的稳定竞争, G = { G c } c = 1 S \mathbf G = \{G_c\}^S_{c=1} G={Gc}c=1S,使用 L2 归一化进行跨通道操作:
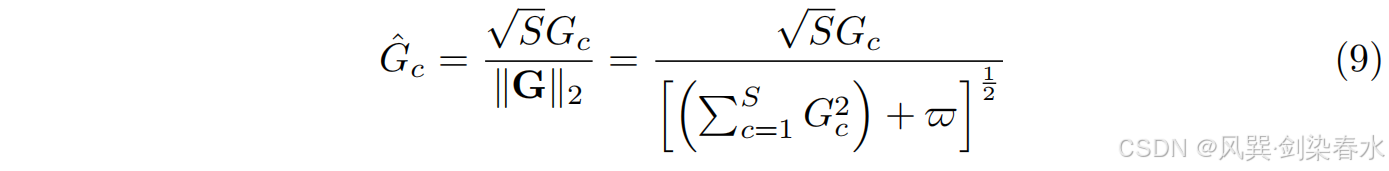
其中 S S S 表示尺度,采用激活机制来更新每个通道,以促进扩散模型训练过程中每种条件的最大利用,并进一步提高合成性能。给定可学习权重 ν = [ ν 1 , ν 2 , . . . , ν c ] ν = [ν_1,ν_2,...,ν_c] ν=[ν1,ν2,...,νc] 和偏置 o = [ o 1 , o 2 , . . . , o c ] o = [o_1,o_2,...,o_c] o=[o1,o2,...,oc] ,计算如下: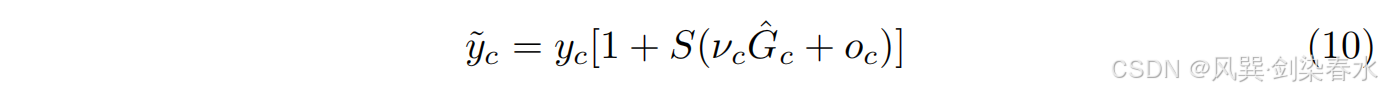
给出了自动加权后每个压缩条件的新表示 y ~ c \widetilde y_c y
c, S ( ⋅ ) S(·) S(⋅) 表示 Sigmoid 激活函数。
3、实验与结果
3.1、数据集与基线
(1)BRATS 2018 数据集:285名胶质瘤患者,四种模态:T1、T2、T1ce 和 FLAIR,190:40:55 划分训练、验证和测试,选择轴向横截面,将选定的切片裁剪为 224×224 的大小;
(2)IXI 数据集:200个健康大脑,140:25:35 划分训练、验证和测试,使用 FSL-FLIRT 将 T2 和 PD 加权图像配准到 T1 加权图像,其他预处理与 BRATS 2018 相同;
(3)对比的多模态 MRI 合成方法:MM-GAN、Hi-Net、ProvoGan 和 LDM;
3.2、实施细节
(1)扩散步骤设为1000;
(2)噪声调度设为线性;
(3)注意力分辨率设为32、16、8;
(4)batch size 为 8;
(6)学习率设为 9.6e−5;
(7)噪声方差范围为 β 1 = 1 0 − 4 β_1=10^{−4} β1=10−4 和 β T = 0.02 β_T = 0.02 βT=0.02;
(8)采用指数移动平均(EMA)对模型参数进行平滑处理,参数更新速率为 0.9999;
(9)2 张 NVIDIA RTX A5000 24 GB 训练;
(10)PyTorch 框架,Adam 优化器;
(11)应用基于知识蒸馏的加速方法进行快速采样;
3.3、定量结果
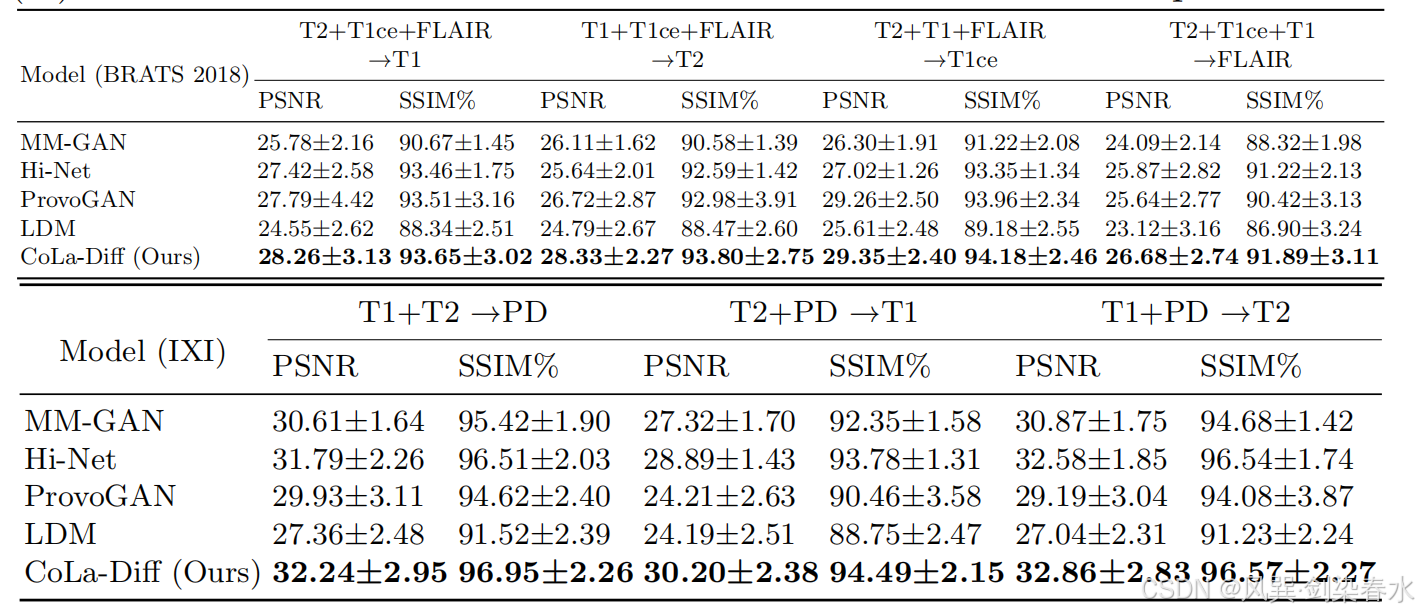
Table 1 | 在 BRATS(上)和 IXI(下)中的表现:测试集中的 PSNR(dB)和 SSIM(%)以均值 ± 标准差表示,加粗标记为最佳模型;
3.4、定性结果
Figure 2 | 合成图像的可视化、细节放大(第1行和第3行)和相应的误差图(第2行和第4行):
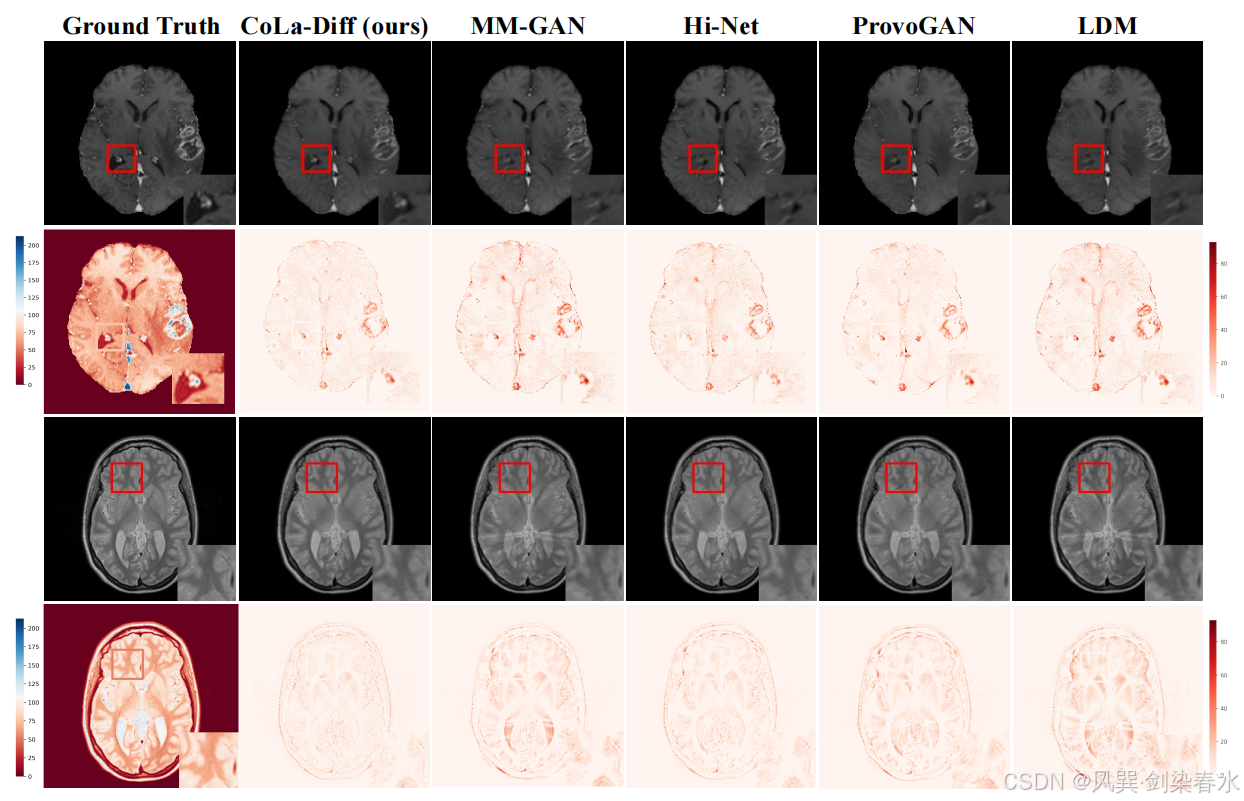
3.5、消融研究和多模态利用能力
Table 2 | 消融四个单独组件(前四行)和多模态信息利用(后三行):粗体标记表示每个数据集上表现最好的场景;
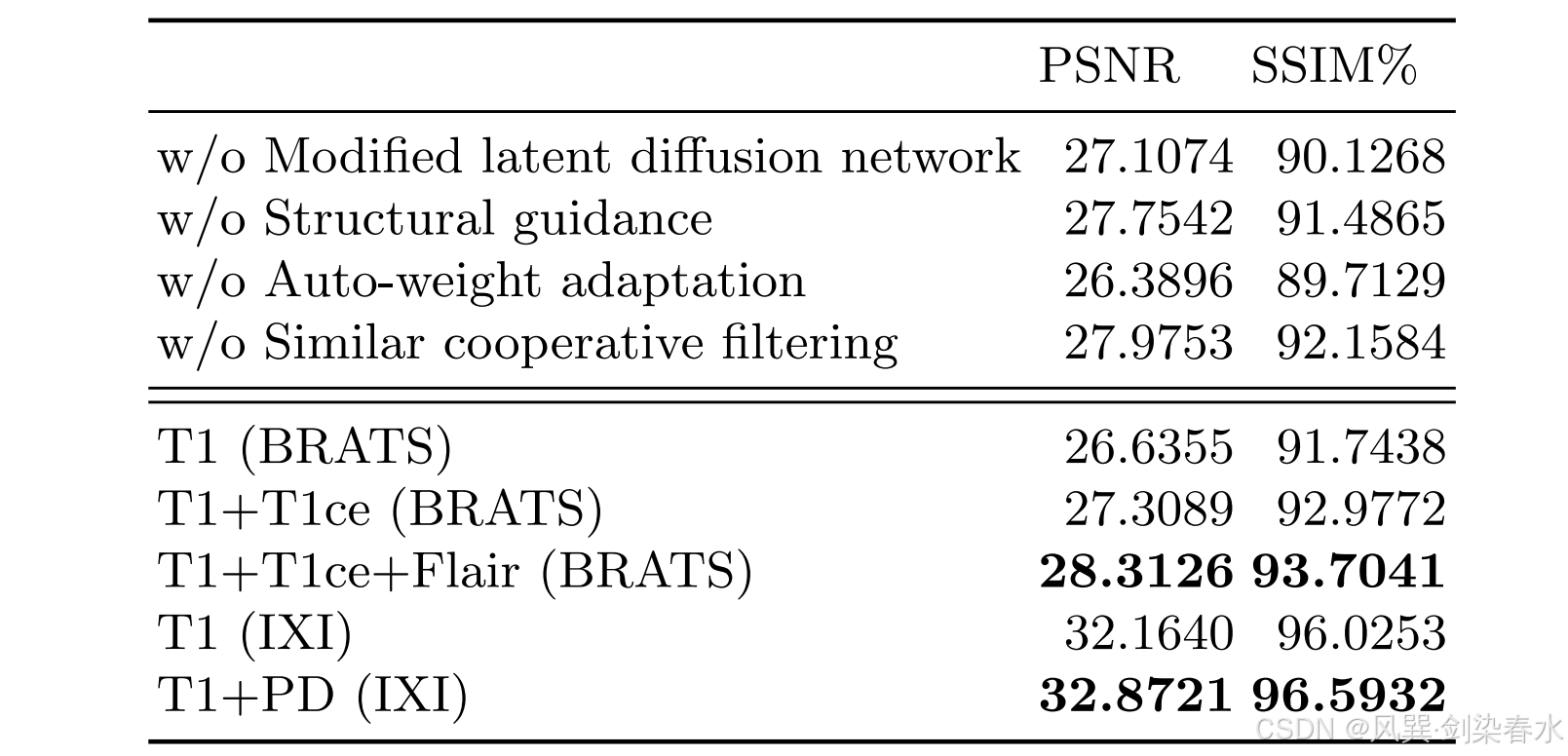
有没有好心人可以告诉我,SSIM 真的可以这么高么(⊙o⊙)

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)