
多模态大语言模型的空间推理:任务、基准与方法综述
本文从认知视角构建空间推理任务分类体系,梳理文本、视觉 - 语言、具身场景下的基准数据集与评估指标,分析训练式、推理式两类提升空间推理能力的方法,揭示当前模型与人类空间智能的核心差距。
摘要:本文从认知视角构建空间推理任务分类体系,梳理文本、视觉 - 语言、具身场景下的基准数据集与评估指标,分析训练式、推理式两类提升空间推理能力的方法,揭示当前模型与人类空间智能的核心差距。
一、引言
大语言模型的发展是人工智能领域的重要里程碑,展现出前所未有的自然语言理解、推理与生成能力。这类基于 Transformer 架构的模型通过大规模文本语料预训练,能完成翻译、摘要、复杂推理等各类语言类任务,还具备少样本学习能力,成为现代人工智能研究的核心基石。
在语言智能的基础上,研究者进一步探索视觉感知与理解能力,视觉 - 语言模型(VLMs)通过将视觉编码器与预训练大语言模型结合,试图打通感知与语言的壁垒。但人类智能中至关重要的空间智能—— 即感知、理解并推理三维世界中物体空间关系的能力,仍是这类模型的核心短板。
语言智能与空间智能的差距体现在任务类型和底层表征两个层面:大语言模型擅长处理文本、代码等离散序列数据,而空间智能需要在连续的三维环境中完成推理,支撑机器人导航、物体操纵等能力。这种差距的本质是表征失配:物理世界是连续的几何结构,而大语言模型将信息编码为离散的序列化令牌,仅能从文本 / 图像数据中学习空间概念的统计共现规律,而非真正的几何原理(比如仅知道 “立方体在圆形左侧” 的文本关联,却无法理解其几何关系)。
从认知科学和神经机制来看,人类通过心理模型处理空间信息,能在脑海中模拟旋转、平移、视角变换等空间变换;而语言将连续的空间关系压缩为离散的类别令牌(如 “左侧”“上方”),仅能描述定性的空间关系。神经层面,海马 - 内嗅皮层回路通过 “位置细胞”“网格细胞” 编码空间环境的度量结构,形成连续的内部坐标系;而大脑皮层中语言的表征则是离散的序列形式,适配语言组合与令牌预测,而非度量空间计算。
这种模拟空间编码与离散语言编码的失配,本质是 “表征层面的符号接地问题”。大语言模型缺乏对空间的内部映射,无法像人类一样在脑海中建模或调整空间关系;即便视觉 - 语言模型依托视觉感知,也局限于二维或投影表征,缺乏深度的三维空间心理建模能力。
提升多模态大语言模型的空间智能,是使其向 “理解并交互真实世界” 的通用世界模型演进的关键。当前模型在语言类任务上表现优异,但空间理解的短板严重限制了其在机器人、自动驾驶、AR/VR、导航等具身场景的落地 —— 这些场景均需连贯的空间推理能力与物理世界的持续交互。
现有相关综述多基于输入模态(如文本、图像、3D 数据)或模型在 3D 任务中的角色分类,而由匹兹堡大学团队研究的《Spatial Reasoning in Multimodal Large Language Models: A Survey of Tasks, Benchmarks and Methods》:跳出模态 / 任务导向的分类框架,从认知过程视角构建分类体系:分析空间任务的核心认知维度(参考系、信息类型、任务性质)与推理复杂度层级,系统梳理文本、视觉 - 语言、3D 场景下的基准,总结训练式、推理式两类提升空间能力的方法,为研究者提供全面的领域认知与可行的研究方向。
二、背景知识与研究动机
2.1 基于 Transformer 的现代模型
Transformer 的核心创新是注意力机制,能并行处理所有输入令牌,自适应分配上下文相关性,结合位置编码保留序列信息,为多模态大语言模型提供了高效建模复杂依赖关系的基础。
2.1.1 大语言模型
大语言模型基于 Transformer 架构实现参数规模的极致扩展,通过海量文本 / 代码语料预训练,以 “预测下一个令牌” 为目标,涌现出少样本 / 零样本学习、思维链推理等能力。但受限于纯文本训练,大语言模型仅能将空间概念学习为文字的统计模式,缺乏接地的几何表征,仅能处理 “在… 之上” 等简单类别关系,无法保证度量精度和物理一致性。
2.1.2 视觉 - 语言模型
视觉 - 语言模型将视觉编码器(如 Vision Transformer)与大语言模型结合,通过对齐模块和跨注意力机制构建视觉 - 语言的共享表征空间,实现多模态对话、指令跟随等能力。这类模型能将空间语言(如 “绿色立方体左侧的蓝色球体”)锚定到图像的像素空间,处理二维的相对位置、对齐等关系,但仍局限于二维投影平面,难以从单张图像推断深度、体积、遮挡物体的三维关系。
2.2 认知功能维度
为系统分析大模型的空间能力,需基于认知科学原理,将空间能力拆解为三个核心正交维度(见图 4):
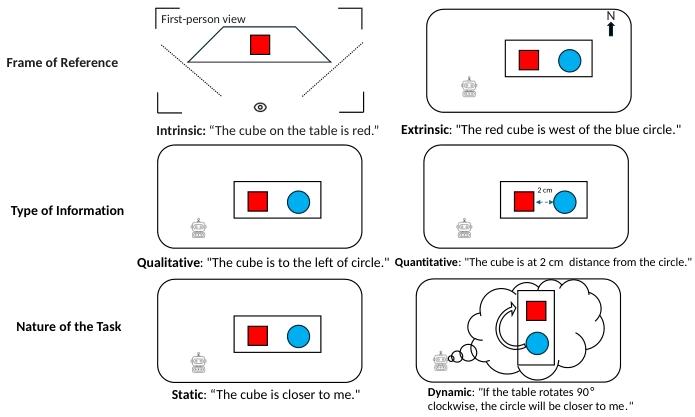
图 4 认知维度示意图:空间推理可拆解为三个维度 —— 参考系(内在 / 外在)、信息类型(定性 / 定量)、任务性质(静态 / 动态),每个维度反映人类与模型编码、比较、变换空间关系的不同方式。
1)内在参考系 vs 外在参考系:参考系是定义物体位置、朝向、关系的坐标系。内在参考系基于物体自身属性 / 朝向描述(聚焦物体本身),外在参考系则基于场景中其他物体或场景属性描述。
2)定性信息 vs 定量信息:空间关系的描述精度分为定性抽象和定量测量。定量推理处理连续、精准的空间数据;定性推理将世界简化为拓扑(在… 内、在… 下)、相对位置(在… 左侧、在… 之间)、朝向(平行于、朝向)等离散类别,是人类描述空间的主要方式。
3)静态推理 vs 动态推理:静态推理聚焦固定场景的空间关系描述与理解,是空间认知的基础;动态推理则需在脑海中模拟空间关系的变化,是规划、问题求解、反事实思考的核心,也是 AI 模型从 “被动描述” 迈向 “主动预测” 的关键。
2.3 从感知到推理的层级
人类空间智能遵循 “感知 - 理解 - 推理” 的渐进层级:
-
空间感知:底层过程,负责获取并组织环境中的原始感官数据;
-
空间理解:将离散的感官印象整合为连贯的环境内部表征(如心理地图),捕捉物体间的关系结构;
-
空间推理:主动操纵内部空间表征,想象变换、预测结果、解决问题,需模拟物体的运动、旋转或视角变化。
大模型要实现从感知到高阶推理的跨越,需完成类似的转变:从提取显性空间线索,到构建稳定的内部表征,最终基于表征实现灵活、可预测、符合物理规律的空间理解。
2.4 多模态大语言模型空间推理的核心挑战
尽管视觉 - 语言模型整合了视觉感知,但当前架构仍难以实现稳健的空间智能,核心挑战包括:
1)视觉编码器的投影瓶颈:视觉 - 语言模型的二维编码器优先优化语义与语言的对齐,而非三维几何的保真度;视觉令牌投影为扁平序列后,深度、朝向、度量连续性等三维信息被弱化,导致模型能识别物体却无法推理精细的空间结构。
2)学习统计关联而非物理约束:预训练目标使模型倾向于利用语义共现(如 “杯子在桌子上”),而非遵循几何 / 物理规律,导致模型通过模式补全回答空间问题,而非验证场景一致性;在度量 / 反事实问题上性能骤降,注意力也更关注显著语义而非几何区域。
3)参考系模糊与不稳定性:空间信息具有视角相对性(自我中心 / 世界中心),但模型缺乏显式的参考系管理机制,仅依赖注意力处理混合令牌,导致视角变化时参考系漂移,多视角定位、视角转换任务中易出现左右 / 前后颠倒,且缺乏场景记忆,不同视角下对同一场景的回答易矛盾。
三、空间推理任务的分类体系
本文提出 “认知维度 + 推理复杂度” 的双轴分类体系,突破仅基于输入模态的分类局限,实现任务的精细化分析。
3.1 基于认知维度的任务分类
结合 “参考系 - 信息类型 - 任务性质” 三维度,筛选出五类核心空间认知任务(排除无意义或重复类别):
1)内在 - 定性 - 静态:推理单一静止物体的内部结构 / 属性,参考系为物体自身,例如 “椅子的靠背在座位上方”。
2)外在 - 定性 - 静态:最常见的空间推理类型,用定性关系描述静态场景中物体的排布,参考系为外部场景 / 其他物体,例如 “桌子和台灯的位置关系是什么?”。
3)定量 - 静态:聚焦度量推理,涵盖单一物体的内在属性、多物体间的外在关系的精准量化,例如 “这张桌子的高度是多少米?”。
4)内在 - 定性 - 动态:基于物体结构模拟其部件的变换,需在脑海中操纵物体构型,例如 “折叠立方体后,某一面的位置如何变化?”。
5)外在 - 定性 - 动态:模拟物体与环境 / 其他物体的关系变换,需推理视角 / 位置变化后的场景,例如 “坐在沙发上时,我右侧的物体是什么?”。
该分类体系能区分同一模态下不同的认知挑战(如同为图像问答,可能是静态描述或动态心理变换),精准诊断模型的能力短板。
3.2 推理复杂度层级
从认知过程的复杂度出发,将任务分为四级:
1)Level 1:直接感知:检索并描述输入中的显性信息,无需推理,仅测试核心感知能力(如物体识别、场景感知)。
2)Level 2:单步推理:超越直接感知,推导两个及以上物体的基础空间关系(物体可直接感知,但关系需推断)。
3)Level 3:多步链式推理:需拆解为多个推理步骤,前一步结论作为后一步前提,类似空间版 “思维链”,需维持连续的心理状态。
4)Level 4:高阶合成推理:整合多种推理类型(如空间推理 + 常识推理),需处理复杂的动态变换,测试模型的泛化能力,例如 “从右侧推动积木堆,积木会按什么顺序掉落?”。
该层级划分能衡量任务的 “认知深度”,精准定位模型的缺陷(如擅长单步推理但无法完成多步链式推理)。
3.3 分类体系示例
图 5 展示了不同空间任务在 “认知类别(横轴)- 推理复杂度(纵轴)” 二维网格中的分布:
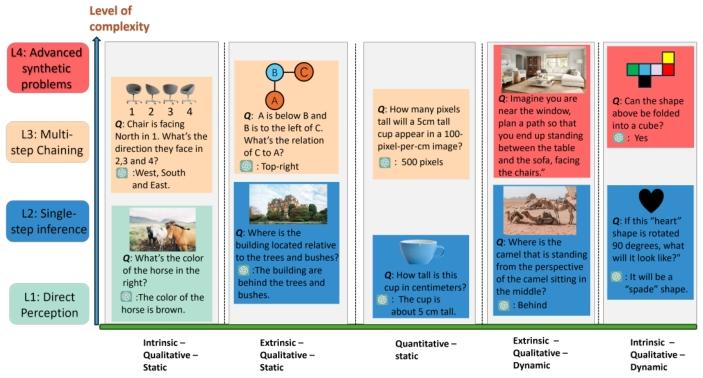
图 5 认知分类与复杂度层级的示例映射:横轴为五类核心认知任务,纵轴为四级推理复杂度,清晰展现任务难度与认知类型的关联,例如外在 - 定性 - 静态类任务中,Level 3 需整合 “A 在 B 下方”“B 在 C 左侧” 推导 “A 与 C 的关系”。
该示例揭示:同一认知类别下,复杂度层级越高,任务难度越大;同一复杂度层级下,不同认知类别测试的核心能力不同(如 Level 2 中,外在 - 定性 - 动态需考虑物体间关系变换,而内在 - 定性 - 动态需操纵单一物体构型)。
四、数据集、基准与评估指标
4.1 基准的核心作用
空间推理的评估依赖数据集与基准体系:数据集是标注化的视觉 / 3D 数据,提供物理世界的真值;基准定义具体的任务挑战与评估协议,测试模型空间知识的有效性、一致性与几何接地性,是衡量领域进展的核心工具。
4.2 空间推理数据集与基准的现状
现有基准的分布呈现显著的倾向性,反映出领域研究的重点与短板:
4.2.1 关系推理类问题占主导
多数基准聚焦 “外在 - 定性 - 静态” 类别(关系推理),例如自动生成视觉场景的文本描述与空间问答对、研究视觉问答中关系推理的影响因素、基于点云扩展多物体定位数据集等。这类任务契合当前模型的优势(语言表达定性关系、视觉锚定文本),是空间智能的基础,但难以反映真正的几何理解。
4.2.2 定量任务分布失衡
定量 - 静态类任务看似覆盖广泛,但多局限于 “物体计数”(Level 1 直接感知),缺乏测试距离、尺寸、角度、体积等真正度量推理的基准;少数聚焦度量推理的基准(如 Q-Spatial Bench)也仅处于初步探索阶段,暴露了离散令牌模型与连续空间的核心失配问题。
4.2.3 动态推理的研究前沿
动态推理(内在 / 外在 - 定性 - 动态)是空间智能的高阶挑战,相关基准分为两类:一是内在动态推理(如立方体折叠),测试物体构型变换的模拟能力;二是外在动态推理(如视角变换问答、导航),测试场景视角 / 位置变换的推理能力。这类基准能更精准衡量模型的通用空间智能。
4.2.4 数据类型趋势(合成 / 真实世界)
合成数据集(如 Open3DVQA)具备无噪声真值、可编程控制的优势,能精准隔离特定推理能力,但易引入合成过程的隐性模式,导致模型过拟合;真实世界数据集更贴合落地场景,但存在噪声、标注成本高的问题。两类数据需互补使用,而非单一依赖。
4.3 评估指标
空间推理任务的多模态特性,要求多样化的评估指标,核心分为四类:
4.3.1 事实与分类任务指标
针对单真值的问答 / 分类任务,常用准确率(Accuracy)、F1 分数,能直接衡量离散预测的正确性,但无法评估推理过程的有效性,也无法奖励 “部分正确但空间合理” 的答案。
4.3.2 语言生成任务指标
字幕生成、对话、推理生成类任务常用 BLEU、ROUGE、CIDEr,通过 n-gram 重叠度衡量与参考文本的相似度,但难以反映空间关系的语义正确性(如 “椅子在桌子左侧且红色” 与 “椅子在桌子左侧且绿色” 的 n-gram 重叠度高,但语义关键属性错误)。
近年兴起的大模型作为评判者(LLM-as-Judge) 能更精准评估语义一致性,例如识别 “台灯在沙发后方” 与 “沙发在台灯前方” 的等价性,弥补传统指标的短板。
4.3.3 空间定位与几何任务指标
针对定位任务,用交并比(IoU)衡量预测区域与真值的重叠度;导航任务用成功率(SR)、路径长度加权成功率(SPL)衡量轨迹规划的正确性与效率;3D 生成 / 重建任务用倒角距离(CD)、推土机距离(EMD)衡量几何形状的相似度,这类指标直接编码空间保真度,而非语言相似度。
4.3.4 人类评估
对于复杂的开放任务(如场景推理、组合生成),自动指标难以覆盖所有维度,人类在环评估是金标准,能评估输出的合理性、创造性与常识符合度,但成本高、可扩展性差。
五、提升空间推理能力的方法
提升大模型空间推理能力的方法分为两类:训练式方法(修改模型参数,嵌入空间先验)、推理式方法(推理阶段引导,不修改参数)。
5.1 训练式方法
通过架构创新、数据增强、强化学习等方式,将空间知识直接嵌入模型参数(见图 6):
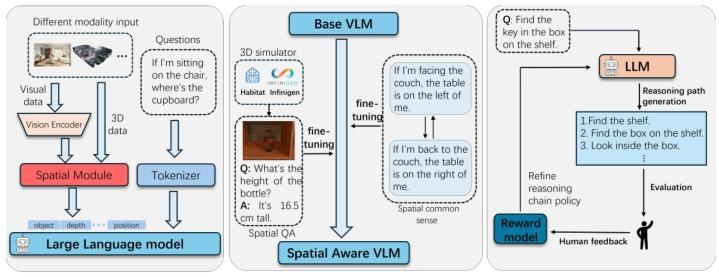
图 6 训练式方法概述:左:引入 3D 编码器等空间感知模块,对齐感知与语言表征;中:利用合成环境生成可控数据,微调空间推理任务;右:强化学习优化多步推理链,提升空间决策精度。
5.1.1 空间感知模块训练
改造 Transformer 架构,嵌入显式的几何信息:例如为 2D 视觉令牌添加 3D 位置嵌入(深度、相机参数),让令牌携带空间坐标;构建点云 - 语言的对齐模块,通过参数高效微调(PEFT)加速 3D 感知与语言的融合。这类方法能提升 3D 定位、空间问答的效率,但会增加架构复杂度与计算开销。
5.1.2 面向特定任务的合成数据微调
利用合成数据解决真实 3D 数据稀缺的问题:例如自动生成大规模空间问答对,覆盖定性 / 定量 3D 关系;基于 ProcTHOR 等引擎生成场景级问答数据,提升模型的动态空间能力。需注意避免合成数据的过拟合问题,例如混合不同合成流程的数据集。
5.1.3 强化学习优化推理过程
将多步空间推理视为序列决策问题,用强化学习优化推理链:先通过有监督微调(SFT)让模型熟悉推理步骤,再用分组相对策略优化(GRPO)等算法,结合任务专属奖励(如格式正确性、任务准确率、长度正则化)优化推理路径。该方法能提升复杂任务的灵活性,但存在训练不稳定、奖励设计难的问题。
5.2 推理式方法
推理阶段通过外部引导提升空间推理能力,无需修改模型参数(见图 7):
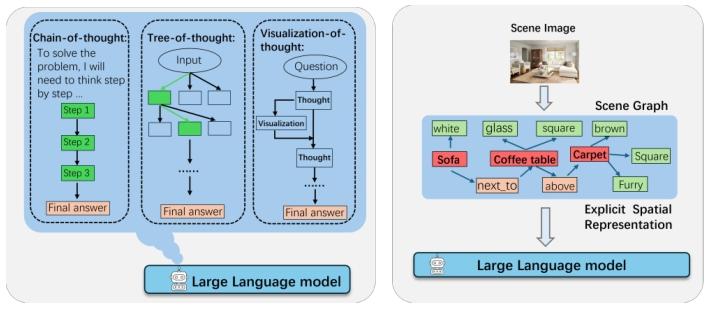
图 7 推理式方法概述:左:结构化提示引导模型分步推理,通过文本 / 可视化思维链提升可解释性;右:场景图等显式空间表征,将语言推理锚定到几何关系,提升准确性。
5.2.1 思维链提示及其变体
核心是通过结构化提示,让模型将复杂问题拆解为多步简单推理:
-
基础思维链(CoT):引导模型输出空间推理的中间步骤,模拟人类解题过程;
-
可视化思维链(VoT):让模型生成 ASCII 艺术 / 符号可视化的中间步骤,适配导航、物体操纵等空间任务;
-
多模态可视化思维链(MVoT):结合语言与动态视觉思维,提升动态空间推理的鲁棒性。
这类方法的短板是依赖基础模型的能力,且易出现错误传播(单步错误导致最终答案错误),部分场景下甚至会降低性能。
5.2.2 显式空间表征
构建场景图、认知地图、网格布局等显式空间表征,将抽象语言锚定到具体空间结构:例如用场景图(物体为节点,空间关系为边)表示环境,支撑零样本导航;用笛卡尔网格线覆盖俯视图,提供几何参考。这类方法能降低推理歧义,但需额外的检测 / 解析模块,引入流水线误差,且场景图易存在信息不全 / 冗余的问题。
六、开放挑战与未来方向
6.1 核心挑战
6.1.1 数据集与基准的缺陷
高质量 3D 数据集稀缺(相较于文本 / 2D 视觉的海量语料),且标注成本高;基准过度聚焦 “外在 - 定性 - 静态” 任务,定量推理、动态推理的覆盖不足,导致对模型空间能力的评估片面。
6.1.2 空间理解的不完整性
模型的空间理解依赖统计模式匹配,而非真正的几何理解;且难以跨参考系泛化(如基于物体中心训练的模型,无法完成环境中心的变换),缺乏统一的世界模型。
6.1.3 架构与训练范式的局限
模型预训练以文本为主,空间接地仅为浅层微调,导致空间知识附属于语言先验;Transformer 的离散序列架构与连续空间本质失配,且缺乏持久的空间记忆,无法整合多视角 / 时序的空间信息。
6.2 未来研究方向
6.2.1 构建高质量数据集与基准
-
扩充大规模、多模态、富空间标注的数据集(含 3D 坐标、物理属性、功能关系);
-
设计聚焦度量推理、动态变换的基准,对齐人类空间认知的发展里程碑;
-
标准化因子分析,量化场景复杂度、视角数等因素对模型性能的影响。
6.2.2 研发空间感知训练策略
-
打破文本主导的预训练范式,开展语言 - 视觉 - 3D 几何的联合预训练,构建统一的世界模型;
-
设计跨模态对比目标,让模型将文本概念直接映射到 3D 几何构型,而非统计关联。
6.2.3 探索空间智能导向的新型架构
-
探索扩散模型等适配连续空间的架构,建模合理的空间排布与变换分布;
-
引入显式的空间记忆模块(如动态场景图、拓扑地图),让模型整合多视角 / 时序的空间信息,结合大模型的高阶推理能力,实现 “语言推理 + 几何表征” 的协同。
七、结论
空间智能是打通语言理解与物理世界推理的核心壁垒。本文从认知视角构建空间推理的分类体系,梳理了文本、视觉 - 语言、具身场景下的基准与评估指标,分析了训练式、推理式两类提升方法,揭示出当前模型的优势(静态定性描述)与短板(度量 / 动态 / 组合推理)。
未来需从表征、学习、评估三方面突破:研发能原生编码 3D 几何的架构、设计跨模态对齐的训练目标、构建贴合人类认知的基准,最终让基础模型具备真正的空间智能,支撑机器人、AR/VR 等具身场景的落地。
END

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 29
29 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)