
Qwen3-VL-235B-A22B-Thinking震撼发布:多模态AI新纪元的巅峰之作
在人工智能飞速发展的浪潮中,视觉语言模型正以前所未有的速度重塑着人机交互的边界。Qwen系列最新旗舰模型——Qwen3-VL-235B-A22B-Thinking的横空出世,无疑为这一领域树立了新的标杆。作为当前Qwen家族中性能最强劲的视觉语言模型,它在文本理解生成、视觉感知推理、上下文处理、空间视频动态认知以及智能体交互等核心维度实现了全方位的跨越式升级,为从边缘设备到云端服务器的多样化部署需
Qwen3-VL-235B-A22B-Thinking震撼发布:多模态AI新纪元的巅峰之作
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking 在人工智能飞速发展的浪潮中,视觉语言模型正以前所未有的速度重塑着人机交互的边界。Qwen系列最新旗舰模型——Qwen3-VL-235B-A22B-Thinking的横空出世,无疑为这一领域树立了新的标杆。作为当前Qwen家族中性能最强劲的视觉语言模型,它在文本理解生成、视觉感知推理、上下文处理、空间视频动态认知以及智能体交互等核心维度实现了全方位的跨越式升级,为从边缘设备到云端服务器的多样化部署需求提供了灵活且强大的解决方案。
全方位升级:解锁多模态AI潜能
Qwen3-VL-235B-A22B-Thinking的强大之处,首先体现在其对多模态能力的深度融合与全面增强。该模型不仅具备卓越的文本理解与生成能力,能够轻松应对各类复杂的自然语言处理任务,更在视觉感知与推理领域实现了质的飞跃。无论是静态图像的精细分析,还是动态视频的连贯理解,Qwen3-VL-235B-A22B-Thinking都展现出了超越前代的敏锐洞察力。其原生支持的256K上下文长度,更是突破性地可扩展至1M,使得处理整本书籍或数小时长视频成为可能,并能实现内容的完全回忆与秒级精准索引,这为处理海量视觉文本混合信息提供了坚实的技术支撑。
 这张架构图清晰地展示了Qwen3-VL-235B-A22B-Thinking的核心技术框架。从中可以直观地看到Interleaved-MRoPE位置嵌入技术如何在时间、宽度和高度上进行全频率分配,以及DeepStack如何融合多级ViT特征,这些创新是模型实现强大性能的关键。
这张架构图清晰地展示了Qwen3-VL-235B-A22B-Thinking的核心技术框架。从中可以直观地看到Interleaved-MRoPE位置嵌入技术如何在时间、宽度和高度上进行全频率分配,以及DeepStack如何融合多级ViT特征,这些创新是模型实现强大性能的关键。
模型在空间感知方面的能力同样令人瞩目。它能够精准判断物体的位置、视角关系以及复杂的遮挡情况,提供更为强大的2D与3D定位支持,这不仅为空间推理任务奠定了坚实基础,更为具身AI的发展铺平了道路。在智能体交互层面,Qwen3-VL-235B-A22B-Thinking赋予了AI操作PC或移动设备图形用户界面(GUI)的能力,它可以识别界面元素、理解其功能、调用相应工具,并最终自主完成指定任务,这标志着AI从被动响应向主动执行迈出了重要一步。
核心增强功能:赋能千行百业
Qwen3-VL-235B-A22B-Thinking的核心增强功能,犹如一把把打开新世界大门的钥匙,为各行各业的创新应用注入了强劲动力。视觉编码增强功能便是其中的佼佼者,它能够直接从图像或视频中生成Draw.io图表、HTML网页以及配套的CSS和JS代码,这极大地降低了从视觉创意到实际数字产品转化的门槛,为设计师、开发者带来了前所未有的高效工作方式。
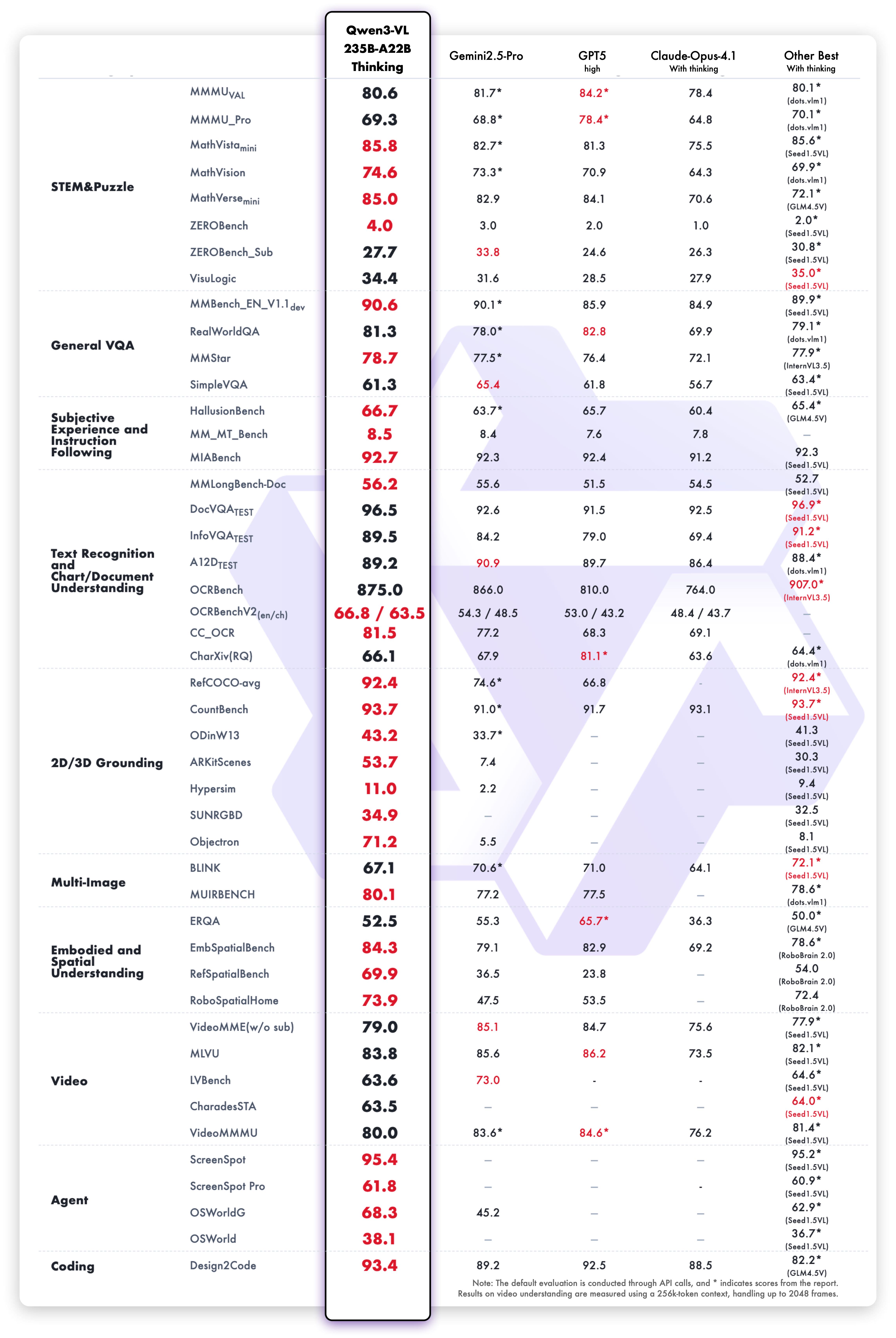 此多模态性能表详细罗列了Qwen3-VL-235B-Thinking在各类视觉语言任务上的表现。通过与同类模型的对比,数据清晰地证明了该模型在视觉问答、图像描述生成、视频理解等多模态任务中的领先地位,凸显了其在复杂场景下的实用价值。
此多模态性能表详细罗列了Qwen3-VL-235B-Thinking在各类视觉语言任务上的表现。通过与同类模型的对比,数据清晰地证明了该模型在视觉问答、图像描述生成、视频理解等多模态任务中的领先地位,凸显了其在复杂场景下的实用价值。
高级空间感知与增强的多模态推理能力,使得Qwen3-VL-235B-A22B-Thinking在STEM领域以及数学问题求解方面展现出非凡的才能。它能够进行深入的因果分析,并基于确凿证据给出逻辑严密的回答,这为科研探索、教育辅导等领域提供了强大的智力支持。在视觉识别的广度和深度上,模型通过更广泛、更高质量的预训练,实现了对“万物”的识别能力,无论是知名人物、热门动漫角色,还是各类产品、地标建筑,乃至丰富多样的动植物,都能被准确识别。
OCR(光学字符识别)功能的扩展更是满足了全球化应用的需求。Qwen3-VL-235B-A22B-Thinking支持的语言种类从19种大幅增加至32种,并且在低光照、图像模糊、文字倾斜等极端情况下依然保持稳健的识别性能。对于稀有文字、古代字符以及特定行业的行话术语,模型也展现出了出色的处理能力,同时在长文档的结构解析方面也有显著改进,这为跨语言信息处理、古籍数字化、行业文档自动化理解等应用场景带来了福音。值得一提的是,该模型在纯文本理解能力上已与顶尖的纯语言模型(LLM)相当,实现了文本与视觉信息的无缝融合,达成了无损且统一的理解境界。
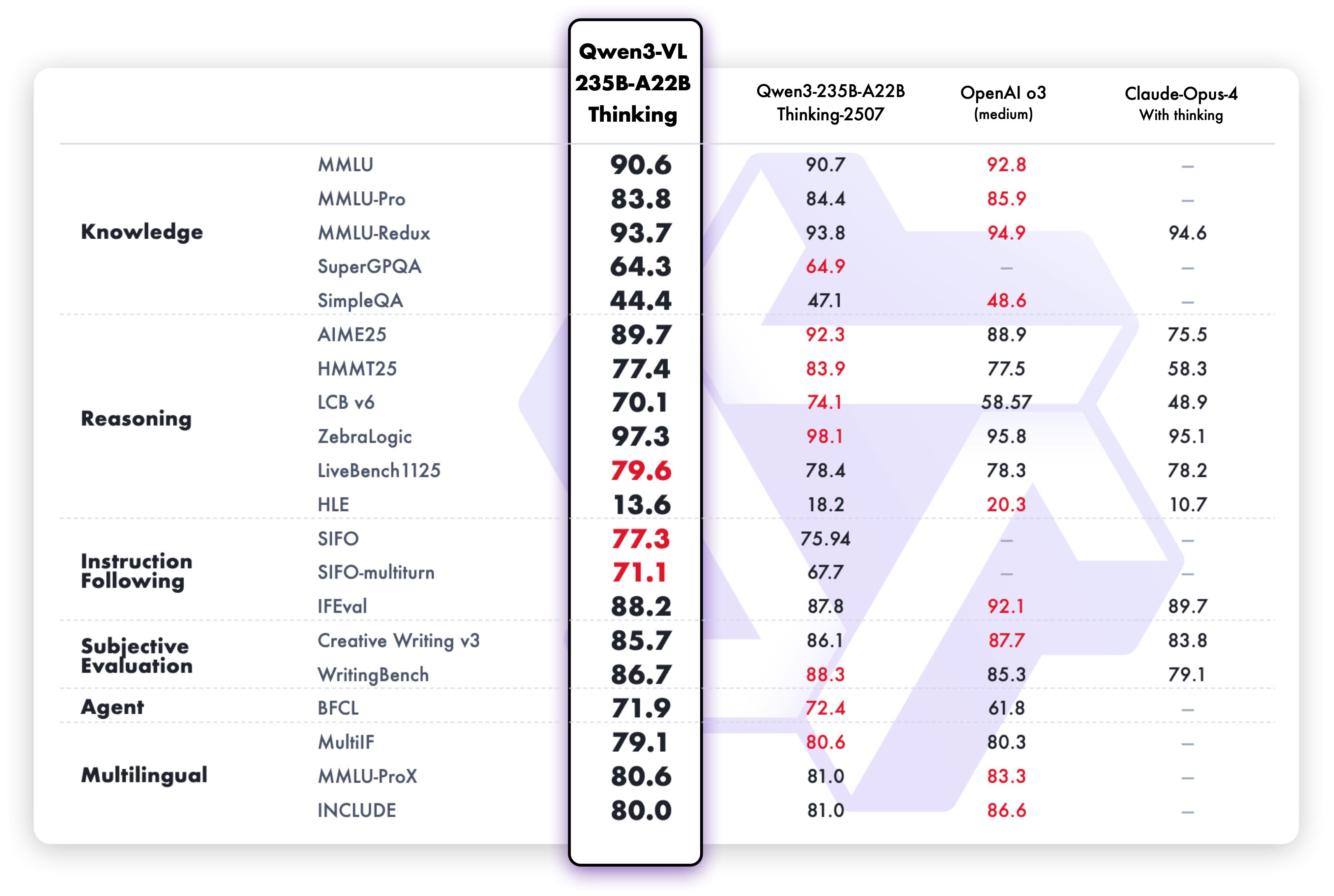 这张纯文本性能表展示了Qwen3-VL-235B-Thinking在各项纯文本任务上的卓越表现。数据表明,尽管是视觉语言模型,其文本理解和生成能力已达到纯LLM的水平,验证了其“无缝文本-视觉融合,实现无损、统一理解”的核心优势。
这张纯文本性能表展示了Qwen3-VL-235B-Thinking在各项纯文本任务上的卓越表现。数据表明,尽管是视觉语言模型,其文本理解和生成能力已达到纯LLM的水平,验证了其“无缝文本-视觉融合,实现无损、统一理解”的核心优势。
架构创新与部署灵活性:引领AI应用新范式
Qwen3-VL-235B-A22B-Thinking的卓越性能,离不开其在模型架构上的一系列突破性创新。Interleaved-MRoPE技术的引入,通过强大的位置嵌入机制,在时间、宽度和高度三个维度上实现了全频率的精细分配,这一创新显著增强了模型对长视界视频的推理能力,使得模型能够更好地理解视频序列中的动态变化和时空关联。DeepStack技术则通过融合多级视觉Transformer(ViT)特征,有效捕捉了图像中的细粒度细节,同时进一步锐化了图像与文本之间的对齐精度,为多模态信息的深度融合提供了坚实保障。
在视频理解的时间维度上,Qwen3-VL-235B-A22B-Thinking采用了超越传统T-RoPE的文本-时间戳对齐技术,实现了对视频中事件的精确时间定位,这一改进极大地增强了模型对视频内容的时间建模能力,使得对视频中复杂事件序列的理解更为准确和深入。
部署的灵活性是Qwen3-VL-235B-A22B-Thinking的另一大亮点。模型提供了从边缘计算到云端服务的多种部署选项,包括密集型架构和混合专家(MoE)架构,以满足不同场景下的算力需求。同时,Instruct版本和推理增强的Thinking版本的推出,使得用户可以根据具体的应用场景和任务需求,灵活选择最适合的模型版本进行部署,这大大降低了模型的应用门槛,加速了AI技术在实际生产生活中的落地与普及。
结语:开启智能交互新时代
Qwen3-VL-235B-A22B-Thinking的发布,不仅是Qwen系列模型发展史上的一个重要里程碑,更是整个多模态AI领域向前迈进的有力证明。它凭借全方位的能力升级、丰富的核心增强功能、创新的模型架构以及灵活的部署选项,为我们描绘了一个更加智能、高效、便捷的人机交互未来。
展望未来,Qwen3-VL-235B-A22B-Thinking有望在智能客服、内容创作、教育培训、自动驾驶、工业质检、医疗诊断等众多领域发挥巨大潜力。随着技术的不断迭代和优化,我们有理由相信,Qwen3-VL系列模型将持续推动多模态AI技术的边界,为各行各业的数字化转型和智能化升级注入源源不断的动力,真正开启一个人机协同、万物互联的智能交互新纪元。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)