
流匹配动作生成
流匹配是一种基于生成模型的动作生成方法,通过定义从噪声分布到目标动作分布的连续路径来实现动作生成。其核心是学习一个速度场v(A^t, o, t),指导噪声样本逐步向真实动作转变。训练时,神经网络学习预测真实速度场,最小化预测与真实速度的L2损失。推理时,从噪声出发,通过迭代应用速度场逐步生成动作。相比传统的行为克隆方法,流匹配提供了一种新的生成式建模思路,能够更灵活地处理动作生成任务。该方法通过连
基于流匹配(Flow Matching)的动作生成
1. 核心思想
传统的方法(如行为克隆)直接学习一个确定性策略 A = π ( o ) A = \pi(o) A=π(o) 或一个条件分布 P ( A ∣ o ) P(A|o) P(A∣o)。而流匹配方法采用了一种生成式模型的思路,通过一个速度场来刻画从噪声分布到目标动作分布的连续变换过程, 如图中从x4->x0,最上边是动作空间X0,坐标原点是高斯噪声空间X4。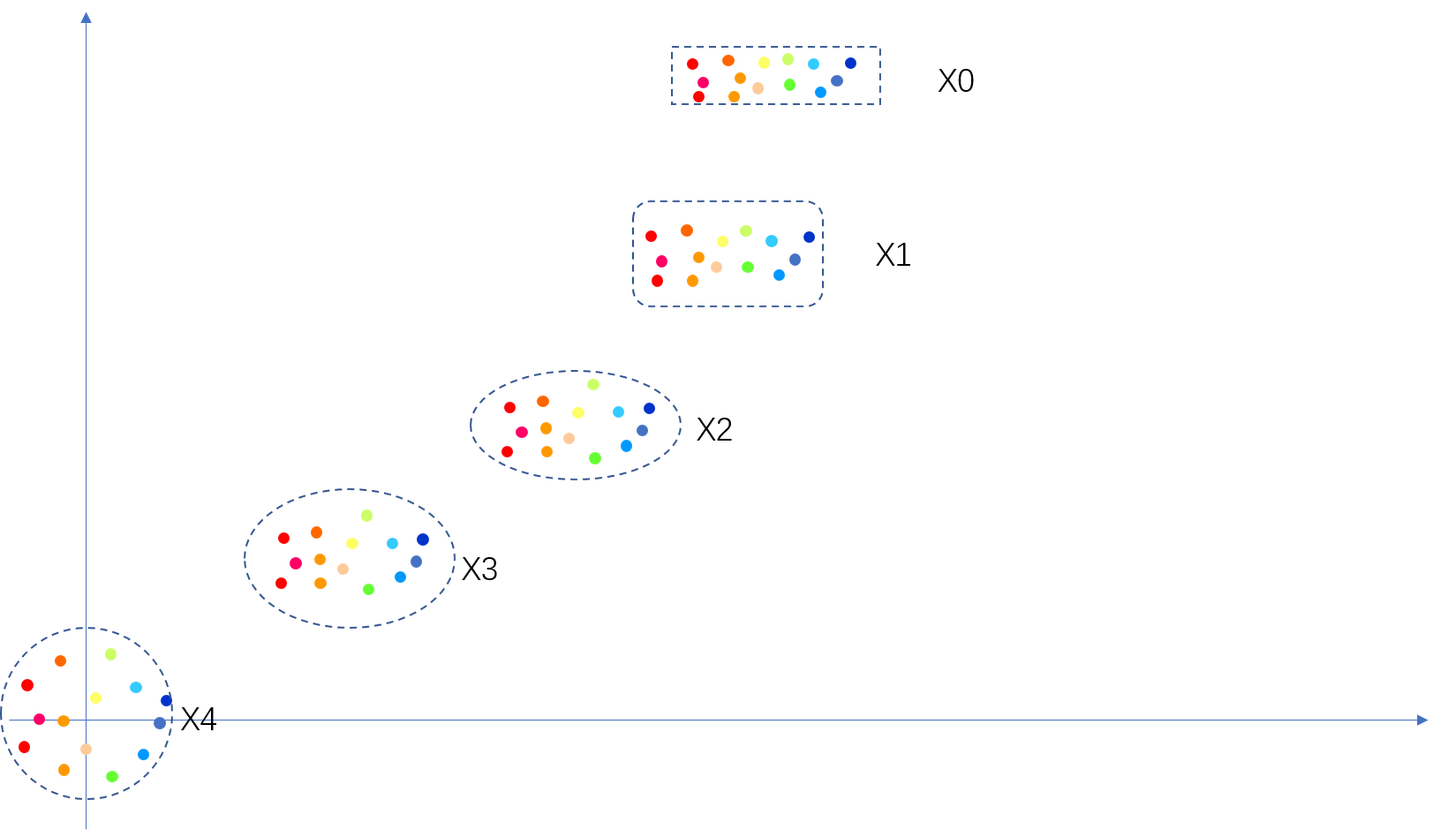
2. 数学框架:定义路径
首先,需要定义一条连接噪声空间和真实动作空间的路径。
-
起点( t = 0 t=0 t=0):一个容易采样的简单分布,通常是标准高斯分布。
- 动作状态: A 0 ∼ p 0 = N ( 0 , I ) A^0 \sim p_0 = \mathcal{N}(0, I) A0∼p0=N(0,I)
-
终点( t = 1 t=1 t=1):我们想要得到的真实、复杂的动作分布。
- 动作状态: A 1 ∼ p data A^1 \sim p_{\text{data}} A1∼pdata(即来自专家数据的真实动作块 A A A)
-
路径( 0 < t < 1 0 < t < 1 0<t<1):在起点和终点之间,我们定义一条连续的路径。对于任意时间 t t t,都有一个对应的动作状态 A t A^t At。最简单的是直线路径:
- A t = ( 1 − t ) ⋅ A 0 + t ⋅ A 1 A^t = (1 - t) \cdot A^0 + t \cdot A^1 At=(1−t)⋅A0+t⋅A1
- 当 t = 0 t=0 t=0 时, A 0 A^0 A0 就是起点噪声
- 当 t = 1 t=1 t=1 时, A 1 A^1 A1 就是终点真实动作
3. 关键概念:速度场(Velocity Field)
速度场 v ( A t , o , t ) v(A^t, o, t) v(At,o,t) 是流匹配方法的核心。
-
直观理解:想象 A t A^t At 是时刻 t t t 的一个粒子。这个粒子要从噪声 A 0 A^0 A0 运动到目标动作 A 1 A^1 A1。速度场 v v v 就定义了这个粒子在每一个时间点 t t t、每一个位置 A t A^t At 上,应该朝着哪个方向、以多快的速度运动。
-
数学定义:速度场是路径 A t A^t At 对时间 t t t 的导数,即瞬时变化率。
- v ( A t , o , t ) = d A t d t v(A^t, o, t) = \frac{dA^t}{dt} v(At,o,t)=dtdAt
对于我们上面定义的直线路径 A t = ( 1 − t ) A 0 + t A 1 A^t = (1-t)A^0 + tA^1 At=(1−t)A0+tA1,我们可以计算其速度场(这是真实的速度场):
v ( A t , o , t ) = d [ ( 1 − t ) A 0 + t A 1 ] d t = A 1 − A 0 v(A^t, o, t) = \frac{d[(1-t)A^0 + tA^1]}{dt} = A^1 - A^0 v(At,o,t)=dtd[(1−t)A0+tA1]=A1−A0
这个结果非常重要:它意味着,对于一条已知的、连接 A 0 A^0 A0 和 A 1 A^1 A1 的路径,其真实的速度场就是终点和起点之间的向量差 ( A 1 − A 0 ) (A^1 - A^0) (A1−A0)。
4. 训练目标:学习速度场
在推理时,我们不知道真实的 A 1 A^1 A1(那就是我们要生成的目标)。所以,我们需要一个神经网络 v θ v_\theta vθ 来学习逼近这个真实的速度场。
- 训练数据:我们拥有专家数据对 ( o , A ) (o, A) (o,A),其中 A A A 就是真实的 A 1 A^1 A1
- 训练过程:
- 随机采样一个专家数据对 ( o , A ) (o, A) (o,A)
- 从高斯分布中采样一个噪声起点 A 0 ∼ N ( 0 , I ) A^0 \sim \mathcal{N}(0, I) A0∼N(0,I)
- 随机采样一个时间点 t ∼ Uniform ( 0 , 1 ) t \sim \text{Uniform}(0, 1) t∼Uniform(0,1)
- 根据路径公式(如直线路径)计算 t t t 时刻的中间状态: A t = ( 1 − t ) A 0 + t ⋅ A A^t = (1-t)A^0 + t \cdot A At=(1−t)A0+t⋅A
- 计算真实的速度场: v true = A − A 0 v_{\text{true}} = A - A^0 vtrue=A−A0(根据上面的推导)
- 让神经网络 v θ v_\theta vθ,以 ( A t , o , t ) (A^t, o, t) (At,o,t) 为输入,预测速度场 v pred = v θ ( A t , o , t ) v_{\text{pred}} = v_\theta(A^t, o, t) vpred=vθ(At,o,t)
- 最小化预测值与真实值之间的差距(如 L2 损失):
L ( θ ) = E [ ∥ v θ ( A t , o , t ) − v ( A t , o , t ) ∥ 2 ] = E [ ∥ v θ ( A t , o , t ) − ( A − A 0 ) ∥ 2 ] \mathcal{L}(\theta) = \mathbb{E}[ \| v_\theta(A^t, o, t) -v(A^t, o, t) \|^2 ]=\mathbb{E}[ \| v_\theta(A^t, o, t) - (A - A^0) \|^2 ] L(θ)=E[∥vθ(At,o,t)−v(At,o,t)∥2]=E[∥vθ(At,o,t)−(A−A0)∥2]
通过这个简单的损失函数,神经网络学会了在给定观测 o o o 下,如何将任意一个中间状态 A t A^t At 推向下一个"更接近"真实专家动作 A A A 的状态。
5. 推理(生成)过程:从噪声迭代到动作
训练好网络后,我们就可以进行推理,从噪声"流式"地生成动作:
-
初始化:从高斯分布采样一个随机噪声 A 0 ∼ N ( 0 , I ) A^0 \sim \mathcal{N}(0, I) A0∼N(0,I)
-
迭代求解(例如使用欧拉法):
-
将时间区间 [ 0 , 1 ] [0, 1] [0,1] 离散成 N N N 个小步(如 t = 0 , 0.1 , 0.2 , … , 1.0 t=0, 0.1, 0.2, \ldots, 1.0 t=0,0.1,0.2,…,1.0)
-
For k = 0 k = 0 k=0 to N − 1 N-1 N−1:
- 当前时间 t k = k / N t_k = k / N tk=k/N,当前状态是 A t k A^{t_k} Atk
- 将 ( A t k , o , t k ) (A^{t_k}, o, t_k) (Atk,o,tk) 输入神经网络 v θ v_\theta vθ,得到预测的速度 v pred v_{\text{pred}} vpred
- 更新状态(向前走一小步):
A t k + 1 = A t k + 1 N ⋅ v pred A^{t_{k+1}} = A^{t_k} + \frac{1}{N} \cdot v_{\text{pred}} Atk+1=Atk+N1⋅vpred
-
End For
-
-
输出:最终的状态 A t = 1 A^{t=1} At=1 就是我们生成的动作 A A A
这个迭代过程,就是沿着学习到的速度场指引的方向,将初始的噪声粒子一步步"流动"到最终符合观测 o o o 的、合理的动作区域。
在迭代求解的过程中还可以使用Runge-Kutta Methods(龙格库塔方法), 其实欧拉法就是一阶龙格库塔方法
代码实现
已上传仓库
flow matching
输出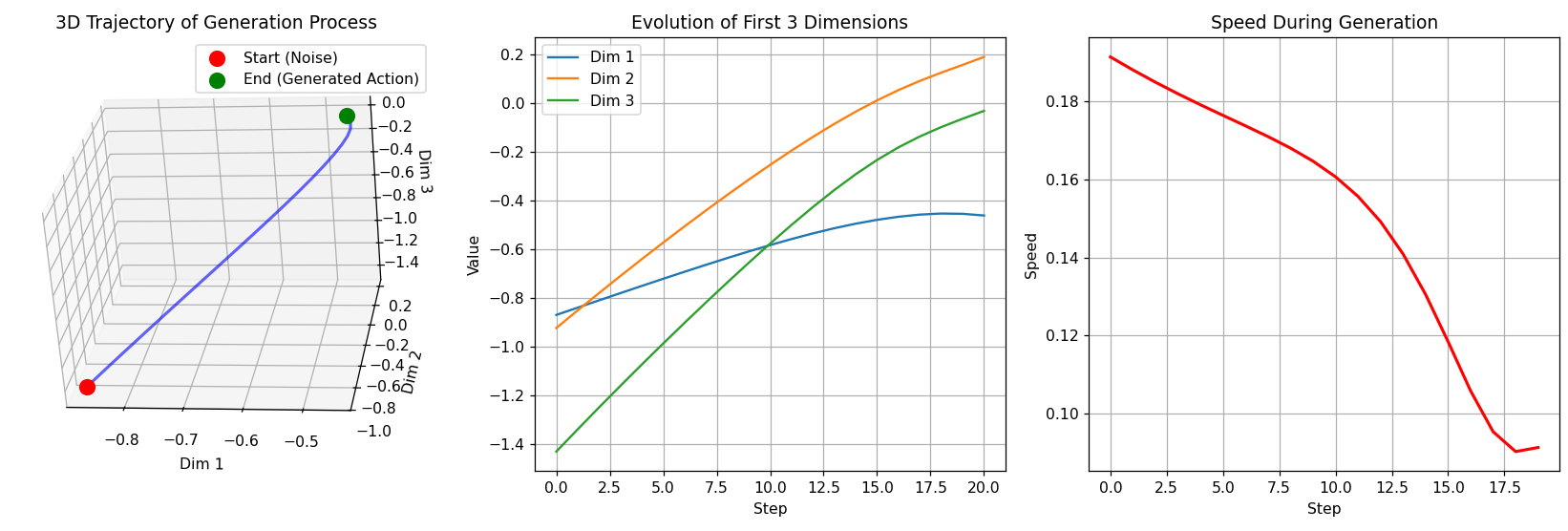
$ python flow_matching.py
Using device: cuda
Model parameters: 151,402
Training on 5000 samples...
Epoch [0/50], Loss: 0.860231
Epoch [10/50], Loss: 0.519448
Epoch [20/50], Loss: 0.498909
Epoch [30/50], Loss: 0.486166
Epoch [40/50], Loss: 0.479616
Testing generation...
1. Using Euler method (default):
Test 1: Generated action shape: torch.Size([1, 10]), Mean: 0.031
Test 2: Generated action shape: torch.Size([1, 10]), Mean: 0.128
Test 3: Generated action shape: torch.Size([1, 10]), Mean: -0.172
2. Using Heun's method (higher order):
Test 1: Generated action shape: torch.Size([1, 10]), Mean: -0.012
Test 2: Generated action shape: torch.Size([1, 10]), Mean: 0.087
Test 3: Generated action shape: torch.Size([1, 10]), Mean: -0.284
Visualizing generation process...
Validating generation quality...
Average MSE between generated and true actions: 0.203130
Testing diversity (multiple generations from same observation):
Average distance between different generations: 1.005326
Done!
==================================================
QUICK USAGE EXAMPLE
==================================================
Model architecture:
VelocityFieldNetwork(
(time_embedding): Sequential(
(0): Linear(in_features=1, out_features=32, bias=True)
(1): SiLU()
(2): Linear(in_features=32, out_features=32, bias=True)
)
(net): Sequential(
(0): Linear(in_features=45, out_features=128, bias=True)
(1): SiLU()
(2): Linear(in_features=128, out_features=128, bias=True)
(3): SiLU()
(4): Linear(in_features=128, out_features=128, bias=True)
(5): SiLU()
(6): Linear(in_features=128, out_features=5, bias=True)
)
)
Input shape - Observations: torch.Size([4, 8])
Output shape - Velocity field: torch.Size([4, 5])
Generated action shape: torch.Size([1, 5])
Generated action sample: [-0.69432604 1.1592369 0.6271717 ]...
ref
https://zhuanlan.zhihu.com/p/704226398
https://blog.csdn.net/weixin_43911479/article/details/149354158
Flow Matching tutorial

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)