
Qwen3-Omni:统一端到端多模态交互模型的架构演进与技术突破
首个支持动态思考模式切换的开源大模型→ 一模型通吃简单与复杂任务。119语言支持 + 36T Token训练→ 真正全球化、多领域能力。强到弱蒸馏 + 高效MoE→ 小模型低成本高性能,推动边缘部署。全系列开源 + 完整技术报告→ 社区可复现、可改进、可商用。
-
Qwen3-Omni:首次实现单一模型统一处理四模态输入(文本、图像、音频、视频)并支持双模态输出(文本 + 语音),在不牺牲任一单模态性能的前提下,构建了端到端、低延迟、高保真的多模态交互闭环。
-
Qwen3-Omni:强大的性能,在36项音频及音视频基准测试中获得32项开源SOTA和22项总体SOTA。超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等闭源强模型。
-
Qwen3-Omni:多语言支持,支持119种文本语言交互、19种语音理解语言与10种语音生成语言。
-
Qwen3-Omni:更快响应,模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms。
-
Qwen3-Omni:长音频处理能力,支持长达30分钟的音频理解。
-
Qwen3-Omni:核心架构升级,Thinker–Talker MoE 架构、低延迟语音合成机制、多语言支持能力及多模态推理增强策略。
一、迈向统一多模态智能体
传统多模态系统通常采用“模态分离 → 对齐 → 融合”范式,存在三大瓶颈:
- 模态割裂:各模态编码器独立训练,语义对齐依赖后处理;
- 延迟高:语音生成依赖块级扩散模型或级联 TTS,无法实时;
- 能力退化:多模态混训常导致单模态性能下降(“多模态诅咒”)。
- Qwen3-Omni:提出 原生全模态统一架构(Native Omni-Modal Architecture),在预训练阶段即融合四模态数据,实现:
- 输入统一:文本、图像、音频、视频共享同一语义空间;
- 输出统一:同步生成文本 token 与语音 token;
- 能力无损:单模态任务性能与同尺寸纯文本/视觉模型持平。
核心理念:不是“多模态拼接”,而是“模态内生”。
二、核心架构:Thinker–Talker MoE 统一框架
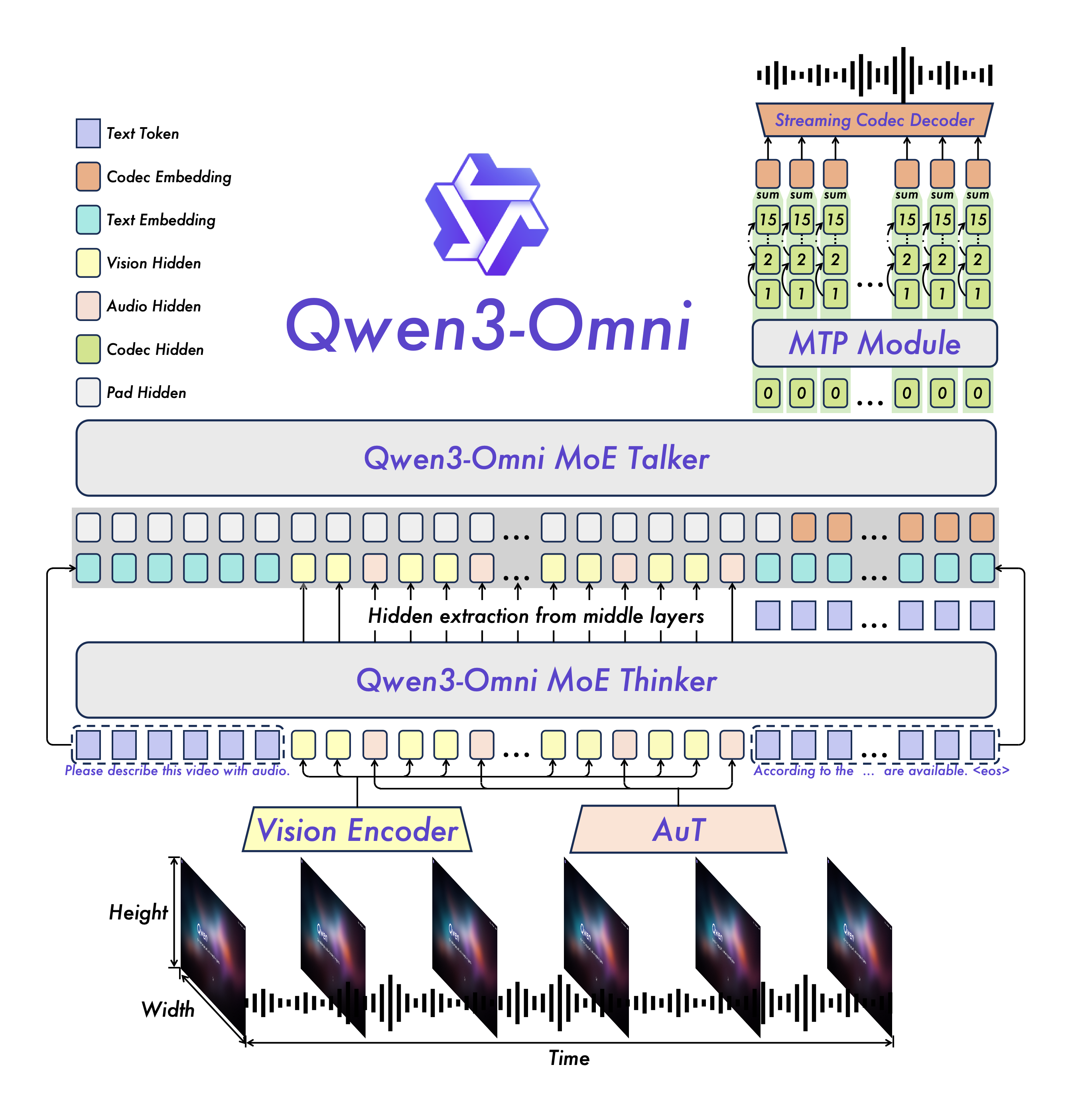
Qwen3-Omni 延续并升级了 Qwen2.5-Omni 的 Thinker–Talker 双模块设计,二者均采用 Mixture-of-Experts (MoE) 架构,实现感知与生成的解耦与协同。
2.1 模块分工
| 模块 | 功能 | 输入模态 | 输出模态 |
|---|---|---|---|
| Thinker | 多模态理解与推理 | 文本、图像、音频、视频 | 隐式语义表示 |
| Talker | 实时语音/文本生成 | Thinker 的中间表示 | 文本 + 语音 |
设计哲学:Thinker 聚焦“理解世界”,Talker 专注“表达响应”,二者通过共享语义空间实现无缝衔接。
2.2 关键技术升级
(1)自研音频编码器 AuT(Audio Transformer)
- 替代方案:以自研 AuT 替换 Whisper 编码器
- 训练数据:基于 2000 万小时 监督音频数据训练
- 通用表征能力:支持语音、音乐、环境声、噪声等任意音频类型
- 实时优化:支持 预填充缓存(prefilled cache),实现流式音频输入的低延迟处理
(2)多码本语音生成(Multi-codebook Speech Synthesis)
- 编码方式:Talker采用多轨离散语音编解码器(multi-track codec)
- 建模能力:显著提升对 声音多样性、副语言线索(如语气、停顿)、声学现象(如混响、噪声) 的建模精度
- 生成机制:Talker 通过 MTP(Multi-track Prediction)模块 自回归预测多个码本层,后由轻量 Code2Wav 模块将码本序列实时合成为波形,无需等待完整句子
(3)超低码率与即时合成
- 音频码率:输入/输出码率降至 12.5 Hz(即每 80ms 一帧)
- 端到端延迟:
- 在冷启动(无上下文)场景下,端到端首包延迟理论值为 234 ms
- 纯音频对话:211 ms(从首帧音频输入到首包语音输出);
- 视频对话:507 ms(含视频帧处理)
- 生成机制:Talker 摒弃传统块级扩散模型,采用 轻量因果 ConvNet 直接从首帧开始生成语音
(4)训练策略:全模态不降智(Omni-Modal Without Degradation)
为避免多模态混训导致的单模态性能下降,Qwen3-Omni 采用 早期混合训练策略:
- 数据混合:在预训练初期即混合单模态(文本、图像)与跨模态(音视频对、图文对)数据;
- 模态掩码:对非目标模态输入施加随机掩码,强制模型学习跨模态泛化;
- 损失加权:对不同模态任务采用自适应损失权重 λ_m\lambda\_mλ_m,平衡优化目标。
实验表明,该策略下:
- 文本任务性能 ≈ Qwen3-30B(纯文本模型);
- 视觉任务性能 ≈ Qwen-VL-30B;
- 音频任务性能显著超越专用 ASR/TTS 系统。
核心结论:全模态 ≠ 多模态拼接,而是模态内生融合。
三、性能表现:全面超越闭源模型
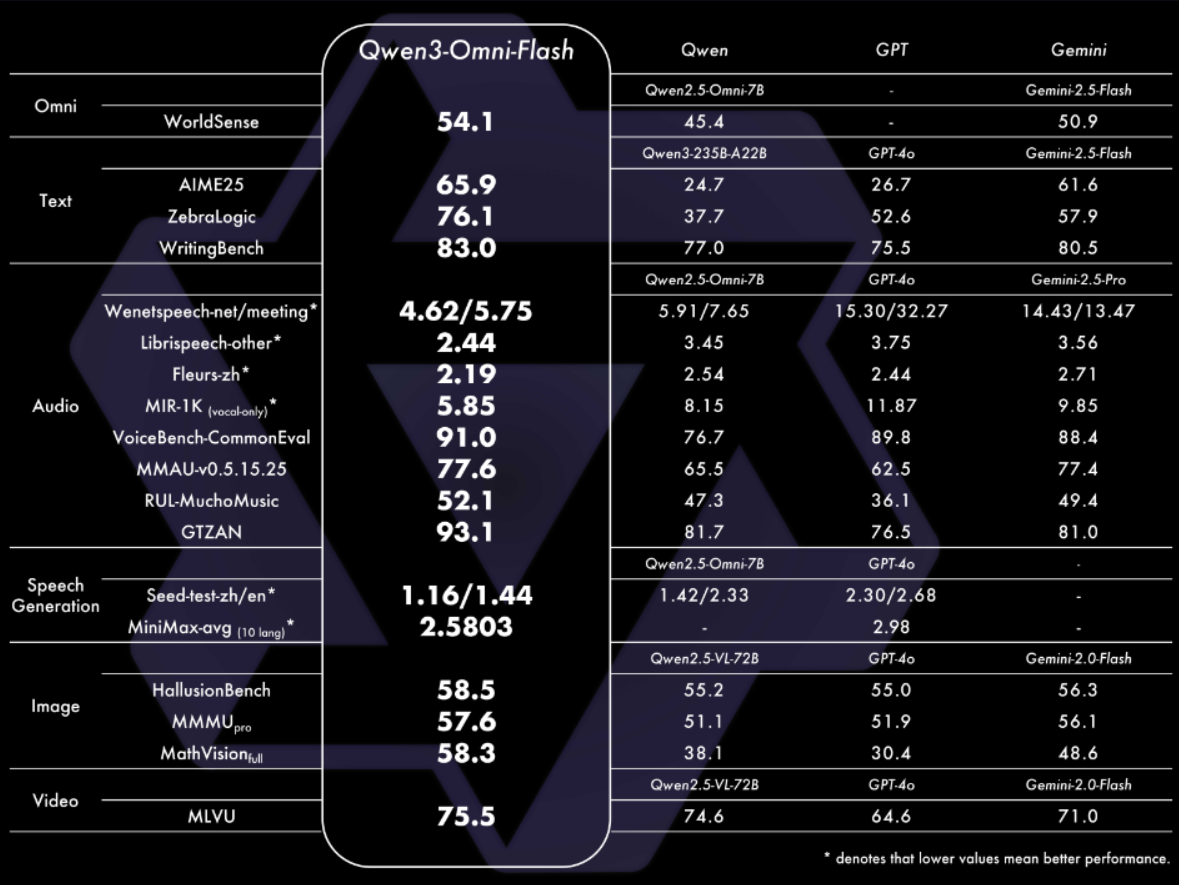
3.1 多模态基准测试结果
| 任务类别 | 基准名称 | Qwen3-Omni | Gemini-2.5-Pro | GPT-4o-Transcribe | SOTA 类型 |
|---|---|---|---|---|---|
| 通用语音理解 | VoiceBench | 89.5 | 89.6 | 88.7 | 整体 SOTA |
| 多模态音频理解 | MMAU | 76.5 | 71.8 | 62.5 | 开源 SOTA |
| 音频语义理解 | MMSU | 84.3 | 66.1 | 70.2 | 开源 SOTA |
| 音乐理解 | RUL-MuchoMusic | 52.1 | — | — | 整体 SOTA |
| 音乐分类 | GTZAN | 93.1 | 87.9 | — | 开源 SOTA |
在 36 项音频/音视频基准中,32 项达开源 SOTA,22 项达整体 SOTA
3.2 语言与上下文支持能力
| 能力维度 | 支持范围 |
|---|---|
| 文本交互语言 | 119 种 |
| 语音理解语言 | 19 种 |
| 语音生成语言 | 10 种 |
| 最大音频输入长度 | > 40 分钟/实例 |
| 上下文长度 | 原生支持 256K tokens |
四、增强推理:Thinking 模型与 Captioner 扩展
为强化复杂推理与内容生成能力,Qwen3-Omni 推出两个专用变体:
4.1 Qwen3-Omni-30B-A3B-Thinking
- 定位:专为 多模态推理 优化
- 能力:显式建模跨模态因果关系,适用于科学问答、逻辑推理、事件预测等任务
- 训练策略:引入 思维链(Chain-of-Thought)监督微调
4.2 Qwen3-Omni-30B-A3B-Captioner
- 动机:当前社区缺乏通用音频描述(Audio Captioning)模型
- 优势:首个开源高性能通用音频 caption 模型
- 定位:为任意音频生成详细、低幻觉的自然语言描述
- 能力:为任意音频生成 详细、低幻觉 的自然语言描述
- 应用场景:无障碍服务、音频内容索引、多媒体检索
开源协议:上述模型均以 Apache 2.0 许可证 开源发布
五、扩展能力:个性化、工具调用与开源 Captioner
5.1 API 调用示例(兼容 OpenAI 协议)
from openai import OpenAI
import os
# 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 多模态请求:图像 + 文本
response = client.chat.completions.create(
model="qwen3-omni", # 或 qwen3-omni-thinking / qwen3-omni-captioner
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请描述图中人物正在做什么,并用中文回答"},
{
"type": "image_url",
"image_url": {
"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"
}
}
]
}
],
stream=False # 支持流式输出
)
print(response.choices[0].message.content)
5.2 关键参数说明
| 参数 | 说明 |
|---|---|
model |
指定模型变体(qwen3-omni, qwen3-omni-thinking 等) |
stream |
是否启用流式响应(适用于实时语音合成) |
max_tokens |
控制生成长度(影响延迟与成本) |
5.3 个性化定制(System Prompt)
支持通过 system 角色消息定制:
- 对话风格(正式/幽默/简洁);
- 人设(医生、教师、客服等);
- 行为约束(如“仅回答事实,不编造”)。
{
"role": "system",
"content": "你是一位专业的音乐评论家,请用中文详细分析以下音频的风格、乐器和情感。"
}
5.4 工具调用(Function Calling)
原生支持 OpenAI 风格 function call,可调用外部 API 实现:
- 实时天气查询;
- 数据库检索;
- 设备控制(如智能家居)。
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {"type": "object", "properties": {"city": {"type": "string"}}}
}
}]
六、技术对比与意义
6.1 与前代模型对比(Qwen2.5-Omni → Qwen3-Omni)
| 特性 | Qwen2.5-Omni | Qwen3-Omni | 提升点 |
|---|---|---|---|
| 音频编码器 | Whisper | 自研 AuT | 延迟↓、精度↑ |
| Talker 架构 | 单轨生成 | 多轨 MoE | 语音自然度↑ |
| 首包延迟 | ~500 ms | 234 ms | 实时性↑ |
| 音频输入长度 | ≤40 分钟 | >40 分钟 | 长音频支持↑ |
| 多语言语音生成 | 未明确 | 10 种语言 | 全球化↑ |
6.2 与主流 Omni 模型对比
| 特性 | Qwen3-Omni | GPT-4o | Gemini-2.5-Pro | Seed-ASR |
|---|---|---|---|---|
| 原生全模态 | ✅ | ⚠️(后期对齐) | ⚠️ | ❌(仅音频) |
| 开源 | ✅(Apache 2.0) | ❌ | ❌ | ❌ |
| 端到端延迟(音频) | 211 ms | ~400 ms | ~300 ms | >1000 ms |
| 语音生成语言 | 10 | 未公开 | 未公开 | 1 |
| 长音频支持 | ≥30 min | 未明确 | 未明确 | <10 min |
6.3 行业影响
- 打破闭源垄断:在关键音频任务上超越 GPT-4o 与 Seed-ASR
- 推动开源生态:提供首个高性能、低延迟、全模态开源 Omni 模型
- 定义新范式:确立“统一端到端 + Thinker–Talker 解耦”为多模态交互新标准
Qwen3-Omni 为多模态智能体奠定了坚实基础,后续方向包括:
- 具身智能扩展:接入机器人控制接口,实现“感知-决策-执行”闭环
- 情感与个性建模:通过系统提示(system prompt)定制对话风格与人格
- 跨模态记忆机制:构建长期多模态记忆库,支持跨会话上下文理解
- 能耗优化:探索稀疏激活与量化压缩,适配边缘设备部署

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)