
LangGraph第2篇 | 智能客服系统案例实战
核心功能意图识别:自动判断用户是咨询问题、投诉还是闲聊知识库问答:基于 RAG 从产品文档中查找答案工单创建:对于投诉类问题,自动创建工单多轮对话:支持上下文记忆的连续对话人工介入:复杂问题自动转人工客服技术亮点使用 LangGraph 编排多个 Agent实现条件路由(根据意图走不同流程)集成 RAG(检索增强生成)实现 Human-in-the-Loop"""客服系统的全局状态"""
本文通过一个完整的智能客服系统案例,手把手带你实现 LangGraph 多 Agent 协作应用。包含环境准备、概要设计、完整代码演示。
一、案例介绍
我们要实现一个智能客服系统,具备以下功能:
核心功能:
-
意图识别:自动判断用户是咨询问题、投诉还是闲聊
-
知识库问答:基于 RAG 从产品文档中查找答案
-
工单创建:对于投诉类问题,自动创建工单
-
多轮对话:支持上下文记忆的连续对话
-
人工介入:复杂问题自动转人工客服
技术亮点:
-
使用 LangGraph 编排多个 Agent
-
实现条件路由(根据意图走不同流程)
-
集成 RAG(检索增强生成)
-
实现 Human-in-the-Loop
二、环境准备
2.1 安装依赖
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装核心依赖
pip install langgraph langchain langchain-openai langchain-community
# 安装向量数据库(用于 RAG)
pip install chromadb
# 安装状态持久化(Checkpointing)
pip install langgraph-checkpoint-sqlite
# 安装工具库
pip install python-dotenv pydantic
完整 requirements.txt:
langgraph==0.2.28
langchain==0.3.0
langchain-openai==0.2.0
langchain-community==0.3.0
chromadb==0.5.0
langgraph-checkpoint-sqlite==1.0.0
python-dotenv==1.0.0
pydantic==2.9.0
2.2 配置环境变量
创建 .env 文件:
# OpenAI API 配置
OPENAI_API_KEY=your-api-key-here
OPENAI_API_BASE=https://api.openai.com/v1
# 模型配置
MODEL_NAME=gpt-4o-mini
TEMPERATURE=0.7
2.3 准备知识库数据
创建 knowledge_base.txt(模拟产品文档):
产品名称:智能手表 Pro
价格:2999元
功能特性:
- 心率监测:24小时连续心率监测
- 运动模式:支持100+种运动模式
- 电池续航:正常使用7天,重度使用3天
- 防水等级:50米防水
- 屏幕:1.43英寸AMOLED屏幕
常见问题:
Q: 如何充电?
A: 使用附赠的磁吸充电器,将充电器对准手表背面即可自动吸附充电。
Q: 支持哪些手机?
A: 支持iOS 12.0及以上、Android 6.0及以上系统。
Q: 如何连接手机?
A: 下载官方APP,打开蓝牙,在APP中搜索设备并配对即可。
售后政策:
- 7天无理由退换
- 1年质保
- 终身技术支持
三、概要设计
3.1 整体架构
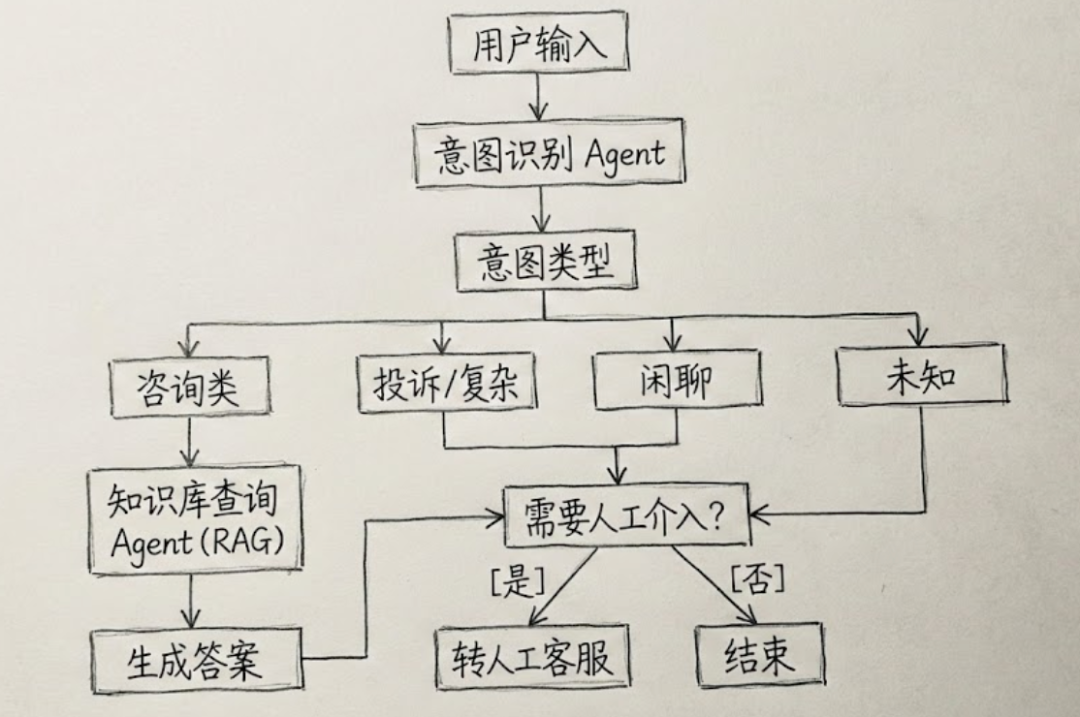
3.2 状态设计
from typing import Annotated, Literal, TypedDict
import operator
class CustomerServiceState(TypedDict):
"""客服系统的全局状态"""
# 对话消息(自动累加)
messages: Annotated[list[dict], operator.add]
# 用户信息
user_id: str
session_id: str
# 意图识别结果
intent: Literal["inquiry", "complaint", "chitchat", "unknown"]
# 知识库检索结果
knowledge_docs: list[str]
# 最终答案
answer: str
# 对话历史(支持多轮对话)
conversation_history: Annotated[list[dict], operator.add]
# 控制流
need_human: bool # 是否需要人工
current_step: str # 当前步骤
3.3 Agent 职责划分
|
Agent |
职责 |
输入 |
输出 |
|---|---|---|---|
| 意图识别 |
判断用户意图 |
用户消息 + 历史 |
intent 类型 |
| 知识库查询 |
RAG 检索相关文档 |
用户问题 |
相关文档列表 |
| 答案生成 |
基于文档生成答案 |
问题 + 文档 + 历史 |
最终答案 |
| 路由器 |
决定下一步走向 |
当前状态 |
下一个节点 |
关键特性:
-
对话历史管理:支持多轮对话,Agent 可以访问历史上下文
-
状态持久化:使用 Checkpointing 保存会话状态,支持中断恢复
四、完整代码实现
4.1 项目结构
intelligent_customer_service/
├── .env # 环境变量
├── knowledge_base.txt # 知识库数据
├── main.py # 主程序
├── config.py # 配置管理
├── agents.py # Agent 实现
├── tools.py # 工具函数(RAG)
└── graph.py # 工作流编排
4.2 配置管理(config.py)
from pydantic_settings import BaseSettings
from dotenv import load_dotenv
load_dotenv()
class Settings(BaseSettings):
"""配置管理"""
openai_api_key: str
openai_api_base: str = "https://api.openai.com/v1"
model_name: str = "gpt-4o-mini"
temperature: float = 0.7
class Config:
env_file = ".env"
settings = Settings()
4.3 状态定义(agents.py - Part 1)
from typing import Annotated, Literal, TypedDict
import operator
class CustomerServiceState(TypedDict):
"""客服系统的全局状态"""
messages: Annotated[list[dict], operator.add]
user_id: str
session_id: str
intent: Literal["inquiry", "complaint", "chitchat", "unknown"]
knowledge_docs: list[str]
answer: str
conversation_history: Annotated[list[dict], operator.add] # 对话历史
need_human: bool
current_step: str
4.4 RAG 工具(tools.py)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from config import settings
class KnowledgeBase:
"""知识库管理(RAG)"""
def __init__(self, knowledge_file: str = "knowledge_base.txt"):
# 1. 读取知识库文件
with open(knowledge_file, 'r', encoding='utf-8') as f:
text = f.read()
# 2. 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50
)
chunks = text_splitter.split_text(text)
# 3. 创建向量数据库
embeddings = OpenAIEmbeddings(
openai_api_key=settings.openai_api_key,
openai_api_base=settings.openai_api_base
)
self.vectorstore = Chroma.from_texts(
texts=chunks,
embedding=embeddings
)
def search(self, query: str, k: int = 3) -> list[str]:
"""检索相关文档"""
docs = self.vectorstore.similarity_search(query, k=k)
return [doc.page_content for doc in docs]
# 初始化知识库(全局单例)
knowledge_base = KnowledgeBase()
4.5 Agent 实现(agents.py - Part 2)
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from config import settings
from tools import knowledge_base
# 初始化 LLM
llm = ChatOpenAI(
model=settings.model_name,
temperature=settings.temperature,
openai_api_key=settings.openai_api_key,
openai_api_base=settings.openai_api_base
)
def intent_classifier_agent(state: CustomerServiceState) -> dict:
"""意图识别 Agent"""
# 获取最新的用户消息
user_message = state["messages"][-1]["content"]
# 获取对话历史(最近3轮)
history = state.get("conversation_history", [])[-6:] # 取最近3轮(6条消息)
history_text = "\n".join([f"{msg['role']}: {msg['content']}"for msg in history]) if history else"无历史对话"
# 构建提示词(包含历史上下文)
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个意图识别专家。请判断用户消息的意图类型。
意图类型:
- inquiry: 咨询产品信息、功能、使用方法等
- complaint: 投诉、退换货、质量问题等
- chitchat: 闲聊、打招呼等
- unknown: 无法识别
参考历史对话上下文,判断用户当前意图。只返回意图类型,不要有其他内容。
【历史对话】
{history}"""),
("user", "当前消息: {message}")
])
# 调用 LLM
chain = prompt | llm
result = chain.invoke({
"history": history_text,
"message": user_message
})
intent = result.content.strip().lower()
# 验证意图
valid_intents = ["inquiry", "complaint", "chitchat", "unknown"]
if intent notin valid_intents:
intent = "unknown"
return {
"intent": intent,
"current_step": "intent_classified"
}
def knowledge_query_agent(state: CustomerServiceState) -> dict:
"""知识库查询 Agent(RAG)"""
user_message = state["messages"][-1]["content"]
# 从知识库检索相关文档
docs = knowledge_base.search(user_message, k=3)
return {
"knowledge_docs": docs,
"current_step": "knowledge_retrieved"
}
def answer_generation_agent(state: CustomerServiceState) -> dict:
"""答案生成 Agent"""
user_message = state["messages"][-1]["content"]
knowledge_docs = state.get("knowledge_docs", [])
# 获取对话历史(最近3轮)
history = state.get("conversation_history", [])[-6:]
history_text = "\n".join([f"{msg['role']}: {msg['content']}"for msg in history]) if history else"无历史对话"
# 构建 RAG 提示词(包含历史上下文)
context = "\n\n".join(knowledge_docs) if knowledge_docs else"暂无相关信息"
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个专业的客服人员。请基于以下知识库内容和历史对话回答用户问题。
【知识库内容】
{context}
【历史对话】
{history}
【回答要求】
1. 结合历史对话理解用户问题
2. 只基于知识库内容回答,不要编造信息
3. 如果知识库中没有相关信息,礼貌地告知用户
4. 回答要简洁、准确、友好
5. 使用第一人称("我"、"我们")"""),
("user", "{question}")
])
chain = prompt | llm
result = chain.invoke({
"context": context,
"history": history_text,
"question": user_message
})
answer = result.content
return {
"answer": answer,
"messages": [{"role": "assistant", "content": answer}],
"conversation_history": [
{"role": "user", "content": user_message},
{"role": "assistant", "content": answer}
],
"current_step": "answer_generated"
}
def chitchat_agent(state: CustomerServiceState) -> dict:
"""闲聊 Agent"""
user_message = state["messages"][-1]["content"]
# 获取历史对话
history = state.get("conversation_history", [])[-4:]
history_text = "\n".join([f"{msg['role']}: {msg['content']}"for msg in history]) if history else"无历史对话"
prompt = ChatPromptTemplate.from_messages([
("system", """你是一个友好的客服人员,用简短、亲切的方式回应用户。
【历史对话】
{history}"""),
("user", "{message}")
])
chain = prompt | llm
result = chain.invoke({
"history": history_text,
"message": user_message
})
answer = result.content
return {
"answer": answer,
"messages": [{"role": "assistant", "content": answer}],
"conversation_history": [
{"role": "user", "content": user_message},
{"role": "assistant", "content": answer}
],
"current_step": "chitchat_completed"
}
def handle_complaint_agent(state: CustomerServiceState) -> dict:
"""处理投诉 Agent(模拟创建工单并转人工)"""
user_message = state["messages"][-1]["content"]
answer = "我已经为您创建了工单,稍后会有专人客服联系您处理。工单号:WO202501234"
return {
"answer": answer,
"messages": [{"role": "assistant", "content": answer}],
"conversation_history": [
{"role": "user", "content": user_message},
{"role": "assistant", "content": answer}
],
"need_human": True,
"current_step": "complaint_handled"
}
4.6 工作流编排(graph.py)
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteSaver
from agents import (
CustomerServiceState,
intent_classifier_agent,
knowledge_query_agent,
answer_generation_agent,
chitchat_agent,
handle_complaint_agent
)
def create_customer_service_graph():
"""创建客服系统工作流(带状态持久化)"""
# 1. 创建状态图
workflow = StateGraph(CustomerServiceState)
# 2. 添加节点
workflow.add_node("classify_intent", intent_classifier_agent)
workflow.add_node("query_knowledge", knowledge_query_agent)
workflow.add_node("generate_answer", answer_generation_agent)
workflow.add_node("chitchat", chitchat_agent)
workflow.add_node("handle_complaint", handle_complaint_agent)
# 3. 定义路由逻辑
def route_by_intent(state: CustomerServiceState) -> str:
"""根据意图路由到不同的 Agent"""
intent = state.get("intent", "unknown")
if intent == "inquiry":
return"query_knowledge"
elif intent == "complaint":
return"handle_complaint"
elif intent == "chitchat":
return"chitchat"
else:
# 未知意图,转人工
return"handle_complaint"
# 4. 设置入口点
workflow.set_entry_point("classify_intent")
# 5. 添加条件边(意图识别后的路由)
workflow.add_conditional_edges(
"classify_intent",
route_by_intent,
{
"query_knowledge": "query_knowledge",
"handle_complaint": "handle_complaint",
"chitchat": "chitchat"
}
)
# 6. 添加普通边
workflow.add_edge("query_knowledge", "generate_answer")
workflow.add_edge("generate_answer", END)
workflow.add_edge("chitchat", END)
workflow.add_edge("handle_complaint", END)
# 7. 配置状态持久化(Checkpointing)
checkpointer = SqliteSaver.from_conn_string(":memory:") # 使用内存数据库,生产环境建议用文件
# 8. 编译(带 Checkpointing)
app = workflow.compile(checkpointer=checkpointer)
return app
4.7 主程序(main.py)
import uuid
from graph import create_customer_service_graph
from agents import CustomerServiceState
def chat(app, user_input: str, session_id: str = None, history: list = None):
"""多轮对话(支持历史)"""
if session_id isNone:
session_id = str(uuid.uuid4())
# 初始化状态
initial_state: CustomerServiceState = {
"messages": [{"role": "user", "content": user_input}],
"user_id": "user_001",
"session_id": session_id,
"intent": "unknown",
"knowledge_docs": [],
"answer": "",
"conversation_history": history or [], # 传入历史对话
"need_human": False,
"current_step": ""
}
# 执行工作流(带 Checkpointing)
config = {"configurable": {"thread_id": session_id}}
result = app.invoke(initial_state, config=config)
return result
def main():
"""主函数 - 演示多轮对话"""
print("=" * 50)
print("智能客服系统 - LangGraph Demo")
print("支持多轮对话 + 状态持久化")
print("=" * 50)
# 创建工作流
app = create_customer_service_graph()
# === 测试1: 单轮对话 ===
print("\n" + "=" * 50)
print("【测试1】单轮对话测试")
print("=" * 50)
single_tests = [
"这个手表怎么充电?",
"我要投诉,手表用了一周就坏了!"
]
for i, user_input in enumerate(single_tests, 1):
print(f"\n--- 测试 {i}: {user_input} ---")
result = chat(app, user_input)
print(f"【意图】{result['intent']} | 【回复】{result['answer']}")
# === 测试2: 多轮对话 ===
print("\n" + "=" * 50)
print("【测试2】多轮对话测试(带历史上下文)")
print("=" * 50)
# 模拟一个持续对话
session_id = str(uuid.uuid4())
conversation_history = []
multi_turn_inputs = [
"你好!",
"你们这个手表支持什么运动模式?", # 上下文:之前提到手表
"续航怎么样?", # 上下文:继续问手表
"那充电呢?"# 上下文:延续话题
]
for i, user_input in enumerate(multi_turn_inputs, 1):
print(f"\n--- 第 {i} 轮对话 ---")
print(f"用户: {user_input}")
# 调用(传入历史)
result = chat(app, user_input, session_id=session_id, history=conversation_history)
# 更新历史
conversation_history = result.get("conversation_history", [])
print(f"客服: {result['answer']}")
print(f"(意图: {result['intent']})")
if __name__ == "__main__":
main()
五、运行示例
5.1 运行程序
python main.py
5.2 输出结果
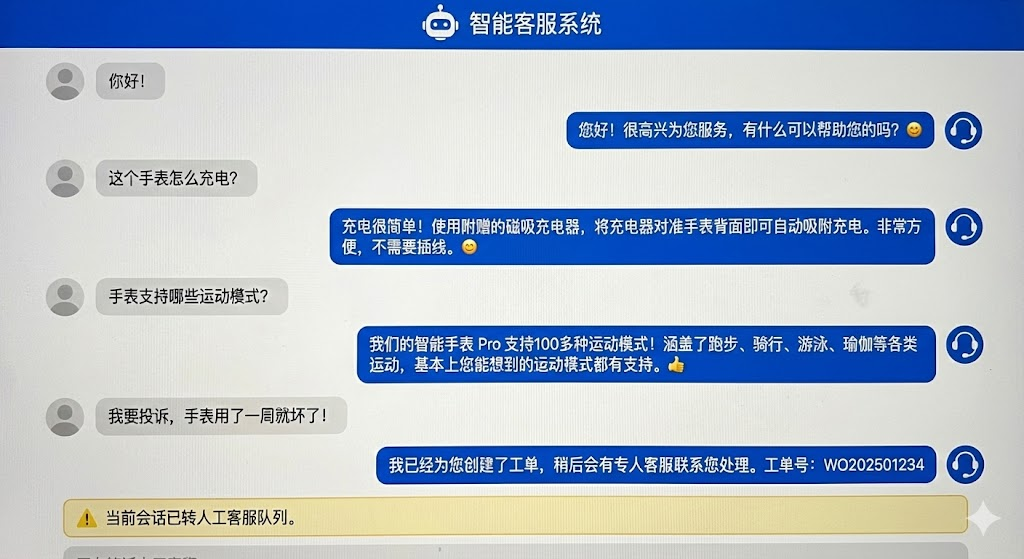
==================================================
智能客服系统 - LangGraph Demo
==================================================
==================================================
测试 1: 你好!
==================================================
【识别意图】: chitchat
【当前步骤】: chitchat_completed
【客服回复】: 您好!很高兴为您服务,有什么可以帮助您的吗?😊
==================================================
测试 2: 这个手表怎么充电?
==================================================
【识别意图】: inquiry
【当前步骤】: answer_generated
【检索文档】:
1. Q: 如何充电?
A: 使用附赠的磁吸充电器,将充电器对准手表背面即可自动吸附充电。
2. 功能特性:
- 心率监测:24小时连续心率监测
- 运动模式:支持100+种运动模式
- 电池续航:正常使用7天,重度使用3天...
3. 产品名称:智能手表 Pro
价格:2999元...
【客服回复】: 充电很简单!使用附赠的磁吸充电器,将充电器对准手表背面即可自动吸附充电。非常方便,不需要插线。😊
==================================================
测试 3: 手表支持哪些运动模式?
==================================================
【识别意图】: inquiry
【当前步骤】: answer_generated
【检索文档】:
1. 功能特性:
- 心率监测:24小时连续心率监测
- 运动模式:支持100+种运动模式...
2. 产品名称:智能手表 Pro
价格:2999元...
3. Q: 如何充电?...
【客服回复】: 我们的智能手表 Pro 支持100多种运动模式!涵盖了跑步、骑行、游泳、瑜伽等各类运动,基本上您能想到的运动模式都有支持。👍
==================================================
测试 4: 我要投诉,手表用了一周就坏了!
==================================================
【识别意图】: complaint
【当前步骤】: complaint_handled
【客服回复】: 我已经为您创建了工单,稍后会有专人客服联系您处理。工单号:WO202501234
⚠️ 已转人工客服
六、代码解析
6.1 状态传递机制
# 状态通过 Annotated[list, operator.add] 自动累加
messages: Annotated[list[dict], operator.add]
# 每个 Agent 返回的字典会自动合并到全局状态
return {
"intent": intent, # 更新 intent 字段
"current_step": "intent_classified" # 更新 current_step
}
6.2 条件路由
# 根据 intent 字段动态决定下一步
def route_by_intent(state: CustomerServiceState) -> str:
intent = state.get("intent", "unknown")
if intent == "inquiry":
return"query_knowledge"
elif intent == "complaint":
return"handle_complaint"
# ...
# 配置条件边
workflow.add_conditional_edges(
"classify_intent", # 从哪个节点出发
route_by_intent, # 路由函数
{ # 路由映射
"query_knowledge": "query_knowledge",
"handle_complaint": "handle_complaint"
}
)
6.3 RAG 流程
# 1. 文本分块
chunks = text_splitter.split_text(text)
# 2. 向量化并存储
vectorstore = Chroma.from_texts(chunks, embedding)
# 3. 检索相关文档
docs = vectorstore.similarity_search(query, k=3)
# 4. 构建提示词(文档 + 问题)
context = "\n\n".join([doc.page_content for doc in docs])
prompt = f"基于以下内容回答:\n{context}\n\n问题:{query}"
# 5. LLM 生成答案
answer = llm.invoke(prompt)
七、总结
本文通过智能客服案例,展示了 LangGraph 的核心用法:
核心功能:
-
状态管理:TypedDict + Annotated 实现自动状态传递
-
多 Agent 协作:意图识别、知识库查询、答案生成各司其职
-
条件路由:根据意图动态选择处理流程
-
RAG 集成:使用 Chroma 实现知识库检索
-
多轮对话:支持对话历史管理,Agent 能理解上下文
-
状态持久化:使用 Checkpointing 保存会话状态,支持中断恢复
待优化项:
-
添加置信度评估(检索结果相关性低时转人工)
-
添加监控和日志(Prometheus + 结构化日志)
-
优化成本控制(压缩历史、模型分级、缓存)
-
部署到生产环境(Docker + K8s + 负载均衡)

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)