
nano-vllm:千行代码实现大模型推理引擎,小白也能轻松上手!大模型实战
nano-vllm是一个极简但功能完整的大语言模型推理引擎实现,代码量仅千余行。它复现了现代推理引擎的核心机制,包括prefill/decode两阶段处理、KVCache分块管理、调度器批次装载与抢占等。项目模块边界清晰,便于阅读和修改,特别适合LLM初学者理解推理引擎的工作原理。通过nano-vllm,读者可以快速掌握"为什么需要分块KV、为什么要区分prefill/decode"等关键问题,并
简介
nano-vllm是一个极简但功能完整的大语言模型推理引擎实现,代码量仅千余行。它复现了现代推理引擎的核心机制,包括prefill/decode两阶段处理、KVCache分块管理、调度器批次装载与抢占等。项目模块边界清晰,便于阅读和修改,特别适合LLM初学者理解推理引擎的工作原理。通过nano-vllm,读者可以快速掌握"为什么需要分块KV、为什么要区分prefill/decode"等关键问题,并能将所学迁移到更完整的工程实现中。
nano-vllm 的目标是用尽量少的代码把现代推理引擎的关键路径跑通:把推理分成 prefill/decode 两阶段,KVCache 以“块”为单位管理并支持前缀复用,调度器负责批次装载与抢占,采样在主进程完成;
为降低小批量解码时的 CPU 开销,提供 CUDA Graph 捕获与回放;同时保留小规模张量并行的骨架。
整个实现控制在约千余行,模块边界清晰(调度器、BlockManager、ModelRunner、注意力层与上下文传递彼此解耦),便于阅读、修改和做实验,适合作为入门与原型的参考工程。
与 vLLM 相比,nano-vllm 并不追求“产品级完备”,而是把 vLLM 的核心思想最小化复现:页式/块式 KV 管理、前缀共享、连续批处理、解码侧的小批量优化(这里用 CUDA Graph,vLLM 则以 PagedAttention 为代表的页表寻址与高效内存布局见长),删去复杂的异步 RPC、多租户与大规模集群调度等工程细节。
对初学者而言,这种“能跑且可读”的版本有利于抓住关键抽象,理解从序列调度到注意力算子的整条执行链。
在单机、常见小批次解码场景下,nano-vllm 的吞吐与延迟可以接近同类引擎的主路径表现,足以用于教学、对比实验和快速验证思路。
与 sglang 的差异在于侧重点。sglang 更强调“LLM 程序”的表达与编排,围绕多轮对话、规划、工具调用、结构化输出等高层能力提供运行时与语法糖;底层推理路径会集成主流引擎以兼顾易用与性能。
nano-vllm 则把精力聚焦在底层执行模型:序列如何被装入批次、KV 如何分页并被注意力按页表取用、prefill 与 decode 怎样共享缓存与上下文,方便读者把“高层能力”与“底层开销”建立直接联系。
nano-vllm 的设计初衷是:以教学与原型为第一优先,尽量还原高性能推理引擎的关键机制,但保持代码极简、边界清楚、路径可追;
让读者在几百到一千多行代码内看懂“为什么需要分块 KV、为什么要区分 prefill/decode、为什么调度要抢占、为什么小批量要用图回放”,并能据此快速做二次实验或把思路迁移到更完整的工程实现上。
一、代码结构
如下:
- 引擎层
- engine/llm_engine.py:高层引擎封装(对外 API、调度/模型协作)
- engine/scheduler.py:序列调度(排队、批次构建、抢占)
- engine/model_runner.py:模型执行(多进程/多卡、KV 缓存、CUDA graph、采样)
- engine/block_manager.py:KVCache block 管理(分配/复用/回收)
- engine/sequence.py:序列状态对象
- 模型与层
- models/qwen3.py:Qwen3 模型定义与 LM 封装
- layers/*:注意力、线性、嵌入/头、RMSNorm、采样器等
- 配置与工具
- config.py:运行配置
- sampling_params.py:采样参数
- utils/context.py:前向上下文(prefill/decode 必要张量)
- utils/loader.py:safetensors 权重加载(含打包映射)
- 对外入口
- llm.py:简化外部接口(继承 LLMEngine)
- example.py:最小示例
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、背景知识
如下:
- 生成两阶段
- Prefill:一次性计算整段 prompt;构建并写入 KVCache 前缀。
- Decode:逐 token 迭代生成;读取/增量写入 KVCache。
- KVCache 与分块(block)
- 将 KV 缓存按固定大小划分为 block(例如 256 tokens/block),便于管理与复用。
- 前缀共享:相同内容的完整块可跨序列复用(通过哈希判等),节省显存与计算。
- 调度问题
- 同步批:prefill 阶段按 token 总量与序列数装批;decode 阶段按序列数装批。
- 资源约束:KVCache block 不足时需要“抢占”(preempt)并回收块。
- CUDA Graph
- 对 decode 小 batch 重复图捕获与复用,显著降低内核启动/调度开销。
- 张量并行(简述)
- 将 attention/MLP 的大线性层按维度切分到多卡,合并时使用通信(本项目演示级)。
三、推理引擎 LLM Engine
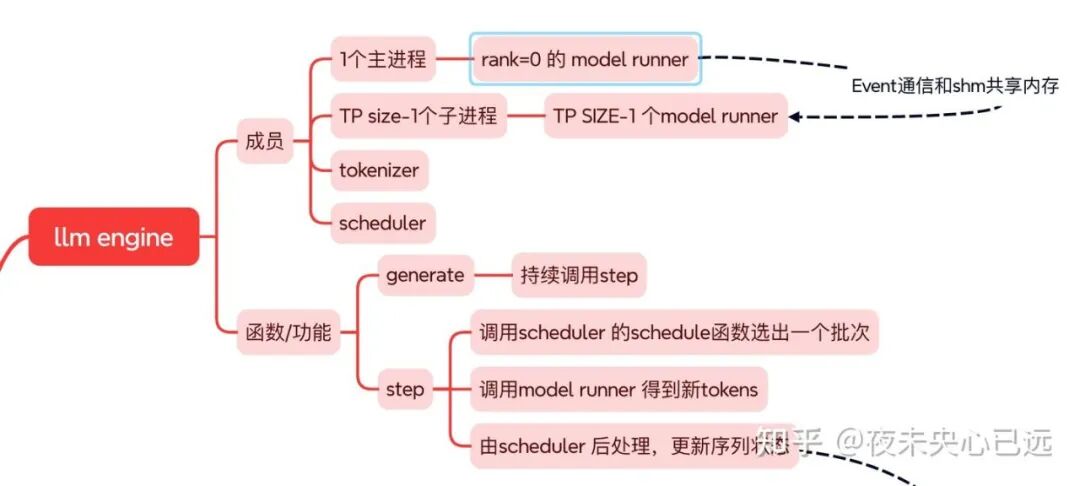
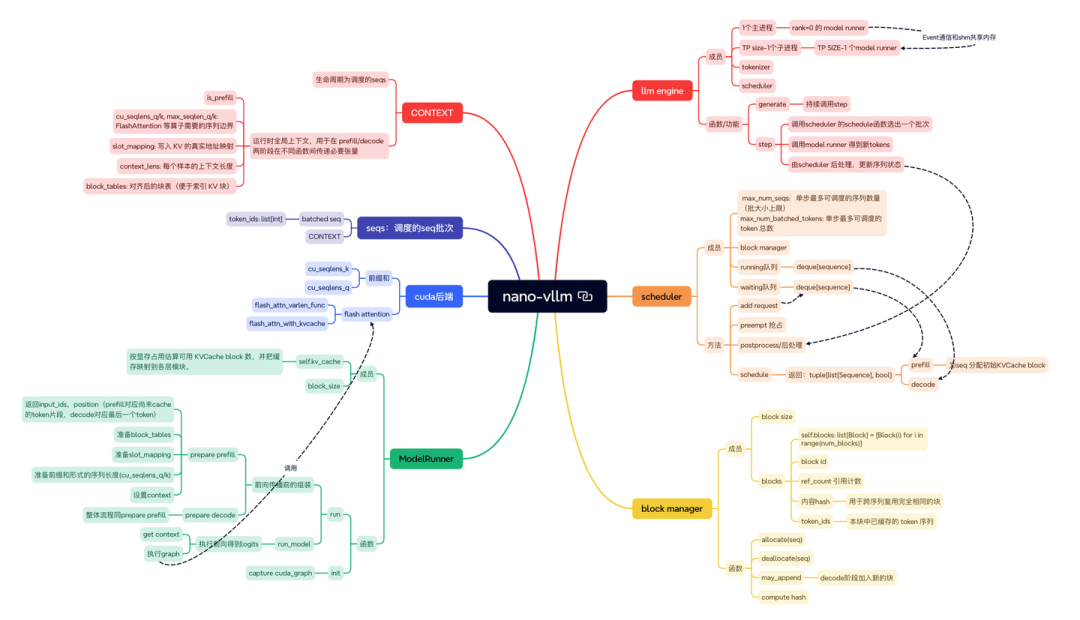
LLM Engine 由一个主进程和 TP size−1 个子进程组成:主进程内创建 rank=0 的 ModelRunner、Tokenizer 与 Scheduler,子进程各自运行一个 ModelRunner,通过 Event 同步与共享内存传递指令;
初始化时 ModelRunner 负责加载权重、预分配 KV Cache、可选捕获多套 CUDA Graph(小批量解码复用),Scheduler 内部用 BlockManager 统一分配逻辑块映射到物理页。
对外 generate 会持续调用 step:step 先让 Scheduler.schedule 选出一个批次(prefill 或 decode),再调用主进程的 ModelRunner.run(多卡时广播到各 rank 同步执行)得到新 tokens,随后 Scheduler.postprocess 追加 token、判断结束并回收块。
每次前向前,ModelRunner 用上下文 context 设置本轮的 slot_mapping、block_table、长度等临时张量,前向结束立即重置;
多个 ModelRunner 各自维护独立 context,但共享同一批序列的块表以保证寻址一致。
整体上,LLM Engine 负责任务编排与进程间协同,Scheduler 负责批次选择与内存块生命周期,ModelRunner 专注一次前向与采样。
用户/上层
配置与采样:
config.py/Config- 重要字段:
max_num_batched_tokens,max_num_seqs,max_model_len,gpu_memory_utilization,tensor_parallel_size,enforce_eager,kvcache_block_size __post_init__回填/约束:HF 模型 config、最大长度等sampling_params.py/SamplingParamstemperature,``max_tokens,ignore_eos(温度过小禁用纯贪心)
四、调度器(Scheduler)
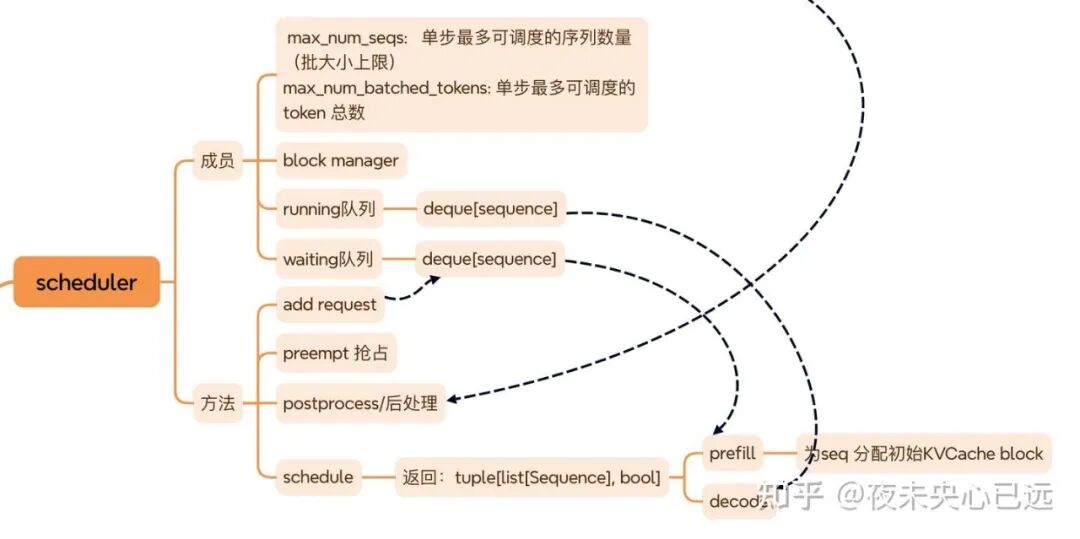
Scheduler 是一个批次调度与资源编排器,内部维护批大小上限与单步可调度 token 总量,并持有唯一的 BlockManager 管理 KV 块,同时用两个队列管理序列状态:waiting 存放待运行序列、running 存放正在解码序列;
外部通过 add 将新序列入 waiting,schedule 每次产出一个批次并指示是 prefill 还是 decode:prefill 分支在不超出 token 与内存上限的前提下,从 waiting 取序列并调用 BlockManager 分配首批 KV 块后转入 running;
若没有可 prefill 的,就进入 decode,从 running 取序列逐 token 推进,必要时根据 KV 空间触发 preempt 抢占其他序列以回收块;
每步计算后由 postprocess 追加新 token、检测结束并回收资源,完成的序列从 running 移除;整体保证批量高效和 KV 资源有序复用与回收。
核心数据结构:
waiting: deque[Sequence]等待队列(prefill 前或抢占后回退于此)running: deque[Sequence]运行队列(decode 中)
调度流程(简化伪代码):
while waiting 非空 且 num_seqs < max_num_seqs:
如上:
- 仅统计“未缓存”的 token 到 num_batched_tokens
- prefill 优先于 decode,只要能装就先装
- decode 按“序列个数”控批(不看 token 上限)
- 资源不足时触发“尾部优先”抢占;极端情况下抢占自身
调度流程图如下:
1. 新请求
抢占(preempt):
preempt(seq):
后处理(postprocess):
对 (seq, new_token) 逐一:
五、KV Block 管理(BlockManager)
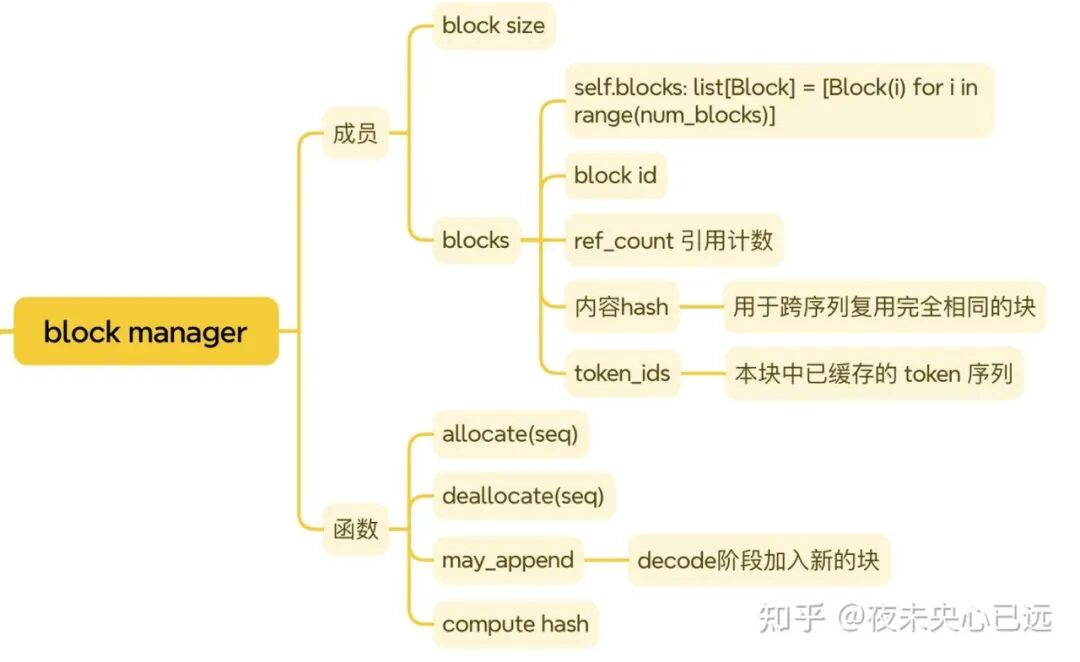
BlockManager 是 KVCache 逻辑块/物理页号的分配与复用管家:以固定的 block_size 和一组 Block 实例构成池子。
每个 Block 记录 block_id、ref_count、内容 hash 与 token_ids,并维护 hash_to_block_id(做前缀命中复用)、free_block_ids 与 used_block_ids。
核心流程是 compute_hash 计算滚动哈希,allocate(seq) 在 prefill 中按块遍历:命中则提升 ref 并累计 num_cached_tokens,未命中则从空闲池取块写入并把 block_id 追加到 seq.block_table;
deallocate(seq) 逐块 ref–,为零即回收;may_append(seq) 在 decode 中在“新块首位置”分配新块、块满时回填哈希;can_allocate/can_append 用于资源可用性判断。
它只管理块与索引,不直接操作物理张量;物理 KV 缓存由 ModelRunner 预分配,注意力通过 block_id/slot_mapping 进行读写。
核心原理(prefill 分配与复用、decode 追加):
allocate(seq):
KV 复用的关键在于“完整块”的哈希命中;decode 过程中当块写满再封口并登记哈希,供后续命中共享(前缀缓存)。
六、模型执行(ModelRunner)
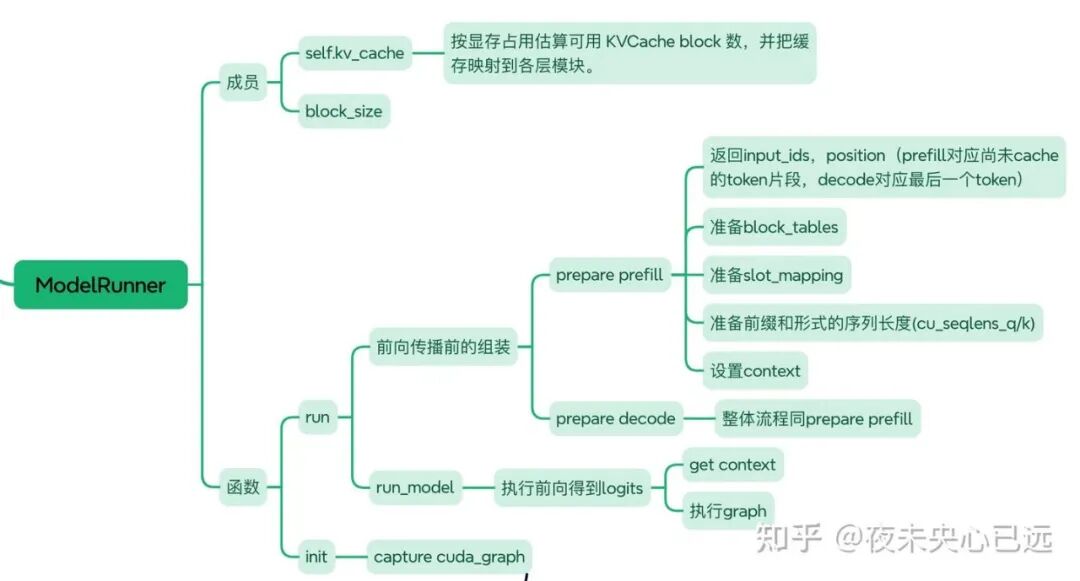
BlockManager 管一池固定大小的 KV 逻辑块,用 block_size 切分序列,池内每个 Block 记录 block_id、ref_count、内容 hash 与 token_ids,并配套 hash_to_block_id(做前缀命中复用)、free_block_ids/used_block_ids(空闲与占用集合)。
prefill 时 allocate(seq) 逐块计算滚动 hash,命中则提升 ref 并累计已缓存长度,未命中就从空闲池取块、写入内容并把 block_id 追加到 seq.block_table;
decode 时 may_append(seq) 在新块首位置分配新块,块写满再回填 hash 供后续复用;deallocate(seq) 逐块 ref–,归零即回收;
can_allocate/can_append 用于资源可用性判断。
它只负责“逻辑块到物理页号”的分配与复用,不直接操作显存,注意力侧通过 seq.block_table/slot_mapping 用这些页号去读写模型里已预分配的 KV 缓存。
多进程/多卡:
rank 0 (主进程):
KVCache 预估与映射:
allocate_kv_cache():
遍历模型模块,将拥有 k_cache/v_cache 的模块映射到该张量切片。
输入准备与 CUDA Graph:
prepare_prefill(seqs):
采样(layers/sampler.py):
按温度缩放 logits,使用 Gumbel-Softmax 近似的“加噪后取 argmax”策略(高性能、可并行)。
七、后端执行(cuda 算子)
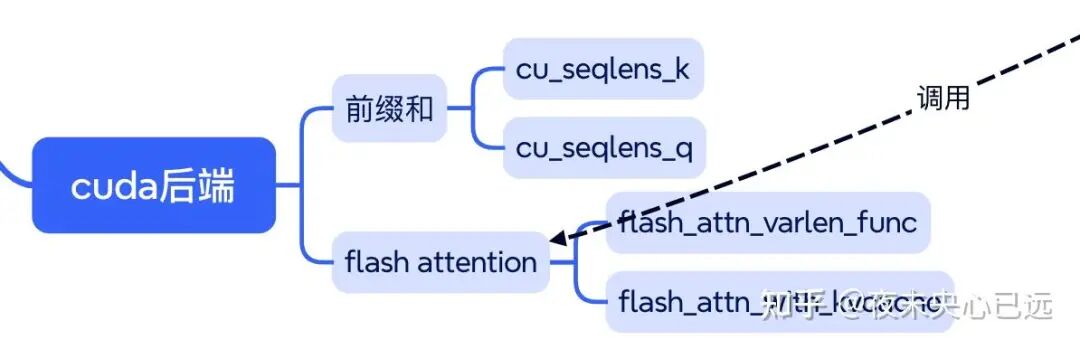
CUDA 后端的骨干是“先把本步所需的索引与边界张量准备好,再用 FlashAttention 完成注意力”的两段式流水:
prefill 时 ModelRunner.prepare_prefill 生成不等长序列的前缀和边界(cu_seqlens_q/k、max_seqlen_q/k),并结合 block_table 计算每个新写入 token 在 KVCache 中的物理槽位 slot_mapping;
decode 时 prepare_decode生成每条序列当前长度 context_lens和最后一个 token 的槽位,同样携带 block_table。
这些临时张量通过 set_context注入到本进程的全局 context,进入注意力算子后先用一个轻量的内核把本步 K/V 按 slot_mapping落到预分配的缓存上。
然后根据阶段选择两种 FlashAttention:prefill 用变长接口flash_attn_varlen_func(吃 cu_seqlens_q/k);
decode 用 flash_attn_with_kvcache(吃 context_lens与页表 block_table),从而在“页”级别完成历史 K/V 的快速访问。
prefill 形如 flash_attn_varlen_func(q, k_cache, v_cache, max_seqlen_q, cu_seqlens_q, max_seqlen_k, cu_seqlens_k, softmax_scale, causal=True, block_table=bt);
decode 形如 flash_attn_with_kvcache(q_last.unsqueeze(1), k_cache, v_cache, cache_seqlens=context_lens, block_table=bt, softmax_scale=...)
关键调用在注意力前向里集中呈现,写缓存与算子调用如下所示:
defforward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
CUDA 后端把“边界/映射的准备”和“FlashAttention 计算”解耦,靠 cu_seqlens_* 与 block_table/slot_mapping 把不等长与页式 KV 访问拼起来,prefill 与 decode 只换输入接口而共享同一套缓存与算子路径。
八、序列与上下文
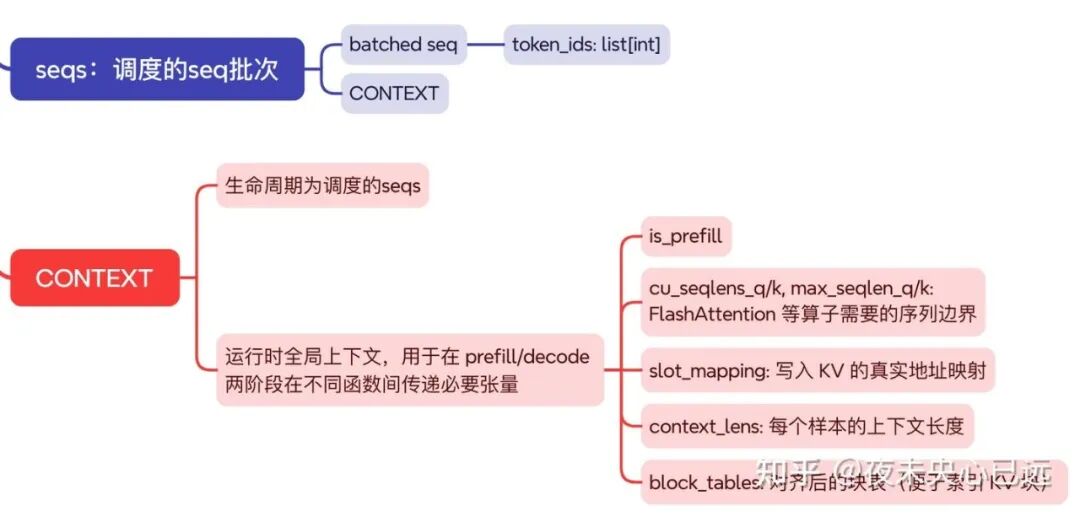
在一次调度中,调度器选出一批 seqs(每个 Sequence保存各自的 token_ids、长度与 block_table等元数据)交给模型执行;
为让 CUDA 侧算子高效工作,ModelRunner在本步前向前构造“上下文”Context,它是进程内、单步生存的全局载体,集中放入本批序列所需的临时张量:是否处在 is_prefill阶段;
不等长注意力所需的 cu_seqlens_q/k与 max_seqlen_q/k;把新写入 KV 的真实物理地址映射成一维索引的 slot_mapping;
每条样本当前上下文长度 context_lens;以及把各序列页式 KV 块对齐后的 block_tables。
prefill 时重点用 cu_seqlens_*与 slot_mapping写入并计算未缓存片段,decode 时用 context_lens、block_tables和最后一 token 的槽位做增量计算;
前向结束立即清空 Context,而 Sequence的状态(如新增 token、更新的 block_table)被长期保留,供下一轮调度继续衔接。
九、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 15
15 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)