
ICML2025|视觉+文本+时间三buff加持!看看多模态怎么赋能时间序列!
来自ICML2025最新前沿时序技术~一个用于增强时间序列预测的多模态视觉语言模型-Time-VLM。
本篇论文来自ICML2025最新前沿时序技术~作者提供了一个用于增强时间序列预测的多模态视觉语言模型-Time-VLM。
最新ICML2025全部63篇时序相关论文小时已经整理好了,关注工中浩“时序大模型”发送"资料"扫码回复“ICML2025时序合集”即可自取哦~
文章信息
论文名称:Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting
论文作者:Siru Zhong, Weilin Ruan, Ming Jin, Huan Li, Qingsong Wen, Yuxuan Liang

研究背景
时间序列预测在金融、气候、能源等多个领域至关重要,但传统模型在捕捉复杂非线性模式、跨域泛化以及数据稀缺场景(如少样本和零样本)中表现不佳。
现有文本增强模型存在模态间隙和时间模式捕捉不足的问题,视觉增强模型则缺乏语义可解释性。为解决这些问题,论文提出 Time-VLM,通过预训练视觉 - 语言模型,融合时间、视觉和文本模态,实现更优预测。
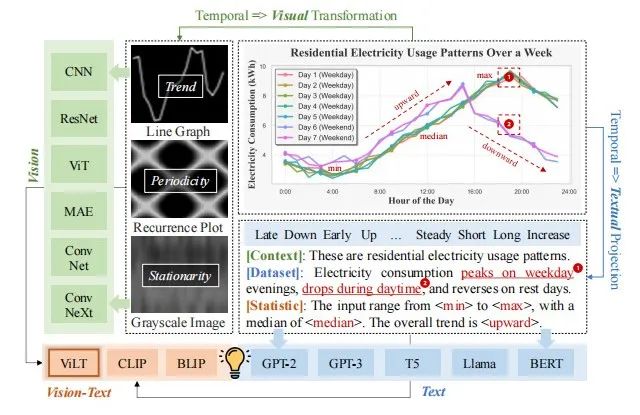
模型框架
Time-VLM是协同预训练VLMs生成多模态嵌入,再与时间特征融合用于最终预测,包含了三个关键组件:
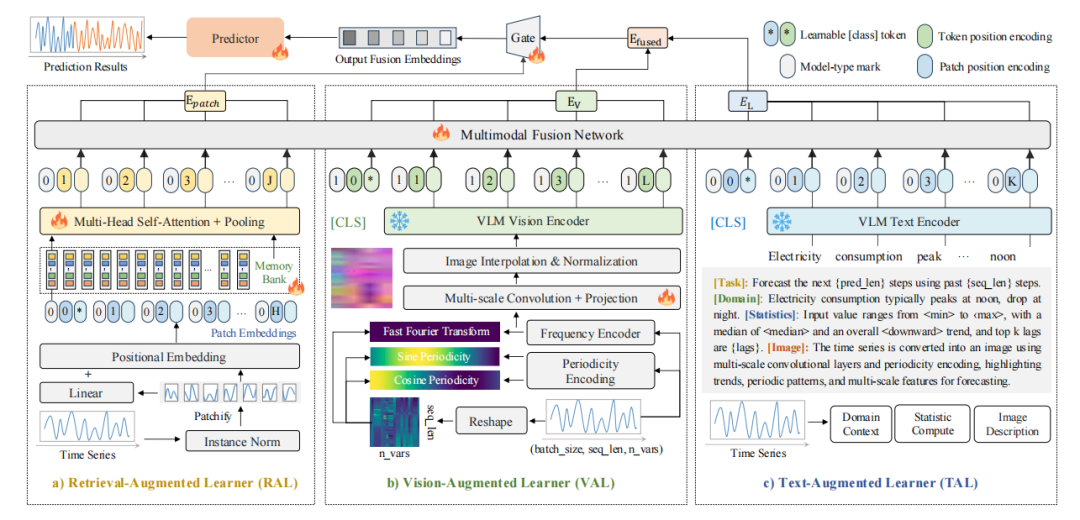
检索增强学习器(RAL):
-
通过基于补丁的特征提取和记忆库交互提取时间特征。
-
将输入时间序列分成重叠补丁,经线性投影和位置嵌入得到补丁嵌入。
-
利用局部记忆(基于余弦相似度检索相似历史补丁)和全局记忆(通过多头自注意力获取上下文表示),并通过门控机制融合,增强长短期依赖建模。
视觉增强学习器(VAL):
-
将时间序列转换为含信息的三通道图像,经冻结的 VLM 视觉编码器提取视觉特征。
-
先进行频率编码(快速傅里叶变换)和周期性编码(正弦余弦函数),再通过多尺度卷积提取层次时间模式,最后经图像插值和归一化处理,确保与 VLM 输入分布对齐。
文本增强学习器(TAL):
-
生成上下文文本提示,包括统计特征(如均值、趋势)、领域上下文和图像描述,经冻结的 VLM 文本编码器生成文本嵌入。
-
支持动态生成和预定义文本描述结合,增强上下文理解,适应不同场景。
作者也进行了多模态的融合与优化:
多模态融合:提取图像和文本的多模态嵌入后,将时间记忆嵌入和多模态嵌入投影到共享空间。 采用跨模态多头注意力机制对齐和整合特征,通过门控融合机制动态加权,最后经微调的预测器生成预测结果。
优化:使用均方误差作为损失函数端到端训练,冻结预训练 VLM,仅优化轻量级组件(如 RAL 的补丁嵌入、VAL 的编码层、预测头)。
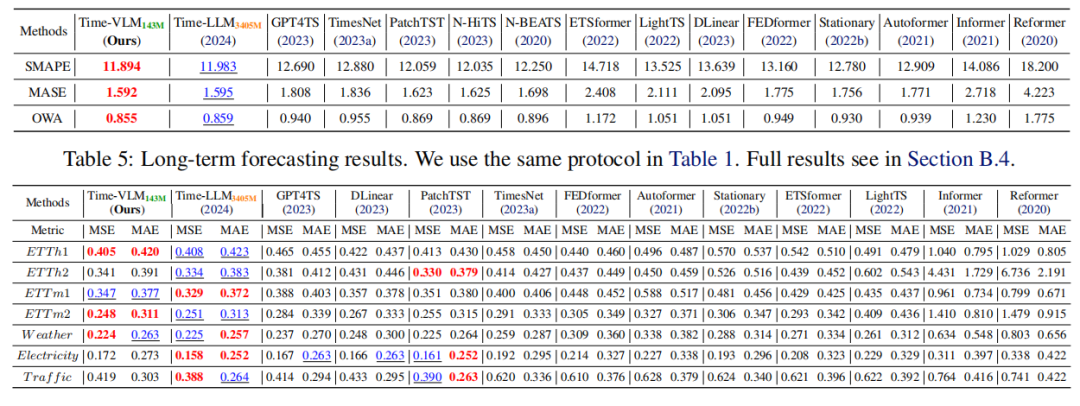
实验数据
数据集与基线:在 7 个时间序列数据集(如 ETT、Weather、Electricity 等)上评估,对比文本增强、视觉增强、传统深度学习等多类基线模型。
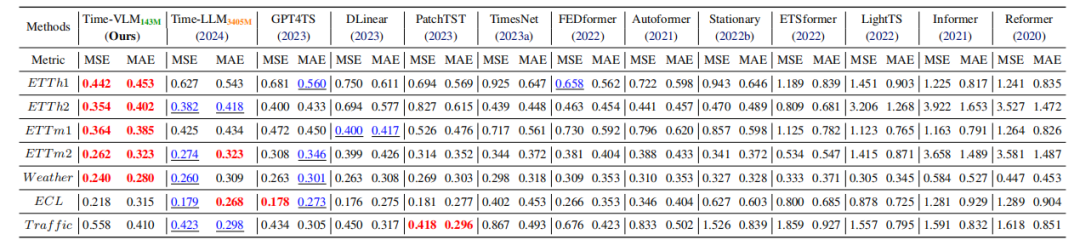
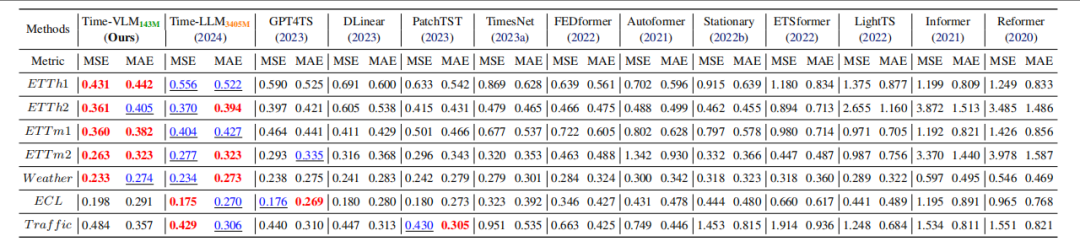
重点实验结果:
-
少样本场景:使用 5% 或 10% 训练数据时,Time-VLM 显著优于基线,如在 ETTh1 的 5% 数据上,MSE 较 Time-LLM 降低 29.5%。
-
零样本场景:跨域预测中表现出色,如 ETTh1→ETTh2 任务,MSE 较 Time-LLM 低 4.2%。
-
短 / 长期预测:在 M4 基准的短期预测中,SMAPE、MASE、OWA 指标优于基线;长期预测中,在多数数据集上表现竞争力。
-
效率:仅 143M 参数(约为 Time-LLM 的 1/20),内存使用和推理速度更优。
小小总结
论文首次提出融合时间、视觉、文本模态的框架,利用其互补性增强预测。 设计了检索增强、视觉增强和文本增强学习器,实现与 VLMs 的无缝集成。 在少样本、零样本等场景表现优异,为多模态时间序列预测开辟新方向。
小时收集整理好了全部63篇ICML2025时序论文合集方便大家学习,关注工中浩“时序大模型”发送"资料"扫码回复“ICML2025时序合集”即可自取哦~,回复“时序论文合集”也可以获取其他前沿时序论文~

关注小时,持续学习前沿时序技术!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)