
多模态融合顶会新成果!CVPR/AAAI /ICLR高分成果,这波思路必须学!
从CVPR、ICLR到AAAI,2025年顶会趋势显示,多模态融合领域正迎来新一轮技术突破。架构创新成为核心驱动力——神经架构搜索正在重新定义融合路径的自动化设计,模块化架构显著提升模型灵活性,状态空间模型则为序列建模带来全新范式,共同推动基础架构向更高效、更强大的方向演进。
更多 原文👉这里:多模态融合顶会新成果!CVPR/AAAI 高分成果,这波思路必须学!
https://mp.weixin.qq.com/s/0VX4lMS_MqOH-QL9dCjxvg
从CVPR、ICLR到AAAI,2025年顶会趋势显示,多模态融合领域正迎来新一轮技术突破。架构创新成为核心驱动力——神经架构搜索正在重新定义融合路径的自动化设计,模块化架构显著提升模型灵活性,状态空间模型则为序列建模带来全新范式,共同推动基础架构向更高效、更强大的方向演进。
在当前技术演进中,“高效轻量”已成为刚需。参数高效微调、低秩适配等方法被广泛采用,致力于在控制计算成本的同时最大化模型性能。研究重点也从基础方法探索转向具体难题攻坚,学界正在深入解决模态缺失、数据对齐、跨域迁移等实际部署中的关键挑战。
边缘设备适配、动态融合策略、轻量化架构设计等方向,正成为具有差异化竞争力的创新切入点。
我整理了20篇【多模态融合】前沿成果+部分相关代码,包含CVPR、ICLR、AAAI等顶会,以及
等热门领域,以下为部分:
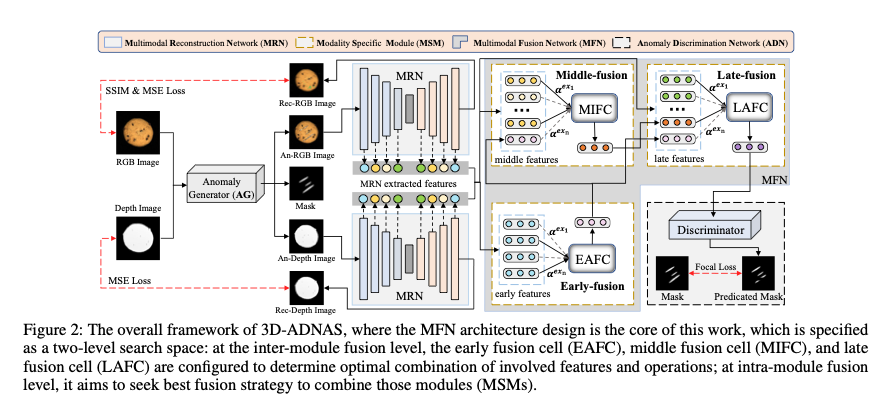
1. Revisiting Multimodal Fusion for 3D Anomaly Detection from an Architectural Perspective
-
中文标题: 从架构视角重新审视3D异常检测中的多模态融合
-
发表期刊/会议: AAAI 2025
-
论文简介: 本文从架构设计的角度系统性地重新审视了3D异常检测中的多模态融合问题。作者指出,手动设计的融合策略往往不是最优的。为此,他们提出了一个名为3D-ADNAS的神经架构搜索框架,该框架能够同步自动搜索最优的模态融合策略与模态专用的处理模块。实验表明,该框架在检测准确率、帧率和内存使用效率方面均实现了显著提升。
-
创新点: 针对手动设计融合策略的局限性,本文核心创新在于提出了3D-ADNAS框架,将模态融合策略的搜索与模态专用编码器的搜索统一在一个协同优化的过程中。该框架通过自动化的架构搜索,发现了超越人工设计范式的融合模式,从而在整体系统性能与效率上实现突破。
-
研究方法: 研究方法核心为神经架构搜索(NAS)。框架设计了一个包含多种候选操作的统一搜索空间,涵盖不同模态的编码器选项和融合策略(如相加、拼接、注意力等)。通过可微分架构搜索技术,联合优化架构参数与模型权重,以任务损失为引导,自动为3D异常检测任务发现最优的多模态处理与融合架构。
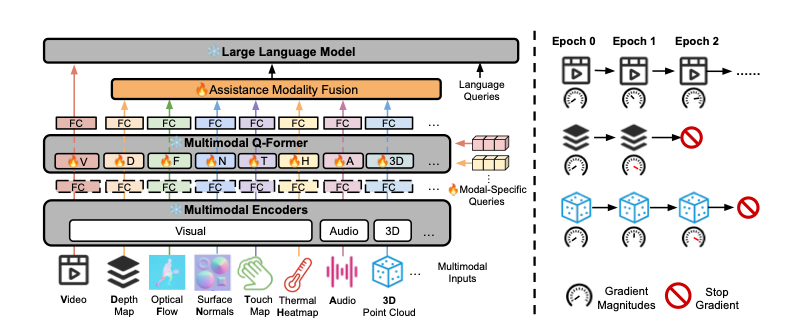
2. Generalizable and Efficient Video-Language Reasoning via Multimodal Modular Fusion
-
中文标题: 通过多模态模块化融合实现可泛化且高效的视频-语言推理
-
发表期刊/会议: ICLR 2025
-
论文简介: 为了应对视频-语言推理任务中模型庞大、计算成本高的问题,本文提出了CREMA框架。该框架采用参数高效的模块化设计和渐进式多模态融合机制,允许模型灵活支持多种模态输入的同时,大幅减少了可训练参数的数量。在7个不同的视频-语言推理任务上的实验表明,CREMA在减少90%以上参数的情况下,性能仍优于主流的多模态大模型,展现了出色的泛化能力和效率。
-
创新点: 主要创新点是提出了参数高效的模块化融合框架CREMA。其核心在于两点:一是引入了可组合的模块化设计,将功能解耦为共享模块和模态专用模块,支持灵活的任务与模态扩展;二是采用了渐进式融合机制,通过门控网络控制信息流,实现从浅层到深层的有效信息整合,显著提升了参数利用率和泛化性。
-
研究方法: 该方法基于模块化网络和参数高效微调(PEFT)思想。框架由一组可重用的模块构成,通过一个轻量级的路由网络动态组合这些模块来处理不同的(视频,语言)任务对。融合过程是渐进的,在网络的多个层逐步集成跨模态信息,从而在保持高性能的同时,仅需训练极少量参数。
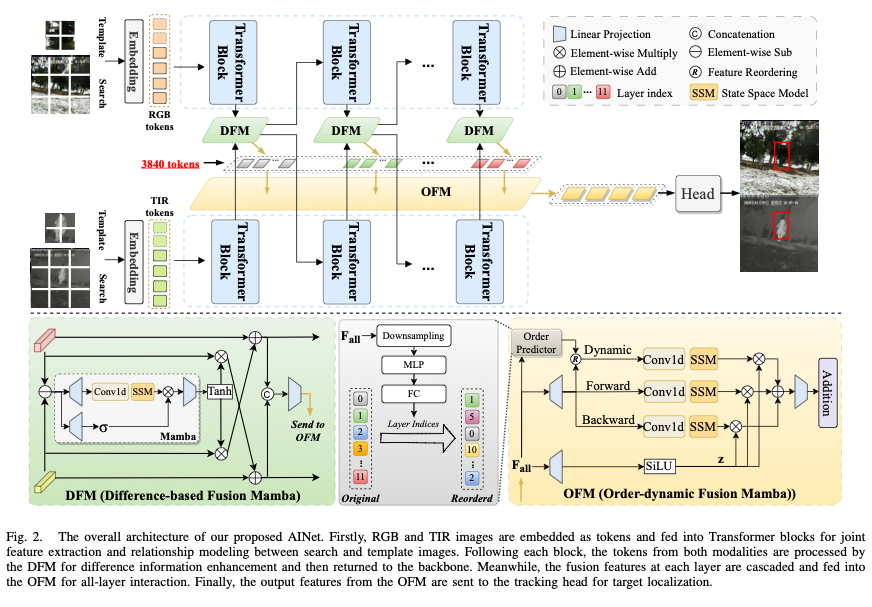
3. RGBT Tracking via All-layer Multimodal Interactions with Progressive Fusion Mamba
-
中文标题: 通过具有渐进融合Mamba的全层多模态交互实现RGBT跟踪
-
发表期刊/会议: AAAI 2025
-
论文简介: 该论文将新兴的Mamba架构引入到RGB-热红外(RGBT)跟踪领域。作者设计了差异融合Mamba(DFM)和顺序动态融合Mamba(SDFM)模块,实现了从浅层到深层的全层级模态交互。这种方法能够有效平衡计算效率与特征融合质量,在RGBT跟踪任务中取得了领先的性能,展示了Mamba结构在多模态视觉任务中的潜力。
-
创新点: 创新点在于将状态空间模型(Mamba)系统性地引入RGBT跟踪,并设计了全层渐进式融合机制。具体而言,提出了两种核心模块:差异融合Mamba(DFM)用于捕捉模态间互补信息,顺序动态融合Mamba(SDFM)用于建模跨模态依赖的动态演化,实现了更高效和精准的模态交互。
-
研究方法: 该方法基于状态空间模型(SSM),特别是Mamba架构。 backbone网络提取RGB和热红外模态的特征后,通过在不同网络层级插入DFM和SDFM模块,实现从低层到高层的渐进式特征融合。Mamba的选择性状态空间机制能够有效建模长距离依赖,并保持线性计算复杂度,兼顾了融合性能与效率。
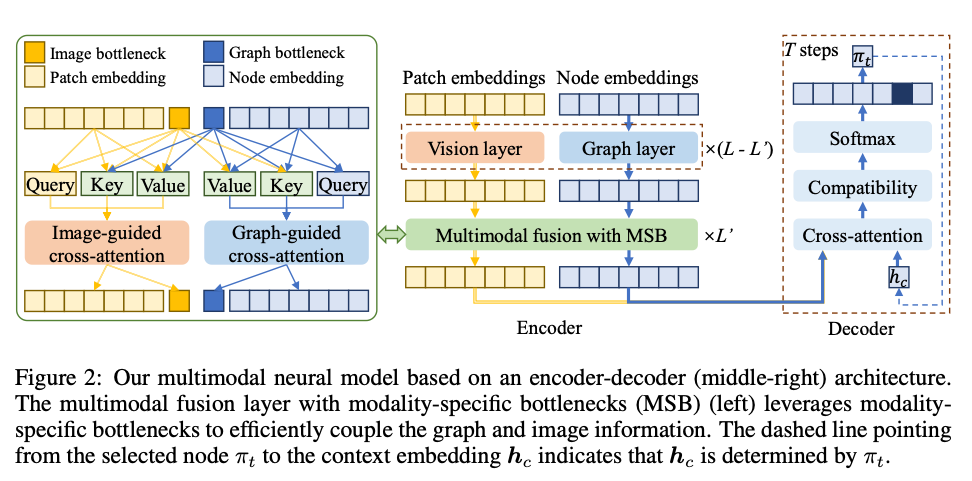
4. Neural Multi-Objective Combinatorial Optimization via Graph-Image Multimodal Fusion
-
中文标题: 通过图-图像多模态融合实现神经多目标组合优化
-
发表期刊/会议: ICLR 2025
-
论文简介: 该研究将多模态融合思想引入神经组合优化领域。作者提出图-图像多模态融合框架GIMF,将组合优化问题的图结构表示与一种新颖的坐标图像表示相结合。通过模态特定的瓶颈机制对两种表示进行过滤和融合,GIMF能够更有效地捕捉问题的复杂结构和目标间的权衡,从而在多个多目标组合优化问题上提升了神经求解器的性能。
-
创新点: 核心创新在于将多目标组合优化问题重新构建为一个图-图像多模态融合任务。为此,提出了坐标图像这一新颖的问题表示方法,将图结构信息编码为图像格式;并设计了模态特定瓶颈模块,用于过滤各模态中的噪声信息,从而在融合前实现更纯净和互补的特征表达。
-
研究方法: 该方法结合了图神经网络(GNN)和卷积神经网络(CNN)。GNN处理问题的原生图结构,CNN处理由节点坐标生成的图像表示。两个模态的特征分别经过一个瓶颈适配层进行提炼,然后通过一个融合模块进行交互,最终由一个共享的解码器输出帕累托最优解的近似。
5. Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
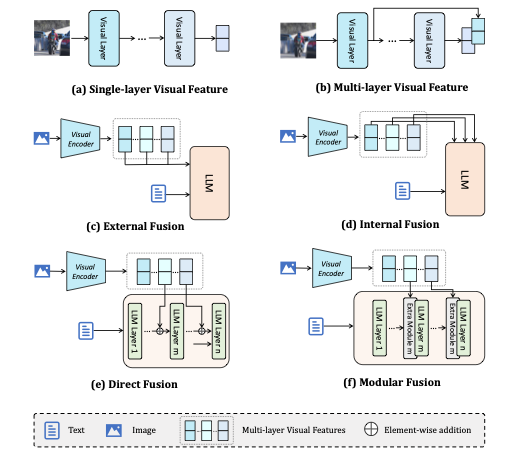
-
中文标题: 多模态大模型中的多层视觉特征融合:方法、分析与最佳实践
-
发表期刊/会议: CVPR 2025
-
论文简介: 如何将视觉特征有效地融入大型语言模型是多模态大模型研究的核心问题。本文对多层视觉特征融合策略进行了系统性的实证研究。研究分析了不同融合阶段(早期、中期、晚期)和融合方法(如连接、交叉注意力)的效果,并总结出最佳实践。结果表明,结合多阶段的视觉特征,并与文本输入在早期进行直接融合,能最有效地提升多模态大模型的视觉推理和泛化能力。
-
创新点: 本文的主要创新点并非提出一种新模型,而是对多模态大模型中的多层视觉特征融合策略进行了首次大规模、系统性的实证分析与评估。通过严谨的对照实验,总结出了关键的融合最佳实践,例如结合多层级视觉特征以及在输入层或浅层进行直接的跨模态交互,为后续模型设计提供了明确指导。
-
研究方法: 采用控制变量法的实证研究。在统一的基准模型(如LLaVA架构变体)上,系统性地改变视觉特征的提取层级(从CNN浅层到ViT深层)、融合的网络阶段(早期、中期、晚期)以及融合器的类型(如MLP、注意力),并在一系列视觉语言理解基准上评估其性能,从而得出有统计意义的结论。
原文、更多 这里 👉 多模态融合顶会新成果!CVPR/AAAI 高分成果,这波思路必须学!![]() https://mp.weixin.qq.com/s/0VX4lMS_MqOH-QL9dCjxvg
https://mp.weixin.qq.com/s/0VX4lMS_MqOH-QL9dCjxvg
7. SSLFusion: Scale and Space Aligned Latent Fusion Model for Multimodal 3D Object Detection
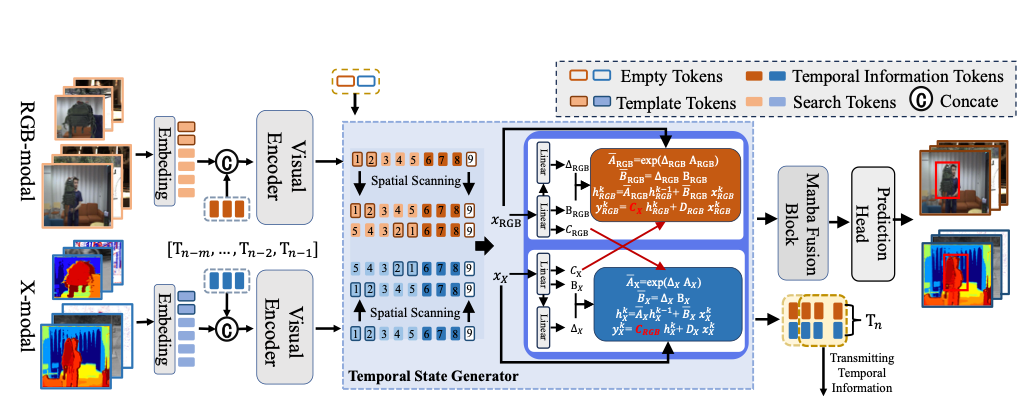
-
中文标题: SSLFusion:面向多模态3D目标检测的尺度与空间对齐潜在融合模型
-
发表期刊/会议: AAAI 2025
-
论文简介: 在融合LiDAR点云和相机图像进行3D检测时,特征图的尺度不匹配和空间未对齐会严重影响性能。SSLFusion通过尺度对齐融合(SAF)策略在潜在空间统一多尺度特征,并利用3D-2D空间对齐(SSA)模块精确校准两种模态的几何对应关系。在nuScenes和KITTI数据集上的实验表明,该方法实现了3D平均精度超过2%的绝对提升,证明了其有效性。
-
创新点: 创新点在于明确识别并解决了多模态3D检测中的两个关键对齐问题:尺度不匹配与空间未对齐。为此,提出了尺度对齐融合(SAF)模块,通过特征金字塔和自适应选择机制统一特征尺度;以及空间对齐(SSA)模块,利用相机几何先验显式地建立3D点云与2D像素之间的精确对应关系。
-
研究方法: 该方法是一个基于LiDAR-Camera融合的3D目标检测器。其核心是两个专用模块:SAF模块处理来自LiDAR和图像Backbone的多尺度特征,通过上采样、池化和门控选择实现尺度自适应融合;SSA模块则利用投影关系,将3D体素特征与对应的2D图像特征在潜在空间进行几何上的精确融合,最后使用检测头输出3D边界框。
往期推荐
杀疯了!2025 最新Agent Memory顶会论文,拿捏发文密码!
ICCV 2025|FrDiff:频域魔法+扩散模型暴力去雾,无监督性能刷爆榜单!
NeurIPS 2025 | 港科大&上交大HoloV:多模态大模型“瘦身”新突破,剪枝88.9%视觉Token,性能几乎无损

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)