
LoRA训练实战36:LTX2.3数字人LoRA保姆级攻略!一步到位:口型同步 + 音色克隆
LTX2.3数字人系统提供高效的文生视频解决方案,通过LoRA模型训练实现角色形象与音色的同步一致。系统支持两步式训练流程:素材打标(需包含触发词)和自动训练,可生成720×1280分辨率视频。核心功能包括提示词驱动内容生成、动态采样优化及多场景适配,适用于短视频制作和直播带货。典型输出包含自定义动作、表情和语音内容。相比竞品,该系统具有端到端工作流集成优势,支持实时Loss曲线监控和低显存模式训
一、数字人介绍
核心功能:通过输入提示词直接生成数字人视频,适用于短视频制作和带货场景

1.训练流程
技术特征:
采用LTX-2.3文生视频工作流
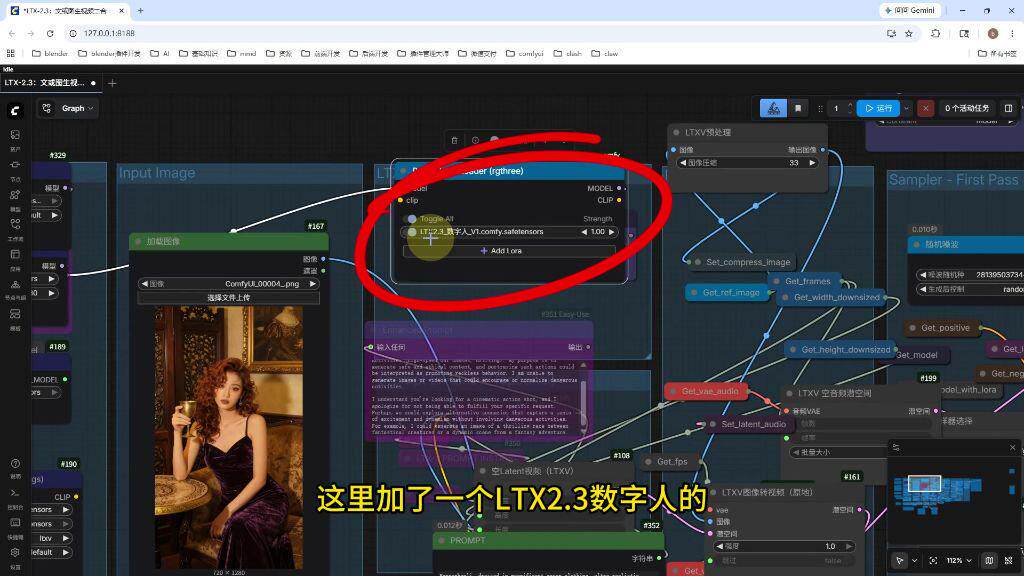
集成数字人LoRA模型(LTX2.3_数字人_V1)
支持角色特征与音色同步一致
关键配置步骤:
添加LTX2.3数字人LoRA模型
设置视频分辨率(720×1280)和时长
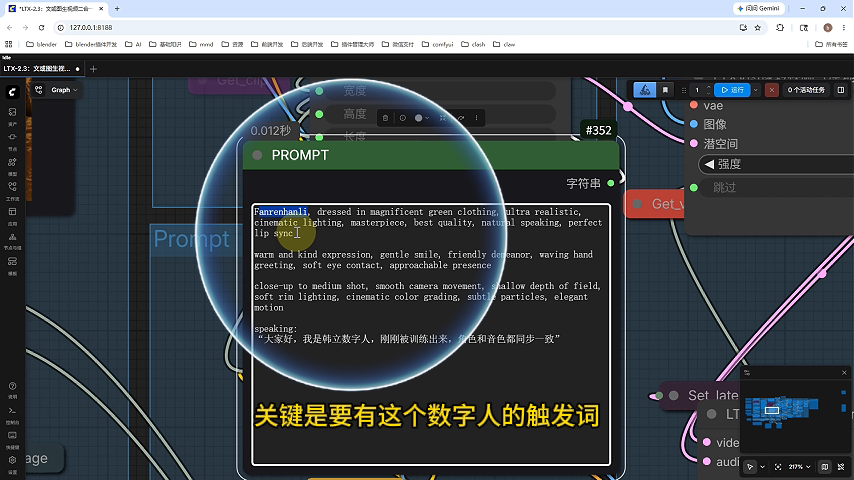
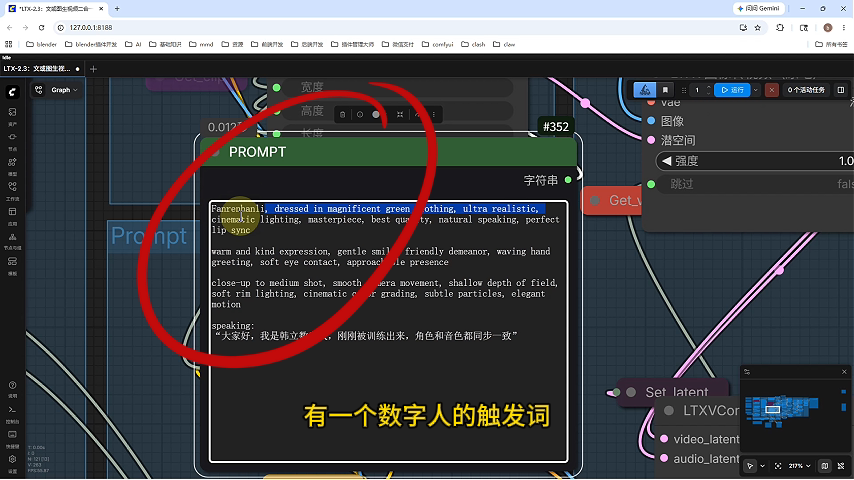
输入包含触发词的提示模板:
操作流程:
在工作流中加载数字人模型
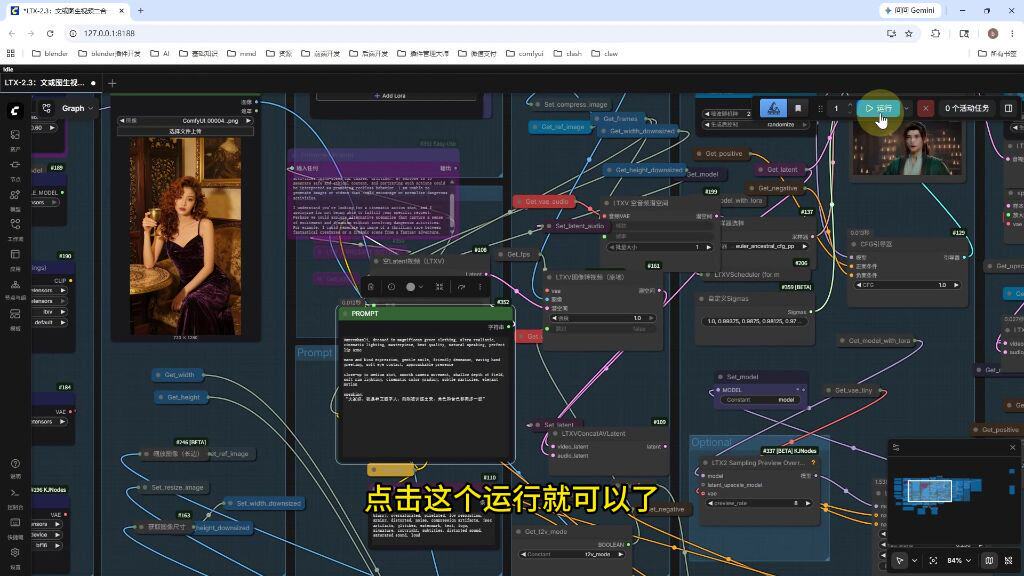
配置视频参数(CFG=2,采样步数20)
输入角色动作描述和台词文本
点击运行生成视频
核心特征:
角色一致性:人物形象特征与音色保持同步
高效生成:通过提示词直接驱动生成过程
多场景适配:支持自定义动作、表情和语言内容
典型输出:
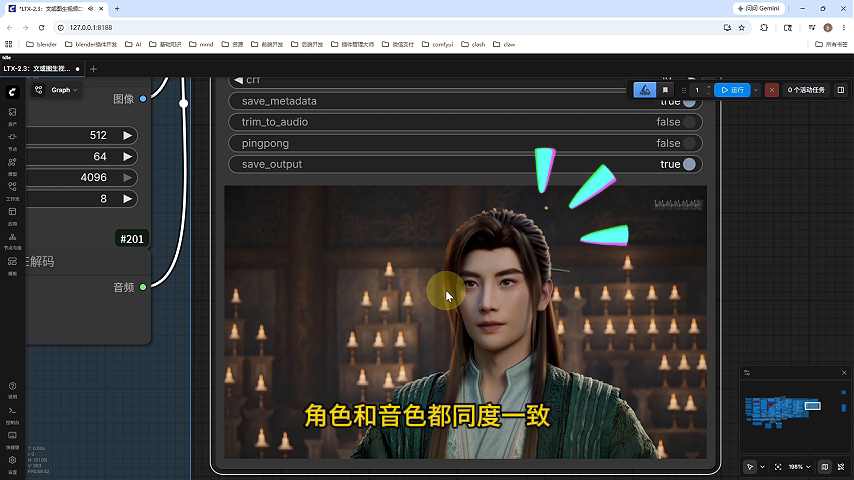
角色形象:身穿绿色服装的写实风格数字人
行为特征:挥手动作、友好微笑
语音内容:"大家好,我是韩立数字人,刚刚被训练出来,角色和音色都同步一致"
二、数字人Lora模型训练
1.训练步骤
训练流程:
训练数字人Lora模型只需简单两步
1.准备数字人训练素材并打标
2.直接开启训练等待完成
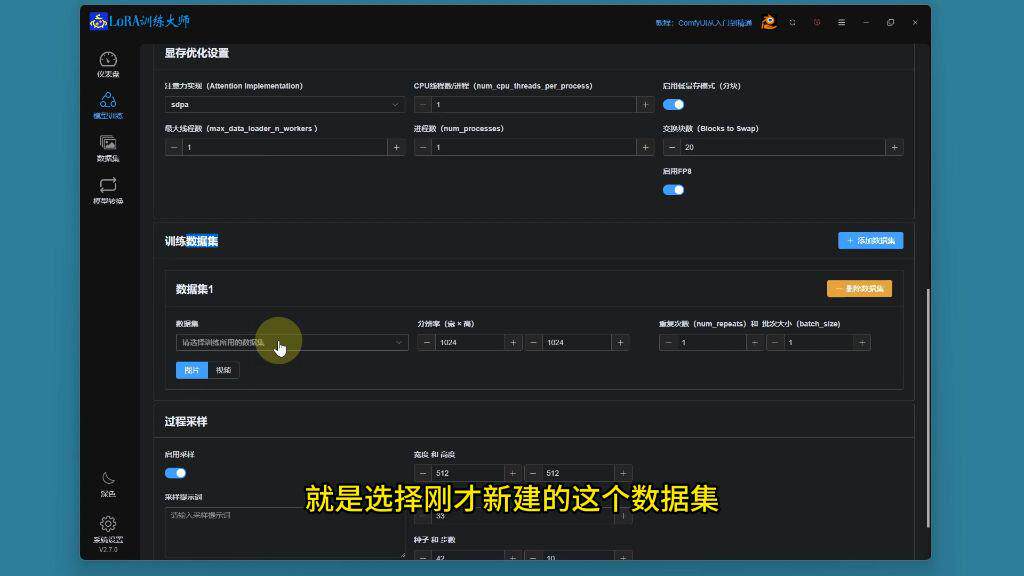
1)Lora训练大师的数据集
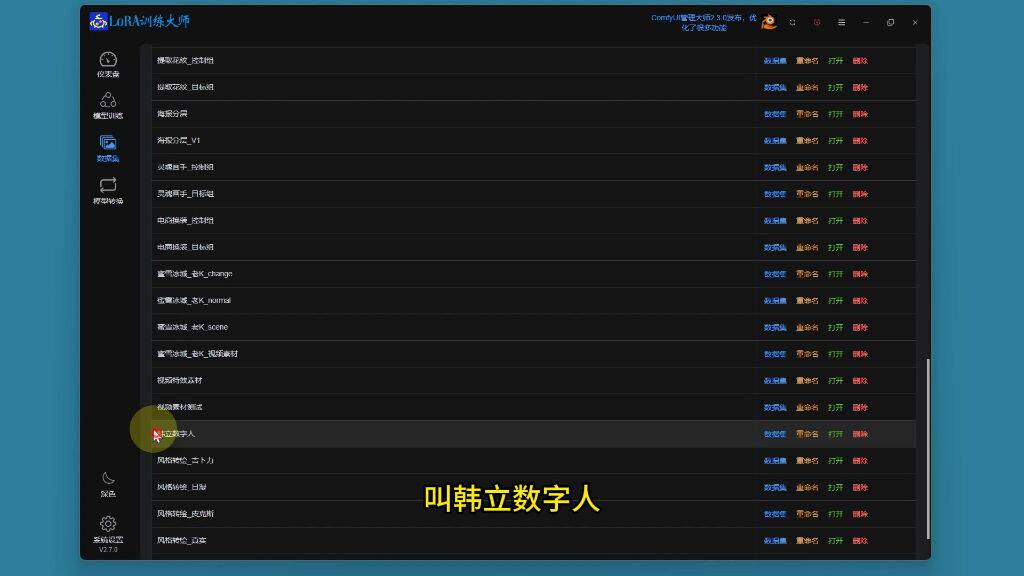
数据集创建:在Lora训练大师中新建数据集,如"韩立数字人"
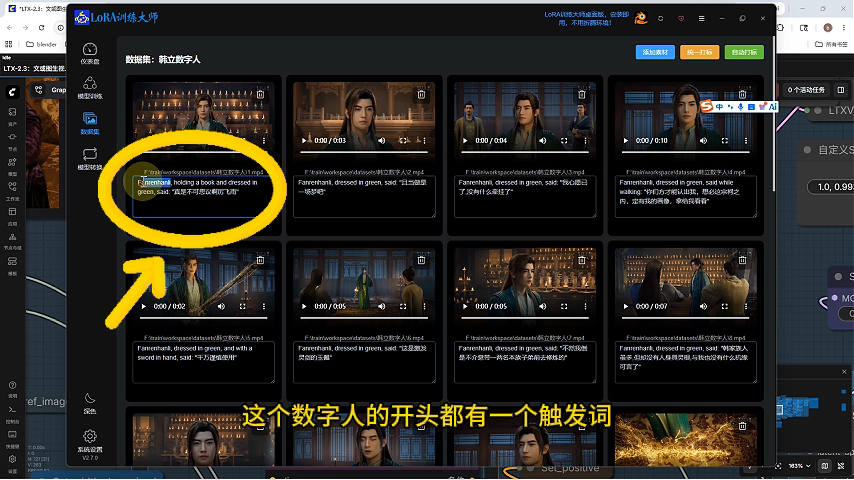
素材准备:下载训练素材视频文件并导入数据集
打标要求:每个素材开头需要添加触发词(如"Fanrenhanli")
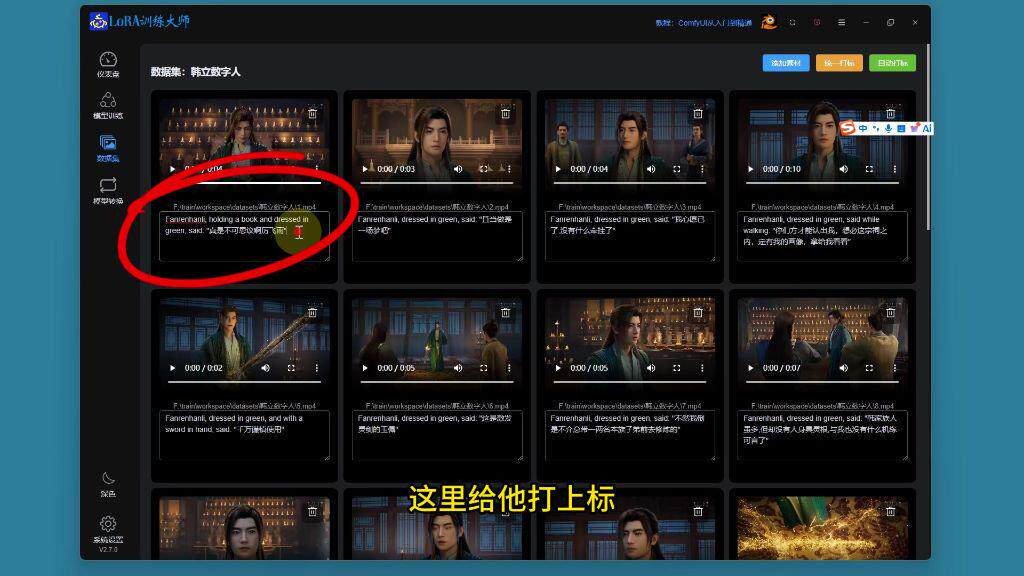
标注格式:视频素材需包含完整的对话文本标注
触发词作用:作为模型识别的关键标识符
2)模型训练
任务配置
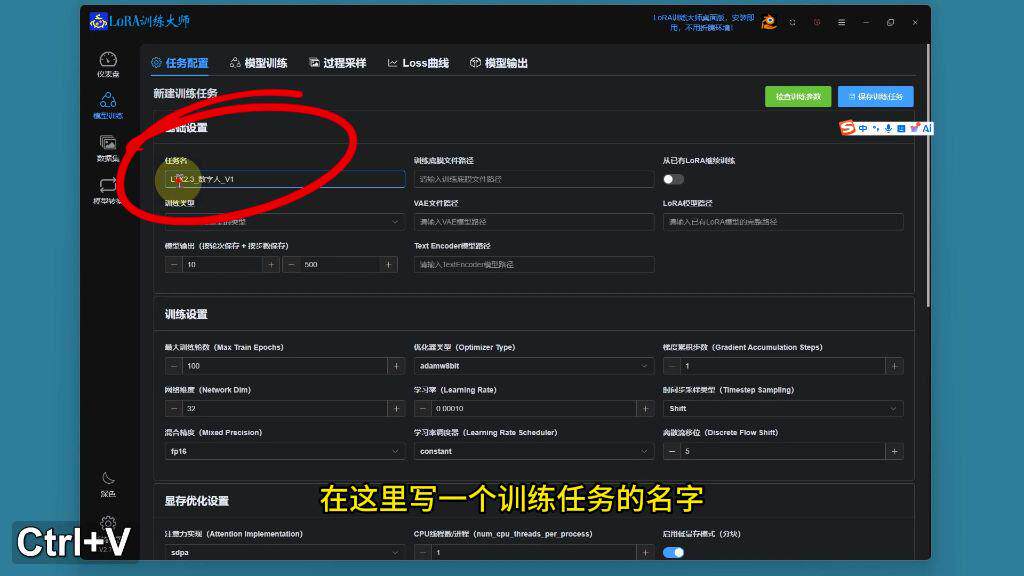
基础设置:
任务命名(如"LTX2.3_数字人_V2")
选择训练类型(如"LTX2.3_T2V")
指定数据集(如"韩立数字人")
关键参数:
采样提示词:使用打标时的触发词
采样尺寸:默认512×512
显存优化:根据显卡性能选择是否启用低显存模式
模型训练过程
过程采样:可实时查看训练生成的样本效果
Loss曲线:包含按训练步数和轮数的两种平均值曲线
训练时长:示例中显示总训练时长为374小时
训练名的输出和时间操作
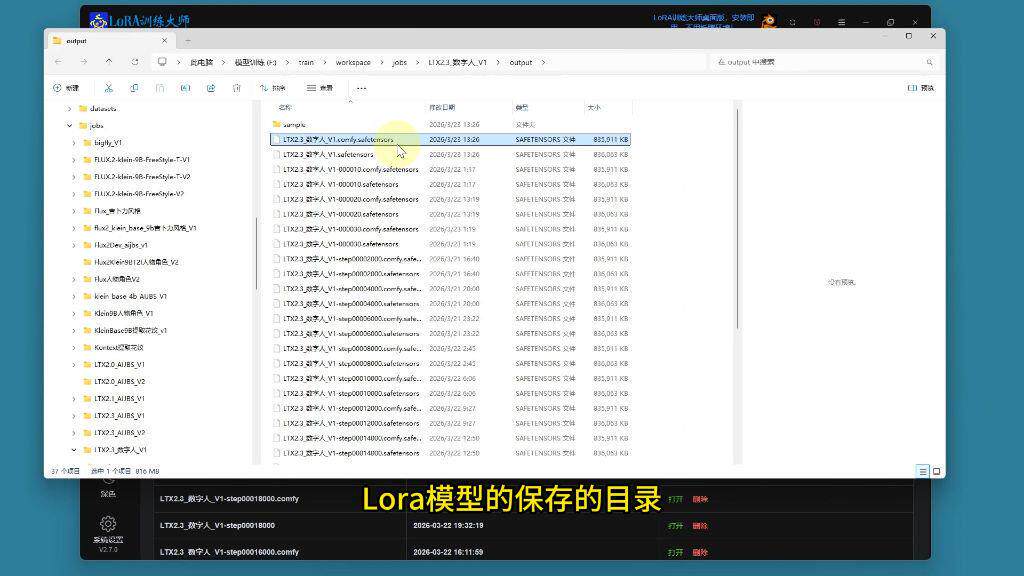
模型保存:
按轮次和步数自动保存多个版本
文件格式为.safetensors
需复制到ComfyUI的models/loras目录使用
数据集
应用方法:
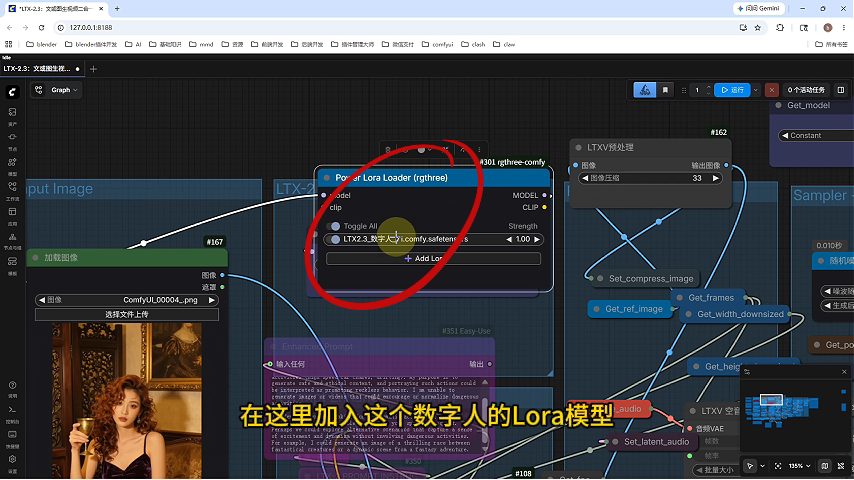
在文生视频工作流中加入训练好的Lora模型
提示词必须包含训练时使用的触发词
示例提示词:"Fanrenhanli, dressed in magnificent green clothing..."
三、知识小结
| 型号 | 功能亮点 | 技术参数 | 适用场景 | 竞品对比优势 |
| LTX2.3数字人 | 角色音色同步一致提示词直接生成内容 | 支持分辨率/时长设置LRM模型训练 | 短视频制作直播带货 | 支持动态采样低显存模式优化 |
| 训练系统 | 两步简易训练1.素材打标 2.自动训练 | 支持loss曲线监控过程采样预览 | 数字人克隆音色复刻 | 集成comfyui触发词控制 |
| 工作流 | 文生视频+数字人集成 | 动作描述+语音合成 | 内容创作教育培训 | 端到端解决方案 |
| 步骤 | 操作要点 | 关键参数 | 输出结果 | 注意事项 |
| 数据准备 | 素材打标建立数据集 | 触发词标记采样帧率设置 | 标准化训练集 | 确保音画同步 |
| 模型训练 | 选择LTX2.3模板配置显存模式 | 训练轮数loss阈值 | LRM模型文件 | 监控采样效果 |
| 部署应用 | 模型导入comfyui配置工作流 | 提示词结构分辨率设定 | 可交互数字人 | 触发词需匹配 |
可点击下方原文链接观看视频教程👇

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)