
CVPR 2024多模态研究趋势:超越图文理解,跨模态结合应用
当人工智能跨越单一模态的局限,融合文本、图像、音频、视频等多维度数据时,一场认知革命正在发生。在未来,多模态大模型将向更人性化、泛在化的智能跃迁,轻量化架构推动端侧普及,量子计算或从根本上突破算力瓶颈,而人形机器人的实用拐点、脑机接口的模态扩展,更将打开AGI时代人与AI协同进化的新维度。
关注gongzhonghao【CVPR顶会精选】
当人工智能跨越单一模态的局限,融合文本、图像、音频、视频等多维度数据时,一场认知革命正在发生。
在未来,多模态大模型将向更人性化、泛在化的智能跃迁,轻量化架构推动端侧普及,量子计算或从根本上突破算力瓶颈,而人形机器人的实用拐点、脑机接口的模态扩展,更将打开AGI时代人与AI协同进化的新维度。今天小图给大家精选3篇CVPR有多模态方向的论文,请注意查收!
论文一:Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
方法:
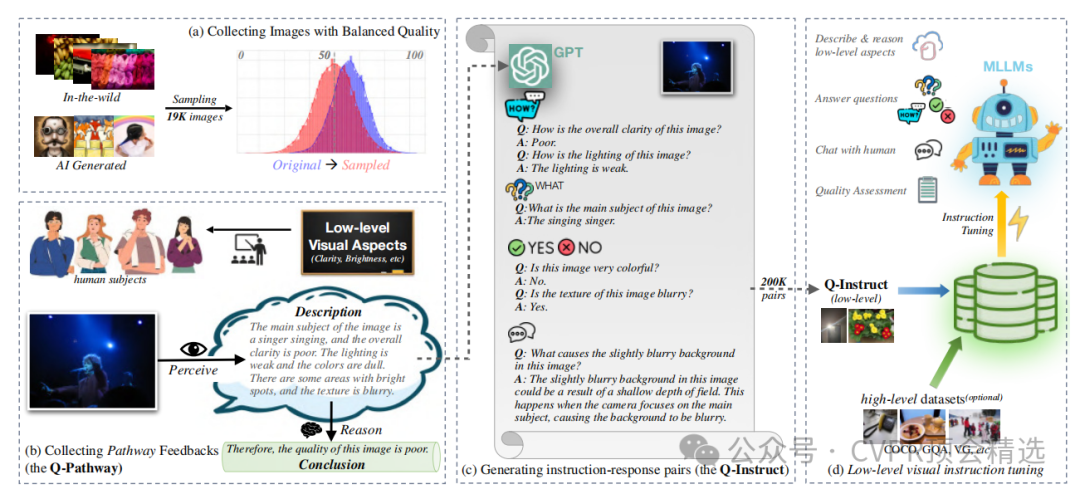
文章首先收集了包含58K人类反馈的Q-Pathway数据集,涵盖18,973张多源图像的低层次视觉属性描述和质量评估。然后,利用GPT将这些反馈转化为200K指令-响应对,形成Q-Instruct数据集,包含推理、问答和对话等多种形式。最后,通过将Q-Instruct与高层次视觉指令调优数据集混合训练,或在高层次调优后进行后续低层次调优,显著提升了多模态大语言模型在低层次视觉任务上的表现。
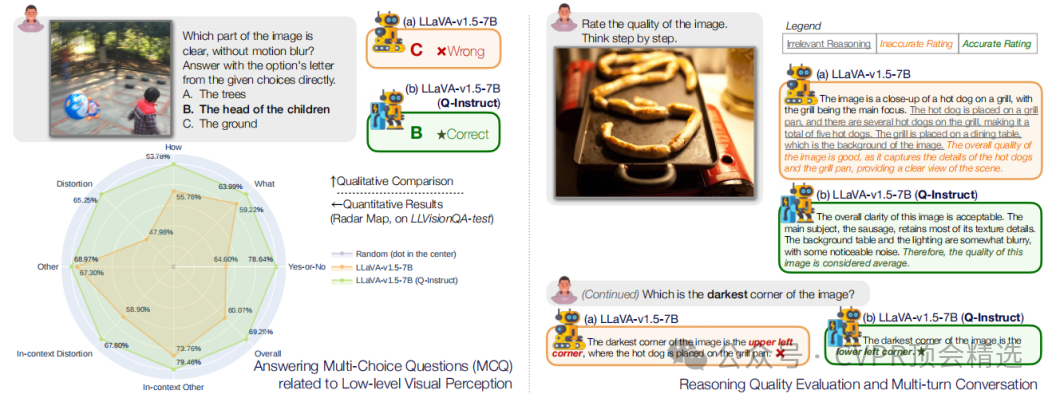
创新点:
-
构建了首个大规模低层次视觉指令调优数据集Q-Instruct,为模型训练提供了丰富的素材。
-
提出了基于人类反馈的低层次视觉描述和推理方法,通过自然语言反馈引导模型学习人类的视觉感知和推理过程,提升模型对图像低层次属性的理解能力。
-
设计了混合训练策略和后续训练策略,有效整合高低层次视觉任务数据,使模型在低层次视觉任务上表现出色,同时保持对高层次视觉任务的理解能力。
论文链接:
https://doi.org/10.1109/CVPR52733.2024.02408
图灵学术论文辅导
论文二:mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
方法:
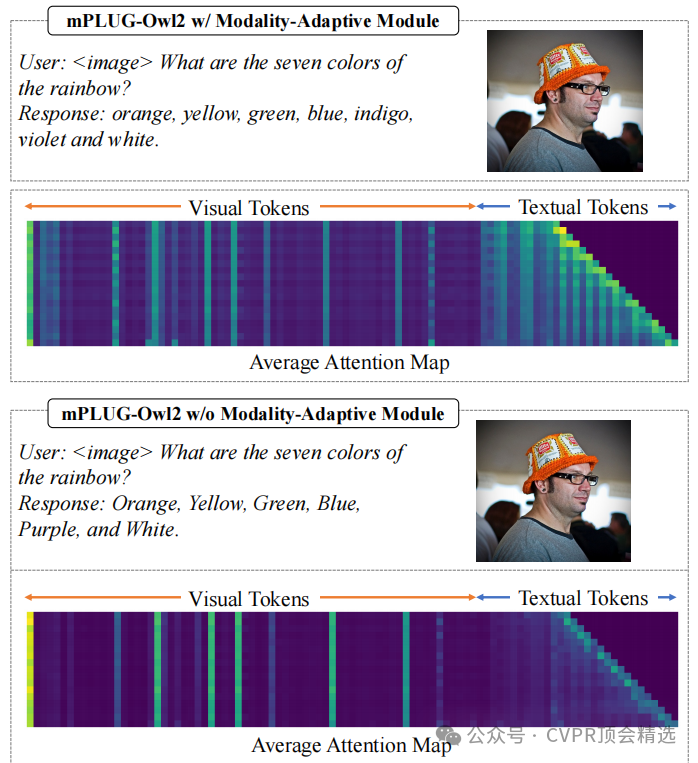
文章首先构建了一个包含视觉编码器、视觉抽象器、文本嵌入层和语言解码器的模块化网络架构,其中语言解码器作为通用接口管理多模态信号。接着引入模态自适应模块,通过将视觉和语言特征投影到共享语义空间并保留各自特性,促进模态间的有效协作。最后采用两阶段训练策略,先进行视觉语言预训练,再进行联合视觉语言指令调优,保持了强大的文本处理能力。
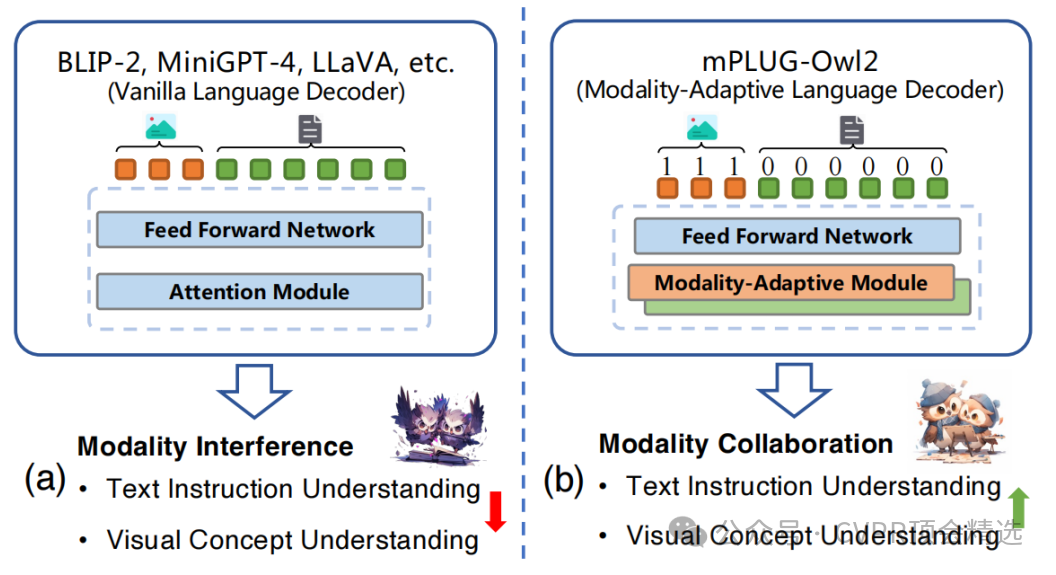
创新点:
-
提出了一种新颖的模态自适应模块,显著提升模型在多模态任务中的表现。
-
设计了两阶段训练范式,使模型能够更有效地捕捉低层次和高层次的视觉语义信息,进一步增强其多模态理解能力。
-
提出首个在纯文本和多模态场景中均展现出模态协作现象的多模态大语言模型,不仅在多模态任务上取得了优异成绩,还在纯文本基准测试中达到了新的高度。
论文链接:
https://arxiv.org/abs/2311.04257
图灵学术论文辅导
论文三:Generative Multimodal Models are In-Context Learners
方法:
文章首先构建了Emu2的架构,包括视觉编码器、多模态建模和视觉解码器,通过预测下一个多模态元素进行统一生成式预训练。接着,Emu2利用大规模多模态序列进行训练,以增强其上下文学习能力。最后,通过指令调优,Emu2能够遵循特定指令,进一步提升其在多模态任务中的性能,特别是在需要即时推理的任务上表现出色。
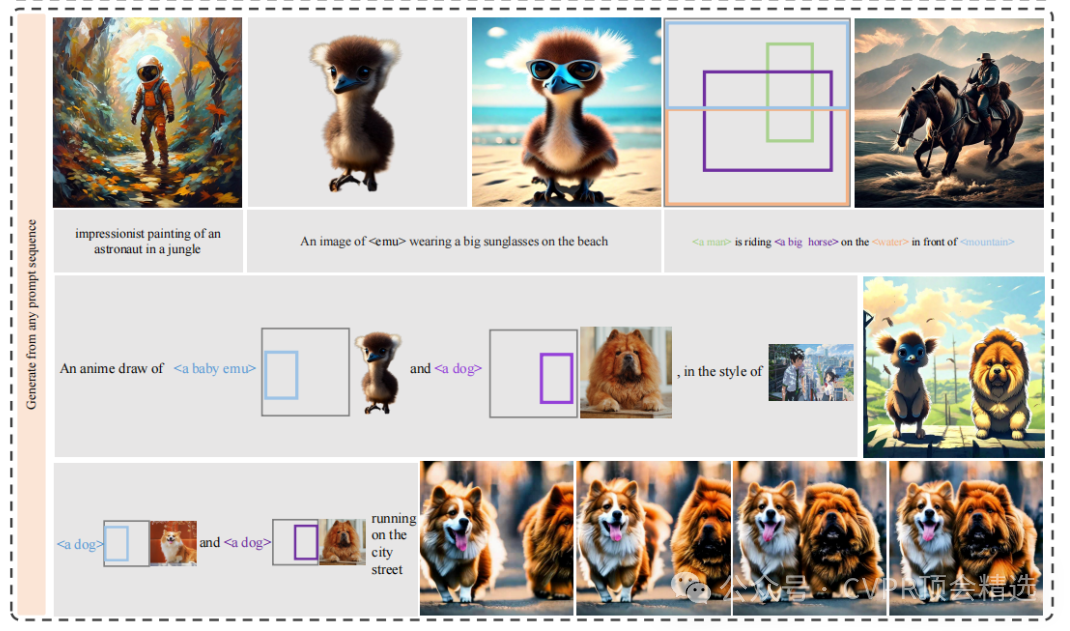
创新点:
-
提出了Emu2模型,通过大规模多模态数据训练,显著增强了多模态任务的上下文学习能力。
-
Emu2在多种多模态理解任务中刷新了少样本设置的记录,并在遵循特定指令的指令调优后,在问答基准测试和开放式主题驱动生成等挑战性任务上达到了新的最佳水平。
-
Emu2作为基础模型和通用接口,能够处理多种多模态任务,包括视觉问答、可控视觉生成等,展示了其在多模态领域的广泛适用性和强大的上下文学习能力。

论文链接:
https://doi.org/10.1109/CVPR52733.2024.01365
本文选自gongzhonghao【CVPR顶会精选】

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)