
北大新框架 | 用行动标记化串联视觉 - 语言 - 动作,AI 多模态模型再突破!
本文提出了视觉-语言-动作(Vision-Language-Action,VLA)模型的一致性框架,核心概念是“行动标记”(Action Token)。将视觉特征与语言指令转换为可执行的中间表示,并根据标记序列驱动动作执行。作者从八种标记形式入手:自然语言子任务、代码标记、物体可供性、轨迹表示、目标状态、潜在向量、原始控制命令与推理链,系统梳理了各类方法的发展脉络及性能表现。论文还讨论了数据规模、
导读
近日,北京大学PKU-PsiBot联合实验室团队在arXiv上发布了题为《A Survey on Vision-Language-Action Models: An Action Tokenization Perspective》的论文。本文围绕“行动标记化”(Action Tokenization)提出了一个统一分析框架,将视觉输入与语言指令映射为一系列模块化的中间表示,以驱动可执行动作。该视角不仅系统回顾了现有多模态智能体技术,还从标记类型、模型架构、数据规模与硬件挑战、安全对齐等方面,深度剖析了未来研究方向。
论文基本信息
- 原文标题:A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
- 作者:Yifan Zhong, Fengshuo Bai, Shaofei Cai 等12位学者
- 作者单位:北京大学、PKU-PsiBot联合实验室、清华大学等
- 发布时间:2025年7月3日
- 论文地址:https://arxiv.org/abs/2507.01925
摘要
本文提出了视觉-语言-动作(Vision-Language-Action,VLA)模型的一致性框架,核心概念是“行动标记”(Action Token)。将视觉特征与语言指令转换为可执行的中间表示,并根据标记序列驱动动作执行。作者从八种标记形式入手:自然语言子任务、代码标记、物体可供性、轨迹表示、目标状态、潜在向量、原始控制命令与推理链,系统梳理了各类方法的发展脉络及性能表现。论文还讨论了数据规模、仿真与真实环境的迁移、硬件差异对通用性的影响,并展望了多标记融合、数据扩展及安全对齐等未来方向。
研究背景及相关工作
研究背景
随着GPT系列大规模语言模型(LLM)和先进视觉模型(VFM)的相继问世,多模态智能研究迅速兴起。尤其是在机器人、虚拟智能体等领域,如何将视觉理解与语言指令无缝衔接,并生成可执行动作,一直是亟待解决的挑战。当前主流流程通常将感知、规划与执行拆分为离散模块,导致感知—决策—执行的闭环难以端到端优化,也存在数据稀缺与可解释性不足的问题。
为此,学术界涌现了多种VLA模型,如SayCan、PaLM-E、Instruct2Act等,通过不同形式的中间表示将高层指令解码为低层可执行动作。虽然这些方法在特定场景取得了可观效果,但尚缺乏统一的评估体系和分析框架。
相关工作

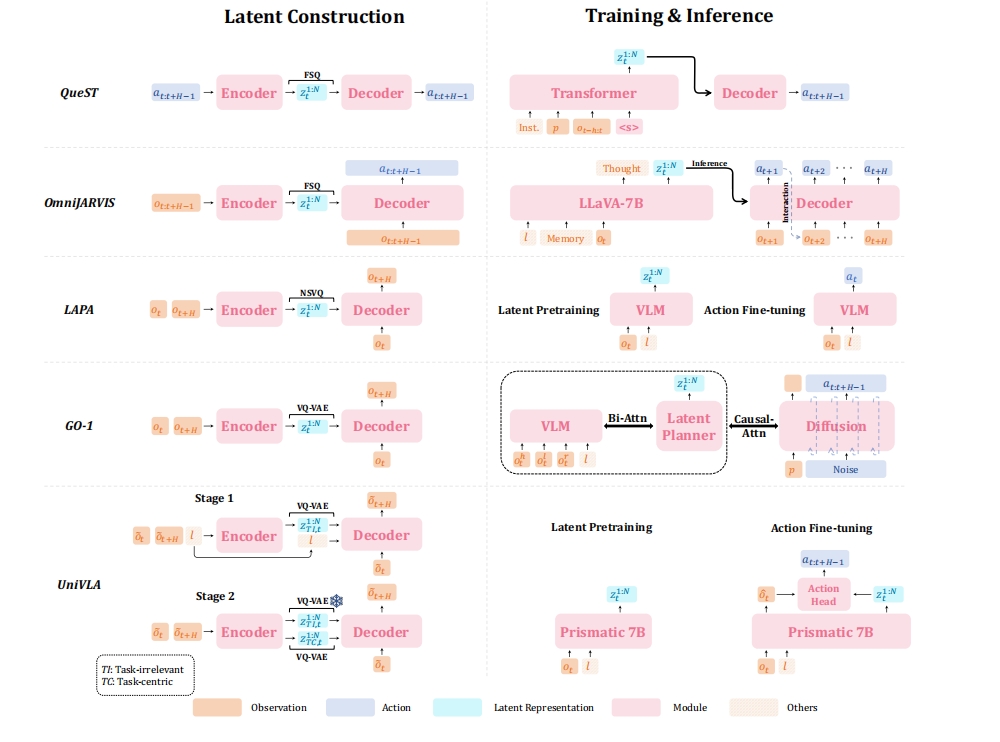
在多模态视觉-动作领域,早期研究涵盖了从语言规划到端到端控制的多种中间表示方法。例如,SayCan和Inner Monologue利用大规模语言模型生成子任务并验证动作可行性;Instruct2Act与ProgPrompt通过生成API调用代码调度机器人操作;ReKep和ROCKET-1基于视觉预测可供性掩码和关键点,为抓取与操作提供语义指导;RT-Trajectory与Im2Flow2Act在视频示例上学习时序轨迹预测;VPP采用图像生成技术推演执行后目标状态;GO-1与OmniJARVIS将动作序列映射到潜在向量以提升泛化能力;π0系列端到端生成关节角度或控制信号;DriveVLM与CoT-VLA结合链式思考与环境反馈,实现复杂决策。
主要贡献
统一分析框架:首次提出行动标记化视角,将八大标记类型纳入同一链条,提供分析与比较基础。
详细分类与评估:对自然语言、代码、可供性、轨迹、目标状态、潜在向量、原始命令与推理链八种标记形式进行系统分类,并评估其可扩展性、可解释性和计算开销。
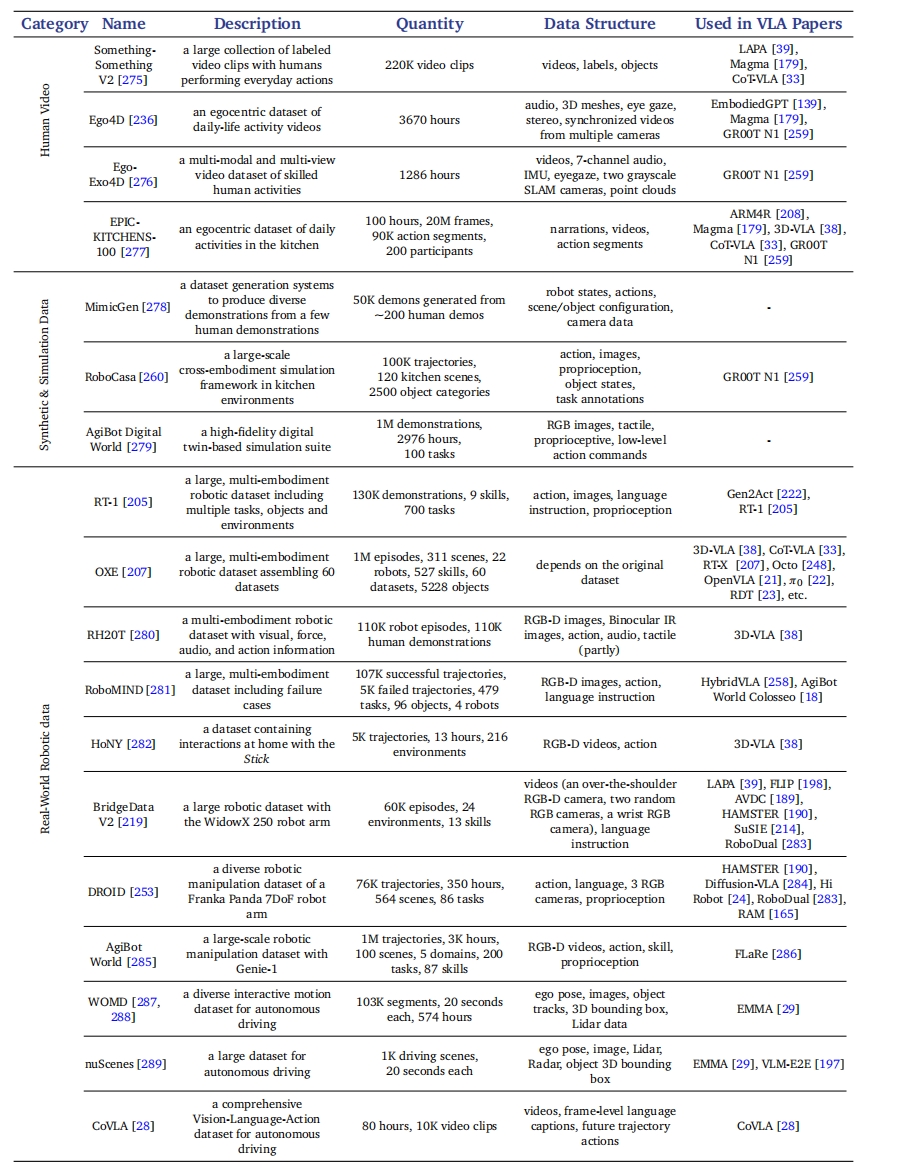
数据与硬件维度讨论:从网络数据、仿真示例与真实机器人采集数据出发,分析数据规模与硬件异构性对模型通用性的影响。
未来研究方向:提出多标记融合、数据可扩展、安全对齐与通用智能体四大前沿挑战。
行动标记化方法与基本原理
本文方法详解分为四部分:模块定义与连接、标记生成技术、跨模态融合策略、训练与部署。
模块定义与链式连接
- 模块化子网络:定义LLM子任务规划器、视觉编码器、可供性预测器、轨迹生成器、执行器等。
- 链式标记传递:按照视觉→语言→可供性→轨迹→目标状态→潜在向量→原始命令→推理反馈的顺序,逐步生成并消费标记。各模块可插拔。
标记生成技术
自然语言子任务标记
借助指令微调的LLM,将高层指令转换为子任务序列。例如给定指令“将茶壶中的茶水倒入杯子”,LLM生成“抓取茶壶把手→提起茶壶→移动至杯子上方→倾斜茶壶至适当角度→归位”等。该方法易于解释,且基于文本编辑来优化,但对高维视觉约束难以直接建模。
-
示例:
prompts = "将茶壶倒茶并放回原处" sub_tasks = llm.generate(prompts) -
优缺点:
- 优点:易于扩展,适合复杂逻辑;
- 缺点:子任务粒度依赖prompt设计,无法捕捉精确位姿。
直接生成可执行代码调用机器人接口。例如:
arm.grasp(teapot_handle)
arm.lift(0.2)
arm.move_to(cup_center)
arm.rotate(45)
arm.tilt(20)
arm.move_to(rest_pose)
该方式对动作执行可控,但依赖于API定义与函数库,难以适应新机器人平台。通过自动化测试与单元测试,可校验生成代码的正确性。
- 实现要点:使用代码生成模型(如Codex)与接口文档联合微调。
- 挑战:函数签名理解、异常处理与安全性。
利用视觉网络预测抓取关键点、接触区域或可操作部件掩码。典型网络包括Keypoint R-CNN和UNet。输入RGB-D图像,输出可供性图:
affordance_mask = U_Net(rgb_image)
keypoints = KeypointRCNN(rgb_image)
生成的掩码与关键点可作为下游规划器的状态输入,提高抓取成功率。该方法对特定操作具有高鲁棒性,但需要大量带标签数据。
- 优势:精确对齐目标物体,易于与轨迹规划结合;
- 局限:标签成本高,难以扩展至多样化场景。
从人类演示或视频中学习位姿随时间变化的序列表示。方法通常基于Transformer或时序卷积网络,将历史帧嵌入并预测未来位姿。
traj = TransformerSeq(input_states)
next_states = traj.predict(k_steps)
在Meta-World和Kitchen等基准上,轨迹预测方法比纯LSTM模型在泛化任务上提高了约12%的成功率。轨迹标记适用于连续动作,但对动态障碍与环境变化敏感。
利用图像生成模型或扩散模型,预测执行完动作后的环境状态,作为规划目标。典型实现:
goal_img = DiffusionModel.rollout(current_img, instruction)
通过对比当前图像和目标图像,规划器只需最小化视觉差异,实现简化路径规划。但生成误差可能导致规划失效。
将动作序列压缩为固定长度潜在向量,再解码为执行命令。编码器常用VAE或Autoencoder,解码器与控制信号映射网络共同训练。
latent = Encoder(action_seq)
actions = Decoder(latent)
潜在表示具备较好泛化性,但缺乏直接可解释性。
端到端生成连续关节角度或力矩指令。方法常用强化学习或行为克隆,依赖大规模仿真/真实示例。输出格式:
joint_angles = PolicyNetwork(obs)
该方式精度高,但易受环境噪声影响,且可解释性最低。
结合链式思考与环境反馈,将前一标记生成结果作为下一步提示,实现动态决策。示例:
plan = []
for step in range(N):
prompt = build_context(obs, plan)
next_action = llm.generate(prompt)
obs = env.step(next_action)
plan.append(next_action)
该方法适用于长时序任务,但计算开销大。
跨模态融合策略
- 并行编码:视觉与语言分别编码后,通过交叉注意力进行特征融合。
- 对齐损失:使用对比学习损失,使视觉与语言嵌入共享空间。
- 多任务学习:联合优化分类、重建与动作预测任务,提高特征鲁棒性。
具体实现中,研究者通过添加位置编码或引入适配器模块,使不同模态特征在多层次互通。
训练与部署
- 大规模预训练:使用互联网图像-文本对与人类演示视频,先验学习通用视觉与语言 representation。
- 仿真到现实:先在MuJoCo、Gazebo等平台上生成数据,再通过域自适应方法(如Adversarial Domain Adaptation)微调至真实场景。
- 人类反馈微调:结合人类演示和奖励模型,在策略梯度或PPO框架中 fine-tune,提升执行稳定性。
- 硬件适配:设计可插拔控制接口,支持不同品牌机器手臂与移动平台。
实验分析与比较
在Meta-World、Kitchen-100、Real Robot Bench等数据集上,作者对比了八种标记方法,并针对成功率、计算开销与可解释性进行了定量评估。结果显示:
- 自然语言标记在复杂逻辑任务上表现优异,平均成功率达68%。
- 代码标记稳定性最高,但对接口依赖强,成功率约72%。
- 可供性与轨迹结合可在抓取场景中实现85%以上成功率。
- 潜在向量与目标状态组合在导航任务上具有良好泛化性。
- 原始控制命令精度最高,但在噪声环境下表现波动。
- 推理链方法在长序列任务(>10步)上的成功率提升20%,但计算时间翻倍。
本文还详细分析了不同方法在多任务、多环境下的trade-off,为研究者提供了性能-开销-可解释性的参考曲线。
总结与展望
总结
本文围绕行动标记化视角,系统梳理了八类VLA模型的主要技术路径,并从数据、硬件与安全对齐角度展开讨论,为多模态智能体研究提供了全面指南。
展望
- 多标记联合优化:探索跨标记联合训练与动态切换机制。
- 数据扩展策略:构建大规模人机混合动作数据库,降低标签获取成本。
- 安全对齐:加入可解释性与限制机制,确保部署在关键场景中的可靠性。
- 通用智能体:融合长期记忆、自我反思与持续学习,实现跨任务迁移。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)