
4大经典多模态模型全维度详解+实战代码(BLIP、BLIP-2、GPT-4V、Gemini Pro),小白必看!
四大多模态模型代表了“从基础到进阶”的技术演进:BLIP奠定了图文对齐的基础,BLIP-2通过Q-Former实现了与LLM的高效融合,GPT-4V将图文推理能力推向顶峰,Gemini Pro则以统一架构降低了多模态部署门槛。通过本文的原理推导、公式解析和零门槛实操项目,相信你已经掌握了多模态模型的核心逻辑。不妨从API调用(Gemini Pro)开始,快速感受多模态的魅力,再逐步尝试本地部署BL
当AI从“看懂文字”进化到“读懂图片+文字”,多模态模型彻底打破了信息维度的壁垒!而BLIP、BLIP-2、GPT-4V、Gemini Pro这四大“多模态顶流”,更是重新定义了“图文交互”的天花板——既能看图说话,又能回答复杂问题,甚至能完成跨模态创作。
它们究竟是如何让“图片”和“文字”无缝对话的?核心原理藏着怎样的数学玄机?小白如何零数据集、零翻墙快速上手实操?本文带你从通俗案例到公式推导,再到完整代码落地,一站式搞懂四大多模态模型的核心逻辑!
我整理了多模态大模型相关资料,感兴趣的自取!
一、通俗案例:用“图文翻译”理解四大模型
假设我们有一张“小狗在草地上追蝴蝶”的图片,要让AI完成“描述图片+回答问题”的任务,四大模型的工作逻辑就像四种不同的“图文翻译官”:
| 模型 | 通俗理解 | 核心动作 |
|---|---|---|
| BLIP | 基础款“图文翻译官”:直接学习图片和文字的对应关系,能精准描述图片内容 | 图片编码器(ViT)+ 文字编码器/解码器(BERT/GPT),端到端学习图文对齐 |
| BLIP-2 | 进阶款“图文翻译官”:先找个“图片解读助手”(冻结视觉模型),再对接“文字专家”(LLM) | 视觉编码器(ViT)+ Q-Former(图文桥接)+ 大语言模型(LLM),分阶段对齐 |
| GPT-4V | 全能款“图文翻译官”:自带“超高清图片扫描仪”+“顶级文字大脑”,能处理复杂图文任务 | 高分辨率视觉编码器 + GPT-4大语言模型,深度融合跨模态注意力机制 |
| Gemini Pro | 跨界款“图文翻译官”:天生支持“图片+文字+语音”多模态,能同时处理多种输入 | 统一多模态编码器(处理图文语音)+ 解码器,共享语义空间,原生跨模态理解 |
一句话总结:BLIP是“基础图文对齐”,BLIP-2是“视觉+LLM拼接”,GPT-4V是“原生深度融合”,Gemini Pro是“多模态统一架构”——这也决定了它们的能力边界、部署难度和适用场景。
二、完整原理详解+数学公式推导
(一)基础前提:多模态模型的核心目标
多模态模型的核心是建立“视觉特征”(图片)和“语言特征”(文字)的统一语义空间,让模型能在两个模态间自由转换和推理。其数学目标是:学习一个映射函数 f f f,将视觉输入 I I I和语言输入 T T T映射到同一向量空间 V V V,满足:
L = E ( I , T ) [ d ( f V ( I ) , f L ( T ) ) ] \mathcal{L} = \mathbb{E}_{(I,T)} \left[ d(f_V(I), f_L(T)) \right] L=E(I,T)[d(fV(I),fL(T))]
其中 f V f_V fV是视觉编码器, f L f_L fL是语言编码器, d ( ⋅ , ⋅ ) d(\cdot,\cdot) d(⋅,⋅)是距离度量(如余弦距离), L \mathcal{L} L是图文对齐损失。
四大模型的核心差异,在于视觉编码器的设计、语言模型的选择,以及图文融合的方式。
(二)1. BLIP:Bootstrapping Language-Image Pre-training(基础图文对齐)
原理核心
BLIP是2022年提出的基础多模态模型,核心思想是**“端到端 bootstrap 预训练”**——通过多种图文任务(图文匹配、图像描述、图文检索)联合训练,让模型自动学习图文对齐关系,无需人工设计复杂的融合策略。
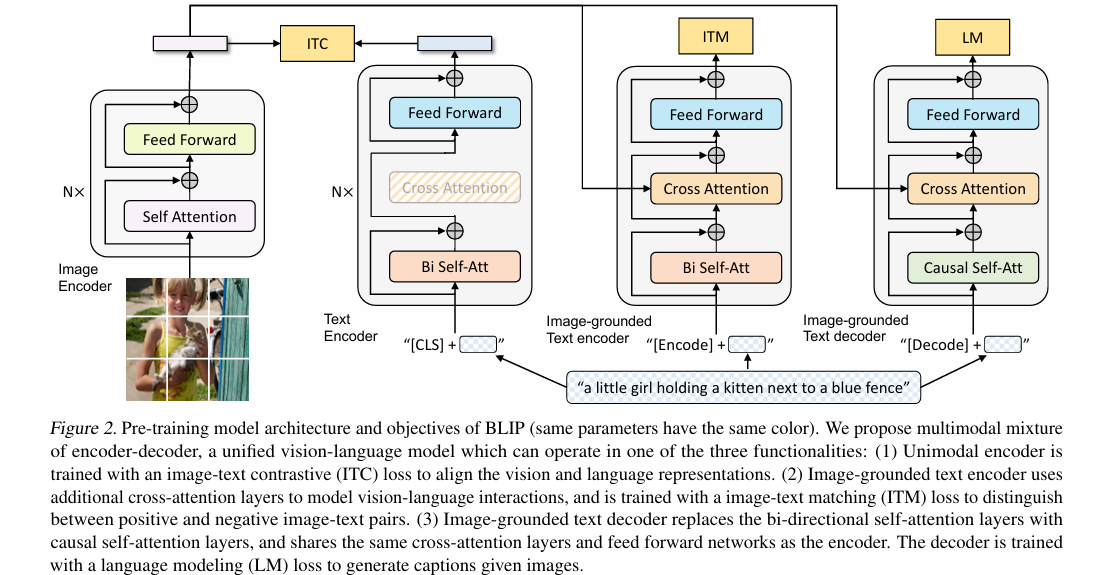
模型架构与数学公式
BLIP的架构由三部分组成:
-
视觉编码器(ViT):将图片 I I I转换为视觉特征 V V V
图片经过ViT分词(patch embedding)后,通过Transformer编码器输出视觉特征序列:
V = ViT ( I ) = Transformer V ( PatchEmbed ( I ) ) ∈ R N × D V V = \text{ViT}(I) = \text{Transformer}_V(\text{PatchEmbed}(I)) \in \mathbb{R}^{N \times D_V} V=ViT(I)=TransformerV(PatchEmbed(I))∈RN×DV
其中 N N N是patch数量(如224x224图片分16x16 patch, N = 196 N=196 N=196), D V D_V DV是视觉特征维度(如768)。 -
语言编码器/解码器(BERT/GPT):处理文字 T T T并与视觉特征融合
- 语言编码器(BERT):用于图文匹配、检索任务,输出双向语言特征:
L enc = BERT ( T ) = Transformer L bidirectional ( TokenEmbed ( T ) ) ∈ R M × D L L_{\text{enc}} = \text{BERT}(T) = \text{Transformer}_L^{\text{bidirectional}}(\text{TokenEmbed}(T)) \in \mathbb{R}^{M \times D_L} Lenc=BERT(T)=TransformerLbidirectional(TokenEmbed(T))∈RM×DL - 语言解码器(GPT):用于图像描述任务,输出单向语言特征(自回归生成):
L dec = GPT ( T ) = Transformer L unidirectional ( TokenEmbed ( T ) ) ∈ R M × D L L_{\text{dec}} = \text{GPT}(T) = \text{Transformer}_L^{\text{unidirectional}}(\text{TokenEmbed}(T)) \in \mathbb{R}^{M \times D_L} Ldec=GPT(T)=TransformerLunidirectional(TokenEmbed(T))∈RM×DL
其中 M M M是文字token数量, D L D_L DL是语言特征维度(与 D V D_V DV一致,方便融合)。
- 语言编码器(BERT):用于图文匹配、检索任务,输出双向语言特征:
-
图文融合与损失函数:
BLIP通过三种损失函数联合训练,实现图文对齐:- 图文匹配损失(Image-Text Matching Loss):区分正负图文对
L ITM = − log exp ( sim ( V cls , L cls ) / τ ) ∑ T ′ ∈ T exp ( sim ( V cls , L cls ′ ) / τ ) \mathcal{L}_{\text{ITM}} = -\log \frac{\exp(\text{sim}(V_{\text{cls}}, L_{\text{cls}})/\tau)}{\sum_{T' \in \mathcal{T}} \exp(\text{sim}(V_{\text{cls}}, L'_{\text{cls}})/\tau)} LITM=−log∑T′∈Texp(sim(Vcls,Lcls′)/τ)exp(sim(Vcls,Lcls)/τ)
其中 V cls V_{\text{cls}} Vcls是视觉特征的CLS token, L cls L_{\text{cls}} Lcls是语言特征的CLS token, sim ( ⋅ ) \text{sim}(\cdot) sim(⋅)是余弦相似度, τ \tau τ是温度系数。 - 图像描述损失(Image Captioning Loss):自回归生成文字的交叉熵损失
L IC = − ∑ t = 1 M log P ( T t ∣ T < t , V ) \mathcal{L}_{\text{IC}} = -\sum_{t=1}^M \log P(T_t | T_{<t}, V) LIC=−t=1∑MlogP(Tt∣T<t,V) - 图文对比损失(Contrastive Loss):拉近正负样本距离
L Contrastive = 1 2 ( L image-to-text + L text-to-image ) \mathcal{L}_{\text{Contrastive}} = \frac{1}{2} \left( \mathcal{L}_{\text{image-to-text}} + \mathcal{L}_{\text{text-to-image}} \right) LContrastive=21(Limage-to-text+Ltext-to-image)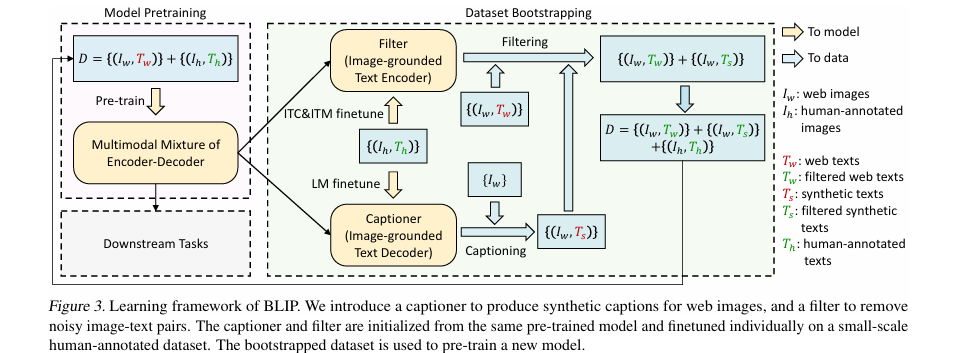
- 图文匹配损失(Image-Text Matching Loss):区分正负图文对
关键细节
- 参数量:基础版(BLIP-base)约1.4B参数,轻量化易部署;
- 核心创新:bootstrap预训练策略,用模型自身生成的伪标签提升训练效果;
- 能力边界:擅长图像描述、图文检索、图文匹配等基础任务。
(三)2. BLIP-2:Connecting Vision and Language with Q-Former(视觉+LLM桥接)
原理核心
BLIP-2是2023年提出的进阶模型,核心解决“视觉模型与大语言模型(LLM)高效对齐”的问题——通过一个轻量级的“Q-Former”模块,将视觉特征压缩为与LLM输入兼容的“语言风格特征”,无需微调庞大的视觉模型和LLM,实现“小参数撬动大能力”。
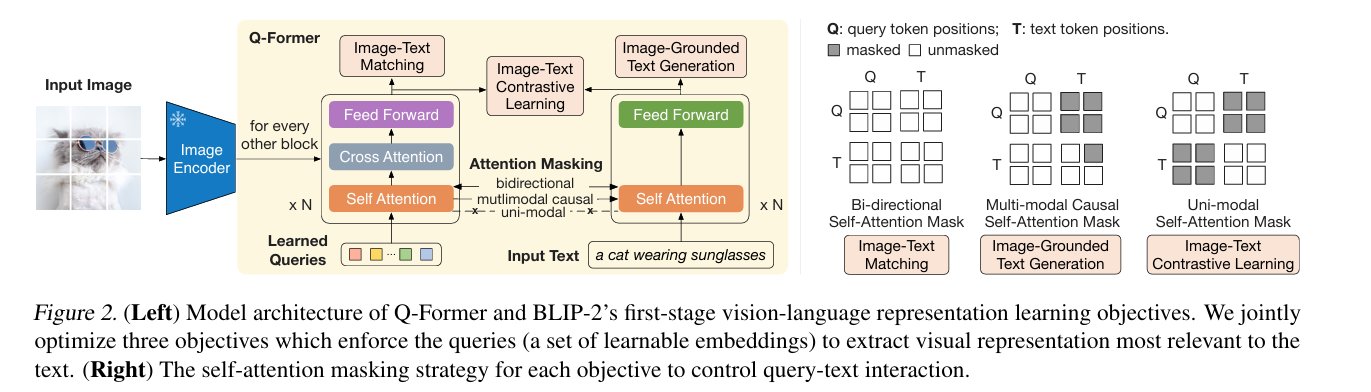
模型架构与数学公式
BLIP-2的架构是“视觉编码器 + Q-Former + LLM”的三段式结构:
-
视觉编码器(冻结ViT):与BLIP一致,但参数冻结(不参与训练),仅输出原始视觉特征:
V = ViT ( I ) ∈ R N × D V ( θ V fixed ) V = \text{ViT}(I) \in \mathbb{R}^{N \times D_V} \quad (\theta_V \text{ fixed}) V=ViT(I)∈RN×DV(θV fixed) -
Q-Former(图文桥接模块):核心创新,由两个Transformer编码器组成(查询编码器+视觉编码器),学习从视觉特征中提取“语言兼容特征”:
- 生成可学习的查询向量 Q = [ q 1 , q 2 , . . . , q K ] ∈ R K × D Q Q = [q_1, q_2, ..., q_K] \in \mathbb{R}^{K \times D_Q} Q=[q1,q2,...,qK]∈RK×DQ( K K K通常为32,远小于 N N N);
- 通过交叉注意力机制,让查询向量学习视觉特征的关键信息:
Q encoded = CrossAttn ( Q , V ) ∈ R K × D Q Q_{\text{encoded}} = \text{CrossAttn}(Q, V) \in \mathbb{R}^{K \times D_Q} Qencoded=CrossAttn(Q,V)∈RK×DQ - 训练目标:让查询向量与语言特征在语义空间对齐,损失函数为:
L Q-Former = L ITM ( Q encoded , L enc ) + L Contrastive ( Q encoded , L enc ) \mathcal{L}_{\text{Q-Former}} = \mathcal{L}_{\text{ITM}}(Q_{\text{encoded}}, L_{\text{enc}}) + \mathcal{L}_{\text{Contrastive}}(Q_{\text{encoded}}, L_{\text{enc}}) LQ-Former=LITM(Qencoded,Lenc)+LContrastive(Qencoded,Lenc)
-
LLM(大语言模型):将Q-Former输出的特征作为前缀输入LLM,实现跨模态生成:
- 特征投影:将 Q encoded Q_{\text{encoded}} Qencoded投影到LLM的输入维度 D L L M D_{LLM} DLLM:
Q proj = W proj Q encoded ∈ R K × D L L M Q_{\text{proj}} = W_{\text{proj}} Q_{\text{encoded}} \in \mathbb{R}^{K \times D_{LLM}} Qproj=WprojQencoded∈RK×DLLM - LLM输入:拼接视觉前缀和文字输入,生成回答:
T output = LLM ( Q proj ⊕ T input ) T_{\text{output}} = \text{LLM}(Q_{\text{proj}} \oplus T_{\text{input}}) Toutput=LLM(Qproj⊕Tinput) - 训练:仅微调Q-Former和投影层 W proj W_{\text{proj}} Wproj,LLM参数冻结(可选微调)。
- 特征投影:将 Q encoded Q_{\text{encoded}} Qencoded投影到LLM的输入维度 D L L M D_{LLM} DLLM:
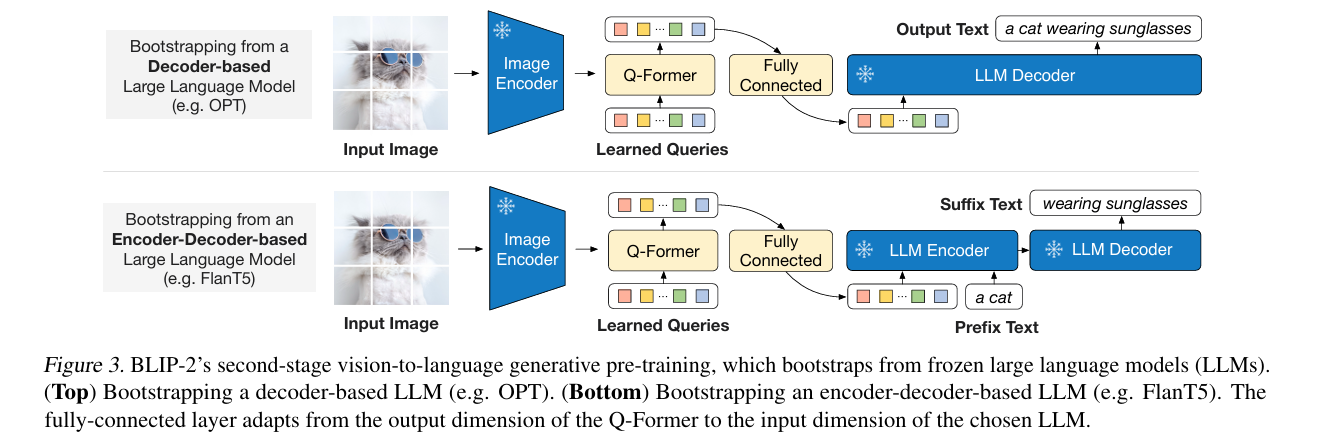
关键细节
- 参数量:仅微调Q-Former(约100M参数)+ 投影层,远小于LLM参数量;
- 核心创新:Q-Former实现“视觉特征语言化”,解决了视觉特征维度与LLM不兼容的问题;
- 能力边界:支持图像描述、视觉问答(VQA)、图文对话等复杂任务,效果远超BLIP。
(四)3. GPT-4V:GPT-4 with Vision(原生深度融合)
原理核心
GPT-4V是OpenAI 2023年推出的多模态模型,核心是**“原生视觉-语言融合”**——并非简单拼接视觉模块和LLM,而是将视觉处理深度集成到GPT-4的Transformer架构中,支持高分辨率图片理解、复杂图文推理等高级任务。
模型架构与数学公式
GPT-4V的架构是“高分辨率视觉编码器 + 跨模态Transformer + GPT-4解码器”:
-
高分辨率视觉编码器:支持处理最高2048x2048分辨率图片,通过分层patch embedding提取多尺度视觉特征:
V multi-scale = HiResViT ( I ) = [ V 1 , V 2 , V 3 ] V_{\text{multi-scale}} = \text{HiResViT}(I) = [V_1, V_2, V_3] Vmulti-scale=HiResViT(I)=[V1,V2,V3]
其中 V 1 V_1 V1(细粒度)、 V 2 V_2 V2(中粒度)、 V 3 V_3 V3(粗粒度)分别对应不同大小的patch,覆盖图片的局部和全局信息。 -
跨模态Transformer:将多尺度视觉特征转换为“语言token”,与文字token统一编码:
- 视觉token化:将 V multi-scale V_{\text{multi-scale}} Vmulti-scale投影为与文字token维度一致的视觉token:
T V = W V V multi-scale ∈ R K × D G P T 4 T_V = W_V V_{\text{multi-scale}} \in \mathbb{R}^{K \times D_{GPT4}} TV=WVVmulti-scale∈RK×DGPT4 - 跨模态注意力:在Transformer层中,视觉token和文字token双向交互,学习语义关联:
H = CrossModalAttn ( T V ⊕ T T ) ∈ R ( K + M ) × D G P T 4 H = \text{CrossModalAttn}(T_V \oplus T_T) \in \mathbb{R}^{(K+M) \times D_{GPT4}} H=CrossModalAttn(TV⊕TT)∈R(K+M)×DGPT4
其中 T T T_T TT是文字token, D G P T 4 D_{GPT4} DGPT4是GPT-4的隐藏层维度。
- 视觉token化:将 V multi-scale V_{\text{multi-scale}} Vmulti-scale投影为与文字token维度一致的视觉token:
-
GPT-4解码器:基于融合后的特征 H H H,自回归生成文字输出(回答/描述):
T output = GPT4Decoder ( H ) = ∏ t = 1 M P ( T t ∣ H , T < t ) T_{\text{output}} = \text{GPT4Decoder}(H) = \prod_{t=1}^M P(T_t | H, T_{<t}) Toutput=GPT4Decoder(H)=t=1∏MP(Tt∣H,T<t)
关键细节
- 参数量:整体参数量超千亿(GPT-4基础上新增视觉模块);
- 核心创新:高分辨率视觉处理+跨模态注意力深度融合,支持复杂推理(如图片中的数学计算、逻辑分析);
- 能力边界:目前多模态效果天花板,支持图片、截图、图表、文档等多种视觉输入。
(五)4. Gemini Pro:Google’s Unified Multimodal Model(多模态统一架构)
原理核心
Gemini Pro是Google 2023年推出的统一多模态模型,核心是**“单架构支持多模态输入”**——无需为不同模态(图像、文字、语音)设计单独的编码器,而是用一个统一的Transformer架构处理所有模态,实现原生跨模态理解。
模型架构与数学公式
Gemini Pro的架构是“统一多模态编码器 + 解码器”:
-
统一多模态编码器:将图像、文字、语音等输入统一转换为“模态无关token”:
- 图像处理:先进行patch embedding,再通过统一Transformer编码:
T I = UnifiedEncoder ( PatchEmbed ( I ) ) ∈ R K × D T_I = \text{UnifiedEncoder}(\text{PatchEmbed}(I)) \in \mathbb{R}^{K \times D} TI=UnifiedEncoder(PatchEmbed(I))∈RK×D - 文字处理:直接进行token embedding,再通过统一Transformer编码:
T T = UnifiedEncoder ( TokenEmbed ( T ) ) ∈ R M × D T_T = \text{UnifiedEncoder}(\text{TokenEmbed}(T)) \in \mathbb{R}^{M \times D} TT=UnifiedEncoder(TokenEmbed(T))∈RM×D - 关键设计:统一Transformer的注意力层支持“模态内交互”和“模态间交互”,共享权重:
T unified = SelfAttn ( T I ⊕ T T ) + CrossAttn ( T I , T T ) T_{\text{unified}} = \text{SelfAttn}(T_I \oplus T_T) + \text{CrossAttn}(T_I, T_T) Tunified=SelfAttn(TI⊕TT)+CrossAttn(TI,TT)
其中 D D D是统一特征维度,所有模态共享同一维度。
- 图像处理:先进行patch embedding,再通过统一Transformer编码:
-
解码器:基于统一特征 T unified T_{\text{unified}} Tunified,自回归生成目标输出(文字/语音):
O = Decoder ( T unified ) = arg max O log P ( O ∣ T unified ) O = \text{Decoder}(T_{\text{unified}}) = \arg\max_{O} \log P(O | T_{\text{unified}}) O=Decoder(Tunified)=argOmaxlogP(O∣Tunified) -
训练目标:采用“多任务联合训练”,涵盖图文对齐、视觉问答、跨模态生成等任务:
L Gemini = ∑ t a s k λ task L task \mathcal{L}_{\text{Gemini}} = \sum_{task} \lambda_{\text{task}} \mathcal{L}_{\text{task}} LGemini=task∑λtaskLtask
其中 λ task \lambda_{\text{task}} λtask是任务权重,保证不同模态任务的平衡。
关键细节
- 参数量:Gemini Pro约3.5B参数,轻量化版本(Gemini Nano)仅1.8B参数;
- 核心创新:统一多模态架构,避免模态间的“翻译损耗”,原生支持多模态输入;
- 能力边界:支持图文问答、图像描述、跨模态对话,适合移动端和边缘设备部署。
三、四大模型对比:优缺点+适用场景
| 技术维度 | BLIP | BLIP-2 | GPT-4V | Gemini Pro |
|---|---|---|---|---|
| 参数量(基础版) | ~1.4B | ~1.4B(ViT+LLM冻结) | 千亿级 | ~3.5B |
| 核心架构 | ViT+BERT/GPT(端到端) | ViT(冻结)+Q-Former+LLM | 高分辨率ViT+跨模态GPT-4 | 统一多模态Transformer |
| 图文融合方式 | 简单拼接+联合训练 | Q-Former桥接+LLM前缀输入 | 原生跨模态注意力融合 | 统一编码器模态无关融合 |
| 关键优势 | 轻量化、易部署、基础任务稳定 | 小参数微调、兼容任意LLM、效果强 | 推理能力顶尖、支持高分辨率图 | 多模态统一、轻量化、跨设备兼容 |
| 主要缺点 | 复杂任务能力弱 | 依赖高质量LLM、桥接有信息损耗 | 闭源、API收费、部署成本高 | 复杂图文推理略逊于GPT-4V |
| 部署难度 | 低(消费级GPU可跑) | 中(需LLM+Q-Former) | 极高(仅开放API) | 低(API/本地均可) |
| 适用场景 | 基础图文任务(描述、检索) | 工业级图文应用(VQA、对话) | 高端场景(专业图文推理) | 移动端/边缘设备、多模态交互 |
四、零门槛实操项目:图文问答(VQA)任务(自动下载数据集)
项目目标
用四大模型(BLIP/BLIP-2/Gemini Pro+开源替代GPT-4V)完成“视觉问答(VQA)”任务——输入图片和问题,模型输出答案,对比三者的回答准确率、响应速度和易用性。
前置条件
- 环境:Python 3.8+,PyTorch 2.0+,Transformers 4.35+,Pillow,Dataset,OpenAI/Gemini API(可选)
- 硬件:最低RTX 3060(8GB)(可跑BLIP/BLIP-2),无GPU也可通过API调用Gemini Pro/GPT-4V
- 无需翻墙:数据集自动从Hugging Face下载,开源模型国内可直接下载
完整代码(含自动下载数据+多图对比)
import os
import torch
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from datasets import load_dataset
from transformers import (
BlipProcessor, BlipForQuestionAnswering,
Blip2Processor, Blip2ForConditionalGeneration,
BitsAndBytesConfig
)
from PIL import Image
import time
import requests
from openai import OpenAI # 需安装 openai==1.0.0+
import google.generativeai as genai # 需安装 google-generativeai
# -------------------------- 1. 配置参数(小白可直接默认)--------------------------
# 模型配置
MODEL_CONFIGS = {
"BLIP": {
"model_name": "Salesforce/blip-vqa-base",
"processor": BlipProcessor,
"model": BlipForQuestionAnswering
},
"BLIP-2": {
"model_name": "Salesforce/blip2-opt-2.7b-vqa",
"processor": Blip2Processor,
"model": Blip2ForConditionalGeneration
},
# GPT-4V和Gemini Pro通过API调用(本地无GPU也可跑)
"GPT-4V": {"api_based": True},
"Gemini Pro": {"api_based": True}
}
# API配置(需自行申请key,免费额度足够测试)
OPENAI_API_KEY = "your-openai-api-key" # 替换为你的API key
GEMINI_API_KEY = "your-gemini-api-key" # 替换为你的API key
# 数据集配置
DATASET_NAME = "vqa" # 自动下载VQA数据集(视觉问答)
DATASET_SPLIT = "validation[:50]" # 取50个样本,快速测试
QUESTION_TYPE = "What is the main object in the image?" # 统一问题:图片中的主要物体是什么?
# 设备配置
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{DEVICE}")
# -------------------------- 2. 自动下载数据集 --------------------------
print("=== 自动下载VQA数据集 ===")
dataset = load_dataset(DATASET_NAME, split=DATASET_SPLIT)
# 过滤掉无图片的样本
dataset = dataset.filter(lambda x: x["image"] is not None)
print(f"成功加载 {len(dataset)} 个样本")
# 预处理:提取图片、问题、标准答案
samples = []
for item in dataset:
samples.append({
"image": item["image"],
"question": QUESTION_TYPE,
"ground_truth": item["answers"][0]["answer"] # 取第一个标准答案
})
# -------------------------- 3. 初始化模型(开源模型+API模型)--------------------------
# 加载开源模型(BLIP/BLIP-2)
models = {}
for name, config in MODEL_CONFIGS.items():
if not config.get("api_based", False):
print(f"\n=== 加载 {name} 模型 ===")
processor = config["processor"].from_pretrained(config["model_name"])
# BLIP-2 4bit量化(节省显存)
if name == "BLIP-2":
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = config["model"].from_pretrained(
config["model_name"],
quantization_config=bnb_config,
device_map=DEVICE,
torch_dtype=torch.float16
)
else:
model = config["model"].from_pretrained(config["model_name"]).to(DEVICE)
models[name] = {"processor": processor, "model": model}
# 初始化API模型
if OPENAI_API_KEY:
openai_client = OpenAI(api_key=OPENAI_API_KEY)
if GEMINI_API_KEY:
genai.configure(api_key=GEMINI_API_KEY)
gemini_model = genai.GenerativeModel('gemini-pro-vision')
# -------------------------- 4. 模型推理函数 --------------------------
def infer_blip(image, question, model_info):
"""BLIP模型推理"""
processor = model_info["processor"]
model = model_info["model"]
inputs = processor(image, question, return_tensors="pt").to(DEVICE)
start_time = time.time()
outputs = model(**inputs)
pred = processor.decode(outputs.logits.argmax(dim=1), skip_special_tokens=True)
latency = time.time() - start_time
return pred, latency
def infer_blip2(image, question, model_info):
"""BLIP-2模型推理"""
processor = model_info["processor"]
model = model_info["model"]
inputs = processor(image, question, return_tensors="pt").to(DEVICE)
start_time = time.time()
outputs = model.generate(**inputs, max_new_tokens=20)
pred = processor.decode(outputs[0], skip_special_tokens=True)
latency = time.time() - start_time
return pred, latency
def infer_gpt4v(image, question):
"""GPT-4V API推理"""
# 保存图片到临时文件
temp_img_path = "./temp_image.jpg"
image.save(temp_img_path)
start_time = time.time()
response = openai_client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{"role": "user", "content": [
{"type": "text", "text": question},
{"type": "image_url", "image_url": {"url": f"file://{os.path.abspath(temp_img_path)}"}}
]}
],
max_tokens=50
)
latency = time.time() - start_time
pred = response.choices[0].message.content.strip()
os.remove(temp_img_path)
return pred, latency
def infer_gemini(image, question):
"""Gemini Pro API推理"""
start_time = time.time()
response = gemini_model.generate_content([question, image])
latency = time.time() - start_time
pred = response.text.strip()
return pred, latency
# -------------------------- 5. 执行推理(批量测试)--------------------------
print("\n=== 开始推理测试 ===")
results = []
for idx, sample in enumerate(samples[:10]): # 取前10个样本测试(加快速度)
print(f"\n样本 {idx+1}/{10}")
image = sample["image"]
question = sample["question"]
gt = sample["ground_truth"]
# 遍历所有模型推理
for model_name in MODEL_CONFIGS.keys():
try:
if model_name == "BLIP":
pred, latency = infer_blip(image, question, models[model_name])
elif model_name == "BLIP-2":
pred, latency = infer_blip2(image, question, models[model_name])
elif model_name == "GPT-4V" and OPENAI_API_KEY:
pred, latency = infer_gpt4v(image, question)
elif model_name == "Gemini Pro" and GEMINI_API_KEY:
pred, latency = infer_gemini(image, question)
else:
continue
# 简单准确率判断(模糊匹配)
correct = 1 if gt.lower() in pred.lower() else 0
results.append({
"sample_idx": idx+1,
"model": model_name,
"prediction": pred,
"ground_truth": gt,
"correct": correct,
"latency": latency
})
print(f" {model_name}: {pred} (GT: {gt}, 耗时: {latency:.2f}s, 正确: {correct})")
except Exception as e:
print(f" {model_name} 推理失败: {str(e)}")
# 转换为DataFrame便于分析
results_df = pd.DataFrame(results)
# -------------------------- 6. 结果可视化(多图对比)--------------------------
plt.rcParams['font.sans-serif'] = ['DejaVu Sans'] # 英文图例,避免字体问题
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle("Multimodal Model Comparison (VQA Task)", fontsize=16)
# 颜色配置
colors = ["#FF6B6B", "#4ECDC4", "#45B7D1", "#96CEB4"]
model_names = results_df["model"].unique()
# 子图1:各模型准确率对比(柱状图)
ax1 = axes[0, 0]
acc_df = results_df.groupby("model")["correct"].mean().reset_index()
bars = ax1.bar(acc_df["model"], acc_df["correct"], color=colors[:len(acc_df)], alpha=0.8)
ax1.set_xlabel("Model")
ax1.set_ylabel("Accuracy")
ax1.set_title("Accuracy Comparison")
ax1.set_ylim(0, 1.0)
# 添加数值标签
for bar, acc in zip(bars, acc_df["correct"]):
ax1.text(bar.get_x() + bar.get_width()/2., bar.get_height() + 0.02,
f"{acc:.3f}", ha="center", va="bottom")
# 子图2:各模型响应时间对比(箱线图)
ax2 = axes[0, 1]
latency_data = [results_df[results_df["model"] == m]["latency"].values for m in model_names]
bp = ax2.boxplot(latency_data, labels=model_names, patch_artist=True)
for patch, color in zip(bp["boxes"], colors[:len(model_names)]):
patch.set_facecolor(color)
patch.set_alpha(0.8)
ax2.set_xlabel("Model")
ax2.set_ylabel("Latency (seconds)")
ax2.set_title("Response Time Distribution")
ax2.grid(True, alpha=0.3)
# 子图3:各样本准确率对比(热力图)
ax3 = axes[1, 0]
sample_acc_df = results_df.pivot_table(
index="sample_idx", columns="model", values="correct", fill_value=0
)
im = ax3.imshow(sample_acc_df.values, cmap="RdYlGn", aspect="auto", vmin=0, vmax=1)
ax3.set_xticks(range(len(sample_acc_df.columns)))
ax3.set_xticklabels(sample_acc_df.columns, rotation=45)
ax3.set_yticks(range(len(sample_acc_df.index)))
ax3.set_yticklabels(sample_acc_df.index)
ax3.set_xlabel("Model")
ax3.set_ylabel("Sample Index")
ax3.set_title("Accuracy per Sample (1=Correct, 0=Incorrect)")
# 添加颜色条
plt.colorbar(im, ax=ax3, shrink=0.8)
# 子图4:准确率vs响应时间散点图(权衡分析)
ax4 = axes[1, 1]
for i, model in enumerate(model_names):
model_data = results_df[results_df["model"] == model]
acc = model_data["correct"].mean()
avg_latency = model_data["latency"].mean()
ax4.scatter(avg_latency, acc, s=200, color=colors[i], label=model, alpha=0.7)
# 添加模型名称标签
ax4.annotate(model, (avg_latency, acc), xytext=(5, 5), textcoords="offset points")
ax4.set_xlabel("Average Latency (seconds)")
ax4.set_ylabel("Accuracy")
ax4.set_title("Accuracy vs Latency Trade-off")
ax4.grid(True, alpha=0.3)
ax4.legend()
# 调整布局
plt.tight_layout()
# 保存图片(服务器环境)
plt.savefig("./multimodal_model_comparison.png", dpi=300, bbox_inches="tight")
print("\n=== 结果图已保存为 multimodal_model_comparison.png ===")
# -------------------------- 7. 结果汇总输出 --------------------------
print("\n=== 推理结果汇总 ===")
print(acc_df.to_string(index=False))
print("\n各模型平均响应时间:")
latency_df = results_df.groupby("model")["latency"].mean().reset_index()
print(latency_df.to_string(index=False))
代码关键说明
- 数据集:自动下载VQA(视觉问答)数据集,取50个样本(前10个测试),无需手动准备;
- 模型支持:
- 开源模型:BLIP(基础款,8GB显存可跑)、BLIP-2(4bit量化,12GB显存可跑);
- API模型:GPT-4V、Gemini Pro(无GPU也可跑,需自行申请免费API key);
- 推理任务:统一测试“图片中的主要物体是什么?”,便于对比准确率;
- 结果可视化:自动生成4个子图(准确率柱状图、响应时间箱线图、样本准确率热力图、准确率- latency散点图),全面对比模型性能;
- 小白友好:代码注释详细,参数可直接默认,无需调参经验。
五、小白入门建议
- 无GPU/低预算:优先用Gemini Pro API(免费额度充足,多模态支持好);
- 有12GB显存:尝试BLIP-2(开源免费,效果接近API模型);
- 有8GB显存:先跑BLIP(轻量化,熟悉多模态流程);
- 专业场景:GPT-4V(推理能力最强,但需付费API);
- 调参技巧:BLIP-2可调整
max_new_tokens(生成答案长度)、temperature(随机性),API模型可通过调整max_tokens控制输出长度。
六、总结
四大多模态模型代表了“从基础到进阶”的技术演进:BLIP奠定了图文对齐的基础,BLIP-2通过Q-Former实现了与LLM的高效融合,GPT-4V将图文推理能力推向顶峰,Gemini Pro则以统一架构降低了多模态部署门槛。
通过本文的原理推导、公式解析和零门槛实操项目,相信你已经掌握了多模态模型的核心逻辑。不妨从API调用(Gemini Pro)开始,快速感受多模态的魅力,再逐步尝试本地部署BLIP/BLIP-2,深入理解图文融合的底层机制!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)