
CoRL‘25最佳论文 | 通研院&宇树UniFP:软硬件解耦新思路,为具身智能开启“无感”交互时代!-研梦非凡
“软硬件解耦”思路,为机器人领域提供了一个通用、低成本且高效的力位混合控制框架
【来源:JOJO极智算法微信公众号】
近日,机器人学习顶会CoRL 2025公布了本届的最佳论文奖(Best Paper Award)。由北京通用人工智能研究院(通研院)、宇树科技(Unitree)和北京邮电大学的华人团队带来的研究成果“Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation”获此殊荣。
该研究直面机器人物理交互的核心难题,提出了首个无需外部力传感器,即可实现足式机器人力与位置统一控制的通用策略(Unified Force-Position Policy, UniFP)。这一突破性框架让机器人仅凭自身的运动状态就能“感知”并与环境进行复杂的物理交互,并在多个真实世界任务中取得了惊人的效果。

图1:我们为足式机器人提出了一个统一的力—位置策略,它能够实现多样的移动操作行为,包括位置跟踪、施加力以及柔顺交互(上图)。当用于模仿学习数据收集时,该策略学习到的内部力估算器能提供力感知演示,从而在无需外部力传感器的情况下,提升模型在富含接触任务中的性能(中图)。在四足和人形机器人上的实验结果证明了该策略的通用性和鲁棒性(下图)。
1. 机器人交互的“硬骨头”:力与位置的协同难题
长期以来,让机器人在现实世界中完成擦拭、开门、搬运等任务,一直面临着一个核心挑战:如何协同控制力与位置。
传统方法的局限:传统的机器人控制方法通常依赖精确的位置控制,但在需要与环境发生持续接触的任务中(如擦拭黑板),这种方法远远不够。机器人无法感知接触力,要么“用力”过猛损坏物体,要么接触不到位导致任务失败。
硬件的束缚:为了解决这个问题,一种方案是安装昂贵且易于损坏的力/力矩传感器。这不仅大大增加了机器人的成本和复杂性,也降低了其在现实环境中应用的鲁棒性。
模仿学习的瓶颈:近年来流行的模仿学习方法,虽然能让机器人学会复杂技能,但由于缺乏力传感数据,收集到的演示数据大多只包含轨迹信息,丢失了最关键的“接触力道”。这导致学习出的策略在需要细腻力控制的场景中表现不佳。
如何摆脱硬件束缚,让机器人学会“察言观色”,智能地控制自己的“力道”,成为了具身智能领域一块难啃的“硬骨头”。
2. 核心解法:无需传感器的“统一力位策略”
该研究团队的思路是:既然人类可以不依赖皮肤上的精密仪器,仅凭肢体的反馈就能感知和控制力量,那么机器人是否也能做到?
答案是肯定的。他们通过强化学习,在Isaac Gym模拟器中训练出一个统一的力—位置控制策略。
巧妙的力估算器 (Estimator):该策略的核心是一个巧妙的“力估算器”。它通过分析机器人自身的历史状态(如关节位置、速度、上一时刻的动作等),学习并预测出当前末端执行器和身体所受到的外部作用力。这相当于为机器人训练出了一个“软传感器”,用算法和数据弥补了硬件的缺失。
统一的控制框架:基于估算出的力,单一的策略模型就能统一处理多种复杂的任务指令。无论是精确的位置跟踪、施加特定的力,还是在“拔河”等人机交互中展现柔顺性,这个统一策略都能胜任。它通过一个统一的数学公式,将位置指令、力指令和外部干扰力整合在一起,动态计算出机器人下一步的目标位置或速度。
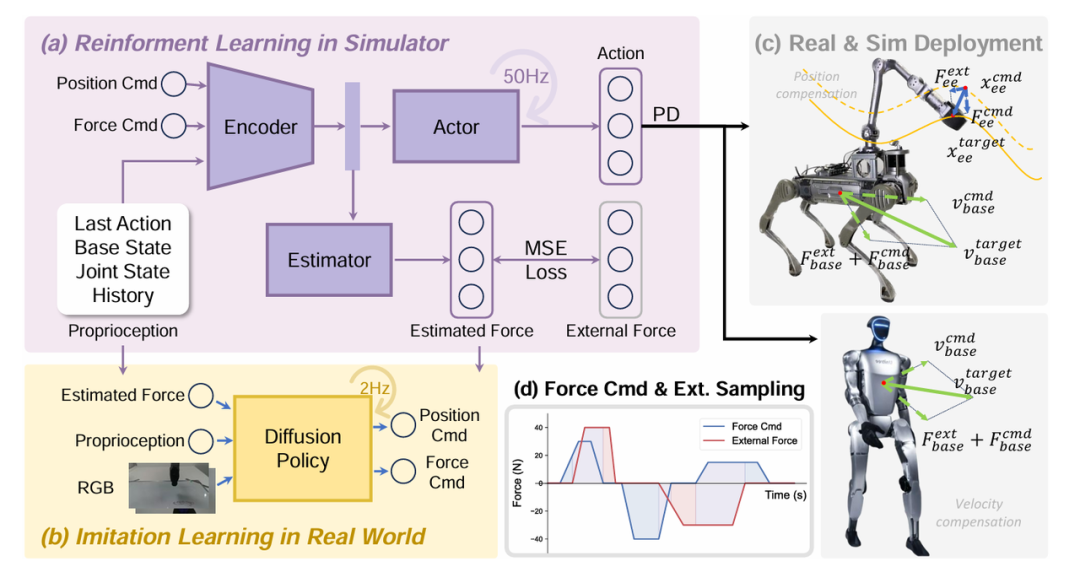
(a) 通过强化学习训练的统一力—位置策略架构,用于在外部干扰下跟踪位置和力指令。(b) 使用我们学习到的策略收集演示数据,赋能了无需力传感器的力感知模仿学习。(c) 在末端执行器和机器人基座上建模力交互的位置和速度补偿示意图。(d) 策略训练期间,用于模拟多样化接触场景的采样力指令和干扰的可视化。
3. 惊人成果:从模拟到现实的全面验证
该研究不仅提出了巧妙的理论,更通过一系列详尽的实验证明了其在模拟和真实世界中的强大能力。
A. 真实世界的精准力控
团队在真实的机器人上进行了直接的力控制测试。通过指令机器人施加从0N到60N不等的力,并使用测力计进行测量,结果显示,机器人的实际输出力与指令值的平均误差在10N以内,力估算器的误差也在5-10N之间,足以满足大多数操作任务的需求。
B. 赋能模仿学习,成功率飙升39.5%
这是本次研究最具影响力的成果之一。团队利用UniFP策略创建了一个力感知数据采集流程。在人类专家遥控机器人完成任务时,力估算器会同步记录下接触力数据。
在擦黑板、开/关柜门、以及视觉被遮挡时开抽屉这四个极具挑战性的真实任务中,使用这种包含力信息的“高质量”数据训练出的模仿学习模型,相比仅使用位置信息的传统方法,平均成功率惊人地提升了约39.5% 。
擦黑板:无力信息的策略无法稳定接触,而力感知策略能持续施加恰当的压力,高效完成任务。
开柜门:对于需要精准按压才能触发的“反弹式”柜门,视觉难以判断,但力感知能精确完成触发动作。 遮挡开抽屉:当视觉被遮挡时,传统方法成功率骤降至30%,而力感知策略凭借接触反馈,将成功率提升至76%。
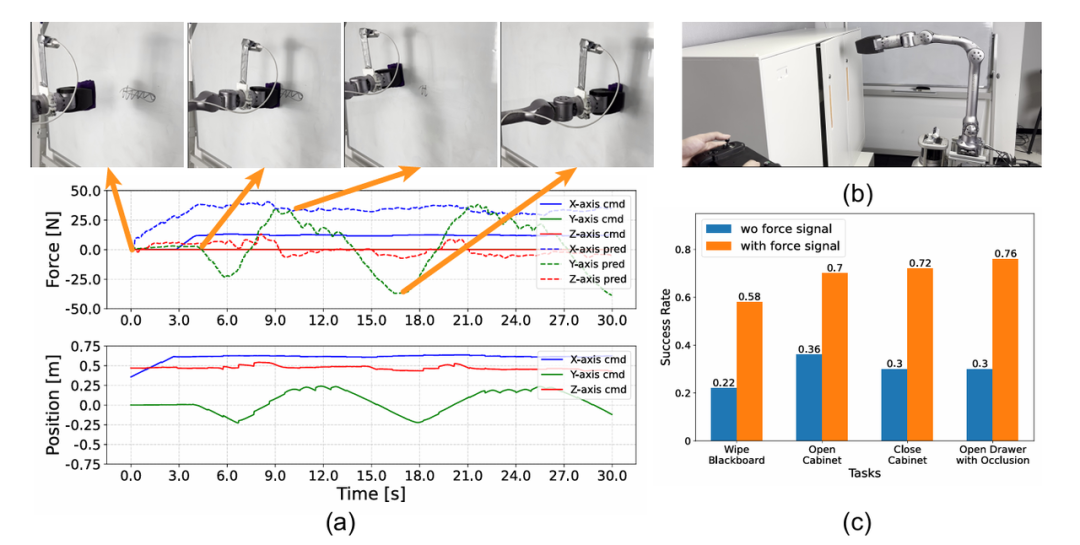
(a)在擦黑板任务中,力感知模仿策略输出的位置和力指令的时间序列图。(b)数据采集过程可视化。(c)在四个任务上,我们的策略(橙色)与仅依赖视觉的基线策略(蓝色)在50次试验中的性能对比。
C. 强大的通用性:跨越平台与任务
UniFP策略的强大之处还在于其通用性。
跨平台验证:该研究在两种形态和结构差异巨大的机器人——Unitree B2-Z1 四足机械臂和Unitree G1 人形机器人——上都进行了验证并取得了成功。
多技能展示:仅用一个策略,机器人就学会了多种高级技能。例如,四足机器人能通过施加25N的力来举起2.5kg的重物;在被推搡时,机器人能柔顺地后退(力跟踪);在“拔河”中,它能根据拉力调整全身姿态(阻抗控制)。
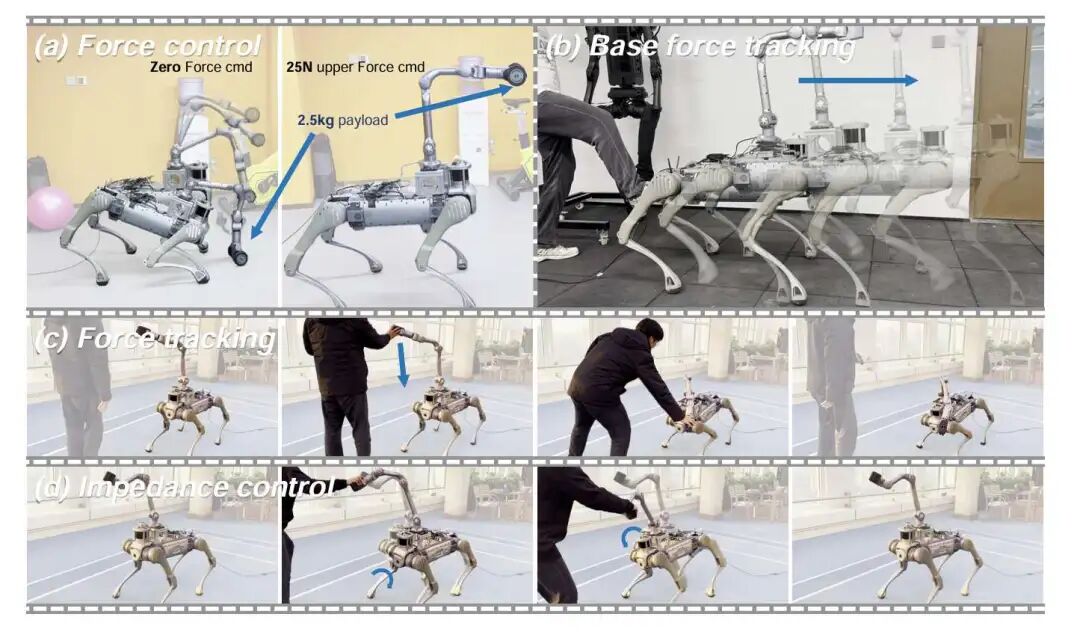
(a)力控制:机器人在接收到25N的力指令后,能抵消重力以支撑负载物。(b)基座力跟踪:机器人对基座的推力做出柔顺反应,实现了直观的人类引导。(c)力跟踪:机器人通过最小化外部力交互来跟踪一个零力指令。(d)阻抗控制:机器人调整其全身姿态以对抗和顺从外部干扰。
4.不止于“力”:为具身智能开启的新可能
这项荣获CoRL'25最佳论文奖的研究,通过一种创新的“软硬件解耦”思路,为机器人领域提供了一个通用、低成本且高效的力位混合控制框架。它不仅让机器人能够在没有力传感器的情况下与世界进行更智能、更安全的物理交互,还为模仿学习的数据采集开辟了新范式,解决了该领域的长期痛点。 尽管研究团队也指出,该方法在高频交互和工作空间边缘的力估算精度仍有提升空间,但这无疑是通向更强大、更通用的具身智能道路上迈出的坚实一步。
论文信息
论文标题: Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation
作者:Peiyuan Zhi, Peiyang Li, Jianqin Yin, Baoxiong Jia, Siyuan Huang
单位:北京通用人工智能研究院(BIGAI),宇树科技(Unitree Robotics),北京邮电大学
论文链接: https://arxiv.org/abs/2505.20829v2
项目主页:https://unified-force.github.io/

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)