
多模态大模型:视觉模型与LLM的结合之路二:MiniGPT-4、QWen-VL
QWenVL提出来能力增强的训练阶段,并使用了B级别的对齐训练数据,M级别的能力增强数据和K级别的指令跟随数据,训练多模态大模型。能力增强训练可能较为耗费资源但能极大程度提升模型效果。后续自己构建大模型时可以考虑构建和下游任务接近的训练任务用于能力增强训练。
本文首发于微信公众号:人工智能与图像处理
多模态大模型:视觉模型与LLM的结合之路二:MiniGPT-4、QWen-VL (qq.com)
一、上期回顾
上期我们介绍了多模态大模型的一般架构和首个将视觉模型与大模型结合的尝试Blip2和LLaVA。其中Blip2的贡献主要在模型结构上,明确了将视觉特征通过一系列变换对齐并加入到大模型的Input Embedding中可以让LLM看到图片。LLaVA的贡献主要在数据上,该文给出了利用chat-gpt等纯文本LLM + 图文对(图片,对该图片的一段描述文本)造多轮对话、指令微调数据集的方法,并使用两阶段的训练方法(大量单一的数据对齐图像特征 + 少量多样的数据去给出多轮对话能力)让模型拥有了基于图片的多轮对话能力。
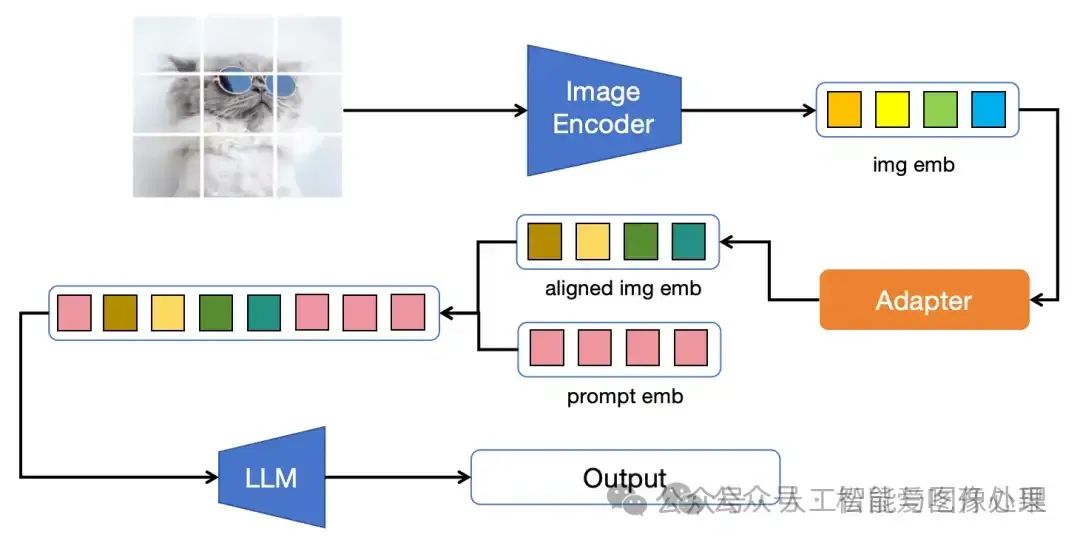
图1:图像与大模型的主流结合方式。(1)将图片经过一个Pretrained VIT,获取视觉特征。(2)将该视觉特征通过某种变换层(Adapter)对齐到大模型 Input Embedding的维度。(3)将对齐后的视觉特征concat到Input Embedding,输入到大模型(Large Language Model, LLM)
本文要介绍的是LLaVA的同期工作:MiniGPT-4。
二、MiniGPT-4
Mini-GPT4同样是为了将多轮对话,逻辑推理等能力,融入到多模态大模型中,与LLaVA不同的是,该文提出的Adapter架构,参数量较小,模型收敛较快,只需4块A100训练1Day。
2.1 Adapter结构
Mini-GPT4沿用了Blip2的Adapter结构,和Blip2的预训练权重。其将图片获取到的img emb通过Q-Former(虚线部分)将seq_len变为指定的长度后,通过全连接层(蓝色部分)对齐到大模型的模型。
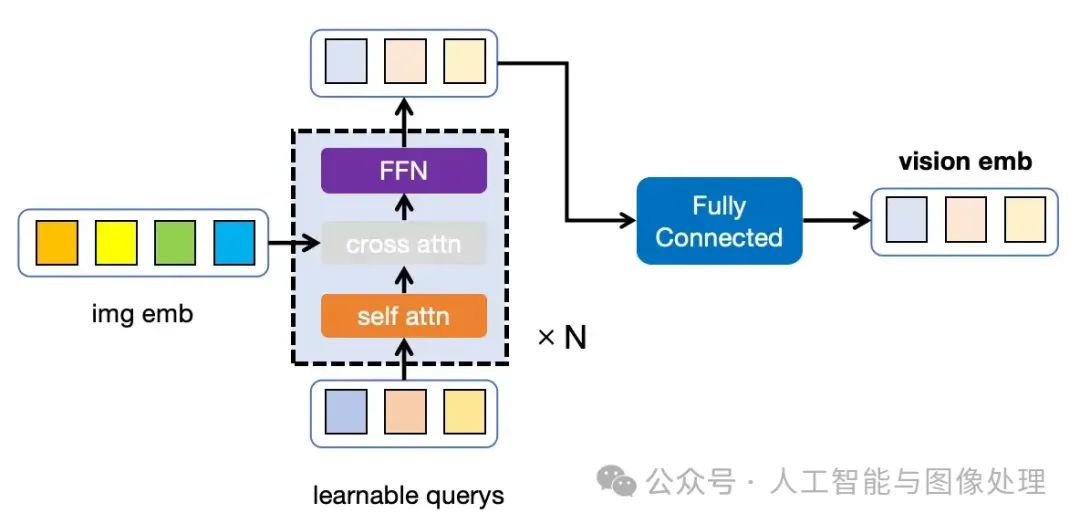
图2:Blip2/MiniGPT-4的Adapter结构,由Q-Former(虚线框)和全连接层(蓝色部分)组成。在MIni-GPT4的训练过程中,仅有全连接层参与训练,其他参数均不更新。
训练MiniGPT-4的过程中,Vision Encoder、LLM和Q-Former的权重全部被冻住,只有全连接层(蓝色部分)参与训练。这也是MiniGPT-4训练速度较快的根源所在。
2.2 模型训练
MiniGPT-4的视觉部分来自Blip2(下图虚线框),LLM部分来自LLaMA(与Blip2不同),因此采用了两阶段的训练方式,第一阶段使用大量数据将视觉模型与LLM进行对齐,第二阶段使用少量、多样的数据,提升模型的理解图片能力。
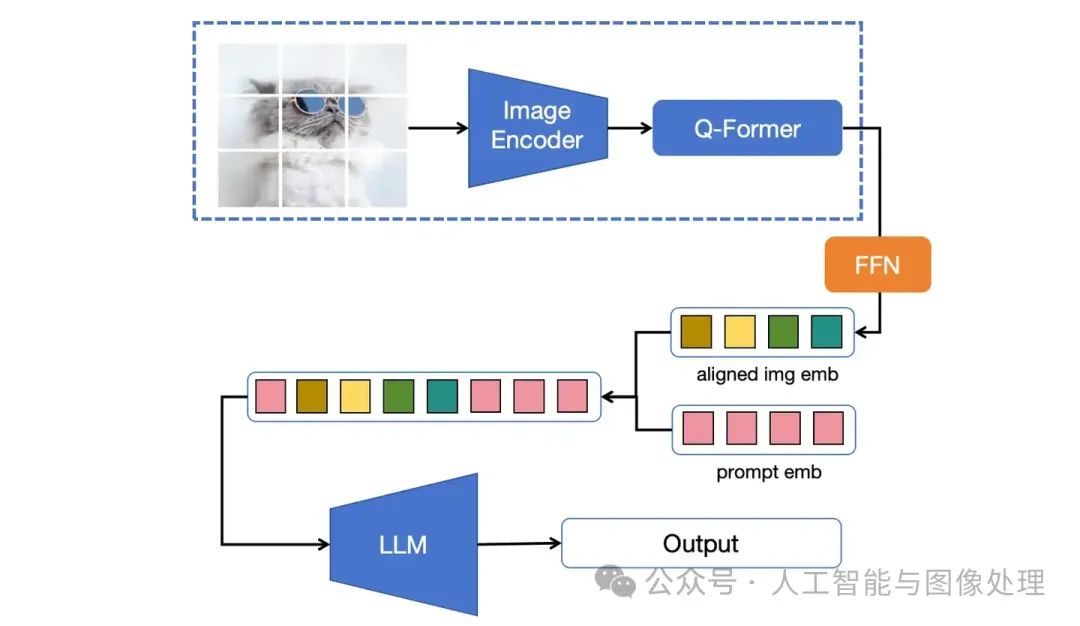
MiniGPT-4的模型结构,其中Q-Former和FFN为Adapter。图中虚线框来自Blip2的模型权重,LLM来自LLaMA的模型权重。模型训练时只训练图中橙色部分,其他权重均固定不变。
2.2.1 特征对齐训练
-
训练任务:图生文,输入图片,LLM需要生成该图片的一个描述。
-
训练数据:LAION, SBU, Conceptual Caption共三个图文对数据集,每条数据是一张图片和该图片对应的一段描述。
-
训练设置:训练20k step,batchsize256,训练数据约5M,4卡A100(80G) * 10小时。
训练完成后,模型输出效果较为一般,会输出只言片语,或者与图片完全不相关的内容。
2.2.2 图像理解训练
Mini-GPT4和LLaVA是同时期的作品,因此Mini-GPT4训练时仍然没有指令微调数据集。为此,论文作者提出了如下造训练数据的方法。
-
从Conceptual Caption中筛选出5k的图片,利用Prompt和第一阶段训练过的模型,输出图像的详细描述。
-
使用Chat-GPT对这些详细描述进行改写,改写为通畅,流利的描述
-
手动去掉Chat-GPT中多余的输出,如”改写后的描述为:“
该文使用这5K条高质量数据继续训练模型,在Batch_Size = 12,单卡A100上训练了7分钟。
2.3 模型效果

MiniGPT-4的模型效果
三、小结
模型训练上:MiniGPT-4全篇只训练单层FFN。在有限的资源下完成了视觉特征和大模型的融合。让小厂也拥有了训练多模态大模型的能力;该模型只训练Img-Caption任务(输出图像的一个描述),但已经拥有了部分指令跟随的能力。可能是因为大模型权重并未做任何更新导致的。
数据集构造上:使用了SelfInstruct的数据集构造方法,提供了构造数据集的另一个思路。
----------------------------分割线---------------------------------
一、上期回顾
上期我们介绍了多模态大模型的一般架构和首个将视觉模型与大模型结合的尝试Mini-GPT4。Mini-GPT4给出了如何利用预训练模型(视觉Encoder 和 预训练LLM),使用少量资源(4卡A100训练半天),构建多模态大模型的方法。
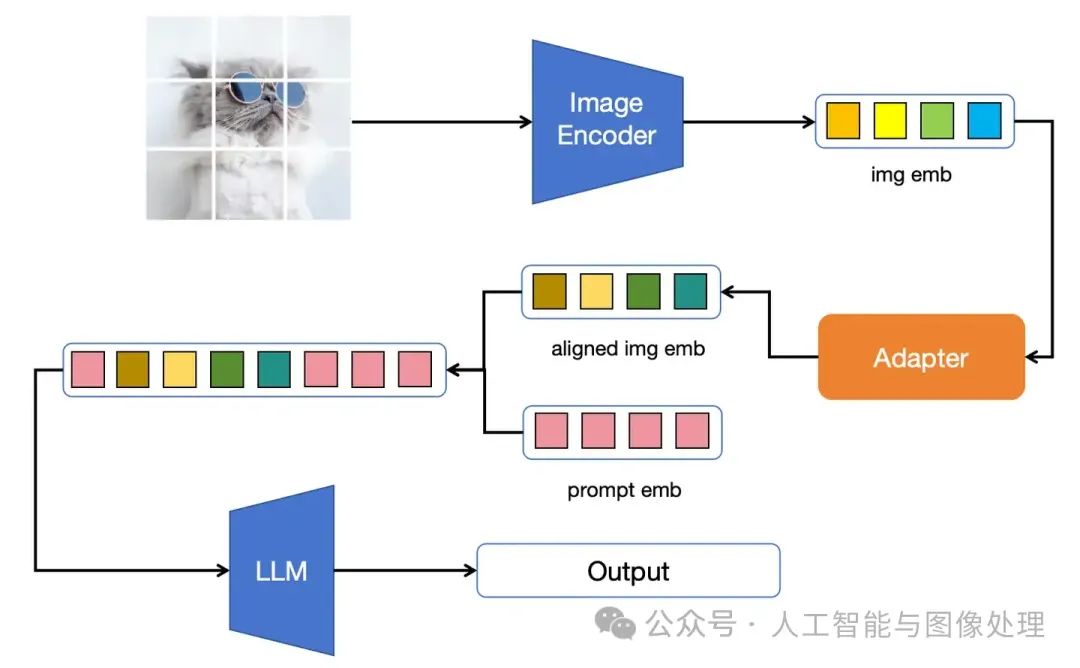
图1:图像与大模型的主流结合方式。(1)将图片经过一个Pretrained VIT,获取视觉特征。(2)将该视觉特征通过某种变换层(Adapter)对齐到大模型 Input Embedding的维度。(3)将对齐后的视觉特征concat到Input Embedding,输入到大模型(Large Language Model, LLM)
本文要介绍的是目前(2024.1)最好的中文开源多模态大模型QWen-VL,该模型可以进行多图多轮对话,识别图中文字和给出图中某物体的准确坐标。
二、QWenVL
QWenVL除了在中文数据上表现较好之外,还能处理多图多轮对话任务,输出图像中物体的位置(以文字格式给出检测框),在TextVQA,OCRVAQ等多个任务上均取得了SOTA的效果。该文提出来 能力增强训练阶段,并在该阶段利用多种训练任务让模型拥有了OCR、目标检测等多个能力,笔者认为,该文的主要贡献在训练任务的设计上。
2.1 输入输出格式
之前的多模态大模型通常是基于单个图片做多轮对话,且不能给出图中某个物体的具体位置。QWenVL更改了模型的输入输出格式,并用标记语言(类似html)和Tokenizer来适配多图多轮对话和目标检测任务。Assistant后面为语言模型需要生成的内容,其他内容均为Prompt。为了方便读者理解,下述例子与QWenVL的真实输入输出略有出入。
其他多模态大模型的输入输出格式, "..."表示图1中的aligned img emb
<img>...</img>
User:请给出图中的动物的种类
Assistant:熊猫
User:请给出图中共有多少只熊猫
Assistant:5个
QWenVL中适配多张图片的输入输出格式
User: Picture 1<img>img_path_1</img>, 请给出图中动物的种类
Assistant:老虎
User: Picture 2<img>img_path_2</img>, 请判断上述两张图中共有多少只动物
Assistant:10只
User: 请给出图1中老虎的位置
Assistant:<ref>老虎</ref><box>(10,12),(120,130)</box>
对多图的处理
QwenVL的Tokenizer在接受Prompt的时候会自动识别Prompt中表示图像地址的部分,然后将该地址pad到固定长度256。在模型进行forward的时候,会识别图片地址的位置并通过图1中的Image Encoder和Adapter将图片转为长度为256的序列(aligned img emb),并将该序列替换掉Prompt中的图片地址。

图2:QWenVL的Tokenizer处理图片的示例。为方便读者理解,图中例子与QWenVL的真实输入输出略有出入。
对目标检测任务的适配
QWenVL还能给出图中物品的类别和坐标,表示方法为
<ref>类别</ref><box>(min_x,min_y),(max_x,max_y)</box>
QWenVL用特定格式的输出表示检测框位置和被检测物体的类别,其坐标直接使用Token表示,坐标是将图片进行等比例缩放直到最长边为1000后图片上的坐标。这种使用Token表示坐标的方式非常反直觉,但确实能Work。
2.2 Adapter结构
QWenVL使用FC层和单层Cross Attention作为将视觉模态Adapter。 与之前介绍的Adapter不同,QWen先使用FC层将图像特征的维度对齐到大模型,再使用Cross Attention将图像特征的长度变为指定的长度,其先使用FC,再使用Cross Attention的做法可能是为了增加Adapter的参数量。
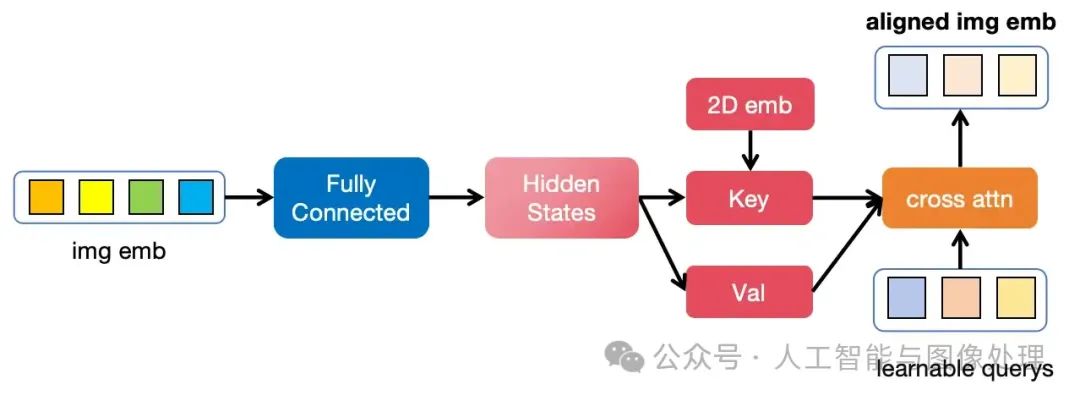
图3:QwenVL的Adapter结构,图中的Key、Val和Hidden States数值上完全相同
除此之外,QWenVL的Adapter还在图像的位置信息上做了一点调整。之前的多模态大模型使用的视觉Encoder通常是将图像的patch按从上到下,从左到右的顺序排序成一个序列(图2中的img emb),并按照序列的顺序给图像加入位置信息emb(1D位置emb)。除此之外,此前介绍的多模态大模型并未关注图像emb的位置信息。
除了来自视觉模型的1D位置emb,QWenVL还在Adapter中的cross attn中加入了2D位置emb。其具体做法是将2D位置emb加到cross attn中的Key上,2D位置emb表示该patch是图像分块后的第几行和第几列,是通过分别计算行、列的1D位置emb再concat到一起得到的,其中行、列的1D位置emb来自sin位置emb。显然的,加入的2D位置emb对于不同长宽比的图片会更加友好,虽然QWenVL输入的图片有着固定的大小,但这可能是为后续的QWenVL-Plus/QWenVL-Max打下的基础。
2.3 模型训练
与LLaVA,Mini-GPT4不同QWenVL的训练被分为三个阶段,分别是特征对齐训练,能力增强训练和指令跟随训练,不同阶段的模型可训练参数也各不相同。
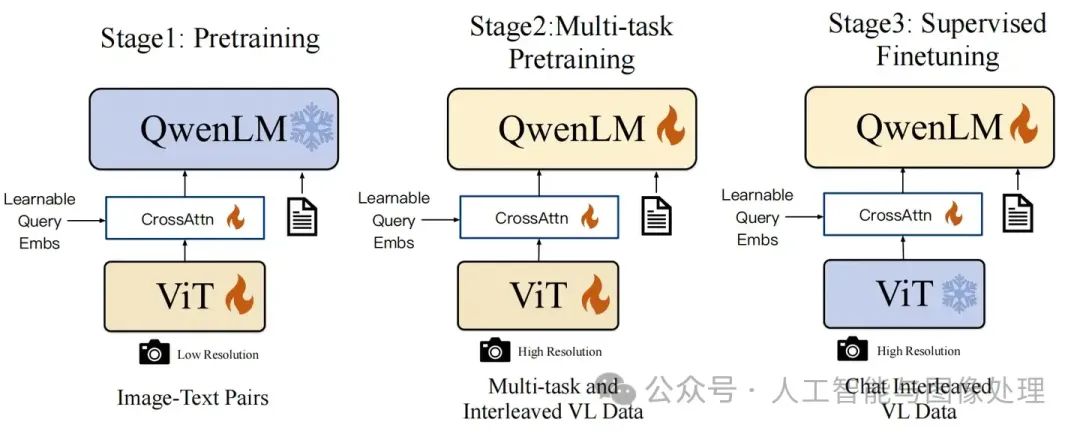
图4:QWenVL不同训练阶段的可训练参数,带火花表示该参数可训练,带雪花表示不可训练
2.3.1 特征对齐训练
特征对齐训练是使用大量的图文对数据(img-caption)将视觉Encoder对齐到LLM上去,让LLM能看到图片上的信息。其特点是数据量大,文字内容小(seq_len较小,256图像 + 512LLM),训练速度快(因为seq_len小,所以训练速度相对较快)。QWenVL从各种开源数据集中收集了1.4B的数据,其中77.3%为英文数据,22.7%为中文数据,具体数据来源见表1。
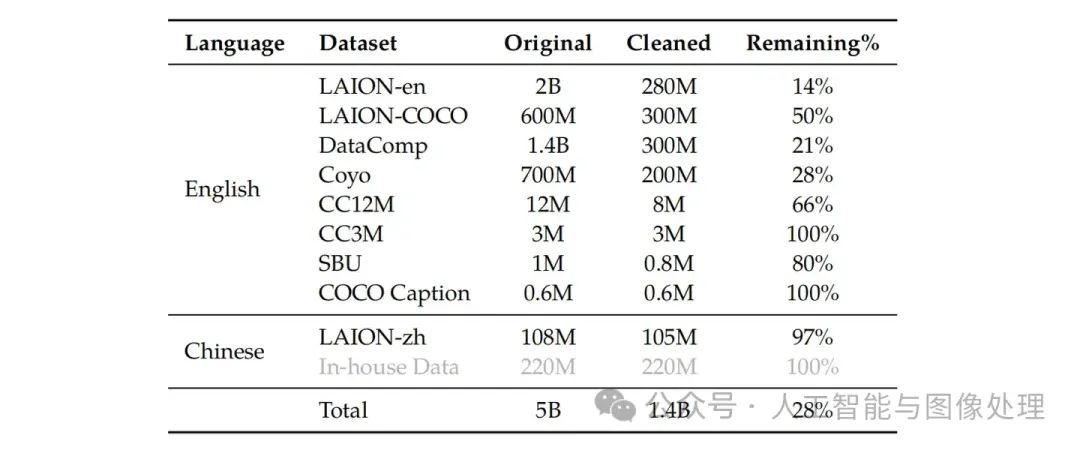
表1:QWenVL特征对齐训练数据集来源
训练时图像被缩放至224*224的大小,batch-size 为30720,训练了50K步,训练时Vision Encoder和Adapter的权重有更新。其输入输出格式如下
User: Picture 1<img>tiger.jpg</img>
Assistant:5只老虎在大草原上捕猎
其训练过程中的Loss,Img Caption指标和DocVQA指标见下图:
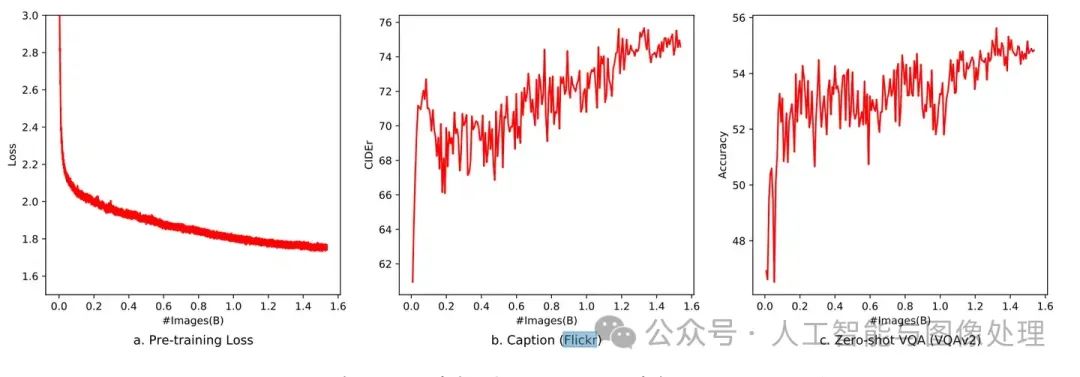
图5:特征对齐预训练的训练过程指标,横轴是训练样本数。左边是训练损失,中间是在Filckr img-caption数据集上的评价文本相似性的指标(CIDEr),右边是在VQAv2数据集上DocVQA的准确率
和Mini-GPT4类似,仅仅训练Img-Caption任务即可提升VQA的准确率。其能力可能来自冻住的LLM有一定的推理能力。
2.3.2 能力增强训练
在将Image Encoder对齐到大模型后,QWenVL将输入的图像大小从224 * 224 调整到 448 * 448,并使用了7个不同的训练任务来增强模型的能力。模型的全部参数均参与训练,训练的seq_len为2048。
- Captioning:
-
训练数据:LAION-en & zh, DataComp, Coyo, CC12M & 3M, SBU, COCO, 自有数据共19.7M
-
训练任务:输入图片,给出图片的一个描述
-
输入输出格式:
-
User: <img>lion.jpg</img>
-
Assistant: 4只狮子在草原上捕食
-
-
- VQA:
-
训练数据:GQA, VGQA, VQAv2, DVQA, OCR-VQA, DocVQA, TextVQA, ChartQA, AI2D 共3.6M
-
训练任务:输入图片,给出一个和图片有关的问题,要求模型给出问题的答案
-
输入输出格式:
-
User:<img>human.jpg<img>图上的人穿什么颜色的衣服
-
Assistant:蓝色
-
-
- Grounding:
-
训练数据: GRIT
-
训练任务:输入图片和图中某个物体的位置,要求模型给出该物体的描述
-
输入输出格式:
-
User:<img>human.jpg<img><ref>This</ref><box>(360,542),(476,705)</box> is
-
Assistant:Yellow cross country ski racing gloves
-
-
- Referring Grounding
-
训练数据:GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg,共8.7M
-
训练任务:输入图片和图中某个物体的位置,要求模型给出该物体的描述
-
输入输出格式:
-
User:<img>VG_100K_2/3.jpg</img><ref>the ear on a giraffe</ref>
-
Assistant:Yellow cross country ski racing gloves
-
-
- Grounded Cap
-
训练数据:GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg,共8.7M
-
训练任务:描述图片内容,并在描述时给出物体的位置
-
输入输出格式:
-
User:<img>coyo700m/1.jpg</img>Generate the caption in English with grounding:
-
Assistant: Beautiful shot of <ref>bees</ref><box>(661,612),(833,812)</box><box>(120,555),(265,770) </box> gathering nectars from <ref>an apricot flower</ref><box>(224,13),(399,313) </box>
-
-
- OCR
-
训练数据:SynthDoG-en & zh, Common Crawl pdf & HTML,共24.8M
-
训练任务:识别图中的文字
-
输入输出格式:
-
User:<img>synthdog/1.jpg</img>OCR with grounding:
-
Assistant: <ref>It is managed</ref> <quad> (568,121), (625,131), (624,182), (567,172)</quad>...
-
-
- Pure-text Autoregression
-
训练数据:自建数据集,共7.8M
-
训练任务:保证MLM的效果不退化
-
该阶段主要是通过7个不同的训练任务,训练模型的读图能力,逻辑推理能力(VQA),识别物体位置的能力(Grounding)和OCR能力。
2.3.3 指令跟随训练
该阶段主要是让模型拥有聊天的能力,模型开放Adapter和LLM的参数用于训练。QWenVL使用了基于LLM生成多模态的对话数据,并保证对话内容和图像内容相关,指令微调数据量为359K,论文中并未具体给出数据生成的方法。数据集的格式如下
<im_start>user
Picture 1: <img>vg/VG_100K_2/649.jpg</img>What is the sign in the picture?<im_end>
<im_start>assistant
The sign is a road closure with an orange rhombus.<im_end>
<im_start>user
How is the weather in the picture?<im_end>
<im_start>assistant
The shape of the road closure sign is an orange rhombus.<im_end>
三、总结
QWenVL提出来能力增强的训练阶段,并使用了B级别的对齐训练数据,M级别的能力增强数据和K级别的指令跟随数据,训练多模态大模型。能力增强训练可能较为耗费资源但能极大程度提升模型效果。后续自己构建大模型时可以考虑构建和下游任务接近的训练任务用于能力增强训练。


电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)