
【GitHub项目推荐--OCRFlux:革命性的多模态PDF转Markdown工具】
OCRFlux 是一个由ChatDOC团队开发的多模态大语言模型工具包,专门用于将PDF和图像转换为干净、可读的纯Markdown文本。该工具在PDF到Markdown转换领域实现了显著的性能突破,将当前技术水平提升到了一个新的高度。🔗 GitHub地址🚀 核心价值:PDF转换 · Markdown生成 · 多模态AI · 跨页合并 · 开源工具项目背景:文档数字化:文档数字

转换效果:
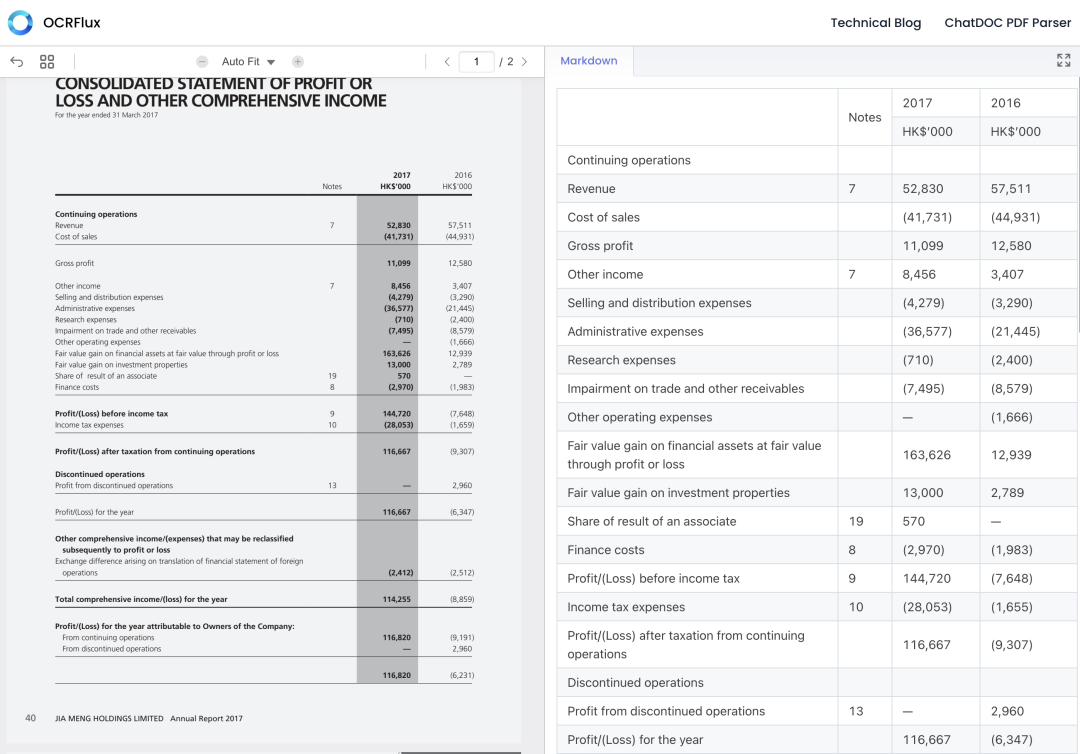
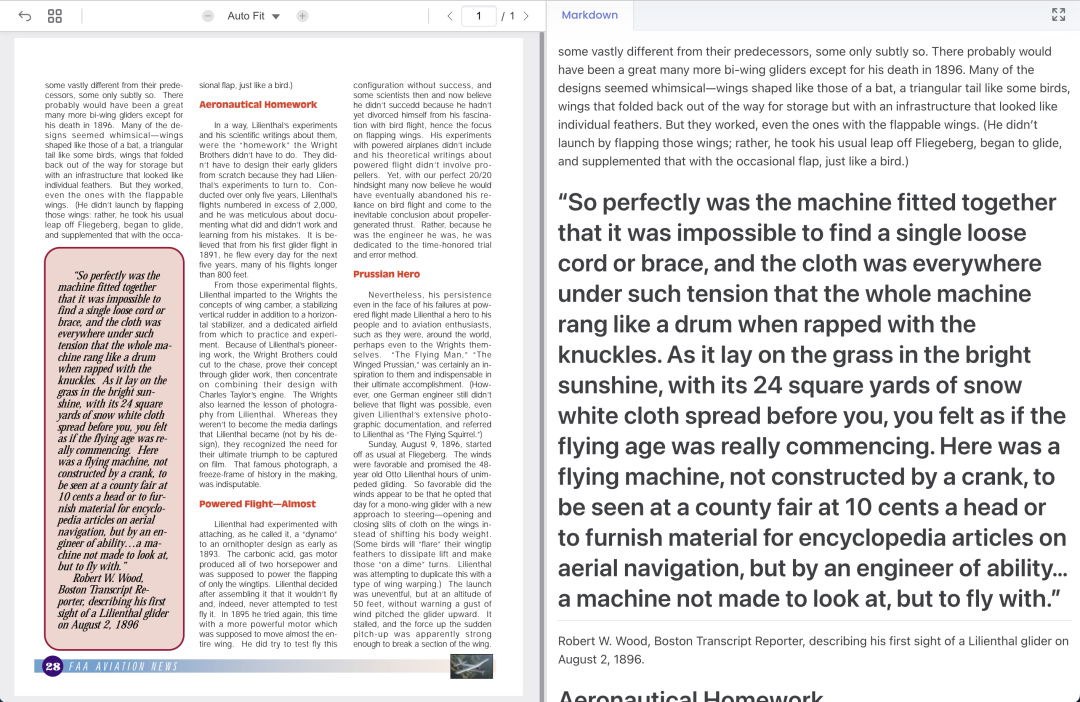
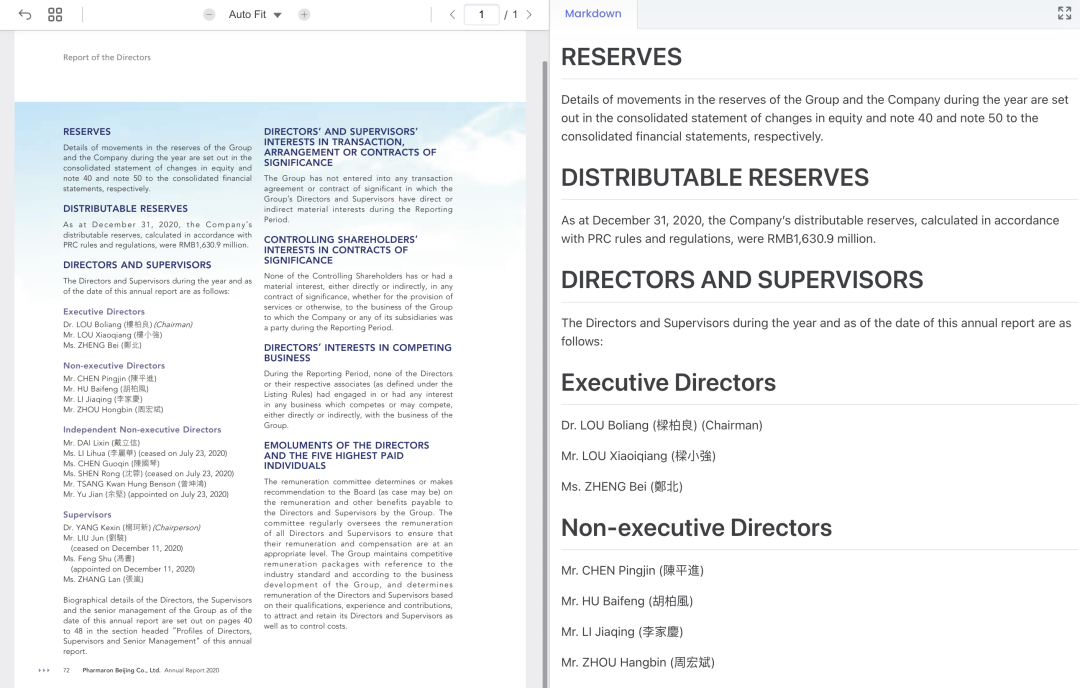
简介
OCRFlux 是一个由ChatDOC团队开发的多模态大语言模型工具包,专门用于将PDF和图像转换为干净、可读的纯Markdown文本。该工具在PDF到Markdown转换领域实现了显著的性能突破,将当前技术水平提升到了一个新的高度。
🔗 GitHub地址:
https://github.com/chatdoc-com/OCRFlux
🚀 核心价值:
PDF转换 · Markdown生成 · 多模态AI · 跨页合并 · 开源工具
项目背景:
-
文档数字化:文档数字化需求增长
-
信息提取:高效信息提取需求
-
格式转换:格式转换技术挑战
-
AI进步:多模态AI技术发展
-
开源贡献:开源社区技术贡献
项目特色:
-
🎯 高精度:卓越的解析精度
-
🌐 多语言:中英文完美支持
-
🔄 跨页合并:跨页表格段落合并
-
🤖 AI驱动:3B参数视觉语言模型
-
⚡ 高效性能:GPU高效运行
技术亮点:
-
多模态融合:视觉与语言模型融合
-
布局理解:复杂布局精确理解
-
表格处理:复杂表格处理能力
-
数学公式:数学公式识别转换
-
跨页智能:智能跨页内容合并
主要功能
1. 核心功能体系
OCRFlux提供了一套完整的文档转换解决方案,涵盖文件解析、布局分析、文本提取、表格处理、公式识别、格式转换、跨页合并、质量优化等多个方面。
解析功能:
文件解析:
- PDF解析: 完整PDF文件解析
- 图像解析: 图像文件解析
- 批量处理: 批量文件处理
- 格式支持: 多种格式支持
- 质量保证: 解析质量保证
页面处理:
- 单页解析: 单页面精确解析
- 多页处理: 多页面连续处理
- 布局分析: 复杂布局分析
- 顺序保持: 自然阅读顺序
- 元素识别: 各种元素识别
内容提取:
- 文本提取: 精确文本提取
- 表格提取: 表格结构提取
- 公式提取: 数学公式提取
- 图片提取: 图片内容处理
- 列表提取: 列表结构提取转换功能:
Markdown生成:
- 纯净文本: 生成纯净Markdown
- 格式保留: 保留原格式
- 结构保持: 保持文档结构
- 语义正确: 语义正确性
- 可读性强: 高可读性输出
表格处理:
- 简单表格: 简单表格转换
- 复杂表格: 复杂表格处理
- 跨行跨列: 行列合并处理
- 格式优化: 表格格式优化
- 对齐保持: 对齐方式保持
公式转换:
- 数学公式: 数学公式识别
- 化学公式: 化学公式处理
- 特殊符号: 特殊符号转换
- LaTeX支持: LaTeX格式支持
- 渲染质量: 高质量渲染2. 高级功能
跨页合并功能:
跨页检测:
- 表格检测: 跨页表格检测
- 段落检测: 跨页段落检测
- 智能识别: 智能内容识别
- 索引定位: 精确索引定位
- 关系分析: 内容关系分析
合并处理:
- 表格合并: 跨页表格合并
- 段落合并: 跨页段落合并
- 内容连贯: 保持内容连贯
- 结构完整: 确保结构完整
- 格式统一: 格式统一处理
复杂场景:
- 表头重复: 重复表头处理
- 长内容: 长内容跨页处理
- 垂直分割: 垂直分割表格
- 混合内容: 混合内容处理
- 特殊情况: 各种特殊情况质量优化功能:
精度优化:
- 错误纠正: 自动错误纠正
- 质量评估: 质量自动评估
- 一致性: 内容一致性检查
- 完整性: 内容完整性验证
- 准确性: 高准确性保证
性能优化:
- 速度优化: 处理速度优化
- 内存优化: 内存使用优化
- GPU优化: GPU性能优化
- 并行处理: 并行处理支持
- 批量优化: 批量处理优化
用户体验:
- 进度显示: 处理进度显示
- 结果预览: 结果预览功能
- 错误报告: 详细错误报告
- 日志记录: 完整日志记录
- 配置灵活: 灵活配置选项评估功能:
基准测试:
- 单页基准: 单页解析基准
- 跨页基准: 跨页合并基准
- 表格基准: 表格处理基准
- 多语言: 多语言基准测试
- 综合评估: 综合性能评估
质量指标:
- EDS评分: 编辑距离相似度
- TEDS评分: 树编辑距离相似度
- 准确率: 检测准确率
- 召回率: 内容召回率
- F1分数: 综合F1分数
比较分析:
- 性能比较: 与基线比较
- 改进分析: 改进点分析
- 优势展示: 优势功能展示
- 案例研究: 详细案例研究
- 持续改进: 基于评估改进安装与配置
1. 环境准备
硬件要求:
GPU要求:
- NVIDIA GPU: RTX 3090, 4090, L40S, A100, H100
- 显存: 12GB+ GPU RAM
- 存储: 20GB+ 可用空间
- 内存: 16GB+ 系统内存
- 网络: 可选网络连接
系统要求:
- 操作系统: Ubuntu/Debian推荐
- 依赖库: Poppler工具集
- 字体: 额外字体包
- 环境: Conda环境
- 工具: 基本开发工具软件依赖:
系统依赖:
- poppler-utils: PDF处理工具
- poppler-data: Poppler数据
- 字体包: 多种字体支持
- Ghostscript: 图形处理
- 其他工具: 辅助工具
Python环境:
- Python: 3.11+
- Conda: 环境管理
- pip: 包管理
- Git: 版本控制
- 编译工具: 构建工具2. 安装步骤
系统依赖安装:
# Ubuntu/Debian系统
sudo apt-get update
sudo apt-get install poppler-utils poppler-data
sudo apt-get install ttf-mscorefonts-installer msttcorefonts
sudo apt-get install fonts-crosextra-caladea fonts-crosextra-carlito
sudo apt-get install gsfonts lcdf-typetoolsPython环境设置:
# 创建Conda环境
conda create -n ocrflux python=3.11
conda activate ocrflux
# 克隆项目
git clone https://github.com/chatdoc-com/OCRFlux.git
cd OCRFlux
# 安装依赖
pip install -e . --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer/模型准备:
# 下载模型
# 需要获取OCRFlux-3B模型
# 放置到合适目录
# 模型路径配置
# 设置模型路径参数
# 确保权限正确验证安装:
# 运行测试
python -m ocrflux.pipeline --help
# 简单测试
python -c "import ocrflux; print('安装成功')"3. 配置说明
基本配置:
# 管道配置示例
pipeline_config = {
"workspace": "./localworkspace",
"task": "pdf2markdown",
"data": ["test.pdf"],
"model": "/path/to/OCRFlux-3B",
"gpu_memory_utilization": 0.8,
"tensor_parallel_size": 1,
"skip_cross_page_merge": False,
"max_page_retries": 1
}性能配置:
# 性能优化配置
performance_config = {
"batch_size": "auto",
"max_model_len": 8192,
"dtype": "auto",
"workers": 4,
"target_longest_image_dim": 2048,
"pages_per_group": 10
}高级配置:
# 高级功能配置
advanced_config = {
"max_page_error_rate": 0.004,
"model_max_context": 4096,
"model_chat_template": "default",
"port": 30024,
"url": "http://localhost"
}使用指南
1. 基本工作流
使用OCRFlux的基本流程包括:环境准备 → 软件安装 → 模型准备 → 文件准备 → 运行转换 → 结果获取 → 质量检查 → 输出使用。整个过程设计为高效可靠。
2. 基本使用
命令行使用:
单文件转换:
- PDF转换: 转换PDF文件
- 图像转换: 转换图像文件
- 指定输出: 指定输出目录
- 参数调整: 调整转换参数
- 结果查看: 查看转换结果
批量处理:
- 目录处理: 处理整个目录
- 文件筛选: 筛选特定文件
- 并行处理: 并行处理文件
- 进度监控: 监控处理进度
- 结果汇总: 汇总处理结果
质量控制:
- 质量检查: 检查输出质量
- 错误处理: 处理转换错误
- 重试机制: 失败重试机制
- 日志分析: 分析处理日志
- 报告生成: 生成质量报告API使用:
编程集成:
- 导入库: 导入OCRFlux库
- 初始化: 初始化模型
- 文件处理: 处理目标文件
- 获取结果: 获取转换结果
- 错误处理: 处理可能错误
离线推理:
- 模型加载: 加载模型
- 直接调用: 直接调用API
- 结果处理: 处理返回结果
- 资源释放: 释放资源
- 性能优化: 优化推理性能
在线服务:
- 服务启动: 启动推理服务
- 客户端: 客户端调用
- 请求处理: 处理转换请求
- 并发支持: 支持并发请求
- 服务管理: 服务管理维护高级使用:
自定义处理:
- 流程定制: 定制处理流程
- 参数调整: 调整处理参数
- 模型选择: 选择不同模型
- 输出格式: 自定义输出格式
- 后处理: 添加后处理步骤
质量优化:
- 参数调优: 调优质量参数
- 重试策略: 优化重试策略
- 错误分析: 深度错误分析
- 改进实施: 实施改进措施
- 效果验证: 验证改进效果
集成开发:
- 系统集成: 集成到其他系统
- 工作流整合: 整合到工作流
- 自动化: 实现自动化处理
- 监控报警: 设置监控报警
- 扩展开发: 开发扩展功能3. 高级用法
大规模处理使用:
批量转换:
- 企业文档: 企业文档批量转换
- 图书馆: 图书馆藏书数字化
- 档案馆: 历史档案数字化
- 出版社: 出版材料转换
- 研究机构: 研究资料处理
自动化流水线:
- 输入处理: 自动化输入处理
- 质量检查: 自动化质量检查
- 结果分发: 自动化结果分发
- 监控报告: 自动化监控报告
- 故障处理: 自动化故障处理
云部署:
- 云环境: 云环境部署
- 弹性扩展: 弹性资源扩展
- 负载均衡: 负载均衡处理
- 成本优化: 云成本优化
- 高可用: 高可用性保障质量保证使用:
质量评估:
- 基准测试: 运行基准测试
- 性能评估: 评估性能指标
- 质量评分: 进行质量评分
- 比较分析: 与基线比较
- 报告生成: 生成评估报告
持续改进:
- 问题识别: 识别质量问题
- 根本分析: 根本原因分析
- 改进方案: 制定改进方案
- 实施验证: 实施并验证
- 效果跟踪: 跟踪改进效果
质量控制:
- 质量标准: 制定质量标准
- 检查流程: 建立检查流程
- 验收标准: 定义验收标准
- 质量监控: 持续质量监控
- 质量文化: 建立质量文化开发研究使用:
算法研究:
- 模型研究: 模型算法研究
- 性能优化: 性能优化研究
- 新功能: 新功能开发研究
- 技术突破: 技术突破研究
- 论文发表: 学术论文研究
基准开发:
- 新基准: 开发新基准测试
- 数据收集: 收集测试数据
- 标注工作: 数据标注工作
- 评估方法: 开发评估方法
- 结果分析: 深度结果分析
开源贡献:
- 代码贡献: 贡献代码改进
- 问题修复: 修复发现问题
- 文档完善: 完善项目文档
- 社区支持: 提供社区支持
- 项目推广: 帮助项目推广应用场景实例
案例1:学术论文转换
场景:学术论文PDF转Markdown
解决方案:使用OCRFlux转换学术论文。
实施方法:
-
论文准备:准备PDF论文
-
转换处理:运行OCRFlux转换
-
质量检查:检查转换质量
-
格式调整:调整输出格式
-
最终使用:使用Markdown版本
学术价值:
-
可搜索性:提高内容可搜索性
-
可编辑性:方便内容编辑
-
引用管理:更好引用管理
-
知识提取:高效知识提取
-
长期保存:长期数字保存
案例2:企业文档数字化
场景:企业历史文档数字化
解决方案:使用OCRFlux进行批量转换。
实施方法:
-
文档收集:收集企业文档
-
批量转换:批量转换处理
-
质量保证:确保转换质量
-
知识管理:集成知识管理系统
-
价值挖掘:挖掘文档价值
企业价值:
-
知识保存:保存企业知识
-
效率提升:提高工作效率
-
决策支持:支持决策制定
-
合规性:满足合规要求
-
竞争优势:获得竞争优势
案例3:图书馆数字化
场景:图书馆藏书数字化
解决方案:使用OCRFlux进行大规模数字化。
实施方法:
-
图书选择:选择需要数字化图书
-
扫描处理:高质量扫描处理
-
批量转换:批量转换扫描件
-
质量控制:严格质量控制
-
服务提供:提供数字服务
图书馆价值:
-
资源保护:保护珍贵资源
-
服务扩展:扩展读者服务
-
远程访问:支持远程访问
-
研究支持:支持学术研究
-
文化传承:促进文化传承
案例4:法律文档处理
场景:法律文档转换管理
解决方案:使用OCRFlux处理法律文档。
实施方法:
-
文档准备:准备法律文档
-
精确转换:高精度转换处理
-
格式保持:保持法律格式
-
审查验证:法律审查验证
-
系统集成:集成法律系统
法律价值:
-
准确性:确保内容准确性
-
效率:提高处理效率
-
检索:增强检索能力
-
合规:满足法律合规
-
安全:保障文档安全
案例5:技术文档转换
场景:技术文档Markdown化
解决方案:使用OCRFlux转换技术文档。
实施方法:
-
技术文档:准备技术文档
-
转换处理:运行转换处理
-
公式处理:特别处理技术公式
-
表格处理:精确处理技术表格
-
发布使用:发布Markdown版本
技术价值:
-
版本控制:更好版本控制
-
协作编辑:方便协作编辑
-
自动生成:支持自动生成
-
多格式输出:多种格式输出
-
现代化:文档现代化
总结
OCRFlux作为一个革命性的多模态文档转换工具,通过其卓越的解析精度、强大的跨页合并能力、多语言支持、开源特性和高性能表现,为PDF到Markdown转换提供了行业领先的解决方案。
核心优势:
-
🎯 高精度:卓越的转换精度
-
🔄 跨页合并:智能跨页内容合并
-
🌐 多语言:中英文完美支持
-
🤖 AI驱动:先进AI技术驱动
-
⚡ 高性能:高效性能表现
适用场景:
-
学术论文转换
-
企业文档数字化
-
图书馆数字化
-
法律文档处理
-
技术文档转换
立即开始使用:
# 克隆项目
git clone https://github.com/chatdoc-com/OCRFlux.git
# 安装使用
cd OCRFlux
conda create -n ocrflux python=3.11
conda activate ocrflux
pip install -e .资源链接:
-
📚 项目地址:GitHub仓库
-
📖 文档:详细文档
-
💬 社区:社区讨论
-
🐛 问题:GitHub Issues
-
📊 基准:性能基准
通过OCRFlux,您可以:
-
高效转换:高效文档转换
-
质量保证:保证转换质量
-
智能处理:智能内容处理
-
批量处理:大规模批量处理
-
集成开发:轻松集成开发
无论您是研究人员、开发者、企业用户、图书馆员还是技术工作者,OCRFlux都能为您提供强大、精确且高效的文档转换解决方案!
特别提示:
-
💻 硬件准备:确保GPU配置
-
📋 依赖安装:正确安装依赖
-
📖 文档阅读:阅读使用文档
-
🐛 问题报告:报告遇到的问题
-
🤝 社区支持:利用社区帮助
通过OCRFlux,体验文档转换的未来!
未来发展:
-
🚀 更多功能:持续添加新功能
-
🤖 更智能:更智能的处理
-
🌍 更广泛:更广泛的支持
-
⚡ 更快速:更快的性能
-
🔧 更易用:更简单的使用
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 开发: 参与代码开发
- 测试: 参与功能测试
- 文档: 贡献文档改进
- 推广: 帮助项目推广
社区价值:
- 技术交流学习
- 问题解答支持
- 功能建议讨论
- 项目合作机会
- 技能提升帮助通过OCRFlux,共同推动文档转换技术发展!
许可证:
开源许可证
免费用于学术和商业用途致谢:
特别感谢:
- 开发团队: ChatDOC开发团队
- 贡献者: 代码功能贡献
- 社区: 社区支持贡献
- 用户: 用户反馈支持
- 支持者: 项目支持者通过OCRFlux,释放文档数字化的无限可能!

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)