
多模态图像配准与评价技术详解
配准流程通常可以分为以下几个主要步骤:图像获取:这是配准流程的第一步,获取需要配准的图像数据。预处理:包括图像的去噪、滤波、增强、对比度调整和归一化处理,以提高图像质量,为特征提取做准备。特征提取:从预处理后的图像中识别关键特征点,这些特征可以是点、边缘、轮廓或区域纹理等。相似性度量:通过计算特征之间的相似度,确定图像间的对应关系,常用的度量技术包括基于像素和基于特征的度量。变换模型定义:建立数学

简介:图像配准技术是计算机视觉和医学成像的核心,关键于图像对齐以利于分析和融合。在“mutlimodal-imge-registration-master”项目中,我们专注于多模态图像配准及其评价,这是一个挑战性的任务,因为要处理不同成像技术产生的图像。项目介绍从预处理到后处理的图像配准流程,并详细解释了评价指标,如点到点距离、结构相似性指数(SSIM)、互信息(MI)、均方根误差(RMSE)和重叠度。这些评价指标对于确定配准的准确性和鲁棒性至关重要,尤其是在多模态配准场景中。理解这些技术对于提高临床诊断和研究分析的准确性具有重要价值。 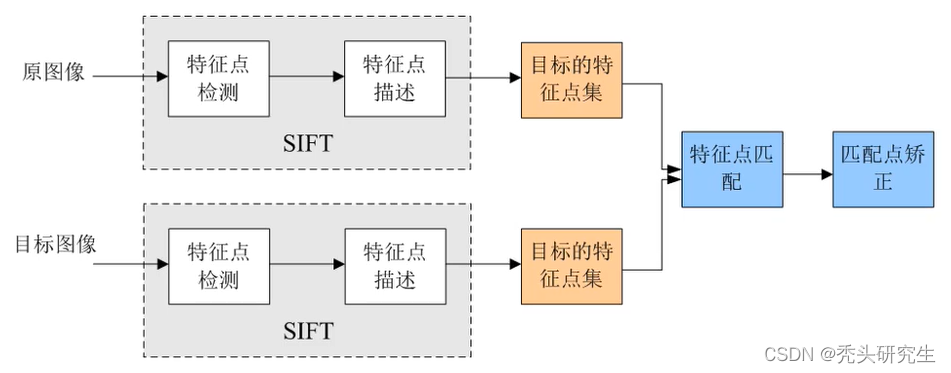
1. 图像配准基本流程
图像配准是数字图像处理中的关键技术之一,它涉及到将两个或多个图像对齐的过程。这一过程在医学成像、遥感、计算机视觉等众多领域都有广泛的应用。图像配准的目标是建立不同图像间的对应关系,使得图像融合或比较变得更加准确和可靠。
1.1 配准流程概述
配准流程通常可以分为以下几个主要步骤:
- 图像获取 :这是配准流程的第一步,获取需要配准的图像数据。
- 预处理 :包括图像的去噪、滤波、增强、对比度调整和归一化处理,以提高图像质量,为特征提取做准备。
- 特征提取 :从预处理后的图像中识别关键特征点,这些特征可以是点、边缘、轮廓或区域纹理等。
- 相似性度量 :通过计算特征之间的相似度,确定图像间的对应关系,常用的度量技术包括基于像素和基于特征的度量。
- 变换模型定义 :建立数学模型来描述图像间的空间变换关系,如仿射变换、透视变换等。
- 优化算法应用 :利用优化技术,如梯度下降法或迭代最优化技术,求解变换模型参数。
- 后处理过程 :包括图像融合、配准结果验证与修正,以及可能的高级后处理技术。
- 评价与改进 :采用不同的评价指标对配准结果进行评估,并根据需要进行优化改进。
1.2 配准的应用意义
图像配准对于图像分析和处理来说至关重要。它可以使得在不同时间、不同视角、或由不同设备获取的图像数据能够有效结合,从而提高数据分析的准确性和可靠性。无论是在医学图像分析、计算机视觉、地理信息系统还是遥感等领域,图像配准都发挥着不可或缺的作用。
接下来的章节中,我们将详细探讨图像配准的每一个步骤,从基础到高级应用,帮助读者全面理解图像配准技术,并能够将其应用到实际工作中去。
2. 预处理步骤
预处理是图像配准流程中的一个重要环节,主要目的是清除图像中的噪声、改善图像质量、标准化图像数据,为后续的特征提取和图像匹配步骤做好准备。在本章节中,我们将详细介绍图像去噪与滤波、对比度调整和图像归一化三个关键步骤。
2.1 图像的去噪和滤波
在获取图像的过程中,由于各种内外部因素,图像往往会受到噪声的干扰。去噪就是利用各种算法和技术对图像中不必要的信息进行处理,以达到提取有效信息的目的。
2.1.1 常见的去噪技术
在众多的去噪技术中,我们主要讨论以下几种:
- 均值滤波:通过用邻域内像素的均值替换中心像素的方式去除噪声,简单易行,但可能会导致图像边缘模糊。
- 中值滤波:用邻域内像素值的中值替换中心像素值,可以有效去除椒盐噪声。
- 高斯滤波:基于高斯分布的卷积核对图像进行平滑处理,可以较好地保留图像边缘信息。
- 双边滤波:同时考虑像素的空间邻近度和像素值相似度,适用于图像降噪同时保持边缘的场景。
下面是一个使用Python进行图像去噪的简单示例代码:
import cv2
import numpy as np
# 加载图像
img = cv2.imread('noisy_image.jpg', 0)
# 使用高斯滤波进行去噪
gaussian_blur = cv2.GaussianBlur(img, (5, 5), 0)
# 使用中值滤波进行去噪
median_blur = cv2.medianBlur(img, 5)
# 显示原始图像和去噪后的图像
cv2.imshow('Original', img)
cv2.imshow('Gaussian Blurred', gaussian_blur)
cv2.imshow('Median Blurred', median_blur)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在应用上述滤波器时,需要选择合适的参数,如滤波器的核大小以及高斯滤波的标准差等,这些参数的选择对于去噪效果有着直接影响。
2.1.2 滤波器的选择和应用
选择合适的滤波器对图像进行预处理是非常重要的。一般情况下,滤波器的选择依赖于噪声的类型以及图像特征的保留需求。均值滤波器适用于高斯噪声,中值滤波器适用于椒盐噪声,而高斯滤波和双边滤波则更常用于保持图像边缘的情况。
在选择滤波器时,我们通常遵循以下原则:
- 若噪声类型明确且对图像细节要求不高,可以使用简单的均值滤波器。
- 若希望在去噪的同时保留边缘信息,高斯滤波器是不错的选择,同时也要关注其核大小和标准差参数的调整。
- 双边滤波是更加强大的边缘保护滤波器,但其计算代价较高。
2.2 图像的增强和对比度调整
图像增强主要是通过一系列处理方法,改进图像的视觉效果,使之更符合人眼的观测习惯,或者更适合后续的图像分析处理。
2.2.1 对比度调整方法
对比度调整方法主要有:
- 线性变换:通过线性函数改变像素值的分布范围,实现对比度的增强。
- 直方图均衡化:通过调整图像的直方图分布,使图像具有更高的对比度。
- 自适应直方图均衡化:在图像的局部区域应用直方图均衡化,能够更有效地增强局部区域的对比度。
下面是一个简单的对比度调整实例代码,展示了如何使用直方图均衡化改善图像的对比度:
import cv2
import matplotlib.pyplot as plt
# 加载图像
img = cv2.imread('low_contrast.jpg', 0)
# 应用直方图均衡化
equalized_img = cv2.equalizeHist(img)
# 绘制直方图
def plot_histogram(image, title):
hist, bins = cv2.calcHist([image], [0], None, [256], [0, 256])
plt.plot(hist, color='gray')
plt.title(title)
plt.xlabel('Bins')
plt.ylabel('# of Pixels')
plt.xlim([0, 256])
# 显示原图和增强后的图像
cv2.imshow('Original', img)
cv2.imshow('Equalized', equalized_img)
# 显示直方图
plt.figure()
plot_histogram(img, 'Histogram for Original Image')
plt.figure()
plot_histogram(equalized_img, 'Histogram for Equalized Image')
plt.show()
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
通过直方图均衡化,可以看到原图的对比度得到了明显的提升。
2.2.2 图像增强技术的实践应用
图像增强技术除了上述提到的对比度调整方法之外,还包括:
- 空间域增强:直接在图像像素上进行操作,如点运算和邻域运算。
- 频域增强:将图像从空间域转换到频域进行处理,例如应用低通滤波器来增强图像的平滑度。
- 对数变换和伽马校正:适用于图像颜色或亮度分布不均的情况。
- 锐化滤波器:通过增强图像中的高频部分来提升图像的清晰度。
在选择图像增强方法时,需要根据实际需求和图像特征进行灵活选择。对于一些特定的应用场景,如医学图像分析,还需要结合专业知识来选择合适的增强方法。
2.3 图像的归一化处理
归一化处理是预处理步骤的最后阶段,它将图像数据标准化到统一的范围,从而降低不同图像间的数据差异,为后续算法的稳定运行打下基础。
2.3.1 数据归一化的意义
数据归一化通常有以下几个意义:
- 提高算法的收敛速度:在很多优化算法中,归一化可以帮助提升算法的收敛速度。
- 减少数值计算的误差:数值计算往往对数据的量级较为敏感,归一化有助于减少因数据量级不同导致的计算误差。
- 提升算法的泛化能力:通过归一化处理,不同来源的图像数据可以在同一个标准下进行比较,有利于后续的图像配准工作。
2.3.2 实际操作中的归一化步骤
在实际操作中,图像归一化的步骤如下:
- 确定归一化的范围,通常是将像素值缩放到[0,1]或[-1,1]区间。
- 应用归一化公式,对每个像素值进行转换。
- 对归一化后的图像进行检查,确保数据没有超出预定范围。
下面是一个对图像进行归一化的Python示例代码:
import numpy as np
import cv2
# 加载图像并转换为浮点型
img = cv2.imread('image.png', cv2.IMREAD_GRAYSCALE).astype(np.float32)
# 将图像缩放到[0, 1]区间
normalized_img = img / 255.0
# 显示原图和归一化后的图像
cv2.imshow('Original Image', img)
cv2.imshow('Normalized Image', normalized_img)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
归一化不仅帮助我们标准化数据,而且还可以在一定程度上缓解光照变化、传感器差异等问题对图像配准的影响。
在这一章节中,我们讨论了图像预处理中的去噪滤波、图像增强和对比度调整、归一化处理三个主要步骤,并提供了相关的代码示例和分析,帮助读者更好地理解并应用这些预处理技术。预处理的优化可以显著提高图像配准的整体效果和后续操作的稳定性。
3. 特征提取方法
在图像配准中,特征提取是至关重要的一步,它涉及到从图像中识别出可以用于配准的关键点、边缘、区域以及纹理等信息。正确而有效的特征提取可以极大提升配准过程的准确性和效率。本章节将详细介绍多种常用的特征提取方法。
3.1 点特征的提取
点特征,又称为关键点,是图像中具有独特信息的区域,可以用于表征图像并作为配准过程中的参照点。关键点提取方法的多样性及其对不同环境的适应性,使得它们成为图像配准中不可或缺的部分。
3.1.1 SIFT特征点检测
尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)是一种广泛用于图像处理的特征检测算法,它能够检测出图像中的稳定关键点,并对这些关键点进行描述。SIFT的特性包括尺度不变性和旋转不变性,使得它在图像配准中表现出色。
import cv2
import numpy as np
def detect_sift_features(image_path):
# 读取图像
img = cv2.imread(image_path)
# 创建 SIFT 对象
sift = cv2.SIFT_create()
# 检测关键点和描述符
keypoints, descriptors = sift.detectAndCompute(img, None)
return keypoints, descriptors
# 示例图片路径
image_path = 'example.jpg'
keypoints, descriptors = detect_sift_features(image_path)
在上述代码中,我们使用OpenCV库来实现SIFT特征点的检测。首先,我们读取需要处理的图像文件,然后创建SIFT对象并使用它来检测关键点及其描述符。这些关键点和描述符将作为后续图像配准的依据。
3.1.2 SURF特征点描述符
加速稳健特征(Speeded-Up Robust Features,SURF)是另一种关键点检测和描述的方法。它比SIFT更快,在保持较高精度的同时,通过简化运算加快了处理速度。
def detect_surf_features(image_path):
# 读取图像
img = cv2.imread(image_path)
# 创建 SURF 对象
surf = cv2.xfeatures2d.SURF_create()
# 检测关键点和描述符
keypoints, descriptors = surf.detectAndCompute(img, None)
return keypoints, descriptors
keypoints, descriptors = detect_surf_features(image_path)
在这里,我们使用OpenCV的扩展库来实现SURF算法。通过创建SURF对象,我们同样可以获取图像的关键点和描述符。SURF是SIFT的改进版,特别适合在对速度有要求的应用场景中使用。
3.2 边缘和轮廓特征的提取
除了点特征外,边缘和轮廓特征也是图像配准中的重要信息源。它们提供了图像的形状和结构信息,有助于提高配准的精度。
3.2.1 Canny边缘检测算法
Canny边缘检测是一种被广泛使用的边缘检测技术。它通过多级滤波和阈值设置,能够有效提取出图像的边缘信息。
def canny_edge_detection(image_path):
# 读取图像
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 应用高斯模糊
blurred = cv2.GaussianBlur(img, (5, 5), 0)
# Canny边缘检测
edges = cv2.Canny(blurred, 50, 150)
return edges
edges = canny_edge_detection(image_path)
代码中首先将图像转换为灰度图,然后应用高斯模糊以减少噪声影响,最后进行Canny边缘检测得到边缘图像。这样处理后的边缘图像可用于进一步的图像配准步骤。
3.2.2 轮廓检测技术与实践
轮廓检测可以帮助我们识别出图像中物体的轮廓线。在OpenCV中,我们可以通过查找轮廓来获取这些信息。
def find_contours(image_path):
# 读取图像
img = cv2.imread(image_path)
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 边缘检测
edged = cv2.Canny(gray, 30, 200)
# 查找轮廓
contours, _ = cv2.findContours(edged, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
return contours
contours = find_contours(image_path)
在这个例子中,我们先将彩色图像转换为灰度图像,之后进行Canny边缘检测,最后使用 findContours 函数获取轮廓。这些轮廓将用于图像配准中的形状对齐和相似性度量。
3.3 区域和纹理特征的提取
区域特征指的是图像中的特定区域或像素群,而纹理特征则描述了图像中像素的局部模式和组织结构。
3.3.1 区域生长算法
区域生长是一种从种子点开始,按照一定的准则,逐步将相邻相似的像素包含进来的图像分割技术。
def region_growing(image_path):
# 读取图像
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 阈值分割,获取初步的种子点
_, seed = cv2.threshold(img, 128, 255, cv2.THRESH_BINARY)
# 根据灰度差异进行区域生长
# ...(区域生长算法实现省略)
return segmented_image
segmented_image = region_growing(image_path)
区域生长算法的实现较为复杂,涉及到种子点选择、相似度度量、区域合并等多个步骤。在这里,我们通过一个简化的例子说明了区域生长算法的基本思想。
3.3.2 纹理特征分析方法
纹理特征可以用来描述图像中的质地信息。常用的纹理特征包括灰度共生矩阵(GLCM)等。
from skimage.feature import greycomatrix, greycoprops
def calculate_glcm_features(image_path):
# 读取图像
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 计算灰度共生矩阵
glcm = greycomatrix(img, [1], [0], levels=256, normed=True, symmetric=True)
# 计算对比度
contrast = greycoprops(glcm, 'contrast')[0][0]
# ...(其他纹理特征计算省略)
return contrast
contrast = calculate_glcm_features(image_path)
上述代码展示了如何使用 skimage 库中的函数计算图像的灰度共生矩阵,并从中提取纹理特征中的对比度属性。实际应用中,我们还会提取其他的纹理特征来增强配准的鲁棒性。
以上便是第三章的核心内容,详细介绍了点特征、边缘和轮廓特征、区域和纹理特征的提取方法。这些方法为图像配准提供了丰富的信息源,是后续配准步骤中不可或缺的基石。在下一章节中,我们将进一步深入到相似性度量技术中,介绍度量技术的基本原理、常用方法以及如何根据实际图像类型选择合适的度量方法。
4. 相似性度量技术
4.1 相似性度量的基本原理
4.1.1 相似度和距离度量的定义
相似性度量在图像处理中扮演着核心的角色。这一概念起源于度量两个或多个对象之间的相似程度。在数学上,相似度与距离度量紧密相关。相似度度量通常是一个介于0和1之间的数,数值越大表示相似度越高。而距离度量则代表了两个对象之间的距离,数值越小表示两者越相似。在图像配准中,相似性度量主要指通过计算方法来评估两幅图像之间的相似性,为图像变换和配准提供定量的依据。
4.1.2 度量技术在图像配准中的重要性
在图像配准任务中,相似性度量是评估配准效果的关键。它决定了是否能够准确地对齐两幅图像,并在医学成像、遥感图像处理、卫星图像配准等多个领域中具有广泛的应用。度量技术的选取直接影响配准的速度和精确度。不同的度量技术有不同的特点和适用场景,选择合适的度量方法可以大幅提升配准效率和准确度。
4.2 常用的相似性度量方法
4.2.1 基于像素的度量方法
基于像素的度量方法是指直接利用像素值进行相似性评价。这类方法包括均方差(MSE)、归一化互相关(NCC)、和绝对误差和(SAD)等。均方差通过计算两幅图像对应像素差的平方和来评估相似性,其值越小表示相似度越高。归一化互相关是将差值标准化后的相关系数,可以有效忽略亮度变化的影响。绝对误差和则是差值绝对值的和,对噪声具有一定的容忍性。基于像素的方法在细节丰富的图像上效果较好,但对噪声和光照变化敏感。
import numpy as np
def mse(imageA, imageB):
err = np.sum((imageA.astype("float") - imageB.astype("float"))**2)
err /= float(imageA.shape[0] * imageA.shape[1])
return err
def ncc(imageA, imageB):
meanA = np.mean(imageA)
meanB = np.mean(imageB)
ncc_value = np.sum((imageA - meanA) * (imageB - meanB)) / (np.sqrt(np.sum((imageA - meanA)**2)) * np.sqrt(np.sum((imageB - meanB)**2)))
return ncc_value
def sad(imageA, imageB):
return np.sum(np.abs(imageA - imageB))
# 示例图像假定为灰度图
imageA = np.random.rand(50, 50)
imageB = np.random.rand(50, 50)
# 计算MSE、NCC、SAD
mse_value = mse(imageA, imageB)
ncc_value = ncc(imageA, imageB)
sad_value = sad(imageA, imageB)
print(f"MSE: {mse_value}")
print(f"NCC: {ncc_value}")
print(f"SAD: {sad_value}")
4.2.2 基于特征的度量方法
基于特征的方法关注的是从图像中提取的特征点、边缘等信息。这些特征具有更好的鲁棒性,能够在图像变形、尺度变化以及光照条件变化等情况下保持一致性。SIFT(尺度不变特征变换)、SURF(加速稳定特征)等特征检测算法通常被用来提取和匹配特征点,进而通过特征点之间的相似性来评估图像的相似性。
import cv2
def extract_features(image):
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(image, None)
return keypoints, descriptors
# 示例图像假定为灰度图
image = cv2.imread("path_to_image", cv2.IMREAD_GRAYSCALE)
keypoints, descriptors = extract_features(image)
# 输出提取的特征点数量和描述符
print(f"Number of Keypoints: {len(keypoints)}")
print(f"Descriptors shape: {descriptors.shape}")
4.3 度量方法的选择与应用
4.3.1 根据图像类型选择度量方法
选择合适的度量方法需要考虑图像的特性,如图像的内容、是否存在几何失真或光照变化等。例如,在医学图像配准中,由于可能存在较大的变形和噪声,基于特征的方法如SIFT往往比基于像素的方法更为适用。在遥感图像处理中,由于图像大小大且包含丰富的纹理信息,互信息(MI)通常被用来评估图像相似性。
4.3.2 应用案例分析
以遥感图像配准为例,通过计算源图像与目标图像的互信息,可以实现两个不同时间或不同传感器获取的图像之间的配准。在实际应用中,首先对两幅图像进行特征提取,然后通过计算得到的特征点集的互信息进行配准。这一度量方法能够有效克服图像之间的尺度、角度和光照差异。
import numpy as np
from skimage.feature import register_translation
from skimage.metrics import structural_similarity as ssim
def mutual_information(imageA, imageB):
# 使用结构相似性指数作为互信息的近似
score, _ = ssim(imageA, imageB, full=True)
return score
# 示例图像假定为灰度图
imageA = np.random.rand(100, 100)
imageB = np.random.rand(100, 100)
# 计算互信息
mi_value = mutual_information(imageA, imageB)
print(f"Mutual Information: {mi_value}")
在选择度量方法时,还需考虑配准任务的实时性要求。基于像素的方法通常计算更快,适合实时图像配准;而基于特征的方法尽管计算复杂度更高,但提供更强的鲁棒性,适合精确度要求高的图像配准任务。因此,在实际应用中需要根据具体需求来权衡相似性度量方法的选择。
5. 变换模型定义
5.1 空间变换模型的种类
在图像配准过程中,变换模型的选择至关重要,它能够描述并校正源图像和目标图像之间的几何差异。最常用的两类变换模型是仿射变换和透视变换。
5.1.1 仿射变换模型
仿射变换是一类包含缩放、旋转、剪切和轴对称等多种变换的广义线性变换。其数学表达式通常表示为一个矩阵乘以向量的操作:
[ \begin{bmatrix} x’ \ y’ \ 1 \end{bmatrix} = \begin{bmatrix} a & b & t_x \ c & d & t_y \ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} x \ y \ 1 \end{bmatrix} ]
其中,( (x’, y’) ) 代表变换后的坐标,( (x, y) ) 代表原始坐标,( a, b, c, d ) 分别代表缩放、旋转、剪切因子,而 ( t_x, t_y ) 则代表水平和垂直方向的平移量。
在实际应用中,仿射变换可以实现图像的倾斜校正、旋转等操作,是图像配准中较为常用的方法。
import numpy as np
import cv2
# 示例:使用仿射变换调整图像
image = cv2.imread('source_image.jpg')
rows, cols = image.shape[:2]
# 设置仿射变换的三个参数:旋转角度、缩放因子和剪切角度
rotation_angle = 30 # 度
scale_factor = 1.0
shear_angle = 10 # 度
# 从角度计算仿射变换的旋转矩阵
M = cv2.getRotationMatrix2D((cols/2, rows/2), rotation_angle, scale_factor)
# 应用仿射变换
rotated_image = cv2.warpAffine(image, M, (cols, rows))
# 显示结果
cv2.imshow('Rotated Image', rotated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.1.2 透视变换模型
透视变换则允许图像进行更复杂的几何校正,通过模拟相机视角变化来实现,常常用于校正图像的透视畸变,比如校正拍摄建筑物时产生的梯形畸变。透视变换矩阵可以表示为:
[ \begin{bmatrix} x’ \ y’ \ w \end{bmatrix} = \begin{bmatrix} a_{11} & a_{12} & a_{13} \ a_{21} & a_{22} & a_{23} \ a_{31} & a_{32} & 1 \end{bmatrix} \begin{bmatrix} x \ y \ 1 \end{bmatrix} ]
其中,( w ) 是一个缩放因子,( (a_{11}, a_{12}, …, a_{32}) ) 是变换矩阵的参数。
透视变换的关键是正确地选择四个点(通常是图像的四个角点)作为控制点,然后计算出变换矩阵并应用到源图像上。
import numpy as np
import cv2
# 示例:使用透视变换校正图像
image = cv2.imread('distorted_image.jpg')
rows, cols = image.shape[:2]
# 定义源图像中的四个角点,以及校正后的对应点
pts_src = np.array([[0, 0], [cols-1, 0], [cols-1, rows-1], [0, rows-1]], np.float32)
pts_dst = np.array([[50, 50], [cols-50, 50], [cols-50, rows-50], [50, rows-50]], np.float32)
# 计算透视变换矩阵
M = cv2.getPerspectiveTransform(pts_src, pts_dst)
# 应用透视变换
warped_image = cv2.warpPerspective(image, M, (cols, rows))
# 显示结果
cv2.imshow('Warped Image', warped_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.2 变换模型参数的求解
在使用变换模型之前,需要准确求解出模型中的参数。常用的参数求解方法有直接线性变换算法和参数优化方法。
5.2.1 直接线性变换算法
直接线性变换(Direct Linear Transform, DLT)是一种利用最小二乘法估计仿射变换参数的算法。其核心思想是通过最小化点对应误差的平方和来求解变换矩阵的参数。
以仿射变换为例,DLT可以对以下形式的方程进行求解:
[ Ax = 0 ]
其中,( A ) 是一个矩阵,由多个对应点组成,( x ) 是变换矩阵的参数向量。
# 示例:使用DLT算法计算仿射变换矩阵
# 假设已知四个点对应关系
points_src = np.array([[1, 2], [4, 4], [2, 5], [5, 7]], dtype=float)
points_dst = np.array([[2, 3], [7, 4], [4, 6], [9, 8]], dtype=float)
# 创建矩阵A
A = np.zeros((8, 8))
for i in range(4):
u, v = points_src[i]
x, y = points_dst[i]
A[2*i] = [-u, -v, -1, 0, 0, 0, u*x, v*x]
A[2*i+1] = [0, 0, 0, -u, -v, -1, u*y, v*y]
# 求解齐次线性方程组得到变换矩阵参数
_, _, Vt = np.linalg.svd(A)
homography = Vt[-1]
# 由于求得的是齐次坐标,需要进行归一化
homography /= homography[-1]
5.2.2 参数优化方法
直接线性变换算法虽然简单且容易实现,但在实际操作中,其求解结果往往不够精确。参数优化方法通过迭代更新变换矩阵的参数,直至找到最优解,常见的优化方法包括随机抽样一致性(Random Sample Consensus, RANSAC)和非线性最小二乘法。
# 示例:使用RANSAC算法优化仿射变换矩阵参数
# 继续使用上一个示例中的points_src和points_dst
# 定义仿射变换模型
model, inliers = cv2.estimateAffine2D(points_src, points_dst, cv2.RANSAC)
# 输出模型参数和内点
print("Homography Matrix:\n", model)
print("Inliers:", inliers)
5.3 变换模型的应用实例
在实际的图像配准任务中,不同的变换模型有着各自的应用场景。本节将介绍两个应用实例:医学图像配准和多传感器图像融合。
5.3.1 医学图像配准中的应用
在医学图像配准中,仿射变换和透视变换被广泛使用来校正图像的几何畸变,从而达到对不同时间点、不同角度或不同成像设备拍摄的医学图像进行精确配准的目的。例如,通过仿射变换可以校正不同患者拍摄的MRI图像的头部倾斜或旋转问题,而透视变换则可以用于矫正内窥镜图像的视角变化。
# 示例:利用仿射变换进行医学图像配准
# 由于医学图像涉及隐私和专业软件处理,这里省略具体代码,仅用伪代码表示
medical_image_1 = ... # 获取第一幅医学图像
medical_image_2 = ... # 获取第二幅医学图像,可能是不同的扫描时间或不同的扫描方向
# 预处理和特征提取
preprocessed_image_1, features_1 = preprocess(medical_image_1)
preprocessed_image_2, features_2 = preprocess(medical_image_2)
# 特征匹配
matched_points = match_features(features_1, features_2)
# 计算仿射变换矩阵并应用变换
homography = estimate_homography(matched_points)
registered_image = apply_transformation(preprocessed_image_2, homography)
# 显示配准后的图像
display_images(medical_image_1, registered_image)
5.3.2 多传感器图像融合中的应用
在多传感器图像融合任务中,图像配准的目标是整合来自多个传感器的图像数据,以便获得比单一传感器更全面的场景信息。对于不同视角或位置拍摄的图像,透视变换能够有效地将它们融合到一个统一的视角中。例如,在无人驾驶汽车的视觉系统中,多个摄像头的图像需要经过透视变换以获得一个统一的俯瞰视角图,为车辆的路径规划和障碍物检测提供支持。
# 示例:利用透视变换进行多传感器图像融合
# 由于具体场景复杂,这里使用伪代码来表示图像融合过程
images_from_sensors = load_images_from_sensors() # 加载来自多个传感器的图像
fused_image = images_from_sensors[0] # 选择一个作为基础图像
# 对其他传感器图像应用透视变换,并将其融合到基础图像中
for image in images_from_sensors[1:]:
homography = calculate_perspective_transformation(image, fused_image)
transformed_image = apply_transformation(image, homography)
fused_image = fuse_images(fused_image, transformed_image)
# 显示融合后的图像
display_image(fused_image)
在本章节中,我们深入了解了空间变换模型的种类,包括仿射变换和透视变换,并通过实际代码示例展示了它们在图像配准中的应用。变换模型参数求解方法的介绍,进一步加深了对模型精确定位的认识。通过医学图像配准和多传感器图像融合的应用实例,我们可以看到变换模型在实际问题解决中的重要作用。下一章节,我们将探索如何进一步通过优化算法,提升图像配准的精度和效率。
6. 优化算法应用
在图像配准过程中,优化算法起着至关重要的作用。它们能够找到最适合图像配准需求的参数,实现不同图像之间的最佳对齐。本章节将深入探讨优化算法的原理、分类、在图像配准中的应用,以及如何根据问题特性选择并实现这些算法。
6.1 优化算法的原理与分类
6.1.1 优化问题的基本概念
优化问题是寻找一组参数,使得某个目标函数达到极值的问题。在图像配准中,目标函数通常代表图像间的不一致性,例如差值或距离,我们的目标是通过调整变换模型参数最小化这个目标函数。优化问题可以分为无约束优化和有约束优化,图像配准一般属于后者。
6.1.2 常见的优化算法
优化算法种类繁多,包括但不限于:
- 梯度下降法 :通过计算目标函数的梯度并沿着最陡峭的方向更新参数以找到最小值。
- 牛顿法与拟牛顿法 :利用目标函数的二阶导数(Hessian矩阵)或其近似来加速收敛。
- 遗传算法 :一种启发式搜索算法,通过模拟自然选择过程来寻找最优解。
- 模拟退火 :通过模拟物理退火过程,以概率方式接受不如当前解的解,以跳出局部最优。
6.2 优化算法在图像配准中的应用
6.2.1 梯度下降法在配准中的应用
梯度下降法是最基本的优化方法之一,它在图像配准中主要用于最小化目标函数,如均方差、互信息等。
import numpy as np
# 假设 cost_function 是一个计算目标函数值的函数
def gradient_descent(cost_function, grad_function, initial_parameters, learning_rate, iterations):
parameters = initial_parameters
for _ in range(iterations):
gradients = grad_function(parameters)
parameters -= learning_rate * gradients
return parameters
# 示例:初始化参数、学习率和迭代次数
initial_params = np.array([0.0, 0.0, 0.0])
learning_rate = 0.01
iterations = 1000
# 执行梯度下降法
optimized_params = gradient_descent(cost_function, grad_function, initial_params, learning_rate, iterations)
在上述代码中, cost_function 是计算目标函数值的函数, grad_function 是计算目标函数梯度的函数。 initial_parameters 是算法的起始点, learning_rate 决定了在梯度方向上参数更新的步长,而 iterations 是优化的迭代次数。
6.2.2 迭代最优化技术
迭代最优化技术是图像配准中常用的一种方法。其中,最著名的是 迭代最临近点(Iterative Closest Point, ICP)算法 。ICP 算法主要用于点云数据的配准,但其思想也可以应用于图像配准。
6.3 优化算法的选择与实现
6.3.1 根据问题特性选择算法
在选择优化算法时,需要考虑问题的特性,例如:
- 目标函数的性质(凸性、平滑性等)
- 参数空间的维度
- 计算资源的限制
- 对算法收敛速度和精度的要求
6.3.2 实现步骤与调试技巧
实现优化算法时,需要遵循以下步骤:
- 定义目标函数及其梯度(或Hessian矩阵)
- 初始化参数和算法参数(学习率、迭代次数等)
- 执行优化算法并监控收敛过程
- 分析优化结果并调整参数以改善性能
调试优化算法时应注意:
- 避免过拟合:确保算法具有良好的泛化能力。
- 监控收敛:检查目标函数值随迭代次数的变化,确保算法正在收敛。
- 参数调优:适当调整学习率和其他超参数以改善性能。
通过遵循这些实现步骤和调试技巧,我们可以更有效地利用优化算法来提高图像配准的性能。
7. 后处理过程
在图像配准的最终阶段,后处理过程扮演着至关重要的角色。它包括对配准结果的优化、验证和修正,以及利用高级技术进一步提升配准质量。本章节将重点介绍图像融合技术、配准结果的验证与修正,以及基于深度学习的后处理方法和多模态图像融合的优化策略。
7.1 图像融合技术
图像融合技术是后处理过程中提升图像质量和信息利用效率的关键步骤。它涉及到将来自同一场景但可能在不同时间、不同视角或不同传感器下捕获的多个图像数据集合并为一个单一图像。
7.1.1 像素级融合方法
像素级融合是最直接的图像融合技术,它在像素层面进行操作。常见的像素级融合方法包括:
- 平均值融合 :将所有图像对应位置的像素值求平均,从而生成融合图像。这种方法简单易实现,适用于图像噪声水平相近的情况。
- 加权平均融合 :与平均值融合类似,但每个像素值都被赋予不同的权重,使得某些图像在融合过程中有更大的影响。
- 主成分分析(PCA)融合 :通过主成分分析选取最重要的特征向量,然后重构图像,以此实现数据降维和特征融合。
7.1.2 特征级融合技术
特征级融合技术关注于不同图像的特征空间,而不是直接在像素空间进行融合。它通常包含以下步骤:
- 特征提取 :从每幅图像中提取关键特征,如边缘、角点或纹理特征。
- 特征匹配 :确定不同图像特征点之间的对应关系。
- 融合决策 :基于特征匹配的结果,决定如何在特征层面进行融合。比如,可以选择在特征空间内进行加权平均或使用决策树方法。
7.2 配准结果的验证与修正
配准结果的准确性直接关系到最终图像的质量和后续分析的可靠性。因此,需要一系列方法来验证和修正配准结果。
7.2.1 验证配准精度的技术
验证配准精度是确保配准正确性的关键步骤。常用的验证方法有:
- 视觉检查 :通过观察配准前后的图像对比来主观评估配准质量。
- 数学统计方法 :计算重叠区域的像素差异,如均方根误差(RMSE)。
- 地面控制点(GCP) :使用预先定义好的控制点来检查配准的准确性。
7.2.2 配准结果的修正策略
如果发现配准结果存在偏差,可以通过以下策略进行修正:
- 自动调整 :利用优化算法进行自动调整,以减小配准误差。
- 手动校正 :对于自动方法未能纠正的错误,可采用手动方式进行微调。
- 混合方法 :结合自动和手动校正,发挥各自的优势以达到最佳效果。
7.3 高级后处理技术
随着机器学习和深度学习技术的发展,高级后处理技术在图像配准领域得到越来越多的应用。
7.3.1 基于深度学习的后处理方法
深度学习提供了强大的数据处理和特征提取能力。典型的后处理方法包括:
- 卷积神经网络(CNN) :利用CNN来学习图像配准的映射关系,直接输出配准后的图像。
- 循环神经网络(RNN) :针对视频图像配准,RNN能够利用时间序列信息进行更准确的配准。
7.3.2 多模态图像融合的优化策略
多模态图像融合旨在将来自不同成像模态的图像信息整合,以获取更全面的场景理解。
- 多尺度融合 :通过不同的尺度空间,提取不同模态图像的特征,并进行融合。
- 决策级别的融合 :首先在每种模态上进行独立的特征提取和配准,然后根据具体任务的需求,选择合适的信息进行融合。
通过上述方法,后处理不仅优化了图像配准结果,而且增强了图像在不同应用中的可用性和准确性。下一章将探讨多模态图像配准评价指标,为配准结果提供更详尽的质量保证。
简介:图像配准技术是计算机视觉和医学成像的核心,关键于图像对齐以利于分析和融合。在“mutlimodal-imge-registration-master”项目中,我们专注于多模态图像配准及其评价,这是一个挑战性的任务,因为要处理不同成像技术产生的图像。项目介绍从预处理到后处理的图像配准流程,并详细解释了评价指标,如点到点距离、结构相似性指数(SSIM)、互信息(MI)、均方根误差(RMSE)和重叠度。这些评价指标对于确定配准的准确性和鲁棒性至关重要,尤其是在多模态配准场景中。理解这些技术对于提高临床诊断和研究分析的准确性具有重要价值。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)