
LMM大型多模态模型
shadow:从去年开始,我做了不少生成式AI的项目,包括MixCopilot、ComfyUI插件mixlab-nodes等,这一个领域的知识更新非常快,去年我们还在聊SDXL,现在生图的基础模型几乎已经切换为Flux了,在图像生成领域,开源已经对闭源的产品(MJ)产生了威胁(效果逼近)。技术发展非常快,我们可以从系统性的角度,开始总结知识了。这个系列是Chip Huyen的一些技术文章的翻译总结
shadow:
从去年开始,我做了不少生成式AI的项目,包括MixCopilot、ComfyUI插件mixlab-nodes等,这一个领域的知识更新非常快,去年我们还在聊SDXL,现在生图的基础模型几乎已经切换为Flux了,在图像生成领域,开源已经对闭源的产品(MJ)产生了威胁(效果逼近)。
技术发展非常快,我们可以从系统性的角度,开始总结知识了。这个系列是Chip Huyen的一些技术文章的翻译总结,分享给大家。


长期以来,每个机器学习模型(AI模型)都以单一的数据模式运行——文本(翻译)、图像(对象检测、图像分类)或音频(语音识别)。
然而,生物智能并不局限于单一模态。人类可以阅读、说话和观察。我们听音乐来放松,留意奇怪的声音来发现危险。能够处理多模态数据对于我们或任何人工智能在现实世界中的运作都至关重要。
OpenAI 在其GPT-4V 系统中指出,“将其他模式(例如图像输入)纳入 LLM 是人工智能研究和开发的关键性前沿技术。”
将其他模态纳入 LLM(大型语言模型)可创建 LMM(大型多模态模型)。并非所有多模态系统都是 LMM。例如,文本到图像模型(如 Midjourney、Stable Diffusion 和 Dall-E)是多模态的,但没有语言模型组件。
多模态,意味着:
- 输入和输出具有不同的形式(例如文本到图像、图像到文本)
- 输入是多模式的(例如,可以同时处理文本和图像的系统)
- 输出是多模式的(例如,可以生成文本和图像的系统)
为何选择多模态?
如果没有多模态性,许多用例就不可能实现,特别是在处理混合数据模态的行业,例如医疗保健、机器人、电子商务、零售、游戏等。
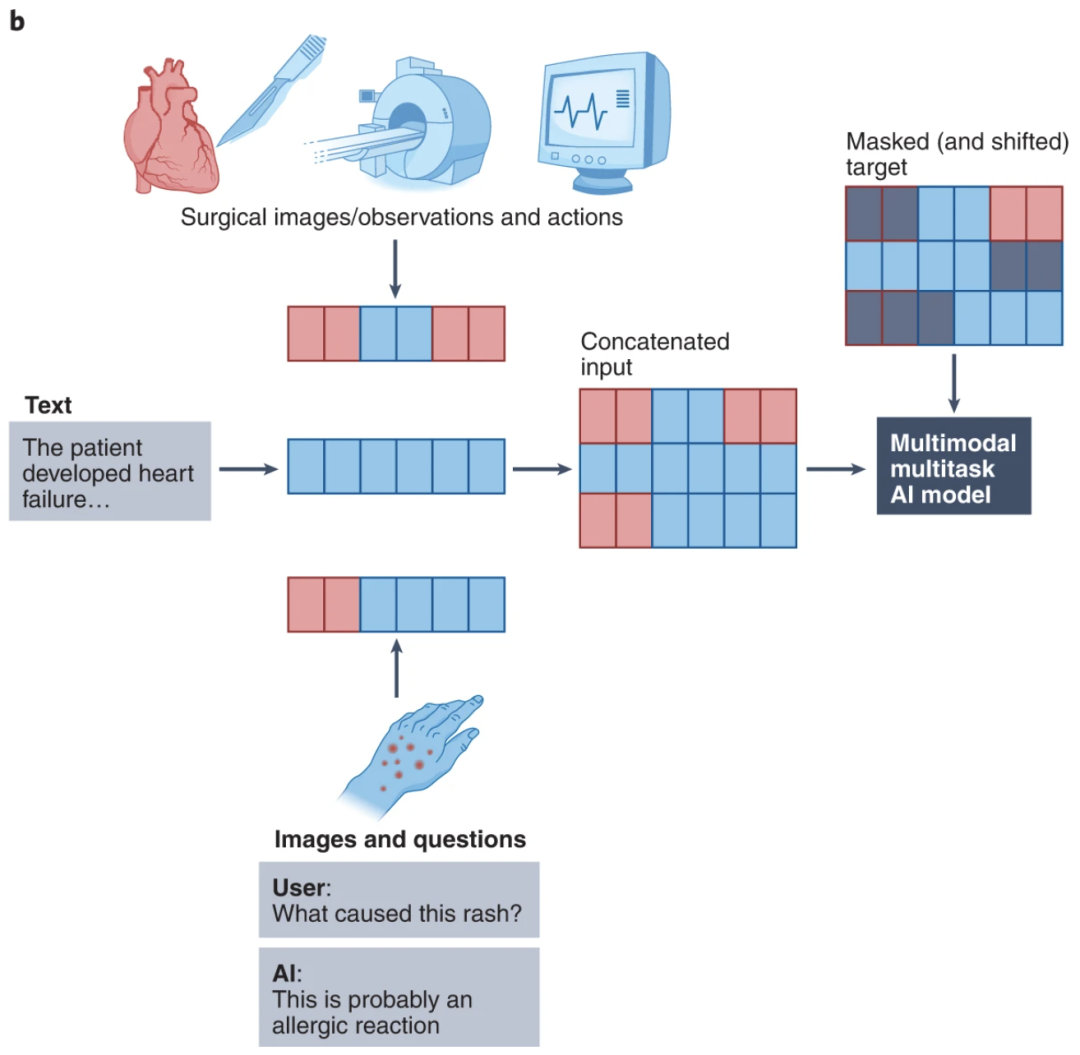
多模态技术在医疗保健中的应用示例。图片来自多模态生物医学 AI(Acosta 等人,《自然医学》2022 年)
不仅如此,结合其他模态的数据有助于提高模型性能。能够从文本和图像中学习的模型难道不应该比只能从文本或图像中学习的模型表现更好吗?
多模态系统可以提供更灵活的界面,让您以当前最适合的方式与它们交互。想象一下,您可以通过打字、说话或将相机对准某个物体来提问。
有一个特别兴奋的例子是,多模态还可以让视障人士浏览互联网并探索现实世界。

GPT-4V 中的一些很酷的多模态用例
数据模式
不同的数据模式包括文本、图像、音频、表格数据等。一种数据模式可以用另一种数据模式表示或近似。例如:
-
音频可以表示为图像(梅尔声谱图)。
-
语音可以转录成文本,但纯文本表示会丢失音量、语调、停顿等信息。
-
图像可以表示为矢量,而矢量又可以被展平并表示为文本标记序列。
-
视频是一系列图像和音频的组合。如今的机器学习模型大多将视频视为一系列图像。这是一个严重的限制,因为事实证明,声音对于视频来说与视觉效果同样重要。88 % 的 TikTok 用户表示,声音对于他们的 TikTok 体验至关重要。
-
只要你拍摄一张照片,文本就可以表示为图像。
-
数据表可以转换成图表,也就是图像。
其他数据模式怎么样?
所有数字数据格式都可以使用位串(0 和 1 的字符串)或字节串来表示。能够有效从位串或字节串中学习的模型将非常强大,它可以从任何数据模式中学习。
我们还未涉及其他数据形式,例如图形和 3D 资产。我们也没有涉及用于表示嗅觉和触觉(触觉)的格式。
在当今的机器学习中,音频仍然在很大程度上被视为基于语音的文本替代品。音频最常见的用例仍然是语音识别(语音转文本)和语音合成(文本转语音)。非语音音频用例(例如音乐生成)仍然相当小众。
图像可能是模型输入最通用的格式,因为它可用于表示文本、表格数据、音频以及某种程度上的视频。视觉数据也比文本数据多得多。如今,我们的手机/网络摄像头会不断拍摄照片和视频。
文本是模型输出的更强大的模式。可以生成图像的模型只能用于图像生成,而可以生成文本的模型可以用于许多任务:摘要、翻译、推理、问答等。
为简单起见,我们将重点关注两种模式:图像和文本。这些知识可以推广到其他模式。
多模态任务
要理解多模态系统,了解它们要解决的任务很有帮助。在文献中,我经常看到视觉语言任务分为两类:生成和视觉语言理解(VLU),后者是所有不需要生成的任务的总称。这两类任务之间的界限很模糊,因为生成答案也需要理解。
生成
对于生成任务,输出可以是单模态(例如文本、图像、3D 渲染)或多模态。虽然单模态输出如今很常见,但多模态输出仍在形成中。
图像生成(文本到图像合成)
此类别很简单。示例:Dall-E、Stable Diffusion 和 Midjourney。
文本生成
一个常见的文本生成任务是视觉问答。您可以为模型提供文本和图像,而不是仅依赖文本来获取上下文。想象一下,您可以将相机对准任何物体并提出问题,例如:
“我的车无法启动。它出了什么问题?”
“如何制作这道菜?”
“这个 meme 是关于什么的?”
另一个常见用例是图像字幕,它可以用作基于文本的图像检索系统的一部分。一个组织可能拥有数百万甚至数十亿张图像:产品图像、图表、设计、团队照片、宣传材料等。人工智能可以自动为它们生成字幕和元数据,让您更轻松地找到所需的确切图像。
视觉语言理解
我们将放大两种任务类型:分类和基于文本的图像检索(TBIR)。
分类
分类模型只能生成属于预定类别列表的输出。当您只关心固定数量的结果时,这种方法很有效。例如,OCR 系统只需要预测视觉内容是否是已知字符之一(例如数字或字母)。
OCR 当与能够理解更广泛上下文的系统一起使用时,它可以允许您与任何教科书、合同、组装说明等“对话”。

使用 GPT-4V 进行文档处理。错误以红色突出显示。
分类相关的一项任务是图像到文本检索:给定一张图片和一组预定义文本,找到最有可能伴随该图片的文本。这对于产品图片搜索(即从图片中检索产品评论)很有帮助。
基于文本的图像检索(图像搜索)
图像搜索不仅对搜索引擎很重要,而且对企业来说也很重要,因为它可以搜索其内部的所有图像和文档。有些人将基于文本的图像检索称为“文本到图像的检索”。
基于文本的图像检索有几种方法。其中两种是:
-
手动或自动为每幅图像生成标题和元数据。给定一个文本查询,找到标题/元数据与该文本查询最接近的图像。
-
为图像和文本训练一个联合嵌入空间。给定一个文本查询,为该查询生成一个嵌入,并找到所有嵌入最接近该嵌入的图像。
第二种方法更加灵活,相信会得到更广泛的应用。这种方法需要为视觉和语言提供强大的联合嵌入空间,就像 OpenAI 的CLIP开发的那样。
多模式训练基础知识
这篇文章选择 两个模型:CLIP(2021)和 Flamingo(2022)作为案例。
-
CLIP 是第一个能够推广到具有零次和几次学习的多个图像分类任务的模型。
-
Flamingo 并不是第一个能够生成开放式响应的大型多模态模型。然而,Flamingo 的强劲表现促使一些人将其视为多模态领域的 GPT-3 时刻。
尽管这两个模型比较老,但它们使用的许多技术在今天仍然适用。我希望它们可以作为理解新模型的基础。
从高层次来看,多模式系统由以下组件组成:
-
针对每种数据模态的编码器,为该模态的数据生成嵌入。
-
将不同模态的嵌入对齐到同一多模态嵌入空间的方法。
-
[仅限生成模型]生成文本响应的语言模型。由于输入可以同时包含文本和视觉效果,因此需要开发新技术,使语言模型不仅能够根据文本,还能根据视觉效果来调节其响应。
理想情况下,这些组件应该尽可能地预先训练并可重复使用。
CLIP:对比语言-图像预训练
CLIP 的主要贡献在于它能够将不同模态(文本和图像)的数据映射到共享的嵌入空间中。这种共享的多模态嵌入空间使文本到图像和图像到文本的任务变得容易得多。
训练这个多模态嵌入空间还产生了一个强大的图像编码器,这使得 CLIP 能够在许多图像分类任务上实现具有竞争力的零样本性能。这种强大的图像编码器可以用于许多其他任务:图像生成、视觉问答和基于文本的图像检索。
Flamingo 和 LLaVa 使用 CLIP 作为其图像编码器。
DALL-E 使用 CLIP 对生成的图像进行重新排序。
目前尚不清楚 GPT-4V 是否使用 CLIP。
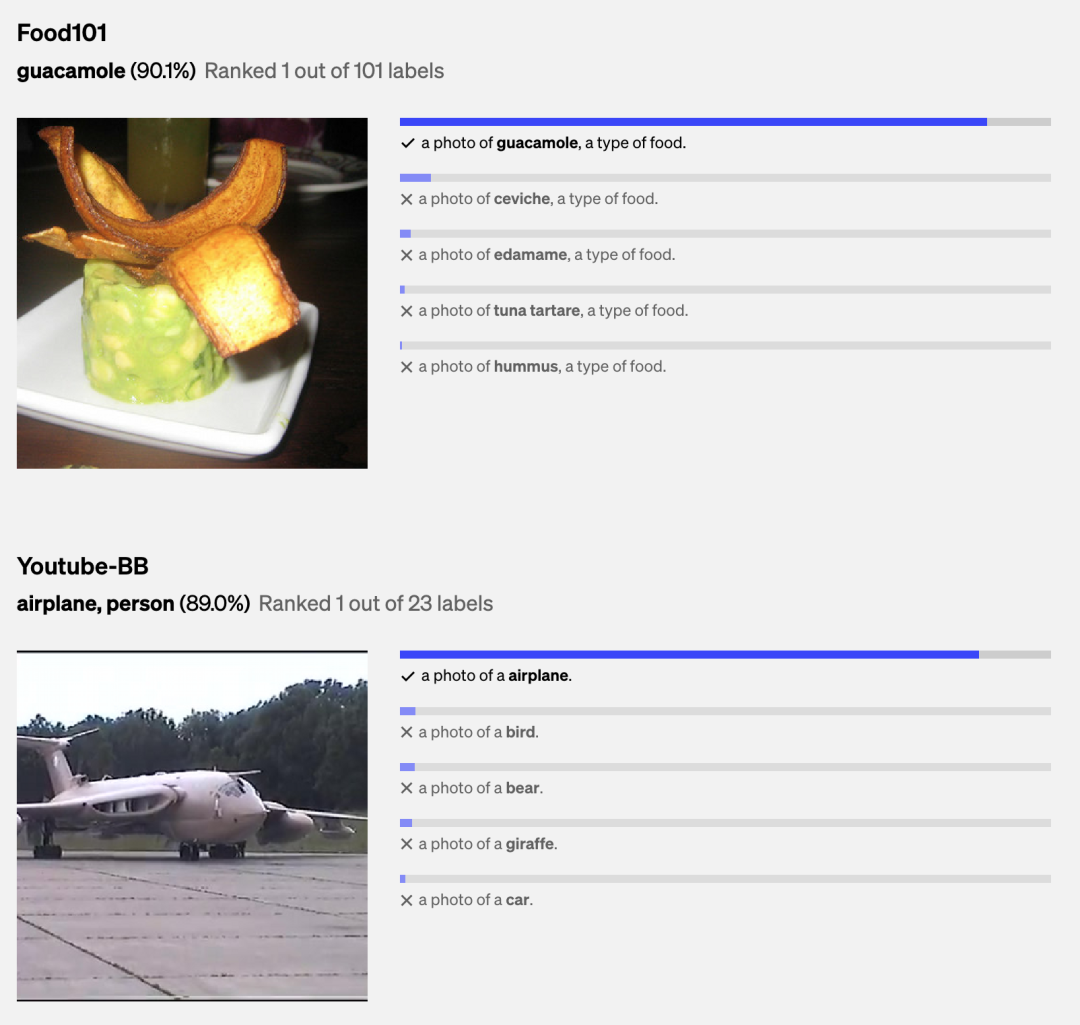
使用 CLIP 进行零样本图像分类
CLIP 利用了自然语言监督和对比学习,这使得 CLIP 既可以扩大数据规模,又可以提高训练效率。我们将介绍这两种技术的工作原理。
CLIP 的架构
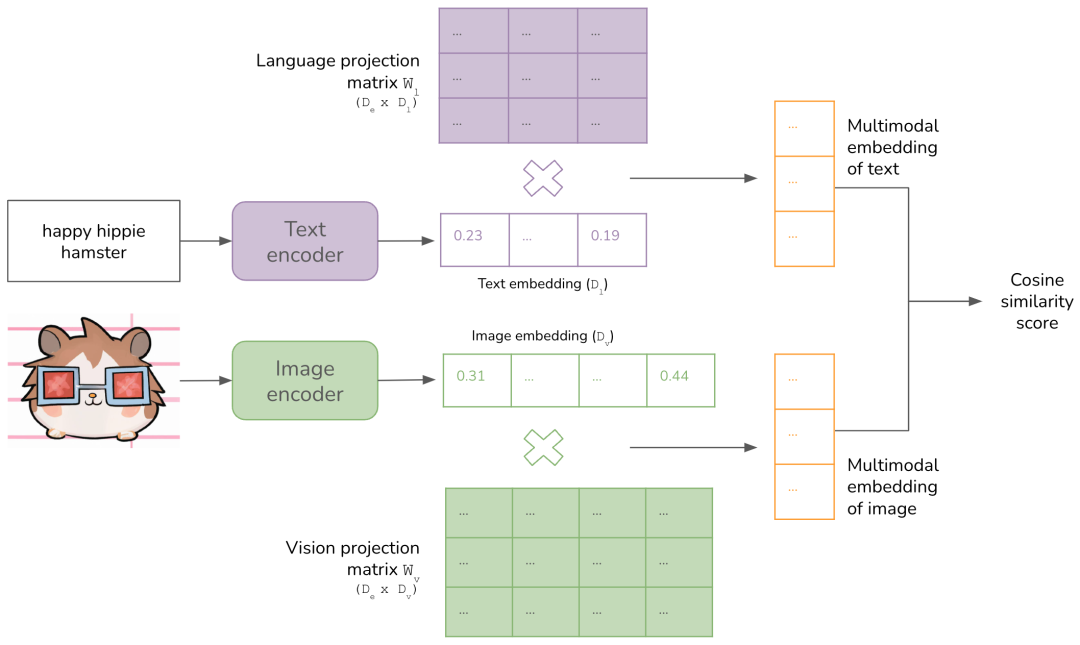
CLIP 的架构。编码器和投影矩阵都是从头开始联合训练的。训练目标是最大化正确(图像、文本)配对的相似度得分,同时最小化错误配对的相似度得分(对比学习)。
对于图像编码器,作者尝试了 ResNet 和 ViT。他们表现最好的模型是ViT-L/14@336px:
-
大型视觉变压器(ViT-L)
-
14 个补丁(每个图像分为 14x14 像素补丁/子图像)
-
336x336 像素输入
对于文本编码器,CLIP 使用与GPT-2类似但更小的 Transformer 模型。其基础模型只有 63M 个参数,带有 8 个注意力头。作者发现 CLIP 的性能对文本编码器的容量不太敏感。
使用两个投影矩阵将图像编码器和文本编码器生成的嵌入投影到同一个嵌入空间中。
当人们说 CLIP 嵌入时,他们要么指这些多模态嵌入,要么指 CLIP 的图像编码器生成的嵌入。
自然语言监督
多年来,图像模型都是使用手动注释的(图像、文本)数据集(例如 ImageNet、MS COCO)进行训练的。这是不可扩展的。手动注释既费时又费钱。
CLIP 论文指出,当时可用的(图像、文本)数据集都不够大、质量不够高。他们创建了自己的数据集 - 4 亿个(图像、文本)对 - 如下所示。
-
构建一个包含 500,000 个查询的列表。查询是常用词、二元词组和热门维基百科文章的标题。
-
查找与这些查询匹配的图像(字符串和子字符串匹配)。论文提到这种搜索并未在搜索引擎上进行,但没有具体说明在哪里进行。我的理论是,由于 OpenAI 已经为他们的 GPT 模型搜索了整个互联网,他们可能只是查询了他们的内部数据库。
-
每个图像都与与其同时出现的文本(例如标题、评论)配对,而不是查询,因为查询太短而无法描述。
由于某些查询比其他查询更受欢迎,为了避免数据不平衡,他们最多使用 20K 张图像进行查询。
对比学习
在 CLIP 之前,大多数视觉语言模型都是使用分类器或语言模型目标进行训练的。对比目标是一种巧妙的技术,它使 CLIP 能够扩展并推广到多个任务。
接下来,我们来讲解为什么语言模型目标更适合 CLIP:给定一张图片,生成一个描述它的文本。
分类器目标
分类器会在预定的类别列表中预测正确的类别。当输出空间有限时,这种方法很有效。之前使用(图像、文本)对数据集的模型都有此限制。例如,使用ILSVRC-2012 的模型将自己限制为 1,000 个类别,而JFT-300M则限制为 18,291 个类别。
这一目标不仅限制了模型输出有意义响应的能力,还限制了其零样本学习的能力。假设模型被训练用于预测 10 个类别,那么它就无法完成包含 100 个类别的任务。
语言模型目标
如果分类器针对每个输入仅输出一个类别,那么语言模型则输出一系列类别。生成的每个类别称为一个标记。每个标记都来自语言模型的预定列表(即词汇表)。
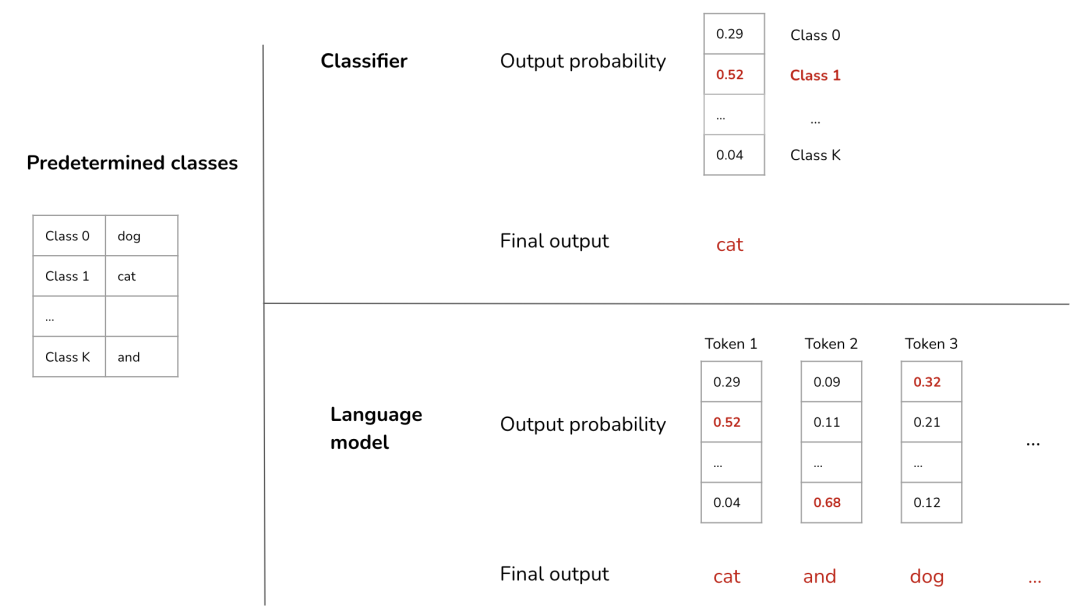
对比学习
虽然语言模型目标允许更灵活的输出,但 CLIP 的作者指出,这一目标使训练变得困难。他们推测这是因为模型试图生成与每幅图像相伴的准确文本,而图像可以附带多种文本:替代文本、标题、评论等。
例如在Flickr30K 数据集中,每幅图像都有 5 个由人工注释者提供的标题,并且同一幅图像的标题可能有很大差异。

对比学习就是为了克服这一挑战。CLIP 不是预测每幅图像的确切文本,而是被训练来预测一段文本是否比其他文本更有可能伴随图像。
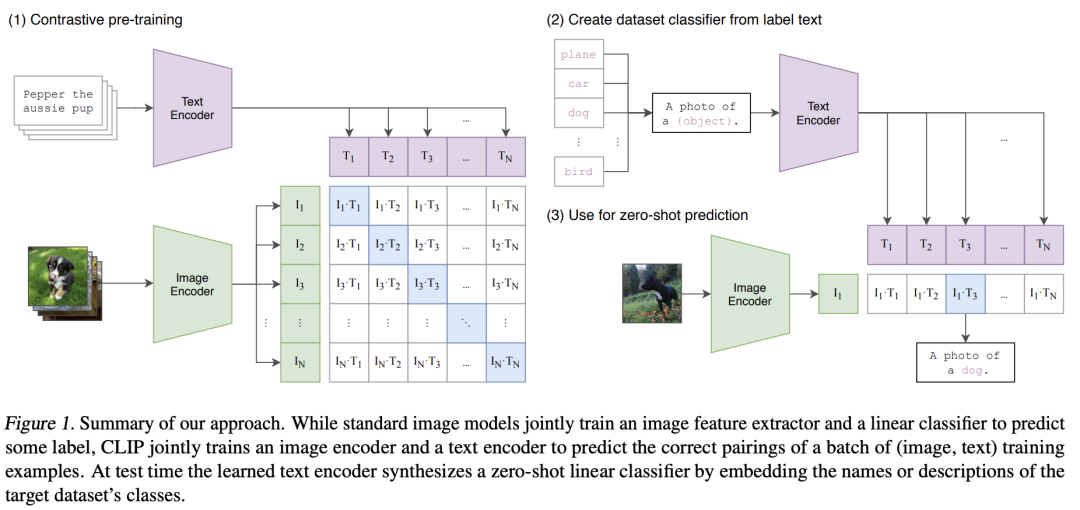
另一种看待这个问题的方式是,CLIP 的每个训练批次都是两个分类任务。
1 每幅图像可以与 N 个可能的文本配对,然后模型会尝试预测正确的文本。这与图像到文本检索的设置相同。
2 每篇文本可以与 N 张可能的图像配对,然后模型会尝试预测正确的图像。这与文本到图像检索的设置相同。
这两个损失的总和被最小化。

伪代码
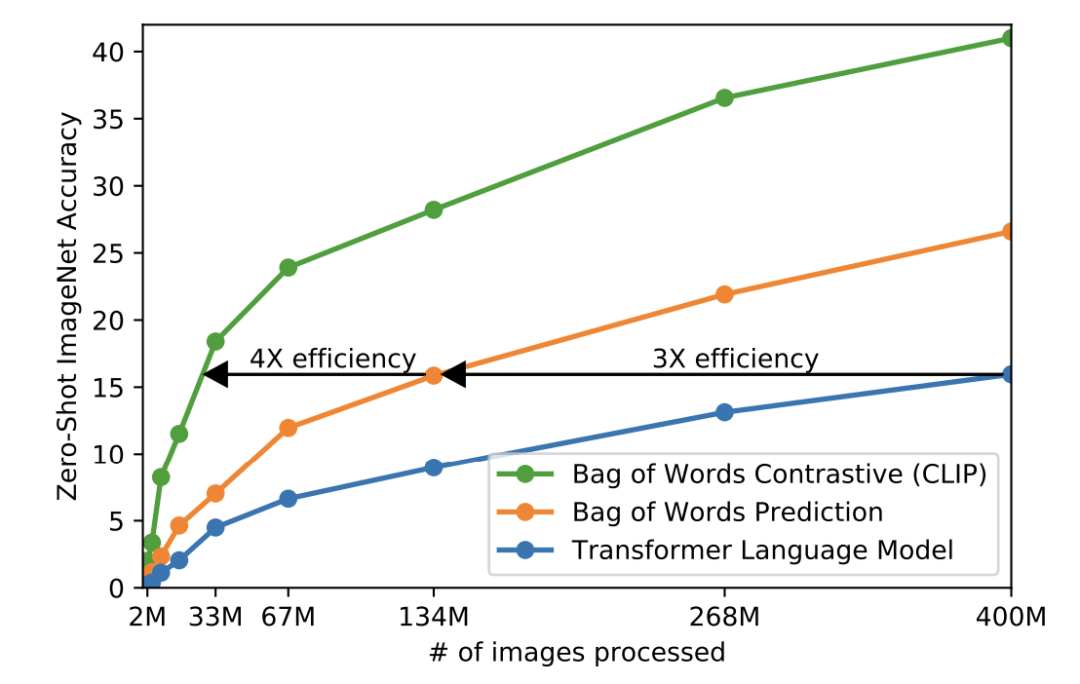
CLIP 的作者发现,与语言模型目标基线相比,对比目标的效率提高了 12 倍,同时产生了更高质量的图像嵌入。
CLIP 应用程序
分类
如今,对于许多图像分类任务而言,CLIP 仍然是一个强大的开箱即用基线,可以直接使用或经过微调。
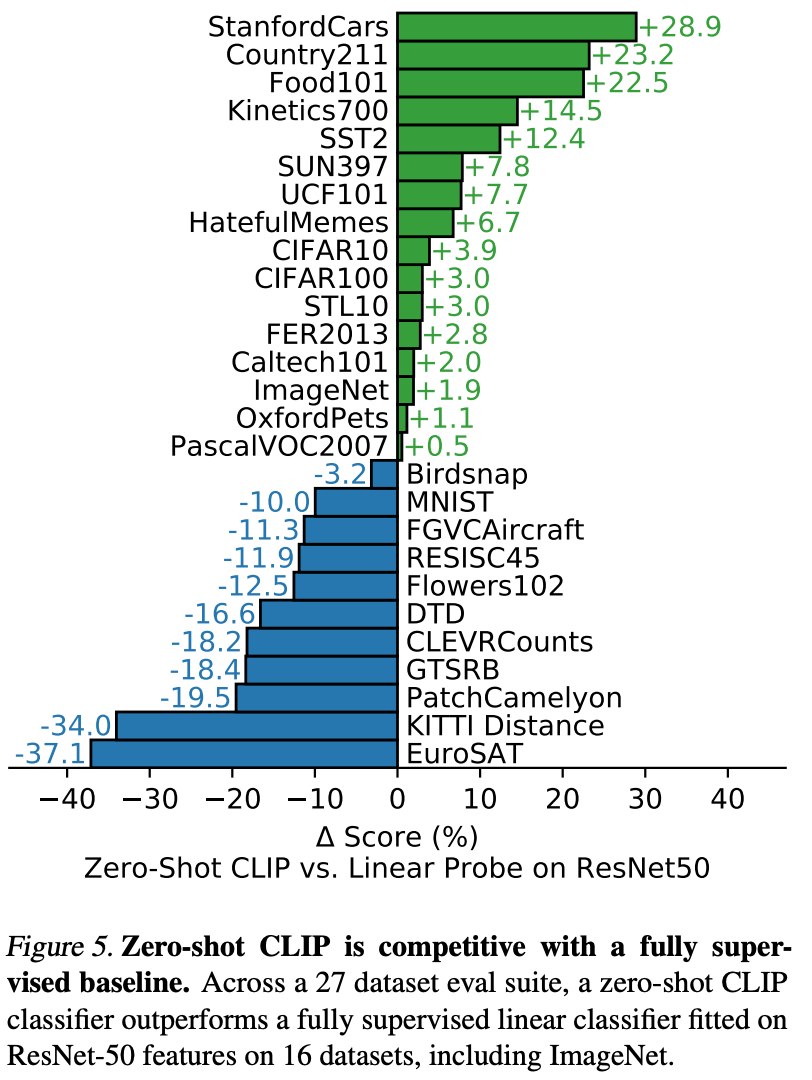
基于文本的图像检索
由于 CLIP 的训练过程在概念上类似于图像到文本检索和文本到图像检索,CLIP“在图像检索或搜索等广泛应用的任务中显示出巨大的潜力”。但是,“在图像检索方面,CLIP 的性能相对于整体最新水平明显较低。
有尝试使用 CLIP 进行图像检索。例如,clip-retrieval包的工作原理如下:
-
为所有图像生成 CLIP 嵌入并将其存储在矢量数据库中。
-
对于每个文本查询,为该文本生成一个 CLIP 嵌入。
-
在向量数据库中查询所有嵌入接近此文本查询嵌入的图像。
图像生成
CLIP 的联合图像文本嵌入对于图像生成非常有用。给定一个文本提示,DALL-E (2021) 会生成许多不同的视觉效果,并使用 CLIP 对这些视觉效果进行重新排序,然后向用户显示排名靠前的视觉效果。
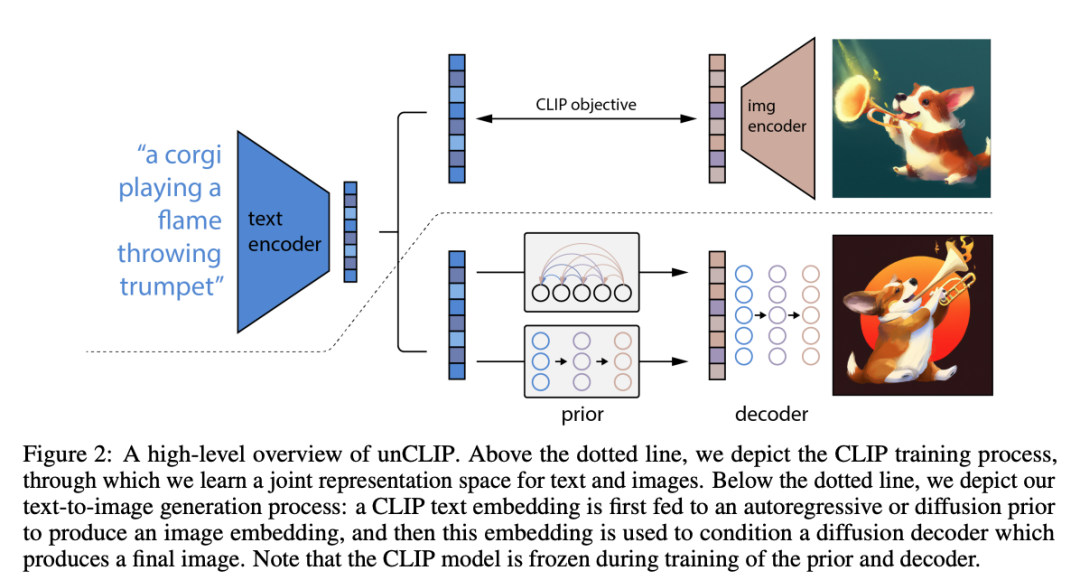
2022 年,OpenAI 推出了unCLIP,这是一种基于 CLIP 潜在特征的文本到图像合成模型。它由两个主要组件组成:
-
CLIP 已训练并冻结。预训练的 CLIP 模型可以在同一个嵌入空间中为文本和图像生成嵌入。
-
图像生成时会发生两件事:
-
使用 CLIP 为该文本生成嵌入。
-
使用扩散解码器生成以此嵌入为条件的图像。
文本生成:视觉问答、字幕
CLIP 的作者确实尝试过创建一个文本生成模型。他们试验过的一个版本叫做 LM RN50。虽然这个模型可以生成文本响应,但在 CLIP 评估的所有视觉语言理解任务中,它的性能始终比 CLIP 表现最好的模型低 10% 左右。
虽然今天 CLIP 并不直接用于文本生成,但其图像编码器通常是可生成文本的 LMM 的骨干。
Flamingo ,LMM 的曙光
与 CLIP 不同,Flamingo 可以生成文本响应。简单来说,Flamingo 是 CLIP + 语言模型, 使语言模型能够根据视觉和文本输入生成文本标记。

Flamingo 可以根据文本和图像生成文本响应
Flamingo 的架构
从高层次来看,Flamingo 由两部分组成:
-
视觉编码器:使用对比学习训练类似 CLIP 的模型。然后丢弃该模型的文本编码器。冻结视觉编码器以在主模型中使用。
-
语言模型:Flamingo 使用语言模型损失对 Chinchilla 进行微调,以生成基于视觉和文本的文本标记,并添加两个附加组件:感知器重采样器和 GATED XATTN-DENSE 层。
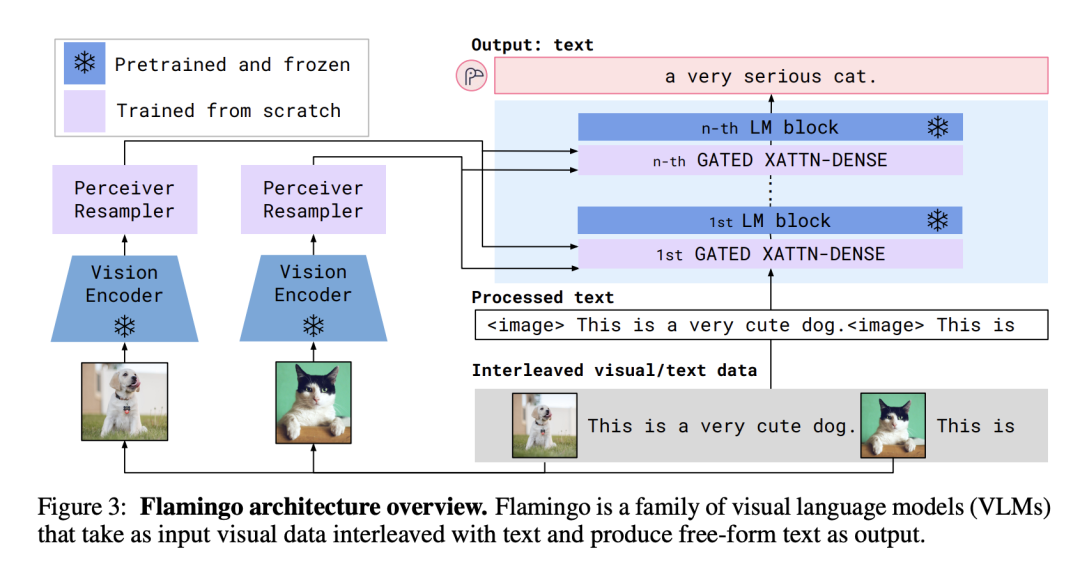
数据
Flamingo 使用了 4 个数据集:2 个(图像,文本)对数据集、1 个(视频,文本)对数据集和 1 个交错图像和文本数据集。

Flamingo 的视觉编码器
Flamingo 首先使用对比学习从头开始训练类似 CLIP 的模型。此组件仅使用 2 个(图像、文本)对数据集,即 ALIGN 和 LTIP,总计 2.1B(图像、文本)对。这比 CLIP 训练所用的数据集大 5 倍。
-
对于文本编码器,Flamingo 使用 BERT 而不是 GPT-2。
-
对于视觉编码器,Flamingo 使用 NormalizerFree ResNet (NFNet) F6 模型。
-
文本和视觉嵌入在投影到联合嵌入空间之前经过均值池化。
Flamingo 的语言模型
Flamingo 使用 Chinchilla 作为其语言模型。更具体地说,他们冻结了 9 个预训练的 Chinchilla LM 层。传统语言模型根据前面的文本标记预测下一个文本标记。Flamingo 根据前面的文本和视觉标记预测下一个文本标记。
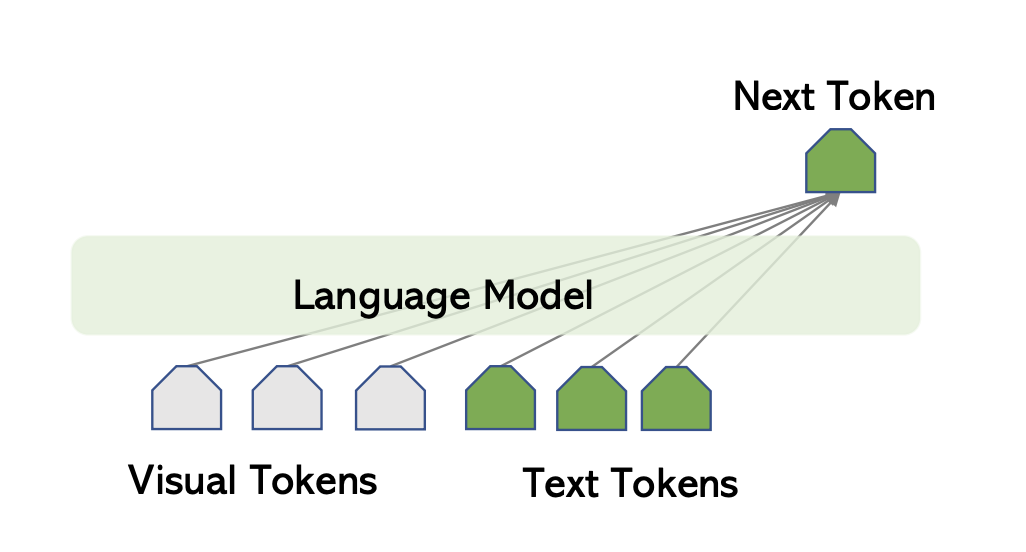
下一个标记生成取决于文本和视觉标记。插图取自 Chunyuan Li 的 CVPR 2023 教程:大型多模态模型。
为了能够生成基于文本和视觉输入的文本,Flamingo 依赖于 Perceiver Resampler 和 GATED XATTN-DENSE 层。
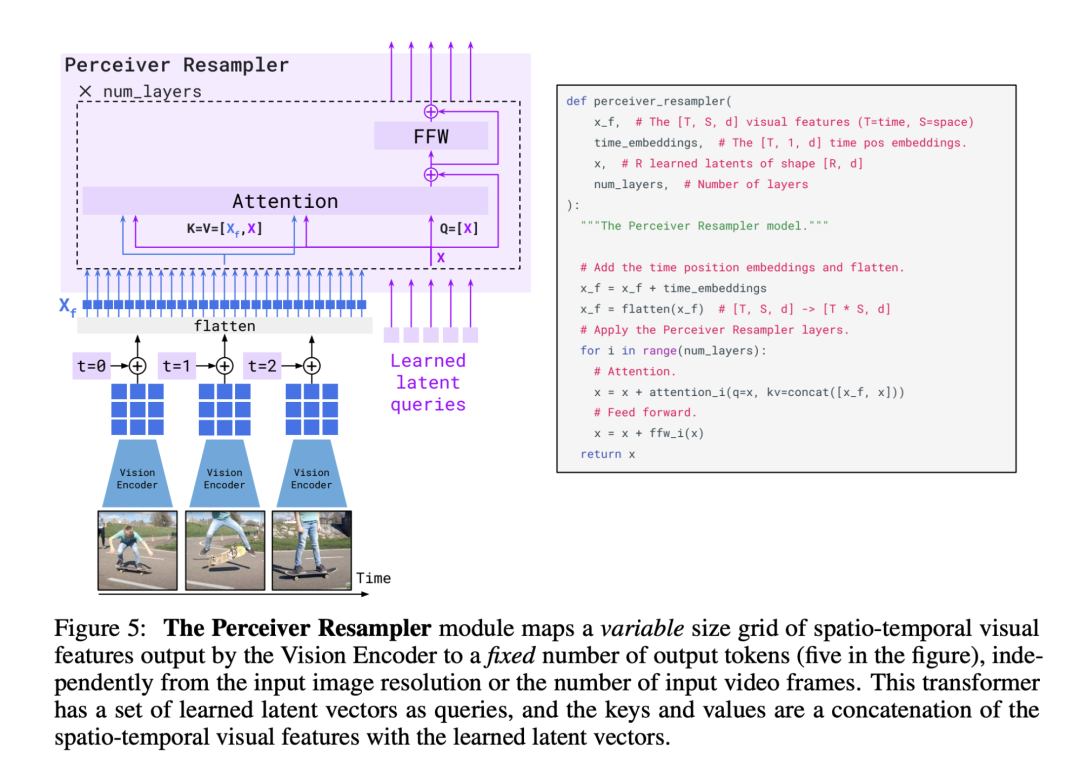
感知器重采样器 Perceiver Resampler
由于视觉输入可以是图像也可以是视频,因此视觉编码器可以生成数量不定的图像或视频特征。感知器重采样器将这些可变特征转换为一致的 64 个视觉输出。
有趣的是,在训练视觉编码器时,使用的分辨率为 288 x 288。然而,在这个阶段,视觉输入的大小被调整为 320 × 320。事实证明,在使用 CNN 时,更高的测试时间分辨率可以提高性能。
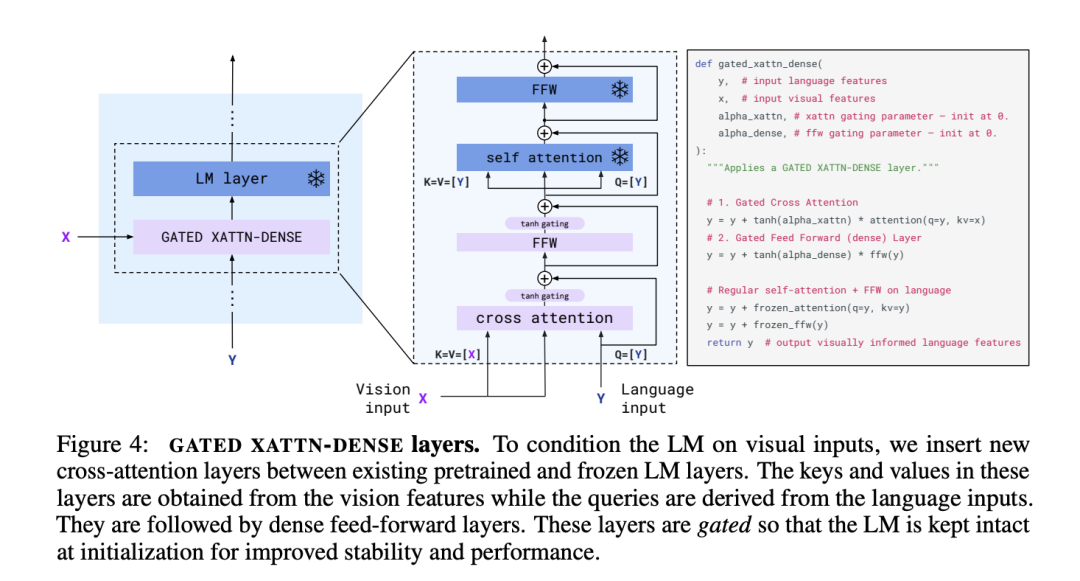
GATED XATTN-DENSE 层
GATED XATTN-DENSE 层插入现有和冻结的 LM 层之间,使语言模型在生成文本标记时能够更有效地关注视觉标记。如果没有这些层,Flamingo 作者注意到总体得分下降了 4.2%。
虽然 Flamingo 不是开源的,但是有很多 Flamingo 的开源复制品:
-
IDEFICS (HuggingFace)
-
mlfoundations/open_flamingo
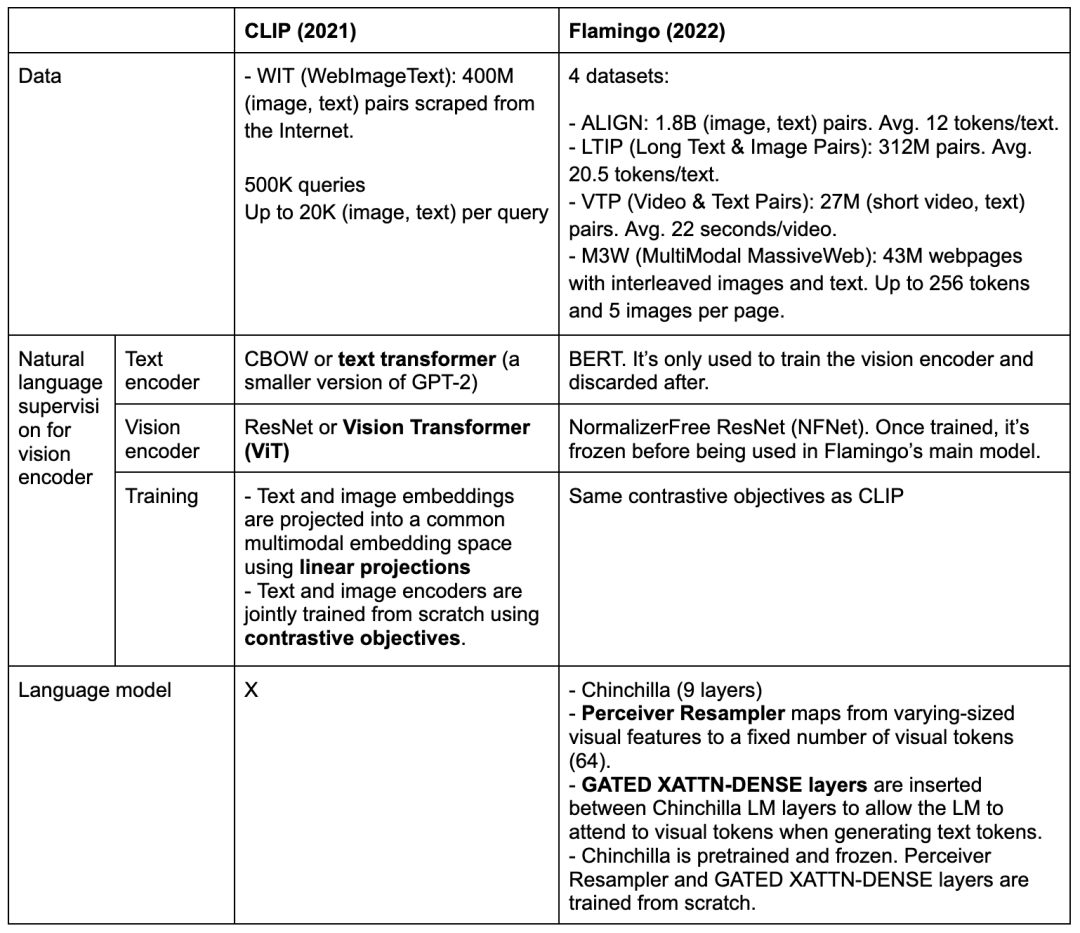
总结CLIP和Flamingo
LMM 的研究方向
CLIP 已经有 3 年历史了,而 Flamingo 也 2 岁了。它们的架构为我们理解 LMM 的构建方式奠定了良好的基础,同时该领域也出现了许多新进展。
整合更多数据模式
如今,大多数多模态系统都适用于文本和图像。我们需要能够整合视频、音乐和 3D 等其他模态的系统只是时间问题。如果所有数据模态都有一个共享的嵌入空间,那岂不是很棒?
此领域的作品示例:
-
ULIP:学习语言、图像和点云的统一表示以实现 3D 理解(Xue 等人,2022 年 12 月)
-
ImageBind:一个嵌入空间即可绑定所有内容(Girdhar 等人,2023 年 5 月)
-
NExT-GPT:任意到任意多模态大型语言模型(Wu 等人,2023 年 9 月)
-
Jeff Dean 雄心勃勃的Pathways项目 (2021):其愿景是“实现同时涵盖视觉、听觉和语言理解的多模式模型”。

用于遵循指令的多模式系统
Flamingo 接受了完成训练,但未接受对话或遵循指令的训练。许多人正在致力于构建可以遵循指令并进行对话的 LMM,例如:
-
MultiInstruct:通过指令调整改进多模态零样本学习(Xu 等人,2022 年 12 月)
-
LLaVA:视觉指令调整(Liu 等人,2023 年 4 月 28 日)
-
InstructBLIP:面向具有指令调整的通用视觉语言模型(Salesforce,2023 年 5 月 11 日)
-
LaVIN:廉价而快速:针对大型语言模型的高效视觉语言指令调整(Luo 等人,2023 年 5 月 24 日)

LaVIN 的论文中展示了 LaVIN 的输出与其他 LMM 的比较示例
生成多模式输出
虽然能够处理多模态输入的模型正在成为常态,但多模态输出仍然滞后。许多用例需要多模态输出。例如,如果我们要求 ChatGPT 解释 RLHF,有效的解释可能需要图表、方程式,甚至简单的动画。
要生成多模态输出,模型首先需要生成一个共享的中间输出。一个关键问题是中间输出是什么样子的。
中间输出的一个选项是文本,然后它将用于生成/合成其他动作。
例如,CM3(Aghajanyan 等人,2022 年)输出 HTML 标记,这些标记可以编译成不仅包含文本还包含格式、链接和图像的网页。GPT-4V 生成 Latex 代码,然后可以将其重建为数据表。

来自 CM3 的采样输出
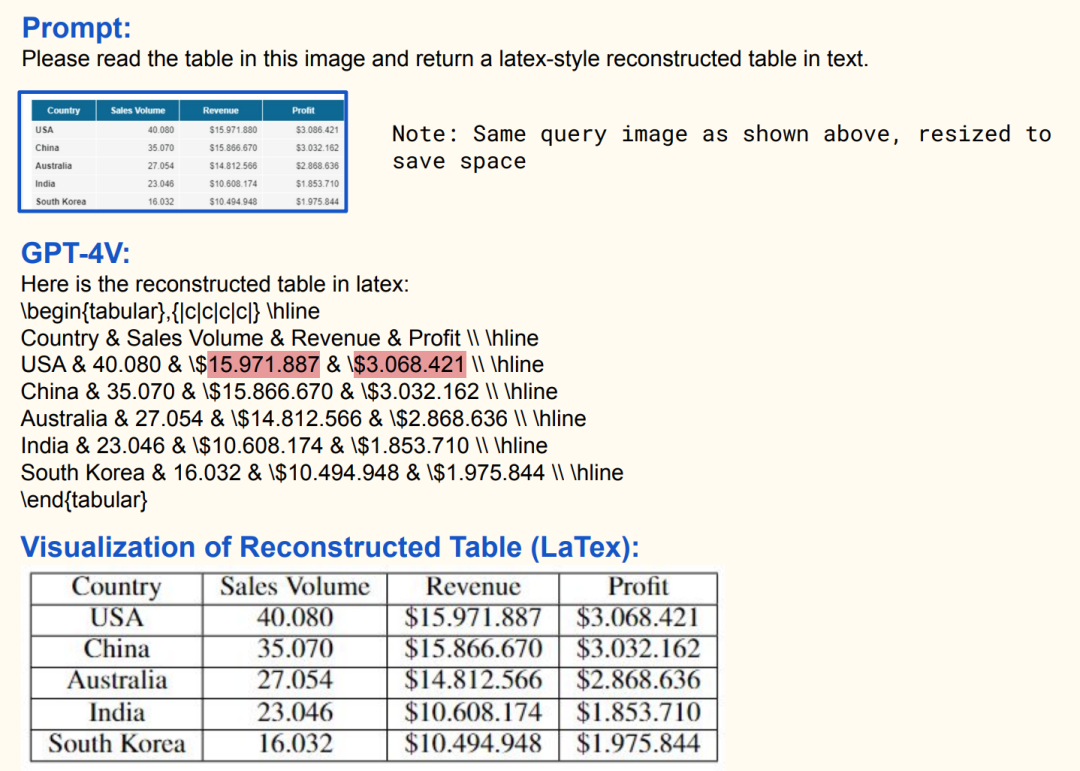
GPT-4V 生成 Latex 代码,然后可以将其重建为数据表
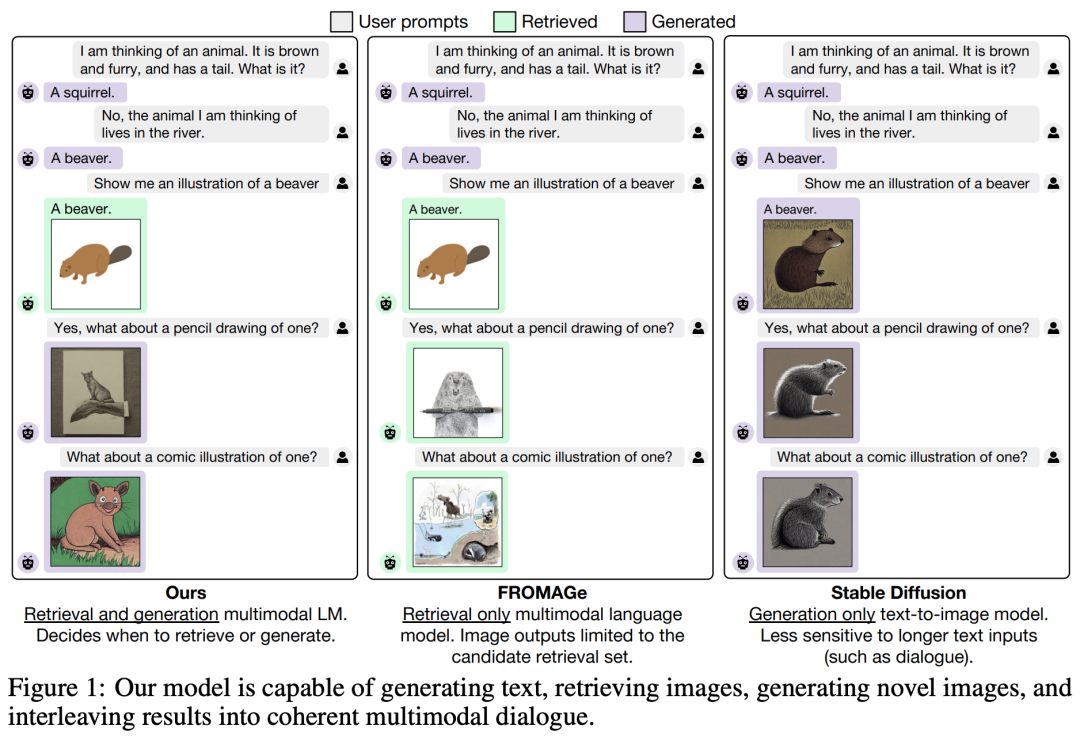
中间输出的另一种选择是多模态标记。Caiming Xiong的团队在 Salesforce 上做了很多出色的多模态工作。每个标记都会有一个标签来表示它是文本标记还是图像标记。然后,图像标记将被输入到 Diffusion 等图像模型中以生成图像。然后,文本标记将被输入到语言模型中。
使用多模态语言模型生成图像(Koh 等人,2023 年 6 月) 是一篇很棒的论文,展示了 LMM 如何生成和检索图像以及生成文本。
最后
我们仍处于多模态系统的早期阶段。多模态系统(尤其是 LMM)将比大型语言模型更具影响力。但是,请记住,LMM 不会让 LLM 过时。随着 LMM 在 LLM 上扩展,LMM 的性能依赖于其基础 LLM 的性能。许多研究多模态系统的实验室同时研究 LLM。
原文:
https://huyenchip.com/2023/10/10/multimodal.html
shadow:
欢迎加入社群交流,我们在研究大模型的应用场景,以及制作AI产品。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 14
14 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)