
Textual Inversion、DreamBooth、LoRA、InstantID:从低成本进化到零成本实现IP专属的AI绘画模型
2023年7月份国内有一款定制写真AI工具爆火。一款名为妙鸭相机的AI写真,成功在C端消费者群体中出圈,并在微信、微博和小红书等平台迅速走红,小红书上的话题Tag获得了330多万的浏览量,相关微信指数飙升到了1800万以上。其他能够提供类似功能例如:LensaAI,Midjourney,DALL-E3,Stable Diffusion,Tiamat。只不过LensaAI和妙鸭相机对于定制图像生成更
2023年7月份国内有一款定制写真AI工具爆火。一款名为妙鸭相机的AI写真小程序,成功在C端消费者群体中出圈,并在微信、微博和小红书等平台迅速走红,小红书上的话题Tag获得了330多万的浏览量,相关微信指数飙升到了1800万以上。
其他能够提供类似功能例如:LensaAI,Midjourney,DALL-E3,Stable Diffusion,Tiamat。只不过LensaAI和妙鸭相机对于定制图像生成更加专精一些。
这背后用到技术演化,就是Textual Inversion、DreamBooth、LoRA、InstantID这四类,从一开始需要样本数据微调,到2024年1月发布InstantID不需要样本数据微调。
本文跟朋友们分享相关技术。
欢迎关注留言!
Stable Diffusion 简称 SD。
Textual Inversion
为了更好理解Textual Inversion算法,我先回顾下SD词嵌入向量的使用方式。 也可以看我以前的文章。
当我在SD AI上画画时,我会先输入一个提示。这个提示会被一个叫做“tokenizer”的工具拆分成很多小部分,每个小部分都有一个独特的标识,叫做“token_id”。接着,这些“token_id”会在一个已经准备好的词库里找到对应的词嵌入向量。这些词嵌入向量就像是我们提示的“翻译”,让机器能更好地理解。
然后,我会把这些词嵌入向量放在一起,传给CLIP的文本编码器。这个编码器会帮我把这些向量变成一种更容易理解的形式,也就是文本表征。有了这个文本表征,我就可以用一个叫做“交叉注意力机制”的工具来控制我的图像生成了。简单来说,就是我想画什么,机器就能帮我画出什么。
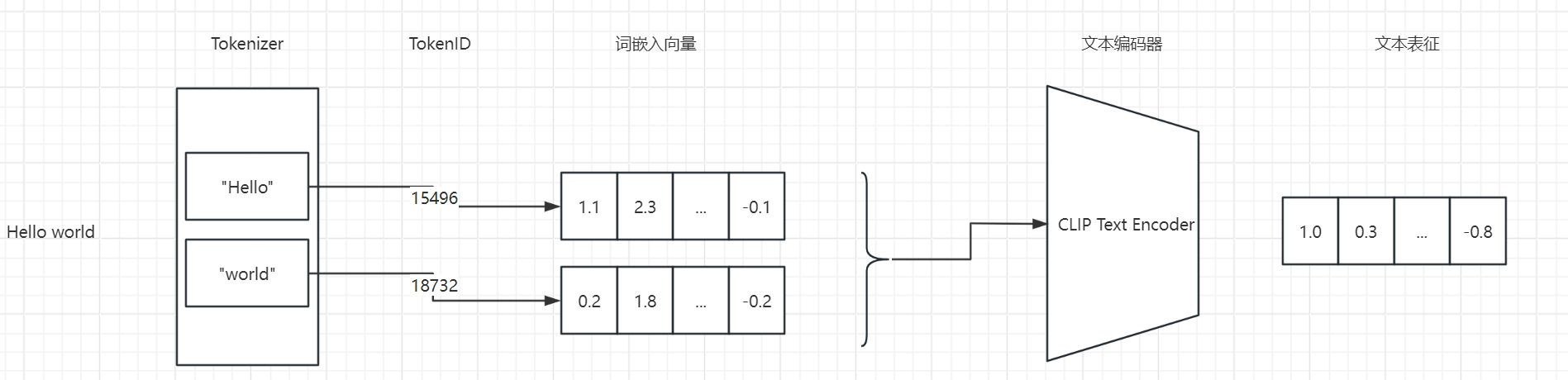
理解了 SD 词嵌入向量的使用,再来学习 Textual Inversion 这个算法就会非常简单。
Textual Inversion 算法的本质是学习一个全新的词嵌入向量,用于指代定制化的内容。其核心思想便是,对于一个给定的物体或者风格,去学习一个全新的词嵌入向量,并绑定一个符号比如 S*,为其分配一个新的 token_id。这样,每次文生图的时候只需要带上 S*,就能生成我们想要定制化的物体或者风格。
**重点在于,这个过程不需要对整个AI模型进行调整或重新训练,只是在它的词汇库中添加了一个新的词汇而已。**这样做的好处是可以保留AI模型原有的理解能力和创造力,同时又增加了一些个性化的元素。
需要3到5张展示特定概念(比如你的猫)的图片来训练AI。
论文地址:https://arxiv.org/pdf/2208.01618.pdf


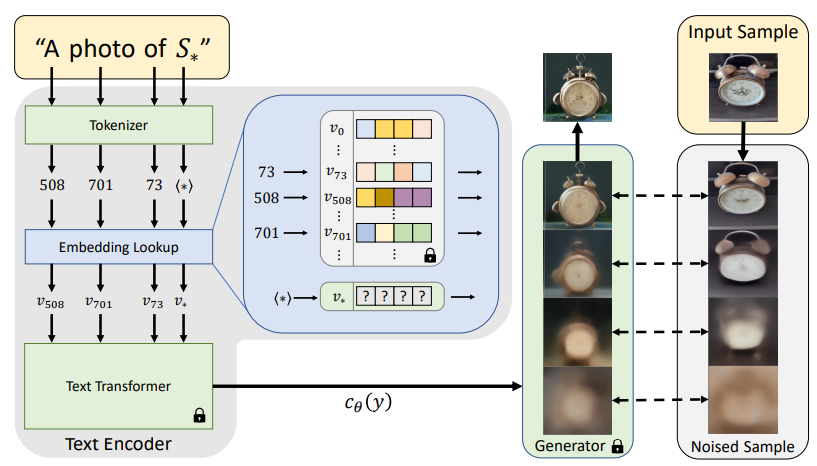
Textual Inversion 的训练其实挺简单的,分两步走。
首先,你得给你想要的关键词,比如 S*,配一个新的“身份证”,我们叫它 token_id。然后,给这个新“身份证”初始化一个词嵌入向量。举个例子,如果原来的词库里已经有 20000 个词了,那 S* 的“身份证”就是第 20001 号。
接下来,找个已经训练好的 AI 画画模型,比如 Stable Diffusion 或者 DALL-E 3。在训练的时候,CLIP 文本编码器和 UNet 这些模型的“技能”都不变,就固定在那里。然后,用你提供的 3-5 张图片,按照模型的标准训练方法来训练。这个过程中,只有你给 S* 新初始化的那个词嵌入向量在“学习”。
训练完了,你就得到了一个定制化的词嵌入向量,它能帮你表达出训练图片里的物体或者风格。
这里有两点要注意: 一是这个词嵌入向量是和你选的 AI 绘画模型绑在一起的; 二是 Textual Inversion 还可以同时优化好几个新增的词嵌入向量。
如果你想更深入了解,可以点击链接去看看 Textual Inversion 的训练代码。
https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py
DreamBooth
DreamBooth 论文:https://arxiv.org/abs/2208.12242
Textual Inversion 在训练时,能学习的参数并不多,大概只有512或768个浮点数那么点儿。所以,它在定制化生成方面的能力就有点儿局限。在市场上,如果你想要更个性化的生成效果,大家通常更喜欢用 DreamBooth。
说到 DreamBooth 这个名字,其实挺有意思的。Google 团队打了个比方,说它就像一个摄影棚,你进去拍照后,不仅仅是一张公开可用的图片,还能把你拍的东西放到你梦想的任何场景里。用 DreamBooth 的时候,你上传3~5张图,再加个新的描述词,就能定制一个物体或者一种风格了。后面我放了些图片,你可以看看 DreamBooth 的生成效果有多酷。


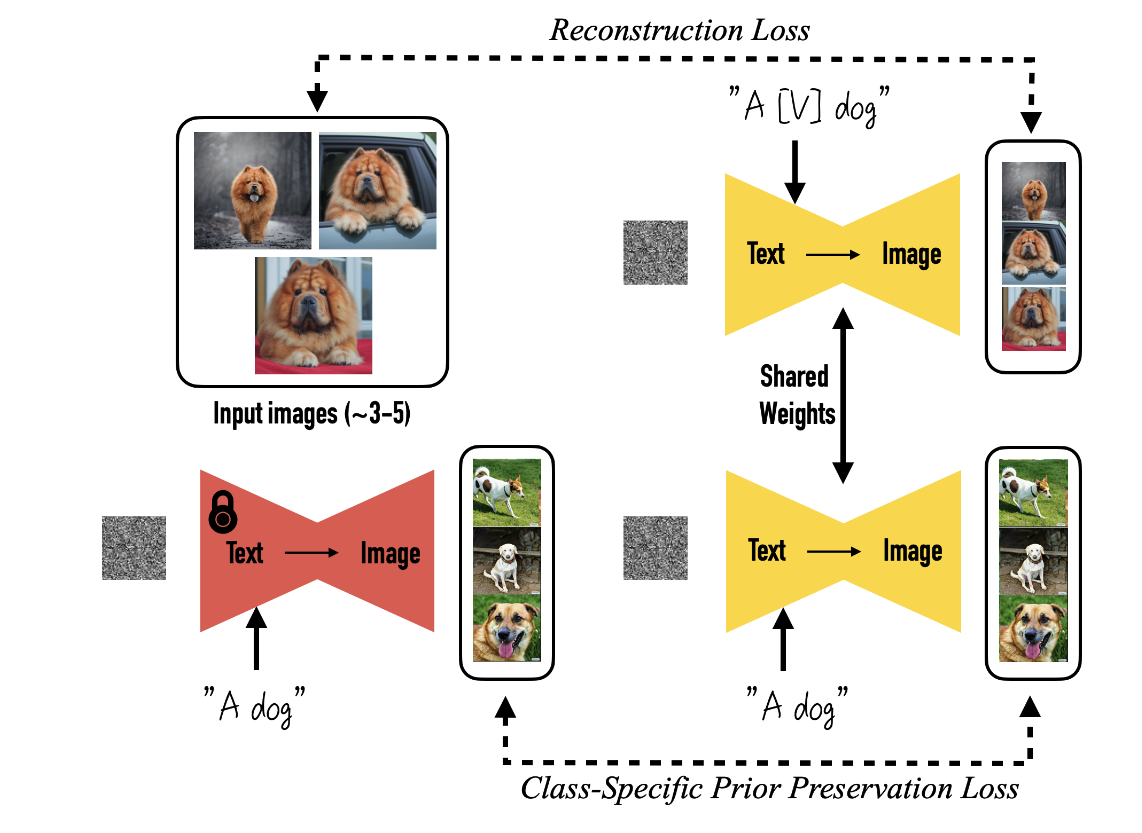
我来给你讲讲这个方案是怎么一回事吧。其实步骤很简单,就两步。
首先,你得挑个不常见的词作为关键词,比如说“CSS”。这个和Textual Inversion有点儿不同,那里的词得绑定全新的词嵌入向量,但这里不用。
然后呢,你得找个已经训练好的AI绘画模型,比如Stable Diffusion或者DALL-E 3。在训练过程中,UNet模型的权重是要打开的。接下来,就按照对应的AI绘画模型的标准训练方法,在你给的3-5张图片上训练一下。
你可能会有个疑问:就用这么几张图去调整UNet那么多参数,模型会不会变得太“偏执”了?比如说,如果你用了3-5张自己小狗的照片去训练,那模型是不是就只会画这一种样式的小狗了?没错,确实会有这个问题。这样训练出来的模型,不管你的prompt是“a CSS dog”还是“a dog”,它都只会画出你训练用的那种小狗。
不过别担心,论文作者已经想到了解决办法,那就是保留损失(preservation loss)。具体操作就是,先用AI绘画模型生成一批小狗的图片,然后在训练DreamBooth的时候,也把这批图像加进去一起训练。这样一来,模型就不会那么“偏执”了。
哦对了,训练DreamBooth的时候,CLIP文本编码器也是可以打开的。实践证明,这样做可以让定制化图像生成的效果更好。
总的来说,Textual Inversion和DreamBooth的区别就在于:前者只是优化一两个词嵌入向量,而后者则是对整个AI绘画模型进行微调。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的zi yuan得到学习提升
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些P DF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习zhi nan已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)