
NeurIPS 25 华中科大&国防科大提出NAUTILUS:突破深海视觉边界,首个水下多模态大模型问世!
此外,对于水下生物多样性的挑战,未来可以尝试将零样本学习(zero-shot learning)或小样本学习(few-shot learning)能力融入模型,使其在面对未知物种时也能做出合理的识别和描述,这对于真正的海洋探索应用至关重要。例如,在低光和浑浊场景下,NAUTILUS (LLaVA-1.5) 的性能提升分别高达7.5和8.1 PR@0.5,充分证明了其在复杂多变的水下环境中的强大适应
水下世界广阔而神秘,但水下图像通常存在颜色失真、对比度低和模糊等问题,这给机器自动理解水下场景带来了巨大困难。现有的研究方法大多只针对单一任务,并且缺乏一个大规模、高质量的数据集来训练能够处理多样化任务的强大模型。因此,如何构建一个既能看懂又能理解复杂水下环境的通用人工智能模型,是一个亟待解决的难题。
为了应对这些挑战,本文提出了一个融合水下物理先验的视觉增强多模态模型,名为NAUTILUS。该模型通过一个创新的模块来“修复”图像在水下损失的信息,并结合一个庞大的、新构建的水下多任务指令数据集NautData进行训练。最终,NAUTILUS在水下场景的分类、检测、问答等八项任务上都取得了领先的效果,展现了其强大的综合理解能力。
另外我整理了NeurIPS 2025 CV 相关论文+源码合集,一共200多篇,感兴趣的自取!
二、论文基本信息

论文标题: NAUTILUS: A Large Multimodal Model for Underwater Scene Understanding
作者姓名: Wei Xu, Cheng Wang, Dingkang Liang, Zongchuang Zhao, Xingyu Jiang, Peng Zhang, Xiang Bai
作者单位: 华中科技大学,国防科技大学
论文链接:https://arxiv.org/abs/2510.27481
项目地址: https://github.com/H-EmbodVis/NAUTILUS
三、主要贡献与创新
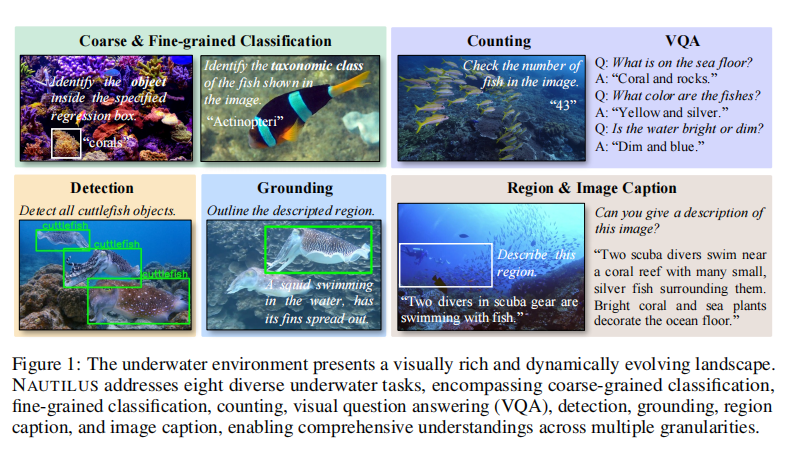
- 构建了首个大规模水下多任务指令微调数据集NautData,包含145万问答对,支持八种水下理解任务。
- 提出了首个能同时处理八项水下任务的大型多模态模型(large multimodal models, LMMs)NAUTILUS,实现了层级化的场景理解。
- 设计了一个即插即用的视觉特征增强模块(VFE),它基于物理模型,能显式地修复水下图像的退化信息。
- 实验证明,所提出的VFE模块能显著提升现有主流LMM在水下任务中的表现,验证了其有效性和通用性。
四、研究方法与原理
该论文提出的模型核心思路是:模仿水下成像物理模型 (underwater imaging model) 的原理,在特征层面“逆向”恢复被水下环境(如光线散射和吸收)破坏的视觉信息,让模型看到更“清晰”的数字世界。
物理成像模型基础
论文首先回顾了经典的水下成像物理模型,该模型认为我们相机拍摄到的水下图像 I c I_c Ic 是由两部分组成的:物体本身反射的光(直接分量) D c D_c Dc 和水中悬浮颗粒散射的光(后向散射分量) B c B_c Bc。其数学表达式为:
I c = D c + B c , D c = J c e − β c ( z ) ⋅ z I_c = D_c + B_c, \quad D_c = J_c e^{-\beta_c(z) \cdot z} Ic=Dc+Bc,Dc=Jce−βc(z)⋅z
其中, J c J_c Jc 是物体在没有水下光线衰减时的“真实”颜色, e − β c ( z ) ⋅ z e^{-\beta_c(z) \cdot z} e−βc(z)⋅z 是光线在水中传播距离 z z z 后的衰减系数。这个公式告诉我们,水下图像的退化主要来自后向散射 B c B_c Bc 的干扰和光线吸收导致的颜色衰减。因此,想要恢复出清晰的图像特征,就需要从原始特征中减去散射影响,并补偿吸收损失。
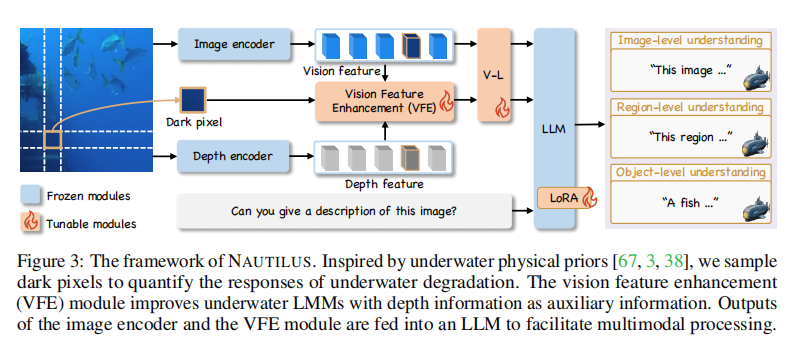
NAUTILUS模型架构
如上图所示,NAUTILUS模型主要由图像编码器、深度编码器、视觉特征增强 (Vision Feature Enhancement, VFE) 模块、视觉到语言投影器和大语言模型 (large language model, LLM) 组成。
当输入一张水下图片 x x x 时,模型首先通过两个编码器分别提取视觉特征 v v v 和深度特征 d d d。深度特征 d d d 描述了场景中物体与摄像机的距离,这对于估计光线吸收程度至关重要。
然后,模型将视觉特征 v v v、深度特征 d d d 以及一个特殊信息——暗像素先验 (dark pixel prior) 的位置索引 k k k 一同送入核心的VFE模块。这个“暗像素先验”基于一个观察:在水下,最暗的区域也常常因为散射而呈现蓝绿色,因此这些像素的颜色值可以近似代表后向散射光的强度。VFE模块利用这些输入,生成一个“增强后”的视觉特征 v e v_e ve。
最后,原始特征 v v v 和增强特征 v e v_e ve 会通过一个共享的投影器转换到与语言相同的空间,然后与用户指令一起输入到LLM中,生成最终的回答。模型同时使用原始和增强特征,是因为前者保留了真实的水下环境信息,而后者则提供了更清晰的物体细节,二者互为补充。
视觉特征增强(VFE)模块详解
VFE模块是本文的创新核心,它分两步来“净化”视觉特征:
-
去除后向散射:
首先,模块根据“暗像素先验”找到特征图 v v v 中代表最暗区域的那个特征向量(称为“dark token”)。理论上,直接减去这个向量可以去除散射影响。但作者考虑到这个向量也混合了全局语义信息,因此设计了一个交叉注意力层来提纯,得到一个更纯净的后向散射响应 s s s。然后,从整个视觉特征中减去这个响应: v − s v - s v−s。 -
恢复光线吸收:
根据物理模型,光线吸收与距离有关。因此,模块利用输入的深度特征 d d d,通过一个小型多层感知机(MLP)来学习一个吸收权重 W W W。距离越远,权重值越大。最后,通过一个符合物理公式的除法操作来恢复被吸收的信息,得到最终的增强特征 v e v_e ve:
v e = ( v − s ) ⊘ exp ( − W ) v_e = (v - s) \oslash \exp(-W) ve=(v−s)⊘exp(−W)
其中 ⊘ \oslash ⊘ 表示逐元素相除。这个公式巧妙地将物理原理融入了神经网络结构中,指导模型进行可解释的特征增强。
五、实验设计与结果分析
论文的实验旨在验证NAUTILUS在多任务水下理解能力以及VFE模块的有效性。
- 数据集:主要使用新构建的 NautData 进行训练和测试。同时在公开的 MarineInst20M 和 IOCfish5k 数据集上进行泛化能力和计数能力的测试。
- 评测指标:针对不同任务使用不同指标,如分类任务使用准确率(acc),目标检测 (object detection) 使用mAP,图像描述使用METEOR,计数任务使用平均绝对误差(MAE)等。
- 训练策略:采用参数高效微调 (parameter-efficient fine-tuning, PEFT) 策略,只训练模型的一小部分参数,以节省计算资源。
对比实验
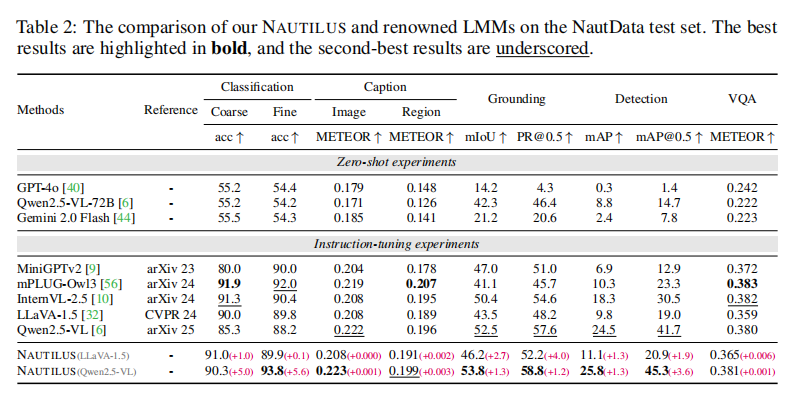
在NautData测试集上,论文将NAUTILUS与多个知名的通用LMM(如GPT-4o、Qwen2.5-VL)以及经过同样数据微调的基础模型(如LLaVA-1.5)进行了比较。
如论文表2所示,无论是基于LLaVA-1.5还是Qwen2.5-VL,NAUTILUS在八个任务中的绝大多数都取得了性能提升。例如,在基于Qwen2.5-VL时,NAUTILUS在细粒度分类、图像描述、定位和检测任务上均达到了最佳性能。这证明了VFE模块的有效性,它通过显式处理图像退化,切实地帮助模型更好地理解水下场景。
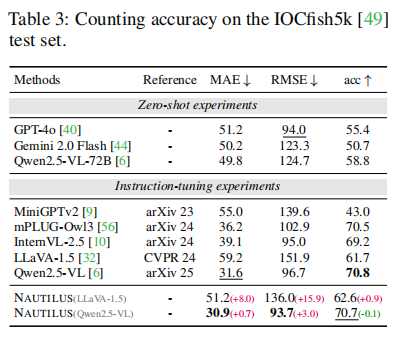
在水下鱼群计数任务(IOCfish5k数据集)上,如论文表3所示,NAUTILUS(基于Qwen2.5-VL)的MAE达到了30.9,优于所有对比模型,显示了其在群体感知方面的卓越能力。
消融实验
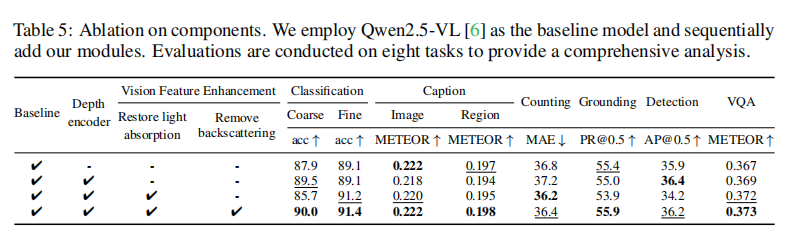
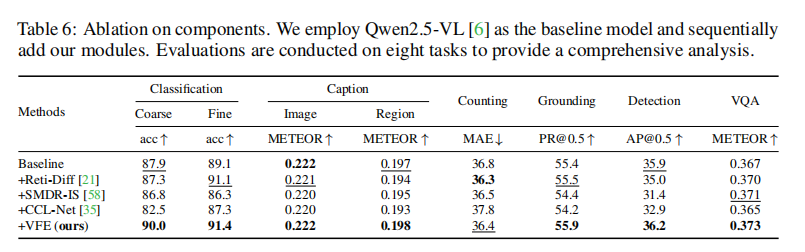
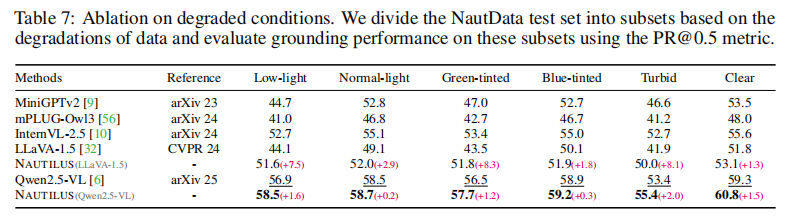
为了验证VFE模块设计的合理性,论文进行了一系列消融研究。
-
VFE模块组件分析:如论文表5所示,实验逐一验证了VFE中“去除后向散射”和“恢复光线吸收”两个步骤的贡献。结果表明,每个组件都对最终性能有积极作用,共同作用时效果最好,证明了基于物理模型的设计是科学且有效的。
-
特征增强 vs. 图像增强:论文还对比了“在特征层面增强”与“直接在输入图像上进行增强”两种策略。如论文表6所示,先用先进的图像增强算法处理图片再输入模型,反而导致了在分类、描述等多个任务上的性能下降。作者认为这是因为图像增强过程可能丢失了原始图像的有用信息。相比之下,NAUTILUS的特征空间增强方法既保留了原始信息,又进行了有效修复,因此更加可靠。
-
恶劣条件下的鲁棒性:如论文表7所示,研究人员将测试集按低光、浑浊、偏绿、偏蓝等不同退化条件进行划分,测试模型的鲁棒性。结果显示,NAUTILUS在所有恶劣条件下的性能提升都非常显著。例如,在低光和浑浊场景下,NAUTILUS (LLaVA-1.5) 的性能提升分别高达7.5和8.1 PR@0.5,充分证明了其在复杂多变的水下环境中的强大适应能力。
六、论文结论与评价
总结
这篇论文的核心结论是,通过将水下成像的物理原理融入到大型多模态模型的设计中,可以显著提升模型对水下场景的理解能力。作者为此构建了一个全新的大规模数据集NautData,并提出了一个即插即用的视觉特征增强(VFE)模块。实验证明,集成了VFE模块的NAUTILUS模型在八项水下任务上表现出色,尤其在处理图像退化问题上展示了强大的鲁棒性。
评价
-
研究影响:这项研究为解决水下视觉任务提供了一个非常新颖且有效的思路。它不仅贡献了一个宝贵的数据集和强大的基线模型,更重要的是,它展示了将领域物理知识与深度学习模型相结合的巨大潜力。这种“物理驱动”的AI设计思想,对于其他受环境因素严重影响的领域(如雾天驾驶、遥感图像分析)也具有重要的借鉴意义。
-
优缺点分析:该方法最大的优点是其创新性和有效性。VFE模块设计巧妙,且有物理理论支撑,不是一个简单的“黑盒”堆叠。它即插即用,可以方便地集成到其他模型中。主要缺点或局限性在于,模型的认知范围仍受限于NautData数据集中的物种和场景。正如论文自己所承认的,它在处理数据集中从未见过的全新物种(即开放词汇能力)方面还有待探索。
-
批判性讨论:虽然模型表现优异,但它依赖于一个独立的深度估计模型来获取深度信息。如果深度估计不准,可能会影响光线吸收的恢复效果。未来的研究可以探索如何在模型内部端到端地联合学习视觉特征、深度信息和修复过程,从而减少对外部模型的依赖。此外,对于水下生物多样性的挑战,未来可以尝试将零样本学习(zero-shot learning)或小样本学习(few-shot learning)能力融入模型,使其在面对未知物种时也能做出合理的识别和描述,这对于真正的海洋探索应用至关重要。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)