
多模态教科书级指南,堪比“原子弹使用说明书”。一篇顶一年自学,Pytorch从0到1,源码级搭建CLIP-VIT相似图像检索系统,原理教学与代码逐行解析
这个项目是一个基于CLIP 和 ViT 的相似图像检索系统,使用PyTorch从零开始实现。该项目适合用于学习目的,帮助理解图像特征提取和相似度检索的基本原理。我相信大家只要认真看完,绝对大有裨益,不仅可以加深大家的代码能力,更能从原理上让大家理解透彻CLIP这个里程碑级别的多模态模型。
这个项目是一个基于CLIP 和 ViT 的相似图像检索系统,使用PyTorch从零开始实现。该项目适合用于学习目的,帮助理解图像特征提取和相似度检索的基本原理。我相信大家只要认真看完,绝对大有裨益,不仅可以加深大家的代码能力,更能从原理上让大家理解透彻CLIP这个里程碑级别的多模态模型。
学习建议:对照架构讲解学习代码,每次看完我的代码解析后,自己再用自己的话复述一遍代码,复述内容包括,有什么用?为什么要用?如何使用?
项目总览
项目结构
CLIPVIT/
│
├── models/ # 模型定义文件夹
│ ├── vit.py # Vision Transformer 实现
│ └── clip.py # CLIP 模型实现
│
├── utils/ # 工具函数
│ ├── data_utils.py # 数据加载和预处理
│ ├── image_utils.py # 图像处理函数
│ └── index_utils.py # 索引和检索工具
│
├── data/ # 数据存储目录(需要自行创建)
│ └── images/ # 存放图片的目录
│
├── index/ # 特征索引存储目录
│
├── scripts/ # 脚本文件
│ ├── extract_features.py # 提取图像特征
│ ├── build_index.py # 构建检索索引
│ └── search.py # 图像检索脚本
│
├── main.py # 主程序入口
├── requirements.txt # 依赖包列表实现细节
-本项目使用Vision Transformer (ViT) 作为特征提取器
-采用CLIP模型的对比学习方法进行图像特征学习
-使用余弦相似度进行图像相似度计算
-支持基于Faiss的高效索引和检索
学习与扩展建议
1. 模型修改:尝试修改ViT模型的结构参数,如层数、注意力头数等
2. 数据增强:在`data_utils.py`中添加更多数据增强方法
3. 特征融合:结合不同层的特征以获得更好的表示
4. 混合索引:实现基于聚类的分层索引,提高大规模检索效率
5. 添加界面:为系统添加一个简单的Web界面或GUI界面
好的,那我们现在开始吧。
模型架构讲解与代码解析
VIT模型架构讲解
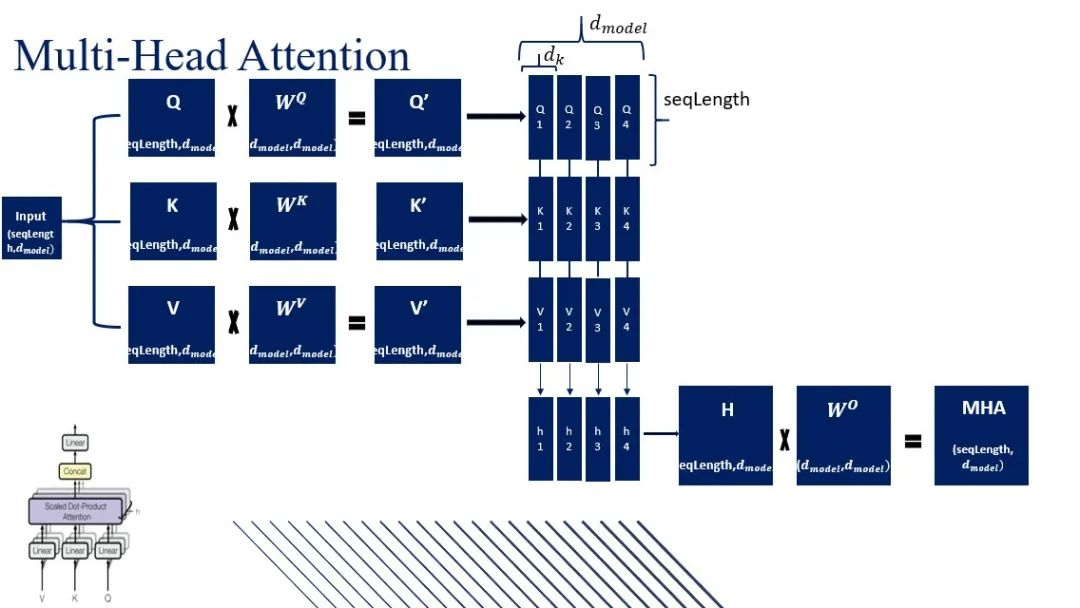
这里首先大概复习一下多头注意力机制:
第1步:生成Q, K, V
将LN后的输出通过三个不同的线性层(矩阵乘法),分别投影到查询(Query)、键(Key)、值(Value) 三个空间。
如果只有一个注意力头,那么Q、K、V的维度都与输入一致,均为 197×768。
第2步:分割成多个头
原文中以12个头为例。768维的嵌入维度被平均分成12份,每一份为 768 / 12 = 64 维。
这个过程相当于将一个大向量“拆解”成12个小向量。因此:
原始的Q、K、V (197×768) 被转换为 12组 更小的Q、K、V。
每一组的维度都是 197×64(768/12)。
第3步:计算自注意力并拼接
这12组Q、K、V会并行地分别计算自注意力。每个头的计算过程是独立的。
每个头计算后都会产生一个197×64的输出序列。
然后将12个输出在特征维度上拼接(Concat) 起来,12个197×64的矩阵拼接后正好恢复为 197×768 的维度。
然后乘以一个W_O矩阵,这也叫输出投影层 。它是一个可学习的线性变换(一个全连接层),其权重矩阵为W_O。
它的首要任务是确保输出维度 (d_model)与输入维度一致。虽然拼接后已经是768维,但投影层提供了进一步变换的可能。
W_o权重矩阵可以学习到如何加权组合来自不同注意力头的信息。 作为一个可学习的参数矩阵,它增加了模型的表达能力。
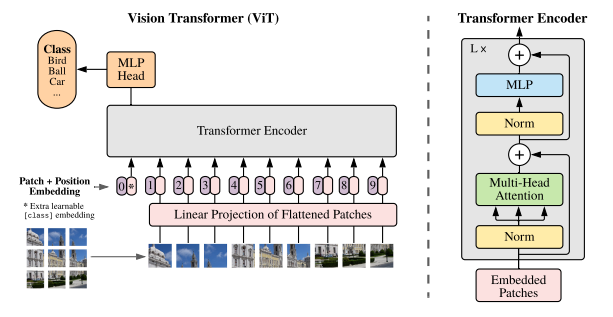
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。
按照上面的流程图,一个ViT block可以分为以下几个步骤
1.通过 patch embedding 将图像转换为序列数据:将一张 224×224 的图像分割成 16×16 的图块,共得到 196 个图块。每个图块转换为 768(16x16x3) 维向量,经线性投射后仍保持 196×768 的维度。在此基础上添加一个 [CLS] 标记,最终形成 197×768 的序列。至此,图像处理问题被转化为序列到序列的问题。
2.ViT 使用可学习的一维位置编码,其形式为一个行数等于序列长度(197)、维度与嵌入维度(768)相同的位置向量表。位置信息通过相加(sum)而非拼接(concat)的方式注入,因此加入位置编码后序列维度仍保持为 197×768。
3.Transformer Encoder:上一个模块(包含197个token,每个token的向量维度是768)先进行LN归一化,然后进入多头自注意力机制,其目的是让每个token(图像块)与所有其他token(包括自己)进行交互,从而捕捉图像的整体上下文信息。然后在过一层LN,维度依然是197x768
4.MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768
5.最后的分类头:它是ViT模型的最终决策层,负责将学习到的抽象特征转化为具体任务输出。接收并处理代表全局图像信息的特殊标记([CLS] token)的特征向量。通过全连接层等结构将该特征映射到目标空间(如分类概率),完成预测。
VIT模块代码解析
- 主要组件:
- PatchEmbedding:将图像分割成小块并进行嵌入
- Attention:实现多头自注意力机制
- MLP:实现前馈神经网络
- Block:组合注意力机制和MLP的Transformer基本单元
- VisionTransformer:完整的Vision Transformer模型,用于图像特征提取
我们首先定义VIT模型:
1.导入库
import torch # 导入PyTorch库,用于深度学习相关操作
import torch.nn as nn # 导入PyTorch的神经网络模块,用于构建模型
import torch.nn.functional as F # 导入PyTorch的函数式接口
import math # 导入数学库,用于数学计算2.PatchEmbedding类
class PatchEmbedding(nn.Module):
"""将图像分割成patch并进行线性嵌入"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
# 使用卷积层将patch映射到嵌入维度
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
"""
x: [batch_size, 3, img_size, img_size]
输出: [batch_size, n_patches, embed_dim]
"""
batch_size, _, _, _ = x.shape
x = self.proj(x) # [batch_size, embed_dim, img_size//patch_size, img_size//patch_size]
x = x.flatten(2) # [batch_size, embed_dim, n_patches]
x = x.transpose(1, 2) # [batch_size, n_patches, embed_dim]
return x讲解:
class PatchEmbedding(nn.Module):
"""将图像分割成patch并进行线性嵌入"""- 定义PatchEmbedding类,继承自nn.Module,用于将输入图像分割成若干个patch并进行嵌入
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2初始化函数,接受参数:
- img_size: 输入图像大小,默认224像素
- patch_size: 每个patch的大小,默认16像素
- in_channels: 输入图像通道数,默认3(RGB)
- embed_dim: 嵌入维度,默认768
- self.n_patches = (img_size // patch_size) ** 2:计算patch数量(图像被分成的网格数)
- 例如:224//16=14,14²=196个patch
# 使用卷积层将patch映射到嵌入维度
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)- 创建一个卷积层作为投影层(proj)
- 这个卷积层的作用是将每个patch映射到embed_dim维度的嵌入向量
设计:
- kernel_size=patch_size:卷积核大小等于patch大小
- stride=patch_size:步长等于patch大小,确保不重叠
- 这样一次卷积操作就能同时完成分割和线性投影
def forward(self, x):
"""
x: [batch_size, 3, img_size, img_size]
输出: [batch_size, n_patches, embed_dim]
"""
batch_size, _, _, _ = x.shape- forward方法定义前向传播过程
- 输入x的形状为[batch_size, 3, img_size, img_size],即批量RGB图像
- 获取批量大小batch_size
x = self.proj(x) # [batch_size, embed_dim, img_size//patch_size, img_size//patch_size]- 应用投影卷积层,将图像转换为patch特征图
- 输出形状:[batch_size, embed_dim, img_size//patch_size, img_size//patch_size]
- 例如:对于224×224图像和16×16的patch,输出形状为[batch_size, embed_dim, 14, 14]
x = x.flatten(2) # [batch_size, embed_dim, n_patches]- 使用flatten(2)将最后两个维度(高度和宽度)展平为一个维度
- 这将网格形式的patch转换为序列
- 输出形状:[batch_size, embed_dim, n_patches]
x = x.transpose(1, 2) # [batch_size, n_patches, embed_dim]
return x- 转置维度1和2,使patch序列成为序列的第一维
- 输出最终形状:[batch_size, n_patches, embed_dim]
- 这种形状符合Transformer处理序列数据的要求
3.Attention类
class Attention(nn.Module):
"""多头自注意力机制"""
def __init__(self, dim, n_heads=12, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.n_heads = n_heads
self.head_dim = dim // n_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
"""
x: [batch_size, n_tokens, dim]
"""
batch_size, n_tokens, dim = x.shape
# 线性投影并分割成q, k, v
qkv = self.qkv(x).reshape(batch_size, n_tokens, 3, self.n_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch_size, n_heads, n_tokens, head_dim]
q, k, v = qkv[0], qkv[1], qkv[2]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * self.scale # [batch_size, n_heads, n_tokens, n_tokens]
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# 聚合value并输出
x = (attn @ v).transpose(1, 2).reshape(batch_size, n_tokens, dim)
x = self.proj(x)
x = self.proj_drop(x)
return x讲解:
计算公式:
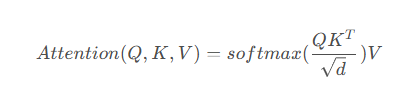
class Attention(nn.Module):
"""多头自注意力机制"""- 定义Attention类,实现多头自注意力机制
def __init__(self, dim, n_heads=12, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.n_heads = n_heads
self.head_dim = dim // n_heads
self.scale = self.head_dim ** -0.5初始化函数参数:
- dim: 输入特征维度
- n_heads: 注意力头的数量,默认12
- qkv_bias: 是否在q,k,v投影中使用偏置,默认True
- attn_drop: 注意力dropout率,默认0
- proj_drop: 输出投影dropout率,默认0
- self.head_dim = dim // n_heads:每个注意力头的维度
- self.scale = self.head_dim ** -0.5:缩放因子,防止点积注意力值过大
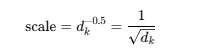
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)- 创建线性层,将输入映射为查询(q)、键(k)和值(v)
- 输出维度是输入的3倍,因为同时生成q、k、v三个向量
- bias=qkv_bias:是否使用偏置
self.attn_drop = nn.Dropout(attn_drop)- 创建注意力权重的dropout层,防止过拟合
self.proj = nn.Linear(dim, dim)- 创建输出投影层,将多头注意力的结果合并回原始维度
self.proj_drop = nn.Dropout(proj_drop)- 创建输出投影的dropout层
def forward(self, x):
"""
x: [batch_size, n_tokens, dim]
"""
batch_size, n_tokens, dim = x.shape- forward方法,输入x的形状为[batch_size, n_patches, embed_dim](n_patches= n_tokens)
- 获取批量大小、token数量和维度
# 线性投影并分割成q, k, v
qkv = self.qkv(x).reshape(batch_size, n_tokens, 3, self.n_heads, self.head_dim)- 应用qkv线性层,并重新整形
embed_dim:输入嵌入的维度(如768)n_heads:注意力头的数量(如12),head_dim:每个注意力头的维度(如64)
- 将输出重新整形为[batch_size, n_tokens, 3, n_heads, head_dim]
- 3表示q、k、v三个向量
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch_size, n_heads, n_tokens, head_dim]- 调整维度顺序为[3, batch_size, n_heads, n_tokens, head_dim]
- 这样可以方便地分离q、k、v
q, k, v = qkv[0], qkv[1], qkv[2]- 分离q、k、v三个向量
- 每个形状为[batch_size, n_heads, n_tokens, head_dim]
# 计算注意力分数
attn = (q @ k.transpose(-2, -1)) * self.scale # [batch_size, n_heads, n_tokens, n_tokens]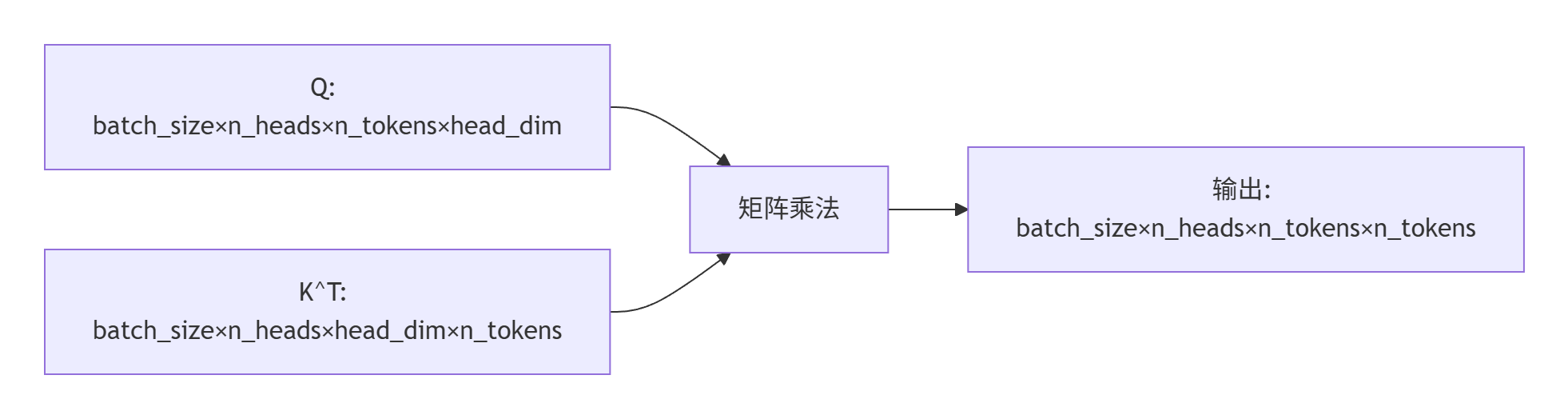
- 计算q和k的点积注意力分数
- k.transpose(-2, -1)将k的最后两个维度转置,便于矩阵乘法
- * self.scale应用缩放因子,防止梯度消失
- 输出形状:[batch_size, n_heads, n_tokens, n_tokens]
attn = attn.softmax(dim=-1)- 对注意力分数应用softmax,转换为概率分布
- dim=-1表示在最后一个维度上应用softmax(对每个token的注意力权重归一化)
attn = self.attn_drop(attn)- 应用注意力dropout
# 聚合value并输出
x = (attn @ v).transpose(1, 2).reshape(batch_size, n_tokens, dim)- 将注意力权重与value矩阵相乘,得到加权值
- .transpose(1, 2)调整维度顺序
- .reshape(batch_size, n_tokens, dim)重新整形,合并所有注意力头
x = self.proj(x)
x = self.proj_drop(x)
return x- 应用输出投影层
- 应用输出dropout
4.MLP类
class MLP(nn.Module):
"""前馈神经网络"""
def __init__(self, in_features, hidden_features, out_features, drop=0.):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x讲解
def __init__(self, in_features, hidden_features, out_features, drop=0.):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)- 初始化函数参数:
- in_features: 输入特征维度
- hidden_features: 隐藏层特征维度
- out_features: 输出特征维度
- drop: dropout率,默认0
- 创建两个线性层,一个激活函数层和一个dropout层
- nn.GELU():使用GELU激活函数(Gaussian Error Linear Unit)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x- 前向传播过程:
- 应用第一个线性层
- 应用GELU激活函数
- 应用dropout
- 应用第二个线性层
- 再次应用dropout
- 返回结果
5.定义Block类,表示Transformer中的编码器块
class Block(nn.Module):
"""Transformer编码器块"""
def __init__(self, dim, n_heads, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.):
super().__init__()
self.norm1 = nn.LayerNorm(dim, eps=1e-6)
self.attn = Attention(
dim=dim,
n_heads=n_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop
)
self.norm2 = nn.LayerNorm(dim, eps=1e-6)
self.mlp = MLP(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
drop=drop
)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x数据将流经 N 个堆叠的 Transformer Encoder 层。每个 Encoder 层都包含一个多头自注意力和个 MLP。
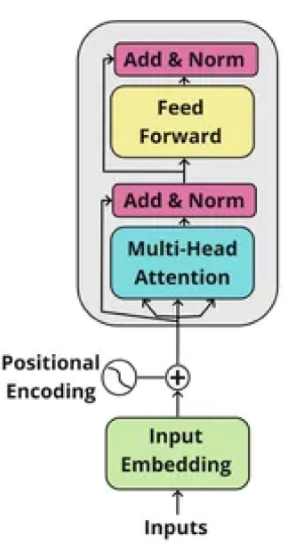
讲解
def __init__(self, dim, n_heads, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.):
super().__init__()
self.norm1 = nn.LayerNorm(dim, eps=1e-6)- 初始化函数参数:
- dim: 输入特征维度
- n_heads: 注意力头数量
- mlp_ratio: MLP隐藏层维度相对于输入维度的比例,默认4
- qkv_bias: 是否在q,k,v投影中使用偏置,默认True
- drop: dropout率,默认0
- attn_drop: 注意力dropout率,默认0
- 创建第一个层归一化层nn.LayerNorm,用于注意力子层
self.attn = Attention(
dim=dim,
n_heads=n_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop
)- 创建注意力层,传递相关参数
self.norm2 = nn.LayerNorm(dim, eps=1e-6)- 创建第二个层归一化层,用于MLP子层
self.mlp = MLP(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
drop=drop
)- 创建MLP层,传递相关参数
- hidden_features=int(dim * mlp_ratio):隐藏层维度为输入维度的mlp_ratio倍
def forward(self, x):
x = x + self.attn(self.norm1(x))- 前向传播过程第一部分:
- 先对输入应用层归一化
- 将归一化后的输入送入注意力层
- 将注意力层的输出注意力分数与原始输入相加(残差连接)
x = x + self.mlp(self.norm2(x))- 前向传播过程第二部分:
- 对第一阶段的输出应用层归一化
- 将归一化后的结果送入MLP层
- 将MLP层的输出与上一步的输出相加(残差连接)
6.VisionTransformer类
class VisionTransformer(nn.Module):
"""Vision Transformer模型"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
depth=12,
n_heads=12,
mlp_ratio=4.0,
qkv_bias=True,
drop_rate=0.,
attn_drop_rate=0.,
embed_layer=PatchEmbedding,
norm_layer=nn.LayerNorm,
output_dim=512
):
super().__init__()
self.embed_dim = embed_dim
# Patch嵌入
self.patch_embed = embed_layer(
img_size=img_size,
patch_size=patch_size,
in_channels=in_channels,
embed_dim=embed_dim
)
num_patches = self.patch_embed.n_patches
# 位置嵌入
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
# Transformer编码器
self.blocks = nn.Sequential(*[
Block(
dim=embed_dim,
n_heads=n_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate
)
for _ in range(depth)
])
self.norm = norm_layer(embed_dim, eps=1e-6)
# 特征映射层
self.head = nn.Linear(embed_dim, output_dim)
# 初始化
self._init_weights()
def _init_weights(self):
# 初始化位置嵌入
pos_embed = self._get_sincos_pos_embed(self.pos_embed.shape[-1], int(self.patch_embed.n_patches**.5))
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
# 初始化cls token
nn.init.normal_(self.cls_token, std=0.02)
# 初始化其他权重
self.apply(self._init_weights_layer)
def _init_weights_layer(self, m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def _get_sincos_pos_embed(self, embed_dim, grid_size):
"""生成正弦余弦位置嵌入"""
grid_h = torch.arange(grid_size, dtype=torch.float32)
grid_w = torch.arange(grid_size, dtype=torch.float32)
grid = torch.meshgrid(grid_h, grid_w, indexing='ij')
grid = torch.stack(grid, dim=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
pos_embed = self._get_2d_sincos_pos_embed(embed_dim, grid)
return pos_embed
def _get_2d_sincos_pos_embed(self, embed_dim, grid):
"""2D正弦余弦位置嵌入"""
assert embed_dim % 2 == 0
# 使用numpy进行计算
import numpy as np
# 使用正弦和余弦函数
omega = np.arange(embed_dim // 4) / (embed_dim // 4 - 1)
omega = 1. / (10000 ** omega)
out_h = grid[0].flatten()
out_w = grid[1].flatten()
pos_embed = np.zeros((out_h.shape[0], embed_dim), dtype=np.float32)
x_pos = out_h.reshape(-1, 1) * omega.reshape(1, -1)
y_pos = out_w.reshape(-1, 1) * omega.reshape(1, -1)
pos_embed[:, 0::4] = np.sin(x_pos)
pos_embed[:, 1::4] = np.cos(x_pos)
pos_embed[:, 2::4] = np.sin(y_pos)
pos_embed[:, 3::4] = np.cos(y_pos)
# 添加一个特殊的位置嵌入给cls token
cls_pos_embed = np.zeros(embed_dim, dtype=np.float32)
pos_embed = np.concatenate([cls_pos_embed[None], pos_embed], axis=0)
return pos_embed
def forward_features(self, x):
"""提取特征"""
# Patch嵌入
x = self.patch_embed(x) # [B, n_patches, embed_dim]
# 添加cls token
cls_token = self.cls_token.expand(x.shape[0], -1, -1) # [B, 1, embed_dim]
x = torch.cat((cls_token, x), dim=1) # [B, 1+n_patches, embed_dim]
# 添加位置嵌入
x = x + self.pos_embed
x = self.pos_drop(x)
# 通过Transformer块
x = self.blocks(x)
x = self.norm(x)
# 使用cls token作为特征表示
x = x[:, 0]
return x
def forward(self, x):
"""前向传播"""
# 提取特征
x = self.forward_features(x)
# 映射到输出维度
x = self.head(x)
# 归一化特征以便于相似度计算
x = F.normalize(x, p=2, dim=-1)
return x数据形状变化一览表
| 步骤 | 操作 | 数据形状 |
| 1. 输入 | 原始图片批次 | [4, 3, 224, 224] |
| 2. Patch 嵌入 | 卷积 + Reshape | [4, 196, 768] |
| 3. 添加 [CLS] | 拼接 (Concatenate) | [4, 197, 768] |
| 4. 添加位置编码 | 元素相加 (Element-wise Add) | [4, 197, 768] |
| 5. Transformer Encoder | N 次自注意力与 MLP | [4, 197, 768] |
| 6. 分类 | 提取 [CLS] Token + MLP |
[4, 分类数量] |
讲解
class VisionTransformer(nn.Module):
"""Vision Transformer模型"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
depth=12,
n_heads=12,
mlp_ratio=4.0,
qkv_bias=True,
drop_rate=0.,
attn_drop_rate=0.,
embed_layer=PatchEmbedding,
norm_layer=nn.LayerNorm,
output_dim=512
):- 初始化函数参数:
- img_size: 输入图像大小,默认224
- patch_size: patch大小,默认16
- in_channels: 输入通道数,默认3(RGB)
- embed_dim: 嵌入维度,默认768
- depth: Transformer编码器层数,默认12
- n_heads: 注意力头数量,默认12
- mlp_ratio: MLP隐藏层维度与嵌入维度的比例,默认4.0
- qkv_bias: 是否在qkv投影中使用偏置,默认True
- drop_rate: dropout率,默认0
- attn_drop_rate: 注意力dropout率,默认0
- embed_layer: 嵌入层类,默认PatchEmbedding
- norm_layer: 归一化层类,默认nn.LayerNorm
- output_dim: 输出特征维度,默认512
super().__init__()
self.embed_dim = embed_dim- 调用父类初始化方法,保存嵌入维度
# Patch嵌入
self.patch_embed = embed_layer(
img_size=img_size,
patch_size=patch_size,
in_channels=in_channels,
embed_dim=embed_dim
)
num_patches = self.patch_embed.n_patches- 创建patch嵌入层,传递相关参数
- 获取patch数量
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))- 创建分类token参数,形状为[1, 1, embed_dim]
- 使用nn.Parameter将其定义为可学习参数
- 这个token会添加到所有patch序列的开头,用于图像分类任务
注:创建一个可学习的向量,我们称之为 [CLS] Token。它的维度也是 D=768。然后把它拼接到每个序列的最前面。
-
[CLS]Token 的形状是[1, 1, 768]。 -
将它扩展到
[4, 1, 768]并与上一步的[4, 196, 768]在序列长度的维度上拼接。
在每个 Encoder 层中,序列中的 197 个向量会相互“关注”,交换和更新信息。[CLS] Token 也会参与其中,不断地从 196 个 Patch 向量中聚合信息。我们只对 [CLS] Token 的最终状态感兴趣。
从 Encoder 的输出 [4, 197, 768] 中,只提取出第一个 Token (即 [CLS] Token) 对应的向量。
从 [4, 197, 768] 中取出索引为 0 的部分,得到形状为 [4, 768] 的张量。通过 MLP 分类器 (假设是一个 nn.Linear(768, 1000)):将 [4, 768] 的张量送入线性层。最终输出形状:[4, 1000]
4: Batch Size
1000: 每个样本在 1000 个类别上的得分 (Logits)。之后可以接一个 Softmax 函数得到概率。
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)这个是位置编码,之所以加1是因为之前我们的clstoken在patch维度上加了1.变成了197
然后我们再添加了个Dropout层优化一下。
# Transformer编码器
self.blocks = nn.Sequential(*[
Block(
dim=embed_dim,
n_heads=n_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate
)
for _ in range(depth)
])- 创建Transformer编码器块序列
- 使用列表推导式创建depth个Block实例
- nn.Sequential(*[...]):将列表中的Block实例转换为顺序模块
self.norm = norm_layer(embed_dim, eps=1e-6)创建最终的归一化
# 特征映射层
self.head = nn.Linear(embed_dim, output_dim)-
目的: 将模型提取到的高级特征映射到最终的输出维度。
-
工作原理: 这是一个简单的全连接层 (Linear Layer)。它会接收
cls_token经过所有Block和norm后的最终状态向量(形状为[B, 768]),然后将其映射到output_dim(例如 512) 维。这个output_dim维的向量就是整个 ViT 模型对输入图片的最终特征表示。
self._init_weights()这是一个约定俗成的做法,调用一个(代码中未展示的)辅助方法来对模型的权重进行特定的初始化。良好的权重初始化可以帮助模型更快更好地收敛。
def _init_weights(self):
# 初始化位置嵌入
pos_embed = self._get_sincos_pos_embed(self.pos_embed.shape[-1], int(self.patch_embed.n_patches**.5))
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))_init_weights 函数的目的就是为模型的不同部分选择合适且有效的初始值,为后续的训练过程打下一个良好的基础。它就像是在赛跑前,帮助运动员调整到最佳的起跑姿势。
目的: 为位置嵌入参数 self.pos_embed 赋予初始值。
工作原理:
1._get_sincos_pos_embed(...): 这一行调用了一个辅助函数,从函数名可以看出,它使用的是 Sine-Cosine 位置编码方法。这是一种固定(非学习)的位置编码技术,源自经典的 Transformer 论文 "Attention Is All You Need"。它利用不同频率的正弦和余弦函数来为每个位置生成一个独特的、高维的向量。
-
self.pos_embed.shape[-1]:获取位置嵌入向量的维度,也就是embed_dim(例如 768)。 -
int(self.patch_embed.n_patches**.5):计算每行(或每列)有多少个 patch。例如,对于 196 个 patches,开方后得到 14,意味着图片被切分成了 14×14 的网格。
2.self.pos_embed.data.copy_(...): 这一行将上一步生成的 NumPy 数组 pos_embed 转换为 PyTorch 张量,并将其值复制到模型的位置嵌入参数 self.pos_embed 中。
-
.data访问参数底层的张量数据。 -
.copy_()是一个 PyTorch 的 in-place (原地) 操作,它直接修改self.pos_embed的值,而不会改变其作为模型参数的身份。
# 初始化cls token
nn.init.normal_(self.cls_token, std=0.02)目的: 为 self.cls_token 这个特殊的、用于最终分类的令牌赋初始值。
工作原理:
-
nn.init.normal_: 这是 PyTorch 的一个初始化函数,它会用从正态分布(高斯分布)中采样的值来填充输入的张量。 -
self.cls_token: 要被初始化的分类令牌。 -
std=0.02: 指定正态分布的标准差为 0.02。均值默认为 0。
-
cls_token在开始时应该是一个“中性”的、不带偏见的向量,因为它需要从所有 patch token 中学习和聚合信息。 -
从一个均值为 0、方差很小的分布中采样,可以确保其初始值接近于 0,但又不完全相同。这是一种安全、稳定且被广泛采用的初始化策略,可以避免初始值过大导致训练初期梯度爆炸。这个
0.02的标准差值也是很多 Transformer 模型(如 BERT)中常用的经验值。
# 初始化其他权重
self.apply(self._init_weights_layer)-
目的: 为模型中所有其他的层(例如,
Block中的线性层、LayerNorm 层等)进行初始化。 -
工作原理:
-
self.apply(fn): 这是nn.Module提供的一个非常有用的方法。它会递归地将函数fn应用到模型自身的每一个子模块 (submodule) 上。 -
它会从
VisionTransformer这个顶层模块开始,遍历self.patch_embed,self.blocks中的每一个Block,以及Block里的nn.Linear,nn.LayerNorm等所有子模块。 -
每遍历到一个模块,就会调用一次
_init_weights_layer(module)这个函数
def _init_weights_layer(self, m):
if isinstance(m, nn.Linear):
# 对线性层使用截断正态分布初始化
nn.init.trunc_normal_(m.weight, std=.02)
if m.bias is not None:
# 对偏置项初始化为0
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
# 对LayerNorm的偏置初始化为0
nn.init.constant_(m.bias, 0)
# 对LayerNorm的权重初始化为1
nn.init.constant_(m.weight, 1.0)-
对线性层 (nn.Linear): 通常使用 Xavier 初始化或 Kaiming 初始化,或者像这里一样使用截断正态分布。这有助于在网络的前向和反向传播中维持信号的方差,防止梯度消失或爆炸。
-
对层归一化 (nn.LayerNorm): 通常将其权重
weight初始化为 1,偏置bias初始化为 0。这样,在训练刚开始时,LayerNorm 层近似于一个恒等变换,不会改变输入的数据分布,让网络有一个更稳定的起点。
以下代码的最终目标是:为图像的每一个 patch(小方块)根据其在二维网格中的 (高, 宽) 坐标,生成一个独特的、固定不变的位置编码向量。
def _get_sincos_pos_embed(self, embed_dim, grid_size):
"""生成正弦余弦位置嵌入"""
# 1. 创建一维坐标轴
grid_h = torch.arange(grid_size, dtype=torch.float32)
grid_w = torch.arange(grid_size, dtype=torch.float32)
# 2. 从坐标轴创建二维网格
grid = torch.meshgrid(grid_h, grid_w, indexing='ij')
grid = torch.stack(grid, dim=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
# 3. 调用核心函数进行计算
pos_embed = self._get_2d_sincos_pos_embed(embed_dim, grid)
return pos_embed-
grid_h = torch.arange(grid_size, ...): 生成一个从 0 到grid_size - 1的一维张量,代表网格的高度(Y 轴)坐标。如果grid_size是 14,grid_h就是[0., 1., 2., ..., 13.]。 -
grid_w = torch.arange(grid_size, ...): 同理,生成宽度(X 轴)的坐标。
grid = torch.meshgrid(grid_h, grid_w, indexing='ij'): 这是最关键的一步。meshgrid 函数接收两个一维坐标轴,生成一个二维坐标网格。
indexing='ij' 意味着它生成的第一个张量代表每一行的 h (高度) 坐标,第二个张量代表每一列的 w (宽度) 坐标。
执行后,grid 是一个包含两个张量的元组,每个张量的形状都是 [grid_size, grid_size]。我们可以称它们为 grid[0] 和 grid[1]。grid[0] 存储了每个点的 h 坐标,grid[1] 存储了每个点的 w 坐标。grid = torch.stack(grid, dim=0): 将这两个 [14, 14] 的坐标网格堆叠起来,形成一个形状为 [2, 14, 14] 的张量。现在,grid[0] 是完整的 h 坐标网格,grid[1] 是完整的 w 坐标网格。
pos_embed = self._get_2d_sincos_pos_embed(...): 将准备好的坐标网格 grid 和目标嵌入维度 embed_dim 传递给下一个函数,让它去完成真正的数学计算。
def _get_2d_sincos_pos_embed(self, embed_dim, grid):
"""2D正弦余弦位置嵌入"""
assert embed_dim % 2 == 0
# ... 省略 import ...
# 1. 计算频率 omega
omega = np.arange(embed_dim // 4) / (embed_dim // 4 - 1)
omega = 1. / (10000 ** omega)
# 2. 准备所有位置的坐标
out_h = grid[0].flatten()
out_w = grid[1].flatten()
# ... 省略初始化 ...
# 3. 计算每个坐标在不同频率下的 sin 和 cos 值
x_pos = out_h.reshape(-1, 1) * omega.reshape(1, -1)
y_pos = out_w.reshape(-1, 1) * omega.reshape(1, -1)
# 4. 将计算结果交错填入最终的嵌入向量
pos_embed[:, 0::4] = np.sin(x_pos)
pos_embed[:, 1::4] = np.cos(x_pos)
pos_embed[:, 2::4] = np.sin(y_pos)
pos_embed[:, 3::4] = np.cos(y_pos)
# 5. 为 cls_token 添加一个零向量
# ... 省略 ...
pos_embed = np.concatenate([cls_pos_embed[None], pos_embed], axis=0)
return pos_embed计算频率 omega:
-
omega = np.arange(embed_dim // 4) / (embed_dim // 4 - 1): 生成一个从 0 线性增加到 1 的序列。 -
omega = 1. / (10000 ** omega): 将上述序列作为指数,计算 10000x 的倒数。这会生成一个从 1/100000=1 几何递减到 1/100001=0.0001 的序列。这个序列omega就扮演了不同“频率”的角色。低频(值接近1)用来编码大概位置,高频(值很小)用来编码精细位置。
准备所有位置的坐标:
-
out_h = grid[0].flatten(): 将[14, 14]的h坐标网格“压平”,变成一个长度为 196 的一维数组,包含了从左到右、从上到下所有 patch 的h坐标。 -
out_w = grid[1].flatten(): 同理,获取所有 patch 的w坐标。
计算 sin 和 cos 的输入:
-
x_pos = out_h.reshape(-1, 1) * omega.reshape(1, -1): 这是一个非常高效的广播乘法。它将每一个h坐标(out_h中的每个元素)与omega序列中的每一个频率相乘。结果x_pos是一个[196, embed_dim/4]的矩阵,其中x_pos[i, j]代表第i个 patch 的h坐标与第j个频率的乘积。 -
y_pos = out_w.reshape(-1, 1) * omega.reshape(1, -1): 对w坐标执行同样的操作。
交错填充嵌入向量:
-
这是此实现最独特的地方。它将
embed_dim维度的向量分成了 4 组。 -
pos_embed[:, 0::4] = np.sin(x_pos): 将sin(x_pos)的结果填充到pos_embed的第 0, 4, 8, 12, ... 列。 -
pos_embed[:, 1::4] = np.cos(x_pos): 将cos(x_pos)的结果填充到pos_embed的第 1, 5, 9, 13, ... 列。 -
pos_embed[:, 2::4] = np.sin(y_pos): 将sin(y_pos)的结果填充到pos_embed的第 2, 6, 10, 14, ... 列。 -
pos_embed[:, 3::4] = np.cos(y_pos): 将cos(y_pos)的结果填充到pos_embed的第 3, 7, 11, 15, ... 列。
效果: 最终,对于任何一个 patch 的位置嵌入向量,它的维度被 H-sin, H-cos, W-sin, W-cos 这四种信息交错填充。例如,前四个维度的值分别是 h 坐标的 sin 和 cos,以及 w 坐标的 sin 和 cos(都使用第一个频率)。这样,一个 embed_dim 维的向量就同时编码了二维空间中的 h 和 w 信息。
为 cls_token 添加位置:
-
cls_token是一个不对应任何空间位置的特殊令牌。因此,这里为它创建了一个全为 0 的位置向量。 -
np.concatenate(...): 将这个全零向量拼接到所有 patch 位置嵌入的最前面,使得最终的pos_embed数组的形状为[197, 768],与cls_token拼接后的 patch 序列长度完全对应。
forward_features 函数是一个子部分,它专门负责从输入的图像中提取出高级特征向量。可以把它理解为整个 ViT 模型的核心“特征提取器”。
def forward_features(self, x):
"""提取特征"""
# Patch嵌入
x = self.patch_embed(x) # [B, n_patches, embed_dim]
# 添加cls token
cls_token = self.cls_token.expand(x.shape[0], -1, -1) # [B, 1, embed_dim]
x = torch.cat((cls_token, x), dim=1) # [B, 1+n_patches, embed_dim]
# 添加位置嵌入
x = x + self.pos_embed
x = self.pos_drop(x)
# 通过Transformer块
x = self.blocks(x)
x = self.norm(x)
# 使用cls token作为特征表示
x = x[:, 0]
return x# Patch嵌入
x = self.patch_embed(x) # [B, n_patches, embed_dim]-
输入
x: 此时的x是一个标准的图像张量,形态为[B, 3, 224, 224](批量大小, 通道数, 高, 宽)。 -
操作: 将图像张量
x送入我们在__init__中定义的self.patch_embed层。 -
作用:
self.patch_embed层将输入的图像网格转换成一个一维的向量序列。它把图片切成小块 (patches),然后将每个小块线性变换成一个向量。 -
输出
x:x的形态发生了根本性变化,从一个二维图像数据变为了一维序列数据。其形态为[B, 196, 768](批量大小, patch数量, 每个patch的嵌入维度)。
# 添加cls token
cls_token = self.cls_token.expand(x.shape[0], -1, -1) # [B, 1, embed_dim]
x = torch.cat((cls_token, x), dim=1) # [B, 1+n_patches, embed_dim]-
输入
x: 形态为[B, 196, 768]。 -
操作:
-
self.cls_token: 这是一个我们在__init__中定义的、可学习的张量,原始形态为[1, 1, 768]。 -
.expand(x.shape[0], -1, -1): 这是一个非常高效的操作。x.shape[0]就是批量大小B。.expand会将cls_token在第 0 维度(批量维度)上“复制”B次,以匹配输入x的批量大小。注意,它并不会真的复制数据占用额外内存,只是在计算上表现得像复制了一样。-1表示保持该维度的大小不变。因此,cls_token的形态变为[B, 1, 768]。 -
torch.cat((cls_token, x), dim=1):cat是拼接操作。dim=1表示在序列维度上进行拼接。它将[B, 1, 768]的cls_token和[B, 196, 768]的x拼接在一起。
-
-
作用: 在序列的最前面(索引为 0 的位置)加入这个特殊的
cls_token,它将作为整个图像的“代表”或“摘要”,用于最终的分类任务。 -
输出
x:x的序列长度增加了 1,形态变为[B, 197, 768]。
# 添加位置嵌入
x = x + self.pos_embed
x = self.pos_drop(x)-
输入
x: 形态为[B, 197, 768]。 -
操作:
-
x = x + self.pos_embed: 将self.pos_embed(形态为[1, 197, 768])与x进行逐元素相加。由于 PyTorch 的广播机制 (broadcasting),self.pos_embed的第 0 维会自动扩展以匹配x的批量大小B。 -
x = self.pos_drop(x): 对相加后的结果应用 Dropout,以进行正则化,防止过拟合。
-
-
作用: 为序列中的每一个向量(包括
cls_token和所有的 patch 向量)注入其原始的空间位置信息。这是至关重要的一步,因为它弥补了自注意力机制本身无法感知顺序的缺陷。 -
输出
x:x的值发生了变化,但其形态保持不变,仍然是[B, 197, 768]。
# 通过Transformer块
x = self.blocks(x)
x = self.norm(x)-
输入
x: 形态为[B, 197, 768],已经是一个包含了内容和位置信息的完整序列。 -
操作:
-
x = self.blocks(x): 将x送入self.blocks。self.blocks是一个nn.Sequential容器,它包含了多层(例如 12 层)的 Transformer Block。数据x会依次穿过每一层 Block。在每一层中,通过多头自注意力机制和前馈网络,序列中的每个向量都会与其他所有向量进行信息交换和深度加工。 -
x = self.norm(x): 经过所有blocks处理后,再通过一个最终的层归一化 (LayerNorm),以稳定输出。
-
-
作用: 这是模型的核心计算阶段。通过层层堆叠的自注意力,模型能够学习到从局部到全局的复杂图像特征。
cls_token在这个过程中不断地与所有 patch 向量交互,最终聚合了整个图像的精华信息。 -
输出
x: 在这个漫长的计算过程中,x的形态始终保持不变,仍然是[B, 197, 768]。
# 使用cls token作为特征表示
x = x[:, 0]-
输入
x: 形态为[B, 197, 768],是经过深度处理的特征序列。 -
操作: 这是一个切片操作。
-
:表示选取第 0 维(批量维度)的所有元素。 -
0表示只选取第 1 维(序列维度)的第 0 个元素。
-
-
作用: 我们只关心序列中位于第一个位置的
cls_token的最终状态。经过所有 Transformer 层的“锤炼”,这个向量已经成为了整个图像的高度浓缩的特征表示。我们把它提取出来用于后续任务。 -
输出
x:x的形态变为[B, 768]。序列维度被去掉了,现在x是一个二维张量,每一行都代表一张图片的高级特征向量。
def forward(self, x):
"""前向传播"""
# 提取特征
x = self.forward_features(x)
# 映射到输出维度
x = self.head(x)
# 归一化特征以便于相似度计算
x = F.normalize(x, p=2, dim=-1)
return x
-
输入
x: 初始的图像张量,形态为[B, 3, 224, 224]。 -
操作: 调用我们刚刚详细分析过的
self.forward_features(x)函数。 -
作用: 执行从图像块嵌入 (Patch Embedding)、添加 CLS 令牌和位置嵌入,到通过所有 Transformer 编码器块的完整过程。这一步的目的是将原始的、高维的像素数据,提炼成一个紧凑且信息丰富的特征向量。
-
输出
x:forward_features函数返回的是cls_token对应的特征向量,所以x的形态从图像张量变为了特征向量张量,形态为[B, 768](或[B, embed_dim])。
-
输入
x: 从上一步得到的特征向量,形态为[B, 768]。 -
操作: 将特征向量
x送入我们在__init__中定义的self.head层。 -
作用:
self.head通常是一个线性层 (nn.Linear),其作用是**“翻译官”或“投影仪”**。它将 Transformer 编码器输出的通用特征(维度为embed_dim=768)映射(或称为投影)到我们任务所需的特定维度(output_dim)。-
如果这是一个 1000 类的分类任务,
self.head就是nn.Linear(768, 1000),输出形态会变为[B, 1000]。 -
在这个例子中,
__init__里定义的output_dim是 512,所以self.head是nn.Linear(768, 512)。
-
-
输出
x:x的维度发生了变化,形态变为[B, 512](或[B, output_dim])。
-
输入
x: 经过head层映射后的特征向量,形态为[B, 512]。 -
操作: 调用 PyTorch 的
functional库中的normalize函数。-
p=2: 指定使用 L2 范数进行归一化。对于一个向量 v,它的 L2 范数就是其所有元素的平方和再开根号,即向量在欧几里得空间中的“长度”,记作 ∣∣v∣∣_2。 -
dim=-1: 指定沿着最后一个维度(在这里就是 512 维的特征维度)进行归一化操作。 -
归一化过程: 对批量中的每一个特征向量 v,都计算 v/∣∣v∣∣_2。
-
-
作用: 它揭示了这个模型的最终目的。
-
强制长度为 1: L2 归一化会强制所有输出的特征向量长度都为 1。这意味着无论原始特征向量的“能量”或“强度”如何,最终它们都会被投影到单位超球面的表面上。
-
关注方向,忽略大小: 这样做的目的是为了让模型在比较两个向量时,更关注它们的方向(角度),而不是它们的长度(大小)。在很多任务中,比如图像检索、人脸识别、对比学习等,我们衡量两个物体是否相似,看的正是它们特征向量之间的夹角(通过余弦相似度 cos(θ) 计算)。
-
简化相似度计算: 当两个向量 v_1 和 v_2 的长度都为 1 时,它们之间的余弦相似度就等于它们的点积 (v_1⋅v_2),这极大地简化了计算。
-
-
输出
x:x的值发生了改变(所有向量的长度都变成了 1),但其形态保持不变,仍然是[B, 512]。
这就是VIT模型的一切了,接下来总结梳理一下。
VIT最终总结梳理
可以分为两个层次:核心构件和整体架构。
第一部分:核心构件
1. PatchEmbedding: 模型的“眼睛”
职责: 负责 ViT 的第一步,也是最核心的转换:将 2D 图像转化为 1D 序列。
实现: 使用了 nn.Conv2d,将 kernel_size 和 stride 都设为 patch_size。这就像一个“印章”,在图片上不重叠地盖过去,一次性完成了图像分块和线性嵌入两个步骤。
数据流: [B, 3, 224, 224] -> [B, 196, 768]。
2. Attention: Transformer 的“大脑”
职责: 实现多头自注意力机制,让序列中的每个 patch 向量都能“看到”并“关注”所有其他的 patch 向量,从而捕捉全局依赖关系。
实现: 代码遵循标准流程:
用一个 nn.Linear 层一次性生成查询 (Q)、键 (K)、值 (V)。
将 Q, K, V 分割成多个“头” (heads),让模型能从不同角度关注信息。
计算注意力分数![]() 并通过
并通过 softmax 归一化。
用注意力分数加权聚合 V。
将多头的结果拼接并经过一个最终的线性层输出。
数据流: 输入 [B, 197, 768],输出形态不变,但内部信息经过了充分的交互和重组。
3. MLP (多层感知机): 信息的“处理器”
职责: 在自注意力之后,为序列中的每一个向量提供一个非线性处理单元。
实现: 这是一个标准的两层全连接网络,中间使用 GELU 激活函数。它对每个 token 进行独立处理,增加了模型的深度和非线性表达能力。
数据流: 输入 [B, 197, 768],输出形态不变,但每个 token 的表示都得到了进一步的提炼。
4. Block: 标准化的“流水线单元”
职责: 将 Attention 和 MLP 组合成一个标准的 Transformer 编码器块。
实现: Transformer 的经典结构:
1.Pre-Norm 结构: 先进行 LayerNorm,再送入 Attention 或 MLP。
2.残差连接 (Residual Connection): x = x + ...,将输入直接加到输出上,这极大地稳定了训练过程,让深度模型成为可能。
流程: 输入 -> LayerNorm -> Attention -> + 输入 -> LayerNorm -> MLP -> + 输入。
第二部分:整体架构 VisionTransformer
__init__ (模型蓝图)
这里定义了模型的所有组件和参数:
self.patch_embed: 实例化模型的“眼睛”。
self.cls_token 和 self.pos_embed: 创建两个至关重要的可学习参数。cls_token 是用于最终分类的“摘要”向量,pos_embed 则是为了给模型注入空间位置信息。
self.blocks: 使用 nn.Sequential 将 depth 个 Block 模块串联起来,形成了模型的主干,即 Transformer 编码器。
self.head: 定义了最终的线性投影层,用于将特征映射到所需的输出维度。
_init_weights & 辅助函数 (初始化与设置)
_get_sincos_pos_embed: 实现了一套完整的、基于数学公式的 2D 正弦余弦位置编码生成方法。这为模型提供了一个强大且无需学习的初始位置信息。
_init_weights_layer: 通过 self.apply 机制,为模型中不同类型的层(nn.Linear, nn.LayerNorm)提供了专门的、效果更好的初始化方案(如 Xavier 初始化)。
_init_weights: 统一调用上述方法,完成了对 pos_embed、cls_token 和其他所有权重的初始化,为模型稳定训练奠定了基础。
forward & forward_features (数据的前向传播)
这部分是模型的动态执行过程,清晰地展示了数据的完整旅程:
-
起点: 一张图片
x,形态为[B, 3, 224, 224]。 -
patch_embed(x): 图片被转化为 patch 序列,x变为[B, 196, 768]。 -
添加
cls_token: 在序列前拼接cls_token,x变为[B, 197, 768]。 -
添加
pos_embed: 逐元素加上位置嵌入,x形态不变,但获得了空间信息。 -
通过
blocks:x流经 12 个 TransformerBlock,在保持形态[B, 197, 768]不变的同时,进行深度的特征学习和信息交互。 -
提取
cls_token: 从序列中取出索引为 0 的cls_token的最终状态,x变为[B, 768]。 -
通过
head: 将cls_token向量投影到最终输出维度,x变为[B, 512]。 -
归一化: 对最终的特征向量进行 L2 归一化,使其长度为 1,
x形态不变,但已准备好用于相似度计算任务。 -
终点: 返回一个高质量的、标准化的图像嵌入向量。
CLIP模型架构讲解
CLIP 的架构非常简洁,主要由两个独立的核心部分组成:一个图像编码器 (Image Encoder) 和一个文本编码器 (Text Encoder)。
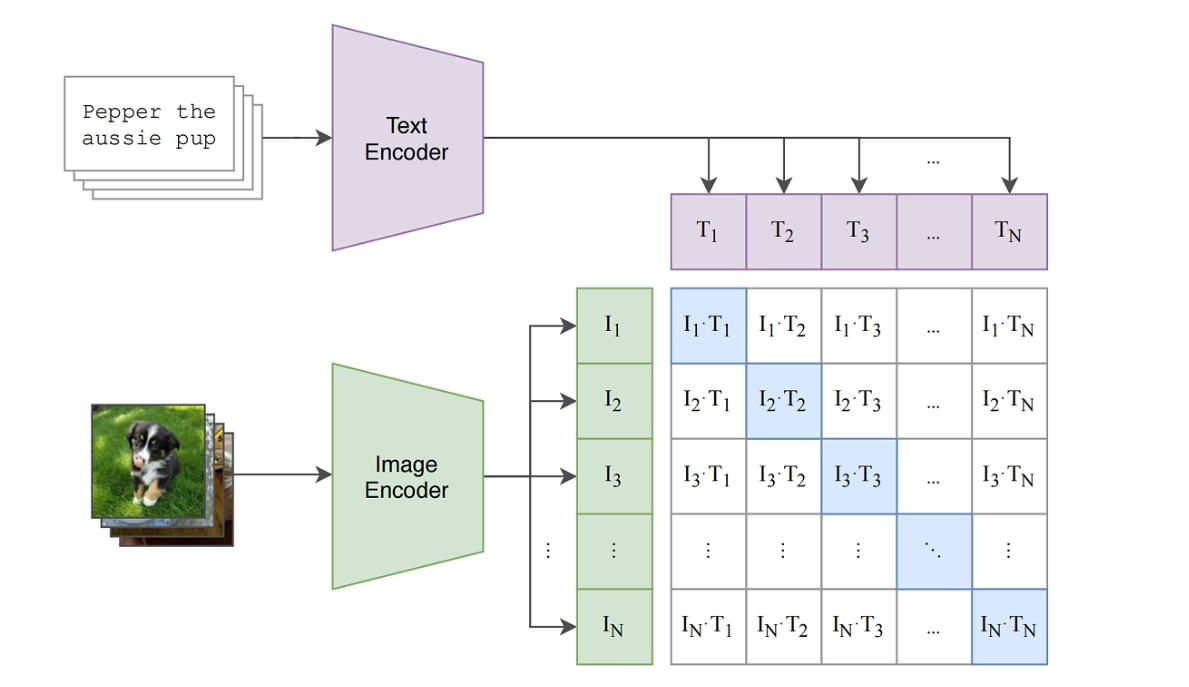
1. 图像编码器
作用: 接收一张图片作为输入,输出一个代表该图片内容的特征向量 I_f。
具体实现: OpenAI 在原论文中实验了两种主流的视觉模型作为图像编码器:
ResNet: 使用了经过修改的 ResNet-50,例如用注意力池化层(Attentional Pooling)取代全局平均池化层,以更好地聚合特征。
Vision Transformer (ViT): 这是更好的一个版本。ViT 将图片分割成一个个小块(Patches),将这些小块线性投影后,像处理单词一样送入一个标准的 Transformer 编码器中,最终提取出代表整张图片的特征向量。
无论使用哪种模型,最终目标都是将任意大小的输入图片,转换成一个固定维度(例如 512 维)的向量 I_f。
2. 文本编码器
作用: 接收一段文本作为输入,输出一个代表该文本语义的特征向量 T_f。
具体实现: CLIP 使用了一个标准的 Transformer 模型。
1.输入处理: 文本首先被分词(Tokenization),转换成数字 ID 序列。
2.编码过程: 这些 ID 序列被送入 Transformer 模型中。通过自注意力机制(Self-Attention),模型能够捕捉单词之间的依赖关系和上下文信息。
3.输出: 通常会取特定 token(如 [EOS] 或 [CLS] token)在最高层的输出,经过处理后,得到代表整个文本的特征向量 T_f。这个向量的维度与图像特征向量 I_f 相同。
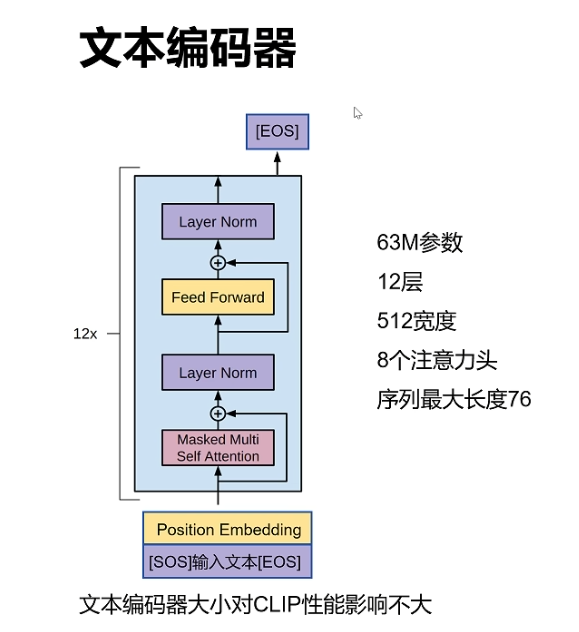
CLIP 工作流程
CLIP 的工作流程可以分为两个主要阶段:预训练 (Pre-training) 和 推理/零样本预测 (Inference / Zero-Shot Prediction)。
第一阶段:预训练
这是 CLIP 学习图像与文本关联的核心步骤。
数据准备: OpenAI 从互联网上收集了一个包含 4 亿个(图像,文本)对的庞大数据集。这些文本描述就是图像的原始标题或说明。
构建训练批次 (Batch):
在训练时,程序会随机抽取 N 个(图像,文本)对组成一个批次 (Batch)。例如,假设 N=3。
这样我们就有了 3 张图像 (I1,I2,I3) 和 3 个对应的文本描述 (T1,T2,T3)。
在这个批次内,I1 与 T1 是正样本对,I2 与 T2 是正样本对,I3 与 T3 也是正样本对。
而 I1 与 T2、I1 与 T3、I2 与 T1 等所有不匹配的组合,都构成负样本对。总共有 N2−N 个负样本对。
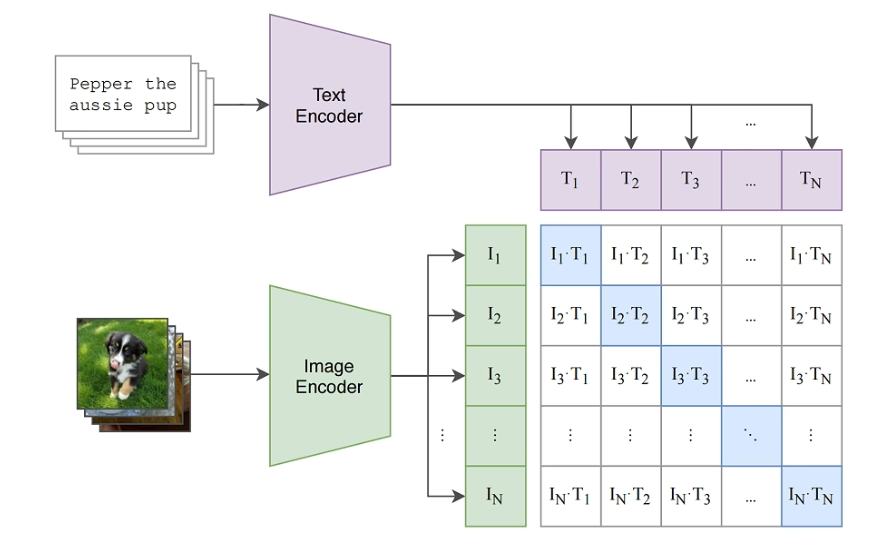
特征编码:
将 N 张图像分别送入图像编码器,得到 N 个图像特征向量 (Image Embeddings)。
将 N 个文本描述分别送入文本编码器,得到 N 个文本特征向量 (Text Embeddings)。
对比学习 (Contrastive Learning):
计算相似度: 对于批次内的每一张图像,计算其特征向量与所有 N 个文本特征向量之间的余弦相似度 (Cosine Similarity)。同样地,也计算每个文本特征向量与所有图像特征向量的相似度。这会形成一个 N×N 的相似度矩阵。
优化目标: 模型的目标是 最大化 正样本对(匹配的图像和文本)的余弦相似度,同时 最小化 所有负样本对(不匹配的图像和文本)的余弦相似度。
损失函数: 通过一个对比损失函数(例如 InfoNCE Loss)来实现上述目标。这个损失函数会同时在图像和文本两个方向上进行计算,促使模型将匹配的(图像,文本)对在特征空间中“拉近”,将不匹配的对“推远”。
通过在亿万级别的数据上反复进行这个过程,图像编码器和文本编码器逐渐学会了将语义相关的图像和文本映射到特征空间中相近的位置。
对角线为正样本,我们最大化对角线的值,减少其余值
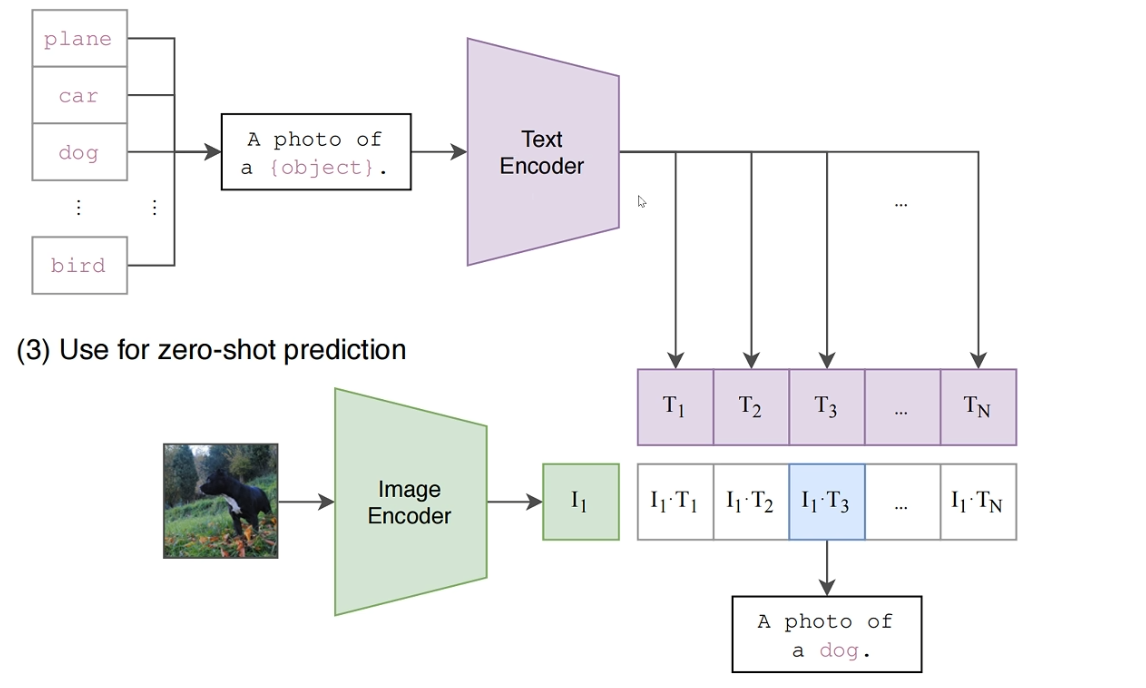
第二阶段:推理/零样本预测
当模型预训练完成后,就可以用它来执行各种分类任务,而无需针对新任务进行任何额外的训练。这个过程被称为“零样本预测”。
假设我们想对一张新的图像进行分类,分类的标签可能是“猫”、“狗”或“飞机”。
准备候选文本: 将所有可能的分类标签转换成描述性的文本。例如,将 "cat" 转换为 "a photo of a cat","dog" 转换为 "a photo of a dog"。这种模板化的方法 (prompt engineering) 能有效提升性能。
编码文本: 将所有这些描述性文本(例如 "a photo of a cat", "a photo of a dog", "a photo of a plane")分别送入已经训练好的 文本编码器,得到它们各自的文本特征向量。
编码图像: 将待分类的新图像送入已经训练好的 图像编码器,得到该图像的特征向量。
计算相似度: 计算该图像的特征向量与 每一个 文本特征向量之间的余弦相似度。
预测结果: 哪个文本描述产生的特征向量与图像特征向量的相似度最高,那么该文本对应的类别就是最终的预测结果。例如,如果图像特征向量与 "a photo of a cat" 的文本特征向量相似度最高,模型就会预测这张图片是“猫”。
CLIP模块代码解析
- 主要组件:
- TextTransformer:文本处理的Transformer模型
- SimpleTokenizer:将文本转换为token序列的工具
- CLIPModel:集成视觉和文本编码器的完整CLIP模型
- CLIPLoss:计算对比学习损失函数,用于训练
- load_clip_model:加载不同配置CLIP模型的工厂函数
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from .vit import VisionTransformer
1.文本编码器
class TextTransformer(nn.Module):
"""文本Transformer编码器"""
def __init__(self, vocab_size=49408, context_length=77, embed_dim=512, transformer_width=512,
transformer_heads=8, transformer_layers=12, output_dim=512):
super().__init__()
self.context_length = context_length # 文本最大长度
# 词嵌入
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
# 位置嵌入
self.positional_embedding = nn.Parameter(torch.empty(context_length, transformer_width))
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=transformer_width,
nhead=transformer_heads,
dim_feedforward=transformer_width * 4,
dropout=0.1,
activation='gelu',
batch_first=True,
norm_first=True
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=transformer_layers)
# 文本特征输出层
self.ln_final = nn.LayerNorm(transformer_width)
self.text_projection = nn.Linear(transformer_width, output_dim, bias=False)
# 初始化
self.initialize_parameters()
def initialize_parameters(self):
# 初始化位置嵌入
nn.init.normal_(self.positional_embedding, std=0.01)
# 初始化token嵌入
nn.init.normal_(self.token_embedding.weight, std=0.02)
# 初始化投影层
nn.init.normal_(self.text_projection.weight, std=self.text_projection.weight.shape[0] ** -0.5)
def forward(self, text):
"""前向传播
参数:
- text: 形状为[batch_size, seq_len]的文本token序列
返回:
- 形状为[batch_size, output_dim]的文本特征
"""
# 确保输入不超过上下文长度
x = text[:, :self.context_length]
# 词嵌入
x = self.token_embedding(x)
# 添加位置嵌入
x = x + self.positional_embedding
# 通过Transformer编码器
x = self.transformer(x)
# 使用序列最后一个token的特征作为文本特征
x = self.ln_final(x[:, -1, :])
# 投影到输出维度
x = self.text_projection(x)
# 归一化特征
x = F.normalize(x, p=2, dim=-1)
return x这种编码器的核心任务是将输入的文本序列(一句话或一段文字)转换成一个固定维度的数学向量,这个向量可以被认为是文本的“特征表示”或“嵌入”。在 CLIP 模型中,与图像特征进行比较。
def __init__(self, vocab_size=49408, context_length=77, embed_dim=512, transformer_width=512,
transformer_heads=8, transformer_layers=12, output_dim=512):这些超参数定义了模型可以接受到多大的文本规模,决定了模型的大小
vocab_size:决定了模型可以识别到多少不同的词(token),49408几乎就是我们日常对话的极限了。
context_length:上下文的长度,就是模型可以接受多少个token的句子,最大的句子长度,最大77,超过被截断,不足就补全
transformer_width:Transformer内部的工作维度,也可说就是词嵌入的维度,d_model,在这里是512
transformer_heads:多头注意力的头个数,这里是8,也是就8个多头注意力头,工作维度由8个注意力头平分。
transformer_layers:这是编码器block堆叠的数量,这里一个层堆叠了12个block,一般来说层数越多,模型学习到的东西越深,但是也更难以训练。
output_dim:最终输出的文本特征向量维度,模型内部的维度是transformer_width,最后通过一个线性层,可以把它映射到任意一个目标维度,这里的目标维度为512
embed_dim:在当前代码里,transformer_width 承担了嵌入维度的角色。
计算机无法直接处理文字,所以第一步需要将文本转换成数字向量。这个过程由嵌入层完成。
# 词嵌入
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
# 位置嵌入
self.positional_embedding = nn.Parameter(torch.empty(context_length, transformer_width))self.token_embedding:这是一个词嵌入层,输入一个词的索引,将词转化为transformer_width维度的向量,这里是把一个词变成512维的向量,每个词都对应一个专属的向量。模型接收一个由词元索引组成的序列(例如一句话 ["Hello", "world"]被转换为 [103, 2046])
#伪代码
learned_embeddings = [
[0.12, 0.84, -0.15, ...], # 索引103对应的向量(代表"Hello")
[0.75, -0.22, 0.41, ...] # 索引2046对应的向量(代表"world")
]self.positional_embedding:位置嵌入,标准的 Transformer 模型本身不包含任何关于序列顺序的信息(它同时处理所有词元)。为了让模型理解词元在句子中的位置关系(比如哪个词在前,哪个词在后),我们需要给每个位置也赋予一个向量。这个位置向量会和对应位置的词元向量相加,从而将位置信息融入到输入中。nn.Parameter 告诉 PyTorch,这个张量是模型的一个可学习参数,它的大小是 (context_length, transformer_width),正好对应序列中每个位置。
将每个位置的索引映射为一个向量(维度与词嵌入相同),然后与词嵌入相加:
输入向量 = 词嵌入向量 + 位置编码向量
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=transformer_width,
nhead=transformer_heads,
dim_feedforward=transformer_width * 4,
dropout=0.1,
activation='gelu',
batch_first=True,
norm_first=True
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=transformer_layers)d_model=transformer_width:设置工作维度
nhead=transformer_heads:多头注意力头数量
dim_feedforward=transformer_width * 4:前馈网络的中间层数,一般是d_model的四倍
batch_first=True:指定batch_size为第一输出通道,指定输入张量的维度顺序是 (批量大小, 序列长度, 特征维度)
norm_first=True:这指定了“Pre-LN”(前置层归一化)结构。即在进入自注意力和前馈网络 之前 进行层归一化(Layer Normalization)。这种结构通常比原始的“Post-LN”结构训练起来更稳定。
nn.TransformerEncoder():这个模块将我们刚刚定义的 encoder_layer 复制并堆叠 transformer_layers (这里是12) 次,构成一个完整的、深度的 Transformer 编码器。输入数据会依次穿过这12层,每一层都会对文本的表示进行一次提炼和加深。
# 文本特征输出层
self.ln_final = nn.LayerNorm(transformer_width)
self.text_projection = nn.Linear(transformer_width, output_dim, bias=False)
# 初始化
self.initialize_parameters()self.ln_final = nn.LayerNorm(transformer_width):进入线形层最终归一化,有益于稳定训练。
self.text_projection:这是将最后输出的文本特征向量将其映射到一个与图像特征对齐的公共空间,从而使得文本和图像可以直接进行比较,计算余弦相似度。
def initialize_parameters(self):
# 初始化位置嵌入
nn.init.normal_(self.positional_embedding, std=0.01)
# 初始化token嵌入
nn.init.normal_(self.token_embedding.weight, std=0.02)
# 初始化投影层
nn.init.normal_(self.text_projection.weight, std=self.text_projection.weight.shape[0] ** -0.5)def forward(self, text):
"""前向传播
参数:
- text: 形状为[batch_size, seq_len]的文本token序列
返回:
- 形状为[batch_size, output_dim]的文本特征
"""
# 确保输入不超过上下文长度
x = text[:, :self.context_length]
# 词嵌入
x = self.token_embedding(x)
# 添加位置嵌入
x = x + self.positional_embedding
# 通过Transformer编码器
x = self.transformer(x)
# 使用序列最后一个token的特征作为文本特征
x = self.ln_final(x[:, -1, :])
# 投影到输出维度
x = self.text_projection(x)
# 归一化特征
x = F.normalize(x, p=2, dim=-1)
return x
x = text[:, :self.context_length]:这是一个安全机制,保证只处理77个词元
# 词嵌入
x = self.token_embedding(x)
# 添加位置嵌入
x = x + self.positional_embedding这两步与之前的解释完全相同。首先,通过 token_embedding 将整数词元ID转换为 transformer_width 维的向量。然后,加上 positional_embedding,将位置信息融入到向量表示中。此时张量 x 的形状为 [batch_size, context_length, transformer_width]。
# 通过Transformer编码器
x = self.transformer(x)这是模型的核心计算部分。包含了位置信息的词向量被送入多层 Transformer 编码器。经过自注意力机制和前馈网络的复杂计算后,输出的张量 x 形状不变,但现在每个位置的向量都包含了对整个句子上下文的理解。
x = self.text_projection(x)
最后经过线性投影层,转化为图片空间的向量对齐。此步骤与之前一样,将归一化后的文本特征从 transformer_width 维度线性投影到最终的 output_dim 维度。此时 x 的形状变为 [batch_size, output_dim]。
2.分词器
分词器(Tokenizer)是连接我们人类语言和 TextTransformer 模型的关键桥梁。神经网络无法直接处理文本字符串,它只能处理数字。因此,分词器的核心任务就是将文本字符串转换成一个由整数组成的序列(Token ID 序列),以及将这个整数序列再转换回文本。
这个 SimpleTokenizer 是一个简化的实现,主要用于教学和理解基本原理。
class SimpleTokenizer:
"""简单的文本分词器,用于处理英文文本"""
def __init__(self, max_length=77):
self.max_length = max_length
# 加载基本词汇表(示例实现)
self.encoder = {"<|startoftext|>": 0, "<|endoftext|>": 1, "<|pad|>": 2}
self.decoder = {0: "<|startoftext|>", 1: "<|endoftext|>", 2: "<|pad|>"}
# 添加基本ASCII字符
for i in range(32, 127):
char = chr(i)
if char not in self.encoder:
self.encoder[char] = len(self.encoder)
self.decoder[len(self.decoder)] = char
# 简单起见,这里只实现了基础ASCII字符的编码
# 实际应用中应该使用BPE或WordPiece等算法构建更完整的词汇表
def encode(self, text):
"""将文本编码为token序列"""
tokens = [self.encoder["<|startoftext|>"]]
for char in text:
if char in self.encoder:
tokens.append(self.encoder[char])
else:
# 对于未知字符,使用空格替代
tokens.append(self.encoder[" "])
tokens.append(self.encoder["<|endoftext|>"])
# 填充或截断到指定长度
if len(tokens) < self.max_length:
tokens.extend([self.encoder["<|pad|>"]] * (self.max_length - len(tokens)))
else:
tokens = tokens[:self.max_length]
return tokens
def decode(self, tokens):
"""将token序列解码为文本"""
text = ""
for token in tokens:
if token == self.encoder["<|startoftext|>"] or token == self.encoder["<|endoftext|>"] or token == self.encoder["<|pad|>"]:
continue
text += self.decoder[token]
return text
def tokenize(self, texts, return_tensors="pt"):
"""批量处理文本"""
if isinstance(texts, str):
texts = [texts]
all_tokens = [self.encode(text) for text in texts]
if return_tensors == "pt":
return torch.tensor(all_tokens)
return all_tokensdef __init__(self, max_length=77):
self.max_length = max_length
self.encoder = {"<|startoftext|>": 0, "<|endoftext|>": 1, "<|pad|>": 2}
self.decoder = {0: "<|startoftext|>", 1: "<|endoftext|>", 2: "<|pad|>"}self.max_length = 77:定义了分词器的最大长度
self.encoder 和 self.decoder:这两个是字典,构成了分词器的词汇表 (Vocabulary)。
encoder负责把词汇转成数字,decoder负责把数字转回词汇
encoder:将词元编码为唯一的整数ID,例如把A=1
decoder:把整数id变为词元A,1->a
<|startoftext|>:id= 0 代表从这里开始
<|endoftext|:id =1.代表从这里结束了
<|pad|>:id = 2,因为模型需要接收固定长度的输入(这里是77),所以对于不够长的文本,就需要用这个填充符补齐到 max_length。
# 添加基本ASCII字符
for i in range(32, 127):
char = chr(i)
if char not in self.encoder:
self.encoder[char] = len(self.encoder)
self.decoder[len(self.decoder)] = char
# 简单起见,这里只实现了基础ASCII字符的编码
# 实际应用中应该使用BPE或WordPiece等算法构建更完整的词汇表这段循环代码用基本的 ASCII 可见字符(如字母、数字、标点符号)来填充词汇表。这是一个非常简化的做法,实际应用中的分词器(如 BPE)会通过算法学习如何将文本切分成更有效的子词单元,而不仅仅是单个字符。
for i in range(32, 127):
range(32, 127) 会生成从 32 到 126 的一系列整数。在 ASCII 编码表中,这个范围正好对应了所有可打印的英文字符,包括空格(ASCII 32)、!(ASCII 33)、数字 0-9、大写字母 A-Z、小写字母 a-z 以及各种标点符号。
char = chr(i):
这是Python内置函数,功能是将整数(ASCII码)转换为对应的字符。
例如:
chr(65) → 'A'
chr(97) → 'a'
chr(33) → '!'
if char not in self.encoder:: 这是一个检查,确保我们不会重复添加已经存在的字符。在这个特定的代码里,由于初始 encoder 里没有这些字符,所以这个判断总是成立的。
self.encoder[char] = len(self.encoder):为新字符分配一个唯一ID
在 for 循环开始之前,encoder 和 decoder 的状态是这样的:
-
self.encoder={"<|startoftext|>": 0, "<|endoftext|>": 1, "<|pad|>": 2}-
当前大小
len(self.encoder)是 3。
-
-
self.decoder={0: "<|startoftext|>", 1: "<|endoftext|>", 2: "<|pad|>"}-
当前大小
len(self.decoder)也是 3。
-
举例讲解:循环第一次 (i = 32)
-
i的值是32。 -
char = chr(32)执行后,char变成了空格' '。 -
关键点来了: 执行
self.encoder[char] = len(self.encoder)-
此时
len(self.encoder)是多少? 是 3。 -
所以这行代码就变成了
self.encoder[' '] = 3。 -
执行后,
self.encoder更新为:{"<|startoftext|>": 0, ..., 2, ' ': 3}。
-
-
接着执行
self.decoder[len(self.decoder)] = char-
此时
len(self.decoder)是多少? 也是 3。 -
所以这行代码就变成了
self.decoder[3] = ' '。 -
执行后,
self.decoder更新为:{0: "...", ..., 2: "...", 3: ' '}。
-
def encode(self, text):
"""将文本编码为token序列"""
tokens = [self.encoder["<|startoftext|>"]]
for char in text:
if char in self.encoder:
tokens.append(self.encoder[char])
else:
# 对于未知字符,使用空格替代
tokens.append(self.encoder[" "])
tokens.append(self.encoder["<|endoftext|>"])
# 填充或截断到指定长度
if len(tokens) < self.max_length:
tokens.extend([self.encoder["<|pad|>"]] * (self.max_length - len(tokens)))
else:
tokens = tokens[:self.max_length]
return tokens简单来说,encode 函数的目标是接收一个普通的文本字符串(比如 "Hello world"),然后输出一个长度固定的、由整数组成的列表。这个列表就是机器学习模型能够理解的格式。
整个过程可以分为四个主要步骤:
-
添加一个特殊的“起始符”。
-
逐字将文本翻译成数字。
-
添加一个特殊的“结束符”。
-
将数字列表调整到固定的长度(要么加长,要么截短)。
tokens = [self.encoder["<|startoftext|>"]]:首先创建一个词元列表,用来存放最终的数字序列。它并不是一个空列表,而是一开始就放入了“文本起始符” <|startoftext|> 对应的数字。
实例:
-
self.encoder["<|startoftext|>"]的值是0。 -
所以执行完这行代码后,
tokens列表是:[0]。
for char in text:
if char in self.encoder:
tokens.append(self.encoder[char])
else:
# 对于未知字符,使用空格替代
tokens.append(self.encoder[" "])作用: 这是编码的核心循环。它会一个一个地处理输入文本中的每个字符。
if char in self.encoder:检查是否在我们的词汇表中,ASCII那个。
tokens.append(self.encoder[char]),如果存在,就从字典中查出它对应的数字,并添加到 tokens 列表的末尾。
-
else: 如果字符不存在(比如一个中文字符或者表情符号),这个分词器不知道该怎么办。 -
tokens.append(self.encoder[" "]): 这是一种简单的处理未知字符的策略:直接用空格的 ID 来代替。更高级的分词器通常会有一个专门的“未知符”<UNK>。
实例 (text = "Hi"):
-
循环第一次:
char是'H'。'H'在self.encoder中,对应的值是72。tokens列表变为:[0, 72]。 -
循环第二次:
char是'i'。'i'在self.encoder中,对应的值是105。tokens列表变为:[0, 72, 105]。
tokens.append(self.encoder["<|endoftext|>"])作用: 当所有字符都处理完毕后,在 tokens 列表的末尾添加“文本结束符” <|endoftext|> 对应的数字。这告诉模型,句子的有效内容到此结束。
# 填充或截断到指定长度
if len(tokens) < self.max_length:
tokens.extend([self.encoder["<|pad|>"]] * (self.max_length - len(tokens)))
else:
tokens = tokens[:self.max_length]这一步至关重要,因为大多数模型要求输入的每个数据都有相同的尺寸。作用: 检查当前 tokens 列表的长度是否等于 self.max_length(在我们的例子中是 7)。
if len(tokens) < self.max_length:: 如果列表长度小于最大长度,就需要填充 (Padding)。
(self.max_length - len(tokens)):计算需要多少pad
[self.encoder["<|pad|>"]] * ...self.encoder["<|pad|>"] 的值是 2。这部分代码会创建一个包含若干个 2 的列表。
tokens.extend(...): 将这个由 2 组成的列表拼接到 tokens 的末尾。
else: tokens = tokens[:self.max_length]:如果大于,就直接截断超过的。
实例 (Padding):
-
当前
tokens是[0, 72, 105, 1],长度len(tokens)是4。 -
self.max_length是7。因为4 < 7,所以执行if内部的代码。 -
需要填充的数量是
7 - 4 = 3。 -
[2] * 3会生成列表[2, 2, 2]。 -
tokens.extend([2, 2, 2])执行后,tokens最终变为[0, 72, 105, 1, 2, 2, 2]。
实例 (Truncation):
-
假设我们的输入文本很长,处理完后
tokens变成了[0, ..., 10, 20, 30, 40, 50, 1],总长度是9。 -
因为
9 > 7,所以执行else内部的代码。 -
tokens = tokens[:7]会截取前7个元素。 -
tokens最终变为[0, ..., 10, 20](这里只是示意)。注意,这种情况下,结尾的“结束符”可能会被截掉。
def decode(self, tokens):
"""将token序列解码为文本"""
text = ""
for token in tokens:
if token == self.encoder["<|startoftext|>"] or token == self.encoder["<|endoftext|>"] or token == self.encoder["<|pad|>"]:
continue
text += self.decoder[token]
return textdecode 函数接收一个由整数组成的列表(比如 encode 函数的输出),然后将这个数字序列转换回一个人类可读的、干净的文本字符串。
它的核心逻辑很简单:
-
准备一个空字符串,用于存放结果。
-
遍历数字列表中的每一个数字。
-
如果数字代表的是特殊控制符(比如开始、结束、填充),就跳过它。
-
如果数字代表的是普通字符,就把它翻译成字符,并拼接到结果字符串上。
-
返回最终的字符串。
为了无缝衔接,我们使用上一问中 encode("Hi") 函数生成的列表作为本函数的输入。 所以,输入的 tokens 列表是: [0, 72, 105, 1, 2, 2, 2]。
同时,我们也需要 self.decoder 这个反向词汇表来进行“翻译”:
-
0:"<|startoftext|>" -
1:"<|endoftext|>" -
2:"<|pad|>" -
...
-
72:"H" -
105:"i"
-
创建一个名为
text的空字符串。我们将在循环中一步步地向这个字符串里添加字符,最终构建出完整的句子。 -
实例: 执行后,
text的值是""
for token in tokens:这是一个循环,会依次取出 tokens 列表中的每一个整数,并将其赋值给变量 token,然后执行循环体内的代码。
实例: 循环将依次处理 0, 72, 105, 1, 2, 2, 2。
if token == self.encoder["<|startoftext|>"] or token == self.encoder["<|endoftext|>"] or token == self.encoder["<|pad|>"]:
continue作用: 这是解码过程中非常关键的一步——过滤。它检查当前的 token (数字)是不是我们不希望在最终文本中看到的特殊控制符。
所以,这行 if 语句实际上就是在检查 if token == 0 or token == 1 or token == 2:
continue: 如果 if 条件成立(即当前 token 是 0, 1, 或 2),continue 关键字会立即结束本次循环,直接跳到下一个 token 的处理,if 后面的代码将不会被执行。
text += self.decoder[token]作用: 只有当 if 条件不成立时(即 token 不是 0, 1, 或 2),这行代码才会被执行。
self.decoder[token]: 这就是“解码”的核心操作。它使用 token (整数)作为键,去 self.decoder 字典中查找对应的值(字符)。
text += ...: += 是字符串拼接操作符,它将查找出的字符追加到 text 字符串的末尾。
实例:
当 token 是 72 时: if 条件不成立。执行这行代码
self.decoder[72] 查到的值是 'H'。text 从 "" 变为 "H"。
当 token 是 105 时: if 条件不成立。执行这行代码。
self.decoder[105] 查到的值是 'i'
text 从 "H" 变为 "Hi"
完整流程回顾
-
输入:
[0, 72, 105, 1, 2, 2, 2] -
text初始化为""。 -
token = 0: 是特殊符,跳过。text仍为""。 -
token = 72: 不是特殊符,解码为'H'。text变为"H"。 -
token = 105: 不是特殊符,解码为'i'。text变为"Hi"。 -
token = 1: 是特殊符,跳过。text仍为"Hi"。 -
token = 2: 是特殊符,跳过。text仍为"Hi"。 -
token = 2: 是特殊符,跳过。text仍为"Hi"。 -
token = 2: 是特殊符,跳过。text仍为"Hi"。 -
循环结束。
-
返回
text,其值为"Hi"。
def tokenize(self, texts, return_tensors="pt"):
"""批量处理文本"""
if isinstance(texts, str):
texts = [texts]
all_tokens = [self.encode(text) for text in texts]
if return_tensors == "pt":
return torch.tensor(all_tokens)
return all_tokensencode 函数一次只能处理一个文本字符串,并且只返回 Python 列表。而 tokenize 函数在此基础上做了两个重要的升级:
-
批量处理: 它可以一次性接收并处理多个文本字符串。
-
格式转换: 它可以选择性地将结果转换成深度学习框架(如 PyTorch)所需的特定数据格式——张量 (Tensor)。
我们假设要处理的输入是 texts = ["Hello", "Cat"]。
def tokenize(self, texts, return_tensors="pt"):,text是输入文本,“pt”是返回pytorch张量
if isinstance(texts, str):
texts = [texts]它检查输入的 texts 是不是一个单独的字符串 (str)
texts = [texts]: 如果 texts 是一个字符串,这行代码会把它放进一个只包含它自己的列表里。例如,如果输入是 "Hello",它会把它变成 ["Hello"]
这样一来,无论用户输入的是单个字符串还是字符串列表,后续的代码都可以统一把 texts 当作一个列表来处理,简化了逻辑。
all_tokens = [self.encode(text) for text in texts]等价于
all_tokens = []
for text in texts:
encoded_text = self.encode(text) # 调用我们之前讲过的 encode 函数
all_tokens.append(encoded_text)它会遍历 texts 列表中的每一个 text 元素,对每个元素调用 self.encode() 方法,然后将每次 encode 返回的结果(一个数字列表)收集起来,形成一个新的列表 all_tokens
实例:
-
text首先是"Hello"。调用self.encode("Hello"),假设返回[0, 72, 101, 108, 108, 111, 1, 2, ...](长度为max_length)。 -
text接着是"Cat"。调用self.encode("Cat"),假设返回[0, 67, 97, 116, 1, 2, 2, ...](长度为max_length)。 -
最终,
all_tokens会是一个列表的列表:[ [0, 72, 101, 108, 108, 111, 1, 2, ...], # "Hello" 的编码结果 [0, 67, 97, 116, 1, 2, 2, ...] # "Cat" 的编码结果 ]
tokenize 函数是一个面向用户的、高级的封装函数。它做了三件事:
-
统一输入: 无论你给它一个还是多个句子,它都能处理。
-
调用核心编码: 它循环使用
encode方法完成对每个句子的实际编码工作。 -
打包输出: 它将结果整理好,并转换成机器学习模型最喜欢的“张量”格式,方便后续直接送入模型进行训练或推理。
3.CLIP模型
这段代码定义了一个名为 CLIPModel 的 Python 类。在 PyTorch 框架中,所有的神经网络模型都应该是一个类,并且这个类需要继承自 nn.Module。nn.Module 是 PyTorch 提供的一个基础类,它帮助我们管理模型的参数、层、以及将模型移动到 GPU 等等。
class CLIPModel(nn.Module):
"""CLIP模型,结合视觉和文本编码器"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
depth=12,
n_heads=12,
output_dim=512,
vocab_size=49408,
context_length=77,
transformer_width=512,
transformer_heads=8,
transformer_layers=12,
pretrained=False
):
super().__init__()
# 初始化视觉编码器 (Vision Transformer)
self.visual = VisionTransformer(
img_size=img_size,
patch_size=patch_size,
in_channels=in_channels,
embed_dim=embed_dim,
depth=depth,
n_heads=n_heads,
output_dim=output_dim
)
# 初始化文本编码器
self.text = TextTransformer(
vocab_size=vocab_size,
context_length=context_length,
embed_dim=transformer_width,
transformer_width=transformer_width,
transformer_heads=transformer_heads,
transformer_layers=transformer_layers,
output_dim=output_dim
)
# 初始化tokenizer
self.tokenizer = SimpleTokenizer(max_length=context_length)
# 特征投影层(可选,用于调整特征空间)
self.logit_scale = nn.Parameter(torch.ones([]) * math.log(1 / 0.07))
# 如果需要使用预训练权重
if pretrained:
self._load_pretrained_weights()
def _load_pretrained_weights(self):
"""加载预训练权重(这里作为示例,实际项目中需要实现具体逻辑)"""
# 这里可以实现加载预训练权重的逻辑
# 例如:使用torch.hub加载OpenAI的CLIP预训练权重
# 或者使用自己的预训练权重
pass
def encode_image(self, image):
"""将图像编码为特征向量"""
return self.visual(image)
def encode_text(self, text):
"""将文本编码为特征向量
参数:
- text: 可以是文本字符串列表或已经分词的token张量
"""
if isinstance(text[0], str):
# 如果输入是字符串列表,进行分词
tokens = self.tokenizer.tokenize(text)
else:
# 否则假定输入已经是token张量
tokens = text
return self.text(tokens)
def forward(self, image=None, text=None):
"""前向传播,返回特征
参数:
- image: 可选,输入图像
- text: 可选,输入文本或token
返回:
- 如果只提供图像:归一化的图像特征
- 如果只提供文本:归一化的文本特征
- 如果都提供:(图像特征, 文本特征, logit_scale)
"""
if image is not None and text is None:
# 只编码图像
image_features = self.encode_image(image)
return image_features
elif text is not None and image is None:
# 只编码文本
text_features = self.encode_text(text)
return text_features
elif image is not None and text is not None:
# 同时编码图像和文本
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# 返回特征和logit_scale,用于计算相似度
return image_features, text_features, self.logit_scale.exp()
else:
raise ValueError("必须提供image或text参数之一")讲解
class CLIPModel(nn.Module):
"""CLIP模型,结合视觉和文本编码器"""
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
embed_dim=768,
depth=12,
n_heads=12,
output_dim=512,
vocab_size=49408,
context_length=77,
transformer_width=512,
transformer_heads=8,
transformer_layers=12,
pretrained=False
):
super().__init__()视觉编码器相关参数:
CLIP 模型的一个核心部分是一个视觉编码器,是一个 Vision Transformer (ViT)。这部分参数就是用来定义这个 ViT 的结构。我们上文以及定义过VIT模,这里不过多赘述。
img_size=224:含义: 输入图像的尺寸。这里假设输入图像是正方形的,高度和宽度都是 224 像素。这是很多计算机视觉模型常用的标准尺寸。
patch_size=16:含义: 图像块 (Patch) 的尺寸。Vision Transformer 的工作原理不是直接处理整个图片,而是先把图片切成一个个小方块 (patch),然后把这些小方块当作单词一样来处理。这里指定了每个小方块的大小是 16x16 像素。对于一个 224x224 的图像,它会被切成 (224/16) x (224/16) = 14 x 14 = 196 个图像块。
in_channels=3:图像通道数(RGB)对于标准的彩色 (RGB) 图像,这个值就是 3
embed_dim=768:嵌入维度 (Embedding Dimension)。每个 16x16 的图像块会被转换 (嵌入) 成一个长度为 768 的向量 (一维数组)。这个向量就是 Transformer 模型真正处理的单元。这个维度越高,通常意味着模型能表示的特征信息越丰富。
depth=12:Transformer 的深度,也就是 Transformer Block 的层数。可以理解为神经网络的层数。层数越深,模型从数据中提取抽象特征的能力就越强。
n_heads=12:多头注意力机制 (Multi-Head Attention) 中的 "头" 的数量。注意力机制是 Transformer 的核心。多头意味着模型可以同时从不同的表示子空间关注信息,从而捕捉到更丰富的特征关系。
文本编码器 (Text Encoder) 相关参数
CLIP 模型的另一核心部分是一个文本编码器,它是一个标准的 Transformer 模型。
vocab_size=49408:词汇表大小 (Vocabulary Size)。这代表模型能认识的独一无二的单词 (或称为 token) 的总数量。任何输入的文本都会先被转换成这个词汇表中的 ID。
context_length=77:上下文长度。这定义了模型一次能处理的文本序列的最大长度。如果输入的文本超过 77 个 token,它会被截断;如果不足 77 个,则会用特殊的填充符补齐,上文关于文本编码与分词器已经具体讲解过。
transformer_width=512:文本 Transformer 的宽度,也就是它的嵌入维度。类似于视觉部分的 embed_dim,每个单词 (token) 都会被转换成一个长度为 512 的向量
transformer_heads=8:含义: 文本 Transformer 中的多头注意力头数
transformer_layers=12:文本 Transformer 的层数。
共享/输出参数
output_dim=512:最终输出特征的维度。无论是视觉编码器处理完一张图片,还是文本编码器处理完一段文字,它们最终都会生成一个长度为 512 的特征向量。
核心思想: CLIP 的关键就在于,它将图像和文本映射到 同一个 特征空间中。这个 512 维的空间就是那个共享空间。在这个空间里,内容相似的图片和文字的特征向量在方向上会非常接近。
初始化:
# 初始化视觉编码器 (Vision Transformer)
self.visual = VisionTransformer(
img_size=img_size, # 输入图像尺寸(默认224x224)
patch_size=patch_size, # 图像分块大小(默认16x16)
in_channels=in_channels, # 输入通道数(RGB图像为3)
embed_dim=embed_dim, # 嵌入维度(默认768)
depth=depth, # Transformer编码器层数(默认12层)
n_heads=n_heads, # 多头注意力头数(默认12头)
output_dim=output_dim # 最终输出特征维度(默认512)
)# 初始化文本编码器
self.text = TextTransformer(
vocab_size=vocab_size, # 词表大小(默认49408)
context_length=context_length, # 文本最大长度(默认77个token)
embed_dim=transformer_width, # 词嵌入维度(默认512)
transformer_width=transformer_width, # Transformer隐藏层维度(默认512)
transformer_heads=transformer_heads, # 注意力头数(默认8头)
transformer_layers=transformer_layers, # Transformer层数(默认12层)
output_dim=output_dim # 最终输出特征维度(默认512)
)# 初始化tokenizer
self.tokenizer = SimpleTokenizer(max_length=context_length)# 特征投影层(可选,用于调整特征空间)
self.logit_scale = nn.Parameter(torch.ones([]) * math.log(1 / 0.07))它的作用是什么? 当模型计算出图像特征向量和文本特征向量后,会通过计算它们之间的余弦相似度来判断匹配程度。logit_scale 是一个可学习的参数,它会乘以这个余弦相似度得分。你可以把它理解成一个 “温度” 参数的对数,用来 缩放相似度得分的范围。一个合适的 logit_scale 可以让模型在训练时更快更好地收敛,有效地区分正负样本。
def _load_pretrained_weights(self):
"""加载预训练权重(这里作为示例,实际项目中需要实现具体逻辑)"""
# 这里可以实现加载预训练权重的逻辑
# 例如:使用torch.hub加载OpenAI的CLIP预训练权重
# 或者使用自己的预训练权重
pass
def encode_image(self, image):
"""将图像编码为特征向量"""
return self.visual(image)
def encode_text(self, text):
"""将文本编码为特征向量
参数:
- text: 可以是文本字符串列表或已经分词的token张量
"""
if isinstance(text[0], str):
# 如果输入是字符串列表,进行分词
tokens = self.tokenizer.tokenize(text)
else:
# 否则假定输入已经是token张量
tokens = text
return self.text(tokens)在一个真实的项目中,pass 会被替换为类似下面的逻辑:
确定权重的来源,可能是一个网址 (URL) 或者一个本地文件路径 (比如 "my_clip_weights.pt")。
使用 PyTorch 的 torch.load() 函数来读取权重文件。
使用 self.load_state_dict() 这个 nn.Module 自带的方法,将读取到的权重加载到模型的相应层中。
def encode_image(self, image):
"""将图像编码为特征向量"""
return self.visual(image)这个方法非常直接,它的功能就是接收一张(或一批)图像,并把它转换成一个数字特征向量。这个特征向量可以被认为是这张图像在高维空间中的一个 “坐标”,它浓缩了图像的核心内容。
参数 image: 这里的 image 不是一个普通的图片文件(如 jpg, png),而是一个经过了预处理的 PyTorch 张量 (Tensor)。预处理通常包括
调整图像尺寸到模型要求的大小(例如 224x224)。
将像素值从 0-255 归一化到特定的范围。
转换成 (批量大小, 通道数, 高度, 宽度) 的格式。
return self.visual(image):
self.visual 是我们在 __init__ 中创建的那个 VisionTransformer 实例
所以,这行代码的本质是:“调用视觉编码器的 forward 功能,让它处理输入的 image 张量。”
self.visual 内部会完成所有复杂的计算(图像分块、嵌入、多层 Transformer 计算等),最后返回一个代表图像特征的向量。
简单来说,这个方法是 CLIPModel 对外提供的 “图像理解” 接口。你给它一张处理好的图片,它还你一个浓缩了图片信息的数学向量。
def encode_text(self, text):
"""将文本编码为特征向量
参数:
- text: 可以是文本字符串列表或已经分词的token张量
"""
if isinstance(text[0], str):
# 如果输入是字符串列表,进行分词
tokens = self.tokenizer.tokenize(text)
else:
# 否则假定输入已经是token张量
tokens = text
return self.text(tokens)与 encode_image 类似,这个方法的功能是接收一段(或一批)文本,并将其转换为一个数字特征向量。这个向量浓缩了文本的语义信息。
灵活的参数 text: 这个方法设计得非常方便。它能接受两种类型的输入:
字符串列表: 比如 ["一张猫的照片", "一条狗在奔跑"]。
已经分词好的 token 张量: 一个二维的数字张量,每一行代表一句话
和 encode_image 的原理完全一样。它调用文本编码器 self.text 的 forward 方法,让它处理 tokens 张量,完成所有 Transformer 相关的计算,最终返回一个代表文本语义的特征向量。
简单来说,这个方法是 CLIPModel 对外提供的 “文本理解” 接口。你给它一句话,它还你一个浓缩了这句话含义的数学向量。
前向传播:
def forward(self, image=None, text=None):
"""前向传播,返回特征
参数:
- image: 可选,输入图像
- text: 可选,输入文本或token
返回:
- 如果只提供图像:归一化的图像特征
- 如果只提供文本:归一化的文本特征
- 如果都提供:(图像特征, 文本特征, logit_scale)
"""
if image is not None and text is None:
# 只编码图像
image_features = self.encode_image(image)
return image_features
elif text is not None and image is None:
# 只编码文本
text_features = self.encode_text(text)
return text_features
elif image is not None and text is not None:
# 同时编码图像和文本
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# 返回特征和logit_scale,用于计算相似度
return image_features, text_features, self.logit_scale.exp()
else:
raise ValueError("必须提供image或text参数之一")情况一:只提供图像:
if image is not None and text is None:
# 只编码图像
image_features = self.encode_image(image)
return image_featuresimage_features = self.encode_image(image): 如果条件成立,它就会调用我们上一问中讲过的 self.encode_image() 方法。这个方法会负责将输入的图像转换成特征向量。
return image_features: 然后,它直接返回这个计算出来的图像特征向量。
用途: 这种模式非常适合于 “以图搜图” 或者需要单独提取图片特征的场景。
情况二:只提供文本
elif text is not None and image is None:
# 只编码文本
text_features = self.encode_text(text)
return text_features调用 self.encode_text() 方法,将输入的文本(无论是字符串还是 token)转换成特征向量。
return text_features: 直接返回计算出的文本特征向量。
用途: 这种模式适合于 “以文搜文”、文本分类等只需要单独处理文本的场景。
情况三:同时提供图像和文本
elif image is not None and text is not None:
# 同时编码图像和文本
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# 返回特征和logit_scale,用于计算相似度
return image_features, text_features, self.logit_scale.exp()它会分别调用 self.encode_image() 和 self.encode_text(),得到图像和文本的特征向量。
它返回了一个包含 三个元素 的元组 (tuple):
image_features: 图像特征向量
text_features: 文本特征向量
self.logit_scale.exp(): 我们在 __init__ 中定义了 self.logit_scale,它的初始值是 log(1/0.07)。.exp() 是指数函数 (ex),是对数函数 (log) 的逆运算。所以 exp(log(x)) = x。这里的 .exp() 操作就是将 logit_scale 从对数空间转换回其原始的数值空间。这个值是计算对比损失 (Contrastive Loss) 时必需的缩放因子,用于调整相似度得分的分布。
4.CLIP模型损失计算
class CLIPLoss(nn.Module):
"""CLIP对比学习损失函数"""
def __init__(self, temperature=0.07):
super().__init__()
self.temperature = temperature
self.cross_entropy = nn.CrossEntropyLoss()
def forward(self, image_features, text_features):
"""
计算图像和文本特征之间的对比学习损失
参数:
- image_features: 形状为 [batch_size, output_dim] 的图像特征
- text_features: 形状为 [batch_size, output_dim] 的文本特征
返回:
- 对比学习损失
"""
# 计算logits矩阵
logits = (image_features @ text_features.T) / self.temperature
# 标签是对角线元素(即每个图像与对应文本的匹配)
labels = torch.arange(logits.shape[0], device=logits.device)
# 计算图像到文本的损失
loss_i2t = self.cross_entropy(logits, labels)
# 计算文本到图像的损失
loss_t2i = self.cross_entropy(logits.T, labels)
# 总损失是两个方向损失的平均
total_loss = (loss_i2t + loss_t2i) / 2.0
return total_loss
这里我们并没有自己从头实现交叉熵损失函数,而是直接创建了一个 PyTorch 内置的 nn.CrossEntropyLoss 实例。
交叉熵损失 (Cross-Entropy Loss) 是分类任务中最常用的损失函数。它的基本思想是:如果模型对正确类别的预测概率很高,损失就小;如果预测概率很低,损失就大。
CLIP 很巧妙地将 “图文匹配” 这个问题转换成了一个 “分类” 问题,我们接下来会在 forward 方法中看到具体是如何做的。
第 1 步:计算 logits 矩阵(相似度得分矩阵)
logits = (image_features @ text_features.T) / self.temperature这是整个损失计算的核心,我们来分解它:
假设我们有一个批次 (batch) 的数据,包含 N 张图片和 N 段与之对应的文本。
image_features 的形状是 [N, D],其中 N 是批量大小,D 是特征维度(比如 512)。
text_features 的形状也是 [N, D]
text_features.T: .T 是转置操作,将 text_features 的形状从 [N, D] 变为 [D, N]
image_features @ text_features.T: 一个 [N, D] 的矩阵乘以一个 [D, N] 的矩阵,结果是一个 [N, N] 的大矩阵。
它是一个 相似度矩阵。矩阵中第 i 行、第 j 列的那个数值,代表的是第 i 张图像的特征与第 j 段文本的特征之间的点积相似度。
我们期望在这个矩阵中,对角线 上的值(即 (image_i, text_i) 的相似度)最大,而所有非对角线上的值(即 (image_i, text_j) 且 i != j 的相似度)都尽可能小。
/ self.temperature: 最后,将整个相似度矩阵中的每个元素都除以温度 temperature。这一步用于缩放相似度得分,控制概率分布的形状。
第 2 步:创建 labels(正确答案)
labels = torch.arange(logits.shape[0], device=logits.device)logits.shape[0] 就是批量大小 N
torch.arange(N) 会创建一个从 0 到 N-1 的整数序列,即 [0, 1, 2, ..., N-1]
为什么这是正确答案?
交叉熵损失函数 nn.CrossEntropyLoss(logits, labels) 拿到 logits 预测和 labels 真实标签后,就会去比较:
-
对于第一行
logits,它会鼓励索引0位置的得分变高,其他位置的得分变低。 -
对于第二行
logits,它会鼓励索引1位置的得分变高,其他位置的得分变低。 -
...以此类推。
# 计算图像到文本的损失
loss_i2t = self.cross_entropy(logits, labels)
# 计算文本到图像的损失
loss_t2i = self.cross_entropy(logits.T, labels)loss_i2t (image-to-text loss):
我们将 logits 矩阵和 labels 传给交叉熵损失函数。
这可以理解为:对于每一张图片(logits 的每一行),把它看作一次分类任务的预测,目标是从 N 个文本中选出正确的那个。
loss_t2i (text-to-image loss):
这里我们传入的是 logits.T(转置后的相似度矩阵)。在转置后的矩阵中,每一行代表一个文本,每一列代表一张图片。
这可以理解为:对于每一段文本(logits.T 的每一行),把它看作一次分类任务的预测,目标是从 N 张图片中选出正确的那张。
计算两个方向的损失是一种 对称 设计,它确保了模型不仅要学会用图片找到对应的文字,也要学会用文字找到对应的图片。
total_loss = (loss_i2t + loss_t2i) / 2.0
return total_loss最后,将两个方向的损失加起来再取平均,得到最终的总损失。
5.加载工厂函数
def load_clip_model(model_name="clip_vit_base_16", pretrained=False):
"""加载CLIP模型的工厂函数"""
if model_name == "clip_vit_base_16":
model = CLIPModel(
img_size=224,
patch_size=16,
embed_dim=768,
depth=12,
n_heads=12,
output_dim=512,
vocab_size=49408,
context_length=77,
transformer_width=512,
transformer_heads=8,
transformer_layers=12,
pretrained=pretrained
)
elif model_name == "clip_vit_large_14":
model = CLIPModel(
img_size=224,
patch_size=14,
embed_dim=1024,
depth=24,
n_heads=16,
output_dim=768,
vocab_size=49408,
context_length=77,
transformer_width=768,
transformer_heads=12,
transformer_layers=12,
pretrained=pretrained
)
else:
raise ValueError(f"不支持的模型名称: {model_name}")
return model1. 什么是“工厂函数” (Factory Function)?
在编程中,“工厂”是一种设计模式。想象一个真实的工厂:你不需要知道制造一辆汽车的所有复杂细节(焊接、喷漆、组装引擎),你只需要告诉工厂你想要什么型号的车(比如 “轿车” 或 “SUV”),工厂就会把一辆完整的车交给你。
这个 load_clip_model 函数就是这样一个 “模型工厂”。它的作用是:
隐藏复杂性:用户不需要记住或手动输入 CLIPModel 所需的一长串超参数(如 embed_dim=768, depth=12 等)。
提供简洁的接口:用户只需要提供一个简单的模型名称字符串(如 "clip_vit_base_16"),这个工厂函数就会负责用正确的参数配置来创建出对应的模型。
便于管理:如果未来要支持更多新模型,只需要在这个函数里增加新的 elif 分支即可,而调用它的代码无需改动。
如何使用它:
# 加载一个基础版的模型,不带预训练权重(用于从头训练)
model_base_scratch = load_clip_model(model_name="clip_vit_base_16", pretrained=False)
# 加载一个大型版的模型,并加载预训练权重(用于推理或微调)
model_large_pretrained = load_clip_model(model_name="clip_vit_large_14", pretrained=True)
# 使用默认参数,加载基础版的模型,不带预训练权重
default_model = load_clip_model()现在最难的已经被我们搞定了,接下来就是一些简单的数据处理模块了。
图像数据处理模块代码解析
- 主要组件:
- ImageDataset:自定义数据集类,用于加载和预处理图像
- get_default_transform:获取默认的图像转换函数
- preprocess_image:处理单张图像的函数
- extract_features:从数据集提取图像特征的函数
- prepare_dataset:准备数据集和数据加载器
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import os
from PIL import Image
import numpy as np
from tqdm import tqdm
class ImageDataset(Dataset):
"""图像数据集,用于加载图像和预处理"""
def __init__(self, image_dir, transform=None):
"""
初始化图像数据集
参数:
- image_dir: 包含图像的目录路径
- transform: 图像转换函数
"""
self.image_dir = image_dir
# 支持的图像格式
self.img_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.webp']
# 如果没有提供转换函数,则使用默认的CLIP图像预处理
if transform is None:
self.transform = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])
else:
self.transform = transform
# 收集所有图像文件
self.image_paths = []
self._collect_images(image_dir)
def _collect_images(self, directory):
"""收集目录中的所有图像文件"""
for root, _, files in os.walk(directory):
for file in files:
ext = os.path.splitext(file)[1].lower()
if ext in self.img_extensions:
self.image_paths.append(os.path.join(root, file))
def __len__(self):
"""返回数据集大小"""
return len(self.image_paths)
def __getitem__(self, idx):
"""获取数据集中的一个样本"""
img_path = self.image_paths[idx]
# 加载图像
try:
image = Image.open(img_path).convert('RGB')
# 应用转换
if self.transform:
image = self.transform(image)
return {
'image': image,
'path': img_path,
'filename': os.path.basename(img_path)
}
except Exception as e:
print(f"无法加载图像 {img_path}: {e}")
# 返回一个随机的占位图像
placeholder = torch.randn(3, 224, 224)
return {
'image': placeholder,
'path': img_path,
'filename': os.path.basename(img_path)
}
def get_default_transform():
"""获取默认的CLIP图像预处理"""
return transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])
def preprocess_image(image_path, transform=None):
"""处理单张图像"""
if transform is None:
transform = get_default_transform()
image = Image.open(image_path).convert('RGB')
image = transform(image)
return image.unsqueeze(0) # 添加批处理维度
def extract_features(model, data_loader, device):
"""从数据集中提取图像特征"""
model.eval()
features = []
paths = []
filenames = []
with torch.no_grad():
for batch in tqdm(data_loader, desc="提取特征"):
images = batch['image'].to(device)
batch_features = model(images)
# 将特征移到CPU并转换为NumPy数组
batch_features = batch_features.cpu().numpy()
features.append(batch_features)
# 保存路径和文件名
paths.extend(batch['path'])
filenames.extend(batch['filename'])
# 将所有特征合并为一个数组
features = np.vstack(features)
return features, paths, filenames
def prepare_dataset(image_dir, batch_size=32, transform=None, shuffle=False, num_workers=4):
"""准备数据集和数据加载器"""
# 创建数据集
dataset = ImageDataset(image_dir, transform)
# 创建数据加载器
data_loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers
)
return dataset, data_loaderImageDataset 类 (核心数据封装)
这是整个脚本的核心。在 PyTorch 中,我们需要创建一个自定义类来表示我们的数据集,并且这个类必须继承自 torch.utils.data.Dataset。一个自定义的 Dataset 类必须实现三个特殊的方法:__init__, __len__ 和 __getitem__。
__init__(self, image_dir, transform=None) (构造函数)
def __init__(self, image_dir, transform=None):
"""
初始化图像数据集
参数:
- image_dir: 包含图像的目录路径
- transform: 图像转换函数
"""
self.image_dir = image_dir
# 支持的图像格式
self.img_extensions = ['.jpg', '.jpeg', '.png', '.bmp', '.webp']
# 如果没有提供转换函数,则使用默认的CLIP图像预处理
if transform is None:
self.transform = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])
else:
self.transform = transform
# 收集所有图像文件
self.image_paths = []
self._collect_images(image_dir)这个方法在创建 ImageDataset 实例时被调用,负责进行初始化工作。
参数:
image_dir: 告诉数据集去哪个文件夹里寻找图片。
transform: 一个可选参数,用于接收一个图像预处理流程。
内部逻辑:定义默认 transform: 如果用户没有提供自己的 transform,代码会创建一个默认的。这个默认流程是 CLIP 模型标准的预处理步骤:
transforms.Resize(224, ...): 将图像的短边缩放到 224 像素。BICUBIC 是一种高质量的插值方法。
transforms.CenterCrop(224): 从图像中心裁剪出一个 224x224 大小的区域。这确保了所有输入模型的图像尺寸都完全一致。
transforms.ToTensor(): 这是一个关键步骤,它将 PIL 图像(像素值范围 0-255)转换成 PyTorch 张量(Tensor),并将像素值缩放到 0.0-1.0 之间。同时,它还会调整维度的顺序,从 (H, W, C) 变为 (C, H, W)。
transforms.Normalize(...): 用给定的均值 (mean) 和标准差 (std) 对张量进行归一化。这些特定的数值是 CLIP 模型在训练时所用的整个数据集的均值和标准差。归一化可以使模型训练更稳定、收敛更快。
收集图像路径: self._collect_images(image_dir) 调用一个内部辅助方法,去遍历 image_dir 文件夹及其所有子文件夹,找到所有支持格式的图片,并将它们的完整路径存入 self.image_paths 列表中。
_collect_images(self, directory) (内部辅助方法)
def _collect_images(self, directory):
"""收集目录中的所有图像文件"""
for root, _, files in os.walk(directory):
for file in files:
ext = os.path.splitext(file)[1].lower()
if ext in self.img_extensions:
self.image_paths.append(os.path.join(root, file))os.walk(directory): 这是一个非常强大的工具,它会递归地遍历一个目录下的所有子目录和文件。
循环内部的逻辑是检查每个文件的扩展名(.jpg, .png 等),如果是支持的图片格式,就将其完整路径添加到 self.image_paths 列表中。
__len__(self) (获取数据集大小)
这个方法必须返回数据集中的样本总数。
它的实现非常简单:return len(self.image_paths),直接返回收集到的图片路径列表的长度。DataLoader 会使用这个方法来知道总共有多少数据。
__getitem__(self, idx) (获取单个样本)
def __getitem__(self, idx):
"""获取数据集中的一个样本"""
img_path = self.image_paths[idx]
# 加载图像
try:
image = Image.open(img_path).convert('RGB')
# 应用转换
if self.transform:
image = self.transform(image)
return {
'image': image,
'path': img_path,
'filename': os.path.basename(img_path)
}
except Exception as e:
print(f"无法加载图像 {img_path}: {e}")
# 返回一个随机的占位图像
placeholder = torch.randn(3, 224, 224)
return {
'image': placeholder,
'path': img_path,
'filename': os.path.basename(img_path)
}这是 Dataset 最核心的方法。DataLoader 在需要数据时,会传入一个索引 idx (比如 0, 1, 2, ...),这个方法则必须返回对应索引的 一个 数据样本。
内部逻辑:
根据索引 idx 从 self.image_paths 列表中获取对应的图片文件路径。
try...except 错误处理: 因为在处理大量图片时,总可能遇到一些损坏的文件。try 块尝试正常加载和处理图片。
Image.open(img_path).convert('RGB'): 使用 Pillow 打开图片文件,并用 .convert('RGB') 确保图片是标准的 3 通道彩色图像(有些图片可能是灰度图或带透明通道的 RGBA 图)。
image = self.transform(image): 应用在 __init__ 中定义好的预处理流程,将图片转换成符合模型输入的张量。
返回字典: 将处理好的 image 张量连同它的原始路径 path 和文件名 filename 一起打包成一个字典返回。使用字典可以使数据结构更清晰。
except 块: 如果 try 块中的代码出错(比如图片文件损坏无法打开),程序不会崩溃,而是会打印一条错误信息,并返回一个随机生成的、尺寸正确的占位符张量。这确保了即使有坏数据,整个处理流程也能继续进行下去。
辅助函数 (工具集)
def get_default_transform():
"""获取默认的CLIP图像预处理"""
return transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])这是一个简单的辅助函数,它的唯一作用就是返回上面讲过的那个默认的 CLIP 图像预处理流程。这使得代码更模块化,易于复用。
def preprocess_image(image_path, transform=None):
"""处理单张图像"""
if transform is None:
transform = get_default_transform()
image = Image.open(image_path).convert('RGB')
image = transform(image)
return image.unsqueeze(0) # 添加批处理维度这是一个用于处理 单张 图片的便捷工具。它接收一个文件路径,然后完成打开、转换、预处理的全过程。
return image.unsqueeze(0):
这是关键一步。神经网络模型通常期望接收一个 批次 (batch) 的数据,而不是单张图片。批次数据的维度通常是 (N, C, H, W),其中 N 是批量大小。unsqueeze(0) 会在张量的最前面增加一个维度,将单张图片的张量 (C, H, W) 变为 (1, C, H, W),即一个批量大小为 1 的批次。
def extract_features(model, data_loader, device):
"""从数据集中提取图像特征"""
model.eval()
features = []
paths = []
filenames = []
with torch.no_grad():
for batch in tqdm(data_loader, desc="提取特征"):
images = batch['image'].to(device)
batch_features = model(images)
# 将特征移到CPU并转换为NumPy数组
batch_features = batch_features.cpu().numpy()
features.append(batch_features)
# 保存路径和文件名
paths.extend(batch['path'])
filenames.extend(batch['filename'])
# 将所有特征合并为一个数组
features = np.vstack(features)
return features, paths, filenames这是执行 批量推理 的核心函数,用于从整个数据集中提取所有图片的特征。
model.eval(): 非常重要。这个方法会告诉模型现在是 “评估模式”。在此模式下,模型会关闭 Dropout 和 Batch Normalization 等只在训练时使用的层,确保推理结果是确定和一致的。
with torch.no_grad(): 非常重要。这个上下文管理器会告诉 PyTorch 在接下来的代码块中不要计算梯度。因为在推理时我们不需要反向传播和更新权重,关闭梯度计算可以极大地 节省显存 和 加快计算速度。
循环: for batch in tqdm(data_loader, ...)
tqdm(data_loader) 会自动为数据加载过程包上一个进度条。
data_loader 会自动地、批量地从 ImageDataset 中获取数据。batch 就是 __getitem__ 返回的那个字典,但现在 image 等字段的值都是一个批次的数据。
images = batch['image'].to(device): 将一个批次的图片张量移动到指定的计算设备上(比如 GPU)。
batch_features = model(images): 执行推理!将图片数据送入模型,得到特征向量。
.cpu().numpy(): 将计算结果(通常在 GPU 上)移回 CPU,并转换成 NumPy 数组,方便后续处理。
np.vstack(features): 在循环结束后,features 是一个包含了多个批次特征的列表(比如 [array1, array2, ...])。np.vstack 会将这些数组垂直堆叠起来,形成一个大的、完整的 NumPy 数组,其中包含了数据集中所有图片的特征。
def prepare_dataset(image_dir, batch_size=32, transform=None, shuffle=False, num_workers=4):
"""准备数据集和数据加载器"""
# 创建数据集
dataset = ImageDataset(image_dir, transform)
# 创建数据加载器
data_loader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=num_workers
)
return dataset, data_loader这是一个高级封装函数,目的是简化 “准备数据” 这一常用步骤。
它内部做了两件事:
dataset = ImageDataset(image_dir, transform): 创建我们自定义的数据集实例。
data_loader = DataLoader(...): 用 DataLoader 将 dataset 包装起来。
DataLoader 的参数:
dataset: 要加载的数据集。
batch_size: 每个批次加载多少个样本。
shuffle: 是否在每个周期 (epoch) 开始时打乱数据顺序。训练时通常设为 True,推理时设为 False。
num_workers: 使用多少个子进程来预加载数据。设置一个大于 0 的值(如 4 或 8)可以大大加快数据读取速度,尤其是在 CPU 成为瓶颈时。
这个函数让只需一行代码就能得到一个配置好的、可以高效读取数据的数据加载器。
图像处理相关功能
主要组件:
load_and_preprocess_image:加载并预处理单张图像
denormalize_image:将归一化的图像转回可视化格式
visualize_query_and_results:可视化检索结果
save_visualization:保存可视化结果
import torch
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms
import os
def load_and_preprocess_image(image_path, transform=None):
"""
加载并预处理单张图像
参数:
- image_path: 图像路径
- transform: 图像转换函数,如果为None则使用默认转换
返回:
- 预处理后的图像张量,形状为 [1, C, H, W]
"""
if transform is None:
transform = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])
image = Image.open(image_path).convert('RGB')
image_tensor = transform(image).unsqueeze(0) # 添加批处理维度
return image_tensor
def denormalize_image(tensor):
"""
将归一化的图像张量转换回可视化的RGB图像
参数:
- tensor: 归一化的图像张量 [C, H, W]
返回:
- 反归一化后的RGB图像,形状为 [H, W, C]
"""
# CLIP模型的均值和标准差
mean = torch.tensor([0.48145466, 0.4578275, 0.40821073])
std = torch.tensor([0.26862954, 0.26130258, 0.27577711])
# 反归一化
tensor = tensor.clone()
for t, m, s in zip(tensor, mean, std):
t.mul_(s).add_(m)
# 将取值范围裁剪到 [0, 1]
tensor = torch.clamp(tensor, 0, 1)
# 转换为NumPy数组,并转换维度顺序从 [C, H, W] 到 [H, W, C]
image = tensor.permute(1, 2, 0).numpy()
return image
def visualize_query_and_results(query_image_path, result_paths, similarity_scores=None, figsize=(15, 10)):
"""
可视化查询图像和检索结果
参数:
- query_image_path: 查询图像路径
- result_paths: 检索结果图像路径列表
- similarity_scores: 相似度分数列表
- figsize: 图像大小
"""
# 计算子图数量
n_results = len(result_paths)
# 创建图像
fig, axes = plt.subplots(1, n_results + 1, figsize=figsize)
# 显示查询图像
query_img = Image.open(query_image_path).convert('RGB')
axes[0].imshow(query_img)
axes[0].set_title(f"查询图像\n{os.path.basename(query_image_path)}")
axes[0].axis('off')
# 显示检索结果
for i, path in enumerate(result_paths):
try:
img = Image.open(path).convert('RGB')
axes[i+1].imshow(img)
# 如果提供了相似度分数,则显示
if similarity_scores is not None:
title = f"结果 #{i+1}\n相似度: {similarity_scores[i]:.4f}\n{os.path.basename(path)}"
else:
title = f"结果 #{i+1}\n{os.path.basename(path)}"
axes[i+1].set_title(title)
axes[i+1].axis('off')
except Exception as e:
axes[i+1].text(0.5, 0.5, f"无法加载图像\n{str(e)}", ha='center', va='center')
axes[i+1].axis('off')
plt.tight_layout()
return fig
def save_visualization(fig, save_path):
"""
保存可视化结果
参数:
- fig: matplotlib图像对象
- save_path: 保存路径
"""
fig.savefig(save_path, bbox_inches='tight')
plt.close(fig)
return save_path讲解
函数 load_and_preprocess_image:加载并预处理图像
def load_and_preprocess_image(image_path, transform=None):
"""
加载并预处理单张图像
...
"""
if transform is None:
transform = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711])
])
image = Image.open(image_path).convert('RGB')
image_tensor = transform(image).unsqueeze(0) # 添加批处理维度
return image_tensor处理图像:
如果没有调用自定义的数据处理,执行以下流程:
1.首先将图像的短边调整到 224 像素。interpolation=transforms.InterpolationMode.BICUBIC 指定了使用双三次插值法进行缩放,这是一种高质量的图像缩放算法。大家记住就行。
2.从图像的中心裁剪出一个 224x224 像素的区域。这一步确保了所有输入图像的尺寸都是完全一致的。
3.将 PIL 图像(或 NumPy 数组)进行两个主要转换:
-
将像素值从
[0, 255]的范围转换到[0.0, 1.0]的范围。 -
将图像的维度顺序从
[H, W, C](高度, 宽度, 通道数) 调整为[C, H, W](通道数, 高度, 宽度),这是 PyTorch 模型的标准输入格式。
4.transforms.Normalize(...): 对图像进行归一化。这个操作会从每个通道的像素值中减去均值 (mean),然后再除以标准差 (std)。公式是 output = (input - mean) / std。归一化可以使模型训练得更快、更稳定。这里的均值和标准差是 OpenAI 的 CLIP 模型在训练时所使用的数据集的统计值,表明这个预处理流程是为 CLIP 模型量身定制的。
5.image = Image.open(image_path).convert('RGB'): 使用 PIL 的 Image.open 打开指定路径 (image_path) 的图像。.convert('RGB') 确保图像是标准的红绿蓝三通道彩色图像,因为有些图像可能是灰度图或者带有透明通道(RGBA)。
6.transform(image): 将上面定义好的一系列变换操作应用到加载的图像上,得到一个形状为 [C, H, W] (即 [3, 224, 224]) 的张量。.unsqueeze(0): 在张量的第 0 个维度(最前面)增加一个维度。这被称为“添加批处理维度 (batch dimension)”。张量的形状从 [C, H, W] 变为 [1, C, H, W]。深度学习模型通常期望接收一批 (a batch of) 数据进行处理,即使我们只处理一张图片,也要把它构造成一个大小为 1 的批次。
函数 denormalize_image:反归一化图像
def denormalize_image(tensor):
"""
将归一化的图像张量转换回可视化的RGB图像
...
"""
mean = torch.tensor(...)
std = torch.tensor(...)
tensor = tensor.clone()
for t, m, s in zip(tensor, mean, std):
t.mul_(s).add_(m)
tensor = torch.clamp(tensor, 0, 1)
image = tensor.permute(1, 2, 0).numpy()
return image这个函数是 load_and_preprocess_image 中归一化步骤的逆操作。它将一个经过归一化的张量还原成一张可以用 Matplotlib 显示的、像素值在 [0, 1] 范围内的正常图像。
mean = torch.tensor(...) 和 std = torch.tensor(...): 定义了与预处理时完全相同的均值和标准差。
tensor = tensor.clone(): 创建输入张量的一个副本。这是一个好习惯,可以避免在函数内部修改原始传入的张量。
for t, m, s in zip(tensor, mean, std):: 这是一个循环,它会同时遍历张量的三个通道 (t)、均值的三个值 (m) 和标准差的三个值 (s)。
t.mul_(s).add_(m): 这是反归一化的核心。对于每个通道,执行与归一化相反的操作:先乘以标准差 (mul_),再加上均值 (add_)。注意带下划线的操作 mul_ 和 add_ 表示“原地操作”,即直接修改张量 t 的值。
tensor = torch.clamp(tensor, 0, 1): 由于浮点数计算可能存在的微小误差,反归一化后的像素值可能会略微超出 [0, 1] 的范围。torch.clamp 函数将所有小于 0 的值设为 0,所有大于 1 的值设为 1,确保像素值在有效范围内。
image = tensor.permute(1, 2, 0).numpy():
.permute(1, 2, 0): 将张量的维度顺序从 [C, H, W] 重新排列为 [H, W, C]。这是 Matplotlib 和 NumPy 显示图像时所期望的维度顺序。
.numpy(): 将 PyTorch 张量转换为 NumPy 数组,这是 Matplotlib imshow 函数可以直接处理的格式。
函数 visualize_query_and_results:可视化查询结果
def visualize_query_and_results(query_image_path, result_paths, similarity_scores=None, figsize=(15, 10)):
"""
可视化查询图像和检索结果
...
"""
n_results = len(result_paths)
fig, axes = plt.subplots(1, n_results + 1, figsize=figsize)
# 显示查询图像
query_img = Image.open(query_image_path).convert('RGB')
axes[0].imshow(query_img)
axes[0].set_title(...)
axes[0].axis('off')
# 显示检索结果
for i, path in enumerate(result_paths):
try:
img = Image.open(path).convert('RGB')
axes[i+1].imshow(img)
# ... 设置标题 ...
axes[i+1].axis('off')
except Exception as e:
# ... 处理无法加载图像的错误 ...
plt.tight_layout()
return fig功能:这个函数用于创建一个包含查询图像和一系列检索结果图像的可视化图表。
fig, axes = plt.subplots(1, n_results + 1, figsize=figsize)-
plt.subplots()创建图表和一组子图 -
参数
1表示只有一行 -
参数
n_results + 1表示列数(查询图像1列 + 结果图像n列) -
figsize=(15, 10)设置整个图表的大小 -
fig是整个图表对象 -
axes是一个包含所有子图的数组
query_img = Image.open(query_image_path).convert('RGB')
axes[0].imshow(query_img)
axes[0].set_title(f"查询图像\n{os.path.basename(query_image_path)}")
axes[0].axis('off')-
使用 PIL 的
Image.open()打开查询图像 -
.convert('RGB')确保图像是 RGB 格式 -
axes[0]表示第一个子图(位置0) -
imshow()在子图上显示图像 -
set_title()设置子图标题:显示"查询图像"和文件名 -
axis('off')关闭坐标轴显示
for i, path in enumerate(result_paths):
try:
img = Image.open(path).convert('RGB')
axes[i+1].imshow(img)
# 设置标题(包含相似度分数)
if similarity_scores is not None:
title = f"结果 #{i+1}\n相似度: {similarity_scores[i]:.4f}\n{os.path.basename(path)}"
else:
title = f"结果 #{i+1}\n{os.path.basename(path)}"
axes[i+1].set_title(title)
axes[i+1].axis('off')
except Exception as e:
axes[i+1].text(0.5, 0.5, f"无法加载图像\n{str(e)}", ha='center', va='center')
axes[i+1].axis('off')-
遍历所有结果图像路径
-
try-except块处理可能的图像加载错误 -
打开并显示每个结果图像(位置从1开始)
-
根据是否提供相似度分数设置不同的标题:
-
有分数:显示结果序号、相似度分数和文件名
-
无分数:只显示结果序号和文件名
-
-
如果加载失败,在子图上显示错误信息
索引和检索相关功能
import numpy as np
import os
import json
from sklearn.metrics.pairwise import cosine_similarity
import pickle
import time
class SimpleIndex:
"""简单的向量索引实现,用于图像检索"""
def __init__(self):
"""初始化索引"""
self.features = None # 特征矩阵,形状为 [n_images, feature_dim]
self.image_paths = [] # 图像路径列表
self.image_filenames = [] # 图像文件名列表
def add_items(self, features, image_paths, image_filenames):
"""
向索引添加项目
参数:
- features: 特征矩阵,形状为 [n_images, feature_dim]
- image_paths: 图像路径列表
- image_filenames: 图像文件名列表
"""
if self.features is None:
self.features = features
else:
self.features = np.vstack([self.features, features])
self.image_paths.extend(image_paths)
self.image_filenames.extend(image_filenames)
def search(self, query_feature, k=5):
"""
搜索最相似的图像
参数:
- query_feature: 查询特征向量,形状为 [1, feature_dim]
- k: 返回的结果数量
返回:
- indices: 最相似图像的索引
- distances: 相似度分数
- paths: 图像路径
- filenames: 图像文件名
"""
# 计算余弦相似度
similarity_scores = cosine_similarity(query_feature, self.features)[0]
# 获取前k个最相似图像的索引
top_indices = np.argsort(-similarity_scores)[:k]
# 获取相应的分数、路径和文件名
top_scores = similarity_scores[top_indices]
top_paths = [self.image_paths[i] for i in top_indices]
top_filenames = [self.image_filenames[i] for i in top_indices]
return top_indices, top_scores, top_paths, top_filenames
def save(self, save_dir):
"""
保存索引到磁盘
参数:
- save_dir: 保存目录
"""
os.makedirs(save_dir, exist_ok=True)
# 保存特征
features_path = os.path.join(save_dir, "features.npy")
np.save(features_path, self.features)
# 保存元数据
metadata = {
"image_paths": self.image_paths,
"image_filenames": self.image_filenames,
"feature_dim": self.features.shape[1] if self.features is not None else 0,
"n_images": len(self.image_paths),
"created_at": time.strftime("%Y-%m-%d %H:%M:%S")
}
metadata_path = os.path.join(save_dir, "metadata.json")
with open(metadata_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
# 返回保存的路径
return features_path, metadata_path
@classmethod
def load(cls, save_dir):
"""
从磁盘加载索引
参数:
- save_dir: 保存目录
返回:
- index: SimpleIndex实例
"""
# 加载特征
features_path = os.path.join(save_dir, "features.npy")
features = np.load(features_path)
# 加载元数据
metadata_path = os.path.join(save_dir, "metadata.json")
with open(metadata_path, 'r', encoding='utf-8') as f:
metadata = json.load(f)
# 创建索引
index = cls()
index.features = features
index.image_paths = metadata["image_paths"]
index.image_filenames = metadata["image_filenames"]
return index
class FaissIndex:
"""使用Faiss库实现的高效索引"""
def __init__(self, d=512, use_gpu=False):
"""
初始化Faiss索引
参数:
- d: 特征维度
- use_gpu: 是否使用GPU
"""
try:
import faiss
self.faiss_available = True
except ImportError:
print("警告: Faiss库不可用,将使用SimpleIndex作为后备")
self.faiss_available = False
self.simple_index = SimpleIndex()
return
self.d = d # 特征维度
self.use_gpu = use_gpu
# 创建索引
# 使用L2归一化 + 内积索引,等效于余弦相似度
self.index = faiss.IndexFlatIP(d)
# 如果使用GPU
if use_gpu:
try:
# 检查是否有GPU
gpu_resources = faiss.StandardGpuResources()
self.index = faiss.index_cpu_to_gpu(gpu_resources, 0, self.index)
print("使用GPU索引")
except Exception as e:
print(f"无法使用GPU: {e}")
self.use_gpu = False
self.image_paths = [] # 图像路径列表
self.image_filenames = [] # 图像文件名列表
def add_items(self, features, image_paths, image_filenames):
"""
向索引添加项目
参数:
- features: 特征矩阵,形状为 [n_images, feature_dim]
- image_paths: 图像路径列表
- image_filenames: 图像文件名列表
"""
if not self.faiss_available:
self.simple_index.add_items(features, image_paths, image_filenames)
return
# 确保特征是float32类型
if features.dtype != np.float32:
features = features.astype(np.float32)
# 添加到索引
self.index.add(features)
# 保存路径和文件名
self.image_paths.extend(image_paths)
self.image_filenames.extend(image_filenames)
def search(self, query_feature, k=5):
"""
搜索最相似的图像
参数:
- query_feature: 查询特征向量,形状为 [1, feature_dim]
- k: 返回的结果数量
返回:
- indices: 最相似图像的索引
- distances: 相似度分数
- paths: 图像路径
- filenames: 图像文件名
"""
if not self.faiss_available:
return self.simple_index.search(query_feature, k)
# 确保查询特征是float32类型
if query_feature.dtype != np.float32:
query_feature = query_feature.astype(np.float32)
# 执行搜索
distances, indices = self.index.search(query_feature, k)
# 获取第一个查询的结果
top_indices = indices[0]
top_scores = distances[0]
# 获取相应的路径和文件名
top_paths = [self.image_paths[i] for i in top_indices]
top_filenames = [self.image_filenames[i] for i in top_indices]
return top_indices, top_scores, top_paths, top_filenames
def save(self, save_dir):
"""
保存索引到磁盘
参数:
- save_dir: 保存目录
"""
if not self.faiss_available:
return self.simple_index.save(save_dir)
os.makedirs(save_dir, exist_ok=True)
try:
import faiss
# 保存Faiss索引
if self.use_gpu:
# 如果是GPU索引,需要先转回CPU
index_cpu = faiss.index_gpu_to_cpu(self.index)
index_path = os.path.join(save_dir, "faiss_index.bin")
faiss.write_index(index_cpu, index_path)
else:
index_path = os.path.join(save_dir, "faiss_index.bin")
faiss.write_index(self.index, index_path)
except Exception as e:
print(f"保存Faiss索引时出错: {e}")
# 转换为NumPy数组作为备份
features = np.zeros((len(self.image_paths), self.d), dtype=np.float32)
for i in range(0, len(self.image_paths), 1000):
batch = np.arange(i, min(i + 1000, len(self.image_paths)))
features[batch] = self.index.reconstruct_batch(batch)
features_path = os.path.join(save_dir, "features.npy")
np.save(features_path, features)
# 保存元数据
metadata = {
"image_paths": self.image_paths,
"image_filenames": self.image_filenames,
"feature_dim": self.d,
"n_images": len(self.image_paths),
"use_faiss": self.faiss_available,
"use_gpu": self.use_gpu,
"created_at": time.strftime("%Y-%m-%d %H:%M:%S")
}
metadata_path = os.path.join(save_dir, "metadata.json")
with open(metadata_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
# 返回保存的路径
return index_path, metadata_path
@classmethod
def load(cls, save_dir, use_gpu=None):
"""
从磁盘加载索引
参数:
- save_dir: 保存目录
- use_gpu: 是否使用GPU,如果为None则使用保存时的设置
返回:
- index: FaissIndex实例
"""
# 加载元数据
metadata_path = os.path.join(save_dir, "metadata.json")
with open(metadata_path, 'r', encoding='utf-8') as f:
metadata = json.load(f)
# 检查是否使用Faiss
if not metadata.get("use_faiss", False):
print("加载的索引没有使用Faiss,将使用SimpleIndex")
index = SimpleIndex.load(save_dir)
return index
try:
import faiss
# 创建索引
d = metadata["feature_dim"]
index = cls(d=d, use_gpu=False) # 先设置use_gpu为False
# 加载Faiss索引
faiss_path = os.path.join(save_dir, "faiss_index.bin")
index.index = faiss.read_index(faiss_path)
# 设置GPU使用
if use_gpu is None:
use_gpu = metadata.get("use_gpu", False)
if use_gpu:
try:
gpu_resources = faiss.StandardGpuResources()
index.index = faiss.index_cpu_to_gpu(gpu_resources, 0, index.index)
index.use_gpu = True
print("索引已加载到GPU")
except Exception as e:
print(f"无法使用GPU: {e}")
index.use_gpu = False
# 加载路径和文件名
index.image_paths = metadata["image_paths"]
index.image_filenames = metadata["image_filenames"]
return index
except ImportError:
print("Faiss不可用,将使用SimpleIndex作为后备")
return SimpleIndex.load(save_dir)
except Exception as e:
print(f"加载Faiss索引时出错: {e}")
print("尝试加载NumPy备份")
# 尝试加载NumPy备份
index = SimpleIndex.load(save_dir)
return index
def create_index(feature_dim=512, use_faiss=True, use_gpu=False):
"""
创建索引
参数:
- feature_dim: 特征维度
- use_faiss: 是否使用Faiss
- use_gpu: 是否使用GPU
返回:
- index: 索引实例
"""
if use_faiss:
return FaissIndex(d=feature_dim, use_gpu=use_gpu)
else:
return SimpleIndex()这段代码的核心功能是为以图搜图系统提供后端向量索引和检索的能力。
好的,我们来详细、基础地讲解一下这段代码。
这段代码的核心功能是为以图搜图系统提供后端向量索引和检索的能力。
想象一下“以图搜图”的流程:
-
你有一大堆图片(比如成千上万张),我们称之为“图库”。
-
首先,一个深度学习模型(比如 CLIP)会把每一张图片“看”一遍,然后把它转换成一个由数字组成的列表,这个列表叫做特征向量 (feature vector)。这个向量可以被看作是这张图片内容的“数学指纹”。
-
当你提供一张新的“查询图片”时,模型同样会把它转换成一个查询特征向量。
-
“以图搜图”的本质,就是拿着这个查询向量,去图库的所有向量中,找出在数学上最“接近”或最“相似”的那些向量。
-
这些最相似的向量所对应的原始图片,就是最终的搜索结果。
这段代码就负责实现第 4 步。它定义了两种方法来存储和快速搜索这些特征向量。它构建了一个“索引”,你可以把它想象成一个为了快速查找而特殊组织过的数据库。你可以不断向这个索引里添加新的图片特征向量,然后用一个新的向量来高效地进行搜索。
代码内部定义的模块:
class SimpleIndex (简单索引):
用途:提供了一个基础、简单易懂的向量索引实现。它不依赖任何特殊的库(除了 NumPy 和 Scikit-learn),适合小规模数据或用于教学和理解原理。
工作原理:它将所有向量存储在一个 NumPy 矩阵中。当搜索时,它会计算查询向量与矩阵中每一个向量的余弦相似度(这是一种“暴力搜索”),然后对相似度进行排序,返回最高的前 k 个结果。
1. 初始化 (__init__)
def __init__(self):
self.features = None # 特征矩阵
self.image_paths = [] # 图像路径列表
self.image_filenames = [] # 图像文件名列表当你创建一个 SimpleIndex 对象时,它内部会准备好三个“容器”:
self.features: 准备用来存放所有图片特征向量的。它将是一个大的 NumPy 矩阵,每一行代表一张图片。初始时是 None,表示里面什么都没有。
self.image_paths: 一个 Python 列表,用来存放每张图片在电脑上的完整路径。
self.image_filenames: 另一个 Python 列表,用来存放每张图片的 文件名。
这三个容器之间通过索引(位置)一一对应。例如,self.features 矩阵的第 10 行,就对应 self.image_paths 列表的第 10 个路径和 self.image_filenames 的第 10 个文件名。
2. 添加数据 (add_items)
def add_items(self, features, image_paths, image_filenames):
if self.features is None:
self.features = features
else:
self.features = np.vstack([self.features, features])
self.image_paths.extend(image_paths)
self.image_filenames.extend(image_filenames)np.vstack: 这个函数的作用是“垂直堆叠”。你可以把它想象成将一个新的 Excel 表格拼接到一个旧表格的下面。每次有新的图片特征向量进来,它就把这些新向量堆叠到 self.features 矩阵的末尾。
.extend(): 这是列表的方法,作用是将一个列表中的所有元素都添加到另一个列表的末尾。
3. 搜索 (search)
def search(self, query_feature, k=5):
# 计算余弦相似度
similarity_scores = cosine_similarity(query_feature, self.features)[0]
# 获取前k个最相似图像的索引
top_indices = np.argsort(-similarity_scores)[:k]
# 获取相应的分数、路径和文件名
top_scores = similarity_scores[top_indices]
top_paths = [self.image_paths[i] for i in top_indices]
top_filenames = [self.image_filenames[i] for i in top_indices]
return top_indices, top_scores, top_paths, top_filenamessimilarity_scores = cosine_similarity(query_feature, self.features)[0]:
-
这一行就是进行“暴力”比较的地方。
cosine_similarity函数会计算query_feature(查询向量) 与self.features矩阵中每一行向量的相似度。 -
最终返回一个包含了所有相似度分数的一维数组,数组的长度等于图库中图片的总数。
top_indices = np.argsort(-similarity_scores)[:k]:
-
这是一个非常巧妙的排序技巧。
np.argsort会返回排序后,原始元素在原数组中的索引。 -
我们想要的是相似度从高到低的排名。但
argsort默认是从小到大排序。 -
所以,通过给
similarity_scores加上一个负号-,最大的数就变成了最小的数。这样再进行从小到大的排序,就等价于对原始分数从高到低的排序。 -
[:k]表示我们只取排序结果的前k个索引,也就是最相似的k个结果的索引。
返回结果:
-
有了这
k个最匹配的索引 (top_indices),我们就可以用这些索引去similarity_scores、self.image_paths和self.image_filenames中取出对应的分数、路径和文件名,然后返回给调用者。
特点总结
简单直观:代码逻辑非常清晰,完全按照“逐一比较、排序、取前k”的思路实现,没有复杂的算法。
精确:由于是暴力搜索,它保证能找到数据集中理论上最相似的几个结果,搜索结果是 100% 精确的。
性能瓶颈:它的缺点也非常明显。当图库中的图片数量变得非常大时(例如超过十万张),每一次搜索都需要进行海量的计算,速度会变得非常慢。
适用场景:非常适合用于几千到几万张图片的小型项目、教学演示,或者作为更复杂索引(如 FaissIndex)的性能对比基准。
class FaissIndex (Faiss 索引):
用途:提供了一个高性能、可扩展的向量索引实现。它封装了强大的 faiss 库,适合处理大规模数据集,是生产环境中的首选。
工作原理:它将向量交给 faiss 内部的专门数据结构来管理。faiss 使用了近似最近邻 (Approximate Nearest Neighbor, ANN) 等高级算法,可以在牺牲极小的精度的情况下,实现比暴力搜索快几个数量级的查询速度。它还支持使用 GPU 进行加速。
FaissIndex 的核心思想是将繁重的计算任务委托给专门优化的底层库。这个库就是 Facebook AI Research 开发的 Faiss。
Faiss 的设计目标就是进行高效的相似性搜索。它不像 SimpleIndex 那样进行纯粹的暴力搜索,而是使用了高度优化的算法和数据结构,能够在大规模数据集(百万、千万甚至十亿级别)上实现极速的查询。
它的关键优势在于:
-
速度极快:底层由 C++ 和 CUDA(用于 GPU)实现,计算效率远超纯 Python 和 NumPy。
-
内存优化:提供了多种索引类型,可以通过压缩(量化)等技术,在保证较高召回率的同时,极大减少内存占用。
-
近似搜索:对于超大规模数据集,Faiss 的真正威力在于其近似最近邻 (ANN) 算法。它可以在牺牲极小的搜索精度(比如找到 99% 相似而不是 100% 相似的结果)的情况下,换来几十甚至几百倍的速度提升。对于“以图搜图”这类应用,这种牺牲几乎不影响用户体验。
-
GPU 加速:可以轻松地将索引和搜索任务转移到 GPU 上执行,利用 GPU 强大的并行计算能力,进一步提升搜索速度。
脚本模块
从图像中提取特征向量并保存
import os
import sys
import argparse
import torch
from tqdm import tqdm
import numpy as np
import json
# 将项目根目录添加到路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from models.clip import load_clip_model
from utils.data_utils import prepare_dataset, extract_features
def parse_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='从图像目录提取特征')
parser.add_argument('--image_dir', type=str, required=True,
help='包含图像的目录路径')
parser.add_argument('--output_dir', type=str, default='index',
help='保存特征的输出目录')
parser.add_argument('--model', type=str, default='clip_vit_base_16',
choices=['clip_vit_base_16', 'clip_vit_large_14'],
help='要使用的模型')
parser.add_argument('--pretrained', action='store_true',
help='是否使用预训练权重')
parser.add_argument('--batch_size', type=int, default=32,
help='批处理大小')
parser.add_argument('--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu',
help='设备 (cuda/cpu)')
parser.add_argument('--num_workers', type=int, default=4,
help='数据加载的工作线程数')
return parser.parse_args()
def main():
"""主函数"""
args = parse_args()
# 确保输出目录存在
os.makedirs(args.output_dir, exist_ok=True)
print(f"使用设备: {args.device}")
# 加载模型
print(f"加载模型: {args.model}...")
model = load_clip_model(args.model, args.pretrained)
model = model.to(args.device)
# 准备数据集
print(f"加载图像目录: {args.image_dir}...")
dataset, data_loader = prepare_dataset(
args.image_dir,
batch_size=args.batch_size,
num_workers=args.num_workers
)
print(f"找到 {len(dataset)} 张图像")
# 提取特征
print("提取特征...")
features, paths, filenames = extract_features(model, data_loader, args.device)
# 保存特征
features_path = os.path.join(args.output_dir, "features.npy")
np.save(features_path, features)
# 保存元数据
metadata = {
"image_paths": paths,
"image_filenames": filenames,
"feature_dim": features.shape[1],
"n_images": len(paths),
"model": args.model,
"device": args.device
}
metadata_path = os.path.join(args.output_dir, "metadata.json")
with open(metadata_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
print(f"保存了 {len(features)} 个特征向量到 {features_path}")
print(f"保存了元数据到 {metadata_path}")
if __name__ == "__main__":
main()这段代码是一个命令行工具,它的核心任务是批量处理一个文件夹里的所有图片,并使用一个深度学习模型(CLIP)为每张图片生成其对应的“数学指纹”——即特征向量。
简单来说,这是整个“以图搜图”流程的第一步:数据准备和建档。
想象一下你要建立一个图书馆的图片检索系统。在你能够搜索之前,必须先有一个图书管理员(就是这个脚本),把每一本书(每一张图片)拿过来,阅读它的内容,然后为它生成一张索引卡片(特征向量),最后把所有的索引卡片都整理好,存放在一个档案盒里(输出的 features.npy 和 metadata.json 文件)。
之后我们介绍过的 SimpleIndex 或 FaissIndex 脚本,就是利用这个档案盒里的资料来建立快速检索引擎的。所以,这个脚本的输出,是那两个索引脚本的输入。
from models.clip import load_clip_model: 这行代码表示,在项目 models/clip 目录下有一个函数叫 load_clip_model。它的作用是加载预训练好的 CLIP 模型。用户可以通过命令行参数选择加载哪个版本的模型(例如 clip_vit_base_16)。
from utils.data_utils import prepare_dataset, extract_features: 这行代码表示,在 utils/data_utils 目录下有两个重要的辅助函数:
prepare_dataset: 它的作用是准备数据集。它会接收一个图片目录路径,然后创建一个 PyTorch 的 Dataset 和 DataLoader。DataLoader 是一个强大的工具,它可以自动地、高效地一批一批地(batch by batch)加载图片、进行预处理(如缩放、裁剪、归一化),并提供给模型。
extract_features: 这是执行特征提取的核心逻辑的函数。它会接收加载好的模型和数据加载器 (DataLoader),然后遍历所有数据,将图片送入模型计算,最后收集并返回所有的特征向量和对应的文件信息。
代码逻辑详解(主函数 main 的执行流程)
当你在命令行运行这个脚本时,main 函数会按照以下步骤执行:
解析参数 (parse_args):
-
脚本首先调用
parse_args()函数。这个函数会读取用户在命令行中输入的参数,比如图片的目录--image_dir,输出目录--output_dir,使用的模型--model等。
创建输出目录:
-
os.makedirs(args.output_dir, exist_ok=True)确保用于存放结果的文件夹存在,如果不存在就会自动创建。
加载模型:
-
调用
load_clip_model()函数,根据用户选择的模型名称,加载对应的 CLIP 模型。 -
model.to(args.device)将模型移动到指定的计算设备上(优先使用 GPUcuda,如果不可用则使用cpu)。在 GPU 上计算会快得多。
准备数据集:
-
调用
prepare_dataset()函数,它会扫描--image_dir目录下的所有图片,并创建一个DataLoader。这个DataLoader会在后台以多线程 (num_workers) 的方式高效地准备好一批批的图片数据。
提取特征:
-
这是最耗时的一步。调用
extract_features()函数。 -
在这个函数内部,它会用
tqdm启动一个循环,从DataLoader中一批一批地取出预处理好的图片张量。 -
对于每一批图片,它会将其送入模型进行前向传播计算,得到这一批图片的特征向量。
-
它会收集每一批的结果,最终将所有批次的特征向量、图片路径、图片文件名分别汇总到三个列表中。
保存结果:
-
当所有图片都处理完毕后,
extract_features函数会返回三个变量:features(一个大的 NumPy 数组,包含了所有向量),paths(所有图片的完整路径列表),和filenames(所有图片的文件名列表)。 -
np.save(...)将巨大的features数组以高效的.npy格式保存到文件中。 -
json.dump(...)将paths和filenames等元数据以清晰的.json格式保存到另一个文件中。
利用提取特征构建索引:
import os
import sys
import argparse
import numpy as np
import json
from tqdm import tqdm
# 将项目根目录添加到路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.index_utils import SimpleIndex, FaissIndex, create_index
def parse_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='从特征构建索引')
parser.add_argument('--feature_dir', type=str, required=True,
help='包含特征的目录路径')
parser.add_argument('--output_dir', type=str, default=None,
help='保存索引的输出目录(默认与特征目录相同)')
parser.add_argument('--use_faiss', action='store_true',
help='使用Faiss索引(如果可用)')
parser.add_argument('--use_gpu', action='store_true',
help='使用GPU(仅适用于Faiss)')
return parser.parse_args()
def main():
"""主函数"""
args = parse_args()
# 如果未指定输出目录,则使用特征目录
if args.output_dir is None:
args.output_dir = args.feature_dir
# 确保输出目录存在
os.makedirs(args.output_dir, exist_ok=True)
# 加载特征和元数据
features_path = os.path.join(args.feature_dir, "features.npy")
metadata_path = os.path.join(args.feature_dir, "metadata.json")
if not os.path.exists(features_path) or not os.path.exists(metadata_path):
print(f"错误: 在 {args.feature_dir} 中找不到特征或元数据文件")
return
print(f"加载特征: {features_path}")
features = np.load(features_path)
print(f"加载元数据: {metadata_path}")
with open(metadata_path, 'r', encoding='utf-8') as f:
metadata = json.load(f)
image_paths = metadata["image_paths"]
image_filenames = metadata["image_filenames"]
feature_dim = metadata["feature_dim"]
# 创建索引
print("创建索引...")
use_faiss_actual = False
if args.use_faiss:
try:
import faiss
print("使用Faiss索引")
use_faiss_actual = True
except ImportError:
print("警告: Faiss不可用,将使用SimpleIndex")
use_faiss_actual = False
else:
print("使用SimpleIndex")
# 创建索引实例
index = create_index(
feature_dim=feature_dim,
use_faiss=use_faiss_actual,
use_gpu=args.use_gpu
)
# 添加特征到索引
print("将特征添加到索引...")
index.add_items(features, image_paths, image_filenames)
# 保存索引
print(f"保存索引到: {args.output_dir}")
index_path, metadata_path = index.save(args.output_dir)
print(f"索引已保存到: {index_path}")
print(f"元数据已保存到: {metadata_path}")
if __name__ == "__main__":
main()这段代码是整个“以图搜图”流程的第二步:构建索引。
它也是一个命令行工具,其主要作用是读取上一步(特征提取脚本)生成的原始特征向量文件 (features.npy) 和元数据文件 (metadata.json),然后利用这些数据来构建一个结构化、可供快速搜索的索引。
我们可以延续图书馆的比喻:
-
第一步(
extract_features脚本)是图书管理员为每一本书制作了一张独立的索引卡片。 -
这一步(
build_index脚本)则是图书管理员拿起所有的卡片,将它们精心组织并放入一个真正的“卡片目录柜”中。用户可以选择是建一个简单的、按字母顺序排列的目录柜(SimpleIndex),还是建一个高效的、带电子检索功能的目录柜(FaissIndex)。
构建完成后,这个“目录柜”(索引文件)就被保存下来,等待最后的搜索程序来使用。这样做的好处是,构建索引这个相对耗时的步骤只需要做一次。之后每次搜索时,直接加载这个现成的索引即可,无需重复构建。
from utils.index_utils import SimpleIndex, FaissIndex, create_index: 这是这个脚本最核心的依赖。
-
它直接从我们之前详细分析过的
index_utils.py文件中,导入了SimpleIndex类、FaissIndex类以及create_index工厂函数。 -
这体现了良好的代码复用:这个脚本本身不负责实现索引的逻辑,它只负责调用和组织已经写好的索引模块。它是一个“总指挥”或“协调者”的角色。
代码逻辑详解(主函数 main 的执行流程)
脚本的执行流程清晰地展示了如何将原始特征数据转换成一个可用的索引。
-
解析参数 (
parse_args):-
脚本启动后,首先解析命令行参数。用户需要提供包含
features.npy的目录 (--feature_dir),并且可以选择是否启用 Faiss (--use_faiss) 和 GPU (--use_gpu)。
-
-
加载原始数据:
-
脚本会根据
--feature_dir路径,找到features.npy和metadata.json这两个文件。 -
np.load(): 加载特征向量,得到一个巨大的 NumPy 矩阵features。 -
json.load(): 加载元数据,得到一个包含图片路径、文件名等信息的 Python 字典metadata。
-
-
决定索引类型:
-
这是一个关键的决策步骤。
-
脚本会检查用户是否在命令行中指定了
--use_faiss。 -
如果用户想用 Faiss,脚本会再次
try...except尝试导入faiss库,以确保用户的环境真的安装了它。这是一个双重保险,非常稳健。 -
根据最终结果,设置一个实际的标志位
use_faiss_actual。
-
-
创建索引实例 (
create_index):-
脚本调用之前我们分析过的
create_index工厂函数。 -
它将从元数据中读取的特征维度
feature_dim,以及上一步确定的use_faiss_actual和use_gpu标志位传递给这个函数。 -
工厂函数会根据这些参数,返回一个具体的索引对象——要么是
SimpleIndex的实例,要么是FaissIndex的实例。
-
-
填充索引 (
index.add_items):-
现在有了一个空的索引对象
index和加载好的全部特征数据features。 -
这一行
index.add_items(...)是核心的构建步骤。它调用索引对象的add_items方法,将所有的特征向量和图片路径信息“喂”给它。 -
无论是
SimpleIndex还是FaissIndex,它们各自的add_items方法都会以自己的方式处理和组织这些数据。
-
-
保存索引 (
index.save):-
当所有数据都添加进内存中的索引对象后,最后一步就是将这个构建好的索引持久化保存到磁盘。
-
调用
index.save(args.output_dir)方法。这个方法也是多态的:-
如果
index是SimpleIndex对象,它会保存成features.npy和metadata.json。 -
如果
index是FaissIndex对象,它会保存成 Faiss 专用的faiss_index.bin和metadata.json。
-
-
-
完成:
-
脚本打印出最终保存的索引文件路径,然后结束。
-
根据查询图像搜索相似图像
import os
import sys
import argparse
import torch
import numpy as np
import matplotlib.pyplot as plt
# 将项目根目录添加到路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from models.clip import load_clip_model
from utils.image_utils import load_and_preprocess_image, visualize_query_and_results
from utils.index_utils import SimpleIndex, FaissIndex
def parse_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='相似图像检索')
parser.add_argument('--query_image', type=str, required=True,
help='查询图像路径')
parser.add_argument('--index_dir', type=str, default='index',
help='包含索引的目录路径')
parser.add_argument('--model', type=str, default='clip_vit_base_16',
choices=['clip_vit_base_16', 'clip_vit_large_14'],
help='要使用的模型')
parser.add_argument('--top_k', type=int, default=5,
help='返回的结果数量')
parser.add_argument('--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu',
help='设备 (cuda/cpu)')
parser.add_argument('--use_gpu_index', action='store_true',
help='使用GPU索引(仅适用于Faiss)')
parser.add_argument('--save_result', type=str, default=None,
help='保存可视化结果的路径')
parser.add_argument('--show', action='store_true',
help='显示可视化结果')
return parser.parse_args()
def main():
"""主函数"""
args = parse_args()
if not os.path.exists(args.query_image):
print(f"错误: 找不到查询图像 {args.query_image}")
return
if not os.path.exists(args.index_dir):
print(f"错误: 找不到索引目录 {args.index_dir}")
return
# 加载模型
print(f"加载模型: {args.model}...")
model = load_clip_model(args.model)
model = model.to(args.device)
model.eval()
# 加载并预处理查询图像
print(f"加载查询图像: {args.query_image}")
query_tensor = load_and_preprocess_image(args.query_image)
query_tensor = query_tensor.to(args.device)
# 提取查询图像特征
print("提取查询特征...")
with torch.no_grad():
query_feature = model(query_tensor)
query_feature = query_feature.cpu().numpy()
# 加载索引
print(f"加载索引: {args.index_dir}")
try:
# 尝试加载Faiss索引
index = FaissIndex.load(args.index_dir, use_gpu=args.use_gpu_index)
print("已加载Faiss索引")
except Exception as e:
print(f"无法加载Faiss索引: {e}")
print("尝试加载SimpleIndex...")
index = SimpleIndex.load(args.index_dir)
print("已加载SimpleIndex")
# 搜索相似图像
print(f"搜索相似图像 (top {args.top_k})...")
indices, scores, paths, filenames = index.search(query_feature, k=args.top_k)
# 打印结果
print("\n检索结果:")
for i, (score, path, filename) in enumerate(zip(scores, paths, filenames)):
print(f"{i+1}. 相似度: {score:.4f}, 文件: {filename}")
# 可视化结果
if args.show or args.save_result:
print("生成可视化...")
fig = visualize_query_and_results(args.query_image, paths, scores)
if args.save_result:
plt.savefig(args.save_result, bbox_inches='tight')
print(f"已保存可视化到: {args.save_result}")
if args.show:
plt.show()
else:
plt.close(fig)
if __name__ == "__main__":
main()
这段代码是整个“以图搜图”项目的最终执行程序,也就是第三步:进行检索。
这是一个完整的、用户可以直接使用的命令行工具。它的功能是:
-
接收用户指定的一张查询图片。
-
接收用户预先构建好的索引库的路径。
-
使用与构建索引时相同的深度学习模型,将用户的查询图片“翻译”成一个特征向量。
-
加载索引库,然后用查询向量在库中进行高速搜索。
-
找出与查询图片最相似的
k张图片。 -
将搜索结果(图片路径、相似度分数)打印在屏幕上,并且可以选择性地将查询图片和结果图片一同可视化显示出来或保存成一张结果图。
我们继续用图书馆的比喻来总结整个流程:
-
第一步 (
extract_features.py): 图书管理员为馆里每一本书制作一张索引卡。 -
第二步 (
build_index.py): 管理员将所有索引卡片整理到一个巨大的、有序的卡片目录柜里。 -
第三步 (这个脚本): 一位读者(用户)拿着一本书(查询图片)来到图书馆,对管理员说:“请帮我找找和这本书最像的 5 本书”。管理员会拿出这本书,制作一张临时的索引卡(提取查询特征),然后利用那个巨大的目录柜(加载索引)快速地找出结果,并把结果展示给读者。
所以,这个脚本是整个项目的“前台应用”,它将之前所有的后台准备工作(特征提取、索引构建)的成果展现给最终用户。
这个脚本巧妙地将之前我们分析过的所有工具模块都“组装”了起来:
-
from models.clip import load_clip_model: 需要用它来加载 CLIP 模型。关键点:这里加载的模型必须和第一步提取特征时用的模型完全一致,否则查询向量和库里的向量就不在同一个“语言体系”里,无法比较。 -
from utils.image_utils import load_and_preprocess_image, visualize_query_and_results:-
load_and_preprocess_image: 在我们分析的第一个代码文件中出现过。这里用它来处理用户输入的单张查询图片,确保它经过了和库中所有图片完全相同的预处理流程。 -
visualize_query_and_results: 同样在第一个代码文件中出现过。在搜索完成后,用它来生成漂亮的可视化结果图。
-
-
from utils.index_utils import SimpleIndex, FaissIndex: 导入这两个类是为了能够调用它们各自的类方法load()来从磁盘加载索引。虽然没有直接创建新索引,但需要它们的定义来反序列化已保存的索引文件。
main 函数的流程就是一次完整的“以图搜图”查询过程:
-
解析参数 (
parse_args): 获取用户输入的命令行指令,包括:查询图片路径 (--query_image)、索引库存放目录 (--index_dir)、返回结果数量 (--top_k) 以及是否显示/保存结果 (--show,--save_result)。 -
加载模型: 加载 CLIP 模型,并将其设置为评估模式 (
model.eval())。这是一个很重要的步骤,它会关闭模型中只在训练时使用的层(如 Dropout),确保每次推理的结果都是确定的。 -
处理查询图片:
-
调用
load_and_preprocess_image()加载并预处理用户给定的查询图片,得到一个 PyTorch 张量query_tensor。 -
with torch.no_grad(): 这是一个上下文管理器,它告诉 PyTorch 在接下来的代码块中不要计算梯度。因为我们只是在做预测(推理),而不是训练,所以不需要梯度信息,这样做可以节省大量显存和计算资源。 -
将图片张量送入模型,得到特征向量,并将其转换为 NumPy 数组
query_feature,准备用于搜索。
-
-
加载索引:
-
这是一个非常稳健的自动识别加载设计。
-
它用
try...except块,首先尝试FaissIndex.load()。因为 Faiss 索引通常是高性能场景下的首选。 -
如果加载失败(比如目录里存的是
SimpleIndex的文件,或者用户环境没装 Faiss),程序不会崩溃,而是会进入except块,自动尝试用SimpleIndex.load()来加载。 -
这样一来,无论第二步构建的是哪种索引,这个搜索脚本都能智能地处理。
-
-
执行搜索 (
index.search):-
这是整个流程的“临门一脚”。调用加载好的
index对象的.search()方法。 -
将上一步得到的
query_feature和用户想要的top_k作为参数传进去。 -
index对象(无论是SimpleIndex还是FaissIndex)会执行它自己的搜索逻辑,并返回最相似的k个结果的索引、分数、路径和文件名。
-
-
展示结果:
-
文本输出: 首先,它会清晰地在命令行中打印出排名、相似度分数和文件名。
-
可视化输出: 如果用户指定了
--show或--save_result,它会:-
调用
visualize_query_and_results()生成一张包含所有结果的 Matplotlib 图像对象fig。 -
如果需要保存,就调用
plt.savefig()。 -
如果需要显示,就调用
plt.show()弹出一个窗口展示图像。
-
-
最后的主函数
功能:提供统一的命令行接口,整合所有功能
主要组件:
build_index:封装索引构建流程
search_image:封装图像检索流程
run_demo:演示模式,展示系统功能
main:处理命令行参数,调用相应功能
import os
import sys
import argparse
import torch
from pathlib import Path
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
from models.clip import load_clip_model
from utils.data_utils import prepare_dataset, extract_features
from utils.image_utils import load_and_preprocess_image, visualize_query_and_results
from utils.index_utils import create_index
def parse_args():
"""解析命令行参数"""
parser = argparse.ArgumentParser(description='CLIP/ViT图像相似度检索系统')
parser.add_argument('--mode', type=str, default='demo',
choices=['index', 'search', 'demo'],
help='运行模式: index(构建索引), search(检索图像), demo(演示模式)')
parser.add_argument('--image_dir', type=str, default='data/images',
help='包含图像的目录路径')
parser.add_argument('--index_dir', type=str, default='index',
help='索引保存目录')
parser.add_argument('--query_image', type=str, default=None,
help='查询图像路径(仅在search模式下使用)')
parser.add_argument('--model', type=str, default='clip_vit_base_16',
choices=['clip_vit_base_16', 'clip_vit_large_14'],
help='要使用的模型')
parser.add_argument('--batch_size', type=int, default=32,
help='批处理大小')
parser.add_argument('--top_k', type=int, default=5,
help='返回的结果数量')
parser.add_argument('--device', type=str, default='cuda' if torch.cuda.is_available() else 'cpu',
help='设备 (cuda/cpu)')
parser.add_argument('--use_faiss', action='store_true',
help='使用Faiss索引')
parser.add_argument('--use_gpu_index', action='store_true',
help='使用GPU索引(仅适用于Faiss)')
parser.add_argument('--demo_dir', type=str, default=None,
help='演示模式下的图像目录(默认使用image_dir)')
parser.add_argument('--save_results', action='store_true',
help='保存检索结果')
parser.add_argument('--result_dir', type=str, default='results',
help='检索结果保存目录')
return parser.parse_args()
def build_index(args):
"""构建索引"""
print(f"\n=== 构建图像索引 ===")
# 检查图像目录
if not os.path.exists(args.image_dir):
print(f"错误: 图像目录不存在: {args.image_dir}")
return
# 确保索引目录存在
os.makedirs(args.index_dir, exist_ok=True)
# 加载模型
print(f"加载模型: {args.model}...")
model = load_clip_model(args.model)
model = model.to(args.device)
model.eval()
# 准备数据集
print(f"加载图像目录: {args.image_dir}...")
dataset, data_loader = prepare_dataset(
args.image_dir,
batch_size=args.batch_size
)
print(f"找到 {len(dataset)} 张图像")
# 提取特征
print("提取特征...")
features, paths, filenames = extract_features(model, data_loader, args.device)
# 创建索引
print("创建索引...")
index = create_index(
feature_dim=features.shape[1],
use_faiss=args.use_faiss,
use_gpu=args.use_gpu_index
)
# 添加特征到索引
index.add_items(features, paths, filenames)
# 保存索引
print(f"保存索引到: {args.index_dir}")
index_path, metadata_path = index.save(args.index_dir)
print(f"索引已成功构建和保存")
return index
def search_image(args, index=None):
"""搜索相似图像"""
print(f"\n=== 图像检索 ===")
# 检查查询图像
if not args.query_image or not os.path.exists(args.query_image):
print(f"错误: 查询图像不存在: {args.query_image}")
return
# 加载索引
if index is None:
print(f"加载索引: {args.index_dir}")
from utils.index_utils import SimpleIndex, FaissIndex
try:
# 尝试加载Faiss索引
index = FaissIndex.load(args.index_dir, use_gpu=args.use_gpu_index)
except Exception as e:
print(f"加载Faiss索引失败: {e}")
print("尝试加载SimpleIndex...")
index = SimpleIndex.load(args.index_dir)
# 加载模型
print(f"加载模型: {args.model}...")
model = load_clip_model(args.model)
model = model.to(args.device)
model.eval()
# 加载并预处理查询图像
print(f"加载查询图像: {args.query_image}")
query_tensor = load_and_preprocess_image(args.query_image)
query_tensor = query_tensor.to(args.device)
# 提取查询图像特征
print("提取查询特征...")
start_time = time.time()
with torch.no_grad():
query_feature = model(query_tensor)
query_feature = query_feature.cpu().numpy()
feature_time = time.time() - start_time
# 搜索相似图像
print(f"搜索相似图像 (top {args.top_k})...")
start_time = time.time()
indices, scores, paths, filenames = index.search(query_feature, k=args.top_k)
search_time = time.time() - start_time
# 打印结果
print(f"\n查询图像: {os.path.basename(args.query_image)}")
print(f"特征提取耗时: {feature_time:.4f}秒")
print(f"搜索耗时: {search_time:.4f}秒")
print("\n检索结果:")
for i, (score, path, filename) in enumerate(zip(scores, paths, filenames)):
print(f"{i+1}. 相似度: {score:.4f}, 文件: {filename}")
# 可视化结果
fig = visualize_query_and_results(args.query_image, paths, scores)
# 保存结果
if args.save_results:
os.makedirs(args.result_dir, exist_ok=True)
result_name = f"result_{Path(args.query_image).stem}.jpg"
result_path = os.path.join(args.result_dir, result_name)
plt.savefig(result_path, bbox_inches='tight')
print(f"\n结果已保存到: {result_path}")
plt.show()
return indices, scores, paths
def run_demo(args):
"""运行演示模式"""
print(f"\n=== CLIP/ViT 图像检索演示 ===")
# 如果未指定演示目录,则使用图像目录
if args.demo_dir is None:
args.demo_dir = args.image_dir
# 检查演示目录
if not os.path.exists(args.demo_dir):
print(f"错误: 演示目录不存在: {args.demo_dir}")
return
# 检查是否已经有索引,如果没有则构建
if not os.path.exists(os.path.join(args.index_dir, "metadata.json")):
print("索引不存在,将先构建索引...")
args.image_dir = args.demo_dir
index = build_index(args)
else:
index = None
# 获取演示目录中的图像
image_exts = ['.jpg', '.jpeg', '.png', '.bmp', '.webp']
demo_images = []
for root, _, files in os.walk(args.demo_dir):
for file in files:
ext = os.path.splitext(file)[1].lower()
if ext in image_exts:
demo_images.append(os.path.join(root, file))
if not demo_images:
print(f"错误: 在演示目录中找不到图像: {args.demo_dir}")
return
print(f"在演示目录中找到 {len(demo_images)} 张图像")
# 随机选择一些图像进行演示
import random
num_demos = min(3, len(demo_images))
demo_images = random.sample(demo_images, num_demos)
# 对每个演示图像进行检索
for i, query_image in enumerate(demo_images):
print(f"\n演示 #{i+1}/{num_demos}")
args.query_image = query_image
search_image(args, index)
def main():
"""主函数"""
args = parse_args()
print("CLIP/ViT 图像相似度检索系统")
print(f"运行模式: {args.mode}")
print(f"使用设备: {args.device}")
if args.mode == 'index':
build_index(args)
elif args.mode == 'search':
search_image(args)
elif args.mode == 'demo':
run_demo(args)
else:
print(f"错误: 未知的模式: {args.mode}")
if __name__ == "__main__":
main()
这是一个完整且统一的图像检索系统命令行界面 (CLI)。用户不再需要运行三个不同的脚本来完成不同阶段的任务,而是只运行这一个脚本,并通过 --mode 参数来告诉它具体要做什么。
它有三种核心运行模式:
-
index模式 (索引模式):-
功能: 负责从一个图片目录中,完成从提取特征到构建索引并保存的全过程。它整合了我们之前分析的第一个(特征提取)和第二个(索引构建)脚本的全部功能。
-
相当于: 你对程序说:“请把这个文件夹里所有图片都处理好,建立一个随时可以搜索的档案库。”
-
-
search模式 (检索模式):-
功能: 负责接收一张查询图片,加载已经构建好的索引,执行相似性搜索,并展示结果。这完全是我们分析的第三个(图像检索)脚本的功能。
-
相当于: 你对程序说:“这是我的图片,请用之前建好的档案库帮我找出最像它的几张。”
-
-
demo模式 (演示模式):-
功能: 这是一个全新的、非常人性化的“一键体验”模式。它会自动检查索引是否存在,如果不存在,就先自动执行一次
index模式来构建索引。然后,它会从图片库中随机挑选几张图片,逐一作为查询图片,自动执行search模式来展示检索效果。 -
相当于: 你对程序说:“我不想管那么多细节,请直接给我展示一下你的能耐吧!”
-
总而言之,这个脚本将整个项目从一系列分散的工具,提升为了一个单一、内聚、用户友好的应用程序。
A. 核心功能模块
-
build_index(args)(索引构建模块):-
作用: 完全负责
index模式的逻辑。 -
内部流程:
-
加载CLIP模型。
-
准备数据集 (
prepare_dataset),扫描图片目录。 -
提取所有图片的特征向量 (
extract_features)。 -
创建一个索引实例 (
create_index,可以是 Simple 或 Faiss)。 -
将所有特征向量填入索引 (
index.add_items)。 -
将构建好的索引保存到磁盘 (
index.save)。
-
-
本质:
extract_features.py和build_index.py两个脚本的逻辑合并体。
-
-
search_image(args, index=None)(图像检索模块):-
作用: 完全负责
search模式的逻辑。 -
内部流程:
-
加载索引(如果外部没有传入的话)。它依然保留了自动识别 Faiss/Simple 索引的健壮设计。
-
加载CLIP模型。
-
加载并预处理单张查询图片。
-
提取查询图片的特征向量。
-
在索引中执行搜索 (
index.search)。 -
打印并可视化结果。
-
-
本质:
search.py脚本的逻辑。
-
-
run_demo(args)(自动演示模块):-
作用: 完全负责
demo模式的逻辑。 -
内部流程:
-
智能检查: 检查索引目录是否存在。如果不存在,它会自动调用
build_index(args)函数来先构建索引。 -
随机采样: 从指定的演示图片目录中,随机挑选几张图片(默认最多3张)。
-
循环检索: 遍历这些随机选出的图片,将每一张都作为查询图片,然后循环调用
search_image(args, index)函数来执行搜索并展示结果。
-
-
B. 主控与辅助模块
-
parse_args(): 参数解析器,是整个程序的“控制面板”。最核心的参数就是--mode,它决定了程序将要进入哪个功能模块。 -
main(): 主函数,是程序的入口和“交通警察”。它的逻辑非常简单:-
解析命令行参数。
-
根据
args.mode的值,判断应该调用build_index、search_image还是run_demo。 -
将程序流程分派给对应的函数去执行。
-
模块之间的协作关系
数据流转过程:
原始图像 → data_utils.py (加载和预处理) → vit.py/clip.py (特征提取) → index_utils.py (索引构建) → 特征索引
查询图像 → image_utils.py (预处理) → vit.py/clip.py (特征提取) → index_utils.py (相似度搜索) → 检索结果 → image_utils.py (可视化)
文本查询过程 (新增功能):
文本查询 → clip.py 中的 TextTransformer (文本特征提取) → index_utils.py (相似度搜索) → 检索结果

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)