
NeurIPS 2025 | 港科大&上交大HoloV:多模态大模型“瘦身”新突破,剪枝88.9%视觉Token,性能几乎无损
关键词:视觉令牌剪枝、多模态大语言模型、全局上下文保留、注意力机制偏差、HoloV框架、自适应令牌分配、视觉上下文重提取、位置偏差、注意力分散
关键词:视觉令牌剪枝、多模态大语言模型、全局上下文保留、注意力机制偏差、HoloV框架、自适应令牌分配、视觉上下文重提取、位置偏差、注意力分散
一、导读
本文针对多模态大语言模型在推理过程中因视觉令牌冗余导致的计算开销问题展开研究。现有基于注意力机制的令牌剪枝方法(如FastV、FasterVLM等)过度依赖局部显著性,忽视了视觉场景的整体语义关联,导致在高剪枝率下性能显著下降。
本文指出,现有方法存在位置偏差和注意力分散等问题,未能有效保留对整体视觉理解至关重要的非显著令牌。为解决这一理论空白,本文提出HoloV框架,通过全局上下文感知的令牌保留策略,实现了在高剪枝率下仍能保持视觉语义完整性,显著提升了效率与性能的平衡。
二、论文基本信息

-
论文标题:Don't Just Chase "Highlighted Tokens" in MLLMs: Revisiting Visual Holistic Context Retention
-
作者:Xin Zou, Di Lu, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Xu Zheng, Linfeng Zhang, Xuming Hu
-
单位:香港科技大学(广州)、香港科技大学、INSAIT Sofia University、上海交通大学
-
来源:arXiv:2510.02912v1
-
链接:https://github.com/obananas/HoloV
三、摘要精炼
本文提出HoloV,一种即插即用的视觉令牌剪枝框架,旨在解决现有注意力优先剪枝方法在高剪枝率下性能急剧下降的问题。HoloV通过自适应分配剪枝预算至不同图像区域,保留具有全局语义多样性的令牌,而非仅关注局部显著区域。实验表明,在LLaVA-1.5模型中,HoloV在剪除88.9%视觉令牌后仍能保持95.8%的原始性能,显著优于FastV、SparseVLM等现有方法。
四、研究背景与相关工作
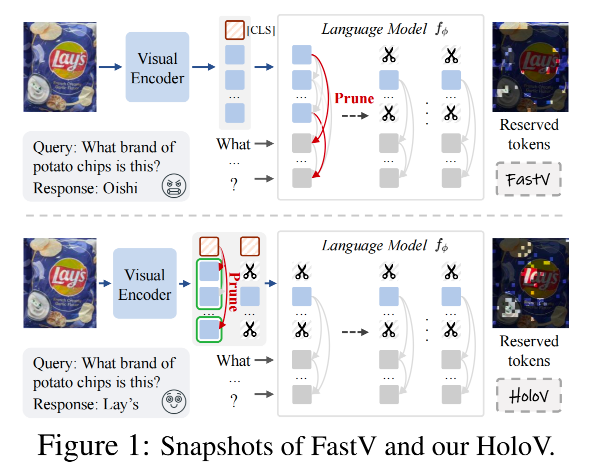
多模态大语言模型在图像描述、视觉问答等任务中表现出色,但其依赖大量视觉令牌导致计算负担加重。现有令牌剪枝方法可分为两类:视觉中心策略(如TokenLearner、FasterVLM)基于图像结构或[CLS]注意力进行剪枝;指令中心策略(如FastV、HiRED)利用跨模态注意力或梯度信息评估令牌重要性。
然而,这些方法普遍假设"高注意力令牌更具信息量",忽视了视觉场景的空间语义关系,导致在高剪枝率下仅保留同质化令牌,破坏整体语义连贯性。本文通过分析注意力分布的位置偏差和分散现象,指出保留全局上下文对视觉理解的重要性,并提出HoloV以弥补这一空白。

五、主要贡献与创新
-
自适应令牌分配机制:提出基于图像分块的自适应令牌分配,结合局部多样性和全局注意力评分,实现令牌保留的全局优化。
-
视觉上下文重提取:引入快速重提取机制,在推理过程中动态补充被剪枝的视觉信息,缓解信息丢失问题。
-
理论保障:理论分析表明HoloV在令牌覆盖率和语义保留上具有有界误差,满足Lipschitz连续性假设。
-
广泛实验验证:在多个基准任务和模型架构上验证HoloV的优越性,尤其在极高剪枝率下仍保持优异性能。
👇👇👇
六、研究方法与原理


HoloV框架首先将图像令牌划分为 个区域,每个区域包含 个令牌。对于第 个区域,计算其内部令牌的相似性矩阵:
其中 为归一化后的令牌嵌入。接着计算每个令牌的语义分布方差:
结合方差 和 [CLS] 注意力 ,构建综合评分:
区域重要性权重为:
令牌配额 根据 分配,并在各区域内选择 最高的 个令牌保留。
此外,HoloV在中间层引入视觉上下文重提取机制,通过前馈网络将剪枝令牌作为键值记忆重新注入,以应对推理中的不确定性。
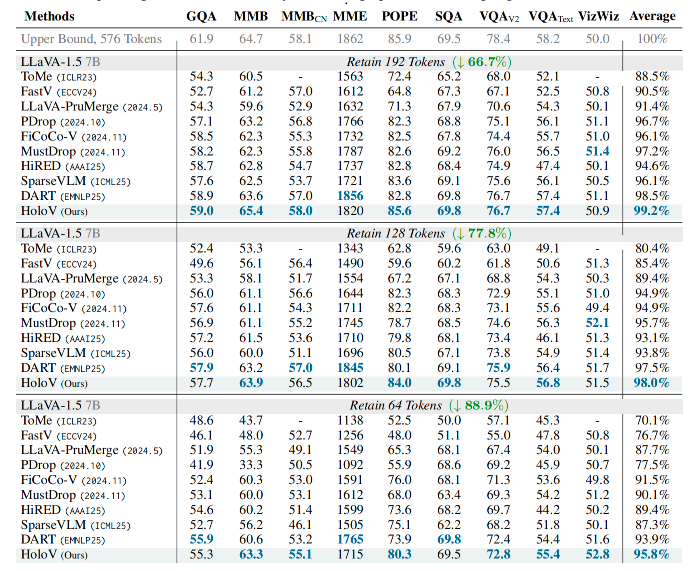
七、实验设计与结果分析
实验设置
-
数据集:10个图像理解基准(GQA、MMBench、POPE、TextVQA等)和2个视频理解基准(MSVD-QA、MSRVTT-QA)
-
模型:LLaVA-1.5、LLaVA-NeXT、Qwen2.5-VL等
-
对比方法:ToMe、FastV、SparseVLM、HiRED等
-
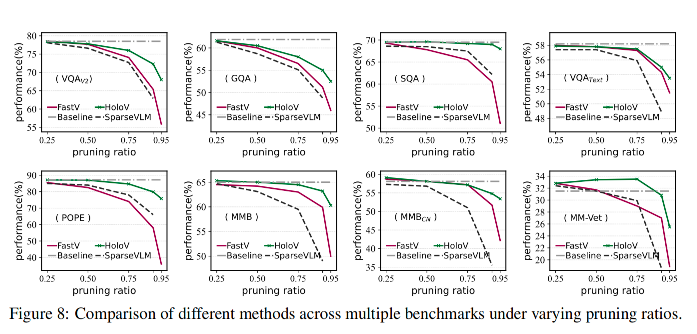
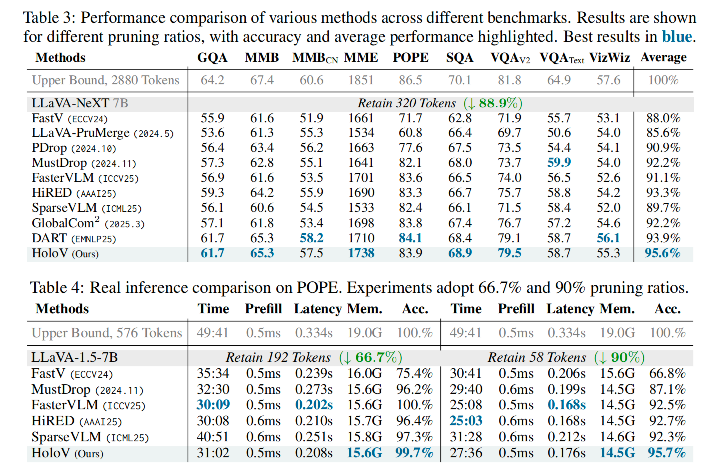
关键结果
|
实验场景 |
性能表现 |
对比优势 |
|---|---|---|
|
LLaVA-1.5 (88.9%剪枝) |
保持95.8%原始性能 |
优于DART(93.9%)、FastV(76.7%) |
|
POPE幻觉评估 |
80.3%准确率 |
显著高于其他方法 |
|
LLaVA-NeXT高分辨率 |
95.6%平均性能 |
优于HiRED(93.3%) |
|
效率优化 |
推理时间↓42.7%,内存使用↓23.7% |
吞吐量5.2样本/秒 |
八、论文结论与启示
本文通过理论分析和实验验证,表明HoloV在高效视觉令牌剪枝中有效保留了全局语义上下文,显著提升了高剪枝率下的模型性能。该研究为多模态模型的高效推理提供了新思路,强调了视觉整体理解在令牌压缩中的重要性。
未来研究方向:
-
自适应分块策略
-
多模态扩展(如3D数据)
-
与幻觉缓解机制的集成
九、整体评价与讨论
优点
-
引入全局上下文保留机制,理论上有界误差保障语义一致性
-
在多个任务和模型上均优于现有方法
-
实现效率与性能的良好平衡
局限性与改进方向
-
分块策略依赖固定划分,难以适应复杂场景的细粒度语义结构
-
极端剪枝率下仍存在精度下降
-
建议探索动态分块机制、结合稀疏注意力技术
-
优化上下文重提取的触发策略,提升边缘设备适用性

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)