
【具身智能】Evo-1:超越 SmolVLA,让具身萌新也能简单上手
轻量化:0.77B 参数,大幅降低训练 / 部署成本;免预训练:无需大规模机器人数据,数据收集成本骤降;强泛化:两阶段训练保护语义表征,面对干扰(如背景变化、目标移位)仍稳定;高实用:实时推理 + 低显存,适配消费级 GPU 和真实机器人场景。为推动未来研究,作者团队公开了代码、训练数据和模型权重,以鼓励轻量级高性能 VLA 模型的进一步研究与实际开发。
Evo-1:超越 SmolVLA,让具身萌新也能简单上手
关键词:#具身智能 #VLA
- 论文题目:Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
- arXiv:2511.04555
- 单位:上海交大
- https://github.com/MINT-SJTU/Evo-1
- 更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/Q0LY44qCCBlC74dt0Nmtag

::: block-1
- 仿真实验:Meta-World、LIBERO、RoboTwin
- 真机:配备平行夹爪的 6-自由度 xArm6 机械臂
:::
现阶段的 VLA 普遍高达十几亿参数,在部署的时候往往需要实验室有 4090 这样的算力。但是很多刚开始具身入门的课题组/萌新并没有这么好的条件。而 Evo-1 仅用 0.77B 参数,部署时只需 2.3GB 显存,即可达到 16.4hz 推理频率,可以在自己的笔记本上控制机械臂。
研究背景
VLA 模型是能够同时理解视觉(摄像头画面)、语言(人类指令)并输出动作(机器人控制信号)的统一模型,让机器人能像人一样"看"懂场景并执行指令。
现有模型的痛点:
- 参数量巨大:动辄数十亿参数,训练和部署成本极高;
- 语义漂移:端到端训练会破坏视觉 - 语言 backbone 的语义表征,泛化差;
- 数据依赖:严重依赖大规模机器人数据,收集成本极高。
Evo-1 架构
Evo-1 的目标:在保持甚至提升性能的前提下,让VLA模型更轻、更快、更易部署。
Evo-1 采用了一种模块化的 VLA 架构,该架构在统一且计算高效的框架内整合了感知、推理和控制。该架构包含 3 个核心组件:
- 一个视觉-语言主干网络,用于从视觉观测和文
本指令中编码多模态表示; - 一个跨模态调制扩散 Transformer,用于生成连续的动作;
- 一个集成模块,通过高效对齐多模态与本体感受表示,连接感知与控制。
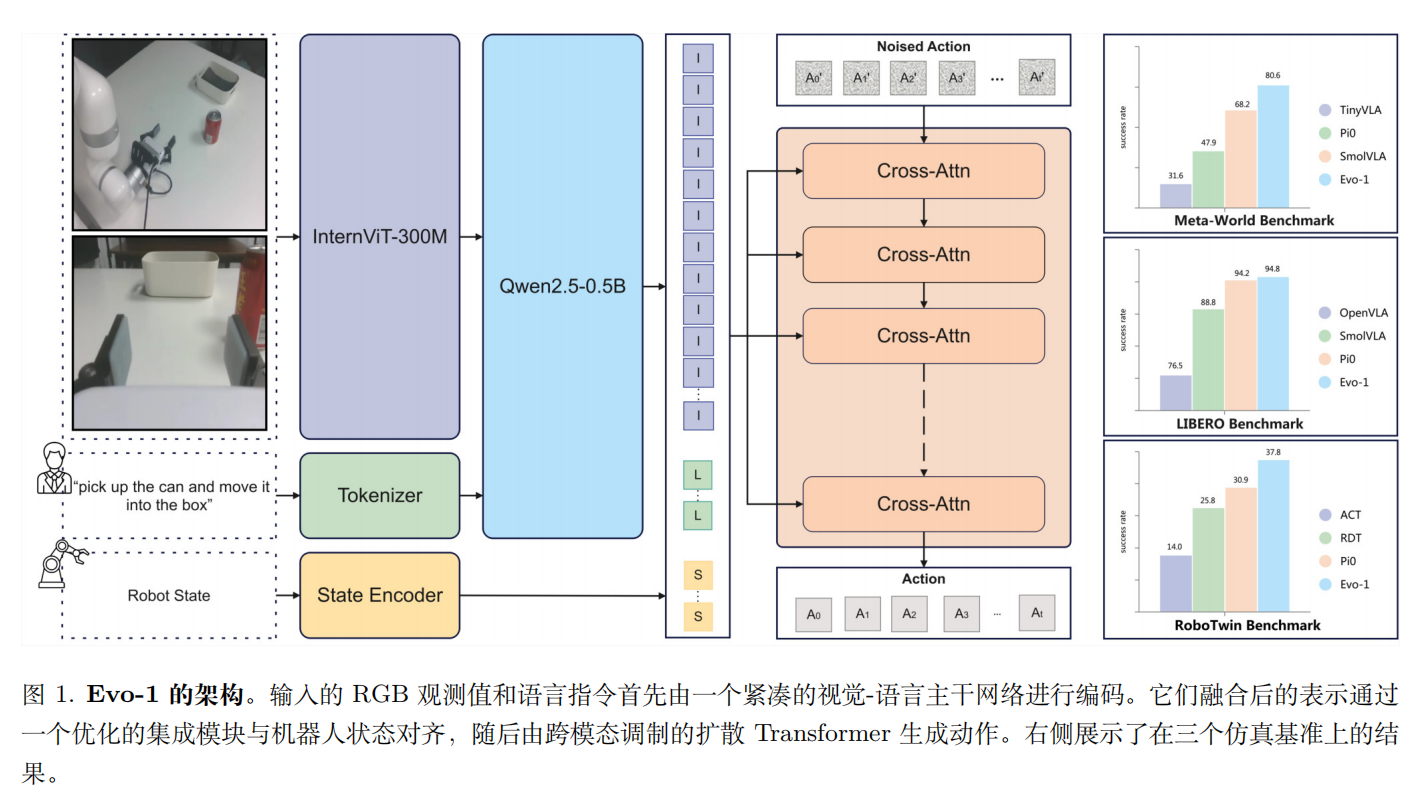
给定一组多视角视觉输入 {Iti}i=1N\{ I^i_t\}^N_{i=1}{Iti}i=1N,语言指令 LtL_tLt,以及机器人状态 sts_tst,视觉-语言主干网络生成多模态表示,这些表示通过融合模块传播,并与交叉调制扩散 Transformer 交互,从而产生最终的控制输出。整体映射可表示为:
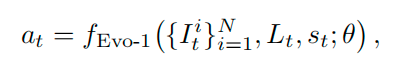
其中 at∈Rdaa_t \in \mathbb{R}^{d_a}at∈Rda 表示在时间 t 执行的连续动作向量,θ\thetaθ 表示整个模型的可学习参数。
该公式总结了 Evo-1 的端到端过程,在轻量且计算高效的框架内,有效连接了高层语义理解与低层运动控制。
视觉-语言主干网络
- 采用 InternVL3-1B 模型作为其视觉语言主干,该模型在原生多模态范式下进行了预训练,联合学习语言和视觉理解。
- 视觉编码器采用 InternViT-300M,这是一种通过逐层负余弦相似度损失从 InternViT-6B 提取的轻量级 Transformer。
- 语言分支利用了 Qwen2.5-0.5B,这是一个基于 Transformer 的解码器,拥有 0.5B 参数。
对于视觉-语言融合,InternVL3-1B 通过替换指定的 <img> 占位符 token,将图像块级嵌入插入到 token 序列中。
为了更好地将预训练的视觉语言模型适应于具身视觉-运动任务,我们仅保留语言分支的前 14 层,因为实验发现中间层在视觉特征与语言特征之间表现出更强的跨模态对齐性,使其在视觉-运动控制中更为有效。
跨模态调制扩散 Transformer
Evo-1 采用条件降噪模块作为 Action Expert,从视觉-语言骨干网络生成的融合多模态嵌入中预测连续控制动作。
遵循 Flow-Matching 范式,它学习一个时间相关的向量场,逐步将初始的噪声动作变换为目标真实动作。
具体而言,每个带噪声的动作序列 AtτA_t^{\tau}Atτ 通过在真实动作 AtA_tAt 与一个随机采样的噪声向量 ϵ\epsilonϵ 之间进行线性插值得到:
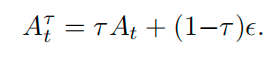
插值权重 τ\tauτ 从贝塔分布中采样,并限制在值域 [0.02, 0.98] 以确保训练过程中的数值稳定性。
训练期间,Action Expert 被优化以学习一个时间相关的速度场 vθv_\thetavθ,该速度场在多模态上下文 ztz_tzt 和机器人状态 sts_tst 下,将插值后的动作 AtτA_t^{\tau}Atτ 驱动至真实动作 AtA_tAt。该目标遵循 Flow-Matching 公式:
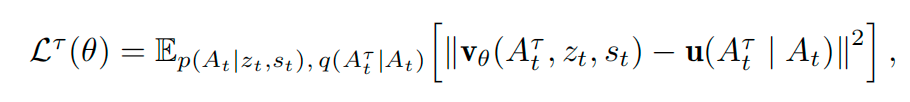
其中 u(Atτ∣At)\textbf{u}(A^\tau_t | A_t)u(Atτ∣At) 表示引导 AtτA^\tau_tAtτ 朝向 AtA_tAt 的目标流向。
推理时,最终的 action chunk A^t\hat{A}_tA^t 由动作专家预测,条件为融合表示 ztz_tzt、当前机器人状态 sts_tst 以及插值动作 AtτA_t^\tauAtτ:
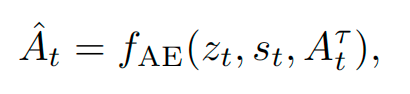
其中 fAEf_{AE}fAE 表示条件动作专家网络,该网络生成一系列 H 未来动作,旨在逼近真实动作序列 AtA_tAt。
集成模块
Evo-1 采用基于交叉注意力机制的融合模块,在条件化交叉调制扩散 Transformer 之前有效融合多模态与本体感觉信息。
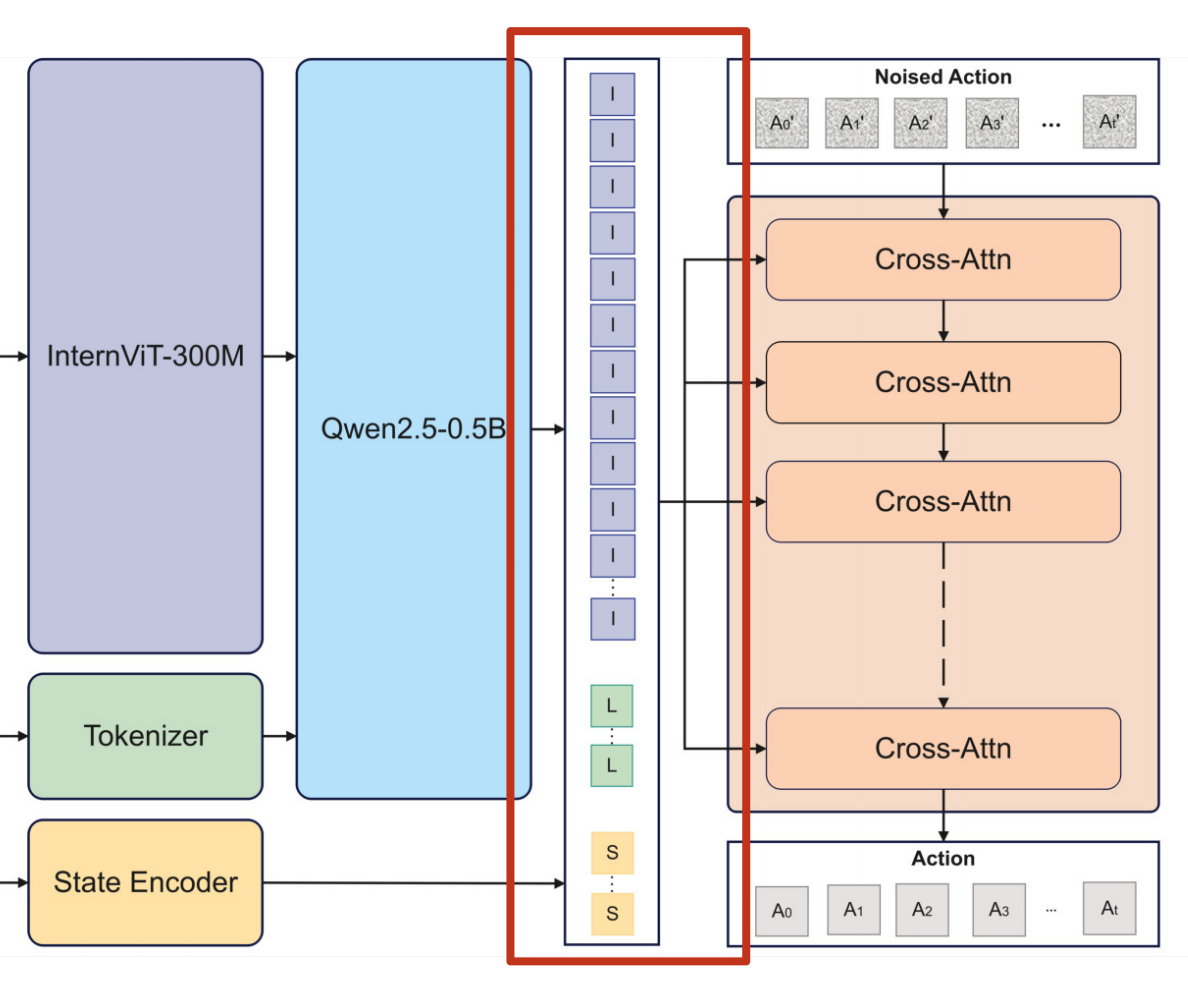
融合后的多模态表示 ztz_tzt 从视觉-语言主干网络的第 14th 层提取,捕捉介于视觉与语言特征之间的中层语义。为保留感知嵌入与机器人本体感觉状态的完整信息,我们选择将 ztz_tzt 与机器人状态 sts_tst 进行连结,而非将其投影到共享嵌入空间。该连结特征作为动作专家的 Transformer 块的键值输入,为动作生成提
供全局且信息保真的上下文。更多融合变体及其对比
结果详见消融研究。
Evo-1 两阶段训练流程
为了在保持视觉-语言主干模型固有的多模态理解能力的同时,将其适配到下游动作生成任务中,我们采用两阶段训练范式。
为什么需要两阶段:保留预训练的多模态语义对于维持模型在多样化视觉-语言场景下的泛化能力至关重要,可防止其过度拟合于特定操作任务。同时,对动作生成的有效适配是必要的,以确保融合的感知表示能够准确引导基于扩散的动作专家,从而提升下游控制任务的成功率。直接进行端到端训练可能会破坏预训练表示,削弱模型固有的多模态理解能力,并导致在特定下游任务上过拟合,最终损害其泛化能力。
阶段 1:Action Expert 对齐
在第一阶段,我们冻结整个 VLM 骨干网络,仅训练动作专家和融合模块。这种设置使得动作专家中的随机初始化权重能够逐渐与多模态嵌入空间对齐,而不会将噪声梯度反向传播至预训练骨干网络。结果,模型在全量微调之前,能够建立视觉-语言模型特征与动作专家之间的连贯对齐。
阶段 2:全规模微调
当集成与动作模块充分对齐后,我们解冻 VLM 主干网络,并对整个架构进行全规模微调。此阶段能够联合优化预训练的视觉-语言主干网络与动作专家,确保更深层次的融合以及对多样化操作任务更好的适应性。
保持多模态语义:为了进一步验证我们训练策略的优势,我们将 InternVL3-1B(来自 Evo-1 经过两阶段训练后)与 OpenVLA 中使用的 Prismatic-7B VLM 生成的图像-文本注意力图进行了比较。如图 2 所示,在机器人操作数据上训练后,InternVL3-1B 的嵌入保留了更清晰的结构和语义一致的注意力区域,而 Prismatic-7B 的嵌入则表现出显著的语义漂移和对齐性能下降。这一结果表明,我们的训练过程能够有效保持原始语义
空间,使模型在适应下游控制任务的同时,仍能维持强
大的视觉-语言理解能力。

实验
仿真实验
- Meta-World(单臂操作):成功率 80.6%,超之前最佳模型 12.4%;
- RoboTwin(双臂操作):成功率 37.8%,超之前最佳 6.9%;
- LIBERO(多类型操作):成功率 94.8%,比肩 3.5B 参数的大模型。
真实场景测试
使用配备平行夹爪的 6-自由度 xArm6 机械臂进行实验,并设计了四种涉及多样物体操作和实时交互的操作任务:
- 拾取与放置易拉罐。该任务要求从不同初始位置抓取一个饮料罐,并将其放入桌上的白色盒子中。
- 将泡沫从杯中倒出。该任务要求从不同的初始位置提起一个装有泡沫的杯子,并旋转杯子将泡沫倒入一个白色盒子中。
- 人工递送。该任务要求从不同位置抓取饮料罐,并轻轻放置到位于不同位置的人类手中。
- 堆叠。该任务要求抓取一个饮料罐并将其稳定地堆叠到另一个饮料罐上。两个罐子完全相同,并随机放置在桌面上。

对于每个任务,我们收集 100 次遥操作示范来构建训练数据集。在评估过程中,每个任务在不同物体配置下进行 20 次试验,以评估其稳定性和可靠性。
结果:4 类核心任务(捡放罐子、倒泡沫、递物、叠罐子):平均成功率 78%,超 SmolVLA(50%)、OpenVLA(55%),甚至优于 3.5B 参数的 π₀(73%)。
泛化实验
泛化实验以真实世界中的抓取并放置易拉罐任务作为基础场景进行。在每次试验中,机器人需要抓起桌面上的饮料罐,并将其放入一个白色盒子中。为了系统性地评估泛化能力,我们定义了四种干扰条件:(i) 添加一个未见过的干扰物体,(ii) 改变背景颜色,(iii) 移动目标位置,以及 (iv) 变化目标高度。所有这些变化均超出训练分布。每种干扰类型针对一个独特的方面,从而能够全面评估模型在多样化场景下的鲁棒性和泛化能力。我们为每种干扰条件进行了 20 次试验,以确保评估结果的统计可靠性。
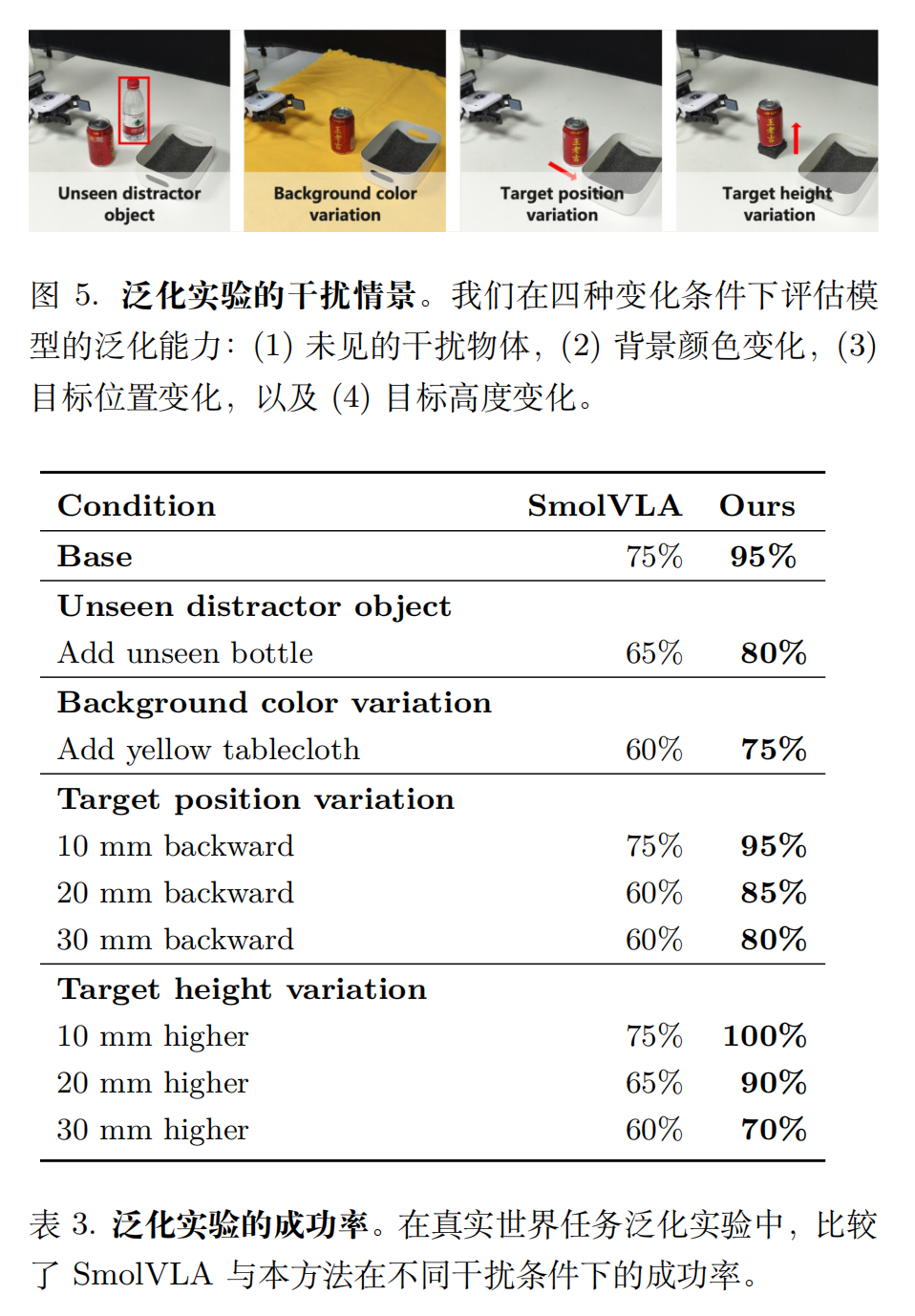
在高度变化条件下,Evo-1 保持优异性能(100%,90%,70%),展现出更强的泛化能力。
消融实验
- 集成模块:纯交叉注意力(Module A)效果最好,引入自注意力会打断信息流。
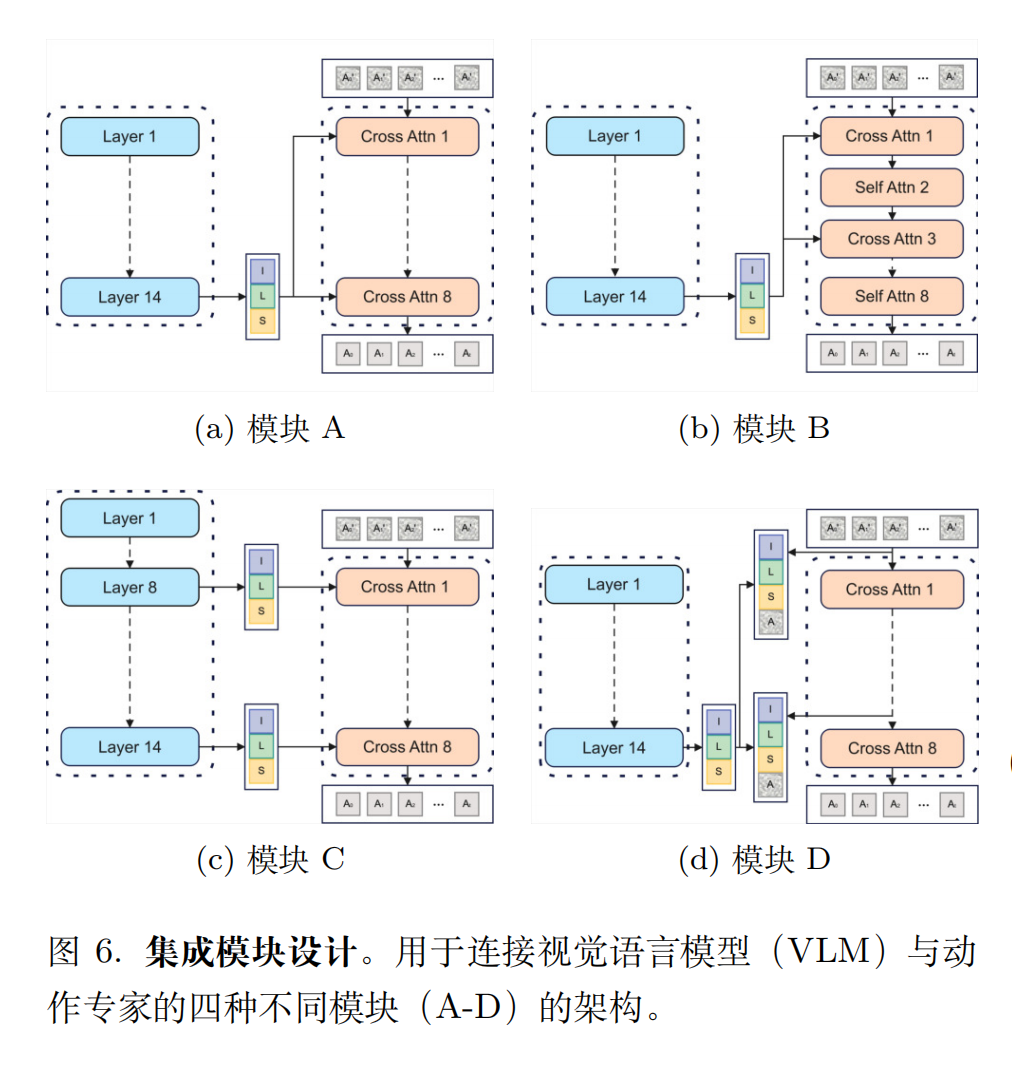
各个模块的介绍可以参考原论文。
- 训练范式:两阶段训练在所有难度级别上均优于单阶段
效率优势(消费级 GPU 即可部署)
- 推理频率 16.4Hz(实时响应),显存占用仅 2.3GB;
- 参数规模仅 0.77B,是同类 SOTA 模型的 1/4~1/10。
总结
- 轻量化:0.77B 参数,大幅降低训练 / 部署成本;
- 免预训练:无需大规模机器人数据,数据收集成本骤降;
- 强泛化:两阶段训练保护语义表征,面对干扰(如背景变化、目标移位)仍稳定;
- 高实用:实时推理 + 低显存,适配消费级 GPU 和真实机器人场景。
为推动未来研究,作者团队公开了代码、训练数据和模型权重,以鼓励轻量级高性能 VLA 模型的进一步研究与实际开发。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)