
InternVL 3.5:最佳开源多模态法学硕士
OpenGVLab/InternVL3_5-8B ·拥抱脸我们正在通过开源和开放科学推进人工智能并实现人工智能民主化。InternVL3.5 的核心是一个多模态视觉语言模型。这意味着它可以同时看到和阅读,处理图像,理解视频,解析密集的文档,根据所见回答问题,甚至遵循空间推理步骤。可以把它想象成拥有眼睛和大脑的人工智能,它开始真正从视觉上“理解”世界,而不仅仅是文本。但与早期的模型不同,早期模型将视
所以,事情是这样的。大多数人工智能世界都在忙于追赶 GPT-4V 或围绕“代理工作流程”玩公关游戏。与此同时,InternVL3.5悄然降临,它不仅仅是参加多式联运会,它基本上改写了资格标准。
是的,我称之为:
InternVL3.5 可能是目前最好的开源多模态模型。
不,这不是炒作。这就是基准测试、架构选择和一些感觉几乎非法的巧妙设计决策。
让我们来分解一下。
按 Enter 键或单击以查看大图
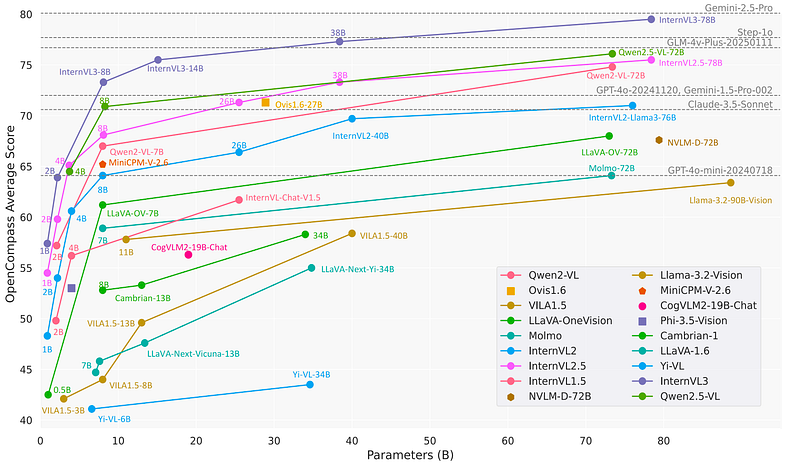
首先,什么是InternVL3.5?
OpenGVLab/InternVL3_5-8B ·拥抱脸
我们正在通过开源和开放科学推进人工智能并实现人工智能民主化。
InternVL3.5 的核心是一个多模态视觉语言模型。这意味着它可以同时看到和阅读,处理图像,理解视频,解析密集的文档,根据所见回答问题,甚至遵循空间推理步骤。
可以把它想象成拥有眼睛和大脑的人工智能,它开始真正从视觉上“理解”世界,而不仅仅是文本。
但与早期的模型不同,早期模型将视觉编码器固定在语言模型上并称其为“多模态”,这个模型实际上感觉是连贯的。它不仅仅是看像素和猜测,它实际上理解它正在查看的内容的结构和意图。
InternVL3.5 系列:型号变体概述
按 Enter 键或单击以查看大图
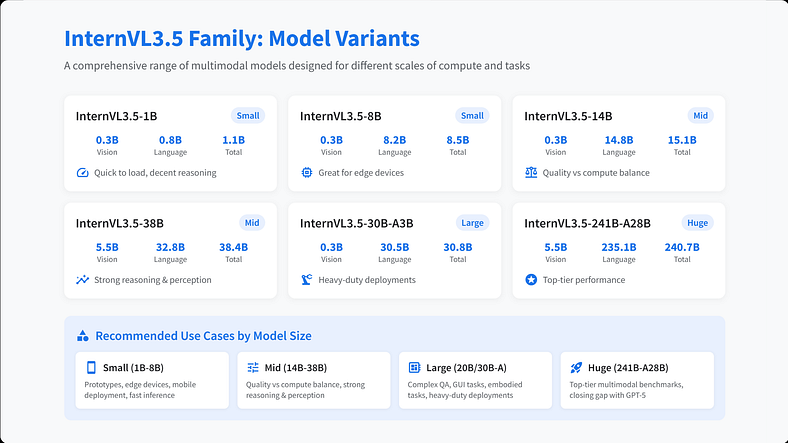
InternVL3.5 具有多种尺寸和格式,专为不同规模的计算和任务而设计。这是那里的内容:
模型比例变体(视觉 + 语言→总计)
- InternVL3.5–1B:0.3B 视觉 + 0.8B 语言→ ~1.1B 总计
- InternVL3.5–2B:0.3B + 2.0B → ~2.3B 总计
- InternVL3.5–4B:0.3B + 4.4B → ~4.7B 总计
- InternVL3.5–8B:0.3B + 8.2B → ~8.5B 总计
- InternVL3.5–14B:0.3B + 14.8B → ~15.1B 总计
- InternVL3.5–38B:5.5B + 32.8B → ~38.4B 总计
- InternVL3.5–20B-A4B:0.3B + ~20.9B→标记为“21.2B-A4B”
- InternVL3.5–30B-A3B:0.3B + ~30.5B →“30.8B-A3B”
- InternVL3.5–241B-A28B:5.5B + ~235.1B →“240.7B-A29B”
为什么您可能使用每种变体
- 小尺寸 (1B–8B):加载速度快,推理能力不错,非常适合原型、边缘或低资源设置。
- 中等尺寸 (14B–38B):质量与计算的最佳点。在推理和感知基准方面很强。
- 大型(20B/30B-A 变体):适用于重型部署、更多模式、复杂的 QA、GUI 和具体任务。
- 巨大(241B-A28B):在所有多模态基准测试中都具有顶级性能,缩小了与 GPT-5 等闭源巨头的差距。想想代理、多模式副驾驶。
- 闪存:对于受限的硬件、移动部署或快速推理,仍然相当敏锐
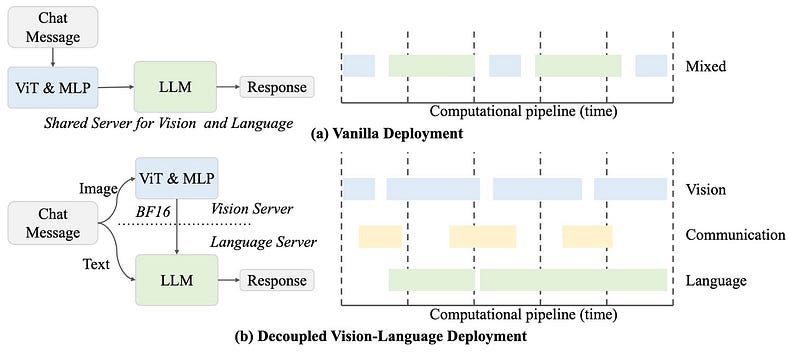
建筑:幕后有什么?
按 Enter 键或单击以查看大图
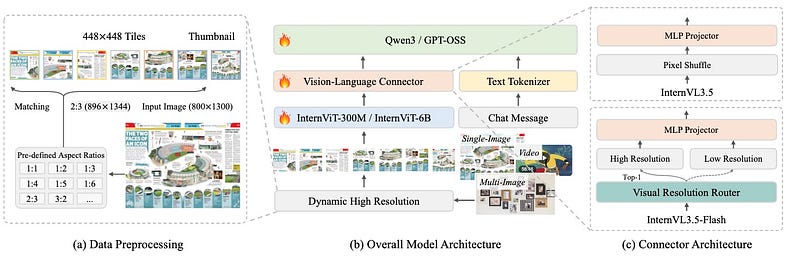
InternVL3.5 使用多组件架构,像一个精心调谐的管弦乐队一样拼接在一起:
按 Enter 键或单击以查看大图

- 图像编码器:EVA-CLIP-E4G(EVA 家族的野兽)将图像处理成视觉标记。它在 CC12M、LAION 等庞大的视觉语言数据集上进行了预训练。
- Q-Former:将其视为将视觉与语言保持一致的翻译器。它会在将正确的视觉信息发送给 LLM 之前获取正确的视觉信息。
- 语言骨干:InternLM2–8B(或大规模的 MoE 版本)。该模型以强大的推理而闻名,当与 Q-Former 配对时,它可以处理复杂的指令。
- 训练配方:他们混合使用多阶段预训练:
分别预训练视觉和语言部分。
将视觉语言任务(如字幕、VQA、OCR 密集型文档和引用表达式)融合和训练。
5. 视觉指令调整:特殊阶段,训练模型遵循人类风格的图像和文档提示。这就是让它感觉更“对话”而不是机器人的原因。
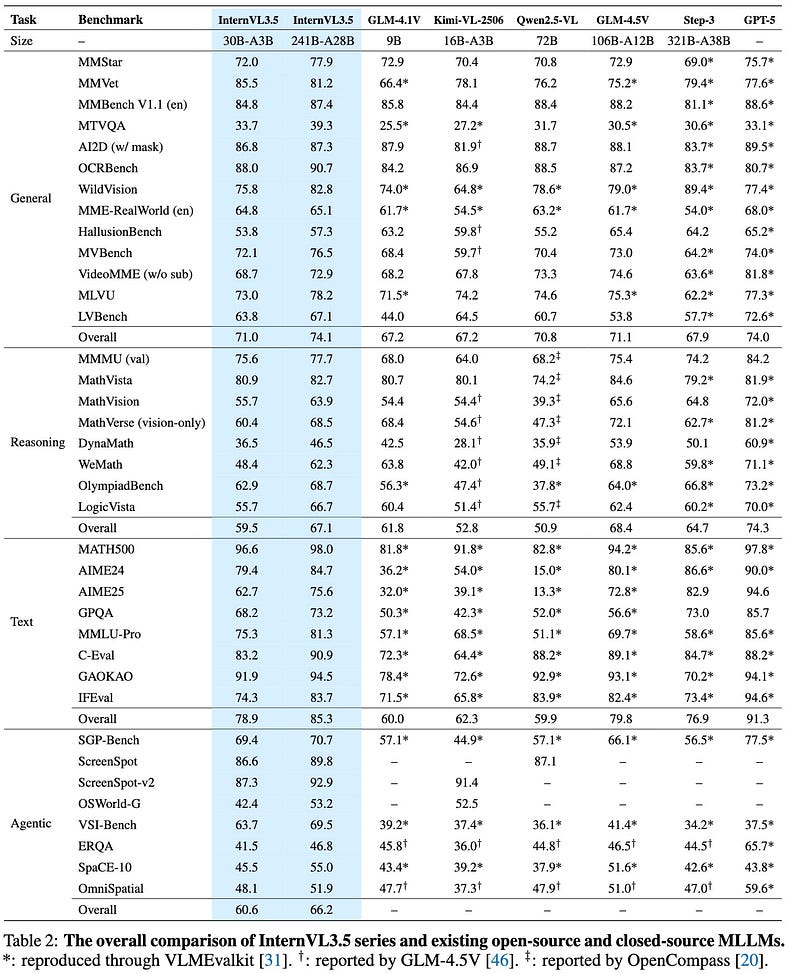
基准测试:它打破了什么
按 Enter 键或单击以查看大图
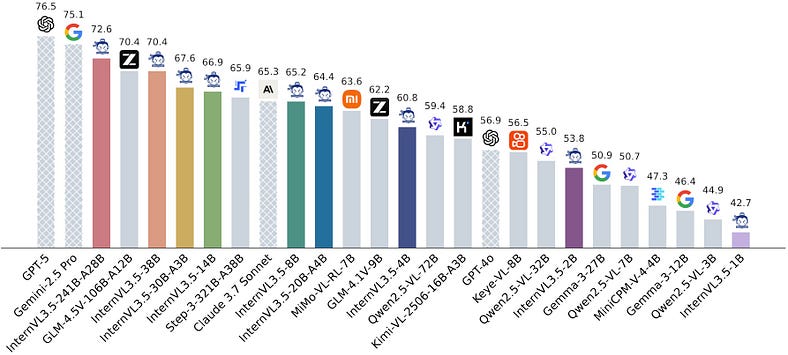
InternVL3.5 正在悄悄地在几个排行榜上杀死它。它在 MMMU 上是 #1,在 ChartQA 上是 #1,在 DocVQA、ScienceQA、TDIUC 和 MMVet 上接近顶部。
一些真正的佼佼者:
- MMMU(多模态多任务统一基准测试):击败 GPT-4V、Claude 3、Gemini Pro 1.5 和 LLaVA-Next。
- ChartQA:终于是一个可以像人类一样真正阅读图表而不是幻觉数字的模型。
- DocVQA:对于大多数法学硕士来说,使用 OCR 理解文档是一个已知的弱点。InternVL3.5 做到了这一点。
按 Enter 键或单击以查看大图
它有什么独特之处?
按 Enter 键或单击以查看大图
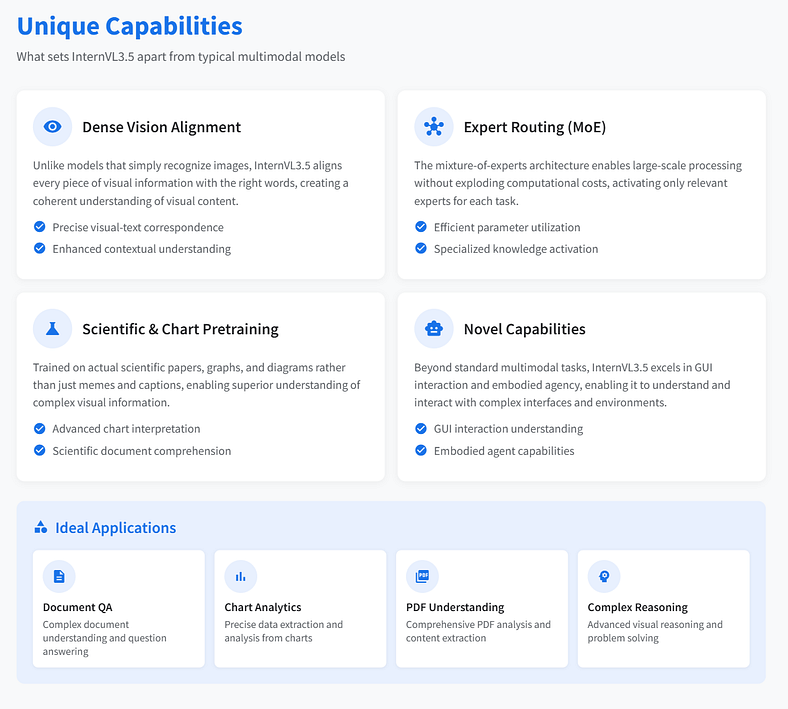
以下是 InternVL3.5 与典型的即插即用多模态模型的区别:
- 密集视觉对齐:它不仅仅是识别图像,还可以将每条视觉信息与正确的单词对齐。
按 Enter 键或单击以查看大图
- 专家路由(在 MoE 中):在不增加计算成本的情况下实现大规模处理。
- 科学和图表预训练:与大多数在模因和标题上训练的模型不同,这个模型已经看到了实际的图表、论文和图表。
- 开源,无付费专区:是的。那也是。
最后的思考
按 Enter 键或单击以查看大图
InternVL3.5 不附带烟花,但不需要烟花。它向我们展示了当你不试图取悦产品经理或赢得品牌战时,精心设计的、特定领域的预培训可以做什么。
如果您正在构建用于文档 QA、图表分析、PDF 理解或复杂图像推理的工具,那么在使用 GPT-4V 之前,该模型值得尝试。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)