
具身智能TL常用算法面经:生成式策略基础与 RL (四)
摘要 本文系统梳理了具身智能算法面试的核心要点,围绕动作生成与优化展开。首先解析了CVAE在ACT中的作用,强调其通过潜变量建模多峰动作分布的优势。然后深入对比了Diffusion Policy和Flow Matching的技术差异:前者通过联合分布建模动作轨迹,后者学习连续向量场实现高效推理。文章进一步探讨了RL算法(PPO/SAC/TD3)的选择策略,以及部署时的稳定性优化方法。最后总结了从模
1. 博客导读
这篇是具身智能算法基础面试的主战场。面试官如果从 VLA 模型继续往下追,通常会追到 动作如何生成、为什么用 action chunk、CVAE/Diffusion/Flow Matching 怎么选、RL 怎么后训练、PPO/SAC/TD3/离线 RL 有什么区别,以及部署时如何保证动作稳定。
建议按下面顺序看:
- 先理解 action chunk + CVAE/ACT:为什么机器人策略不能只做单步 MSE 回归。
- 再理解 Diffusion Policy、Flow Matching、Consistency Model:这是 2024-2026 VLA 动作头和生成式策略的核心。
- 再看 VLA action representation:RT-2/OpenVLA 的离散动作 token,Octo/Diffusion Policy 的连续轨迹,π0 的 flow matching action expert。
- 然后进入 RL 高频题:DDQN vs PPO、PPO clip/GAE、SAC/TD3、离线 RL、GRPO/RLHF、reward design。
- 最后补 部署和训练工程:动作抖动、不确定性、risk-aware training、LoRA、attention 复杂度、batch size 和学习率。
这篇目的不是罗列论文名,而是把面试中容易被深挖的算法问题串成一条线:先用模仿学习学会动作分布,再用生成式模型表达多峰轨迹,必要时用 RL/偏好优化做后训练,最后用控制和安全层保证真机可部署。
2. 阶段四总图谱:从动作生成到后训练
| 模块 | 代表方法 | 在机器人里的作用 | 面试重点 | 风险/短板 |
|---|---|---|---|---|
| 基础模仿学习 | BC、ACT、CVAE | 从示教数据学习动作或动作块 | compounding error、多峰动作、latent style | 容易学平均动作,OOD 状态恢复弱 |
| 扩散策略 | Diffusion Policy、DDIM、DPM-Solver | 条件生成连续 action chunk | joint distribution、去噪目标、receding horizon | 多步采样慢,部署需优化 |
| 流匹配策略 | Flow Matching、π0 action expert | 学噪声到动作的连续向量场 | velocity field、ODE 积分、连续动作头 | 训练/实现复杂,稳定性依赖设计 |
| 少步生成 | Consistency Model、蒸馏 | 把多步生成压到少步/一步 | 延迟、质量-速度权衡 | 蒸馏质量和鲁棒性要验证 |
| 在线 RL | PPO、SAC、TD3 | 用环境反馈优化成功率和恢复能力 | on-policy/off-policy、entropy、critic 稳定性 | 真机采样贵,探索危险 |
| 离线/批量 RL | CQL、IQL、AWAC/AWR | 从历史轨迹中超过行为策略 | distribution shift、保守 Q、advantage weighting | 数据覆盖不足时容易外推错误 |
| 大模型后训练 | DPO、PPO、GRPO、RLHF/RLAIF | 用偏好、规则 reward 或成功预测器对齐 VLA | value model、relative advantage、reranking | 不能直接照搬 LLM 到低层控制 |
| 部署稳定性 | smoothness loss、MPC/CBF、uncertainty | 约束动作抖动和风险 | jitter、risk-aware、Lyapunov 边界 | 端到端神经策略难形式化证明 |
3. Q1:ACT/action chunking 为什么重要?CVAE latent style 在 ACT 里有什么作用?
3.1 面试官问法
- ACT 为什么不用普通 Transformer 回归?
- CVAE 的 latent 表示什么?
- VAE loss 怎么写?
3.2 考察点
这是基础生成模型题。面试官会看你是否理解“多解动作”和“平均动作问题”。
3.3 30 秒回答
CVAE(Conditional VAE,条件变分自编码器)在 ACT 里用于建模同一观测下多种合理动作风格。训练时 encoder(编码器) 看专家 action chunk(动作块),把轨迹压成 latent(潜变量) z z z;decoder(解码器) 根据图像、状态和 z z z 重建动作 chunk。这样模型不会只用 MSE(Mean Squared Error,均方误差) 学成平均动作,而能表达不同示教风格或路径选择。
3.4 2-3 分钟展开回答
VAE(Variational Autoencoder,变分自编码器) 的基本思想是用 latent variable(潜变量) z z z 表示数据背后的隐含因素。普通 autoencoder(自编码器) 只学编码和重建,VAE 额外约束 z z z 接近一个 prior distribution(先验分布),比如标准高斯,这样推理时可以从先验采样。
CVAE 是 conditional VAE(条件 VAE)。机器人里条件 c c c 可以是图像、语言、机器人状态;目标 x x x 是未来动作 chunk。训练目标通常包括两部分:
$$
L = \mathrm{reconstruction_loss}(\mathrm{action_chunk}, \mathrm{predicted_action_chunk})
- \beta \cdot \mathrm{KL}(q(z \mid \mathrm{action_chunk}, \mathrm{condition}) ,|, p(z \mid \mathrm{condition}))
$$
在 ACT 中, z z z 可以理解成示教风格或局部轨迹模式。例如同一个抓取任务,可以从左边接近,也可以从右边接近;可以先抬高手臂再伸过去,也可以直线接近。没有 latent 时,MSE 可能把多个模式平均成一个不可执行轨迹。
推理时没有专家动作,所以不能用 posterior encoder(后验编码器),只能从 prior(先验分布) 采样或用 z z z 的均值。实际项目里为了稳定,很多时候会取均值而不是随机采样。
3.5 常见追问
- posterior collapse 是什么?
- KL 权重怎么调?
- CVAE 和 diffusion 都能建模多峰,区别是什么?
3.6 高分追问回答
Posterior collapse(后验坍塌) 指 decoder 太强,模型忽略 z z z,导致 latent 不携带动作风格信息。可以通过调小 KL 权重、KL annealing(KL 权重退火,逐步增大 KL 项权重)、限制 decoder、增大 latent 作用路径来缓解。CVAE 推理快、工程简单,但分布表达不如 diffusion/flow 强;diffusion 更适合复杂连续轨迹,但推理更慢。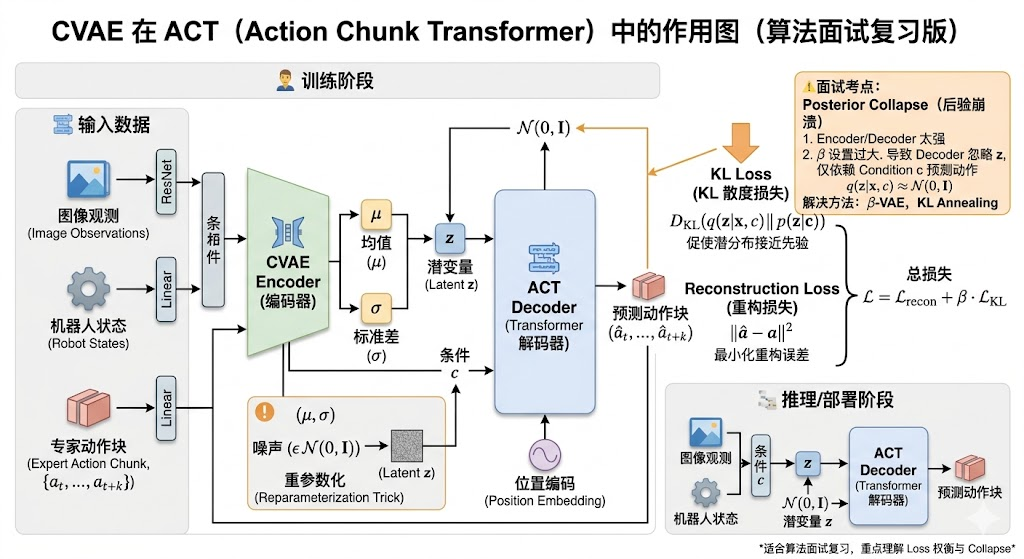
4. Q2:Diffusion Policy 是如何建模 action space 的?joint distribution 还是 marginal?
4.1 面试官问法
- Diffusion Policy 建模的是单步动作还是轨迹?
- 它是 joint distribution 还是每一维独立?
- 为什么 diffusion 比 BC 更适合多峰动作?
4.2 考察点
这是扩散策略核心题。回答要明确:通常建模未来 action chunk 的联合分布。
4.3 30 秒回答
Diffusion Policy(扩散策略)通常建模未来一段 action chunk 的 conditional joint distribution(条件联合分布) p ( a t : t + H ∣ o b s , s t a t e , l a n g ) p(a_{t:t+H} \mid \mathrm{obs}, \mathrm{state}, \mathrm{lang}) p(at:t+H∣obs,state,lang),不是每个时间步或每个维度独立建模。训练时给真实动作轨迹加噪,模型学习在观测条件下 denoise(去噪);推理时从高斯噪声开始,多步去噪得到连续动作轨迹。
4.4 2-3 分钟展开回答
机器人动作不是独立标量。末端位移、旋转、夹爪开合和时间步之间有强相关性。比如抓取时,手先接近,夹爪再闭合,然后抬起;如果每个动作维度独立预测,很容易破坏这种时序结构。
Diffusion Policy 把整个 action chunk 当成一个高维样本。训练时随机采一个噪声等级,把真实动作 chunk 加噪成 noisy action(带噪动作),再让模型预测噪声或干净动作。模型条件包括视觉特征、机器人状态、语言指令和 diffusion timestep(扩散时间步)。
它比 BC 更适合多峰动作,是因为BC 的 MSE 对多模态分布会学均值,而 diffusion 能从噪声采样出不同模式。比如绕障碍物时,左绕和右绕都是合理解,平均轨迹可能撞障碍;生成模型可以保留两个模式。
4.5 常见追问
- 推理时每次采样不同,机器人会不会不稳定?
- 如何控制 diffusion policy 的动作平滑?
- 采样步数太多怎么办?
4.6 高分追问回答
部署时通常不会无限随机采样,可以固定 seed(随机种子)、low-temperature sampling(低温采样,降低随机性)、选择高置信轨迹或用 receding horizon(滚动时域,只执行前几步再重规划)。平滑性来自三个层面:训练数据本身平滑、生成整个 action chunk、loss 中加入速度/加速度 penalty(惩罚项) 或用 temporal ensemble。采样慢可以用 DDIM(确定性扩散隐式模型采样)、少步 sampler(采样器)、distillation(蒸馏)、consistency model 或 flow matching。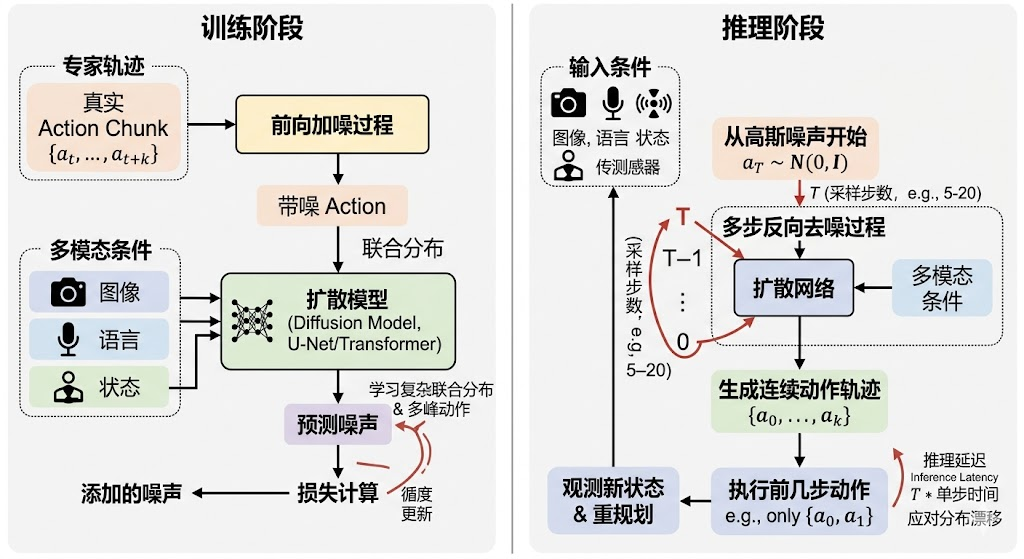
5. Q3:Flow Matching 是什么?和 Diffusion/DDIM 的区别是什么?
5.1 面试官问法
- Flow matching 怎么解释?
- π0 为什么用 flow matching?
- Flow matching 和 diffusion 本质区别是什么?
5.2 考察点
这是 2025-2026 VLA 高频基础。面试官想看你是否能用直觉解释,而不是只背公式。
5.3 30 秒回答
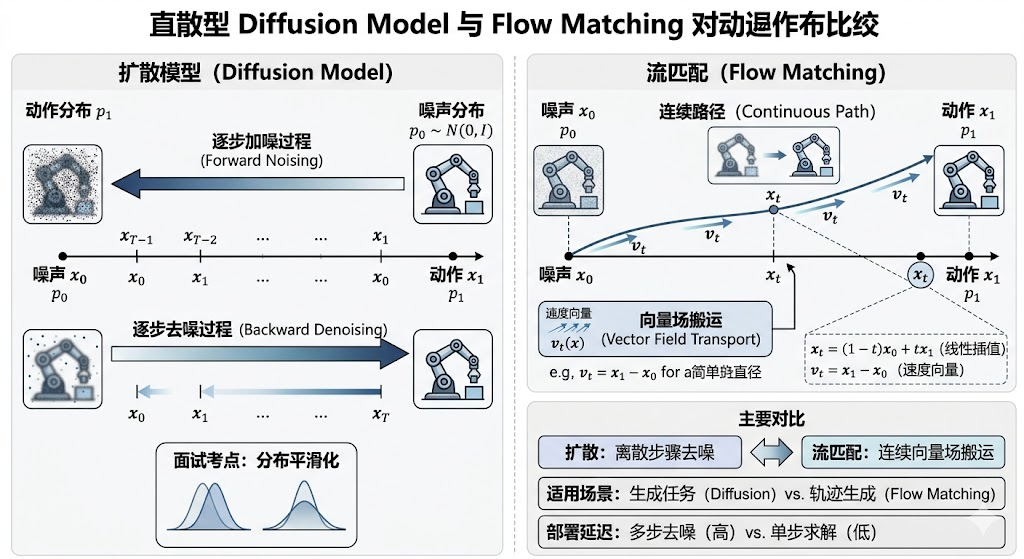
Flow Matching(流匹配)学的是一个连续时间 vector field(向量场),把简单噪声分布中的样本沿着流搬运到真实动作分布。Diffusion 更常见的说法是逐步加噪和逐步去噪;flow matching 直接监督中间路径上的 velocity field(速度场)。对机器人动作来说,它适合生成连续 action chunk,并且有少步推理潜力。
5.4 2-3 分钟展开回答
可以用 “搬运” 来理解 flow matching。假设起点是高斯噪声 x 0 x_0 x0,终点是真实动作轨迹 x 1 x_1 x1。我们在中间时间 t t t 构造一个插值点 x t x_t xt,模型学习此时应该沿哪个方向移动,也就是速度 v t v_t vt。推理时从噪声出发,沿模型预测的速度场积分,最后到达动作轨迹。
Diffusion 的训练常围绕噪声预测或 score matching(分数匹配),推理是反向去噪过程。Flow matching 则更直接地学习从源分布到目标分布的向量场。两者都可以看作生成模型,但训练目标和采样路径表述不同。
机器人里使用 flow matching 的原因:
- 动作是连续轨迹,向量场生成很自然。
- 可以输出 action chunk,适合低频策略 + 高频控制器。
- 相比传统多步 diffusion,有潜力用更少步数得到可用动作。
- 易于和 VLM 条件结合,让语义上下文调制动作生成。
5.5 常见追问
- Flow matching 是不是一定比 diffusion 快?
- 一致性模型和 flow matching 有什么不同?
- Flow matching 训练需要什么监督?
5.6 高分追问回答
不一定。Flow matching 有少步推理潜力,但实际速度取决于网络大小、积分步数、稳定性和部署优化。Consistency model(一致性模型) 更像把多步生成过程蒸馏成少步映射,目标是快速采样;flow matching 是直接学习连续向量场。训练监督来自真实动作样本和构造的噪声-数据路径,不需要 RL reward。
6. Q4:一致性模型/流匹配如何加速 VLA 推理?和 DDIM 蒸馏区别是什么?
6.1 面试官问法
- 多步 diffusion 太慢,你怎么加速?
- Consistency model、DDIM、flow matching 的关系是什么?
- 加速会不会牺牲动作质量?
6.2 考察点
这是生成模型和部署结合题。回答要落到机器人推理延迟。
6.3 30 秒回答
加速思路有三类:用 DDIM/少步 sampler 减少去噪步数;用一致性模型把多步生成蒸馏成一步或少步;用 flow matching 学向量场并用少步 ODE 积分生成动作。区别在于DDIM 是换采样路径,consistency 更偏蒸馏快速映射,flow matching 是训练时直接学搬运速度场。
6.4 2-3 分钟展开回答
Diffusion Policy 的问题是每次推理要多步去噪。如果机器人控制频率是 10-30Hz,多步采样会成为瓶颈。加速可以从模型、采样和系统三层做。
采样层:DDIM 或 DPM-Solver(扩散概率模型求解器) 类方法减少采样步数,从几十步降到几步。优点是简单,缺点是步数太少可能动作质量下降。
模型层:Consistency model 把一个多步生成过程蒸馏成少步映射,让模型在不同噪声水平上输出一致结果。优点是推理快,缺点是蒸馏数据和 teacher(教师模型) 质量很关键。
训练目标层:Flow matching 直接学习从噪声到动作的速度场,推理时通过 ODE(Ordinary Differential Equation,常微分方程) 积分生成。它不等同于 DDIM,也不只是蒸馏,而是另一种生成建模目标。
系统层:即使生成模型本身不够快,也可以用 action chunk 和异步推理。机器人执行当前 chunk 时,后台生成下一段,降低等待时间。
6.5 常见追问
- 少步采样导致动作不稳定怎么办?
- 机器人实时控制是否必须一步生成?
- 加速后怎么评估?
6.6 高分追问回答
实时控制不一定要求一步生成,因为策略频率和低层控制频率可以分开。比如策略 5-10Hz 输出 chunk,低层控制器 100-1000Hz 插补执行。加速后不能只看 inference time,还要看成功率、轨迹平滑、碰撞率、恢复能力和长任务完成率。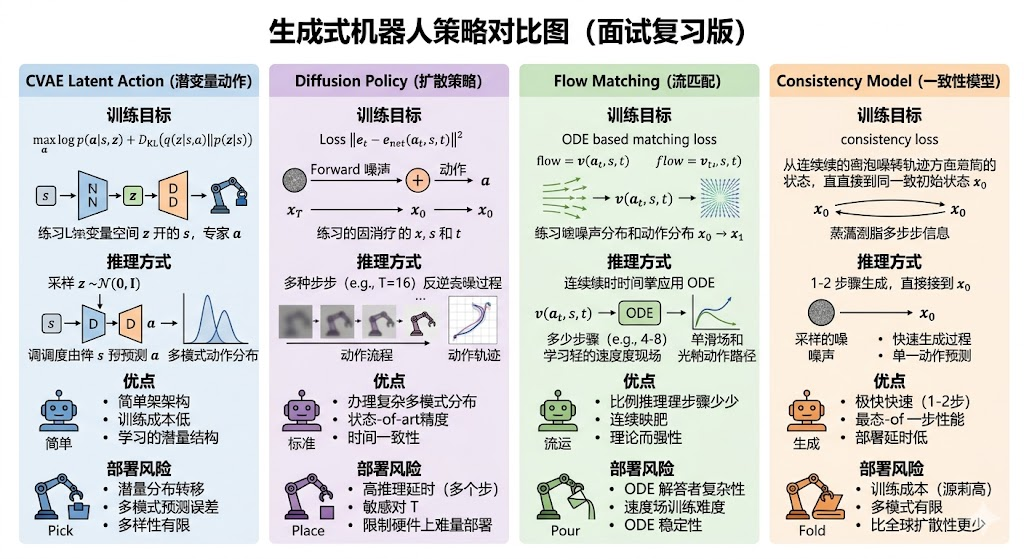
7. Q5:VLA 的动作头怎么选?离散 action token、diffusion 和 flow matching 怎么对比?
7.1 面试官问法
- RT-2/OpenVLA 为什么把动作离散成 token?
- Octo/Diffusion Policy/π0 为什么更强调连续 action chunk?
- 如果换机器人平台,action head 要怎么适配?
7.2 考察点
这是近期 VLA 高频题。面试官想看你是否理解:VLM 语义能力和低层连续控制不是同一个问题,动作表示会直接影响控制精度、泛化和部署延迟。
7.3 30 秒回答
**VLA 的动作头本质是在回答“语言视觉表示怎么变成机器人可执行动作”。**RT-2/OpenVLA 这类路线把动作离散化成 token,优点是能复用 LLM 自回归训练范式,工程统一;缺点是连续控制精度受 binning/action schema 影响。Diffusion/Octo/π0 这类路线更强调连续 action chunk,能更自然建模多峰轨迹和平滑控制;其中 π0 用 flow matching action expert,把预训练 VLM 的语义表示接到连续动作生成上。
7.4 2-3 分钟展开回答
离散动作 token 的优点是统一。图像、语言和动作都可以进同一个 token 序列,训练目标类似 next-token prediction,所以能直接利用大模型工具链和预训练能力。缺点也明显:机器人动作本来是连续的,平移、旋转、夹爪、关节速度被离散化以后,精度和动作平滑性依赖 bin 数、动作归一化和控制频率。
连续动作头的优点是更贴近控制。Diffusion Policy、Octo 或 flow matching policy 通常输出未来一段 action chunk,而不是单个 token。这样可以建模时间相关性、多峰路径选择和轨迹平滑。π0 的代表性在于:VLM 负责理解图像和语言,flow matching action expert 负责生成连续动作轨迹。
如果换机器人平台,核心问题不是只改 prompt,而是 action schema 变了:末端位姿、关节空间、夹爪、双臂同步、移动底盘都有不同维度和归一化方式。实际项目中通常需要重新训练或微调 action head / adapter,并重新计算数据统计量;LoRA 只能帮助适配 backbone,不一定能解决动作空间不匹配。
7.5 高分追问回答
我会按任务选动作头:语义泛化强、动作频率不高、动作空间简单时,离散 token VLA 更容易搭建;高精度 manipulation、接触丰富、动作连续性要求高时,更倾向 diffusion/flow action chunk。工程上还要看推理频率:策略可以 5-10Hz 生成 chunk,低层控制器 100-1000Hz 跟踪插补,不要求大模型每个低层控制周期都推理一次。
8. Q6:DDQN 和 PPO 有什么区别?PPO 的优势函数怎么计算?
8.1 面试官问法
- DDQN 和 PPO 的区别是什么?
- PPO 的 advantage 怎么算?
- 为什么机器人里 PPO 比 DQN 类方法更常见?
8.2 考察点
这是强化学习基础。机器人动作通常连续,所以面试官会看你是否知道 value-based 和 policy-based 的区别。
8.3 30 秒回答
DDQN(Double Deep Q-Network,双重深度 Q 网络) 是 value-based(基于价值) 方法,主要适合离散动作,通过估计 Q 值选动作;PPO 是 policy-gradient(策略梯度) 方法,直接优化策略,适合连续动作控制。PPO 的优势函数常用 GAE(Generalized Advantage Estimation,广义优势估计) 计算,近似衡量当前动作比 value baseline 好多少。机器人连续控制里 PPO、SAC、TD3 这类方法通常比 DQN/DDQN 更常见。
8.4 2-3 分钟展开回答
DDQN 解决的是 DQN 的过估计问题,用 online network 选动作、target network 估值。它适合离散动作,比如 Atari。机器人控制常见动作是连续的末端位姿、关节速度或 torque,直接离散化会维度爆炸,所以 DQN 系列不常作为低层控制首选。
PPO 直接输出动作分布,比如高斯策略,然后用采样轨迹更新策略。Advantage 可以简单写成:
A t = R t − V ( s t ) A_t = R_t - V(s_t) At=Rt−V(st)
实践中常用 GAE:
δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
A t = ∑ l ( γ λ ) l δ t + l A_t = \sum_l (\gamma \lambda)^l \delta_{t+l} At=l∑(γλ)lδt+l
GAE 用 λ \lambda λ 平衡 bias(偏差) 和 variance(方差)。 λ \lambda λ 越接近 1,方差更大但偏差更小;越接近 0,更依赖一步 TD(Temporal Difference,时序差分),方差小但偏差大。
8.5 高分追问回答
如果面试官问 PPO 为什么在机器人里仍然难,答案是:真机采样贵、探索危险、reward 设计难、reset 成本高。PPO 本身稳定,但不等于适合直接在真机从零训练。更常见路线是仿真 RL + sim-to-real,或者先用模仿学习初始化再做 RL fine-tuning。
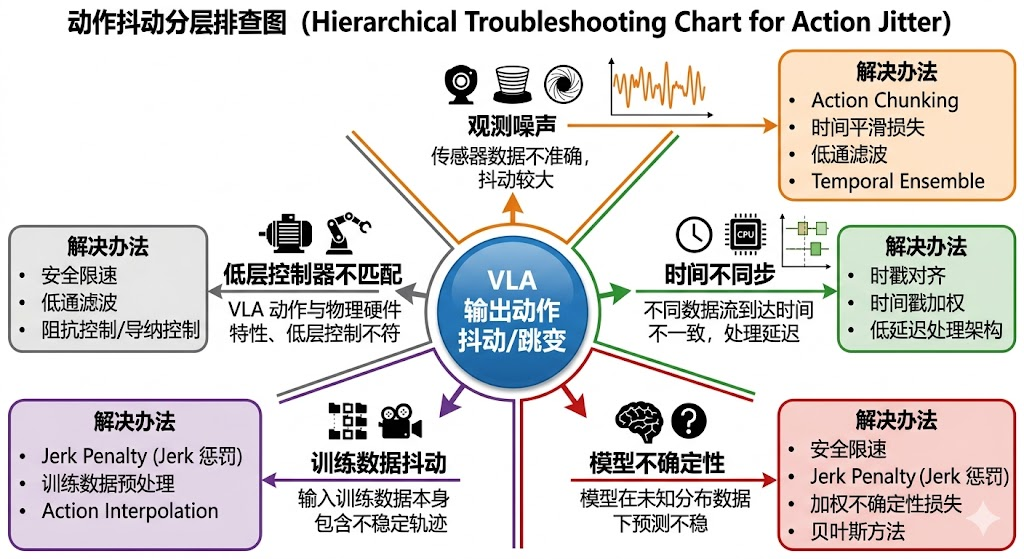
9. Q7:VLA 输出动作抖动/跳变,从模型层面怎么约束?
9.1 面试官问法
- 除了后处理滤波,怎么解决动作抖动?
- policy 输出波动大,你会在 policy 层加滤波还是 loss 层加 penalty?
- action drift 怎么防止?
9.2 考察点
这是模型和控制结合题。面试官不希望只听到“加低通滤波”。
9.3 30 秒回答
**我会先定位抖动来源,再分层处理。**模型层可以用 action chunk、temporal smoothness loss(时间平滑损失)、速度/加速度/jerk penalty(加加速度惩罚)、trajectory diffusion/flow、temporal ensemble(时间集成)、一致性正则和不确定性过滤。后处理滤波可以用,但它会引入滞后,所以不能作为唯一方案。
9.4 2-3 分钟展开回答
动作抖动可能来自观测噪声、时间不同步、模型不确定性、训练数据抖动、动作表示不连续或低层控制器不匹配。不同来源处理方式不同。
模型层面有几种方法:
- 预测 action chunk,而不是单步动作,让模型学习短轨迹结构。
- 在 loss 中加入 ∥ a t − a t − 1 ∥ \lVert a_t - a_{t-1} \rVert ∥at−at−1∥、加速度或 jerk penalty。
- 用 diffusion/flow 生成整段轨迹,建模时间相关性。
- 对重叠 chunk 做 temporal ensemble,减少边界跳变。
- 加 consistency regularization,让相邻观测输出一致。
- 用
uncertainty(不确定性)触发低速模式或fallback(失败兜底策略)。
滤波适合作为安全补丁,但会带来相位滞后。比如抓取接触瞬间,如果滤波过强,夹爪可能错过最佳闭合时机。因此高分回答要说**“先模型和数据,再工程滤波兜底”**。
10. Q8:PPO 为什么用 Clip 机制?它如何保证策略更新稳定?
10.1 面试官问法
- PPO 中 clip objective 怎么写?
- 为什么不用传统 KL 约束?
- Clip 机制怎么避免策略崩?
10.2 考察点
PPO 是具身智能/RL 基础高频题。回答要讲 ratio、advantage、trust region 的近似。
10.3 30 秒回答
PPO(Proximal Policy Optimization,近端策略优化) 用新旧策略概率比 r t ( θ ) r_t(\theta) rt(θ) 和 advantage(优势函数) 构造 clipped objective(截断目标函数),限制策略单次更新幅度。相比 TRPO(Trust Region Policy Optimization,信赖域策略优化) 的显式 KL 约束,clip 实现简单、无需二阶优化,对超参更鲁棒 。它 不是严格保证 KL 不超界,而是通过截断过大的概率比,降低策略更新过猛导致崩溃的风险。
10.4 2-3 分钟展开回答
PPO 的核心目标可以写成:
L c l i p = E [ min ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] L_{\mathrm{clip}} = \mathbb{E}\left[ \min\left( r_t(\theta) A_t, \mathrm{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right] Lclip=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中 r t ( θ ) = π θ ( a t ∣ s t ) / π o l d ( a t ∣ s t ) r_t(\theta) = \pi_\theta(a_t \mid s_t) / \pi_{\mathrm{old}}(a_t \mid s_t) rt(θ)=πθ(at∣st)/πold(at∣st)。如果 advantage 为正,说明这个动作比平均好,更新会提高它的概率;但如果提高太多,ratio(新旧策略概率比) 超过 1 + ϵ 1+\epsilon 1+ϵ,clip 会限制收益。advantage 为负时,策略会降低该动作概率,但降低过多也会被限制。
PPO 的直觉是 trust region(信赖域,限制策略每次不要变化太大)。TRPO 用 KL 约束显式限制新旧策略差异,但实现复杂;PPO 用 clip 做一阶近似,工程上更简单。
需要强调:clip 不是严格数学保证策略稳定。实践中仍要监控 KL(KL 散度)、entropy(熵,衡量策略随机性)、value loss(价值函数损失)、clip fraction(被截断样本比例)、reward 曲线和梯度。如果 KL 突然飙升,说明策略更新仍然过大。
10.5 常见追问
- PPO 训练崩了怎么 debug?
- entropy bonus 有什么用?
- PPO 在真机机器人上难在哪里?
10.6 高分追问回答
PPO 崩溃先看 KL、clip fraction、advantage scale、reward scale 和 value loss。如果 KL 大,降低学习率或 epoch;如果 entropy(熵) 掉太快,策略过早收敛;如果 value loss 爆炸,说明 critic 不稳。真机难点是采样贵、探索危险、reward 难设计、reset 成本高,所以常用仿真训练、离线数据初始化、safe RL 或只在高层策略上用 RL。
11. Q9:SAC/TD3 为什么在机器人连续控制里高频?和 PPO 怎么选?
11.1 面试官问法
- PPO、SAC、TD3 分别适合什么机器人任务?
- 为什么机器人连续控制常见 SAC/TD3?
- off-policy 比 on-policy 的优势和风险是什么?
11.2 考察点
这是 RL 工程题。很多候选人只背 PPO,但机器人真机采样昂贵,面试官会看你是否理解 sample efficiency、critic 稳定性、探索安全和 replay buffer。
11.3 30 秒回答
**PPO 是 on-policy,稳定、实现成熟,但样本效率低;SAC/TD3 是 off-policy actor-critic,能复用 replay buffer,更适合样本昂贵的连续控制。**SAC 加最大熵目标,鼓励探索并提升稳定性;TD3 用双 critic、延迟策略更新和 target smoothing 缓解 Q 过估计。机器人里如果是仿真大规模并行训练,PPO 很常见;如果是真机样本贵或需要复用历史数据,SAC/TD3/离线 RL 更值得考虑。
11.4 2-3 分钟展开回答
PPO 的优点是更新受 clip 限制,工程上比较稳,适合仿真里并行采样大量 rollouts,比如 locomotion 或高层策略。但它每次更新依赖当前策略采样的数据,旧数据很快不能再用,所以真机效率不高。
SAC 是 off-policy maximum entropy 方法。它同时最大化 reward 和 entropy,让策略不要太早变确定,从而增强探索和鲁棒性。因为可以使用 replay buffer,采样效率通常比 PPO 更高。TD3 也是 off-policy,重点解决 actor-critic 中 Q 值过估计:用两个 critic 取较小值、延迟 actor 更新,并对 target action 加平滑噪声。
选择时看约束:
- 仿真并行、reward 清楚、需要稳定 baseline:PPO。
- 连续控制、样本贵、希望复用数据:SAC/TD3。
- 数据主要来自示教或日志,不能在线探索:离线 RL 或 BC + conservative fine-tuning。
- VLA 后训练:通常不直接从零 RL,而是先 imitation/VLA 初始化,再在仿真或安全约束下做少量 RL。
11.5 高分追问回答
off-policy 的风险是 distribution shift。critic 会在数据覆盖不足的动作上外推错误,导致 actor 利用错误 Q 值。解决方法包括保守 Q 学习、限制策略偏离行为策略、用示教数据 warm start、加安全约束和只在仿真中做大范围探索。真机上我不会让随机探索直接接管低层控制,而会把 RL 放在 residual、高层 subgoal 或受限 action space 里。
12. Q10:离线 RL/CQL/IQL/AWAC 在机器人里解决什么问题?
12.1 面试官问法
- 只有历史示教数据,能不能用 RL 超过 BC?
- offline RL 和 behavior cloning 的区别是什么?
- CQL/IQL/AWAC 分别在防什么问题?
12.2 考察点
这是“从真实数据学习机器人策略”的高频方向。回答要抓住核心矛盾:离线 RL 想利用 reward 提升策略,但不能在线试错,所以最怕对数据外动作的 Q 值过度乐观。
12.3 30 秒回答
**离线 RL 试图只用固定数据集学习比行为策略更好的策略。**BC 只模仿数据中出现的动作,不直接优化 reward;offline RL 会用 reward/return 学价值函数,但会遇到 distribution shift(分布偏移) 和 Q 外推误差。CQL 倾向把数据外动作的 Q 压低,IQL 避免显式查询 OOD 动作,AWAC/AWR 用 advantage weighting 在不偏离数据太远的情况下强化好动作。
12.4 2-3 分钟展开回答
在机器人里,离线 RL 很有吸引力,因为真机探索贵且危险,而实验室往往已有大量 teleop、失败轨迹、仿真轨迹或历史日志。问题是:如果 actor 选了数据里没见过的动作,critic 没有真实反馈,只能外推;一旦 Q 被高估,策略就会朝不可执行动作跑。
几类方法的直觉:
- CQL:保守估计 Q,宁愿低估数据外动作,避免 actor 利用虚高 Q。
- IQL:通过 expectile value learning 和 advantage-weighted regression,尽量在数据分布内提升。
- AWAC/AWR:仍然像加权 BC,给高 advantage 的动作更高权重,降低偏离行为策略的风险。
和 BC 的区别是:BC 不需要 reward,稳定但可能复制次优行为;离线 RL 需要 reward 或成功标签,有机会从混合质量数据中提取更优行为,但对数据覆盖、reward 质量和保守性很敏感。
12.5 高分追问回答
我会先问数据质量:如果数据几乎都是专家成功轨迹,BC/ACT/Diffusion Policy 往往够用;如果数据里有失败、次优和恢复片段,离线 RL 才更有价值。部署前必须做离线 policy evaluation、仿真回放、OOD 检测和安全约束,不能只看离线 Q 值。
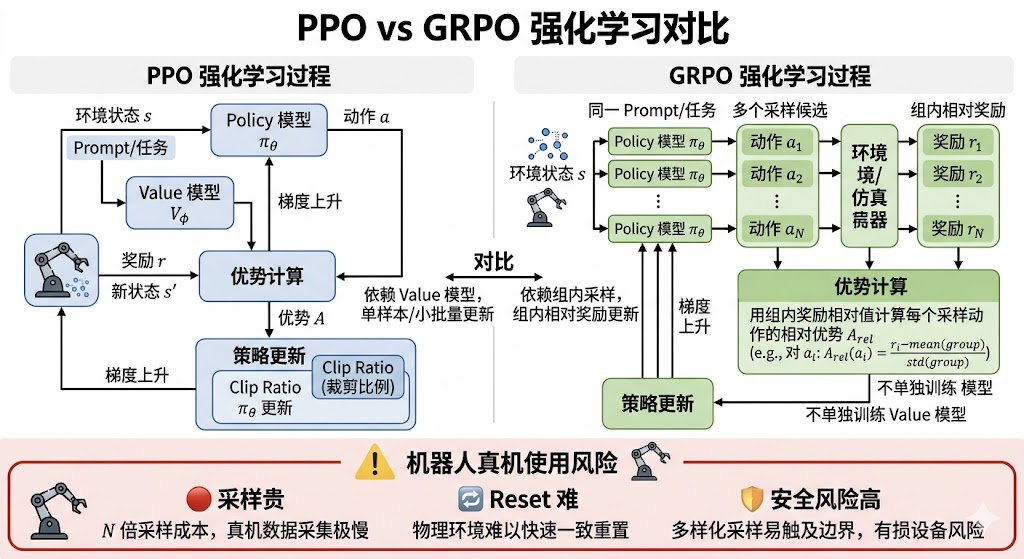
13. Q11:GRPO 和 PPO 的区别是什么?机器人里能不能用?
13.1 面试官问法
- GRPO 和 PPO 有什么区别?
- 为什么 GRPO 可以不用 value model?
- GRPO 适合 VLA 或机器人后训练吗?
13.2 考察点
这是大模型 RL 和机器人 RL 的交叉题。高分回答要避免把 LLM 的 GRPO 直接套到低层控制。
13.3 30 秒回答
PPO 通常用 critic/value model(价值模型) 估计 advantage;GRPO(Group Relative Policy Optimization,组相对策略优化) 用同一 prompt 下多条 sampled outputs(采样输出) 的组内相对奖励来估计 advantage,可以省掉 value model。它适合 LLM 这种可对同一问题采多条回答并比较奖励的场景。机器人里可以借鉴“组内相对排序”做高层策略或轨迹候选选择,但不宜直接替代低层连续控制的稳定 RL 框架。
13.4 2-3 分钟展开回答
PPO 的 advantage 通常来自 reward-to-go 减 value baseline。value model 的作用是降低方差,但也带来训练成本和误差。
GRPO 的思路是:对同一个输入采样一组输出,得到一组 reward,然后用组内均值和标准差归一化,构造相对 advantage。这样不需要单独训练 value model。这在 LLM reasoning(大语言模型推理任务) 中很自然,因为同一个数学题可以采多个答案,并用规则或 reward model(奖励模型) 打分。
机器人里使用要谨慎。低层连续控制的状态会被动作改变,采样多条轨迹代价很高,而且真机无法轻易 reset。GRPO 更适合:
- 高层任务规划候选排序。
- 仿真中多轨迹采样和相对奖励优化。
- VLA 输出多个 subgoal 或 action chunk 后做
reranking(重排序/候选轨迹再排序)。
如果直接用于真机低层控制,要解决安全、采样成本、状态一致性和 reset 问题。
13.5 常见追问
- GRPO 为什么在 LLM 中流行?
- 它和 rejection sampling 有什么区别?
- 如果用在 VLA 后训练,你会怎么设计?
13.6 高分追问回答
GRPO 在 LLM 中流行是因为它省 value model,适合按 prompt(提示词/任务输入) 采样多个候选并基于相对奖励优化。Rejection sampling(拒绝采样) 只筛选好样本再监督学习,不直接做策略梯度;GRPO 仍然更新策略概率。用于 VLA 后训练时,我会先在仿真或离线环境中生成多个候选 action chunk,用成功预测器、安全约束、轨迹平滑和任务 reward 打分,再谨慎更新高层或 action head。
14. Q12:RL 在 VLA 里怎么用?奖励函数怎么设计?
14.1 面试官问法
- VLA 里为什么还需要 RL?
- 奖励函数怎么设计?
- 真机 RL 最大困难是什么?
…详情请参照古月居

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐
 0
0 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)