
面向具身智能与机器人仿真的三维生成技术:一项综述解读
具身智能系统对三维内容的需求正从"视觉逼真"转向"仿真就绪"。香港科技大学领衔的研究团队系统梳理了面向具身智能与机器人仿真的三维生成技术,提出以"数据生成器—仿真环境—Sim2Real桥接"为核心的三角色分类体系,涵盖从仿真就绪资产生产、可交互世界构建到虚实迁移闭环的完整技术链路。
来源:arXiv:2604.26509v2 [cs.RO]项目主页:3dgen4robot.github.io研究团队:香港科技大学、武汉大学、哈尔滨工业大学等
**核心观点:**具身智能系统对三维内容的需求正从"视觉逼真"转向"仿真就绪"。香港科技大学领衔的研究团队系统梳理了面向具身智能与机器人仿真的三维生成技术,提出以"数据生成器—仿真环境—Sim2Real桥接"为核心的三角色分类体系,涵盖从仿真就绪资产生产、可交互世界构建到虚实迁移闭环的完整技术链路。
一、研究背景:为何需要仿真就绪的三维生成?
近年来,具身智能(Embodied AI)与机器人系统被期望在开放的物理环境中完成感知、推理与行动[1]。大规模策略学习、视觉-语言-动作(VLA)模型以及高保真仿真平台的快速发展,显著拓展了这些系统的能力边界[3-9]。然而,其性能从根本上受限于可扩展、多样化且支持交互的三维资产与环境的可用性。
与传统三维生成任务不同,面向具身应用的三维生成提出了更为严苛的要求:生成的柜子不仅需要外观逼真,还需要其门板围绕合理的关节旋转[13,14];生成的衣物不仅要有正确的形状,还需要在接触下发生符合物理规律的形变[15,16];生成的场景不仅要视觉连贯,还要支持在物理约束下的导航、交互与任务执行[17]。这些需求使得面向具身智能的三维生成成为一个远比视觉内容合成更广泛的课题。
在这一背景下,三维生成建模与面向机器人的仿真之间出现了快速融合。一方面,扩散模型、重建管线、大语言模型和多模态基础模型显著提升了从稀疏输入(如文本、图像或演示)生成几何、纹理、结构和语义的能力[18-20]。另一方面,机器人仿真对生成输出提出了额外要求,包括运动学结构、物理参数、材料属性、可供性语义,以及与URDF、MJCF等执行格式的兼容性[14,21]。因此,当前的核心问题已不再是"如何生成看似合理的三维内容",而是"如何生成可直接用于仿真的三维内容,以支持具身感知、规划、控制以及虚实迁移"。

图1 论文提出的三角色分类体系:数据生成器(Data Generator)、仿真环境(Simulation Environments)与Sim2Real桥接(Sim2Real Bridge),分别对应资产级创建、场景级合成与虚实迁移闭环。
二、数据生成器:仿真就绪资产的自动化生产
数据生成器模块关注如何利用生成模型生产可直接部署于物理引擎的物体与资产,其核心挑战并非视觉可信度,而是物理可部署性:生成的资产必须携带运动学约束、材料属性以及与仿真器兼容的格式[1]。该模块按照物理复杂度递增的顺序组织,涵盖关节型物体、物理 grounded 物体、可变形物体以及端到端仿真就绪管线。
2.1 关节型物体生成:从几何到运动学结构
关节型物体的生成需要同时建模几何外观与运动学结构。早期的重建类方法[103,104]主要从观测中恢复关节结构,但对未见类别的泛化能力有限。生成式方法则学习几何与运动结构的先验分布,以实现可扩展的关节资产创建[22,76,83]。
在结构拓扑与参数化方面,Kinematify[80]采用蒙特卡洛树搜索(MCTS)结合物理奖励来剪枝不可行的结构;GAOT[79]与NAP[22]利用层次化学习处理部件连接关系;UniArt[82]引入了Joint-to-Voxel表示,将运动学约束映射到连续三维体素中。对于运动参数估计,基于扩散的方法(如CAGE[23]、ArtFormer[72]、ArtiLatent[76])联合建模几何与运动学分布。MagicArticulate[49]将骨架生成重新表述为自回归序列建模,并结合功能扩散预测蒙皮权重,从而将静态网格转换为完全可驱动的资产。
近年来,大语言模型(LLM)与视觉语言模型(VLM)的语义先验被引入该领域。Articulate-Anything[13]采用VLM Actor-Critic框架并结合仿真器反馈;URDF-Anything[14]集成分割感知令牌以联合进行部件分解与运动预测;ArtLLM[84]、ArtiWorld[73]与SPARK[85]进一步利用语义推理进行关节推断。URDFormer[67]直接从图像回归URDF参数;Real2Code[69]通过LLM合成可执行的运动程序;URDF-Anything+[50]则将这一过程扩展为端到端的自回归URDF生成。
2.2 物理 grounded 物体生成:从后处理到原生统一
面向仿真的资产需要满足物理约束,包括结构稳定性、质量分布、材料响应与接触动力学。研究演进呈现出从后验修正向原生统一生成的清晰脉络。
在物理属性理解方面,NeRF2Physics[87]从语言嵌入的特征场中蒸馏物理属性(密度、摩擦、硬度),实现零样本属性预测;GaussianProperty[93]结合SAM分割与GPT-4V推理,通过多视角投票为3DGS资产分配逐部件材料属性。在后验物理修正策略中,Atlas3D[88]将可微仿真信号引入文本到三维的优化过程,对稳定性违反进行惩罚;PhysComp[89]在力学平衡约束下优化四面体网格;DensiCrafter[96]在不改变可见几何的前提下细化内部密度场以实现稳定性。
更具原则性的方向是将仿真器反馈纳入训练过程。DSO[92]通过非可微仿真器为生成物体标注稳定性分数,构建偏好数据集,进而通过偏好优化微调生成器以内化物理稳定性。PhyCAGE[90]将三维高斯表示与物理引导的分数蒸馏相结合,实现组合式多物体生成。最新的原生统一物理生成框架则在一个模型内联合建模几何、外观与物理属性:PhysX-3D[21]编码了几何、尺度、材料与运动学属性;PhysX-Anything[97]进一步将其扩展为基于图像条件的生成,并直接导出URDF与MJCF格式;SOPHY[94]强调了空间变化材料场对异质物体的重要性;PhysGaussian[33]将3DGS与物质点法(MPM)耦合,统一了渲染与仿真。
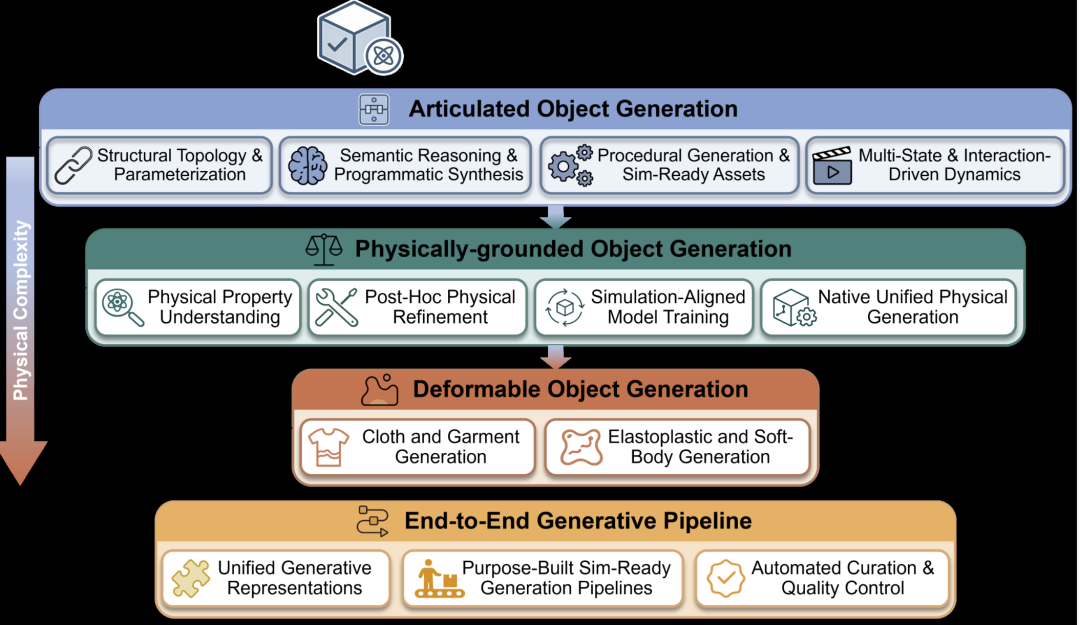
图2 面向具身智能的生成式三维物体方法概览,按物理复杂度递增组织:关节型(运动拓扑与运动学)、物理 grounded(质量、摩擦、材料属性)、可变形(连续介质力学)与端到端管线。
2.3 可变形物体生成:布料与软体的仿真就绪表达
可变形物体的生成需要处理由连续介质力学(FEM、MPM、PBD) governing 的高维连续状态空间。当前进展主要集中在两个方向:面向人形操作的服装生成,以及面向接触丰富交互的弹塑性软体生成。
在服装生成方面, sewing pattern(缝制图案)提供了与布料仿真器直接兼容的仿真就绪中间表示。DressCode[98]开创性地通过语言提示生成缝制图案序列,并合成PBR纹理;GarmentDreamer[100]将其扩展为基于3DGS多视角引导的文本到三维生成,同时保持仿真兼容的拓扑;Dress-1-to-3[15]将可微布料仿真器嵌入优化循环,从单张图像联合恢复缝制图案与材料属性;Image2Garment[101]通过前馈框架一次性预测材料组成,提升了可扩展性。
对于软体对象(泡沫、绳索、食物、颗粒材料),核心难点在于材料场估计。PhysGaussian[33]将3DGS与MPM耦合,使每个高斯基元同时充当渲染原语与仿真粒子,支持弹性、塑性、流体与颗粒动力学。PhysDreamer[99]通过优化空间材料场,使MPM仿真运动与视频生成先验的动态相匹配,从而消除了手动材料指定。虽然缝制图案管线已开始实现布料资产的大规模仿真就绪,但通用软体生成仍面临高昂的逐实例优化成本。
2.4 端到端仿真就绪管线:从生成到部署的自动化
实际部署的主要瓶颈在于集成鸿沟:即使高质量的网格也需要经过修复、UV映射、材质分解、尺度校准、碰撞几何与格式序列化等后处理才能进入物理引擎。端到端管线通过自动化从生成到仿真就绪的完整路径来解决这一问题。
TRELLIS[34]提出了一种结构化隐式表示,联合编码三维结构与视觉细节,使多个解码器能够从共享隐式编码同时输出辐射场、3DGS或网格。其后续工作TRELLIS.2[102]进一步增加了几何锐度与原生PBR支持。Seed3D 1.0[26]将几何生成与多视角纹理合成、PBR估计、UV补全与数据标准化相结合,产出可导入Isaac Sim的封闭纹理网格。EmbodiedGen[25]采用模块化方法,集成图像/文本到三维生成、质量控制、物理属性估计、URDF序列化与布局构建。这些管线表明,生成系统正从视觉内容创作者进化为具身资产引擎。

图3 数据生成方法的定性结果示例,涵盖关节型物体生成(URDFormer、Articulate-Anything、SINGAPO)与物理 grounded 物体生成(PhysX-3D、PhysX-Anything)的可供性、描述与材料属性可视化。
三、仿真环境:从静态场景到可交互世界
具身智能体训练需要可执行的仿真环境,以支持大规模感知、导航与操作。由于构建和标注真实环境成本高昂且扩展性受限,自动场景生成已成为扩展数据与任务多样性的关键手段。生成的环境不仅需要几何与外观,还需要提供语义结构、物理有效的布局、交互可供性以及仿真器所需的运行时元数据。
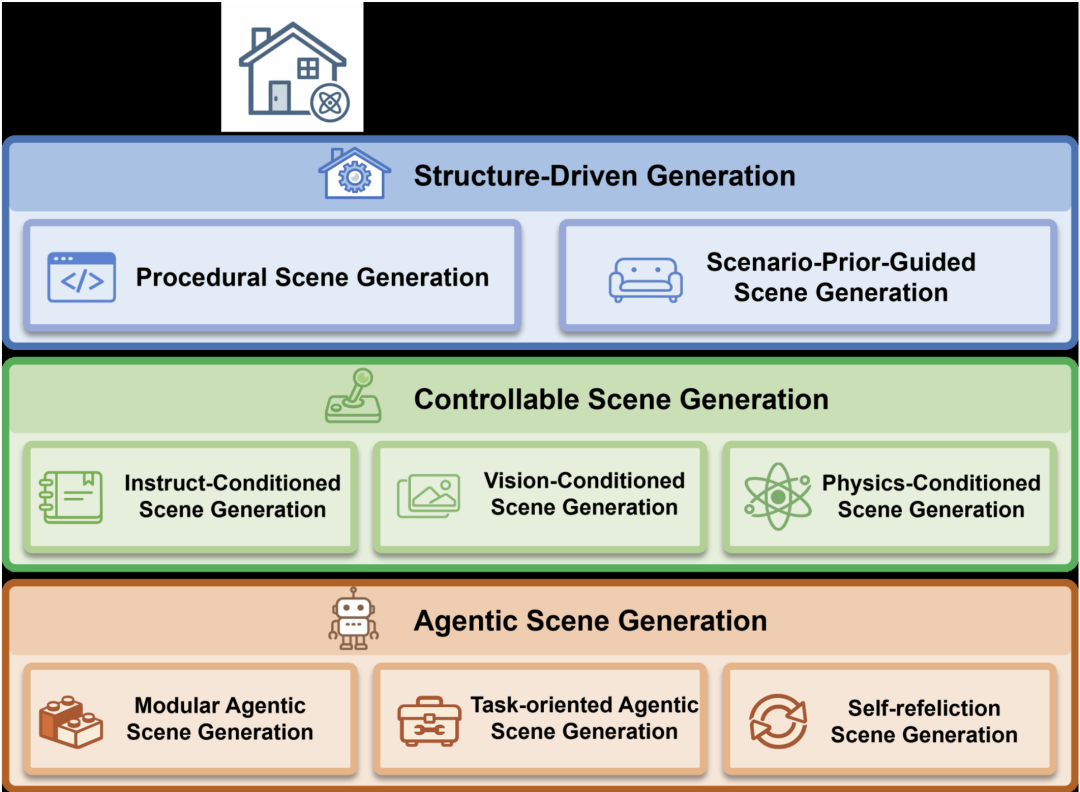
图4 面向具身智能的室内场景生成方法概览,从结构驱动生成(程序规则或学习先验),到可控生成(指令、视觉或物理条件),再到智能体生成(基础模型规划与自校正)。
3.1 结构驱动场景生成:布局先验与程序规则
早期方法首先产生机器可读的场景规格(房间布局、物体列表及其位姿与尺寸),然后从现有资产库中检索并实例化物体。ProcTHOR[117]在显式约束下采样楼层平面图、房间拓扑与物体放置,生成大规模交互式室内环境。Infinigen Indoors[120]在Blender中使用层次化程序规则产出多样化、照片级真实的场景,并附带元数据导出。LayoutGPT[119]利用LLM将文本提示转换为结构化的布局规格,并通过资产检索进行落地。Holodeck[121]将语言描述转换为关系约束,在实例化前优化物体配置。
另一类方法学习结构化场景表示的统计规律,并从学习到的分布中采样布局。Graph-to-3D[29]从关系场景图预测物体级三维表示;ATISS[47]以自回归方式生成室内场景,输出物体边界框与属性集合;CC3D[118]以二维语义布局为条件合成组合式三维场景;DiffuScene[122]在物体属性空间中进行去噪,生成多样化配置后再实例化资产。需要注意的是,所有结构驱动方法均依赖外部资产库(如3D-FUTURE、Objaverse)进行物体实例化,因此场景多样性最终受限于资产库的覆盖范围而非布局生成器本身。
3.2 可控场景生成:语言、视觉与物理条件
结构驱动方法仅提供粗粒度控制。可控场景生成引入灵活的条件信号(语言指令、图像或物理约束),以将布局合成引导至特定需求。
在指令条件生成方面,InstructScene[123]引入中间结构化表示以对齐文本指令与三维室内布局;SceneFoundry[129]面向公寓尺度生成,结合语言引导与基于扩散的合成以及物理可行性信号;Steerable Scene Generation[128]通过后训练与推理时搜索,使生成模型朝向下游目标进行适配。在视觉条件生成方面,SceneGen[130]通过组合式预测几何、纹理与空间排布,从单张图像生成多物体三维场景;DepR[124]以深度线索为条件进行实例级生成;MIDI[125]将扩散模型扩展为基于单张图像的多实例场景生成。在物理条件生成方面,PhyScene[17]将物理与交互引导纳入布局生成,以弥合视觉可信度与仿真可用性之间的差距;DynScene[126]面向动态操作场景,将生成分解为静态场景合成与动作相关组件;FactoredScenes[127]使用类程序生成对房间结构与物体位姿进行因子化。
3.3 智能体场景生成:基础模型驱动的规划与自校正
基础模型使智能体场景生成成为可能,其将高层意图转化为结构化规格,并通过工具使用与反馈持续修正语义与物理不匹配,从而提升单遍生成的鲁棒性。
模块化智能体将规划、检索、布局求解与验证通过结构化中间表示连接起来。OptiScene[133]通过分阶段偏好优化提升布局对齐度;LayoutVLM[134]结合视觉语言落地与可微优化,将布局细化为物理可信的配置;SceneCraft[131]采用代码生成方法,使用LLM智能体产出Blender可执行脚本。自反思方法则纳入显式评估与修复循环:SceneWeaver[135]将多种合成工具统一为具有迭代规划、评估与针对性修复的反思框架;SAGE[145]将布局与物体组合生成器与语义可信度和物理稳定性的学习评判器相结合;DisCo-Layout[139]通过协调的多智能体角色分离语义与物理细化。PAT3D[143]将刚体仿真集成到文本到三维生成中以减少穿透;PhyScensis[144]将物理关系表述为由物理求解器执行的谓词;SceneSmith[146]采用分阶段基于角色的智能体构建,并在各阶段进行验证与物理属性估计。

图5 面向具身智能的仿真环境生成代表性示例。HoloDeck通常产生结构化布局与相对受限的物体排布;SceneWeaver、SAGE与SceneSmith则生成更多样化且组合更丰富的场景,具备改进的物体多样性与空间复杂度。
四、Sim2Real桥接:连接仿真与现实的闭环数据流
前述章节聚焦于生成新的三维资产与将其组合为交互环境,而将这些能力部署于机器人学习则需要弥合合成生成与现实执行之间的鸿沟。Sim2Real桥接模块从三个顺序维度审视生成式三维表示如何支持这一连接:基于观测构建物理忠实的数字孪生、基于重建资产进行三维 grounded 数据增强,以及通过仿真与生成模型扩展任务相关的演示数据。
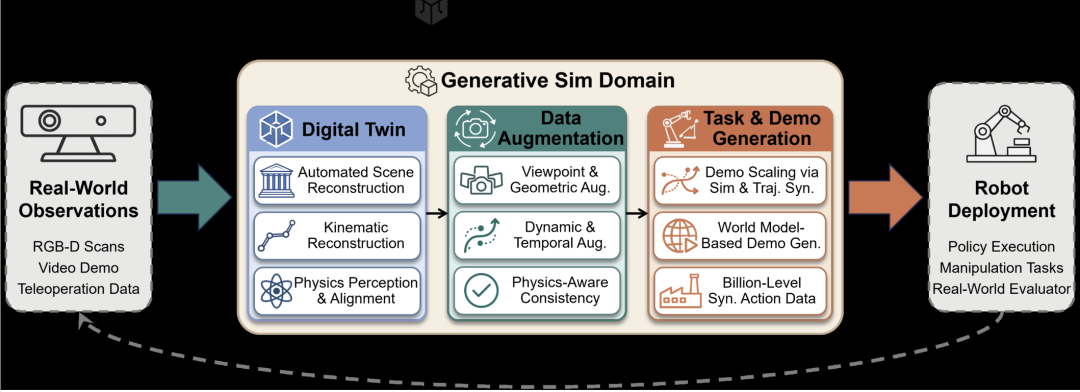
图6 Sim2Real桥接作为具身智能闭环数据生命周期的概览。真实世界观测被转换为数字孪生(Digital Twin),通过三维 grounded 数据增强进行扩充,并通过任务与演示生成实现规模化。合成数据训练真实机器人策略,其执行反馈迭代优化仿真。
4.1 生成式数字孪生:从观测到仿真就绪复制品
生成式数字孪生的目标是自动化地从真实世界观测构建仿真就绪复制品,以替代手工建模。DRAWER[159]与LiteReality[160]将原始视觉与深度数据转换为适用于图形引擎的交互环境。LatticeWorld[161]进一步集成LLM以协调多步重建,从多模态输入产出语义标注的虚拟复制品。RoboSimGS[162]从多视角图像构建混合3DGS-网格表示,并利用多模态LLM推断物理属性,实现零样本仿真到现实的迁移。
在运动学重建方面,Ditto[164]利用隐式神经表示从交互式三维点云联合优化几何与关节模型。PARIS[103]与ArticFlow[165]采用流匹配与形变场在动态观测序列上建立跨运动状态的密集对应关系。近期基于3DGS的方法提升了渲染保真度与运动学跟踪:ArticulatedGS[166]将高斯基元与刚性部件关联,实现关节状态优化与实时渲染;ArtGS[167]与REArtGS++[104]将这一方法扩展为从多视角或单目视频重建复杂关节拓扑与视角相关外观。
视觉保真度与正确运动学本身不足以闭合仿真到现实的鸿沟,还需要推断质量分布、表面摩擦、弹性与恢复系数等物理参数并注入重建表示。PhysTwin[169]结合弹簧-质量动力学模型、生成式形状先验与3DGS渲染,使用层次化稀疏到稠密优化从稀疏视频中提取材料参数。TwinAligner[170]将碰撞几何(用于刚体接触的SDF网格)与视觉渲染(叠加的3DGS原语)解耦,通过无梯度优化器匹配速度、惯性与质心参数,产出支持零样本策略部署的物理感知数字孪生。
4.2 生成式数据增强:从像素扰动到几何一致性
机器人操作的数据增强已从传统的二维图像空间编辑转向显式的三维与四维时空增强。核心动机是从少量人工采集的演示扩展到大量合成生成、物理 grounded 的样本。
在视角与几何增强方面,RoboSplat[173]将演示重建为3DGS场景,并在多样化相机位姿下渲染多视角伪观测,支持内容替换与等变变换。AOMGen[191]将这一方法扩展至关节型物体,生成尊重底层关节状态的多视角RGB轨迹。SplatSim[174]在仿真器中用高斯 splats 替代多边形网格,渲染照片级真实的观测以降低视觉域差距。
在动态与时序增强方面,ExoGS[63]将真实世界操作序列重建为可编辑的带有时序动态的3DGS资产,并引入掩码适配器注入实例级语义线索。GAF[177]用显式运动属性扩展三维高斯,以联合建模动态场景演化与动作预测。在物理感知一致性方面,Splat-MOVER[171]利用3DGS的显式语义可编辑性,在多阶段开放词汇操作过程中保持几何一致的数字孪生;SIGHT[175]通过将合成轨迹落地于显式三维空间表示,确保生成的动作序列尊重物理边界与接触几何。
4.3 生成式任务与演示:规模化合成动作数据
除了增强现有观测,另一互补方向是在规模上生成全新的演示与任务相关轨迹。MimicGen[179]通过空间变换将少量人类演示中的以物体为中心的动作段转换为跨多样化场景配置的数万条轨迹。Gen2Sim[180]将开放世界图像提升为三维资产,然后利用LLM分配物理参数并生成任务分解与奖励函数;GenSim2[181]进一步利用多模态推理LLM创建多达100个关节型物体任务与200个物体,训练可零样本迁移至真实机器人的多任务策略。
在世界模型驱动的演示生成方面,DreamGen[65]将图像到视频模型适配为面向机器人具身,生成照片级真实的推演并恢复伪动作序列;AnchorDream[185]将扩散直接条件化于渲染的机器人运动,将生成锚定于机器人运动学结构以防止空间幻觉;PhysWorld[186]将任务条件视频生成与物理世界重建相结合,通过以物体为中心的残差强化学习将合成运动落地为可执行动作。在基础模型规模合成训练方面,GraspVLA[190]策划了十亿帧的仿真抓取数据集SynGrasp-1B,通过渐进式动作生成(PAG)架构整合自回归视觉感知与基于流匹配的动作生成,展示了仿真规模三维生成可作为训练开放词汇具身基础模型的前提基础设施。

图7 Sim2Real桥接代表性示例。从左至右:Real-is-Sim展示同步数字孪生;SplatSim展示基于3DGS的仿真与数据增强;Gen2Sim展示为策略学习生成的关节型物体任务。
五、数据集与评测:从几何精度到具身性能
面向具身智能的三维资产生成进展依赖于同时提供 ground-truth 几何、物理标注与交互语义的数据集。与传统三维生成基准不同,具身应用需要联合捕获几何结构、物理属性与仿真器兼容性的数据集。
5.1 数据集演进
物体资产数据集沿两个轴线演进:几何规模与物理标注深度。早期数据集如ShapeNet[194]与PartNet[195]提供了几何基础但缺乏物理或运动学参数。向仿真就绪数据集的过渡以PartNet-Mobility[196]与AKB-48[200]中的运动学标注为标志,以及以Objaverse[201]与Objaverse-XL[204]为代表的大规模预训练语料库,后者以物理标注换取几何多样性。最新数据集如PhysXNet[21]、PhysX-Mobility[97]与Articulation-XL[49]解决了物理标注的关键缺口;DTC[205]与ManiTwin[206]则分别贡献了照片级真实感质量与操作相关元数据。
场景数据集从被动采集演进为主动构建。源数据集如3D-FRONT[211]与ScanNet[208]提供布局与语义先验;真实扫描数据集(Matterport3D[207]、Replica[209]、HM3D[212])作为场景先验与仿真环境。生成式数据集如ProcTHOR-10K[117]、SAGE-10K[145]与MetaScenes[138]强调可扩展性与仿真器就绪性。机器人演示数据集如Open X-Embodiment[213]、DROID[214]、RH20T[215]与BridgeData V2[216]提供高保真轨迹,而仿真基准如ManiSkill2/3[10]、RLBench[219]与LIBERO[220]提供受控评估平台。

图8 面向具身智能三维生成的主要数据集时间线,按资产类型(物体级、场景级、具身操作)组织,展示了从早期几何数据集到最新仿真就绪与任务导向数据集的演进。
5.2 三级评测体系
面向具身智能的三维资产生成评测超越了视觉质量,要求输出不仅在视觉上正确,而且在物理仿真下行为正确并支持下游机器人学习。这催生了一个三级层次化评测体系。
第一级为几何与外观质量,沿用标准几何指标(Chamfer Distance、EMD、F-Score、IoU)评估形状保真度,以及FID、CLIP Score评估语义对齐与分布视觉质量。然而,这些指标遗漏了关键的具身失效模式:低CD网格仍可能包含自相交或非流形边;外观指标与物理保真度及稳定渲染的相关性较弱。
第二级为物理可信度与仿真就绪性,包括物体级指标(如稳定性比率[92]、关节类型/轴/原点/限位误差[13,67]、穿透体积与无碰撞比率[91]、材料误差[21])以及场景级指标(碰撞率、超出平面图比率[17]、物体可达性[17]、稳定物体比率[145]、物理可信度分数[143])。其主要局限在于仿真器依赖性:在MuJoCo中稳定的资产可能在Isaac Sim中呈现伪影。
第三级为具身任务性能,是生成资产质量最直接的验证,将几何、物理与语义要求整合为单一标量。物体级指标包括抓取成功率[26]与关节操作成功率[25,97];场景级指标包括导航成功率与SPL[227];任务完成率[141]评估生成环境中的端到端任务执行;仿真到现实成功率[190]衡量在生成资产上训练的策略向真实机器人的迁移能力。
六、挑战与未来方向
尽管 surveyed 研究方向进展迅速,在三维资产生成成为具身智能可靠、可扩展的基础之前,仍存在显著挑战。
规模化物理 grounding
大规模仓库如Objaverse提供数百万几何模型但缺乏材料属性、质量分布与运动学参数。物理标注数据集远小于此,限制了PhysX-3D与SOPHY等模型的泛化能力。未来需要通过LLM/VLM辅助标注、可微仿真器自监督标注以及Infinite Mobility等程序管线的合成自举来扩展标注规模。
可变形与动态资产生成
与刚体和关节型物体相比,可变形资产生成尚不成熟。服装生成通过缝制图案管线已实现仿真就绪,但通用软体生成仍依赖昂贵的逐实例优化。发现类似于缝制图案的通用软体中间表示(如带有本构参数注释的物质点云)可能是解锁可扩展可变形资产生成的关键。
效率与可控性的权衡
基于学习的场景合成效率高但难以保证语义一致性与长程空间连贯性;智能体方法通过迭代LLM驱动细化实现更强的语义对齐,但计算成本高昂。未来方向包括摊销验证(用轻量级学习评判器替代完整物理仿真)与层次化生成(用高效扩散或前馈模型产生粗略布局,仅对任务关键区域进行智能体细化)。
此外,评测标准化亟待推进:当前几何指标忽视物理有效性,物理指标使用不一致,下游任务评估依赖仿真器与策略选择。需要建立覆盖格式有效性、物理可信度与下游任务性能的三级标准化基准套件,并包含跨仿真器一致性测试以暴露求解器依赖的伪影。
最后,闭合仿真到现实循环仍是结构性难题。生成模型产出用于渲染的网格或高斯,物理引擎需要带物理参数的封闭碰撞几何,策略学习需要任务相关语义——这些在独立社区中发展,通过脆弱的转换管线连接。长期方向是统一的基础模型,联合推理几何、物理与任务语义。PhysGaussian等表示(原语同时服务于渲染与仿真)以及EmbodiedGen与PhysX-Anything等联合产出几何、运动学与物理的管线,是迈向这一统一的早期步骤。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)