
具身智能中的传感器技术50——传感器融合0
摘要:本文系统阐述了具身智能的多模态感知融合体系。首先提出传感器"解剖学"框架,将机器人划分为小脑/前庭、双腿/底盘、双手/头三大功能区,并配置相应的传感器组合。其次重点分析了三大核心融合场景:1)"不倒翁"链路实现高动态平衡;2)"穿针引线"链路完成手眼力触协同;3)"听音辨位"链路实现视听融合。最后指出数据融合的三
·
摘要:本文系统阐述了具身智能的多模态感知融合体系。首先提出传感器"解剖学"框架,将机器人划分为小脑/前庭、双腿/底盘、双手/头三大功能区,并配置相应的传感器组合。其次重点分析了三大核心融合场景:1)"不倒翁"链路实现高动态平衡;2)"穿针引线"链路完成手眼力触协同;3)"听音辨位"链路实现视听融合。最后指出数据融合的三个进化阶段:Level1信号级融合(EKF滤波)、Level2特征级融合(BEV空间)、Level3决策级融合(VLA大模型),展现了从分立感知到端到端智能的发展路径。
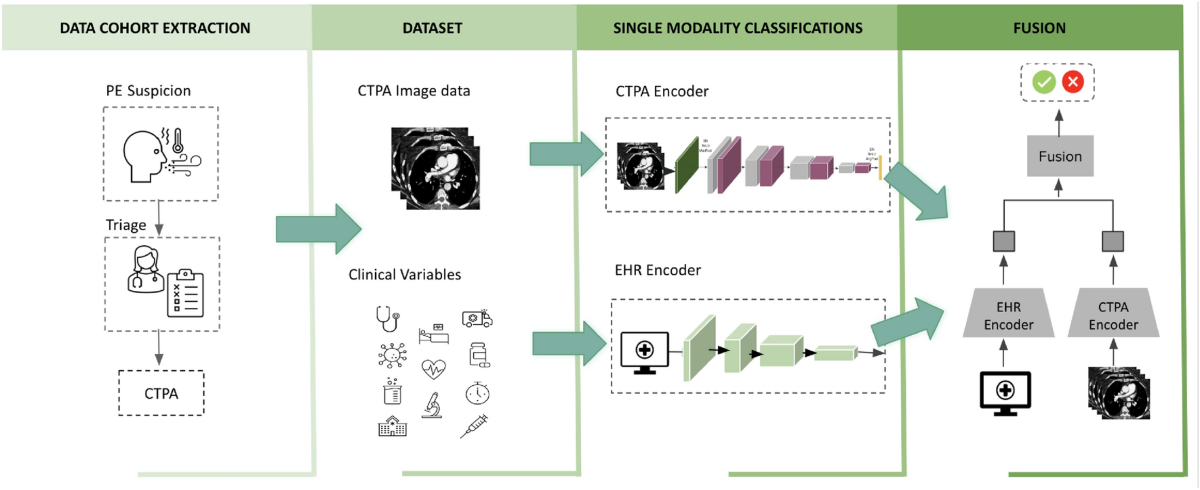
单纯堆砌传感器没有意义,具身智能的核心在于**“多模态融合 (Multimodal Fusion)”。我们将整套系统看作一个生物体**,从器官搭配(硬件组合)到神经传导(数据融合)进行系统性梳理。
一、 传感器“解剖学”:全能感知体系
我们将机器人分为三个功能区,每个区域有其固定的“传感器套餐”:
| 功能区 | 核心任务 | 传感器搭配 (黄金组合) | 生物学类比 |
|---|---|---|---|
| 小脑/前庭<br>(全身基准) | 活着 (不摔倒) | IMU (核心) + 关节编码器 + 关节力矩传感器 | 内耳前庭 + 肌梭 + 腱器官<br>(本体感知) |
| 双腿/底盘<br>(移动) | 走路 (去哪儿) | 激光雷达 (建图) + 鱼眼/ToF相机 (避障) + 脚踝六维力 (平衡) | 周围视觉 + 足底神经 |
| 双手/头<br>(操作/交互) | 干活 (怎么做) | RGB-D相机 (手眼协调) + 手腕六维力 (接触) + 触觉阵列/视触觉 (指尖) + 麦克风阵列 (听) | 中心视觉 + 手部触觉 + 耳朵 |
二、 核心融合场景:它们是如何配合的?
单打独斗是不行的,具身智能依赖以下三条核心**“反射弧”**(融合链路):
1. “不倒翁”链路:高动态平衡融合
- 场景: 机器人走路时被狠狠推了一把,或者踩到了电线。
- 传感器配合:
- IMU (毫秒级): 率先感到加速度突变,尖叫“要摔了!”。
- 脚踝六维力: 感知到 ZMP (零力矩点) 已经偏出脚掌边缘。
- 关节编码器: 汇报当前腿是弯的还是直的。
- 融合算法: 状态观测器 (State Observer)。
- 将 IMU 的高频数据与运动学模型融合,估算出质心 (CoM) 的真实状态。
- WBC (全身控制) 算法根据状态,瞬间命令脚踝电机发力“抓地”,腰部电机反向扭动“回正”。
2. “穿针引线”链路:手眼力触融合
- 场景: 机器人从桌上拿起一个装满水的软纸杯。
- 传感器配合:
- RGB-D 相机: 看到杯子,算出 (x,y,z) 坐标(视觉引导)。
- 机械臂: 伸过去,但视觉有误差,可能没对准。
- 手腕六维力/关节力矩: 手指碰到杯壁的瞬间,感受到阻力,停止运动(防止撞飞)。
- 指尖触觉/视触觉: 闭合手指,检测到压力分布和杯壁变形(判断纸杯软硬)。
- 指尖压电/事件相机: 刚拿起时,检测到杯子有微小滑移震动。
- 融合策略: 力位混合控制 + 触觉闭环。
- 视觉负责“大概位置”,触觉负责“最后1厘米”。如果检测到滑移,瞬间增加握力。
3. “听音辨位”链路:视听融合
- 场景: 嘈杂环境有人喊“嘿,机器人”。
- 传感器配合:
- 麦克风阵列: 计算出声音大概在右后方 135° (DOA)。
- 机器人: 转头,用 RGB 相机 扫描该方向。
- 视觉算法: 检测到那个方向有一张人脸且嘴巴在动。
- 融合算法: 注意力机制 (Attention Mechanism)。
- 将声源角度作为“提示 (Prompt)”,引导视觉系统锁定目标,实现精准交互。
三、 关键融合技术:从数学到 AI
数据融合分为三个层级,目前正从 Level 1 向 Level 3 进化。
Level 1: 信号级融合 (Signal Level) —— 数学滤波
- 核心算法: 扩展卡尔曼滤波 (EKF)。
- 典型应用: VIO (视觉惯性里程计)。
- 问题: 视觉(RGB-D)算出的位移虽然准但慢,且容易丢(白墙);IMU 算出的位移快但飘(积分误差)。
- 融合: 用 EKF 把两者“捏”在一起。视觉负责校准 IMU 的漂移,IMU 负责在视觉丢失时填补空缺。这是机器人定位的基石。
Level 2: 特征级融合 (Feature Level) —— BEV 空间
- 核心算法: BEV (Bird's Eye View) Transformer。
- 这主要是从自动驾驶学来的。
- 典型应用: 导航避障。
- 将 激光雷达的点云 和 摄像头的图像,统一投影到一个上帝视角的 3D 空间(BEV)中。
- 不管前面是人、车还是空气墙,都在这个统一的空间里被标记为“障碍物”。
Level 3: 决策级融合 (Decision Level) —— VLA 大模型
- 核心算法: Transformer / End-to-End Model。
- 典型应用: Google RT-2 / Tesla Optimus。
- 原理: 不再区分什么是视觉信号、什么是触觉信号。
- Tokenization: 把图像(Patches)、语言(Text)、触觉(Data)、关节角度(Floats)全部切片变成 Token。
- Inference: 扔进一个巨大的 Transformer 模型里,模型依靠“直觉”输出下一步动作。
- 例子: 模型“感觉”到(视觉+触觉)手里的杯子很滑且很重,直接输出“抓紧点”的指令,而不需要写一行
if slip then grip_harder的代码。
总结:具身智能的感知进化论
- 过去(拼凑): 视觉归视觉,力控归力控,各算各的,最后在代码里写
if-else。 - 现在(数学融合): 用 EKF/VIO 解决定位问题,用 WBC 解决平衡问题。
- 未来(端到端): VLA 大模型接管一切。所有的传感器数据都是大模型的输入 Token,所有的动作都是大模型的输出 Token。

电影级数字人,免显卡端渲染SDK,十行代码即可调用,工业级demo免费开源下载!
更多推荐



 19
19 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)